✨ARM Instruction Set Architecture (3)
임베디드시스템설계

ARM Memory Access
Load-Modify-Store
x = x + 1;이 있을 때, x의 memory address가 x에 저장되어 있다고 가정하면
LDR r0, [r1] ; load value of x from memory
ADD r0, r0, #1 ; x = x + 1
STR r0, [r1] ; store x into memoryARM에서는 memory에 있는 data에 바로 access할 수 없고 반드시 register에 그 값을 load하고 결과 값을 store하는 과정을 거쳐야 한다.
Load Instructions
LDR rt, [rs]load instruction의 rt와 rs는 모두 register이다.
load instruction LDR은 rs에 들어있는 memory의 주소로부터 레지스터 rt로 data를 fetch한다.
; Assume r0 = 0x08200004
; Load a word:
LDR r1, [r0] ; r1 = Memory.word[0x08200004]Store Instructions
STR rt, [rs]base register rs에 들어있는 memory address로 레지스터 rt에 있는 값을 저장한다.
; Assume r0 = 0x08200004
; Store a word:
STR r1, [r0] ; Memory.word[0x08200004] = r1Single Register Data Transfer
LDR의 기본은 word이다. 그래서 아무것도 붙지 않은 LDR은 load word이다.
STR의 기본 역시 word이다. 그리고 store에서 B나 H가 붙었을 때 무조건 lower 기준이다.
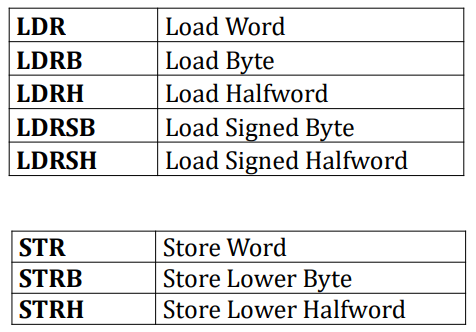
Load a Byte, Half-word, Word
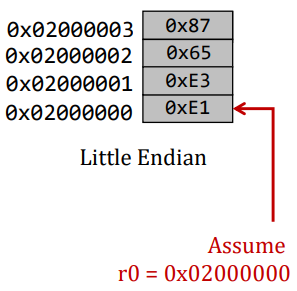 다음과 같은 경우일 때,
다음과 같은 경우일 때,
-
Load a Byte
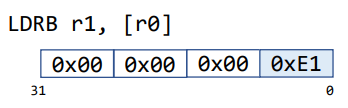
-
Load a Halfword
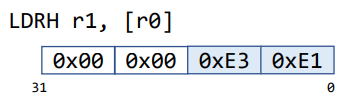
-
Load a Word

load도 lower address 기준으로 동작한다.
Sign Extension
다음과 같은 경우일 때,
-
