< 프로그래머스 LV2 뒤에 있는 큰 수 찾기>
키워드 : Stack
using System;
using System.Collections.Generic;
public class Solution
{
public int[] solution(int[] numbers)
{
int[] answer = new int[numbers.Length];
var stack = new Stack<(int, int)>(); // index -> value 순서
for (int i = 0; i < numbers.Length; i++)
{
while (stack.Count > 0 && numbers[i] > stack.Peek().Item2)
{
var top = stack.Pop();
answer[top.Item1] = numbers[i];
}
stack.Push((i, numbers[i]));
}
while (stack.Count > 0)
{
var top = stack.Pop();
answer[top.Item1] = -1;
}
return answer;
}
}자주 등장하는 BFS 문제를 풀이 할 때 사용하게 되는 Queue와 달리, Stack은 DFS 에서 쓴다고는 하지만 재귀로도 구현 할 수 있어 그렇게 까지 많이 사용해보지는 않았습니다.
해당 문제는 DFS 풀이는 아니지만 자신의 뒤에 오는 가장 가까운 최대값을 찾기 위해서 선입 후출 방식의 Stack 을 이용해서 푸는 것이 무식하게 이중 for문을 도는 것보다 훨씬 빠르게 풀이를 진행 할 수 있게 도와줍니다.
Stack 에서의 동작은 아래와 같습니다.
- Stack 내부에는 (순서, 해당하는 값) 의 튜플이 들어가게 됩니다.
- for문을 돌면서 현재의 숫자를 가지고 Stack의 While문을 을 돌면서 현재의 number[i] 값보다 낮은 값들은 모두 Answer 의 위치에 현재 값을 넣습니다.
- 최종적으로 남은 값들은 이미 뒤에 큰 수가 없는 상태이므로 모두 -1을 집어넣습니다.
이렇게 순회하면서 특정한 조건을 찾는 경우에도, 위와 같은 조건이라면 Stack 을 이용해 볼 수 있다는 사실을 알 수 있었습니다.
< 프로그래머스 LV2 연속된 부분수열의 합>
키워드 : 투 포인터
public class Solution
{
public int[] solution(int[] sequence, int k)
{
int[] answer = new int[2] { -1, -1 };
int left = 0;
int right = 0;
int add = 0;
int min = int.MaxValue;
int n = sequence.Length;
while (right < n)
{
add += sequence[right];
while (add > k && left <= right)
{
add -= sequence[left];
left++;
}
if (add == k)
{
if (right - left < min)
{
min = right - left;
answer[0] = left;
answer[1] = right;
}
}
right++;
}
return answer;
}
}
가장 기본적인 형태의 투 포인터 문제였습니다.
투 포인터는 두 개의 포인터를 이용해서 효율적으로 리스트나 배열을 순회하는 알고리즘으로 아래와 같은 특징을 가집니다
시작점과 끝점을 지정하여 점진적으로 이동하면서 조건을 만족하는지 확인함.
두 개의 포인터가 한 방향으로 이동하거나, 서로를 향해 이동하는 방식으로 진행됨.
시간 복잡도를 O(N)으로 줄일 수 있음 (대부분의 브루트포스 풀이보다 빠름).
사용하는 문제 유형은 아래와 같습니다.
- 두 수의 합 (Two Sum, 정렬된 배열)
- 특정 조건을 만족하는 부분 배열 찾기 (연속 부분 합, 투 포인터 & 슬라이딩 윈도우)
- 배열에서 중복을 제거하거나 특정 조건을 만족하는 요소들을 필터링하기
- 회문 검사 (Palindrome Check)
이 중에서 위의 2개는 많이 풀어 본 유형이었으나 아래 2개는 처음 들어보는 유형이었습니다.
-
먼저 중복 제거는 -> 선행하는 Fast 와 따라오는 slow 두개의 포인터를 두고, fast가 지나오면서 확인한 것이 slow에서 찾아진다면 제거하는 형식으로 구현됩니다.
