
개요 : em.find() vs JPQL 조회
-
em.find(Member.class , memberId) : JPA가 뭘 어떤 방식으로 조회해야되는지를 알고 있음
-
JPQL 조회 쿼리(select m from Member m) : JPQL 작성 시 JPA는 오직 SQL로 번역해주는 역할만을 하므로 처음 jpql만 보고는 JPA가 뭘 어떤 방식으로 조회해야되는지를 모름
-
즉 즉시 로딩일 경우 em.find()는 한 쿼리로 JPA가 내부적으로 조인 질의를 작성하여 한꺼번에 가져오고 JPQL 조회 쿼리는 우선 JPQL로 조회하려는 엔티티 조회 후 그 뒤에 JPA가 FetchType을 확인해서 즉시 로딩일 경우 한번 더 조회 sql을 날리는 것임
-
반면 지연 로딩일 경우는 둘 다 똑같겠지 지연 로딩은 호출되는 시점에 로딩이므로 JPA가 알든 모르든 똑같이 조회하려는 엔티티가 Member이면 Member만 조회하겠지
개념
-
JPQL에서 성능 최적화를 위해 제공하는 기능 , SQL과는 관련 없음
-
특정 엔티티를 조회할 때 연관된 엔티티의 정보도 같이 조회하고싶은 경우 사용
➤ 예를 들어 회원과 팀이 엔티티가 서로 연관관계에 있을 때 회원 조회 시 회원이 속한 팀에 대한 정보를 조회하고싶은 경우 사용 -
지연 로딩이든 즉시 로딩이든 전부 무시되고 페치 조인 시 한 쿼리로 연관관계에 있는 엔티티 한꺼번에 조회 가능함에 따라 대부분의 N + 1문제 해결
-
말만 봤을 땐 이해가 역시나 되기 어렵다 예시를 함께 봐보자
예제 코드
엔티티(회원 , 팀)
//회원 엔티티
@Entity
@Getter @Setter
public class Member {
@Id @GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "member_id")
private Long id;
private String name;
private int age;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "team_id")
private Team team;
public void addTeam(Team team){
this.team = team;
team.getMembers().add(this);
}
}
//팀 엔티티
@Entity
@Getter @Setter
public class Team {
@Id @GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "team_id")
private Long id;
private String name;
@OneToMany(fetch = FetchType.LAZY , mappedBy = "team")
private List<Member> members = new ArrayList<>();
}리포지토리(회원 , 팀)
//회원 리포지토리
@Repository
@RequiredArgsConstructor
@Transactional
public class MemberRepository{
private final EntityManager em;
public void save(Member member){
em.persist(member);
}
public List<Member> findAllWithTeam(){
return em.createQuery("select m from Member m join fetch m.team" , Member.class).getResultList();
}
}
//팀 리포지토리
@Repository
@RequiredArgsConstructor
@Transactional
public class TeamRepository{
private final EntityManager em;
public void save(Team team){
em.persist(team);
}
}
테스트
//테스트
@SpringBootTest
public class FetchTest {
@Autowired MemberRepository memberRepository;
@Autowired TeamRepository teamRepository;
@Test
@DisplayName("fetch join 테스트")
void fetchTest(){
Team team1 = new Team();
team1.setName("SSG 랜더스");
teamRepository.save(team1);
Team team2 = new Team();
team2.setName("LG 트윈스");
teamRepository.save(team2);
Member member1 = new Member();
member1.setName("김광현");
member1.setAge(30);
member1.addTeam(team1);
memberRepository.save(member1);
Member member2 = new Member();
member2.setName("박성빈");
member2.setAge(35);
member2.addTeam(team1);
memberRepository.save(member2);
Member member3 = new Member();
member3.setName("성동현");
member3.setAge(40);
member3.addTeam(team2);
memberRepository.save(member3);
List<Member> findMembers = memberRepository.findAllWithTeam();
for (Member member : findMembers) {
System.out.println("[회원 : "+member.getName() + " | 회원이 속한 팀 : "+member.getTeam().getName()+"]");
}
}
}
결과
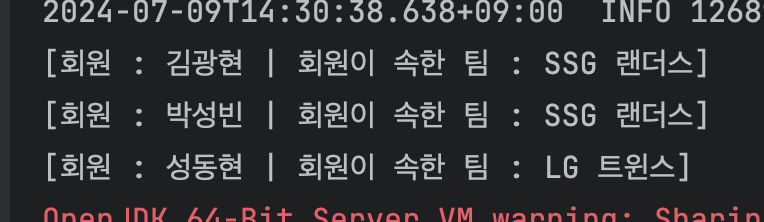
-
스프링 부트 및 순수 JPA를 사용했다
-
코드가 복잡해보일 수 있지만 간단하게 팀 리포지토리에 저장 기능만 구현하였고, 회원 리포지토리에 저장 및 팀 정보와 함께 회원들을 조회하는 로직을 구현하였다.
