
최근 로깅 시스템을 새롭게 구축하기 위해 그 방법을 찾고 있었는데 그 중 찾은 한 가지 방법은 다음과 같다.
- Kinesis Data Streams에 데이터를 쌓는다.(기존과 동일)
- 데이터가 들어오면 이에 대한 이벤트를 트리거 한다.
- Lambda를 통해 DynamoDB에 로그 데이터를 쌓는다.
그런데 여기서 어떤 지표에 유의해야 할 지, 그리고 Lambda의 성능을 어떻게 높일 수 있을 지를 자세히 알아보기 위해 aws summit 2002에서 발표한 "데이터 분석 실시간으로 처리하기: Kinesis Data Streams vs MSK" 강연을 참고했다.
모니터링 지표
제약 조건
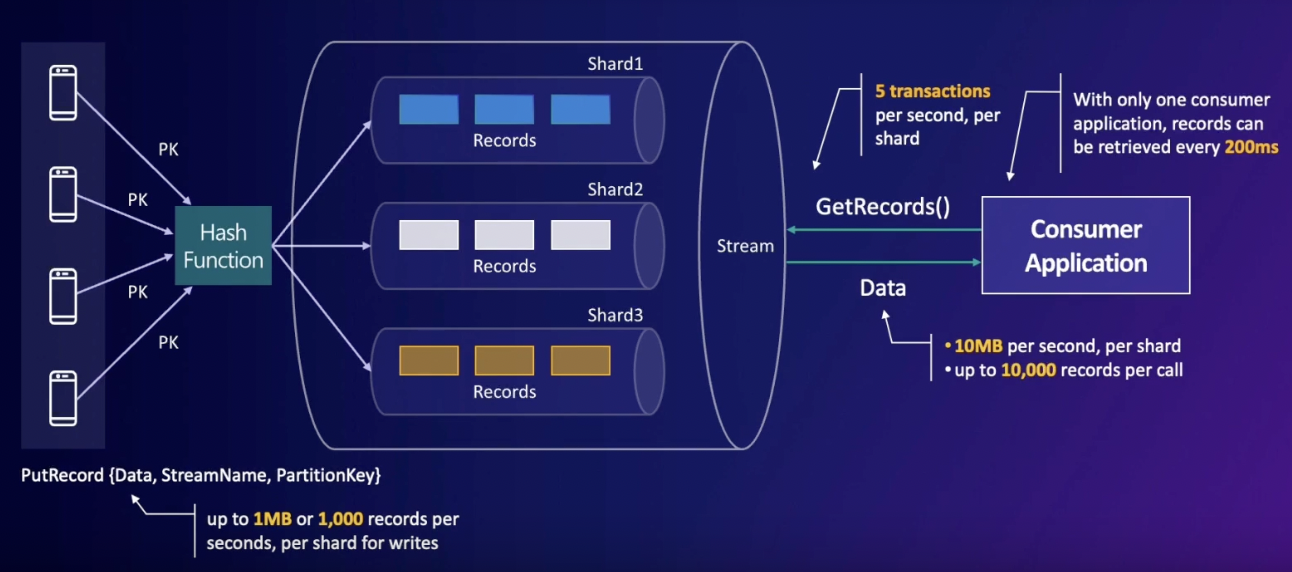
API 제약 조건
PutRecord의 경우 초 당, 샤드 당 1MB만 가능하며 1000개의 레코드만 넣을 수 있다. 반면 GetRecord의 경우 초 당, 샤드 당 10MB만 가능하며 한 API 호출 당 10000개의 레코드만 읽을 수 있다.
Transactions
하나의 샤드에 대해 초 당 5번의 read만 가능하다(5 transactions). 이 조건을 넘어 갈 경우 counsumer들은 추가 데이터를 읽기 위해 wait 하게 되어 샤드 안에서 읽어지지 못한 데이터들이 남아서 대기하는 시간이 길어지게 된다. 따라서, 샤드 내의 레코드들이 얼마나 오랫동안 처리되지 못하고 대기하고 있는 지 모니터링 하는 것이 필요하다.
모니터링 지표
- Incoming data(count)
- 스트림에서 수집한 개별 레코드의 수
- Incoming data - sum(bytes)
- 스트림에서 수집한 총 데이터의 양
- GetRecords.IteratorAgeMilliseconds
- 'iterator age'가 증가하면 데이터 소비량이 데이터 수집량보다 뒤쳐지고 있음을 나타낸다.
- WriteProvisionedThroughputExceeded
- 위에서 언급한 Write throughtput을 초과한 레코드의 수
- ReadProvisionedThroughputExceeded
- 위에서 언급한 Read throughput을 초과한 레코드의 수
위 지표들 중 "샤드 내에서 레코드들이 얼마나 오랫동안 처리되지 못하고 대기하고 있는 지를 알 수 있는" 3번 메트릭이 가장 중요하다. 만약 이 메트릭 값이 길어지면 consumer가 데이터를 빠르게 읽지 못하고 있거나 샤드 당 1초에 5번만 읽을 수 있는 제약 조건을 넘어선 경우일 수 있기 때문에 샤드 수를 추가해 해당 이슈를 해결할 수 있다.
Lambda를 Consumer로 이용하기
람다가 kinesis에서 데이터를 읽어들일 때 throughput을 늘리고 latency를 줄일 수 있는 방법을 알아보자.
Throughput 늘리기
배치 사이즈/ 배치 윈도우 조정
배치 사이즈를 늘리거나 배치 윈도우를 늘리면 각 호출마다 함수에 전달 되는 평균 레코드 수를 늘릴 수 있을 뿐만 아니라 호출 횟수를 줄이고 비용을 최적화 할 수 있는 효과도 있다. 이 때, 배치 윈도우는 최대 300초까지 늘릴 수 있다.
Enhanced fan-out
다수의 Enhanced fan-out(EFO) consumers 기능을 사용하면 각 소비자에게 초 당 2MB의 전용 읽기 처리량을 제공할 수 있다.
Parallelization factor 조정하기
Parallelization factor는 람다가 polling 하는 동시 배치 수로, 동시에 병렬로 많은 레코드를 처리해야 하는 애플리케이션에 대해 설정하는 값이다. 기본적으로 람다 함수는 한 샤드에 대해서만 읽도록 설정되어 있어서 기본 값은 1이다. 이는 최대 10까지 설정이 가능하다. 만약 100개의 kinesis data shard가 있고 Parallelization factor를 2로 설정 했다면 최대 200개의 람다 함수를 동시에 호출할 수 있어 데이터 처리량을 늘릴 수 있다.
Latency 줄이기
배치 사이즈/ 배치 윈도우 조정
위의 throughput에서와 방법은 동일하다.
Provisioned concurrency 사용하기
데이터 처리량이 증가하는 경우 람다 리소스의 cold start 때문에 latency가 증가할 수 있다. 이 경우 람다의 Provisioned concurrency를 사용해 cold start 시간을 줄일 수 있다.
(이는 또 다른 대안으로 cron으로 주기적으로 dummy data를 넣는 방법도 사용할 수 있을 것이다.)
Enhanced fan-out
HTTP/2 데이터 검색 API를 통해 latency를 1초에서 70ms 이내로 단축할 수 있다.
