고급 쿼리
GROUP BY
GROUP BY는 행을 특정 컬럼 값을 기준으로 그룹화하여 집계 함수와 함께 사용하는 SQL 구문이다.
그룹 함수는 단 한 개의 결과 값만 산출하기 때문에 그룹이 여러 개일 경우 오류가 발생하다.
여러 개의 결과 값을 산출하기 위해 그룹 함수가 적용될 그룹의 기준을 GROUP BY절에 기술하여 사용
SELECT dept_code, SUM(salary) FROM employee; -- 에러 발생: SUM은 GROUP BY 함수
SELECT dept_code, SUM(salary) FROM employee GROUP BY dept_code;집계 함수(Aggregate Function), 그룹 함수
집계 함수는 여러 행의 데이터를 하나의 값으로 요약하는 함수이다.
주로 GROUP BY 절과 함께 사용되며, 합계, 평균, 개수 등을 구할 때 사용된다.
| 구분 | 설명 |
|---|---|
| SUM | 그룹의 누적 합계 반환 |
| AVG | 그룹의 평균 반환 |
| COUNT | 그룹의 총 개수 반환 |
| MAX | 그룹의 최대 값 반환 |
| MIN | 그룹의 최소 값 반환 |
| STD/STDDEV | 그룹의 표준 편차 값 반환 |
| VARIANCE | 그룹의 분산 값 출력 |
GROUP BY
-- EMPLOYEE에서 부서코드, 그룹 별 급여의 합계, 그룹 별 급여의 평균(정수처리), 인원 수를 조회하고 부서 코드 순으로 정렬
SELECT dept_code AS 부서코드,
SUM(salary) AS 합계,
FLOOR(AVG(salary)) AS 평균,
COUNT(*) AS 인원수
FROM employee
GROUP BY dept_code
ORDER BY dept_code ASC;
-- EMPLOYEE에서 부서코드와 보너스 받는 사원 수 조회하고 부서코드 순으로 정렬
SELECT dept_code 부서코드,
COUNT(bonus) 인원수
FROM employee
WHERE bonus IS NOT NULL
GROUP BY dept_code
ORDER BY dept_code ASC;
-- EMPLOYEE테이블에서 성별과 성별 별 급여 평균(정수처리), 급여 합계, 인원 수 조회하고 인원수로 내림차순 정렬
SELECT
CASE
WHEN SUBSTRING(emp_no, 8, 1) IN ('1','3') THEN '남'
WHEN SUBSTRING(emp_no, 8, 1) IN ('2','4') THEN '여'
ELSE'기타'
END AS 성별,
FLOOR(AVG(salary)) AS 평균,
SUM(salary) AS 합계,
COUNT(*) AS 인원수
FROM employee
GROUP BY 1 -- 성별
ORDER BY 인원수 DESC;HAVING 절
HAVING절은 GROUP BY로 그룹화된 결과에 조건을 걸 때 사용하는 SQL 절이다.
WHERE이 개별 행에 조건을 걸 때 사용하는 것과 달리, HAVING은 집계 함수 결과에 조건을 걸 때 사용
-- 부서 코드와 급여 3000000 이상인 직원의 그룹별 평균 조회
SELECT dept_code, FLOOR(AVG(salary)) 평균
FROM employee
WHERE salary >= 3000000
GROUP BY dept_code
ORDER BY 1;
-- 부서 코드와 급여 평균이 3000000 이상인 그룹 조회
SELECT DEPT_CODE, FLOOR(AVG(salary)) 평균
FROM employee
GROUP BY dept_code
HAVING FLOOR(AVG(salary)) >= 3000000
ORDER BY dept_code;ROLLUP
ROLLUP은 GROUP BY 절에서 다단계 소계와 총계를 함께 출력할 수 있도록 확장하는 기능
상위 그룹부터 하위 그룹까지의 집계 결과를 자동 생성하여 분석에 유용하게 활용된다.
SELECT job_code, SUM(salary)
FROM employee
GROUP BY ROLLUP(job_code);인자로 전달받은 그룹 중 가장 먼저 지정한 그룹별로 추가적 집계 결과 반환
SELECT job_code, dept_code, SUM(salary)
FROM employee
GROUP BY ROLLUP(job_code, dept_code)
ORDER BY job_code, dept_code;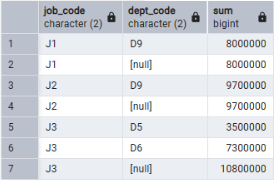
GROUPING
ROLLUP이나 CUBE에 의한 집계 산출물이 인자로 전달받은 컬럼
집합의 산출물이면 0 반환 아니면 1 반환
SELECT dept_code, job_code, SUM(salary),
CASE WHEN GROUPING(dept_code) = 0 AND GROUPING(job_code) = 1
THEN '부서별 합계'
WHEN GROUPING(dept_code) = 1 AND GROUPING(job_code) = 0
THEN '직급별 합계'
WHEN GROUPING(dept_code) = 1 AND GROUPING(job_code) = 1
THEN '총 합계'
ELSE '그룹별 합계'
END AS 구분
FROM employee
GROUP BY ROLLUP(dept_code, job_code)
ORDER BY dept_code, job_code;집합 연산자
집합 연산자
여러 개의 SELECT 결과물을 하나의 쿼리로 만드는 연산자
→ 서로 다른 테이블에서도 병합이 가능함으로 현업에서 매우 유용하게 활용!
UNION, UNION ALL, INTERSECT, EXCEPT
UNION
여러 개의 쿼리 결과를 합치는 연산자로 중복된 영역은 제외하여 합치는 연산자
SELECT emp_id, emp_name, dept_code, salary
FROM employee
WHERE dept_code = 'D5'
UNION
SELECT emp_id, emp_name, dept_code, salary
FROM employee
WHERE salary > 3000000;UNION 연산자는 컬럼명의 개수만 일치하면 서로 다른 테이블도 병합이 가능하다.
→ 사실 약간 비정상적인 활용이지만, 현업에서는 굉장히 유용하다.
SELECT local_code, local_name FROM location
UNION
SELECT job_code, job_name FROM jobUNION 정렬하기
UNION을 정렬하기 위해선 Subquery로 묶어 ORDER BY를 한번에 적용하면 된다.
(SELECT local_code, local_name FROM location
UNION
SELECT job_code, job_name FROM job)
ORDER BY 1;UNION ALL
여러 쿼리 결과를 합치는 연산자로 중복된 영역 모두 포함하여 합치는 연산자
SELECT emp_id, emp_name, dept_code, salary
FROM employee
WHERE dept_code = ‘D5’
UNION ALL
SELECT emp_id, emp_name, dept_code, salary
FROM employee
WHERE salary > 3000000;INTERSECT
여러 개의 SELECT 결과에서 공통된 부분만 결과로 추출(교집합)
SELECT emp_id, emp_name, dept_code, salary
FROM employee
WHERE dept_code = 'D5'
INTERSECT
SELECT emp_id, emp_name, dept_code, salary
FROM employee
WHERE salary > 3000000;EXCEPT
선행 SELECT 결과에서 다음 SELECT 결과와 겹치는 부분을 제외한 나머지 부분 추출(차집합)
SELECT emp_id, emp_name, dept_code, salary
FROM employee
WHERE dept_code = 'D5'
EXCEPT
SELECT emp_id, emp_name, dept_code, salary
FROM employee
WHERE dept_code = 'D5' AND salary > 3000000;