< 프로그래머스 LV3 단어 변환 >
using System;
using System.Collections.Generic;
using System.Linq;
public class Solution
{
public int solution(string begin, string target, string[] words)
{
if (!words.Contains(target))
return 0;
Queue<(string, List<string>, int)> queue = new Queue<(string, List<string>, int)>();// 현재 문자열, 방문 체크
List<string> wordList = words.ToList();
queue.Enqueue((begin, wordList, 0));
while (queue.Count > 0)
{
(string nowString, List<string> nowList, int count) = queue.Dequeue();
int nextCount = count + 1;
foreach (var value in wordList)
{
if (CompareStringOne(nowString, value))
{
if (target == value)
return nextCount;
List<string> nextList = nowList.ToList();
nextList.Remove(value);
queue.Enqueue((value, nextList, nextCount));
}
}
}
return 0;
}
bool CompareStringOne(string a, string b)
{
int count = 0;
for (int i = 0; i < a.Length; i++)
{
if (a[i] != b[i])
count++;
}
if (count != 1)
return false;
return true;
}
}BFS를 통해서 가장 빠르게 단어를 원하는 단어로 한글자씩 변환해나가면서 찾는 문제였습니다.
해당 문제에서 먼저 구현해야 할 함수는 단어 string 값을 서로 비교해서 1개의 문자만 차이나는지 확인하는 함수 CompareStringOne 입니다.
이 함수를 구현하고 나면 이제 일반적인 Bfs와 같이 queue를 돌면서 queue 속의 List를 해당 함수로 확인하면서 조건에 맞는 단어를 찾아주면 됩니다. 단 ,이때 단순히 list를 건내게 되면 기존의 전체의 list에 영향을 줄 수 있으므로, 새로운 list로 copy 해서 Enqueue 시켜 주어야 합니다.
< 프로그래머스 LV3 아이템 줍기 >
using System;
using System.Collections.Generic;
public class Solution
{
// 좌표와 이동횟수를 담는 클래스
public class Pos
{
public int y;
public int x;
public int count;
public Pos(int y, int x, int count)
{
this.y = y;
this.x = x;
this.count = count;
}
}
public int solution(int[,] rectangle, int characterX, int characterY, int itemX, int itemY)
{
int answer = 0;
// 다각형의 테두리 1 (갈 수 있음), 다각형의 테두리 안쪽 2 (갈 수 없음)
var intArrays = new int[102, 102];
// 한 변의 길이가 1인 사각형에 대응하기 위해 모든 좌표를 *2로 둠
characterY *= 2;
characterX *= 2;
itemY *= 2;
itemX *= 2;
// 각 사각형 영역을 탐색해 다각형의 테두리와 내부를 구함
for (int i = 0; i < rectangle.GetLength(0); i++)
{
// 모든 좌표 * 2
int startPosY = rectangle[i, 1] * 2;
int startPosX = rectangle[i, 0] * 2;
int endPosY = rectangle[i, 3] * 2;
int endPosX = rectangle[i, 2] * 2;
// 현재 탐색하는 사각형의 영역 탐색
for (int y = startPosY; y <= endPosY; y++)
{
for (int x = startPosX; x <= endPosX; x++)
{
// 테두리인 경우
if (y == startPosY || y == endPosY || x == startPosX || x == endPosX)
{
// 다른 사각형의 테두리 안쪽이 아닌 경우에만 갈 수 있는 길로 체크
if (intArrays[y, x] != 2)
{
intArrays[y, x] = 1;
continue;
}
}
// 테두리 안쪽인 경우
intArrays[y, x] = 2;
}
}
}
var queue = new Queue<Pos>();
var dirY = new int[4] { 0, 0, 1, -1 };
var dirX = new int[4] { 1, -1, 0, 0 };
queue.Enqueue(new Pos(characterY, characterX, 0));
// BFS 탐색
while (queue.Count > 0)
{
Pos currPos = queue.Dequeue();
intArrays[currPos.y, currPos.x] = 2; // 방문처리
for (int i = 0; i < 4; i++)
{
// 범위를 벗어날 수 없으므로 예외처리하지 않음 (0,0 ~ 101,101)
Pos movePos = new Pos(currPos.y + dirY[i], currPos.x + dirX[i], currPos.count + 1);
// 목표 지점에 도착
if (movePos.y == itemY && movePos.x == itemX)
{
// 모든 좌표 * 2 였기 때문에 이동 횟수 / 2
answer = movePos.count / 2;
queue.Clear();
break;
}
if (intArrays[movePos.y, movePos.x] == 1)
queue.Enqueue(movePos);
}
}
return answer;
}
}최초의 문제 풀이 시에는 int[,] 배열을 이용해 사각형들을 for문으로 돌면서 중첩된 배열에는 숫자를 놓게 쌓는것으로, 해당하는 배열 숫자가 1이거나 2(교차점) 만 이동할 수 있도록 하여 문제를 풀었습니다.
