ORM과 JPA의 이해
ORM 등장 배경 - 객체와 RDB의 패러다임 불일치
ORM이 등장하기 이전, 관계형 데이터베이스와 연동하기 위해선 주로 JDBC를 사용하였다.
이때 객체지향 언어인 Java와 RDB간의 패러다임 불일치 발생하였는데, 객체는 클래스, 상속, 캡슐화, 참조를 기반으로 표현되지만 관계형 데이터베이스는 테이블, 행, 열, 외래키로만 데이터를 표현 되었고, 이로 인해 객체의 계층 구조나 다형성을 테이블 구조로 매핑하기 어렵고, 조인이나 별도의 변환 과정이 필요하였다.
public List<User> findAll() {
List<User> users = new ArrayList<>();
String sql = "SELECT id, username, email FROM users";
try (PreparedStatement pstmt = conn.prepareStatement(sql);
ResultSet rs = pstmt.executeQuery()) {
while (rs.next()) {
User user = new User();
user.setId(rs.getLong("id"));
user.setUsername(rs.getString("username"));
user.setEmail(rs.getString("email"));
users.add(user);
}
} catch (SQLException e) {}
return users;
}ORM 등장배경 - SQL 중심 개발의 문제점
JDBC의 등장 이후 RDB와 객체지향 언어인 Java와 연동성을 편리하기 위해 등장한 프레임워크는 MyBatis(구 iBatis)다. SQL Mapper를 통해 RDB의 결과를 객체와 자동으로 Mapping하는 기능이 탑재되었지만, 여전히 SQL을 직접 작성해야 해 비즈니스 로직이 SQL에 강하게 결합된다. 객체 모델의 상속·연관관계를 SQL로 풀어내야 하므로 패러다임 불일치 문제가 해소되지 않는다. 이에 따라 SQL 관리 부담과 유지보수성 한계를 해결하기 위해 ORM(Hibernate)가 등장하였다.
MyBatis 코드 예시- 활용
// 사용자 조회
User user = mapper.findById(1L);
System.out.println(user.getUsername());
// 사용자 생성
User newUser = new User();
newUser.setId(2L);
newUser.setUsername("hong");
newUser.setEmail("hong@example.com");
mapper.insertUser(newUser);MyBatis 코드 예시 – Mapper + XML
public interface UserMapper {
User findById(Long id);
void insertUser(User user);
}
<select id="findById" resultType="User">
SELECT id, username, email
FROM users
WHERE id = #{id}
</select>
<insert id="insertUser" parameterType="User">
INSERT INTO users (id, username, email)
VALUES (#{id}, #{username}, #{email})
</insert>ORM(Object Relational Mapping)이란?
ORM은 객체지향 언어의 클래스와 관계형 데이터베이스의 테이블을 매핑하여 SQL 없이도 데이터 조작이 가능하도록 하는 기술이다. 개발자는 객체 중심으로 비즈니스 로직을 작성하면 ORM이 이를 SQL로 변환하고 실행한다. 이를 통해 패러다임 불일치 문제를 줄이고, 또한 특정 DBMS의 문법에 종속되지 않고, 동일한 코드로 여러 데이터베이스를 지원할 수 있도록 추상화를 제공하여 동일한 코드로 다른 DBMS 연동이 가능하다.
