✨ARM Interrupts (2)
임베디드시스템설계

Pending Status
Interrupt Inputs and Pending Behavior
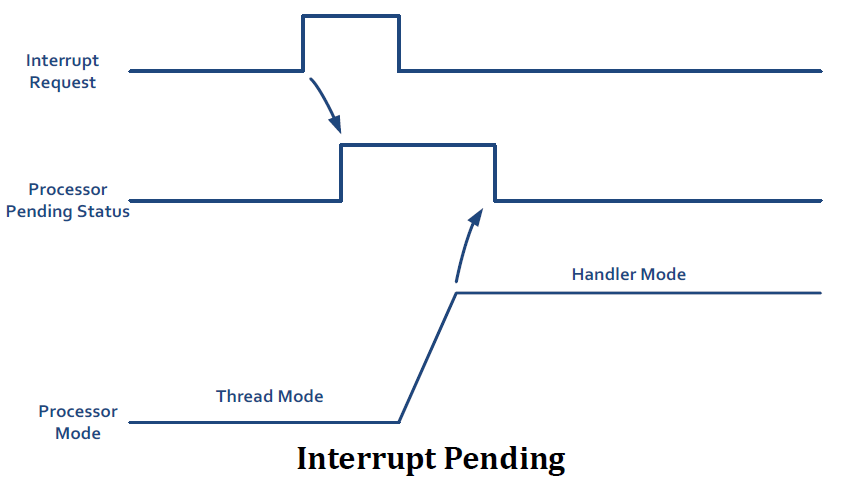 interrupt가 assert되었을 때 interrupt는 pending될 수 있다.
interrupt가 assert되었을 때 interrupt는 pending될 수 있다.
interrupt-set-pending-register(SETPEND)가 pending status를 담고 있다.
interrupt source가 interrupt를 de-assert하더라도 pended interrupt status는 interrupt handler가 실행되도록 한다.
assert는 raise정도의 의미를 가진듯?
interrut request signal이 사라져도 pending status가 유지돼서 interrupt handler가 실행된다.. 그런 의미인듯.
processor가 pended interrupt에 응답하기 전에 pending status가 clear되면 interrupt는 cancel될 수 있다.
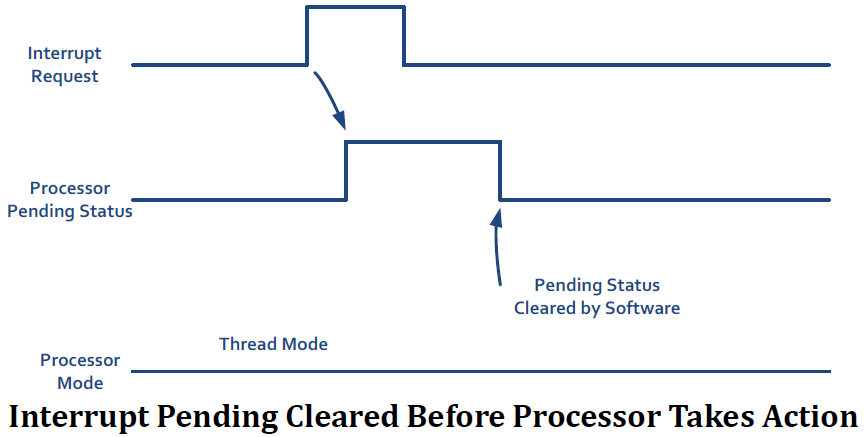 pending status는 handler가 시작되면 자동으로 clear된다.
pending status는 handler가 시작되면 자동으로 clear된다.
software interrupt를 발생시키기 위해 pending status를 이용할 수 있다 (의도적으로 generate할 수 있다는 뜻인듯).
