인터넷에 있는 정보를 긁어와 사용할 수있는 jsoup활용!!
일단 maven을 추가합니다(gradle)은 찾아야해요
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.13.1</version>
</dependency> @RequestMapping("/")
@ResponseBody
public String getHtml() {
Document doc;
try {
String url = "https://www.netflix.com/kr/browse/genre/81472392";
doc = Jsoup.connect(url).get();
Elements el = doc.select("section div ul li");
System.out.println(el);
return el.toString();
}catch(IOException e) {
e.printStackTrace();
return "1";
}
}코드는 간단합니다.
1. url에 가져오고 싶은 사이트의 url 입력
2. 해당 url을 Jsoup.connect().get()를 사용해 Document로 받기
3. 지금 doc에는 html이 전부 담겨 있습니다. 여기서 우리가 원하는 정보만을 가져오는 방법은 css에서 선택을 하는 방법과 같습니다.
ex) "section div ul li" section태그 안의 div안의 ul안의 li들의 내용만 선택하라는 뜻입니다.
4. 추출된 내용을 Elements태그에 담습니다.
5. String 타입으로 return을 해서 사용을 해봤습니다.
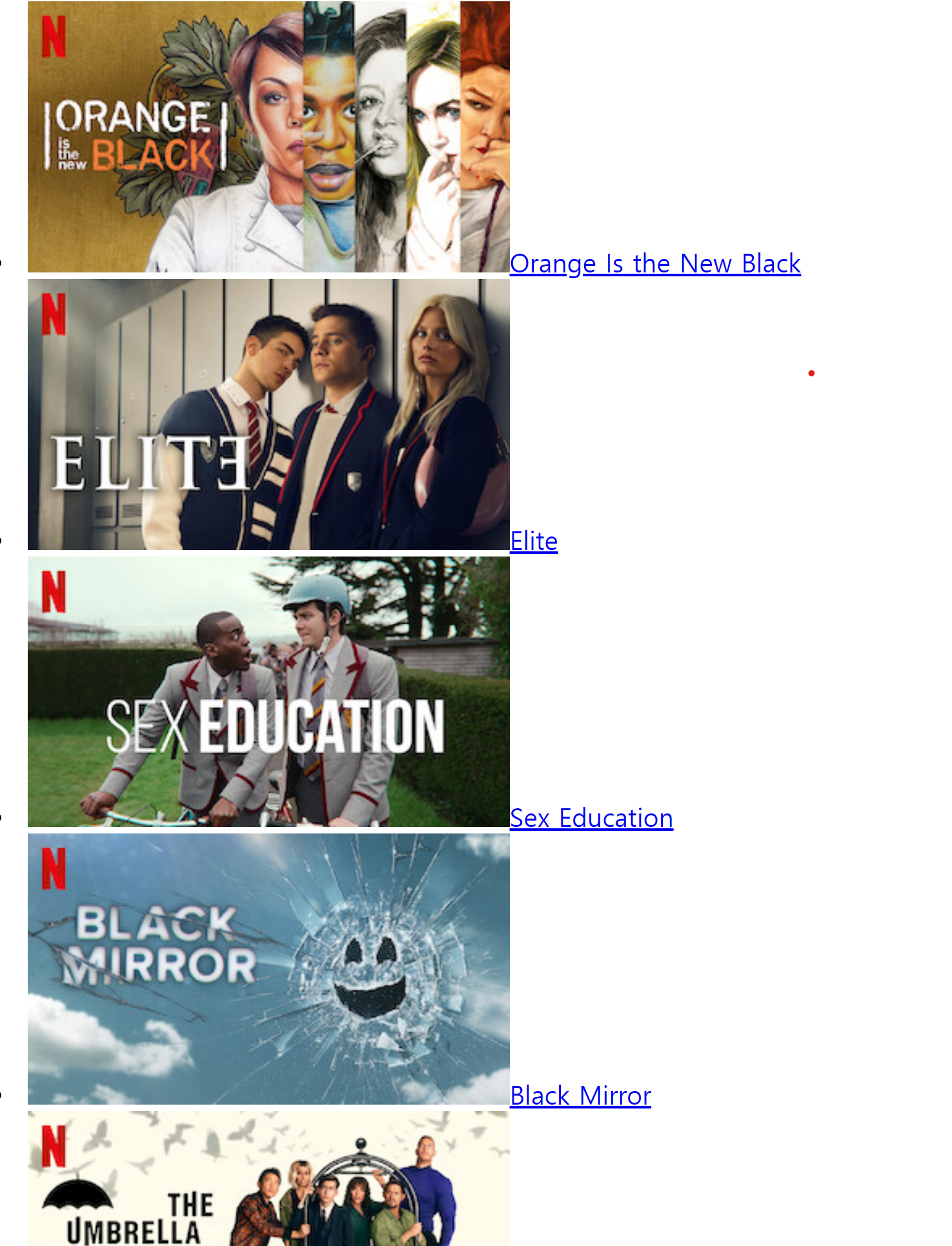
넷플릭스 현재 순위 1~10를 가져왔습니다. img태그도 있었기에 이미지도 나오네요!
