
Databases 타입(이어서)
Athena
- S3 위의 SQL layer라 볼 수 있다.
- S3의 데이터를 쿼리하기 위해 사용한다. - 완전한 서버리스 데이터베이스이다.
- 얼마나 많은 쿼리를 사용했는 지에 따라 비용을 지불한다.
- 쿼리 결과를 S3에 다시 적재할 수 있다.
- IAM을 통해 보안을 높일 수 있다.
사용 예시
- 1회용 SQL 쿼리
- S3에 대한 서버리스 쿼리
- 로그 분석
Solutions Architecture 관점의 Athena
- 운영
- 서버리스이기 때문에 관리가 필요하지 않다. - 보안
- IAM + S3 보안(버킷 정책)을 사용한다. - 신뢰성
- 뛰어난 Presto 엔진을 사용하는 완전 관리형이며 고 가용성이다. - 성능
- 쿼리는 데이터 크기에 따라 확장 된다. - 비용
- 실제 스캔된 데이터에 대해서만 지불하기 때문에 서버리스라 할 수 있다.
Redshift
- PostgreSQL 기반으로 만들어 졌다.
- OLAP(online analytical processing)를 하는 data warehouse이다.
- DW(Data Warehouse)보다 10배 더 좋은 성능을 갖는다.
- PB 단위의 데이터까지 확장이 가능하다. - row를 사용하지 않고 컬럼 형식으로 데이터를 저장한다.
- 대규모 병렬 쿼리 엔진인 MPP를 사용해 고성능이다.
- SQL로 쿼리를 수행할 수 있다.
- 프로비저닝 된 인스턴스에 따라 비용이 부과 된다.