-
다음으로 회문 검사는 ABCBA 와 같은 대칭되는 문자를 찾는 것인데, 이 경우에는 포인터가 둘 다 0에서 시작하는 것이 아니라, 하나는 0, 하나는 끝에서 시작해 둘다 중앙으로 이동하면서 서로의 값이 같은지 확인하는 방식으로 구현됩니다.
< 소수찾기 - 에라토스테네스의 체>
static bool[] SieveOfEratosthenes(int n)
{
bool[] isPrime = new bool[n + 1];
Array.Fill(isPrime, true); // 모든 수를 소수로 가정
isPrime[0] = isPrime[1] = false; // 0과 1은 소수가 아님
for (int i = 2; i * i <= n; i++)
{
if (isPrime[i]) // i가 소수이면
{
for (int j = i * i; j <= n; j += i) // i의 배수를 제거
{
isPrime[j] = false;
}
}
}
return isPrime;
}일반적으로 위와 같이 구해지는 에라토스테네스의 체 는 N 이하의 모든 소수를 찾아 내는 데 효율적인 알고리즘 입니다.
이 알고리즘의 핵심은, 소수가 판별되면, 그 소수의 배수를 제거하는 방법으로 이루어 집니다.
또한, 이때에 for문의 조건에서 i * i < n 으로 한정되는데 이는, 이후의 값은 앞선 조건에 의해서 이미 찾아졌기 때문입니다.
- 즉 n = a * b라고 가정했을 때, a 또는 b 둘 중 하나는 반드시 √n 이하이기 때문에 위와 같은 조건으로 범위를 단축 시킬 수 있는 것입니다.
< CS 공부 >
( 컬랙션 )
c# 에서 System.Collections 의 네임 스페이스에서는 다음과 같은 컬랙션을 제공합니다.
- ArrayList : 배열과 흡사하지만 생성 추가에 따라 크기가 자동으로 변화
- Hashtable : key와 value로 구성됨
- Hashset : 중복이 불가능한 컬랙션, 검색에 빠르다
- Queue : 선입 선출
- Stack : 후입 선출
그리고 이러한 컬랙션은 모든 데이터 타입을 가질 수 있다는 특징을 공통적으로 가집니다.
단, 이러한 컬랙션을 사용하게 되면 아래 서술할 박싱 언박싱 문제를 발생시킬 수 있습니다.
( 박싱 언박싱 )
박싱과 언박싱은 무심코 사용하게 되면 큰 성능 문제를 발생 시킬 수 있으므로 꼭 기억하고 가는 것이 좋습니다. 특히 면접 질문에 빈번히 등장하는 것으로 알려져 있습니다.
- 박싱 : 값 탕비의 객체를 참조 타입으로 변환하는 작업.
-> Stack 에 있던 값 타입의 객체를 Heap 으로 이동할 때 복사가 한번 일어난다. Heap 에서는 복사된 이 영역을 참조 타입이 가리키게 된다.- 언박싱 : 참조 타입을 값 타입으로 변환하는 작업.
-> Heap 에 있던 데이터를 Stack으로 복사한다.
여러번 언급 되어왔지만 다시한번 정리하자면
값 타입 : 실질적인 데이터 값으로 stack 에 저장,
ex ) : 정수형, 실수형, 문자형 , 불린형
참조 타입 : 값을 가지는 데이터의 주소를 가지고 있는 값 Heap 에 저장
ex ) 컬랙션, new 키워드로 생성되는 것들
다음으로 박싱과 언박싱의 과정에 대해서 확인하면 아래와 같습니다.
