최근 흥미롭게 읽었던 책인 실전 카프카 개발부터 운영까지 - 고승범을 다시 정리해서 기록해두려고 한다.
중요한 이론과 개인적으로 느낀점을 다룰 예정이며, 실습은 기록하지 않는다.
2.3 프로듀서의 기본 동작과 예제 맛보기
2.3.1 프로듀서 디자인
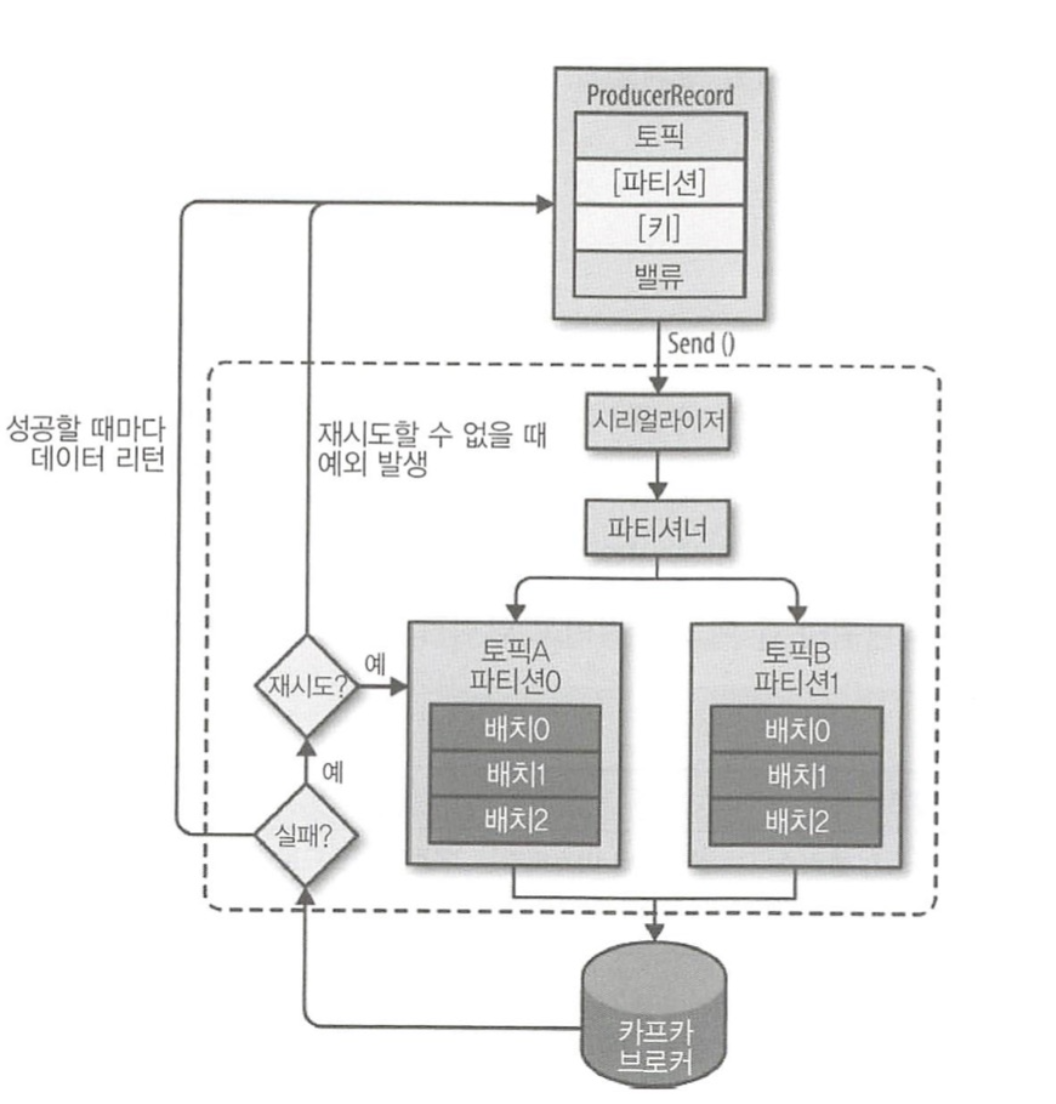
위 그림은 프로듀서의 전체 흐름을 나타낸 그림이다.