Load a Signed Byte
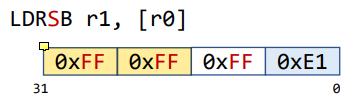
0xE1은0x11100001이므로 sign extension을 하면0xFFFFFFE1이 된다.0xE1의 최상위 bit이 1이기 때문에 빈 공간이 1로 채워지는 것. -
Load a Signed Halfword

0xE3E1은0x1110001111100001이므로 sign extension을 하면0xFFFFE3E1이 된다.0xE3E1의 최상위 bit이 1이기 때문에 모든 빈 공간이 1로 채워진다.
Address
LDR과 STR로 access되는 address는 그냥 숫자 자체로 나오는게 아니라 base register과 그에 대한 offset으로 명시된다.
word와 unsigned byte access라면 offset은
- 12-bit immediate value(상수)
LDR r0, [r1,#8]- immediate value에 의해 optionally shift된 register
LDR r0, [r1,r2] ; r2 는 offset을 나타내는 register
LDR r0, [r1,r2,LSL#2] ; r2 는 barrel shifter에 의해 shift된 offset register이 될 수 있다.
halfword와 signed byte access라면 offset은
- 8-bit immediate value
- unshift된 register
가 될 수 있다.
Addressing에서는 pre-indexed와 post-indexed 중 선택해 사용할 수 있다.
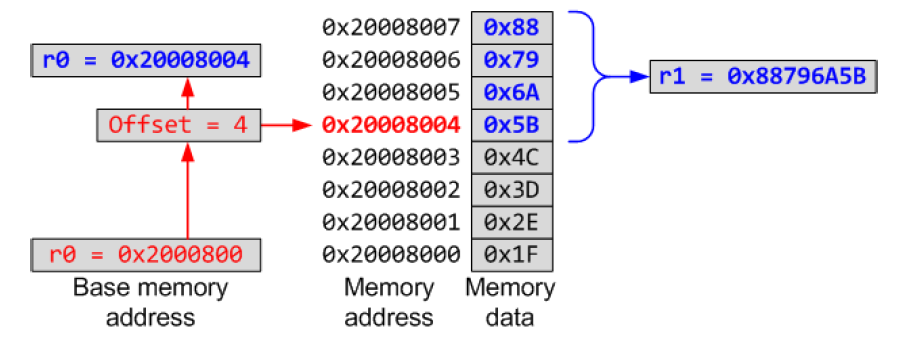
Pre-index
LDR r1, [r0, #4]base address가 담겨있는 r0로부터 offset만큼 떨어진 주소인 0x200080004에서 1 word를 읽었기 때문에 r1에는 0x88796A5B가 담긴다.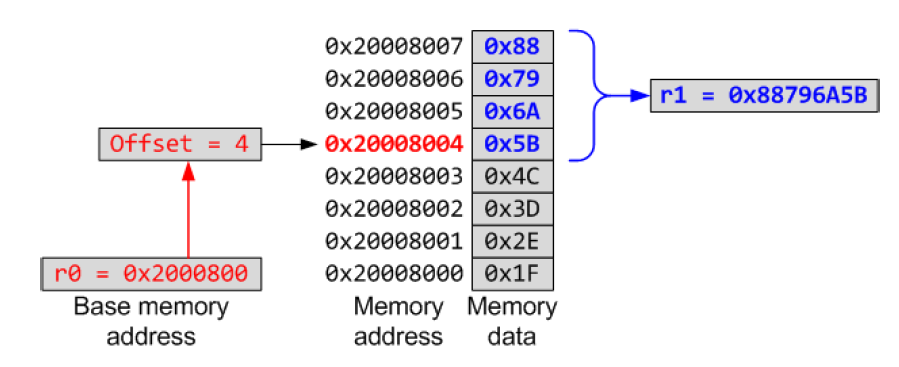
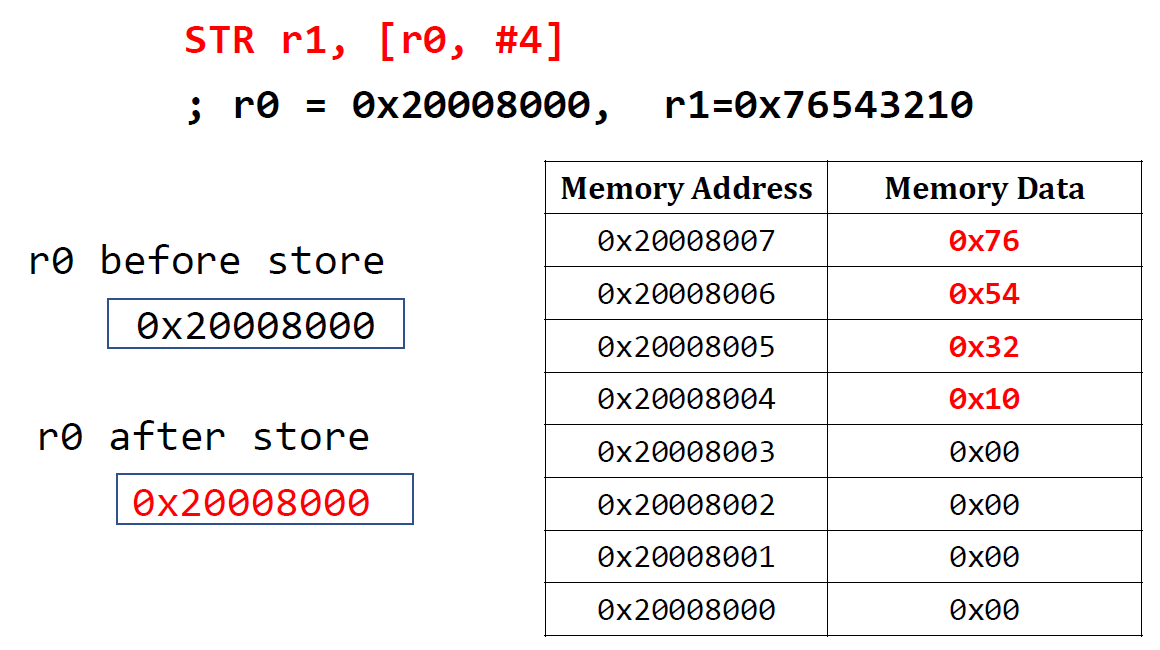
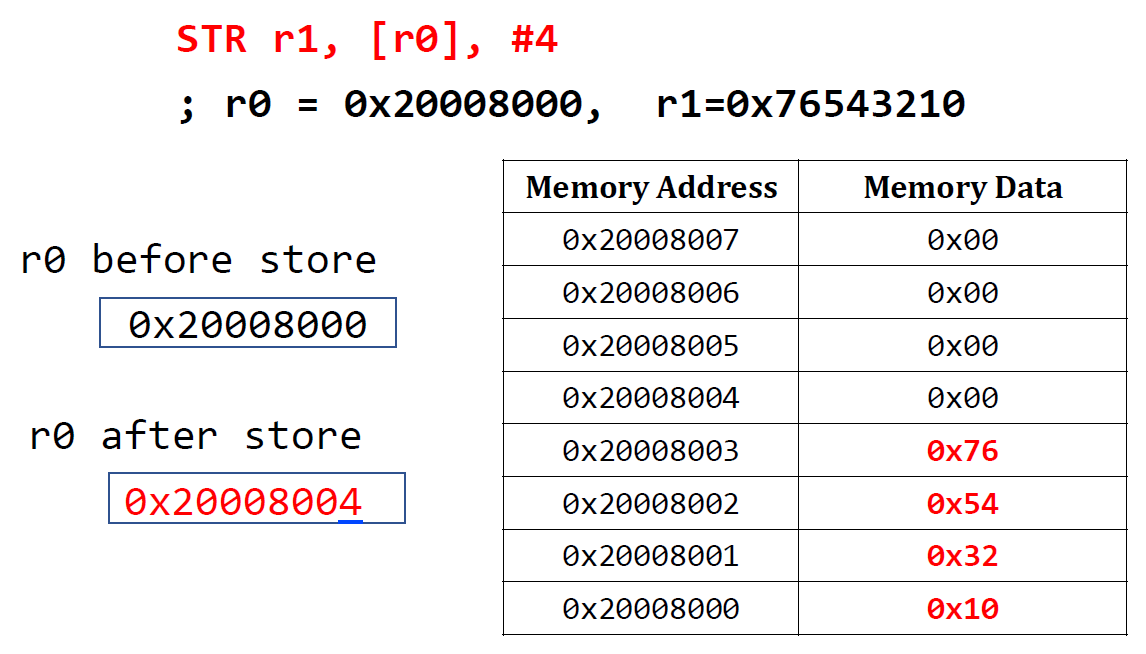
Post-index
LDR r1, [r0], #4base address가 담겨있는 r0로부터 1 word를 먼저 읽고, offset만큼 r0를 update한다.
그래서 r1는 원래 r0로부터의 1 word인 0x4C3D2E1F가 담기고 r0는 0x20008004로 update되었다.
