문제 풀이 아이디어
특별하게 필요한 알고리즘은 없다. 단지 문자열을 원하는 조건에 맞게 다루기만 하면 된다. 원하는 조건은 다음과 같다.
- 대소문자를 무시할 것 (= 소문자로 변경할 것)
- 구두점을 제외할 것 (= 알파벳만 포함할 것)
- 단어를 셀 것
코드를 소개하기 전에 각각 단계에 내가 사용한 방법을 소개한다.
소문자로 바꿀 때는 한번에
어차피 각각의 단어를 소문자로 바꿀 것이라면 주어진 문자열 자체를 소문자로 바꾸고 시작하는 것이 편하다
paragraph.lowercased()구두점 제외하기
보통은 split 혹은 component를 활용하여 문장 안에 있는 단어를 나누곤 한다. 하지만 여기는 공백(” “) 뿐만 아니라 다른 구두점들 까지도 단어를 나누는데 사용된다. 따라서 하나의 Character를 기준으로 하는 기존의 split이 아닌 .split(whereSeparator:)를 사용하였다. 클로저의 parameter인 $0은 String의 Element, 즉 Character로 볼 수 있다.
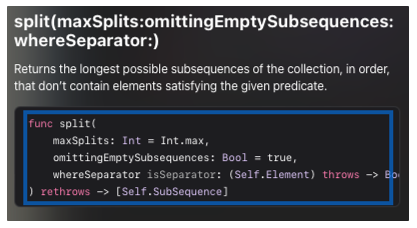
var words = paragraph
.lowercased()
.split(whereSeparator: { !$0.isLetter })
// 문자가 아닌 것을 기준으로 split단어 세기
파이썬에는 Counter라는 아주 편한 기능이 있다. 하지만 Swift에는 그런 것 없다. 대신 우리는 Dictionary(grouping: , by: )가 있다. 이 Dictionary의 initializer는 Sequence (여기서는 Array) 안에 있는 Element들을 by에 제시된 기준에 따라서 묶어 준다. 아래 예시를 보자.
// words가 ["bob", "a", "ball", "the", "ball", "flew", "far", "after", "it", "was"]일 때
print(Dictionary(grouping: words, by: { $0 }))
//🖨️ 출력 결과
// ["it": ["it"], "after": ["after"], "ball": ["ball", "ball"], "bob": ["bob"], "was": ["was"], "flew": ["flew"], "the": ["the"], "a": ["a"], "far": ["far"]]유레카다. 드디어 Swift에서도 파이썬을 부럽지 않은 편의기능을 알아냈다. 해당 코드를 해석해보면 words를 그룹핑 해주는데 기준은 자기자신 ($0)이라는 것이다. 즉 동일한 String끼리 묶어서 그룹핑을 해준다. 쉽게 설명하면 by에 제시된 클로저의 리턴값이 key, words의 element들이 value가 된다고 이해하면 된다. 하나의 예를 더 보자
print(
Dictionary(
grouping: [1, 2, 3, 4, 5, 6],
by: { $0 % 2 == 0 ? "짝수" : "홀수" }
)
)
//🖨️ 출력결과
// ["짝수": [2, 4, 6], "홀수": [1, 3, 5]]코드
나머지 설명은 code에 적었다.
class Solution {
func mostCommonWord(_ paragraph: String, _ banned: [String]) -> String {
var words = paragraph
.lowercased() // 소문자로
.split(whereSeparator: { !$0.isLetter }) // 알파벳이 아닌 것을 기준으로 split
.map { String($0) } // String으로 파싱
.filter({ !banned.contains($0) }) // banned에 들어간 것은 필터링
let counter = Dictionary(grouping: words, by: { $0 }).mapValues { $0.count } // 단어들을 그룹핑해서 카운트
return counter.sorted { $0.value > $1.value }.map { $0.key }[0] // value 기준 내림차순으로 정렬해서 가장 큰 값의 key를 리턴
}
}