
안녕하세요 머랭입니다.
최근, Spring Framework에 제출한 PR이 머지되었습니다.
CGLIB 프록시를 생성할 때 불필요하게 반복되던 연산을 개선한 과정을 정리해보려 합니다.
배경
스프링 환경에서 디버깅을 하다 보면 MyService$$SpringCGLIB$$0 처럼 길고 복잡한 클래스명을 접하게 됩니다.
Spring은 인터페이스가 없는 클래스에 프록시를 적용할 때 기본적으로 CGLIB 기반 프록시를 사용하는데, 이때 원본 클래스를 상속받아 런타임에 동적으로 프록시를 생성합니다.
이때 생겨나는 프록시 클래스가 MyService$$SpringCGLIB$$0 같은 클래스입니다.
최근, "저 긴 이름은 내부적으로 어떤 과정을 거쳐서 조합되는 걸까?" 하는 호기심이 생겼습니다.
프록시 이름 규칙을 조사하던 중, ClassNameReader라는 유틸 클래스가 눈에 들어왔습니다.
문제
ClassNameReader는 바이트코드(byte[])를 읽어 Full-Qualified-Class-Name(FQCN, 예: "com.example.MyService")을 추출하는 역할을 합니다.
제 눈길을 끈 건 getClassName(r) 메서드였습니다.
public static String getClassName(ClassReader r) {
return getClassInfo(r)[0];
}코드를 보면 getClassInfo(r)가 반환하는 배열의 첫 번째 원소만 꺼내서 반환합니다.
그런데, 이 getClassInfo(r)의 내부 구현이 생각보다 무거웠습니다.
public static String[] getClassInfo(ClassReader r) {
final List<String> array = new ArrayList<>();
try {
r.accept(new ClassVisitor(Constants.ASM_API, null) {
@Override
public void visit(int version, int access, String name,
String signature, String superName, String[] interfaces) {
array.add(name.replace('/', '.'));
if (superName != null) {
array.add(superName.replace('/', '.'));
}
for (String element : interfaces) {
array.add(element.replace('/', '.'));
}
throw EARLY_EXIT;
}
}, ClassReader.SKIP_DEBUG | ClassReader.SKIP_FRAMES);
} catch (EarlyExitException e) { }
return array.toArray(new String[0]);
}이 메서드는 내부적으로 다음 작업들을 수행합니다.
- ArrayList와 익명 ClassVisitor 객체를 새로 할당합니다.
- ASM의 비지터 패턴을 이용해 클래스 헤더를 순회합니다.
- ASM의 ClassVisitor가 헤더를 순회할 때 대상 클래스의 이름뿐만 아니라, 부모 클래스와 구현한 모든 인터페이스 이름까지 전부 UTF-8로 디코딩하고 replace('/', '.') 연산을 거쳐 리스트에 담습니다.
- 헤더에 있는 정보(자신의 이름, 부모, 인터페이스)를 모두 리스트에 담고 나면, 필드나 메서드 등 클래스의 나머지 부분까지 불필요하게 파싱하는 것을 막기 위해 미리 만들어 둔 예외(EARLY_EXIT)를 던져 중단합니다.
- 이 예외를 catch 블록으로 잡아낸 뒤, 담겨있던 리스트를 toArray로 변환해 배열로 반환합니다.
💡 ASM이란?
ASM은 자바 바이트코드를 조작하고 분석하기 위한 범용 프레임워크로,.class파일의 바이트를 직접 읽고 쓸 수 있게 해줍니다.
크기가 매우 작고 속도가 빨라서 Spring, CGLIB, Hibernate 같은 프레임워크들이 런타임에 동적으로 클래스(프록시)를 만들어낼 때 사용하는 핵심 기술입니다.Spring은 이를 org.springframework.asm 패키지로 자체 내장하여 사용하고 있습니다.
문제는 getClassName(r)이 배열의 첫 번째 원소만 사용한다는 점입니다.