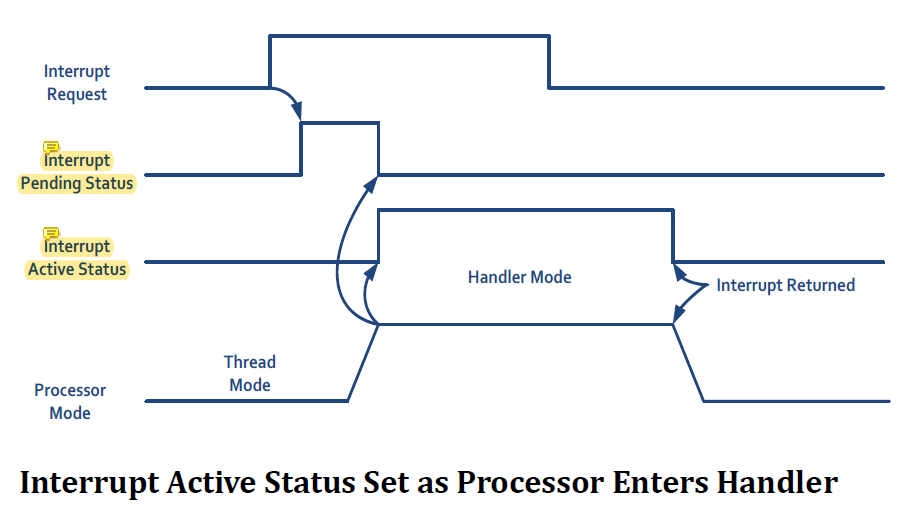 processor가 interrupt 실행을 시작하면 interrupt가 active된다.
processor가 interrupt 실행을 시작하면 interrupt가 active된다.
interrup가 active되면 pending signal은 자동으로 clear된다.
processor가 interrupt pending status bit을 보고 interrupt를 handling하기 시작하면 active state가 되고 handler가 끝나면 active status가 clear된다.
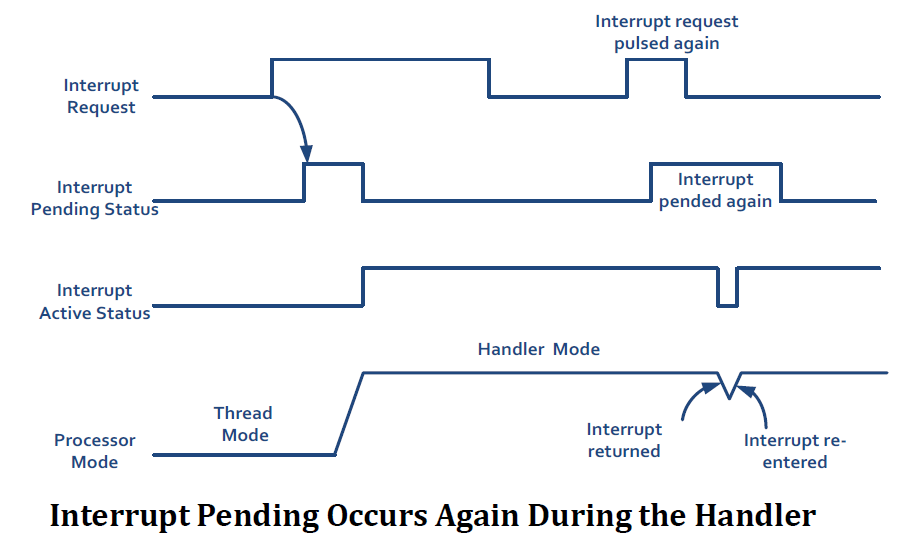
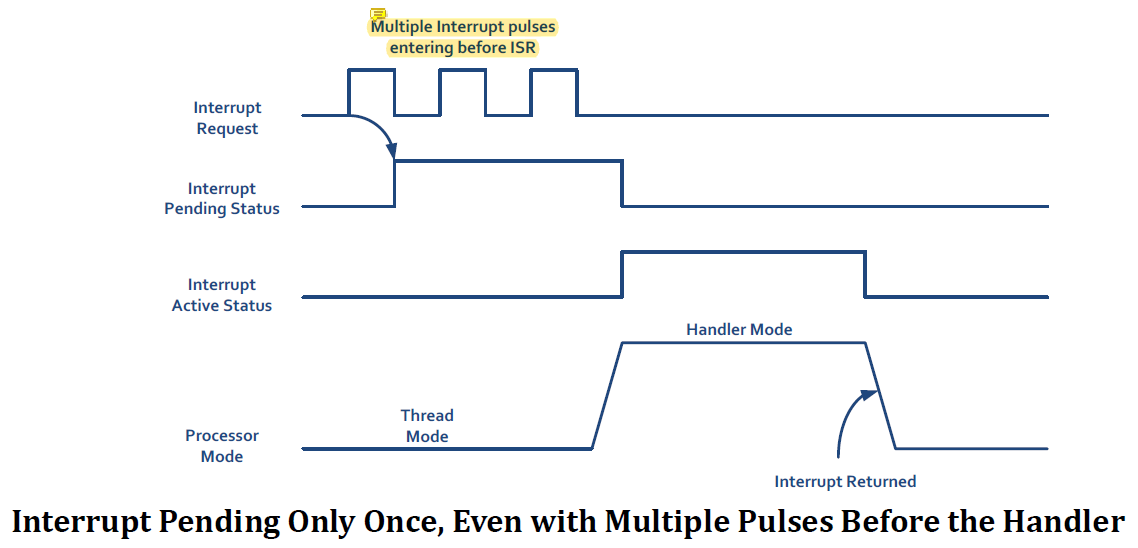 processor가 interrupt를 processing하기 전에 interrupt가 여러 번 pulse되면 하나의 single interrupt request로 처리한다.