그러나 여기서 배열 자체가 연속적이지 않고 이산적이기 때문에 서로 떨어져 있음에도, 상하좌우에서 1이 있으면 건너뛰어 이동해 버리는 문제가 있었습니다.
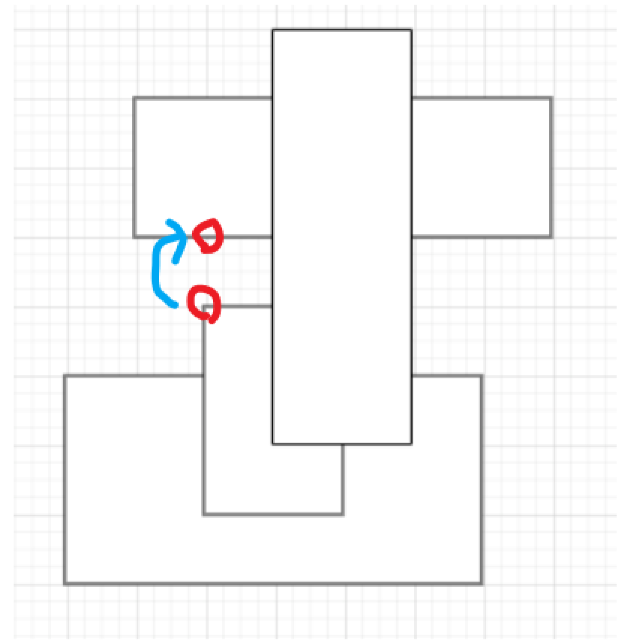
위와 같이 실제로는 서로 떨어져 있음에도, BFS를 도는 중에는 저 부분이 연결 되어있는 것으로 판단해 버립니다.
이를 해결하기 위해서 애초에 처음 배열을 생성할때 길이를 2배로 하여, 건너뛸 수 없도록 하고, 최종적인 거리를 1/2 로 줄여 출력해 주는 방식으로 풀이를 수정했습니다.
< CS 공부 >
( out 과 ref )
ref
목적 : 함수에 인자로 전달될 때, 해당 변수의 값을 함수 안에서 수정할 수 있게 합니다. 즉, 복사가 아니라 참조 값을 넘여야 할때 붙여주어야 합니다
사용법 : ref를 사용할 때는 함수 호출 전 변수에 반드시 초기값이 있어야 합니다.
특징 : 함수 내에서 전달된 값을 수정하고, 수정된 값을 호출한 곳에 반영합니다.
void ModifyValue(ref int value)
{
value = value * 2;
}out
목적 : 함수에 전달된 변수를 함수 안에서 초기화할 수 있게 합니다.
사용법 : out을 사용할 때는 함수 호출 전에 변수가 초기화되지 않아도 되며, 반드시 함수 내에서 초기화가 되어야 합니다.
