인덱스는 데이터를 빠르게 찾기위해 목차를 만들어 놓은 것이다.
b-트리 인덱스
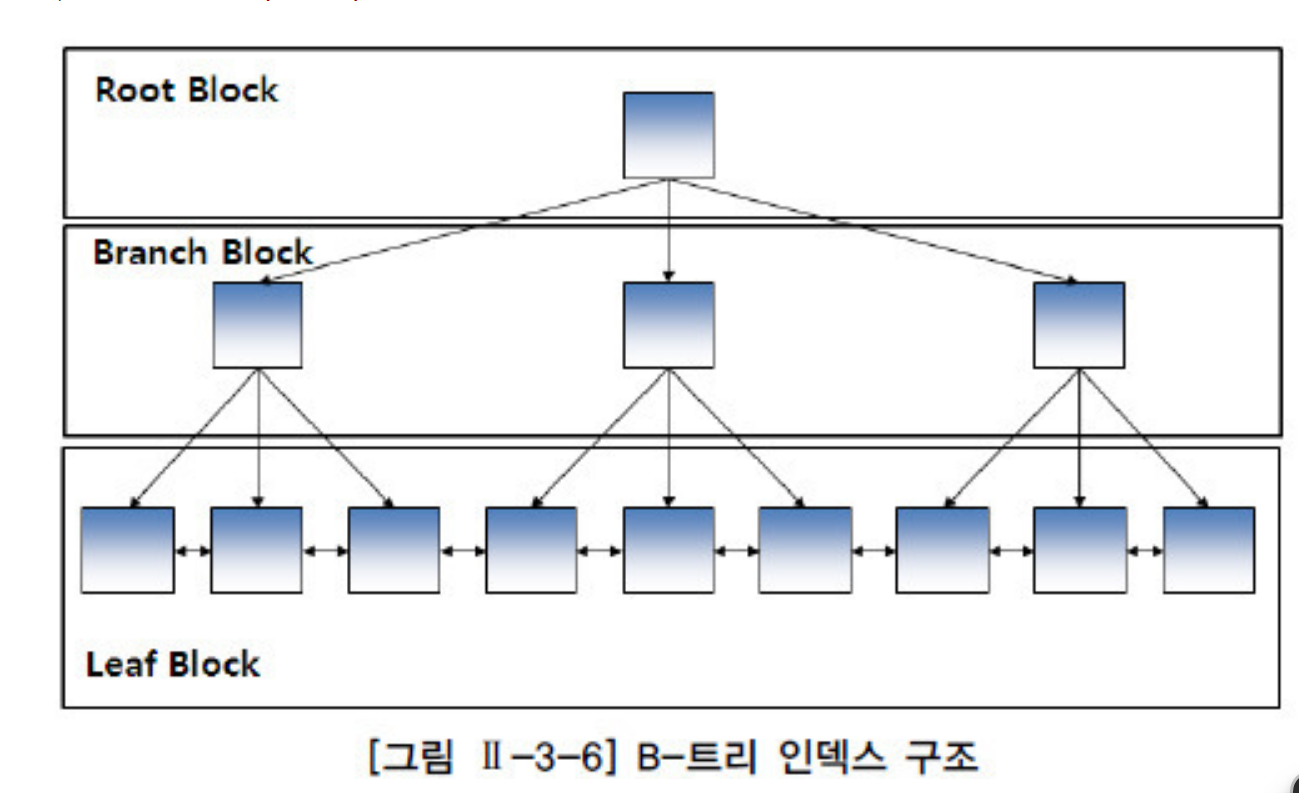
3단계로 나뉘어진 그림이다.