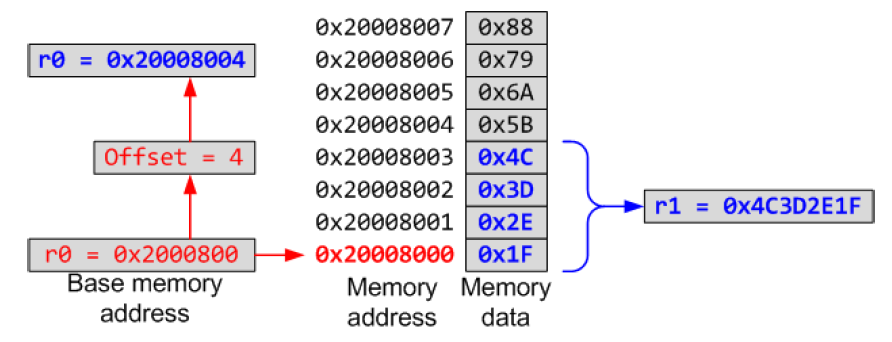
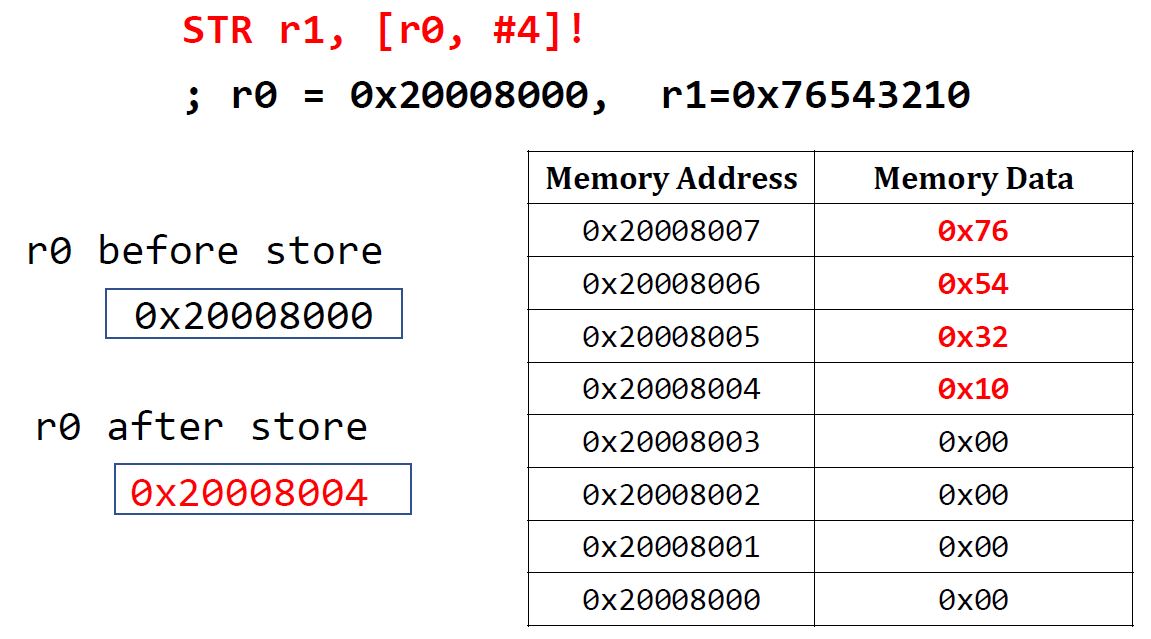
Pre-index with Updates
LDR r1, [r0, #4]![]뒤에 !을 붙이면 pre-index의 경우에도 base address가 담겨있던 r0의 값을 update하게 된다. load되는 값은 pre-index와 동일하다.
Summary of Pre-index and Post-index
정리하자면 load되는 것은
[]내부의 결과로 나오는 address로 구해진다.pre-index에서는[]안에 offset이 있었기 때문에 offset을 적용한 주소값에서 1 word를 load했고,post-index에서는[]밖에 offset이 있었기 때문에 원래 주소값에서 1 word를 구했다.

Load/Store Multiple Instructions
STMxx rn{!}, {register_list}
LDMxx rn{!}, {register_list}STM은 store multiple, LDM은 load multiple로 추정된다.
xx 자리에 다음과 같은 값을 넣을 수 있다.

IA는 1 word가 load/store된 후(after)에 address가 4 증가한다.
IB는 1 word가 load/store되기 전(before)에 먼저 address를 4 증가시킨다.
DA는 1 word가 load/store된 후(after)에 address가 4 감소한다.
DB는 1 word가 load/store되기 전(before)에 먼저 address를 4 감소시킨다.
다음과 같은 instruction이 있다고 가정해보자.
stmia r5, {r0,r1,r2}
; mem[r5] = r0
; mem[r5+4] = r1
; mem[r5+8] = r2
stmib r5, {r0,r1,r2}
; mem[r5+4] = r0
; mem[r5+8] = r1
; mem[r5+12] = r2이 두 경우는 같은 것이다.
STM==STMIALDM==LDMIA
📌STM, LDM instruction에서 나열된 register의 순서는 중요하지 않다❗
lowest number의 register가 lowest memory address에 저장된다.
stm r5, {r0,r1,r2} == stm r5, {r2,r1,r0}
Store Multiple Instructions
다음과 같은 instruction이 있다고 가정할 때,
STMxx r0!, {r3,r1,r7,r2}
xx에 따라 어떻게 동작하는지 확인해보자.
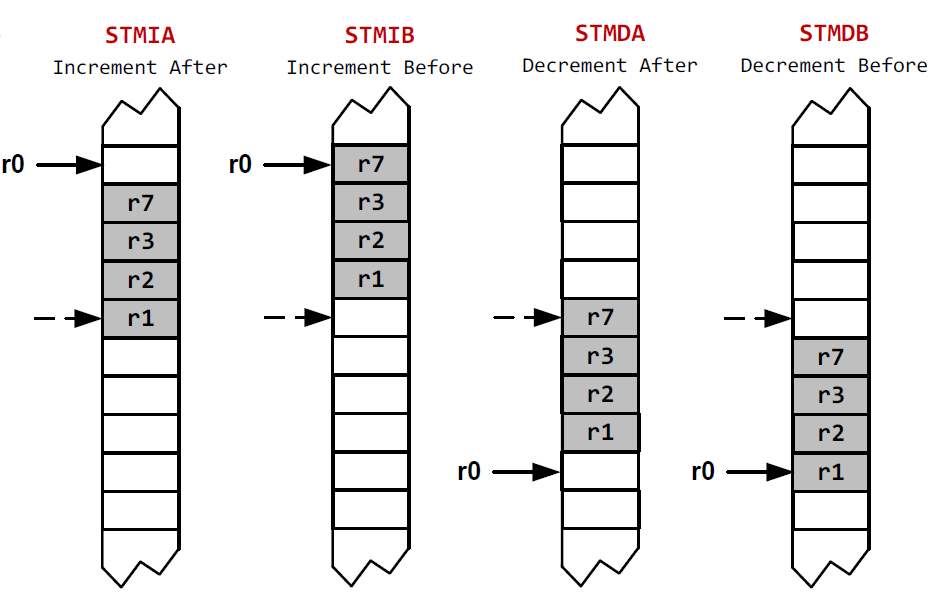
여기서 주의할 점은
DA와DB에서 lowest address의 값이 lowest register에 load된다는 것이다. 연산되는 순서대로 레지스터에 값이 들어가는 것이 아니다.