processor가 interrupt를 processing하기 전에 interrupt가 여러 번 pulse되면 하나의 single interrupt request로 처리한다.
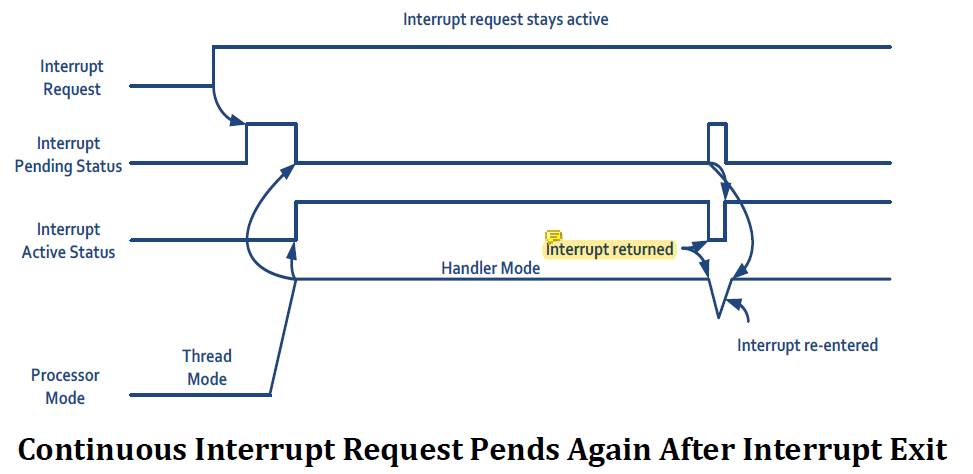 만약 한 interrupt source가 계속해서 interrupt request signal을 active로 유지하면 interrupt는 interrupt service routine이 끝날 때까지 다시 pend된다.
만약 한 interrupt source가 계속해서 interrupt request signal을 active로 유지하면 interrupt는 interrupt service routine이 끝날 때까지 다시 pend된다.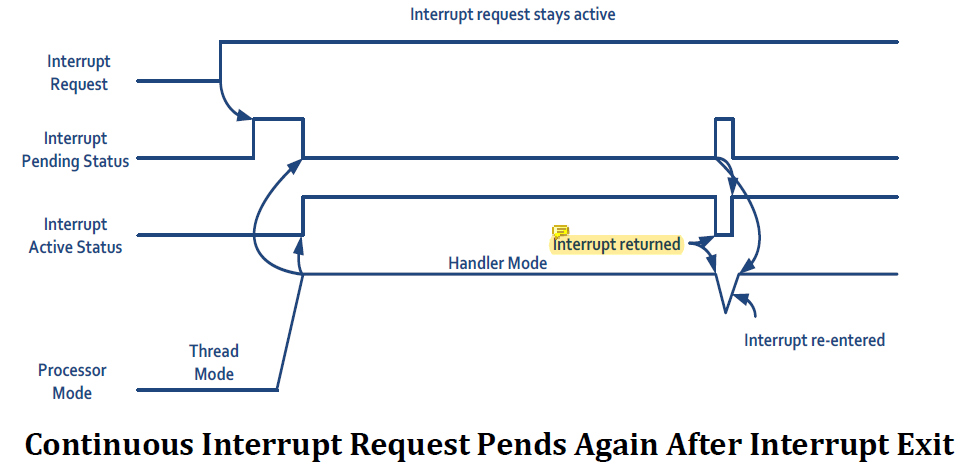 같은 interrupt signal이 여러 번 들어온거면 한 interrupt로 취급할텐데 interrupt request signal이 그 interrupt를 handle하는게 끝날 때 까지도 계속 active하니까 interrupt가 return되었을 때 잠시 pending status가 올라갔다가 다시 같은 interrupt를 handle하는 것..
