1. Spring WebMvc: 검증된 안정성, 직관적인 동기 처리
Spring WebMvc는 Servlet API 기반의 동기(Synchronous), 블로킹(Blocking) I/O 모델을 사용함. Spring 프레임워크의 시작과 함께한, 가장 전통적이고 널리 사용되는 스택임.
핵심 동작 원리: 요청 당 스레드 (Thread-per-Request)
- 서블릿 컨테이너(ex. Tomcat)의 스레드 풀: 클라이언트 요청이 들어올 때마다, 스레드 풀에서 가용한 스레드를 하나씩 할당함.
- 순차적 블로킹 처리: 할당된 스레드는 요청의 시작부터 끝까지 모든 로직을 책임짐. 만약 DB 조회나 외부 API 호출과 같은 I/O 작업이 발생하면, 해당 스레드는 결과가 올 때까지 대기(Block) 상태에 들어감.
- 자원 소모: 동시 사용자가 늘어나면, 그 수에 비례하여 스레드 수도 증가해야 함. 이는 메모리 사용량 증가와 잦은 컨텍스트 스위칭(Context Switching) 비용을 유발하여, 고도의 동시성 환경에서는 성능 저하의 원인이 될 수 있음.
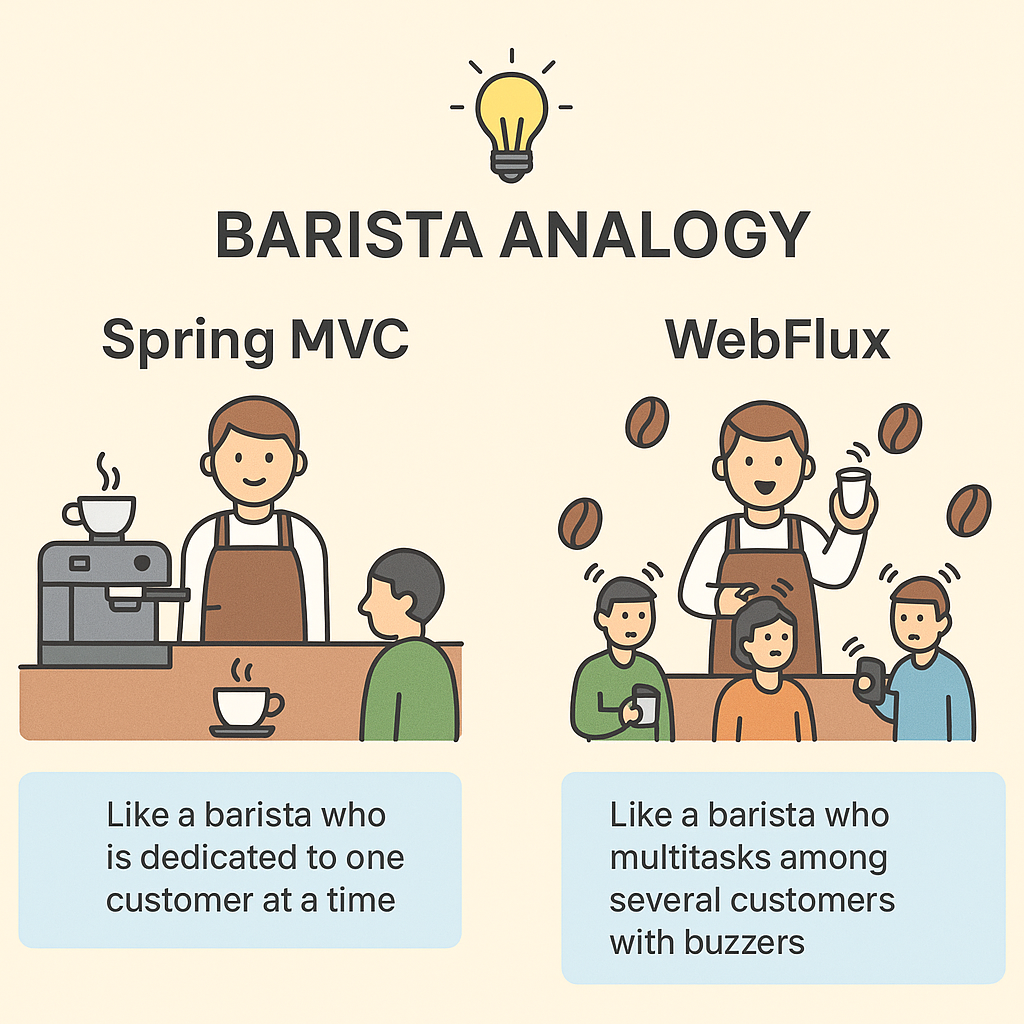
💡 비유: 전담 바리스타
WebMvc는손님 한 명을 끝까지 책임지는 바리스타와 같음.
바리스타(스레드)는 손님(요청)의 주문을 받고, 커피 원두를 갈고, 에스프레소를 내리는 모든 과정이 끝날 때까지 그 손님 옆에서 기다림. 다른 손님이 와도, 지금 손님의 커피가 완성되기 전까지는 응대할 수 없음. 손님이 많아지면 바리스타를 더 많이 고용해야 함.
언제 선택할까?
- 대부분의 로직이 CPU 연산 위주(CPU-Bound)인 애플리케이션.
- JPA, JDBC와 같이 블로킹 방식의 라이브러리 사용이 필수적일 때.
- 반응형 프로그래밍에 익숙하지 않은 팀이 개발 생산성을 높여야 할 때.
- 복잡한 비즈니스 로직을 순차적으로 명확하게 표현하고 싶을 때.
