
DynamoDB란?
- 완전 관리형 NoSQL 데이터베이스로 고가용성이며 여러 AZ에 자동으로 복제된다.
- 분산형 데이터베이스로 대규모 워크로드에 확장하기 좋으며 수평 확장 가능성이 있다.
- 많은 용량을 저장할 수 있다.
- 한 테이블 안에서 일 초 당 수백번의 요청을 할 수 있다.
- 수 조의 행을 가질 수 있다.
- 수 백 TB를 저장할 수 있다. - 빠르며 일관된 성능을 가지고 있으며 지연시간이 짧다.
- 보안, 권한부여, 관리에 좋아 IAM과 통합하여 잘 사용한다.
- DynamoDB Streams를 통해 Event driven 프로그래밍이 가능하다.
- 비용이 적게 들며 auto-scaling을 할 수 있다.
구성
- 테이블로 구성된다.
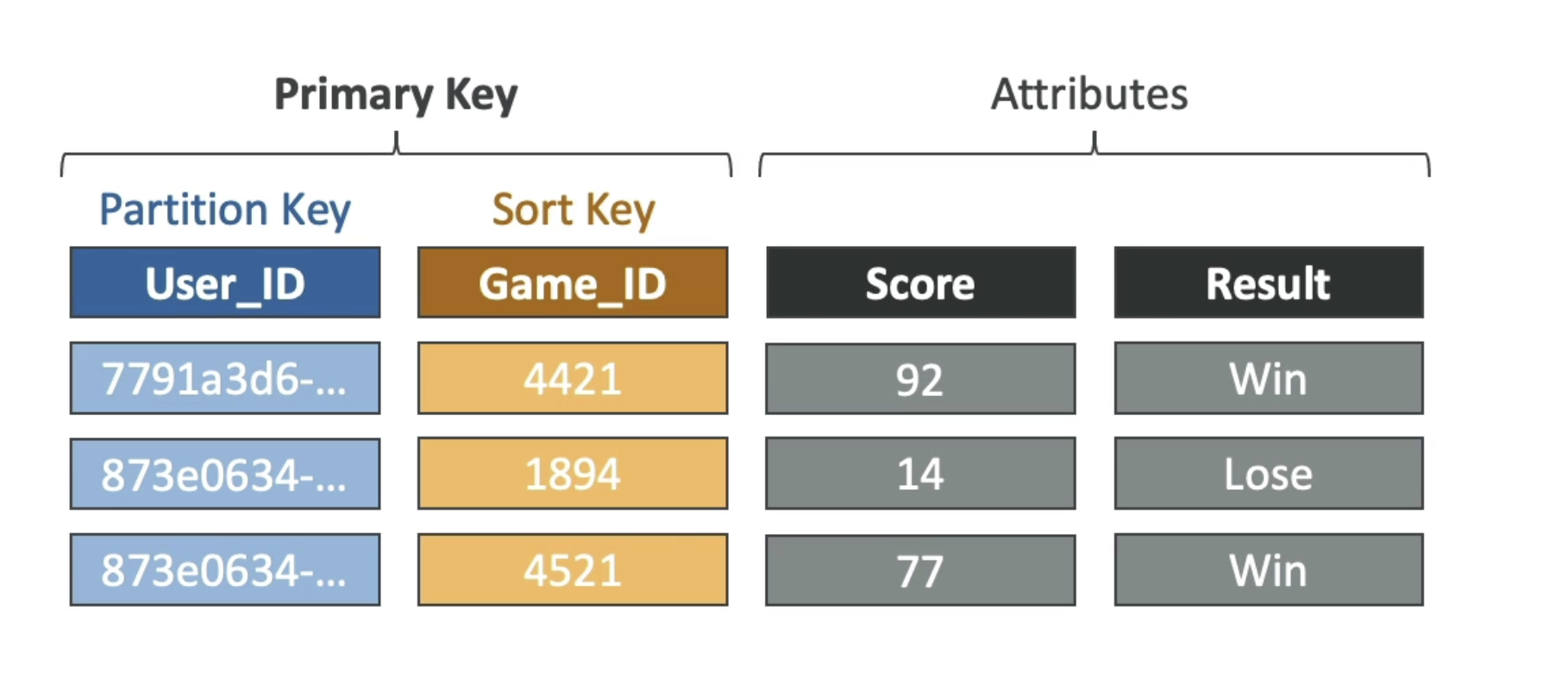
- 데이터베이스는 관리형으로 이미 생성된 것이기 때문에 테이블만 관리하면 된다. - 각 테이블은 Primary Key를 가지며 이는 테이블 생성시 정해져야 한다.