부모 클래스나 인터페이스 이름들을 디코딩하고 문자열을 치환해 리스트에 담는 연산들이, 정작 호출한 곳에서는 사용되지 않고 있었습니다.
해결
ASM의 ClassReader는 객체가 생성될 때 클래스 파일을 한 번 스캔하여 클래스 파일 내 상수 풀의 모든 항목 위치를 인덱싱해 메모리에 저장합니다.
ASM은 이 인덱스를 활용하는 getClassName()이라는 public 메서드를 제공하고 있었습니다.
이 메서드를 사용하면 Visitor로 클래스 헤더를 순회하지 않아도 클래스 이름을 얻을 수 있습니다.
// 변경 전
public static String getClassName(ClassReader r) {
return getClassInfo(r)[0];
}
// 변경 후
public static String getClassName(ClassReader r) {
return r.getClassName().replace('/', '.');
}ASM이 이미 만들어 둔 인덱스를 사용해 클래스 이름만 읽어오도록 변경했고, 다음 이점을 얻을 수 있었습니다.
- 객체 할당 횟수가 약 7회에서 2회로 줄었습니다.
- 부모 클래스와 인터페이스 이름들에 대한 불필요한 UTF-8 디코딩 연산이 제거되었습니다.
- Visitor 객체를 생성하고, 예외를 던져 흐름을 제어하는 오버헤드가 사라졌습니다.
벤치마킹을 통한 증명
"불필요한 연산을 줄였다"는 정성적 설명만으로는 메인테이너를 설득하기 부족하다고 판단했습니다.
실제로 성능이 얼마나 개선되었는지 객관적인 수치로 증명하기 위해 JMH를 사용해 벤치마크 환경을 구축했습니다.
벤치마크를 설계할 때 가장 고민했던 부분은 데이터 구축이었습니다. 제가 변경한 메서드는 실제 CGLIB가 프록시 바이트코드를 읽을 때 호출되므로, 임의로 만든 가짜 바이트 배열을 넣으면 측정 결과의 신뢰도가 떨어진다고 판단했습니다.
그래서 CGLIB의 Enhancer를 사용해 프록시 클래스를 생성하되, 바이트코드 생성 전략(GeneratorStrategy)을 조작해 생성된 byte[]를 직접 캡쳐하는 방식을 사용했습니다.
측정 환경
JMH AverageTime 모드, 5 forks × (warmup 5회 × measurement 5회), -prof gc 옵션으로 메모리 할당량까지 측정했습니다.
인터페이스를 구현하지 않은 경우 / 인터페이스를 3개 구현한 경우를 나누어 측정했습니다.
public class ClassNameReaderBenchmark {
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.NANOSECONDS)
@Warmup(iterations = 5, time = 2)
@Measurement(iterations = 5, time = 2)
public static class WithoutInterfaces {
@State(Scope.Benchmark)
public static class BenchmarkState {
public ClassReader classReader;
@Setup(Level.Trial)
public void setup() {
this.classReader = generateProxyReader(new Class<?>[0]);
}
}
@Benchmark
public String viaGetClassInfo(BenchmarkState state) {
return ClassNameReader.getClassInfo(state.classReader)[0];
}
@Benchmark
public String viaGetClassName(BenchmarkState state) {
return state.classReader.getClassName().replace('/', '.');
}
}
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.NANOSECONDS)
@Warmup(iterations = 5, time = 2)
@Measurement(iterations = 5, time = 2)
public static class WithInterfaces {
@State(Scope.Benchmark)
public static class BenchmarkState {
public ClassReader classReader;
@Setup(Level.Trial)
public void setup() {
this.classReader = generateProxyReader(
new Class<?>[]{Cloneable.class, Comparable.class, Runnable.class}
);
}
}
@Benchmark
public String viaGetClassInfo(BenchmarkState state) {
return ClassNameReader.getClassInfo(state.classReader)[0];
}
@Benchmark
public String viaGetClassName(BenchmarkState state) {
return state.classReader.getClassName().replace('/', '.');
}
}
private static ClassReader generateProxyReader(Class<?>[] interfaces) {
CapturingGeneratorStrategy strategy = new CapturingGeneratorStrategy();
Enhancer enhancer = new Enhancer();
enhancer.setSuperclass(ProxyTarget.class);
enhancer.setCallbackType(MethodInterceptor.class);
enhancer.setUseCache(false);
enhancer.setInterfaces(interfaces);
enhancer.setStrategy(strategy);
enhancer.createClass();
return strategy.createClassReader();
}
public static class ProxyTarget { }
// 커스텀 GeneratorStrategy를 사용해, CGLIB를 통해 생성된 클래스의 바이트코드를 캡쳐합니다.
