계기
지난 글에서 만든 Semi-Lockfree Object Pool을 이용해 Lockfree Queue를 구현하다 버그가 좀 나와서, 디버깅한 방법론을 정리해본다.
In-memory logging
기본적인 디버깅 방법 중 하나는 로그를 남기는 것이다.
흔히 파일이나 콘솔에 로그를 남겨, 상태 변화를 추적해보고는 한다.
문제는 파일이나 콘솔에 동기 I/O 작업을 하면, 해당 thread가 block 상태에 들어간다는 데 있다.
멀티스레드 코드에서는 한 thread가 block 상태에 들어가버리는 바람에, 동시에 thread가 돌면서 나타나는 동기화 문제가 숨겨질 가능성이 높다.
이에 대한 대안으로, 메모리 상에 로그를 남기는 방법이 있다.
미리 고정 크기 버퍼를 할당해 놓고, 거기다가 무슨 일이 일어났는지를 기입하는 방법이다.
(가변 크기로 하는 것은 적절치 않은게, 추가 공간을 위한 동적 할당이 들어가게 되면 그 자체로 동기화가 돼버려 문제가 감춰질 수 있다.)
고정 크기를 할당해놓으면, 로그가 넘치면 어떻게 할까?
한 바퀴 돌아서 기존 로그를 덮어쓰도록 하면 된다.
template <typename Param, std::size_t MaxEntries>
class MemoryLogger
{
public:
struct Entry {
std::thread::id tid;
std::string_view msg;
Param param;
std::size_t no;
std::source_location loc;
};
public:
void log(std::string_view message, Param param, std::source_location loc = std::source_location::current()) {
const auto event_idx = _event_index++;
auto& entry = _logs[event_idx % MaxEntries];
entry.tid = std::this_thread::get_id();
entry.msg = message;
entry.param = param;
entry.no = event_idx;
entry.loc = loc;
}
private:
std::atomic<std::size_t> _event_index;
std::array<Entry, MaxEntries> _logs;
static_assert(decltype(_event_index)::is_always_lock_free);
};아주 간단하게 구현해본 MemoryLogger다.
각 MemoryLogger::Entry마다 thread ID(tid), 메시지(msg), 저장할 임의의 변수값 하나(param), 로그 남긴 순서 (no), 소스 위치(loc)를 남겨봤다.
그리고 Entry의 고정 크기 배열을 둬서, 이번 index에 로그를 남기는 방식이다.
모든 thread 가 MemoryLogger::log()를 호출할 것인데, 동시에 같은 index에 로그를 남기지 않도록 _event_index를 std::atomic<std::size_t>으로 선언해 index를 증가시킨다.
msg가 std::string_view인 이유는, 로깅하는 데 문자열을 복사한다는 건 불필요한 오버헤드이기 때문이다.
복사 대신, 프로그램 실행 시간동안 사라지지 않을 문자열의 view를 전달하면 복사가 최소화된다.
보통은 C-style string literal을 전달할텐데, 그러면 char*와 문자열 길이만 복사가 될 것이다.
이제 이걸 사용해 디버깅을 한 예시를 보기 위해 Lockfree Queue를 살펴보자.
Lockfree Queue
개념
구현해볼 것은 Michael-Scott Queue이다.
우선 Lockfree Queue가 되기 위해서는, Queue의 head와 tail을 따로 조작할 수 있어야 할 것이다.
한번에 head와 tail을 동시에 수정하면서 동기화를 맞춘다는 것은 불가능할테니...
문제는 Queue에 단 1개의 data만 들어 있어서, head와 tail이 같은 node를 가리키고 있을 때이다.
여기서 그 마지막 data까지 꺼내려면? head와 tail를 동시에 nullptr로 만들어야 하는 상황이 된다.
그걸 피하기 위해, 데이터가 없을 때에도 1개의 dummy node를 가리키도록 하자.