- 각 테이블의 행의 수는 무한대이다.
- 테이블의 각 item은 attributes(속성)을 지닌다.
- 시간이 지나면서 추가할 수 있으며 - item의 최대 크기는 400KB이다.
- 따라서, 큰 개체를 저장하기에는 좋지 않다. - 지원되는 데이터 타입
- Scalar Types: String, Number, Binary, Boolean, Null
- Document Types: List, Map
- Set types: String Set, Number Set, Binary Set - 모든 아이템은 서로 다른 속성을 가질 수 있다.
Read/Write Capacity Modes
- 이는 테이블 용량을 제어하는 방법이다.
- DynamoDB는 읽기와 쓰기에 어느 정도의 용량이 필요한 지만 정의하면 된다.
Provisioned Mode(default)
- 테이블에서 필요로 하는 초 당 읽기와 쓰기 숫자를 미리 명시한다.
- 용량은 미리 계획되어야 한다.
- 공급한 모든 것에 대한 비용을 지불해야 한다.
- Read Capacity Units(RCU) & Write Capacity Units(WCU)
- RCU, WCU 갯수에 따라 매월 비용을 지불하게 된다. - RCU와 WCU를 위해 Auto-scaling이 가능하다.
On demand Mode
- 워크로드(작업량)에 따라 읽기와 쓰기를 늘이거나 줄인다.
- 따라서, RCU 또는 WCU가 없다.
- 자동으로 모든 Read와 Write를 받아들이기 때문이다. - 용량 계획이 필요하지 않다.
- 자동으로 auto-scaling 한다. - 사용한 것에 대해서만 지불하지만 Provisioned Mode보다 비싸다(2~3배).
- 예측 불가능한 작업량을 가진 경우 사용하는 것이 좋다.
고급 기능