private static class CapturingGeneratorStrategy implements GeneratorStrategy {
private static final GeneratorStrategy delegate = DefaultGeneratorStrategy.INSTANCE;
private byte[] captured;
@Override
public byte[] generate(ClassGenerator cg) throws Exception {
this.captured = delegate.generate(cg);
return this.captured;
}
private ClassReader createClassReader() {
return new ClassReader(this.captured);
}
}
}측정 코드의 핵심은 CapturingGeneratorStrategy입니다.
Enhancer는 클래스 생성을 GeneratorStrategy에 위임하는데, CapturingGeneratorStrategy는 기본 전략이 생성한 바이트코드를 캡쳐해 보관합니다.
이 바이트코드로 ClassReader를 만들면 실제 프록시 환경과 동일한 조건에서 두 방식을 비교할 수 있습니다.
측정 결과
인터페이스가 없는 경우
| 방식 | 실행 시간 | 메모리 할당 |
|---|---|---|
| 기존 | 216.9 ns/op | 816 B/op |
| 개선 후 | 22.0 ns/op | 432 B/op |
결과: 9.9배 빠름, 메모리 할당 약 47% 감소
인터페이스를 3개 구현한 경우
| 방식 | 실행 시간 | 메모리 할당 |
|---|---|---|
| 기존 | 314.5 ns/op | 1024 B/op |
| 개선 후 | 21.7 ns/op | 432 B/op |
결과: 14.5배 빠름, 메모리 할당 약 58% 감소
개선 후 방식은 타겟으로 삼은 클래스 이름만 읽기 때문에, 인터페이스 개수가 늘어나도 실행 시간과 메모리 할당량이 거의 변함없이 유지되었습니다.
반면, 기존 방식은 인터페이스가 늘어날수록 디코딩 연산이 많아져 성능 격차가 더욱 벌어졌습니다.
이 결과는 CGLIB 클래스 이름 파싱 메서드만 테스트한 벤치마크 수치이므로, 애플리케이션 전체 기동 시간이 극적으로 단축되는 것은 아닙니다.
하지만, 스프링 애플리케이션에선 CGLIB 프록시 생성이 빈번하게 발생하기 때문에 충분히 의미 있는 개선이라고 판단했습니다.