2. Spring WebFlux: 높은 동시성, 효율적인 비동기 처리
Spring 5부터 등장한 WebFlux는 비동기(Asynchronous), 논블로킹(Non-Blocking) I/O 모델을 기반으로 하는 반응형(Reactive) 웹 스택임. 적은 리소스로 높은 처리량을 목표로 함.
핵심 동작 원리: 이벤트 루프 (Event Loop)
- 최소한의 스레드: 기본적으로 CPU 코어 수만큼의 적은 스레드로 모든 요청을 처리함. (기본 서버는 Netty)
- 논블로킹 처리와 콜백: 요청이 들어오면 이벤트 루프가 이를 받아 작업을 시작함. 만약 I/O 작업이 발생하면, 스레드는 결과를 기다리지 않고 해당 작업을 별도의 컴포넌트(OS 커널, 워커 스레드)에 위임하고 즉시 다른 요청을 처리하러 감. I/O 작업이 완료되면, 이벤트/콜백(Callback)이 발생하여 이벤트 루프에게 알려주고, 남은 로직을 마저 처리함.
- 자원 효율성: 스레드가 대기 상태에 빠지지 않고 계속 일하기 때문에, 적은 수의 스레드로 수많은 동시 요청을 효율적으로 처리할 수 있음. I/O 바운드(I/O-Bound) 작업이 많은 시스템에서 탁월한 성능을 보임.
💡 비유: 효율적인 멀티태스킹 바리스타
WebFlux는진동벨을 활용하는 바리스타와 같음.
바리스타(스레드)는 손님(요청)의 주문을 받고, 진동벨(Mono/Flux)을 나눠준 뒤 바로 다음 손님의 주문을 받음. 커피 제작은 머신에 맡기고, 자신은 계속해서 주문을 처리함. 커피가 완성되면 진동벨이 울리고(이벤트), 손님은 커피를 받아감. 한 명의 바리스타가 동시에 여러 손님을 효율적으로 관리할 수 있음.
언제 선택할까?
- 마이크로서비스 아키텍처에서 다른 서비스와의 통신이 잦은 경우.
- 실시간 데이터 스트리밍(SSE), 채팅, 알림 등 대용량 트래픽을 처리해야 할 때.
- R2DBC, WebClient 등 논블로킹 I/O를 지원하는 인프라를 적극적으로 사용할 수 있을 때.
- 최소한의 하드웨어 리소스로 최대의 성능 효율을 뽑아내야 하는 경우.
3. 코드로 보는 차이점
간단한 사용자 조회 API를 통해 두 스택의 코드 스타일 차이를 확인해보자.
공통 User DTO
// Lombok 어노테이션을 사용해 코드 간소화
@Data
@NoArgsConstructor
@AllArgsConstructor
public class User {
private String id;
private String name;
}WebMvc 컨트롤러: 직관적인 순차 실행
반환 타입은 User와 같은 일반 객체. 코드가 위에서 아래로 순차적으로 실행됨.
userService.findById는 결과를 받을 때까지 현재 스레드를 블로킹함.
@RestController
@RequestMapping("/mvc/users")
@RequiredArgsConstructor // final 필드에 대한 생성자 자동 주입
public class UserMvcController {
private final BlockingUserService userService;
@GetMapping("/{id}")
public User getUserById(@PathVariable String id) {
// 이 메서드는 User 객체를 반환할 때까지 스레드를 점유함.
return userService.findById(id);
}
}WebFlux 컨트롤러: 비동기 데이터 파이프라인
반환 타입은 Mono<User>(0-1개 데이터) 또는 Flux<User>(0-N개 데이터) 같은 Reactive Type. 데이터의 흐름을 정의하는 파이프라인을 구축함.
@RestController
@RequestMapping("/webflux/users")
@RequiredArgsConstructor
public class UserWebFluxController {
private final ReactiveUserService userService;
@GetMapping("/{id}")
public Mono<User> getUserById(@PathVariable String id) {
// 이 메서드는 즉시 Mono<User> 객체를 반환하고 스레드를 놓아줌.
// 실제 데이터는 비동기적으로 처리되어 파이프라인을 따라 흐름.
return userService.findById(id)
.doOnSuccess(user -> log.info("User found: {}", user.getName())); // 작업 완료 시 로그 출력 (논블로킹)
}
}WebFlux에서는 .map(), .filter(), .doOnSuccess() 같은 연산자를 체이닝하여 데이터 처리 과정을 선언적으로 정의함. 스레드는 이 선언을 등록하고 즉시 다른 일을 하러 간다는 점이 핵심.
4. 최종 결정 가이드: 핵심 질문들
어떤 스택을 선택할지 고민될 때, 스스로에게 다음 질문을 던져보자.
- 나의 주된 작업은 I/O 바운드인가, CPU 바운드인가?
- I/O 바운드 (DB, API 호출 많음) → WebFlux 고려
- CPU 바운드 (복잡한 연산, 데이터 처리) → WebMvc로도 충분
- 내가 사용하는 라이브러리(DB Driver, 등)는 논블로킹을 지원하는가?
- 하나라도 블로킹 라이브러리가 섞여 있다면 WebFlux의 장점이 희석됨.
BlockHound같은 라이브러리로 블로킹 호출을 탐지할 수 있음.
- 하나라도 블로킹 라이브러리가 섞여 있다면 WebFlux의 장점이 희석됨.
- 우리 팀은 반응형 프로그래밍에 익숙한가?
- 학습 곡선과 디버깅의 어려움(stack trace가 복잡해짐)은 분명한 단점. 생산성과 유지보수 비용을 고려해야 함.
- Kotlin을 사용하고 있는가?
- Kotlin Coroutines를 사용하면 WebFlux 위에서 비동기 코드를 동기 코드처럼 간결하게 작성할 수 있어, WebFlux의 단점인 복잡성을 크게 완화할 수 있음.