같은 interrupt signal이 여러 번 들어온거면 한 interrupt로 취급할텐데 interrupt request signal이 그 interrupt를 handle하는게 끝날 때 까지도 계속 active하니까 interrupt가 return되었을 때 잠시 pending status가 올라갔다가 다시 같은 interrupt를 handle하는 것..
interrupt가 de-assert되고 interrupt service routine 도중에 다시 pulse된다면 다시 pend된다.
 interrupt service routine 도중에 같은 interrupt request signal이 들어온다면 그건 pending 했다가 나중에 다시 handle해주는 것.
interrupt service routine 도중에 같은 interrupt request signal이 들어온다면 그건 pending 했다가 나중에 다시 handle해주는 것.
interrupt handling이 시작되기 전에 여러 번 들어온 signal은 퉁쳐서 하나로 취급했지만 handling 하는데 또 들어온 신호는 무시하지 않는다.
Nested Interrupts
NVIC는 nested interrupt를 지원한다.
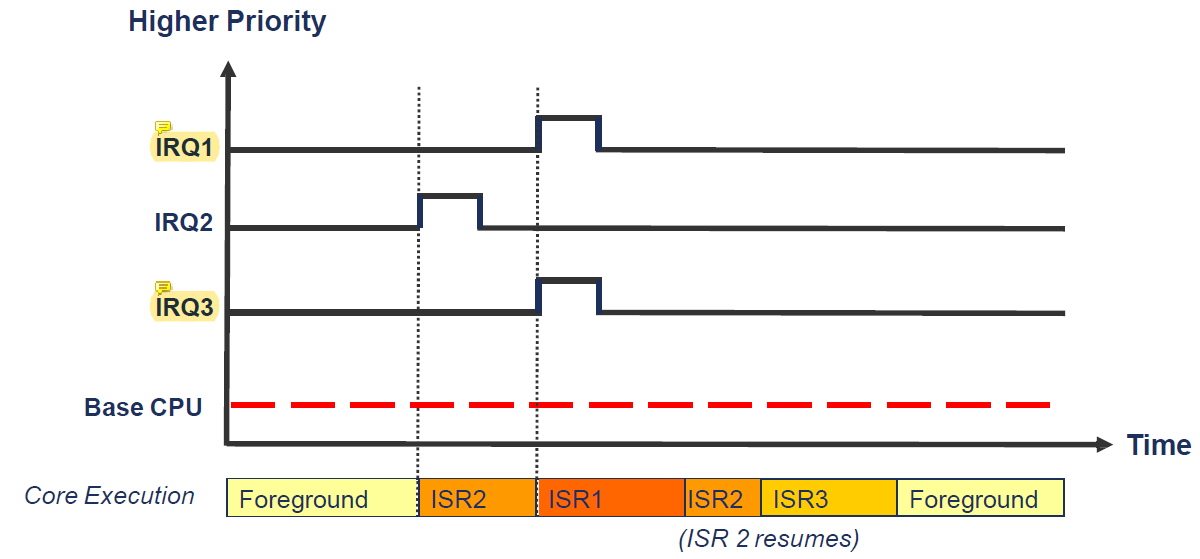 어떤 interrupt가 handling되고 있는 도중에 새로운 interrupt가 들어왔는데 우선순위가 더 높다면 우선순위가 높은 interrupt를 우선적으로 처리한다.
어떤 interrupt가 handling되고 있는 도중에 새로운 interrupt가 들어왔는데 우선순위가 더 높다면 우선순위가 높은 interrupt를 우선적으로 처리한다.