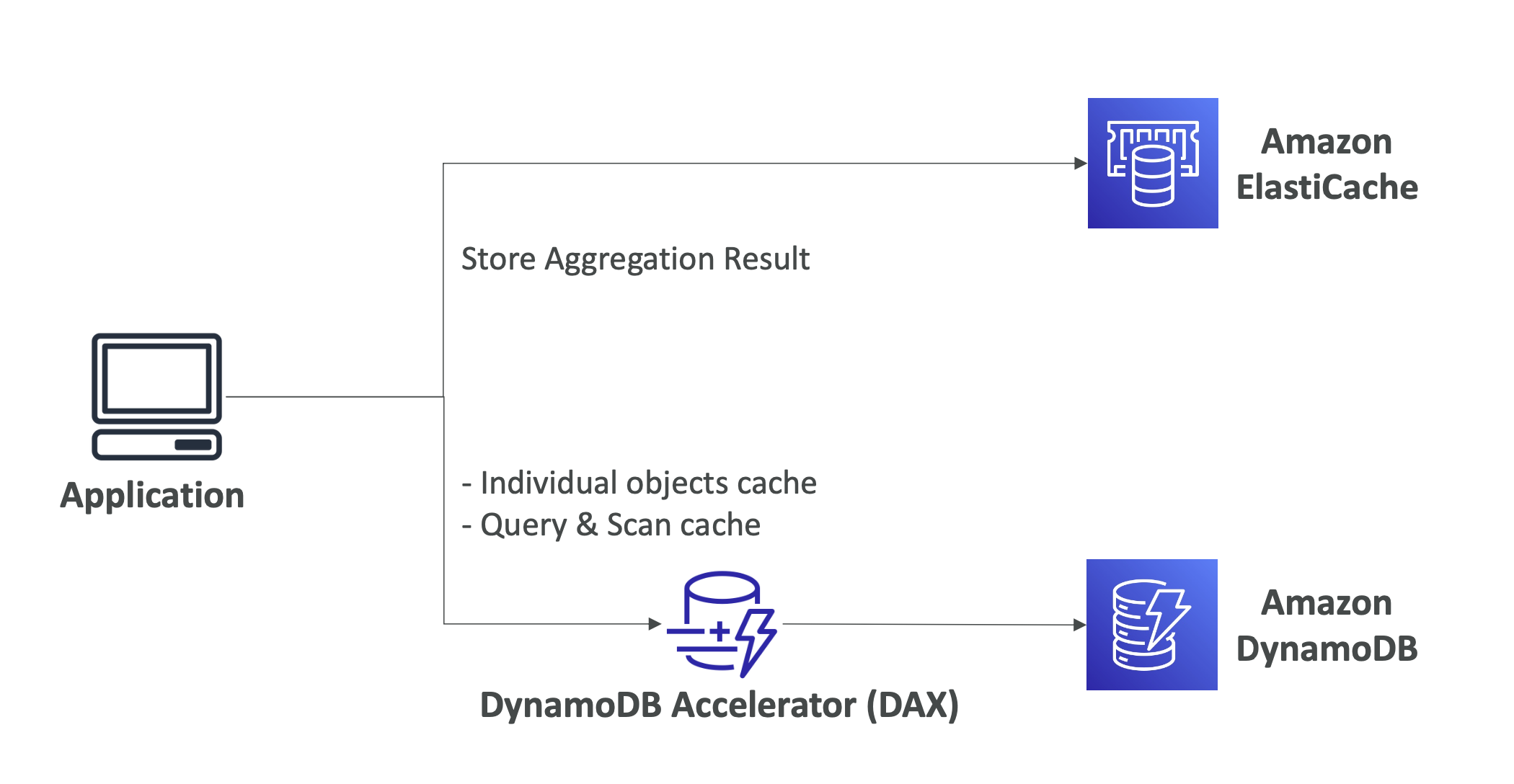
DynamoDB Accelerator(DAX)
- 완전 관리형의, 고가용성 인메모리 캐시이다.
- 읽기 데이터를 캐시에 저장해 읽기 혼잡을 해결한다.
- 캐시 데이터를 가져올 때 마이크로 초의 지연 시간이 생긴다.
- 기존에 사용하고 있던 DynamoDB API를 그대로 사용할 수 있다.
- 새로운 데이터는 5분간 저장된다(5 min TTL for cahche).
- 5분이 지나면 데이터는 만료되며 DynamoDB에서 re-fetch될 것이다.

DAX vs ElastiChache
DAX
- DAX는 DynamoDB를 위한 것으로, 개별 개체, 캐시, 쿼리 및 검색 쿼리에 사용하기 알맞다.
ElastiCache
- 만약 application이 DynamoDB로부터 데이터를 불러와 일종의 계산을 하고 집계 결과를 저장해야 하는 경우 사용하기에 좋다.
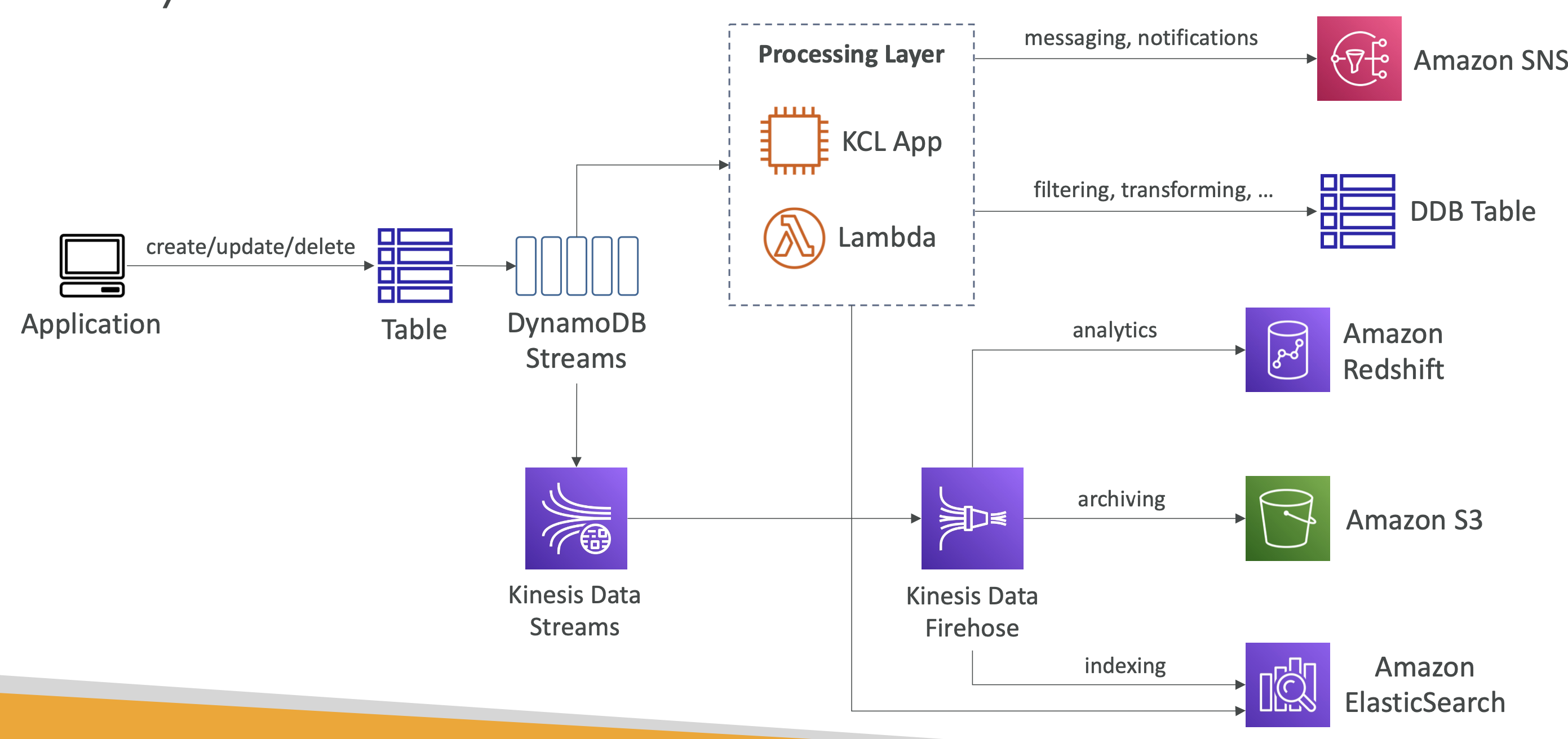
DynamoDB Streams
- 테이블의 아이템 레벨 수정을 나타내는 정렬된 스트림이다.
- 아이템을 생성, 수정, 삭제할 때마다 DynamoDB Streams를 거치게 된다. - Stream 기록들은
- Kinesis Data Stream로 보내지거나
- AWS Lambda가 읽거나
- Kinesis Client Library applications가 읽게 될 것이다. - DynamoDB 스트림의 데이터는 24시간 동안 보관된다.
- 사용 사례
- 실시간 변화에 대응(사용자에게 환영 이메일 보내기)
- 변화된 데이터 분석
- 파생 테이블에 삽입
- ElasticSeach에 삽입
- 영역간 복제
DynamoDB Global Tables