2023-01-18
유튜브의 크롤링을 시도했다.
1. 위의 방식으로는 유튜브의 html 생성 방식이 script로 받은 다음 재로딩을 하는 것으로 보이기 때문에 태그 추출이 불가능 하다.
2. 그럼으로 추가된 방법이 필요했다. 코드는 아래와 같다.
package com.youtube.rank;
import java.io.IOException;
import java.util.List;
import org.json.simple.JSONArray;
import org.json.simple.JSONObject;
import org.json.simple.parser.JSONParser;
import org.jsoup.Connection;
import org.jsoup.Jsoup;
import org.jsoup.nodes.DataNode;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import com.jayway.jsonpath.Configuration;
import com.jayway.jsonpath.JsonPath;
@RestController
public class Rank {
@GetMapping("/youtube/{id}")
public String getYoutuber(@PathVariable String id) {
Document doc = null;
String user_agent = "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.133 Safari/537.36";
String url = "https://www.youtube.com/@huehueman";
try {
Connection.Response nvDocument = Jsoup.connect(url).userAgent(user_agent)
.method(Connection.Method.GET)
.execute();
doc = nvDocument.parse();
Elements datas = doc.select("script");
for(Element data : datas) {
for(DataNode node : data.dataNodes()) {
if(node.getWholeData().contains("var ytInitialData = ")) {
String nodeData = node.getWholeData();
nodeData = nodeData.replace("var ytInitialData = ", "");
nodeData = nodeData.replace(nodeData.substring(nodeData.length() -1), "");
//비디오 ID
Object videoId = JsonPath.read(nodeData, "$.contents.twoColumnBrowseResultsRenderer.tabs[*].tabRenderer.content.sectionListRenderer.contents[*]."
+ "itemSectionRenderer.contents[*].channelVideoPlayerRenderer.videoId");
//제목, 작성자, 등록경과일, 영상길이, 조회수
Object titleInfo = JsonPath.read(nodeData, "$.contents.twoColumnBrowseResultsRenderer.tabs[*].tabRenderer.content.sectionListRenderer.contents[*]."
+ "itemSectionRenderer.contents[*].channelVideoPlayerRenderer.title.accessibility.accessibilityData.label");
//최근 동영상 4개 ID
List<String> recentVideoId = JsonPath.read(nodeData, "$.contents.twoColumnBrowseResultsRenderer.tabs[*].tabRenderer.content.sectionListRenderer.contents[*]."
+ "itemSectionRenderer.contents[*].shelfRenderer.content..horizontalListRenderer.items[*].gridVideoRenderer.videoId");
//최근 동영상 4개 제목, 작성자, 등록경과일, 영상길이, 조회수
List<String> recentVideoInfo = JsonPath.read(nodeData, "$.contents.twoColumnBrowseResultsRenderer.tabs[*].tabRenderer.content.sectionListRenderer.contents[*]."
+ "itemSectionRenderer.contents[*].shelfRenderer.content..horizontalListRenderer.items[*].gridVideoRenderer.title.accessibility.accessibilityData.label");
System.out.println("현재 뽑은 내용 : " + videoId);
System.out.println("현재 뽑은 내용 : " + titleInfo);
System.out.println("현재 뽑은 내용 : " + recentVideoId);
System.out.println("현재 뽑은 내용 : " + recentVideoInfo);
}
}
}
return "1";
}catch(Exception e) {
e.printStackTrace();
return "0";
}
}
@RequestMapping("/")
public String test() {
return "<iframe width=\"560\" height=\"315\" src=\"https://www.youtube.com/embed/HbKnQxnmPUQ\"></iframe>";
}
}
- 크롤링 단계에서 user_agent를 추가하여 헤더에 값을 추가하였다.
- <script> 태그에 담긴 값이 날라온다.
- 태그를 지워주고 해당 로그들을 다시 추려내기 작업을 한다.
- 처음에는 simpleJson을 사용하여 태그를 들어갔지만 현실적으로 너무 많은 태그들이 존재함으로
가독성과 실용성이 떨어진다. - 그래서 찾은 라이브러이가 jsonPath다 (https://github.com/json-path/JsonPath)
- 앞으로 url에 해당 유튜버를 입력시 자동으로 해당 유튜버의 아이디로 변환 후 필요 정보들을 출력하는 api를 구현 할 것이다.

꾸준히 배우자(다른 사람 글 복붙 할 바에 링크를 걸어라)