Load Multiple Instructions
다음과 같은 instruction이 있다고 가정할 때,
LDMxx r0!, {r3,r1,r7,r2}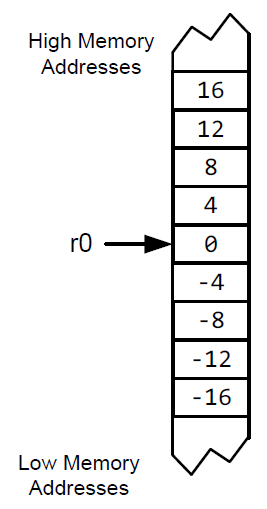
xx에 따라 어떻게 동작하는지 확인해보자.
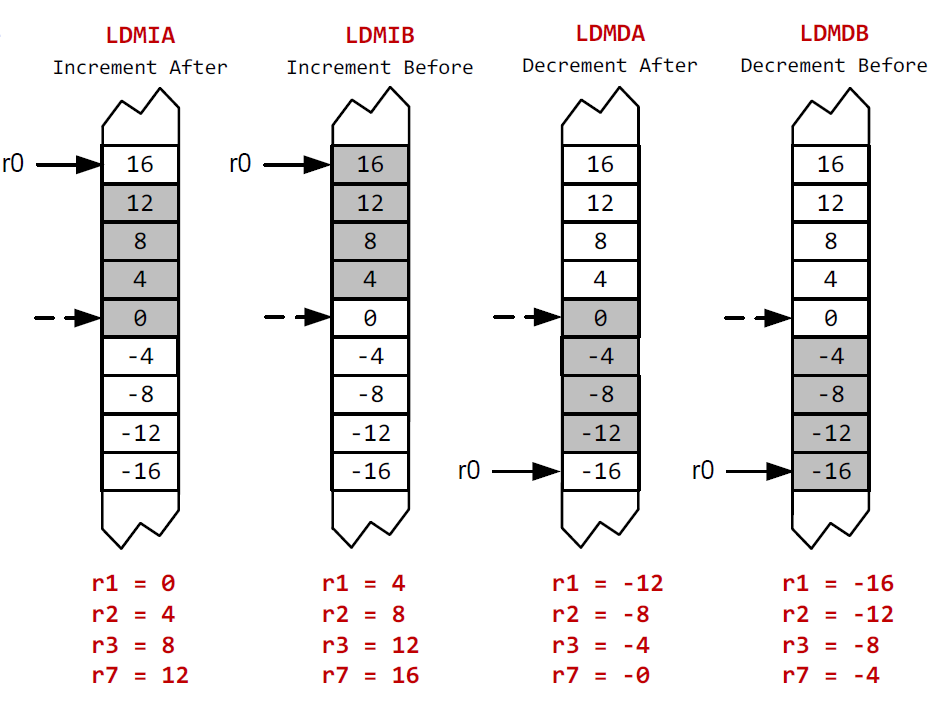
여기서 주의할 점은
DA와DB에서 lowest address의 값이 lowest register에 load된다는 것이다. 연산되는 순서대로 레지스터에 값이 들어가는 것이 아니다.
ARM 32-bit Load Pseudo-op
LDR에서 operand는 memory address나 large constant가 될 수 없다.
LDR r3, =0x55555555 ; place 0x55555555 in r3다음과 같이 사용할 수 없다..0x55555555는 32-bit constant나 symbol이 되어야한다. 이것은 instruction에서 destination을 나타낼 수 있는 bit 수가 한정되어있기 때문이다.
위와 같은 경우에서는 만약 immediate constant를 찾을 수 있다면 MOV instruction을 사용한다.
그럴 수 없다면 constant를 literal pool에 넣어 사용한다.
LDR r3, [PC, #offset]
...
...
...
.word 0x55555555 ; in literal pool following code'어셈블러는 distance를 계산할 수 있기 때문에 PC-relative offset을 구해낼 수 있다.
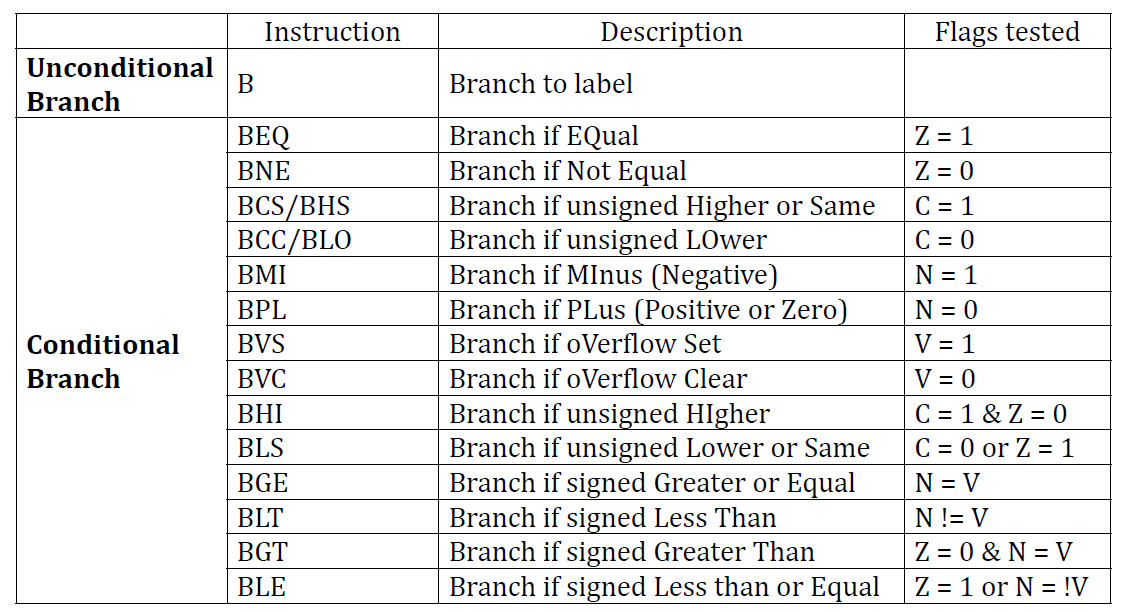
ARM Flow Control
Branch Instructions

B label:label로 branch한다.BL label: 다음 instruction의 주소를r14(lr, link register)에 넣고label로 branch한다.BX Rm:Rm레지스터에 들어있는 address로 branch한다.BLX Rm: 다음 instruction의 주소를r14(lr, link register)에 넣고Rm레지스터에 들어있는 address로 branch한다.