박싱 : Stack -> Heap
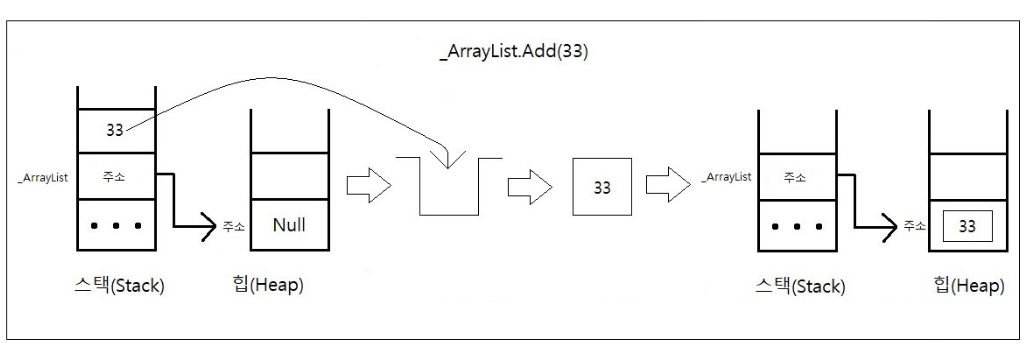
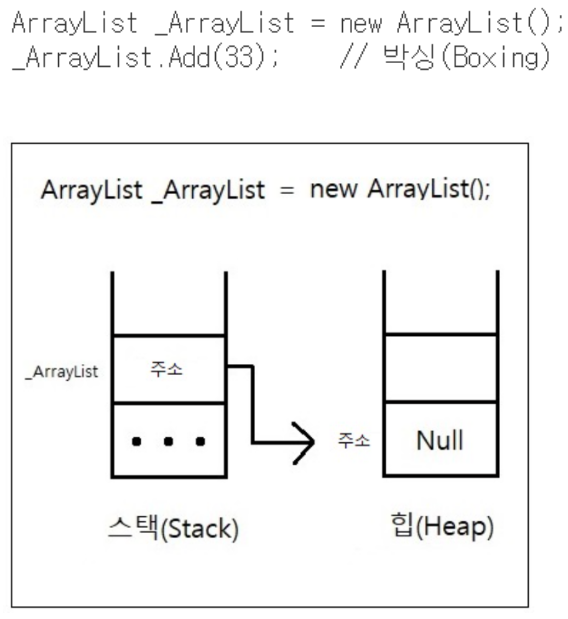
new 로 생성된 arrayList 는 참조 타입이고 여기에 33이라는 값 타입을 넣을때 박싱이 발생한다.
언박싱 : Heap -> Stack
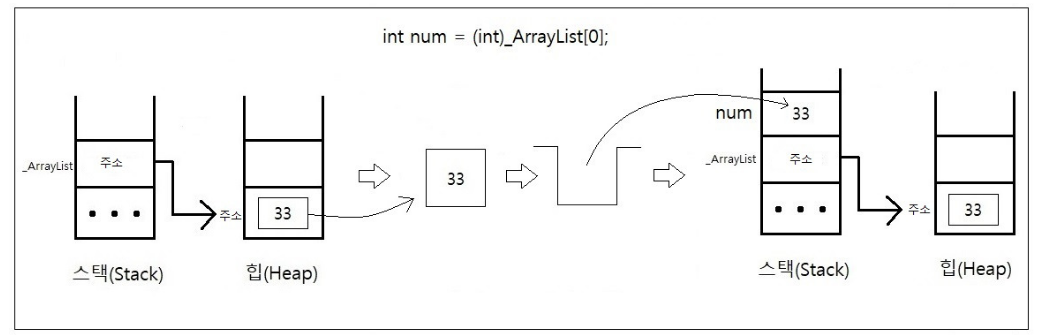
Heap 에서 해당하는 값의 주소를 통해 값을 꺼내와서 Stack 영역으로 복사합니다.
여기서 가장 중요한 것은 박싱, 언박싱의 문제점 입니다.
- 박싱, 언박싱은 성능적인 문제가 가장 큰데, 단순히 힙에 넣는 것 보다 박싱을 통해서 힙에 값을 넣게 되면 많게는 20배 까지 시간이 더 걸리게 됩니다. 또한 언박싱도 4배 정도의 시간이 더 소모될 수 있습니다.
- 따라서 코드가 복잡해 질 수록 시간이 더 많이 걸리므로, 이를 해결한 일반화 컬랙션을 사용하는 것을 권장합니다.
( 일반화 컬랙션 )
일반화 컬렉션은 제네릭 타입 를 이용하므로, 어떤 데이터가 들어갈지 미리 정하는 방식을 사용해 박싱과 언박싱 문제를 해결합니다.