ORM과 Mybatis의 장단점 비교
| 구분 | ORM (JPA/Hibernate) | MyBatis |
|---|---|---|
| 개념 | 객체와 테이블을 매핑하여 SQL을 자동 생성·실행하는 프레임워크 | 개발자가 작성한 SQL과 객체를 매핑하는 SQL 매퍼 프레임워크 |
| 개발 방식 | 객체 중심, SQL 자동화 | SQL 중심, 매퍼(XML/Annotation) 기반 |
| 제어권 | 프레임워크가 SQL 생성·실행 제어 | 개발자가 SQL 직접 작성·최적화 |
| 패러다임 불일치 | 자동 매핑으로 상당 부분 해소 | 매퍼로 일부 해소되지만 완전 해결 불가 |
| DB 종속성 | 낮음 (DBMS 독립적) | 높음 (DBMS 문법 의존) |
| 장점 | - SQL 작성 최소화, 객체지향적 개발 - DB 독립성 확보 - 생산성·유지보수성 향상 | - SQL 제어권 있어 성능 최적화 용이 - 복잡한 쿼리 작성에 강함 - JDBC보다 코드 간결 |
| 단점 | - 복잡한 SQL 최적화 어려움 - 학습 곡선 존재 - 성능 튜닝 필요 | - SQL 관리·유지보수 부담 - DB 종속성 높음 - 패러다임 불일치 완전 해결 불가 |
| 적용 사례 | - 대규모 엔터프라이즈 시스템 - 표준화된 CRUD 중심 서비스 - DB 이식성이 중요한 환경 | - 데이터 분석/리포트 시스템 - 복잡한 쿼리 중심 시스템 - 성능 튜닝이 중요한 금융/대용량 처리 시스템 |
JPA(Java Persistence API) 소개
JPA는 자바 진영의 ORM 표준 명세로, 객체와 관계형 데이터베이스 간 매핑을 지원한다.
개발자는 SQL을 직접 작성하지 않고 객체 중심으로 코드를 작성하면, JPA 구현체(Hibernate 등)에서 SQL을 자동으로 생성한다. 이를 통해 패러다임 불일치 문제를 줄이고 생산성, 이식성, 유지보수성을 높인다.
JPA 특징
| 특징 | 설명 |
|---|---|
| ORM 표준 | 자바 진영의 ORM 표준 명세로 Hibernate, EclipseLink 등이 구현체 |
| 객체 중심 개발 | SQL 대신 엔티티(Entity)와 객체 그래프 탐색을 통한 데이터 처리 |
| SQL 자동 생성 | CRUD 및 연관관계 매핑 시 SQL을 자동 생성·실행 |
| 패러다임 불일치 해소 | 상속, 연관관계, 컬렉션 매핑 등을 지원해 객체와 RDB 간 간극 축소 |
| DB 독립성 확보 | DBMS에 종속되지 않고 다양한 DB로 이식 가능 |
| 캐시 성능 최적화 | 1차 캐시, 지연 로딩, 배치 처리 등 성능 최적화 기능 제공 |
Hibernate와 JPA의 관계
JPA(Java Persistence API)는 자바 진영에서 ORM을 표준화하기 위해 정의한 명세(Interface, API 스펙)이고, Hibernate는 이러한 JPA 명세를 구현한 대표적인 구현체(Implementation)이다.
JPA 표준을 따르면서 자체 기능도 추가 제공한다. 따라서 JPA는 표준 규격, Hibernate는 실제 동작하는 구현체라고 이해할 수 있다.
JPA 동작 방식의 이해
JPA는 사용자가 작성한 엔티티 객체를 기반으로 SQL을 자동 생성하고 실행하는 메커니즘을 가진다.
개발자가 Spring Data JPA를 통해 엔티티(Entity)를 작성하면, 내부적으로 JPA 구현체(Hibernate 등)가 SQL을 생성한다. 생성된 SQL은 JDBC API를 거쳐 JDBC Driver를 통해 실제 데이터베이스에 전달 되며, 개발자는 객체 단위로 작업하고 JPA가 SQL 변환과 DB 연동을 대신 처리한다.