- 테이블은 여러 리전에 걸쳐 있을 수 있다.
- 즉, 동일한 테이블이 us-east-1, ap-southeast-2 등에 있을 수 있다.
- 이 때, 두 테이블은 two-way replication을 하며 global table이 만들어진다. - Global Tables를 만드는 이유는 여러 리전에 걸쳐 DynamoDB의 테이블에 접속하는 데 낮은 지연 시간을 소요되도록 하기 위함이다.
- two-way replication을 Active-Active replication이라 한다.
- application은 어느 지역에서든 테이블에 READ, WRITE가 가능하다.
- 즉, 위 그림에서 us-east-1에 쓰면 ap-southeast-2에도 쓰게 되고 read일 경우에도 마찬가지가 된다. - 위에서 언급한 two-way replication이 가능하기 위해서는 DynamoDB steams가 전제조건으로 필요하다.
- 따라서, DynamoDB Streams를 활성화 해야 한다.
- 그러면 업데이트 로그가 변경되면서 각 테이블은 서로 업데이트를 해서 two-way replication을 할 수 있다.
Time To Live(TTL)
- 만료 timestamp 이후에 자동으로 아이템을 삭제할 수 있다.
Indexes
- 높은 수준의 단계에서, pk 뿐만 아니라 다른 속성으로 쿼리하기 위해 사용할 수 있다.
- GSI(Global Secondary Indexes)와 LSI(Local Secondary Indexes)로 이루어져 있다.
Transactions
- 예를 들어 은행 잔고를 확인하기 위한 테이블
AccountBalance와BankTransaction가 있을 때 한 번에 두 테이블에 write 하거나 둘 중 어느 테이블에도 write 하지 않아야 한다.