-
회원과 팀은 서로 양방향 연관관계로 걸려있어서 연관관계 설정은
Member엔티티의addTeam()메서드로 하였다 -
핵심은
findAllWithTeam()이다. 해당 메서드를 통해 페치 조인을 테스트 할 수 있었다. 위의 결과와 같이 각 회원이 속한 팀의 정보를 페치 조인을 통해 알 수 있었다.
Trouble Shooting : JPQL N + 1
※ JPQL N + 1 문제란?
-
하나 조회했는데 N개만큼 더 조회되는 문제
-
예를 들어 1개의 쿼리를 날렸는데 해당 엔티티의 연관관계가 10개면 10개만큼 더 쿼리가 나가는 것
-
즉 하나 조회하면 1 + 10개가 조회되게 됨
지연로딩 , 즉시 로딩에서의 N + 1 문제
-
즉시 로딩 : 즉시 N개의 연관관계 조회 쿼리 생성
-
지연 로딩 : 나중에 호출 시점에 N개의 연관관계 조회 쿼리 생성
-
즉 지연 로딩이든 즉시 로딩이든 시점에 차이만 있을 뿐이지 결국엔 N+1문제를 피할 수 없음
N + 1문제 해결책 : 페치 조인
-
한 쿼리로 특정 엔티티 및 연관관계 엔티티까지 한번에 조인해서 로딩됨에 따라 N개의 추가 쿼리가 발생하지 않게 됨
-
대부분의 N+1 문제 페치 조인으로 해결
실무
- 전부 지연 로딩으로 설정 후 필요한 연관관계 페치 조인 쓰자

※ 객체 그래프 탐색 기본 원칙
-
회원 => 주문 => 상품(member.getOrder().getItem()) 이런 식으로 특정 객체에서 연관관계에 있는 객체들을 자유롭게 탐색하는 것을 뜻함
-
기본적으로 객체 그래프 탐색 시 각 객체에 대한 모든 데이터를 조회할 수 있어야됨
-
특정 데이터만을 조회하면 그 뒤의 다른 명령을 내릴 때 데이터 정합성 문제가 발생하므로
1. 페치 조인 시 연관관계에 대한 별칭(alias) 지정 불가능
-
원칙적으로 스펙 상으로도 페치 조인 시 연관관계 엔티티에 대한 별칭을 주면 안 됨
-
별칭 줌으로써 조회하려는 엔티티에 대한 조건을 걸 수 있게 되므로 데이터의 일부분만을 추출해올 수가 있게 됨
➤ 예를 들어m.team t라고 별칭을 줘버리면where t.name like "SSG%"와 같이 데이터를 필터링해서 갖고오게 됨 -
이렇게 하지만 객체 그래프 탐색 시 데이터의 일부분을 추출해서 가져오게 되면 데이터 정합성의 문제가 발생
➤ 예를 들어 회원에 3개의 데이터가 담겼는데select m from Member m join fetch m.team t t.name="SSG 랜더스"로 페치 조인하면 Member에 대한 Team 데이터는 1개만 나오게 되며 cascade 옵션이나 orphanRemoval 걸려있으면 데이터 꼬임
➤ 또한 영속성 컨텍스트에서도 어떤 엔티티는 데이터 100개 중 50개만 들고오고 어떤 엔티티는 데이터 100개 중 30개만 들고오고 이러면 어떻게 해당 엔티티를 관리해야될지 애매해짐 -
즉 페치 조인은 기본적으로 연관된 엔티티에 대한 내용을 “전부” 긁어오는 것임 , 중간에 몇 개의 데이터를 필터링해서 가져오고싶으면 페치 조인을 쓰면 안 됨
-
A => B => C로 탐색할 때 B에서 어쩔 수 없이 alias를 쓰는 경우 외엔 쓰면 안 됨
2. 둘 이상의 컬렉션은 페치 조인 할 수 없음
-
한 컬렉션만 조인해도 데이터의 중복이 발생해서 JPA가 내부적으로 DISTINCT를 걸어주는데, 둘 이상의 컬렉션을 조인하면 예상할 수 없을 정도로 많아짐
-
일대다 페치 조인 시 연관관계에 대한 컬렉션은 오직 하나만 지정!