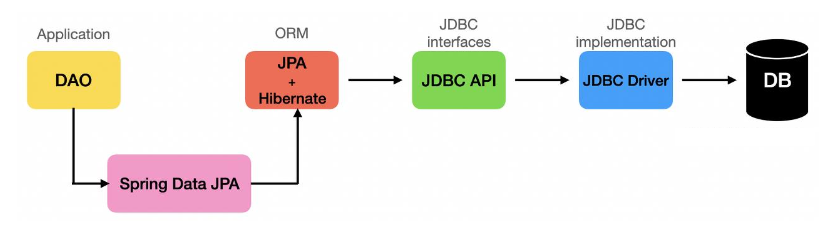
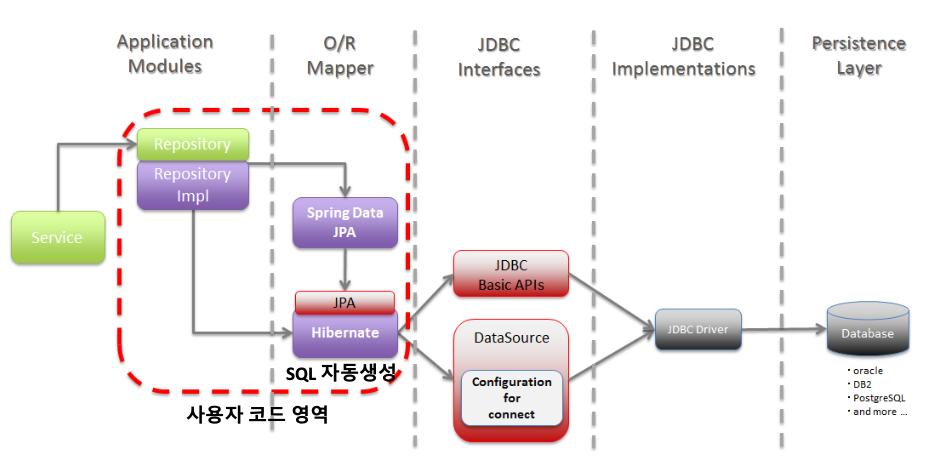
JPA 주요 구성 요소 소개
Entity: 데이터베이스 테이블과 매핑되는 자바 클래스이며, JPA가 관리하는 영속 객체이다. 각 엔티티 인스턴스는 테이블의 한 행(Row)에 해당하며, @Entity 어노테이션으로 선언된다.
EntityManager: JPA에서 엔티티를 관리하는 핵심 객체로, 엔티티의 생명주기(등록, 조회, 수정, 삭제)를 관리한다. 내부적으로 DB 연결을 담당하며, persist, find, merge, remove 등의 메서드를 제공한다.
영속성 컨텍스트(Persistence Context)
영속성 컨텍스트는 엔티티를 영구 저장하기 위해 엔티티를 관리하는 1차 캐시(메모리 공간)이다.
EntityManager가 관리하는 엔티티 인스턴스는 모두 이 컨텍스트에 저장되며, 변경 감지(Dirty Checking)와 동일성 보장(Identity) 같은 기능을 제공한다.
JPQL 개요
JPQL(Java Persistence Query Language)은 JPA에서 제공하는 객체지향 쿼리 언어로, 엔티티와 그 속성을 대상으로 쿼리를 작성한다. SQL과 유사하지만 테이블이 아닌 엔티티 클래스를 대상으로 하며, 데이터베이스 독립적인 쿼리를 지원한다. 실행 시 JPQL은 SQL로 변환되어 실제 데이터베이스에서 실행된다.
SELECT
u.id, u.username, p.id, p.title
FROM users u
JOIN posts p ON u.id = p.user_id
WHERE u.username = 'hong';SELECT u
FROM User u
JOIN u.posts p
WHERE u.username = :usernamepublic interface UserRepository extends JpaRepository<User, Long> {
@Query("SELECT u FROM User u JOIN FETCH u.posts p WHERE u.username = :username")
User findUserWithPosts(@Param("username") String username);
}Spring Data JPA 시작하기
Spring Data JPA 소개
Spring Data JPA는 JPA를 쉽게 사용할 수 있도록 스프링에서 제공하는 데이터 접근 추상화 프레임워크이다.
개발자가 인터페이스만 정의하면 런타임에 구현체를 자동 생성하여 반복적인 CRUD 코드를 줄여준다.
메소드 이름 기반 쿼리, @Query 어노테이션, 페이징· 정렬 기능 등 다양한 편의 기능을 지원한다.