Interrupt Response
Tail Chaining
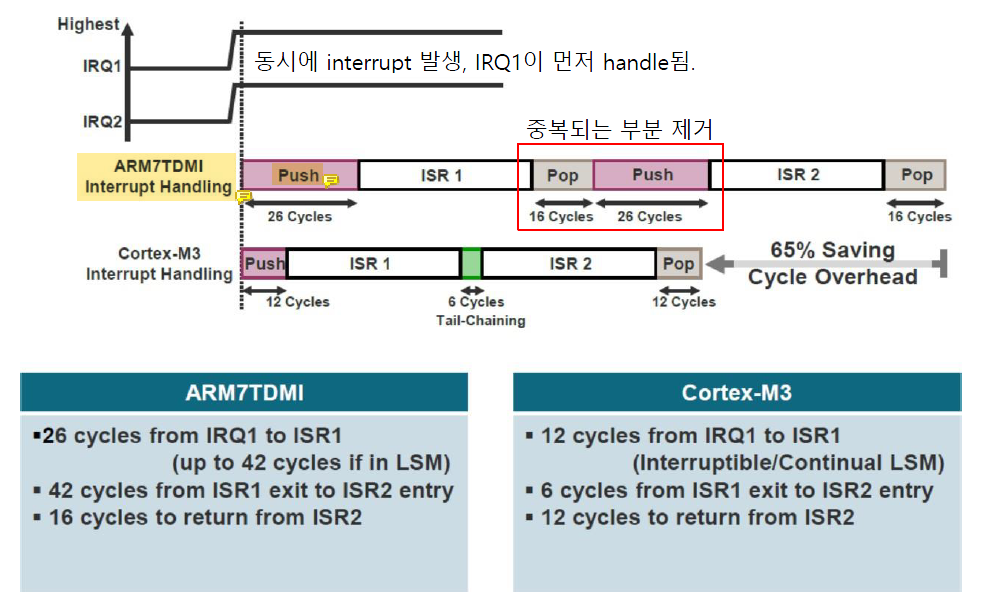 processor는 stacking과 unstacking 과정을 생략하고 pended exception의 exception handler로 최대한 빨리 진입한다.
processor는 stacking과 unstacking 과정을 생략하고 pended exception의 exception handler로 최대한 빨리 진입한다.
두 interrupt IRQ1과 IRQ2 사이에 그 어떤 instruction도 실행하지 않기 때문에 ISR 1 실행을 위해 한 번 stacking한 상태에서 ISR 1 실행이 끝났을 때 unstacking했다가 곧바로 ISR 2를 위해 다시 stacking하게 된다.
어차피 stacking/unstacking 하는 레지스터의 값이 변하지 않으므로 중간의 unstacking-stacking 과정을 생략하면 cycle을 아낄 수 있다.
Late Arriving
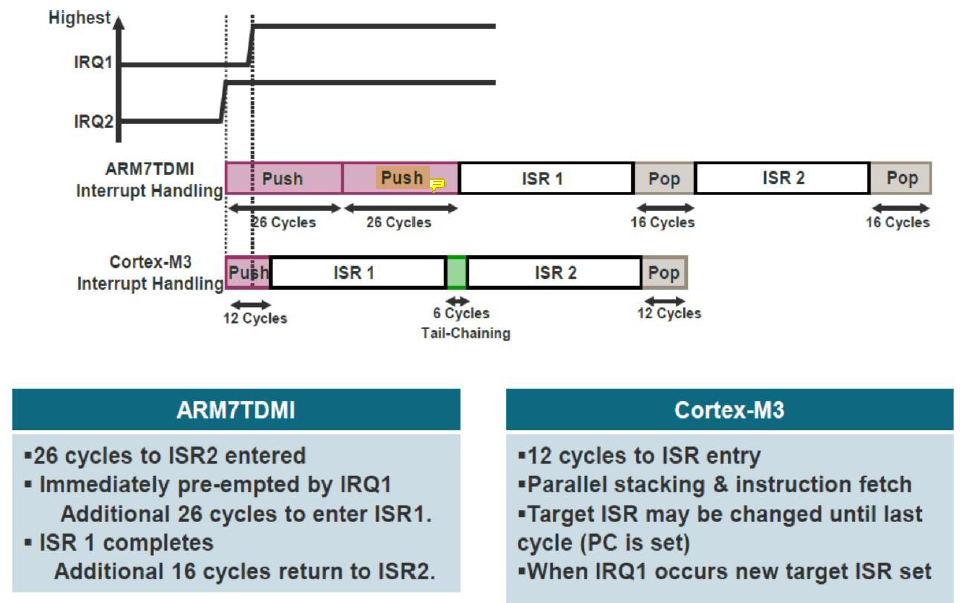 현재 interrupt의 stacking opration 도중 더 높은 priority를 가진 interrupt가 도착하면 늦게 도착했더라도 높은 priority의 interrupt가 먼저 service된다.
현재 interrupt의 stacking opration 도중 더 높은 priority를 가진 interrupt가 도착하면 늦게 도착했더라도 높은 priority의 interrupt가 먼저 service된다.