ProducerRecord는 카프카로 전송하기 위한 실제 데이터이며, 레코드는 토픽, 파티션, 키, 밸류로 구성된다. 프로듀서가 레코드를 전송할 때, 카프카의 특정 토픽으로 메시지를 전송해야하므로 레코드의 토픽과 밸류(메시지 내용)는 필숫값이다. 특정 파티션을 지정하기 위한 레코드의 파티션, 특정 파티션에 레코드들을 정렬하기 위한 레코드의 키는 선택사항(옵션)이다.
프로듀서의 send() 메소드를 실행하면, 먼저 시리얼라이저를 통해 레코드가 Serialize 된다. 그리고 파티셔너를 거쳐 레코드를 파티션별로 잠시 모아두는 공간으로 가게된다. 만약 프로듀서의 레코드의 선택사항인 파티션을 지정했다면 파티셔너는 아무 역할을 하지 않는다. 파티션을 지정하지 않은 경우에는 키를 가지고 파티션을 선택해 레코드를 전달하는데, 기본적으로 라운드 로빈(round robin) 방식으로 동작한다(파티셔너에 대해선 뒤에서 더 자세히 공부할 것이다). 그리고 파티셔너를 거쳐 파티션별로 잠시 모아두는 이유는, 배치 전송을 하기 위함이다. 전송이 실패하면 재시도 동작이 이뤄지고, 지정된 횟수만큼의 재시도가 실패하면 최종 실패를 전달하며, 전송이 성공하면 메타데이터를 리턴한다.
2.3.2 프로듀서의 주요 옵션
자신이 원하는 형태로 카프카를 이용해 메시지를 전송하려면 프로듀서의 주요 옵션을 잘 파악해야 한다.
| 프로듀서 옵션 | 설명 |
|---|---|
| bootstrap.server | 클라이언트가 카프카 클러스터에 처음 연결하기 위한 호스트&포트 정보 |
| client.dns.lookup | 하나의 호스트에 여러 IP를 매핑해 사용하는 일부 환경에서 클라이언트가 하나의 IP와 연결하지 못할 경우에 다른 IP로 시도하는 설정 |
| acks | 프로듀서가 카프카 토픽의 리더 측에 메시지를 전송한 후 요청을 완료하기를 결정하는 옵션. 0,1,all(-1)로 표현하며, 0은 리더 측에서 메시지를 받았는지 확인하지 않는다. 따라서 전송이 빠르지만, 일부 메시지가 유실될 가능성이 있다. 1은 리더가 메시지를 받았는지 확인하지만, 모든 팔로워 전부를 확인하진 않는다. 대부분 기본값으로 1을 사용한다. all은 팔로워가 메시지를 받았는지 여부를 확인한다. |
| buffer.memory | 카프카 서버로 데이터를 보내기 위해 잠시 대기(배치 전송이나 딜레이 등)할 수 있는 전체 메모리 바이트 |
| compression.type | 프로듀서가 메시지 전송 시 선택할 수 있는 압축 타입. (none, gzip, snappy, lz4, zstd) |
| enable.idempotence | 설정을 true로 하면 중복 없는 전송이 가능함(중복 없는 전송은 max.flight.requests.per.connection은 5이하, retries는 0이상, acks는 all로 설정해야함) |
| max.in.flight.request.per.connection | 하나의 커넥션에서 프로듀서가 최대한 ACK 없이 전송할 수 있는 요청 수. 메시지 순서가 중요하다면 1로 설정할 것을 권장하지만, 성능은 다소 떨어진다. |
| retries | 전송에 실패한 데이터를 다시 보내는 횟수 |
| batch.size | 배치 전송할 배치 크기 |
| linger.ms | 배치 크기에 도달하지 못한 상황에서 linger.ms 제한 시간에 도달했을 때 메시지를 전송한다 |
| transactional.id | '정확히 한번 전송'을 위해 사용하는 옵션이며, 동일한 TransactionalId에 한해 정확히 한 번을 보장한다. 옵션을 사용하기 전 enable.idempotence를 true로 설정해야 함 |
2.4 컨슈머의 기본 동작과 예제 맛보기
컨슈머는 카프카의 토픽에 저장되어 있는 메시지를 가져오는 역할을 담당한다. 컨슈머가 단순하게 카프카로부터 메시지만 가져오는 것 같지만, 내부적으로는 컨슈머 그룹, 리밸런싱 등 여러 동작을 수행한다. 프로듀서가 아무리 빠르게 카프카로 메시지를 전송하더라도 컨슈머가 카프카로부터 빠르게 메시지를 읽어오지 못한다면 결국 지연이 발생한다.