- 위치: 애플리케이션의 DAO(Repository) 계층에 위치하여 데이터 접근 로직을 담당한다.
- 역할: JPA를 기반으로 CRUD 구현체를 자동 생성하고, 쿼리 메서드, 페이징, 정렬 등 고수준의 데이터 접근 기능을 제공
JPA와 Spring Data JPA의 관계
JPA: 자바 ORM 기술에 대한 표준 명세이며, 엔티티 매핑, 영속성 컨텍스트, JPQL 등을 정의한다.
Spring Data JPA: JPA 명세를 쉽게 활용할 수 있도록 스프링이 제공하는 추상화 프레임워크. 자동 구현·편의 기능을 제공하는 확장 계층이다.
Spring Data JPA가 제공하는 기능들
| 구분 | 기능 | 설명 |
|---|---|---|
| 기본 CRUD 지원 | JpaRepository 인터페이스 | save, findById, findAll, delete 등 기본적인 CRUD 메서드 자동 제공 |
| 쿼리 메서드 | 메서드 이름 기반 쿼리 생성 | findByUsername, findByEmailAndStatus 등 메서드 네이밍 규칙으로 JPQL 자동 생성 |
| @Query 지원 | 사용자 정의 쿼리 작성 | JPQL 또는 네이티브 SQL을 @Query 어노테이션으로 직접 작성 가능 |
| 페이징 & 정렬 | Pageable, Sort 인터페이스 | findAll(Pageable pageable), findAll(Sort sort) 등 페이징· 정렬 기능 내장 |
| Auditing | 생성· 수정 시간 자동 관리 | @CreatedDate, @LastModifiedDate로 엔티티 변경 이력 자동 기록 |
| 벌크 연산 | @Modifying @Query | UPDATE, DELETE 등 대량 데이터 처리 쿼리 지원 |
| 엔티티 그래프 | @EntityGraph | 연관 엔티티를 JPQL Join 없이 즉시 로딩(Eager fetch) 처리 |
| Projections | DTO 매핑 지원 | 엔티티 전체가 아닌 DTO 인터페이스/클래스로 결과 매핑 가능 |
JPA - 프로젝트 설정
의존성 추가
spring-boot-starter-data-jpa는 JPA와 Hibernate를 쉽게 사용할 수 있게 해주고, postgresql 드라이버는 PostgreSQL DB와 연결할 수 있도록 지원한다.
데이터소스 & JPA 설정
데이터소스 설정은 사용할 데이터베이스 연결 정보(URL, 사용자, 비밀번호, 드라이버 등) 를 지정하는 과정이다.
JPA 설정은 엔티티와 테이블 매핑, SQL 실행 방식, DDL 자동 생성 옵션 등 ORM 동작을 제어하는 환경 구성을 의미한다.
spring:
# DB 접속 정보
datasource:
url: jdbc:postgresql://localhost:5432/spring # PostgreSQL 접속 URL (DB명: spring)
username: user # DB 사용자 계정
password: 1234 # DB 비밀번호
driver-class-name: org.postgresql.Driver # PostgreSQL JDBC 드라이버 클래스
# JPA 설정
jpa:
hibernate:
ddl-auto: validate # 테이블 자동 생성/업데이트 옵션
# create, create-drop, update, validate, none
show-sql: true # 실행되는 SQL 콘솔 출력 여부
properties:
hibernate:
format_sql: true # SQL 문을 보기 좋게 줄바꿈/들여쓰기 출력
highlight_sql: true # 콘솔에 SQL 키워드를 색상 강조 (Hibernate 6.x 지원)
use_sql_comments: true # SQL에 JPQL/HQL 주석 추가 (어떤 쿼리인지 표시)
dialect: org.hibernate.dialect.PostgreSQLDialect # PostgreSQL 전용 Hibernate 방언(Dialect)
physical_naming_strategy: org.hibernate.boot.model.naming.CamelCaseToUnderscoresNamingStrategy # ★ Naming 전략 추가 DB스네이크-Java카멜
jdbc.time_zone: UTC # JDBC 레벨에서 UTC로 통일로깅 설정
JPA 로깅 설정은 Hibernate가 실행하는 SQL 쿼리와 바인딩된 파라미터 값을 로그로 확인할 수 있게 하는 기능이다.