이미 타입이 정해져 있으므로 값 타입 그대로를 주소에 저장하기 때문에 박싱 언박싱 문제가 발생하지 않습니다.
일반화 컬랙션은 아래와 같습니다.
- List : 리스트는 저장위치에 접근이 가능하고 동적으로 사용 가능합니다.
- Dictionary : 딕셔너리는 HashTable과 같이 Key와 Value로 구분됩니다. 많은 데이터가 저장된 경우 리스트보다 빠르나, 두개의 값을 가지므로 사용 메모리가 커질 수 있습니다.
- Queue: 선입 선출
- Stack : 후입 선출
( 메모리 구조)
이러한 Heap 과 Stack 의 영역이 어떻게 분리되어있고 관리되는지 확인하기 전에 먼저, 프로그램의 실행 방식에 대해서 알아둘 필요가 있습니다.
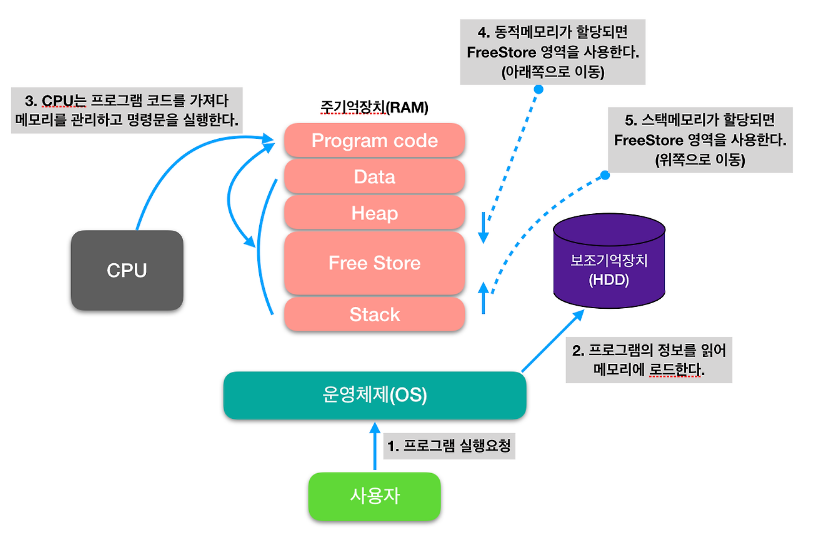
- 프로그램이 시작되면 주 메모리 RAM에 로드됩니다. 이 메모리 공간은 프로그램의 명령과 데이터를 저장하는데 사용됩니다.
- 프로그램이 처음 로드 될 때, OS는 일반적으로 인접한 메모리 블록을 할당하는데, 이를 프로세스라 하며 코드, 데이터 및 스택 공간을 포함하여 모든 리소스를 저장합니다.
- 프로그램에 할당된 메모리는 특정 목정으로 여러 영역으로 나뉘는데, 이 영역은 아래와 같이 표현될 수 있습니다.
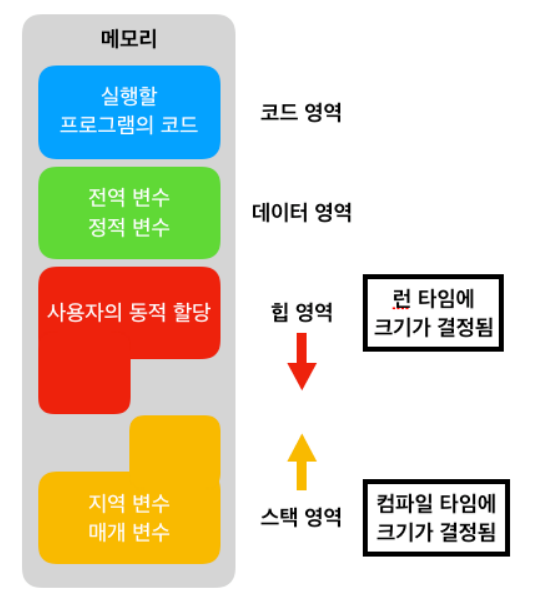
- 코드 영역 : 프로그램을 구성하는 명령 저장. 해당 부분이 개발자가 작성한 소스코드가 들어가는 영역. 함수, 제어문, 상수 등이 여기에 해당.
