자바스크립트의 배열을 공부하다가 자바스크립트에서 배열은 일반적인 자료구조 배열이 아니라 해시 테이블로 구현된 객체라는 것을 알고 해시 테이블에 대해 좀 더 자세히 공부해보기로 했다.
해시 테이블의 개념
해시 테이블은 Key에 Value을 매핑하여 저장하는 자료구조이다. 해시 테이블은 입력 받은 Key를 해시 함수를 사용하여 index를 계산한다. 계산된 index를 통해 버킷(buckets) 또는 슬롯(slots)이라는 장소에 값이 저장된다.
index는 다음과 같이 계산된다.
index = fuction(key, array_size)
위의 식은 일반적으로 2단계로 나뉜다.
hash = hashfunc(key)index = hash % array_size
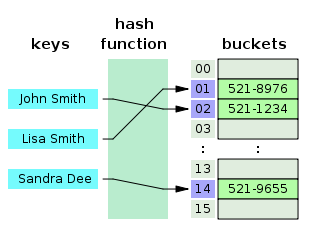
즉 위의 그림을 바탕으로 John Smith 라는 Key값과 521-1234라는 값을 해시 테이블에 저장한다고 예시를 들면
- John Smith라는 Key값을
hashfunc의 인수에 전달한다. hashfunc를 통해 반환된 값이hash가 된다.hash는array_size보다 클 수 있기 때문에hash % array_size를 한 값이 최종적으로 index가 되며array[index]에 521-1234라는 값이 저장된다.
이렇게 해시 테이블은 Key에 매핑된 Value를 찾을 때 1번의 hashfunc 를 수행하면 찾을 수 있기 때문에 특정 요소를 검색하거나 요소를 삽입 또는 삭제하는 경우 시간이 굉장히 빠르다는 장점이 있다. 특히 엔트리가 크고 최대 엔트리의 수를 예측할 수 있을 때 효율적이다.
충돌을 해결하는 방법
당연하게도 위에서 살펴본 계산을 통해 나온 index 가 중복되어 겹칠 수 있다. 이렇게 index가 충돌하는 어떤 방법을 사용할 수 있는지 살펴보자.
Separate chaining
Separate chaining은 Linked list를 이용하는 방법이며 buckets들은 linked-list를 가리키는 참조값을 가지고 있는다. index가 충돌하는 경우 해당 index의 buckets이 가리키는 linked-list의 node로 추가된다.
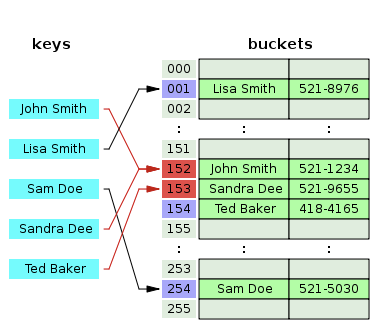
위의 그림과 같이 Key값 John Smith와 Sandra Dee 둘 다 152번 index로 충돌이 발생하였다.
(John Smith, 521-1234)가 먼저 저장되었기 때문에 (Sandra Dee, 521-9655)는 해당 linked-list의 다음 node로 추가가 된다.
데이터 삭제
Separate chaning에서 데이터를 삭제하는 경우 그냥 linked-list에서 node를 삭제하면 된다.
이 방법의 최악의 경우는 모든 항목이 동일한 bucket에 삽입되는 경우 해시 테이블이란 자료 구조가 유효하지 않게 되며 리스트를 n개 만큼 순차적으로 탐색해야 한다.
Open addressing
Open addressing 은 추가적인 메모리 공간을 사용하지 않고 해시 테이블의 비어 있는 공간을 활용하는 방법이다. 예시를 통해 Open addressing의 일반적인 개념을 살펴보자
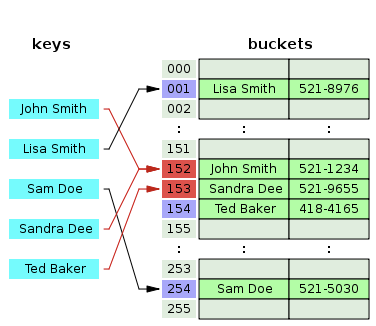
위의 그림에서는 (John Smith, 521-1234)가 152번 index에 저장되었다. 그 이후 (Sandra Dee, 521-1234)도 152번 index에 저장하려 했지만 이미 152번은 사용하고 있는 슬롯이기 때문에 그 이후 index인 153 index에 저장되었다. 그리고 (Ted Baker, 418-4165) 또한 계산된 index가 153이었지만 이미 사용하고 있는 슬롯이어서 그 이후 index인 154번 index에 저장되었다.
이렇게 index가 충돌하는 경우 그 index 이후부터 비어 있는 슬롯을 발견할 때까지 특정 index 만큼 움직인다.
위에서 말한 특정 index를 정하는 방법이 3가지 있다.
- Linear probing: 고정 폭만큼 index를 이동시키는 방법이며 일반적으로 그 고정폭의 크기는 1이다.
- Quadratic probing: 이동하는 폭의 크기가 제곱수로 늘어난다.
- Double hashing: 2개의 해시 함수를 사용하여 하나는 최초의 해시 값을 얻는데 사용하고, 나머지 하나는 충돌이 일어났을 경우 이동폭의 크기를 얻는데 사용한다.
데이터 삭제
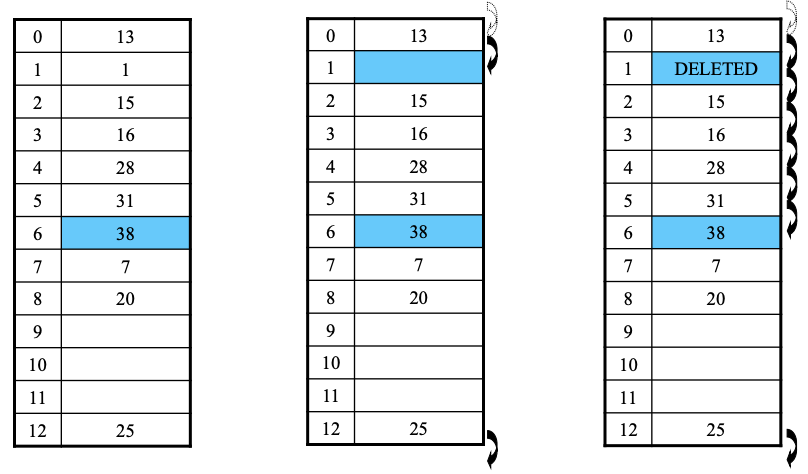
위의 그림처럼 1과 38을 삭제하려고 한다. 이때 1과 38 둘 다 해시 함수에 의해 0번 index 부터 검색을 한다고 가정을 한다. 1을 삭제한 후 38을 삭제하기위해 0번 index 부터 검색을 하는데 1번 index가 비어있으면 탐색을 끝내 우리가 원하는 데이터인 38을 못찾게 된다. 따라서 삭제한 빈 슬롯에는 Dummy data를 넣는다.
Reference