특징 : 함수 내에서 전달된 변수의 값을 "새롭게 설정"하는 용도로 사용됩니다.
out 매개변수는 함수 내에서 값을 반드시 초기화해야 하며, 호출한 곳에서는 그 값을 사용할 수 있습니다.
void InitializeValue(out int value)
{
value = 42; // 값이 초기화됨
}정리하자면 둘 다 함수에 영향을 받고 값이 변환 되나, ref는 기존에 사용하던 변수를 함수에 집어넣어 복사가 아닌 참조로 값을 가져오는 것이고, out은 아예 함수 내에서 변수를 밖으로 던져주는 방식입니다. 따라서 ref는 외부에서 초기화가, out은 내부에서 초기화가 됩니다.
( overroading - 오버로딩 )
프로그래밍에서 오버로딩은 같은 이름을 가지는 함수를 여러가지 매개변수의 형태로 사용 할 수 있는것을 말합니다. 이는 나중에 배울 오버라이딩과는 다른 개념입니다.
즉, 오버로딩은 같은 작업을 하는 메소드이나, 입력받는 값들이 다른 경우에 사용합니다.
오버로딩 규칙
1. 메소드 이름은 동일해야 한다
2. 매개변수의 수나 타입이 달라야 한다. 단, 반환 타입만 다르고 매개변수의 종류와 수가 같다면 이는 오버로딩으로 간주하지 않는다.
3. 매개변수의 순서도 달라야한다.
오버로딩을 사용하면 아래와 같이 같은 이름의 함수를 여러 형태로 나타낼 수 있습니다.
// 정수 두 개 더하기
int Add(int a, int b)
{
return a + b;
}
// 실수 두 개 더하기
float Add(float a, float b)
{
return a + b;
}
// 정수 세 개 더하기
int Add(int a, int b, int c)
{
return a + b + c;
}오버로딩 사용시 발 생 할 수 있는 문제점
-> 앞서 말했듯이 반환 타입만 다르게 하는것은 오버로딩이 아닙니다
-> 매개변수 타입이나 갯수가 비슷한 경우 명확한 구분을 하지 못해 에러가 발생할 수 있습니다.
결론 :
이러한 오버로딩을 사용하면 코드의 재사용성을 높이고 함수의 이름을 일관되게 유지해서 코드 작성시에 번잡스럽지 않게 개발을 진행 할 수 있습니다.(Add2Num Add3Num ... 처럼 이름을 여러개 지을 필요가 없음
( 구조체와 클래스 - Struct vs Class)
둘은 비슷해 보이나 아래와 같은 차이점이 있습니다.
타입
Struct는 값 타입입니다. 때문에 복사가 이루어지면 원붠과 복사본이 독립적으로 동작합니다. 또한 값 타입이기 때문에 stack 영역에 할당됩니다.
Class 는 참조 타입입니다. 이는 주소를 저장하므로 복사를 진행하면 주속밧만 복사하여 원본에 영향을 주게 됩니다. 또한 참조 타입임으로 힙 영역에 할당됩니다.
상속
Struct는 상속을 지원하지 않지만 Class 에서는 상속을 지원하여 다형성을 활용할 수 있습니다.
Null 허용 여부
Struct는 값타입으로 null을 할당할 수 없습니다. 단 ? 를 이용해서 nullable로 체크하면 할당이 가능합니다. class는 참조 타입이므로 당연하게 null을 할당할 수 있습니다.
사용 사례
Struct는 값타입이므로 작고 가벼운 데이터 구조에 적합합니다. 되도록이면 필드만으로 구성된 케이스가 좋습니다.
ex) 플레이어 데이터
Class 는 복잡한 데이터 구조나 객체 지향적으로 프로그래밍, 즉 메소드들이 포함되어 있을 때에 사용하기 좋습니다.
ex) 플레이어 동작과 관련된 스크립트