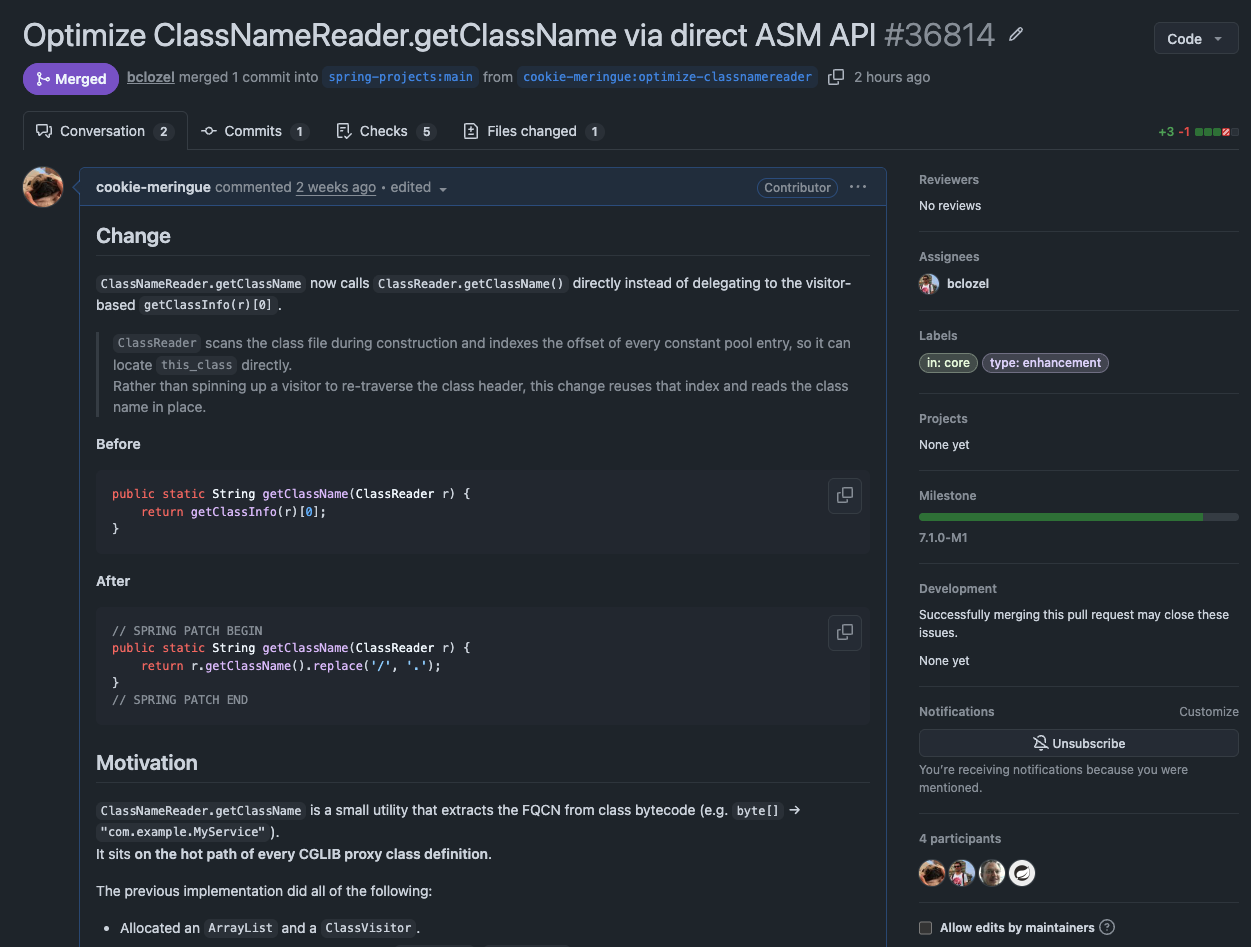
PR 제출, 머지
개선 배경, JMH 벤치마크 결과를 정리해 Spring Framework에 PR을 제출했습니다.
PR 링크: https://github.com/spring-projects/spring-framework/pull/36814
in:core, type:enhancement 라벨이 붙었고, 메인테이너의 감사 인사와 함께 7.1.0-M1 마일스톤으로 머지되었습니다.
마치며
제가 수정한 코드는 단 한 줄에 불과합니다.
하지만, 그 한 줄의 변경을 정당화하고 증명하는 과정이 가장 핵심이었습니다.
오픈소스 프로젝트에선, 성능 개선을 제안할 때 단순히 "이렇게 하면 더 빠릅니다" 라는 주장만으로는 메인테이너를 설득할 수 없습니다.
다음 두 가지 질문에 대한 명확한 답을 준비해야 합니다.
- 실제로 성능이 개선되는가?
- 그 개선이 유의미한 수준인가?
저는 이 질문에 답하기 위해 벤치마크 환경을 구축하고, 구체적으로 어느 정도의 성능 향상이 이루어졌는지 객관적인 수치를 제시했습니다.
이번 기여를 통해, 좋은 PR은 '단순 주장'이 아니라 '확실한 근거와 데이터'를 기반으로 완성된다는 점을 깊이 깨달을 수 있었습니다.


대머랭...