- 데이터 영역 : 프로그램이 실행되는 동안 사용하는 데이터를 저장하는 메모리 영역. 전역 변수, 정적 변수, 지역 변수를 모두 포함.
- 스택 영역 : 프로그램이 자동으로 사용하며, 함수 호출 및 로컬 변수등의 임시 데이터를 저장하는 영역. 함수 호출이 끝나면 사라진다.(후입 선출 방식)
- 힙 영역 : 동적으로 메모리 블록을 할당 및 해제하는데 사용하는 영역.
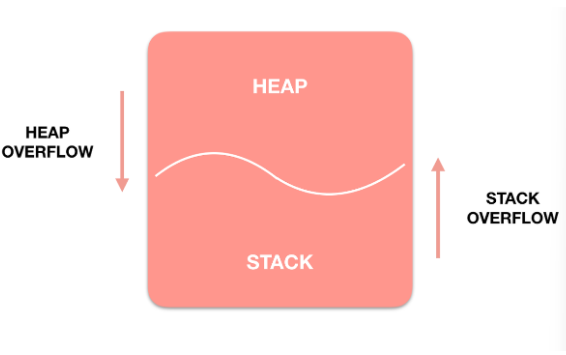
또한 위의 그림처럼 Heap과 Stack 영역은 같은 공간을 공유하므로, 서로의 영역을 침범하는 OverFlow가 발생할 수 있습니다.
( 스택 영역 )
스택 영역에서는 함수 호출 및 실행에 관련된 데이터를 저장합니다. 스택 영역은 그 이름처럼 후입 선출 방식으로 메모리를 할당, 해제 하기 때문에 메모리를 쉽게 관리할 수 있습니다.
이에 해당하는 값은 값 타입으로, 지역변수, 매개변수, 리턴 값 등이 포함됩니다.

또한
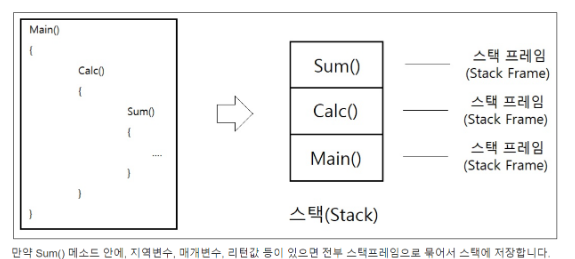
앞서 말한 Stack 구조의 이점으로 Main -> Calc -> Sum 순서로 호출 되었다면 데이터 해제는 Sum -> Calc -> Main 순으로 진행됩니다.
추가적으로, 스택은 제한된 리소스이며 함수가 재귀 형태처럼 너무 많이 반복되면 스택 오버플로우가 발생할 수 있습니다. 이러한 용량 제한은 운영체제에 의해 결정됩니다.
- 스택 크기가 너무 작으면 : 스택 오버 플로우가 발생 할 수 있는 깊게 호출된 함수를 처리하지 못할 수 있습니다.
- 스택 크기가 너무 크면 : 많은 양의 메모리를 소비하여 시스템 전체 성능에 영향을 미칠 수 있습니다.
( 힙 영역 )
힙은 동적 메모리 할당에 사용되는 영역입니다. 스택과 달리 가변적이어서 프로그램 실행 도중에 메모리를 할당하는데 사용합니다.
이는 new 키워드를 이용해서 생성한 매모리가 저장됩니다. 또한 Class, 델리게이트, 인터페이스도 여기에 할당됩니다.
- 추가적으로 C# 에서는 힙 영역은 GC(가비지 컬렉터)에 의해 자동으로 정리되는데, 이른 주소가 삭제되어 접근이 불가능해진 메모리를 삭제해주는 것을 말합니다. 단, 어느 시점에 GC가 동작할지는 알 수 없습니다.