IRQ2가 먼저 도착했기 때문에 ISR 2를 위한 stacking이 진행되고 있을 때 IRQ1이 도착한다면 이전에는 ISR 2를 위한 stacking을 마저 하고 ISR 1을 위한 stacking을 한 번 더 진행한 뒤 ISR 1을 실행하였다.
하지만 두 stacking의 내용은 같기 때문에 굳이 두 번의 stacking을 수행하는 것은 불필요하다.
따라서 ISR 2를 위해 진행하던 stacking을 마저 한 다음 그것으로 ISR 1을 실행한다.
그리고 ISR 1와 ISR 2사이는 위에서 설명했던 tail-chaining을 이용하면 cycle을 아낄 수 있다.
Pop Pre-emption
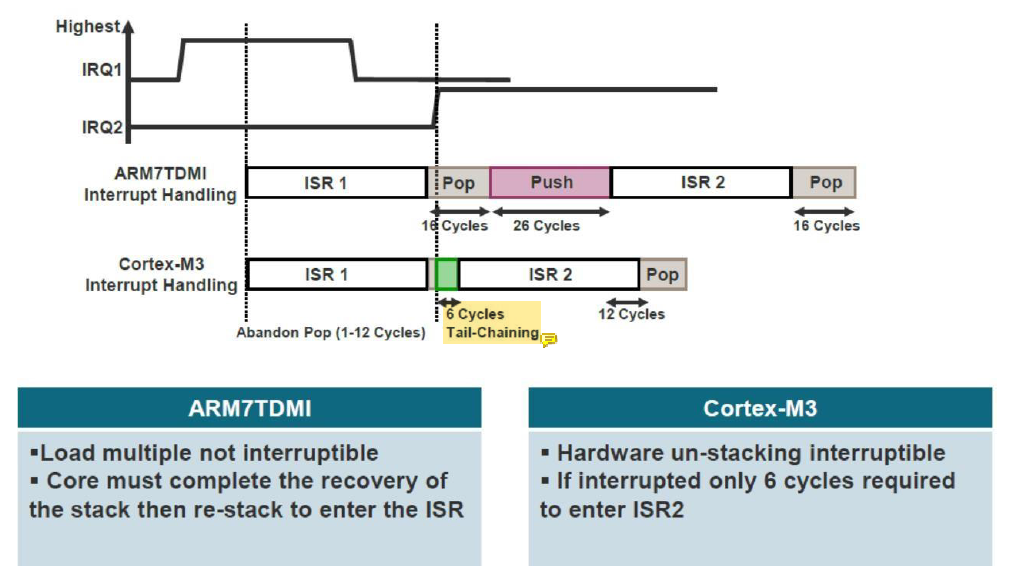 만약 unstacking을 하고 있었는데 다른 exception이 발생하면 unstacking하고 있던 것은 버려지고 새로운 exception을 service한다.
만약 unstacking을 하고 있었는데 다른 exception이 발생하면 unstacking하고 있던 것은 버려지고 새로운 exception을 service한다.
ISR 1의 실행이 끝나고 unstacking하는 도중에 새로운 exception이 도착해서 unstacking 하던 것을 취소하고 tail-chaining을 사용해 ISR 2를 실행하는 것을 볼 수 있다.
Faults and Supervisor Call Exceptions
Hard Faults
usage fault, bus fault, memory management fault가 handle되지 않았을 때 발생한다.
예를 들면 bus fault로 인해 vector table을 fetch하지 못했다던가..
hard fault status register로 이를 나타낸다.
Bus Faults
bus fault는 AHB interface에서 transfer를 하는 도중에 error response를 받았을 때 발생한다.
prefetch abort, data abort, stacking error, unstacking error, reading of an interrupt vector address error 등..
bus를 통한 transaction에 문제가 생기는 경우다.
bus fault status register로 이를 나타낸다.
bus fault는
- invalid memory region에 access하려고 시도하거나
- 아직 ready되지 않은 target device에 접근을 시도하거나
- 지원되지 않는 transfer size나 privilege level을 가진 target device에 접근을 시도하는 경우
발생한다.
Memory Management Faults
common memory manage fault는 memory management fault status regsiter로 나타내어진다.
memory access violation과 관련이 있다.
memory management fault는
MPUsetup에서 정의되지 않은 memory region에 접근하거나- nonexecutable memory region의 코드를 실행하거나
- read-only region에 값을 쓰거나
- user state로 privileged access only로 define된 영역에 접근하려고 하는 경우
발생한다.