2.4.1 컨슈머의 기본 동작
프로듀서가 카프카의 토픽으로 메시지를 전송하면, 해당 메시지들은 브로커들의 로컬 디스크에 저장된다. 그리고 우리는 컨슈머를 이용해 토픽에 저장된 메시지를 가져올 수 있다. 컨슈머 그룹은 하나 이상의 컨슈머들이 모여 있는 그룹을 의미하고, 컨슈머는 반드시 컨슈머 그룹에 속하게 된다. 그리고 이 컨슈머 그룹은 각 파티션의 리더에게 카프카 토픽에 저장된 메시지를 가져오기 위한 요청을 보낸다. 이때 파티션 수와 컨슈머 수는 일대일로 매핑되는 것이 이상적이다.
2.4.2 컨슈머의 주요 옵션
카프카에는 메시지가 잘 저장되어 있어도 관리자가 컨슈머를 어떻게 처리하고 다루느냐에 따라 컨슈머 동작에서 메시지의 중복, 유실 등 여러 가지 상황이 발생할 수 있다. 컨슈머를 사용하는 목적이 최대한 안정적이며 지연이 없도록 카프카로부터 메시지를 가져오는 것인데, 이를 위한 옵션을 잘 이해하고 사용해야만 원하는 형태로 컨슈머가 동작할 것이다.
| 컨슈머 옵션 | 설명 |
|---|---|
| bootstrap.servers | 브로커의 정보 |
| fetch.min.bytes | 한 번에 가져올 수 있는 최소 데이터 크기. 만약 지정한 크기보다 작은 경우, 요청에 응답하지 않고 데이터가 누적될 때까지 기다린다. |
| group.id | 컨슈머가 속한 컨슈머 그룹을 식별하는 식별자. 동일한 그룹 내의 컨슈머 정보는 모두 공유된다. |
| heartbeat.interval.ms | 하트비트가 있다는 것은 컨슈머의 상태가 active임을 의미. 일반적으로 session.timeout.ms의 1/3로 설정한다. |
| max.partition.fetch.bytes | 파티션당 가져올 수 있는 최대 크기 |
| session.timeout.ms | 이 시간을 이용해, 컨슈머가 종료된 것인지를 파악한다. 컨슈머는 주기적으로 하트비트를 보내야 하고, 만약 이 시간 전까지 하트비트를 보내지 않았다면 해당 컨슈머는 종료된 것으로 간주하고 컨슈머 그룹에서 제외하고 리밸런싱을 시작한다. |
