사실 앞쪽의 게시물 중 SNS에 대해 정리한 것이 있는데, 여기서 CloudWatch가 사용되고 있다. 따라서 CloudWatch 기능에 대해 간단히 언급한 부분이 있다. 순서가 뒤죽박죽 된 것은 그 때 스스로 필요에 의해 SNS에 대한 이해가 필요했기 때문이다. 이제 CloudWatch도 정리하고 넘어가려 한다.
CloudWatch란?
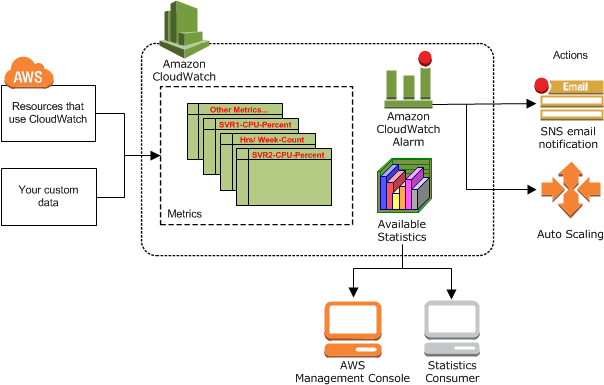
CloudWatch는 AWS 리소스 및 AWS에서 실행되는 애플리케이션을 실시간으로 모니터링 한다. 이를 통해 리소스 및 애플리케이션에 대해 측정할 수 있는 변수인 지표(metric)를 수집하고 추적할 수 있다.
CloudWatch에 들어가면 현재 내가 사용 중인 모든 AWS 서비스에 관한 지표가 자동으로 생성된다.
대시보드 기능
CloudWatch에서 대시보드 기능을 사용하면 현재 내가 여러 지표와 기간을 쪼개어 생성한 그래프를 저장할 수 있다. 기본적으로, 현재 생성된 그래프는 임시적인 것이기 때문에 새로고침하면 전부 사라지는 불상사가 생길 수 있다. 따라서, 그래프 우측 상단의 작업> 대시보드 생성 에서 해당 기능을 사용해 자주 사용하는 statistics 또는 기간 등을 저장할 수 있다.
생성된 대시보드를 확인할 때는 대시보드 메뉴로 들어가서 확인할 수 있는데, 확인하고 대시보드 저장 을 꼭 눌러줘야 원하는 상태로 저장하는 것이 가능하다.
경보
CloudWatch는 지표를 감시하여 알림을 보낼 수 있는데, 이 때 경보를 미리 설정할 수 있다. 즉, 내가 생각하기에 적절한 임계값을 설정하고 해당 임계값을 위반하면 모니터링 중인 리소스를 자동으로 변경하도록 만들 수 있다.
현재 내가 자주 사용하고 있는 것은 CPU Utilization이다. 임계값을 70~80으로 설정하고 CPU 점유율이 이 이상을 넘으면 SNS 알림이 슬랙으로 오도록 설정되어 있다. 이러한 경보 기능은 상당히 유용한데, 예를 들어 EC2 인스턴스의 CPU 임계값을 지정하여 사용량을 모니터링 하도록 설정해 놓았을 때 해당 임계값 이하인 상태가 계속 유지되면 이 인스턴스는 잘 사용하지 않는 인스턴스라는 의미가 된다. 따라서, 이를 계속 사용하는 것은 괜한 비용 추가를 발생시킬 뿐 불필요한 상황이 될 수 있다.
그러므로, 이 인스턴스를 중지할 수 있다는 의사 결정을 할 수 있으며 비용 절약을 가능하게 만들 수 있다. 또한 경보 생성시 auto-scaling 트리거를 발생시키도록 설정하면 알아서 auto-scaling까지 하도록 만들 수 있다. 이 밖에도 SNS event 트리거를 설정해 놓을 수도 있다.
용어 정리
가령,
- EC2 인스턴스의 CPU 점유율을 보고 싶다.
- RDS 인스턴스의 CPU 점유율을 보고 싶다.
라고 한다면 이 때 EC2 & RDS는 Namespace 라고 하며 CPU 점유율은 지표 metric 이라 한다. 또한, 이들을 인스턴스의 type(nano 혹은 micro) 별로 확인하고 싶다면 이러한 그룹은 Dimension 이라고 한다. 여기서 각 Dimension 별 평균 또는 최대, 최소 등등의 통계는 statistics 라고 부른다.
참고
1) 생활코딩 강의: AWS의 눈 - Cloud Watch
https://www.youtube.com/watch?v=jGryI-hBA38
2) AWS Docs
https://docs.aws.amazon.com/ko_kr/AmazonCloudWatch/latest/monitoring/WhatIsCloudWatch.html