Branch With Link
branch with link(BL) instruction은 next instruction의 주소를 LR에 넣어서 subroutine call을 구현한다.
PC에 LR에 들어있는 값을 restore하기만 하면 subroutine으로부터 return할 수 있다.
MOV pc, lr == BX lr (PC레지스터에는 next instruction의 주소가 담겨있다)
다음과 같이 사용할 수 있다.
bl foo
<A>
...
foo:
...
bx lr ; <A>의 위치부터 실행을 재개함
📌일반 branch instruction(B)는 LR에 영향을 미치지 않는다❗
Condition Codes
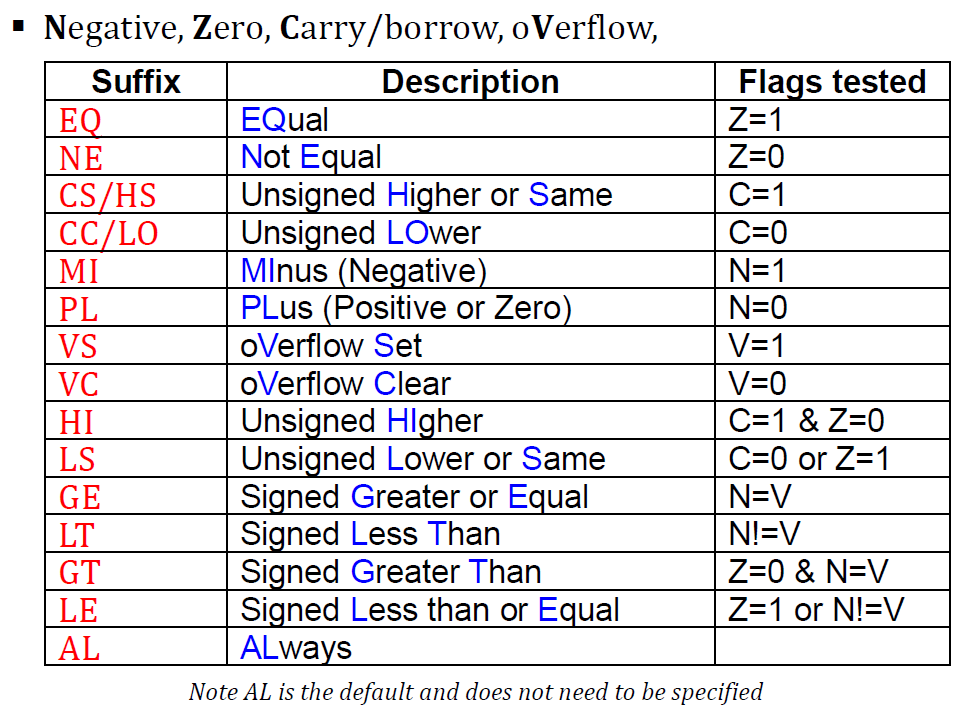
Conditional Branch Instructions
condition code 앞에 B만 붙은 형태이다.
condition code의 조건을 만족하면 branch하는 형태이다.
Comparison Instructions
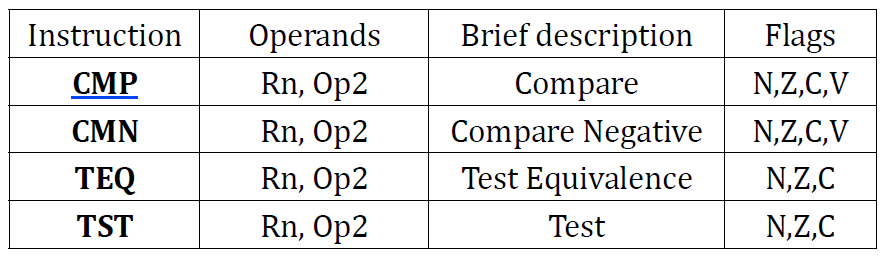 comparison instruction은 condition flag를 update하는 것 밖에 없다. 그 이외에 다른 것은 하지 않는다. 비교의 결과 역시 저장되지 않는다.
comparison instruction은 condition flag를 update하는 것 밖에 없다. 그 이외에 다른 것은 하지 않는다. 비교의 결과 역시 저장되지 않는다.
CMP r0, r1 ; condition flag update됨, r0의 값은 변하지 않음
SUBS r0, r1 ; condition flag update됨, r0 = r0 - r1CMP and CMN
CMP{cond} Rn, Operand2
CMN{cond} Rn, Operand2-
CMP는Rn - Operand2를 수행한다.SUBS와 동일하게 동작하지만 연산 결과는 버린다 (condition flag만 update함). -
CMN은Rn + Operand2를 수행한다.ADDS와 동일하게 동작하지만 연산 결과는 버린다 (condition flag만 update함).
이 instruction들은 N, Z, C, V flag를 연산 결과에 따라 update한다 (결과만 버려짐).
TST and TEQ
TST{cond} Rn, Operand2 ; Bitwise AND
TEQ{cond} Rn, Operand2 ; Bitwise Exclusive OR-
TST는Rn & Operand2를 수행한다.ANDS와 동일하게 동작하지만 연산 결과는 버린다 (condition flag만 update함). -
TEQ는Rn ^ Operand2를 수행한다.EORS와 동일하게 동작하지만 연산 결과는 버린다 (condition flag만 update함).
이 instruction들은 N, Z flag를 연산 결과에 따라 update한다 (결과만 버려짐).
경우에 따라 Operand2를 계산하면서 C flag를 update할 수는 있지만 V flag를 바꾸지는 않는다.