- Quicksight나 Tableau와 같은 BI tool과 통합해 사용할 수 있다.
- S3로부터 DynamoDB, DMS 등에 로드 된다.
- 1 -> 128 개의 노드까지 확장이 가능하며 한 노드 당 128TB까지 사용 가능하다.
- Node 종류
- Leader Node: 쿼리 계획을 위해 사용되며 결과를 모으는 역할을 한다.
- Compute Noe: 쿼리를 수행해 Leader에게 그 결과를 전달한다. - Redshift spectrum: 다른 곳에 적재할 필요 없이 S3에서 바로 쿼리를 날리는 역할을 한다.
- 백업과 저장이 가능하며 vpc/IAM/KMS를 통한 보안 설정을 할 수 있고 모니터링이 가능하다.
- Redshift 강화 vpc 라우팅: COPY와 UNLOAD 명령은 공용 인터넷 대신 S3를 통해 vpc를 이용한다.
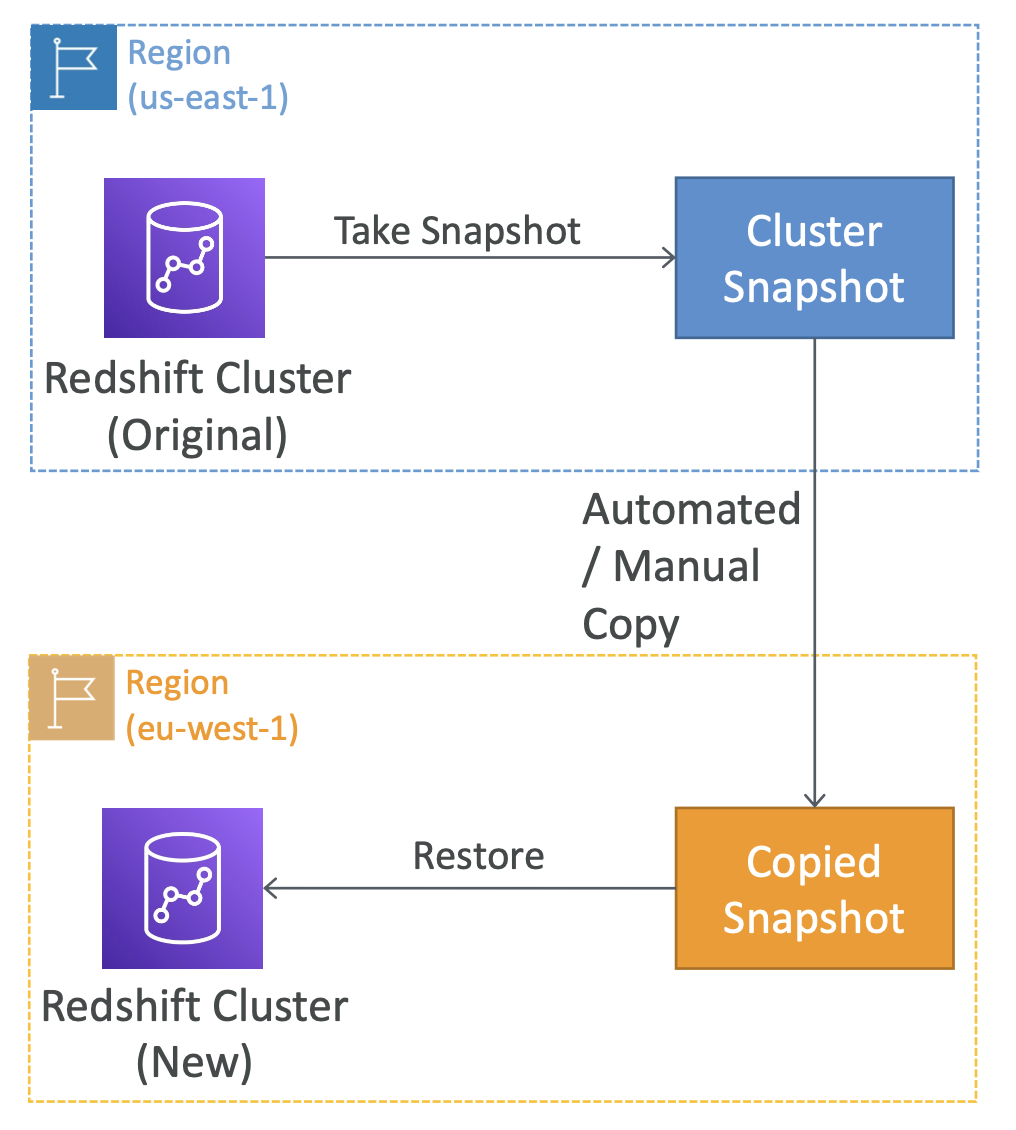
Snapshots & DR
- Multi-AZ 모드를 지원하지 않기 때문에 재해 복구를 하고 싶다면 스냅샷을 이용해야 한다.
- S3에 저장 된다.
- 변화가 있는 것만 저장해 공간을 절약할 수 있다.
- 스냅샷을 새로운 클러스터에 복원할 수 있다.
- 스냅샷 설정
- 자동화: 8시간 마다, 5GB 마다 스냅샷을 찍을 수 있으며 보존 기간을 설정할 수 있다.
- 수동: 스냅샷을 삭제하기 전까지는 계속해서 보존 된다.
-> 자동 설정이든 수동 설정이든 간에 스냅샷을 자동으로 복제해 다른 리전으로 보내 재해 복구에 사용할 수 있도록 설정할 수 있다.