-
select t from Team t join fetch t.member이렇게 컬렉션 하나만 지정 하자
3. 컬렉션 페치 조인 시 페이징을 절대 하면 안 된다.
-
다대일 페치 조인 :
select m from Member m join fetch m.team; -
일대다 페치 조인 :
select t from Team t join fetch t.members; -
이와 같이 일대다 페치 조인은 한 Team에 대해 여러 회원들의 데이터가 나오게 되므로 데이터베이스 입장에선 당연하지만, 자바 입장에선 데이터의 중복이 발생함에 따라 Hibernate 6.0부턴 자동으로 DISTINCT 옵션을 컬렉션 페치 조인 시 자동으로 제공함
-
하지만 JPA에서는 중복을 제거해서 조회하지만 데이터베이스에선 제거해선 안 됨 , 참조 무결성에 어긋나므로
-
즉 JPA는 페이징을 통해 DB에서 데이터를 절삭시켜버리면 데이터가 절삭됐는지 알 길이 없음 , 그냥 DB에서 내려준 데이터를 반환할 뿐임(페이징으로 인해 절삭한 데이터를 그저 조회할 뿐)
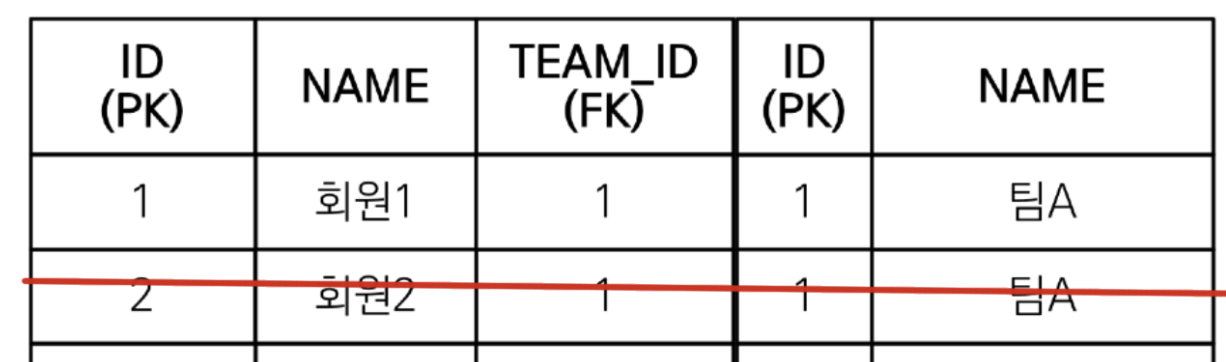
-
즉 실제로 저장된 회원2 데이터가 사라진 채 조회될 수 있음
추가 : N + 1 문제 해결
-
페치 조인
-
@EntityGraph
-
BATCH 사이즈 : n + 1 이 아닌 1 + 1
- 2 , 3번은 다음에 다뤄보도록 한다.