If-then Statement
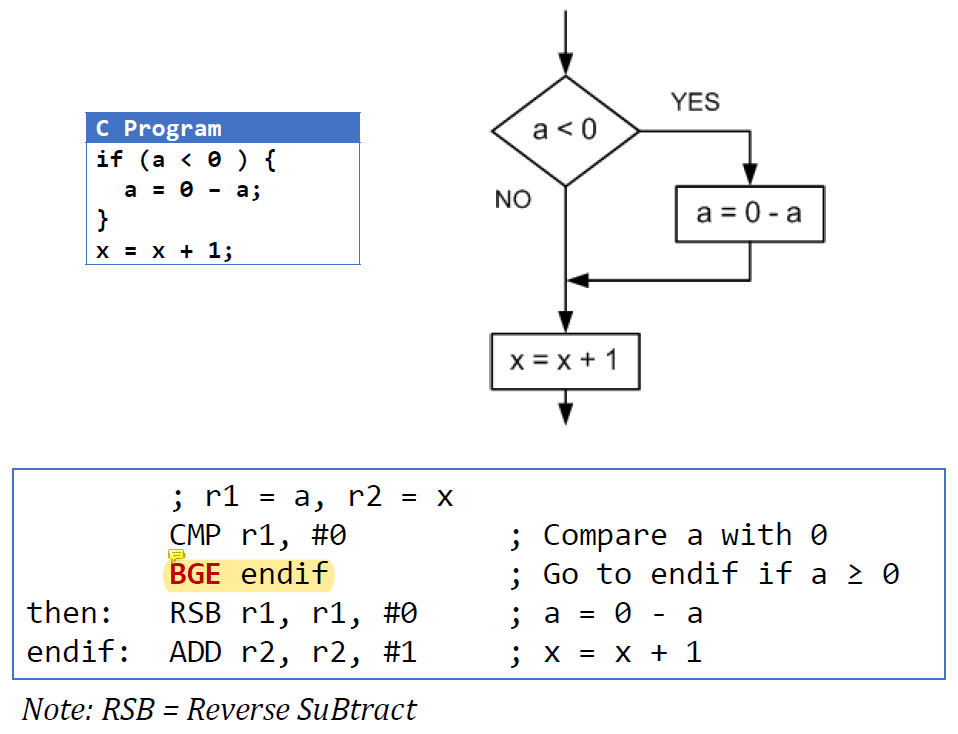
CMP를 실행하면 r1 - 0을 수행해서 그 결과에 따라 condition flag가 update된다.
그리고 그 condition flag를 보고 BGE에 해당하는지 확인한다.
BGE는 r1 >= 0일 때 branch할 것이다.
instruction의 대소비교는 모두 operand1 기준이다.
Compound Boolean Expression
 아름답네...
아름답네...
If-then-else
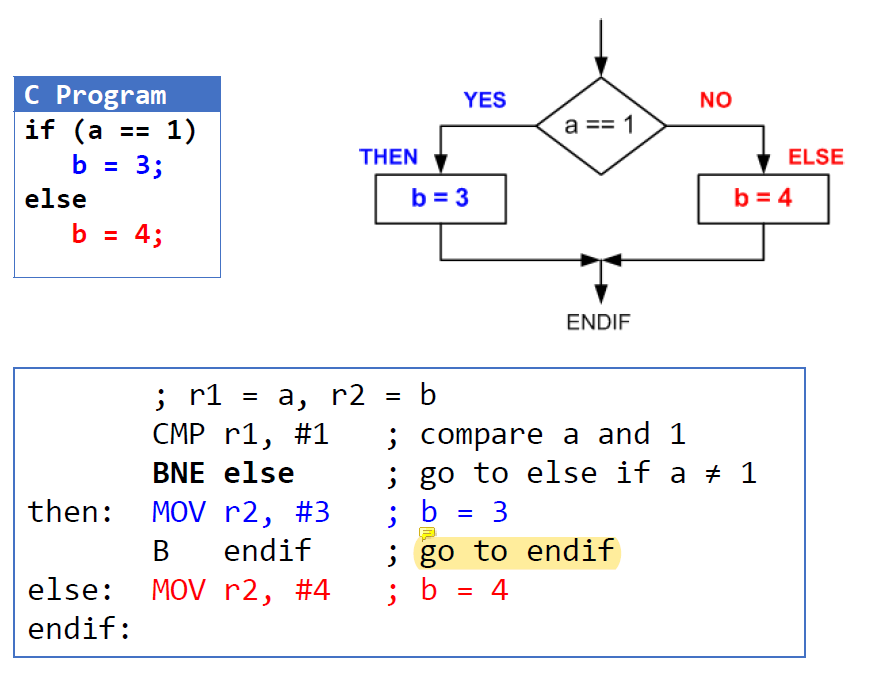 어셈블리도 다른 언어들처럼 다르게 표현할 수 있다.
어셈블리도 다른 언어들처럼 다르게 표현할 수 있다.
아래의 어셈블리 식도 결론적으로는 같은 동작을 한다. 순서가 살짝 다를 뿐이다.
; r1 = a, r2 = b
CMP r1, #1
BEQ then
else: MOV r2, #4
B endif
then: MOV r2, #3
endif:For Loop
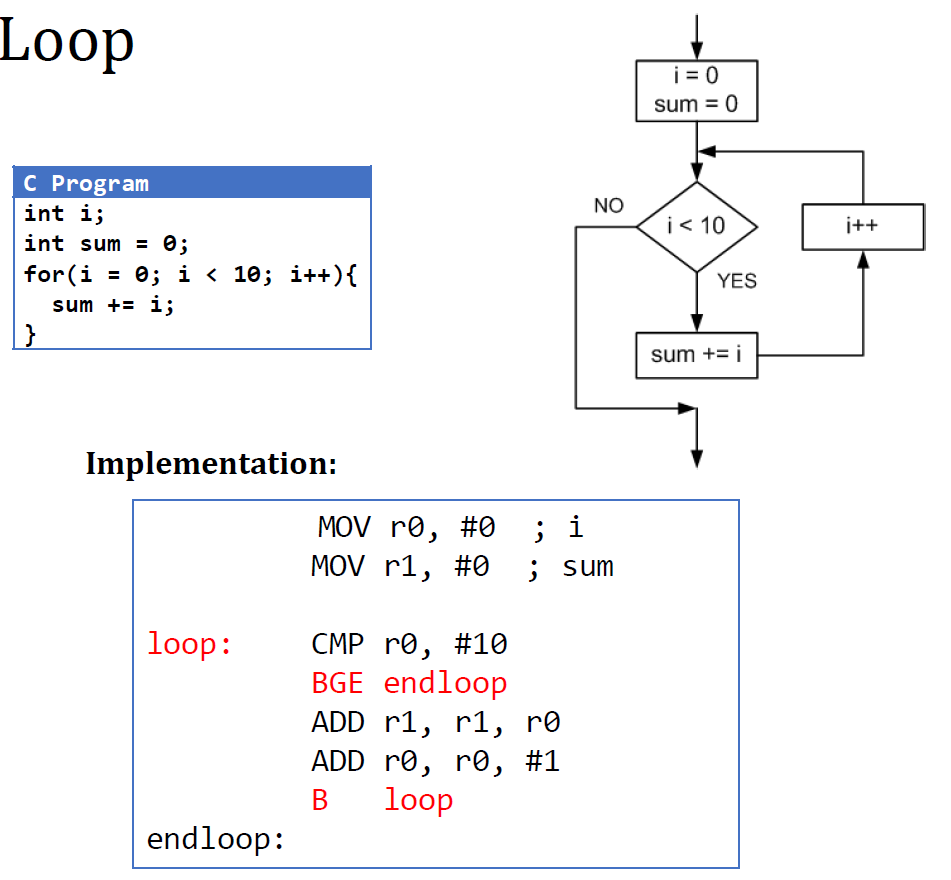
ARM instruction이기 때문에 ADD의 operand가 3개가 됨에 유의하자.