이런 그림으로 인덱스가 세분화 될 수 있다고 이해하고 아래그림을 보자
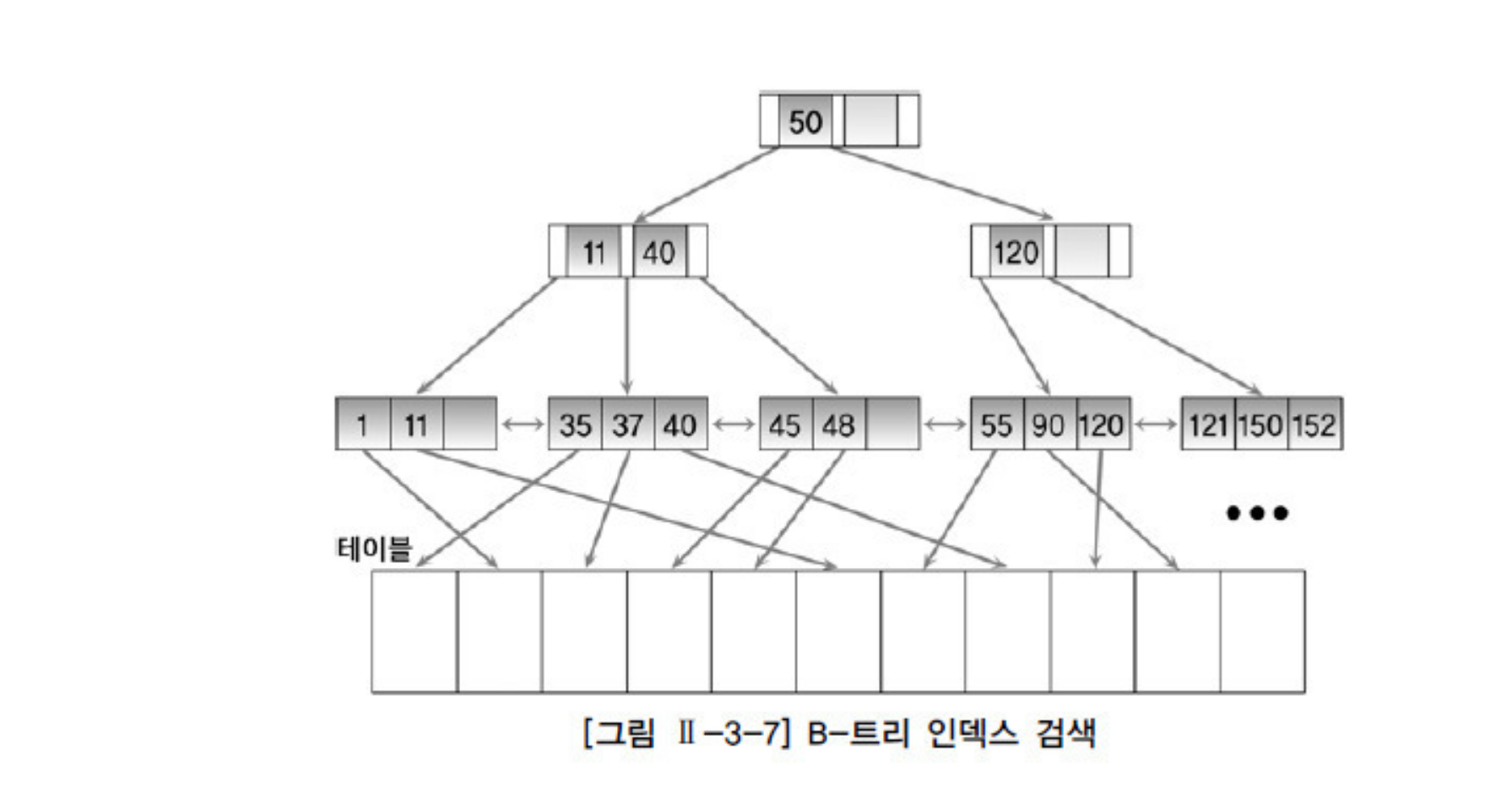
인덱스가 숫자로 저장된 경우를 예시로 들어보면
Root Block에 50이 적혀있다. 이렇게 적혀 있을 경우 50 이하의 숫자를 찾는다면 Brach Block의 왼쪽으로 갈 것이고 이상이면 오른쪽으로 타고 내려갈 것이다.
Branch Block에 내려 왔다면 11과 40이 있는데 이번에는 3방향으로 쪼개져 있다. 조건이 11과 40 사이면 가운대로 갈 것이고 아니면 좌 우로 나뉘어 질 것이다.
그런데 만약 30~50 이런 범위를 찾는다면 30을 기준으로 타고 내려가서 Leaf Block에서 1씩 증가하며 데이터를 찾을 것이다.
*insert, Update, Delete같은 DML작업은 테이블과 인덱스 함께 변셩해야 하기 때문에 index를 사용하면 오히려 느려 질 수 있다.
Clustered 인덱스 / non-Clustered 인덱스
Clustered란 정렬이라고 생각하면 편하다.
1,2,3,4,5
a,b,c,d,e 처럼 데이터에 순서로 구분할 수 있게 정렬을 시키는 것이다.
장: select가 빠르다(범위검색 강함)
단: insert가 힘들다 (예를 들어 데이터 중간에 새로운 데이터를 넣게되면 밀리는 친구들의 index가 전부 변경되야 한다.)
non-Clustered
순서에 상관 없이 fk 처럼, 가벼운 테이블을 하나 따로 만든다고 생각하는것이 편할 듯 싶다.
장: 데이터의 추가 편집이 편하다
단: 공간을 더 필요로 한다
sql에서 인덱스
pk는 자동으로 인덱스가 생성된다.
unique도 인덱스가 생성된다.
-인덱스를 추가 할 때는 카디널리티(희소성)이 높은 것을 선택하는 것이 좋다.
-자주 사용하는 컬럼을 인덱스로 등록해야 한다.