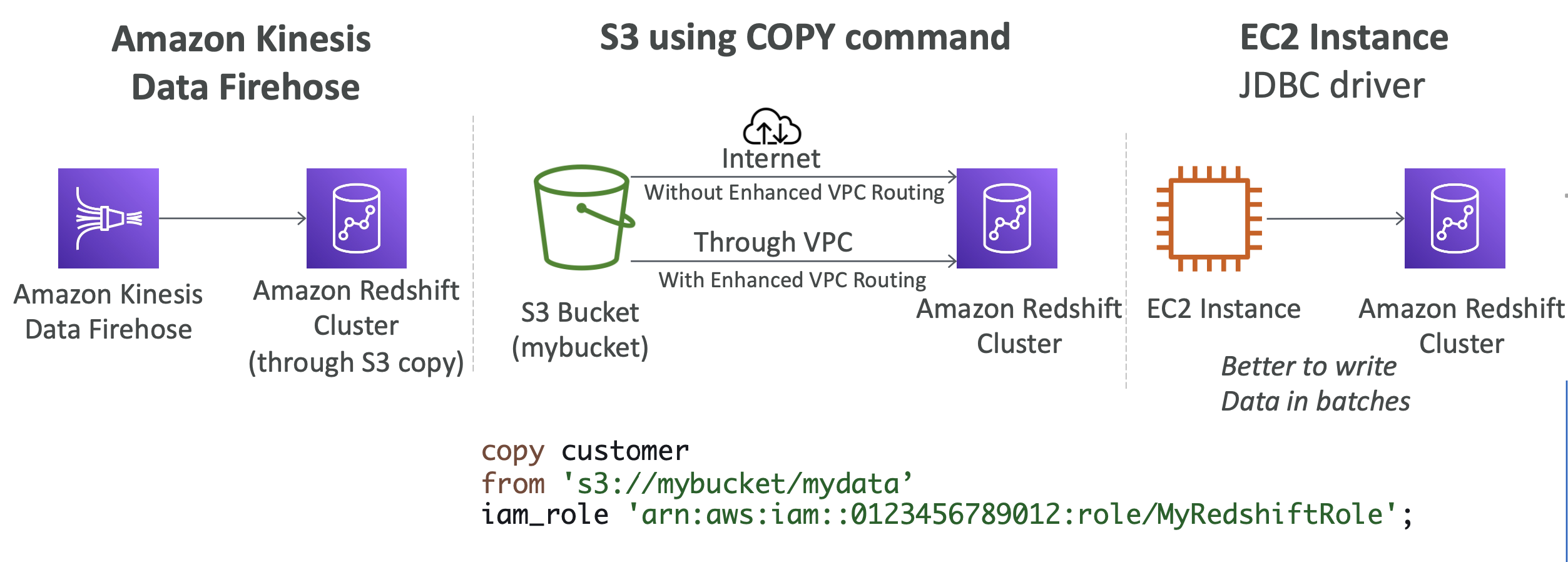
Redshift로 데이터 적재하기: 3가지 방법
-
Kinesis Data Firehose 이용하기
- 먼저 S3 버킷에 데이터를 기록한다.
- kinesis가 자동으로 S3 데이터를 복사하도록 명령을 내려 Redshift로 적재하도록 만든다.
-
S3에 COPY 명령을 이용하기
- 인터넷을 이용하는 방법과 향상된 VPC 라우팅을 이용하는 두 가지 방법이 있다.
- 보안을 높이려면 향상된 VPC 라우팅을 이용하는 것이 좋다.
-
EC2 instance의 JDBC 드라이버 이용하기
- EC2 인스턴스에 배포된 애플리케이션을 이용하고 있을 때 사용하면 된다.
- 데이터를 배치로 적재하는 데 유용하다.
Redshift Spectrum
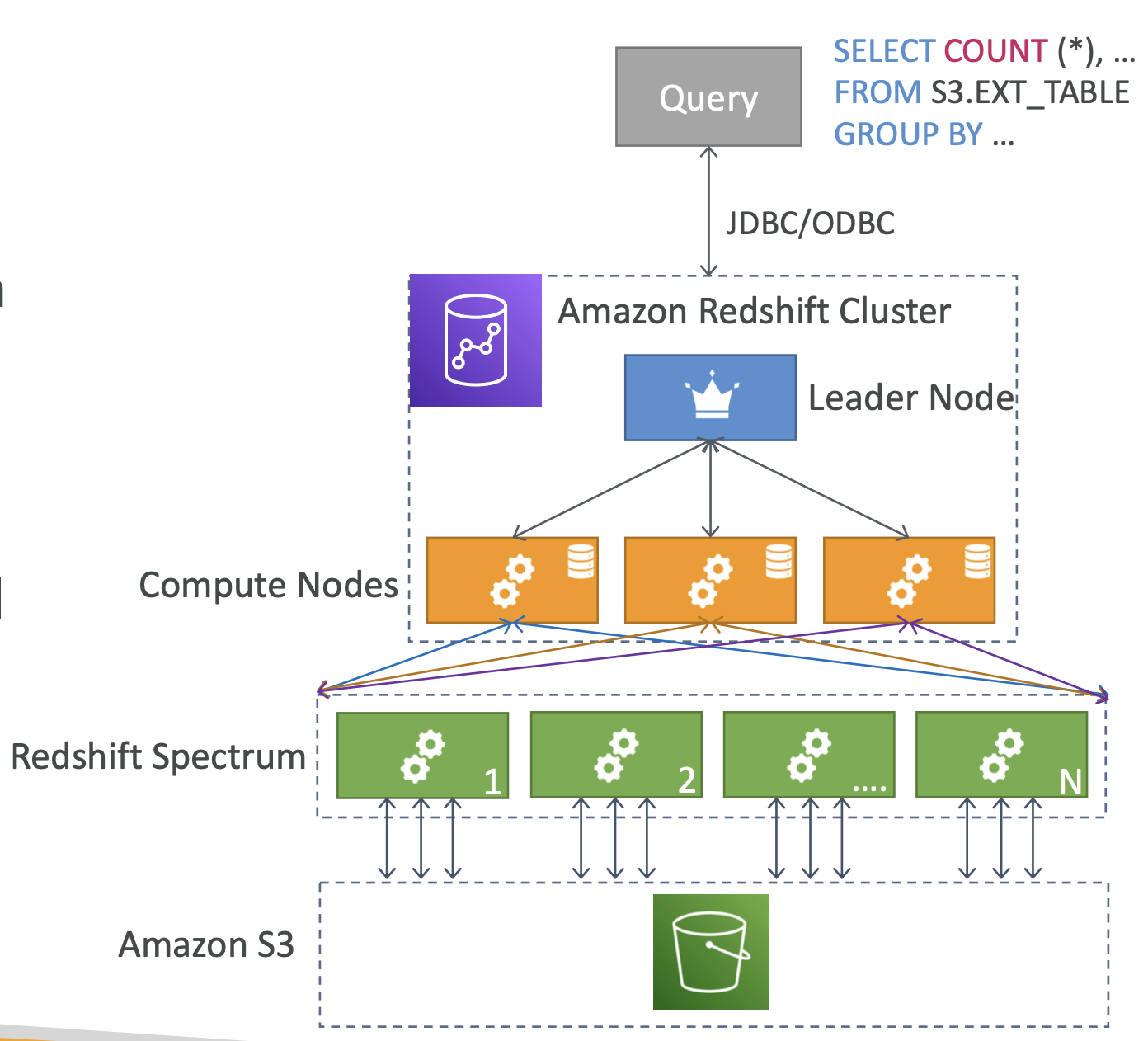
- S3에 있는 데이터를 Redshift로 적재하지 않고 쿼리를 날릴 수 있다.
- 쿼리하기 위해서는 Redshift cluster가 있어야 한다. - 쿼리는 수천개의 Redshift spectrum node에 전해지고 이를 통해 S3에서 쿼리한 뒤 그 결과를 Redshift cluster로 전달한다.
- 그러면 결과가 사용자에게 다시 전달된다. - Redshift Spectrum을 이용하면 Redshift cluster에 S3 데이터를 적재해 쿼리하는 것보다 훨씬 높은 성능을 보인다.
Redshift의 solutions architect
- 운영
- RDS와 유사하다. - 보안
- IAM, VPC, SSL, KMS - 신뢰성
- 자동 치유 기능과 교차 리전 스냅샷 복제 기능이 있어 재해 복구가 가능하다. - 성능
- 일반 data warehouse, 그리고 유사한 데이터 압축 대비 10배에 달하는 성능을 보인다. - 비용
- 프로비저닝 된 노드 당 요금이 부과 되며 다른 data warehouse의 1/10에 해당하는 비용이 부과된다. - Athena와 비교시 더 빠른 쿼리 처리 속도를 보이고 더 많은 데이터를 조인할 수 있으며 인덱스를 정의할 수 있기 때문에 더 빨리 데이터를 집계할 수 있다.
OLAP, BI, Data warehouse에 대한 이야기가 나온다면 Redshift를 떠올리면 된다.