ADD r1, r0은 thumb instruction의 표기법이다.
Conditional Execution
condition code 앞에 ADD가 붙은 형태이다.
해당 조건을 만족할 때 ADD를 하겠다는 의미이다.
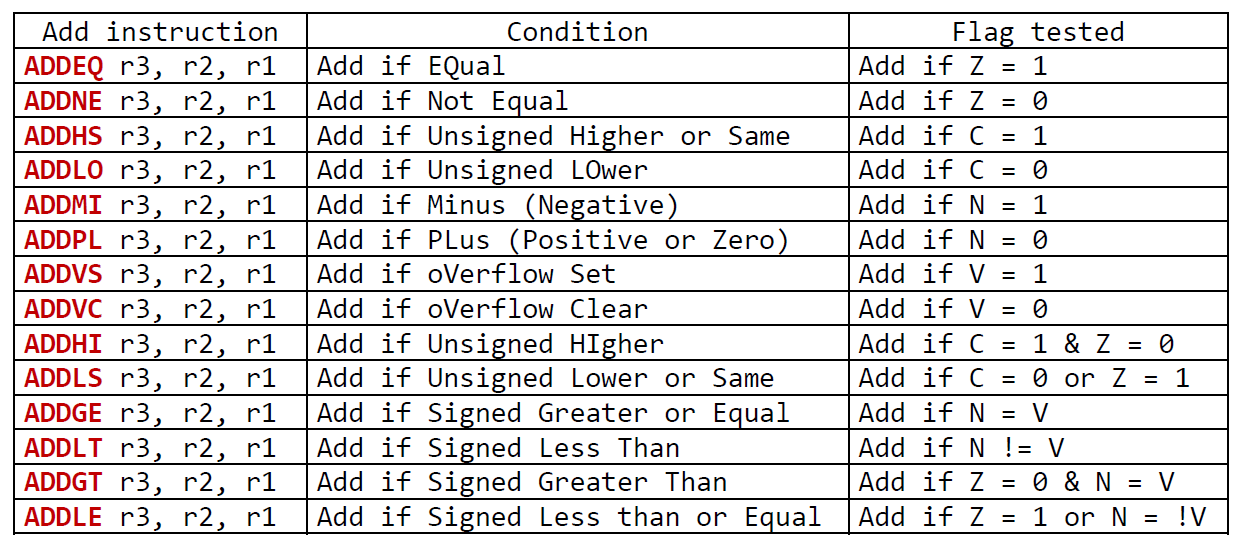
Example of Conditional Execution
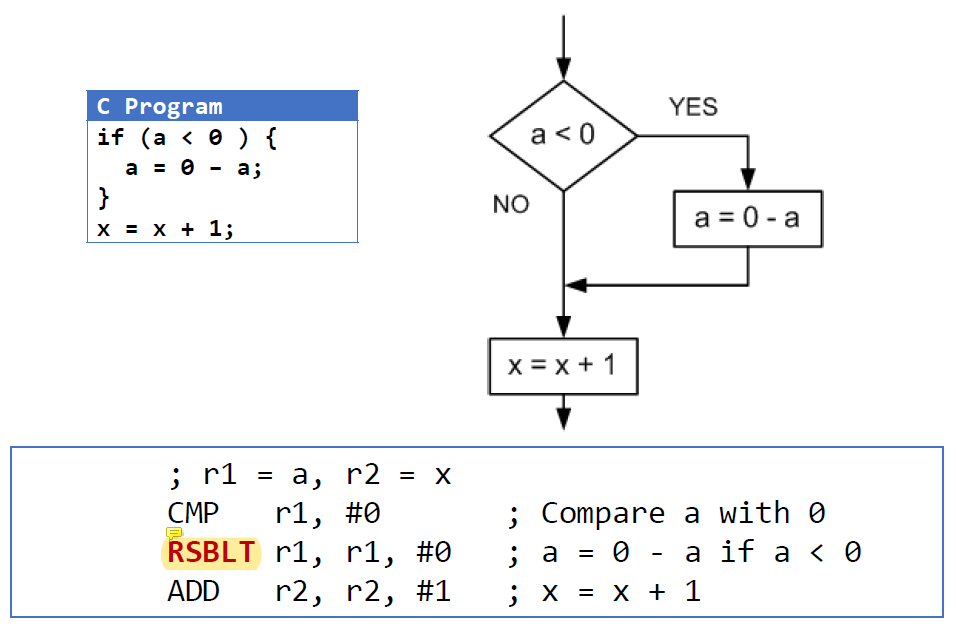 혁명이다 이거는..
혁명이다 이거는..
기존의 코드를 보자.
; r1 = a, r2 = x
CMP r1, #0
BGE endif
then: RSB r1, r1, #0
endif: ADD r2, r2, #1LT앞에 RSB를 붙여서 LT일 때만, 즉 r1 < 0일 때만 RSB를 실행하면서 instruction의 수를 줄일 수 있었다.
clock cycle을 아껴서 다른 instruction을 실행할 수 있는 것이다.