위 그림은 push()를 2번, pop()을 2번 시행한 예시이다.
Queue가 비어있을 때에는 head와 tail 모두 dummy node를 가리키고 있다.
그렇지 않을 때에는 Queue에 데이터가 들어있는 것이며, head.next 로 제일 앞 데이터를 가져올 수 있다.
push()의 기본 동작
- 새로 추가할 데이터를 위한
new_node를 할당받고, 그 안에 데이터를 세팅한다. tail.next가nullptr가 아니라면, 다른 thread가push()진행 중이므로, 처음부터 재시도한다.- (Optional) 여기서 관찰한
tail.next로tail을 CAS로 바로 옮겨줘, 또 재시도할 확률을 줄일 수도 있다.
- (Optional) 여기서 관찰한
tail.next = new_node로 연결하려 시도한다.- 다른 thread도 또 다른 새로운 노드를
tail.next에 연결하려 시도할 수 있으므로, CAS로 처리해야 한다.
- 다른 thread도 또 다른 새로운 노드를
- 성공 시,
tail = new_node로 tail을 전진시킨다. 실패 시, 처음부터 재시도한다.- 만일, 위에서 (Optional)을 했다면, tail이 다른 thread에 의해 전진될 수도 있으므로, CAS로 전진시켜야 한다.
pop()의 기본 동작
head.next == nullptrorhead == tail이면 비어 있으므로,std::nullopt를 반환한다.- 비어 있지 않다면:
head.next에 들어있는 데이터를 반환하기 위해 임시로 복사한다.head전진 전 미리 복사해둬야, node 재사용으로 데이터가 덮어씌워지는 불상사를 방지할 수 있다.head가 이미 바뀌어,head전진이 실패할 수도 있으므로, node 이동은 불가능하다.- 이 경우
head에서 값을 복사하는 것이 안전하려면, node가 Object Pool을 통해 관리되어 아직 해제되지 않았어야 하고, 저장할T타입이 trivially copyable해야 한다.
- 이 경우
head = head.next로 head를 전진시키려 시도한다.- 다른 thread와 같이 시도하므로, CAS로 처리해야 한다.
- 성공 시, 임시 복사해놓은 데이터를 반환한다. 실패 시, 처음부터 재시도한다.
구현 및 디버깅
위 동작 설명에서 보다시피, 실수할 수 있는 부분이 꽤 있다.
실수하면 어떤 문제가 발생하는지, 그리고 그걸 In-memory logging으로 어떻게 잡을 수 있는지 한가지 예시를 들어 살펴보자.
문제 상황 예시
문제
여러 문제가 나타날 수 있지만, 대표적으로 head<->head.next 간의 / tail<->tail.next 간의 동기화 문제가 있을 수 있다.
head를 읽은 후에, 그걸 이용해 head->next를 읽으려고 할 텐데, 그 사이에 틈이 있다.
그 틈에 다른 thread가 그 head를 pop 시켜버린다면? dangling pointer access가 된다.
이걸 막으려면 메모리를 재사용하는 Object Pool을 사용할 수 있지만...
그러면 그 틈에 다른 thread가 그 head를 pop 시켜버리고, 또 새로운 push를 시켰는데, 그 head였던 node가 재사용된다면?
기존 head가 재사용되어 tail이 되어버리면, head->next를 읽었더니 nullptr이고, 따라서 Queue가 비어있지 않은데도 비어있다고 판별할 수도 있다.
tail node의 경우에도 동일한 원리의 문제가 발생하는데, 그 경우에는 tail->next가 비어 있다는 판단을 하게 되어, 새로운 node를 이미 사라진 node 뒤에 붙인 후, tail 이동 CAS에서 실패하게 된다.
디버깅
이 상황을 실제 동작으로 확인해보자.
앞에서 만들었던 MemoryLogger를 활용해, atomic 변수에 read/write 할 때마다 로그를 남겨 추적할 수 있다.