| enable.auto.commit | 백그라운드로 주기적으로 오프셋을 커밋한다. |
| auto.offset.reset | 카프카에서 초기 오프셋이 없거나 현재 오프셋이 더 이상 존재하지 않는 경우에 다음 옵션으로 reset한다. - earliest: 가장 초기의 오프셋값으로 설정 - latest: 가장 마지막의 오프셋값으로 설정. - none: 이전 오프셋값을 찾지 못하면 에러 발생 |
| fetch.max.bytes | 한 번의 가져오기 요청으로 가져올 수 있는 최대 크기 |
| group.instance.id | 컨슈머의 고유한 식별자. 만약 설정한다면 static 멤버로 간주되어, 불필요한 리밸런싱을 하지 않는다 |
| isolation.level | 트랜잭션 컨슈머에서 사용되는 옵션으로, read_uncommitted는 기본값으로 모든 메시지를 읽고, read_committed는 트랜잭션이 완료된 메시지만 읽는다. |
| max.poll.records | 한 번의 poll() 요청으로 가져오는 최대 메시지의 수 |
| partition.assignment.strategy | 파티션 할당 전략이며, 기본값은 range |
| fetch.max.wait.ms | fetch.min.bytes에 의해 설정된 데이터보다 적은 경우 요청에 대한 응답을 기다리는 최대 시간 |
2.4.3 컨슈머 그룹의 이해
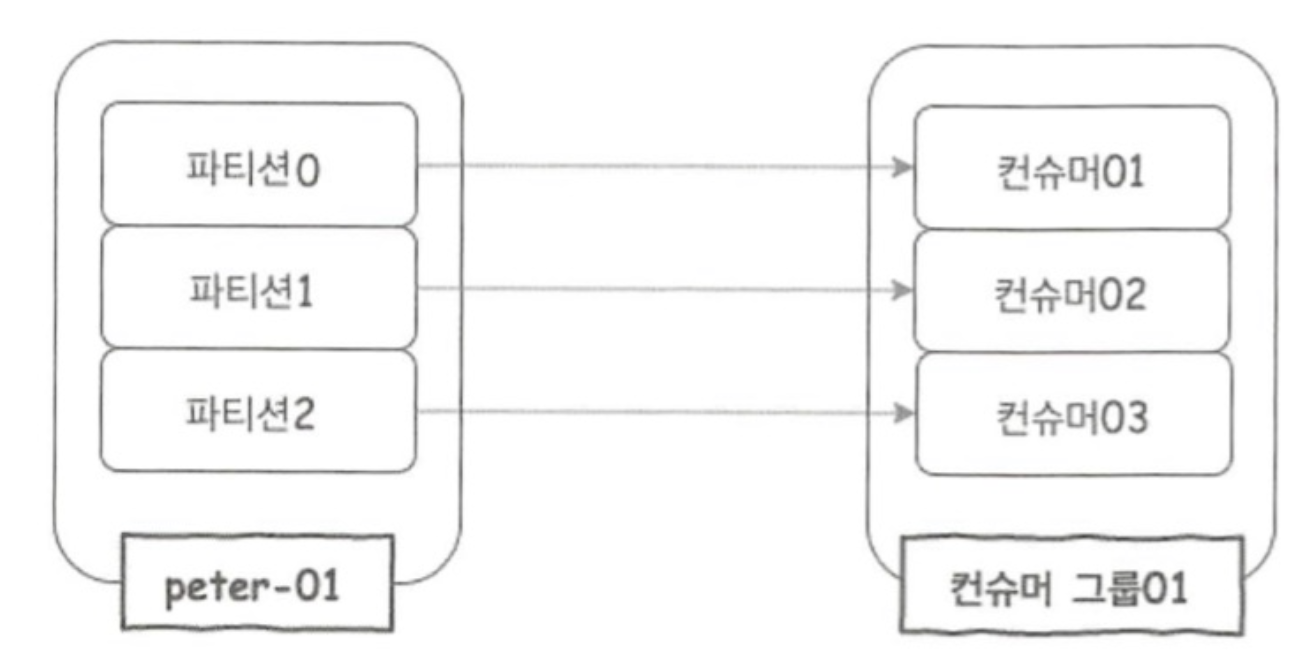
컨슈머는 컨슈머 그룹 안에 속한 것이 일반적인 구조로, 하나의 컨슈머 그룹 안에 여러 개의 컨슈머가 구성될 수 있다. 그리고 컨슈머들은 아래 그림과 같이 토픽의 파티션과 일대일로 매핑되어 메시지를 가져오게 된다.
정리
이번 장에서는 기본적인 용어와 개념들에 대해서 알아보고, 프로듀서와 컨슈머에 대해서도 간단히 알아봤다. 또한 어떤 기능들이 카프카의 성능을 높여줬는지도 알아봤다. 다음 장부터는 조금 더 구체적으로 알아보도록 한다.