이를 통해 실행된 실제 SQL과 데이터 매핑 과정을 추적하며, 디버깅과 성능 최적화에 활용할 수 있다.
logging:
level:
org.hibernate.SQL: debug # 실행되는 SQL 출력
org.hibernate.orm.jdbc.bind: trace # 바인딩된 파라미터 값 출력
org.hibernate.type.descriptor.sql: trace # (추가) 컬럼 값 변환 로깅Repository 인터페이스 계층 구조
Repository 계층은 Repository → CrudRepository → PagingAndSortingRepository → JpaRepository 순으로 확장된다. Repository는 마커 인터페이스이고, CrudRepository는 기본적인 CRUD 기능을 제공한다.
JpaRepository는 CRUD·페이징·정렬 기능을 모두 포함하면서 JPA에 특화된 추가 기능까지 제공하는 최종 확장 인터페이스이다.
| 인터페이스 | 역할 |
|---|---|
| Repository | 최상위 마커 인터페이스 스프링 데이터 리포지토리 인식 용도 |
| CrudRepository | 기본 CRUD 메서드 제공 (save, findById, delete 등) |
| PagingAndSorting Repository | CRUD+페이징(Pageable), 정렬(Sort) 기능 추가 |
| JpaRepository (사용 권장) | 모든 상위 기능 포함 + JPA 특화 기능 (flush, 배치 처리 등) |
Spring Data JPA가 제공하는 인터페이스들
| 인터페이스 | 상속 관계 | 주요 기능 |
|---|---|---|
| Repository<T, ID> | 최상위 인터페이스 | 마커 인터페이스(기본동작 없음), 스프링 데이터 저장소로 인식시키는 역할 |
| CrudRepository<T, ID> | Repository 상속 | save, findById, findAll, delete 등 기본 CRUD 메서드 제공 |
| PagingAndSortingRepository<T, ID> | CrudRepository 상속 | CRUD+페이징(Pageable), 정렬(Sort) 기능 제공 |
| JpaRepository<T, ID> | PagingAndSortingRepository 상속 | JPA 관련 확장 기능(flush, saveAll, 배치 처리, deleteInBatch 등) 제공 |
| QueryByExampleExecutor | 독립적 사용 가능 | Example 객체 기반 동적 쿼리 지원 (findAll(Example<T>)) |
| JpaSpecificationExecutor | JpaRepository와 조합 | Specification 기반의 동적 쿼리 작성 지원 (Criteria API 활용) |
JPA 자동 구현의 원리
JpaRepository 인터페이스를 정의하면, 프록시(Proxy) 기반 동적 구현 클래스를 런타임에 자동 생성 한다.
메서드 이름 규칙이나 @Query 어노테이션을 해석해 SQL/JPQL을 생성하고 실행한다.
이를 통해 개발자는 구현체 작성 없이 선언형 인터페이스만으로 데이터 접근 계층을 구성할 수 있다.
| 단계 | 동작 원리 | 설명 |
|---|---|---|
| 1 | 프록시 기반 리포지토리 생성 | JpaRepository 인터페이스를 상속하면, Spring Data JPA가 런타임에 프록시 객체를 자동 생성하여 구현체 제공 |
| 2 | 메서드 네이밍 규칙 해석 | findByUsernameAndEmail 같은 메서드명을 분석 적절한 JPQL을 자동 생성 |
| 3 | JPQL → SQL 변환 및 실행 | 생성된 JPQL을 EntityManager가 실제 SQL(PostgreSQL 등)로 변환해 실행 |
| 4 | 결과 매핑 | 실행 결과(ResultSet)를 엔티티 객체(User, Post 등)로 매핑하여 반환 |