위 상황은 Queue가 비어있지 않은데도 비어있다고 판별하는 상황이니, 상황을 만들자면 이렇다.
thread 2개가 무한히 push() 2번 -> pop() 2번을 수행한다.
그러면 pop() 수행 시에 비어있다고 판별했다면, 오류 상황이라고 할 수 있다.
오류 상황을 감지했다면, Queue 안에 디버깅용 atomic _failed flag를 true로 세팅하고 예외를 던져 작동을 중지시킨다.
Queue의 push()와 pop() 코드 중간중간에 이 _failed flag를 체크해서, true인 경우에 다른 thread도 작동이 중지될 수 있도록 한다.
이렇게 하면, 1번 thread에서 예외를 던지는 데 너무 오래 걸려버려, 2번 thread가 로그를 다 덮어씌워버리는 상황을 방지할 수 있다.
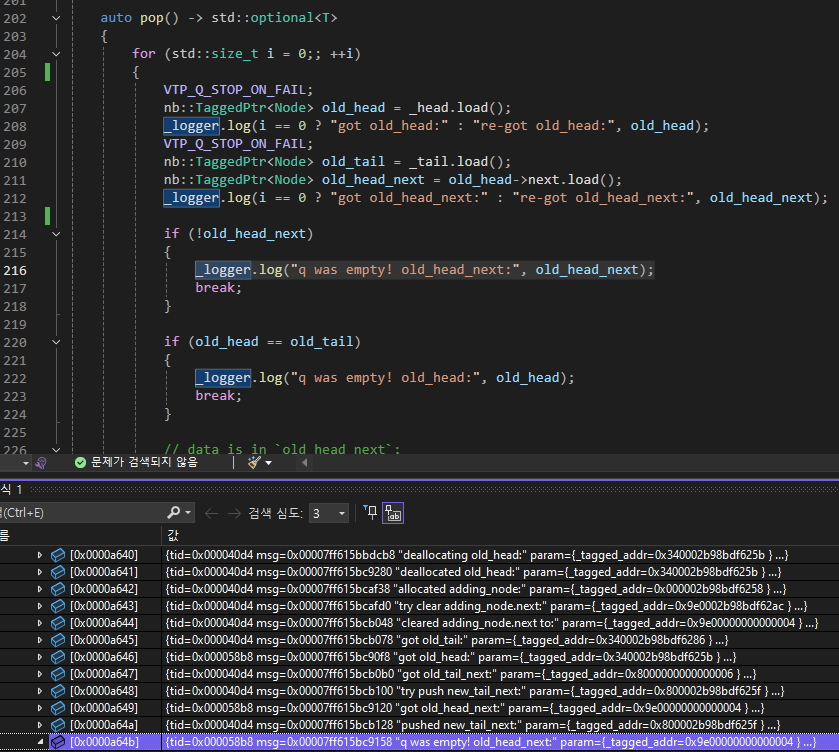
메모리 로그는 위와 같이 남게 된다.
현재 TaggedPtr<Node> 구현상 pointer 상위 8-bit와 하위 3-bit를 tag로 활용중이므로 node 주소를 해석할 때는 이 부분을 빼고 생각해야 한다.