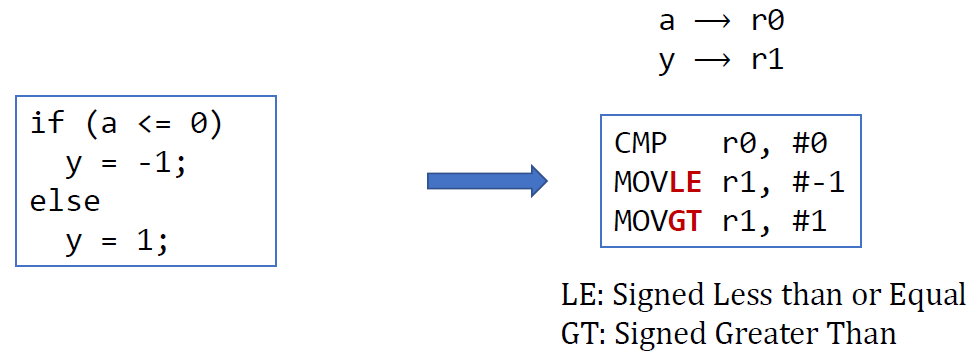 위의 경우에도 instruction의 수를 줄일 수 있다.
위의 경우에도 instruction의 수를 줄일 수 있다.
기존의 방법대로 표현해보자.
; r0 = a, r1 = y
CMP r0, #0
BGT else
then: MOV r1, #-1
B endif
else: MOV r1, #1
endif:MOVLE와 MOVGT를 통해 instruction의 수를 2개나 줄일 수 있게 되었다.
Compound Boolean Expression
 위의 instruction도 원래는 다음과 같이 표현했었다.
위의 instruction도 원래는 다음과 같이 표현했었다.
; r0 = x, r1 = a
CMP r0, #20
BLE then
CMP r0, #25
BLT endif
then: MOV r1, #1
endif:insturction의 개수를 1개 아낄 수 있었다.
 조건문의 boolean expression의 개수가 늘어날 수록 아낄 수 있는 instruction의 수가 늘어난다.
조건문의 boolean expression의 개수가 늘어날 수록 아낄 수 있는 instruction의 수가 늘어난다.
; r0 = a, r1 = y
CMP r0, #1
BEQ then
CMP r0, #7
BEQ then
CMP r0, #11
BNE else
then: MOV r1, #1
B endif
else: MOV r1, #-1
endif:원래는 이렇게 총 9개의 instruction으로 표현되었어야 할 if문을 5개의 instruction으로 줄일 수 있다. 무려 4개의 clock cycle을 아꼈다❗
위의 예시는 더욱 더 아름답다...
맨 처음의 CMP에서 r0 == 1인 경우, Z flag를 1로 set하면서 아래의 CMPNE가 자동으로 무시된다. 즉 운이 나쁘면 모든 CMP, CMPNE문을 실행하겠지만 운이 좋다면 3개를 전부 다 실행하지 않고 건너뛸 수 있다는 의미이다. 매우 효율적이라고 할 수 있다.
Combination
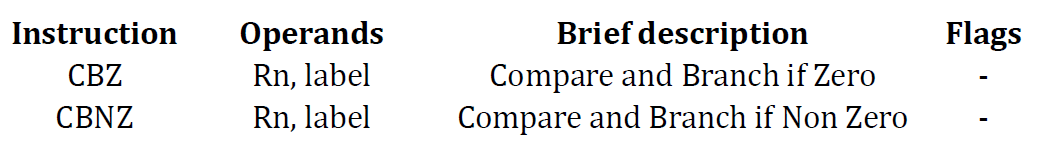 combination은 compare와 branch를 합친 형태이다.
combination은 compare와 branch를 합친 형태이다.
assembly instruction을 보면 compare를 하고 난 후 필연적으로 branch instruction이 나오게 되어있다. 따라서 이 두 개를 합친다면 많은 경우 두 instruction을 하나로 줄일 수 있게 된다.
** 1. CBZ **
CMP Rn, #0
BEQ label
; is equivalent to
CBZ Rn, label
** 2. CBNZ **
CMP Rn, #0
BNE label
; is equivalent to
CBNZ Rn, label
IT(If-then) Instruction
ARM instruction set과 Thumb instruction set 모두 conditional execution을 지원하지만
- ARM instruction set에서 condition은 그 instruction 내부에 embedded된다.
- Thumb instruction set에서 condition은 instruction 내부에 embedded될 수 없다, instruction의 길이가 짧아 사용할 수 있는 bit이 얼마 없기 때문이다.
UAL(unified assembly language, thumb2에 사용됨, 여기 참고)을 위해 thumb mode에서 conditional execution은 IT를 통해 implement된다.
IT{x{y{z}}} {cond}여기서 x, y, z는 optional conditional instruction이 더 있음을 나타낸다. x, y, z는 T(Then) 혹은 E(Else)가 될 수 있다.
만약 ITTTE라면 If-Then-Then-Then-Else이다.
좀 대환장파티다.
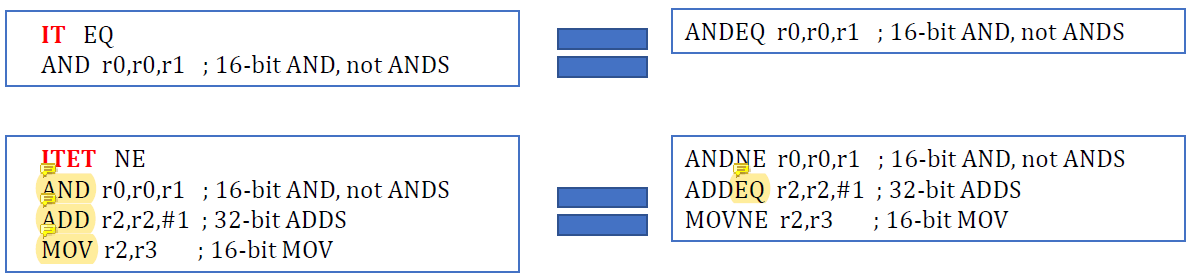
IT{x{y{z}}}가 있으면 그 뒤에 instruction들이 각각에 걸린다고 생각하면 된다.
1.
IT EQ ; if에 해당됨
AND r0, r0, r1 ; then에 해당됨, 위의 if문의 조건에 해당하면 실행
2.
ITET NE ; if에 해당됨
AND r0, r0, r1 ; then에 해당됨, 뒤의 if문의 조건에 해당하면 실행
ADD r2, r2, #1 ; else에 해당됨, if문의 조건에 해당되지 않으면 실행
MOV r2, r3 ; then에 해당됨, 위의 else 조건을 충족하면 실행여기서 주목할 점은 ITET 예제에서 ADD가 ADDEQ가 되었다는 점이다.
NE가 아닐 때 실행되는 것이기 때문에 NE의 반전된 형태인 EQ를 사용하고 있다.
IT instruction은 Thumb mode에서만 사용할 수 있다.