| idx | Thread ID | Message | Node* |
|---|---|---|---|
| 0 | 0x40d4 | got old_head: | 0x340002b98bdf625b |
| 1 | 0x40d4 | got old_head_next: | 0x9e0002b98bdf62ac |
| 2 | 0x40d4 | extracting data from old_head_next: | 0x9e0002b98bdf62ac |
| 3 | 0x40d4 | extracted data from old_head_next: | 0x9e0002b98bdf62ac |
| 4 | 0x40d4 | try move to new_head: | 0x340002b98bdf62ac |
| 5 | 0x40d4 | popped: | 0x340002b98bdf625b |
| 6 | 0x40d4 | deallocating old_head: | 0x340002b98bdf625b |
| 7 | 0x40d4 | deallocated old_head: | 0x340002b98bdf625b |
| 8 | 0x40d4 | allocated adding_node: | 0x000002b98bdf6258 |
| 9 | 0x40d4 | try clear adding_node.next: | 0x9e0002b98bdf62ac |
| 10 | 0x40d4 | cleared adding_node.next to: | 0x9e00000000000004 |
| 11 | 0x40d4 | got old_tail: | 0x340002b98bdf6286 |
| 12 | 0x58b8 | got old_head: | 0x340002b98bdf625b |
| 13 | 0x40d4 | got old_tail_next: | 0x8000000000000006 |
| 14 | 0x40d4 | try push new_tail_next: | 0x800002b98bdf625f |
| 15 | 0x58b8 | got old_head_next: | 0x9e00000000000004 |
| 16 | 0x40d4 | pushed new_tail_next: | 0x800002b98bdf625f |
| 17 | 0x58b8 | q was empty! old_head_next: | 0x9e00000000000004 |
위 로그에서 문제가 되는 head node 는 0x0002b98bdf6258이다.
Thread #40d4와 Thread #58b8 둘 모두 old_head를 해당 head node로 읽었는데, Thread #40d4에서 먼저 그 head node를 pop() 시킨 후, 다시 push()해서 해당 node가 재사용이 되고, 그 node의 next가 nullptr로 설정되었다.
그 상태에서 Thread #58b8은 이미 head가 아닌 재사용된 old_head의 next를 읽어버려서 nullptr이 읽히고, 그 결과 Queue가 비어있다는 잘못된 판단을 하게 되는 것이다.
이렇게 메모리 로그를 남겨 문제 원인을 파악할 수 있었다.
해결
이 문제는 어떻게 해결해야 할까?
head를 읽고 head.next를 읽기 전 틈에 기존 head가 바뀌어버리는 게 문제이므로, 일단 둘 모두를 읽은 후에, head를 한번 더 읽어 처음 읽은 head와 같은지 검사하는 방법이 있다.
아직 head가 바뀌지 않았다면, 기존에 읽었던 head.next도 head가 실제로 head이던 시점에 읽은 값임을 보장할 수 있다.
(참고로 head는 tag를 포함하므로, head가 재사용되고 다시 head 위치까지 오는 ABA 문제는 예방된다.)
바뀌었으면 어떻게 하느냐? 그냥 continue로 처음부터 재시도하면 된다.
nb::TaggedPtr<Node> old_head = _head.load();
nb::TaggedPtr<Node> old_tail = _tail.load();
nb::TaggedPtr<Node> old_head_next = old_head->next.load();
// check if `old_head_next` got from `old_head` is valid
// via checking `old_head` was still current `_head`
const nb::TaggedPtr<Node> old_head_validate = _head.load();
if (old_head_validate != old_head) {
_logger.log("retry pop, head changed to:", old_head_validate);
continue;
}테스트
Lockfree Queue의 테스트는 어떻게 해야 할까?
전과 마찬가지로, 시스템 논리 프로세서 개수만큼 thread를 생성해 push()와 pop()을 한다로 시작해보자.
저장할 데이터는 (thread id, index)로 해 보자.
각 thread는 push()시, 자신의 tid와, 1씩 증가하는 index 값을 Queue에 집어넣는다.
그리고, pop()시, 꺼낸 데이터의 (tid, index)가 몇번 나왔는지 따로 보관해둔다.
그러면, 모든 thread 종료 후 결과를 취합해서, 각 tid별로 각 index 값이 정확히 1번씩만 pop()됐는지를 검사해 볼 수 있다.
또한, 각 thread가 pop()시, 여타 thread들에서 push()한 index 값들을 읽어올텐데, 그 thread별 index는 항상 증가해야 하므로, 각 thread 별로 그것도 체크한다.
참고자료
- Preshing on Programming
- Lockfree Queue