Usage Faults
usage fault는 usage fault status register로 나타내진다.
usage fault는
- undefined instruction인 경우 (interrupt의 description을 찾을 수 없다던가)
- coprocessor instruction인 경우 (Cortex-M3은 coprocessor를 지원하지 않음)
- ARM state로 switch하려고 하는 경우 (LSB를 0으로 바꾸려고 하는 경우)
- invalid interrupt return
- multiple load/store에서 memory access가 unalign 되어있는 경우
- active interrupt가 있는데 thread mode로 return하는 경우 (handler mode로 return해야 하는듯)
발생한다.
NVIC의 특정 control bit을 set해서 divide by zero, 모든 unaligned memory access에 대해서 usage fault를 발생시킬 수도 있다.
Dealing with Faults
fault status regsiter를 통해 어떤 fault가 발생했는지 확인하고 어떤 행동을 취할지 알아낼 수 있다.
만약 OS가 존재한다면 OS가 offending task를 종료할 수 있다.
OS가 없다면
-
Reset
시스템을 reset한다.
application interrupt and reset control register(AIRCR)의VECTRESETbit으로 processor core를 reset하고SYSRESETREQbit으로 전체 chip을 reset한다. -
Recover
fault exception을 발생시킨 문제를 해결하려고 노력한다..
SVC and PendSV
SVC(supervisor call)과 PendSV(pended supervisor call)은 OS를 target으로 한 exception이다.
SVC
SVC instruction을 통해 generate된다.

SVC는 software를 더 portable하게 만들어준다. user application이 hardware의 programming detail을 몰라도 되기 때문이다.
PendSV
Interrupt Control and State Register(ICSR)의 PENDSVSET-bit으로 generate된다.
PendSV는 시스템에서 가장 낮은 우선순위를 가지고 있는 exception으로, OS의 SVC와 함께 동작한다.
OS가 exception을 pending해서 더 중요한(높은 우선순위를 가진) 다른 task를 실행한 후 action이 수행될 수 있도록 도와준다.
보통 context switching에 사용된다.
아래 그림과 같이 SYSTICK이 context switching을 trigger헌다고 가정해보자.
SYSTICK은 timer interrupt이다. 그 때마다 context switching이 발생하는데 이 implementation은 safe하지 않다.
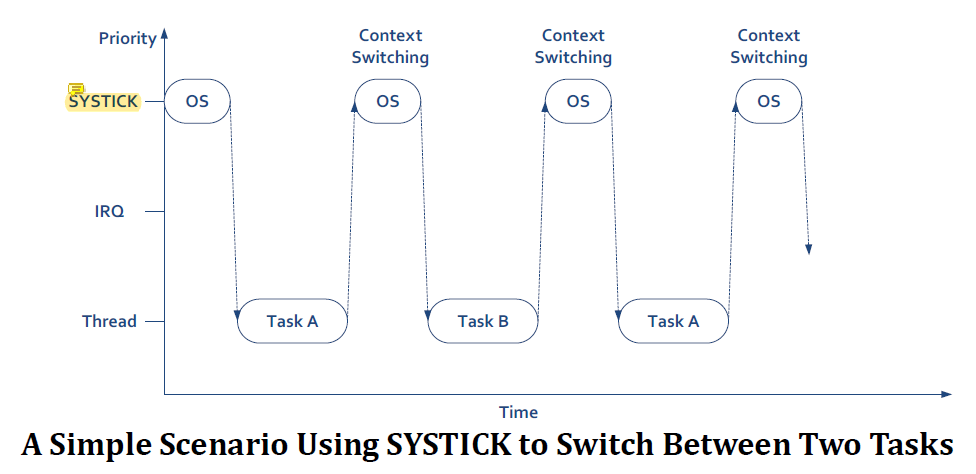 만약
만약 SYSTICK이 어떤 interrupt가 handle되고 있는 도중에 발생해서 context switching이 trigger되면 usage fault가 발생한다.
SYSTICK의 우선순위가 더 높아서 IRQ를 handle하기 전에 SYSTICK을 먼저 handle한다.
그리고 나서 SYSTICK을 그냥 return해버리면 active된 interrupt인 IRQ가 존재하는데 thread mode로 return해서 usage fault가 발생한다.
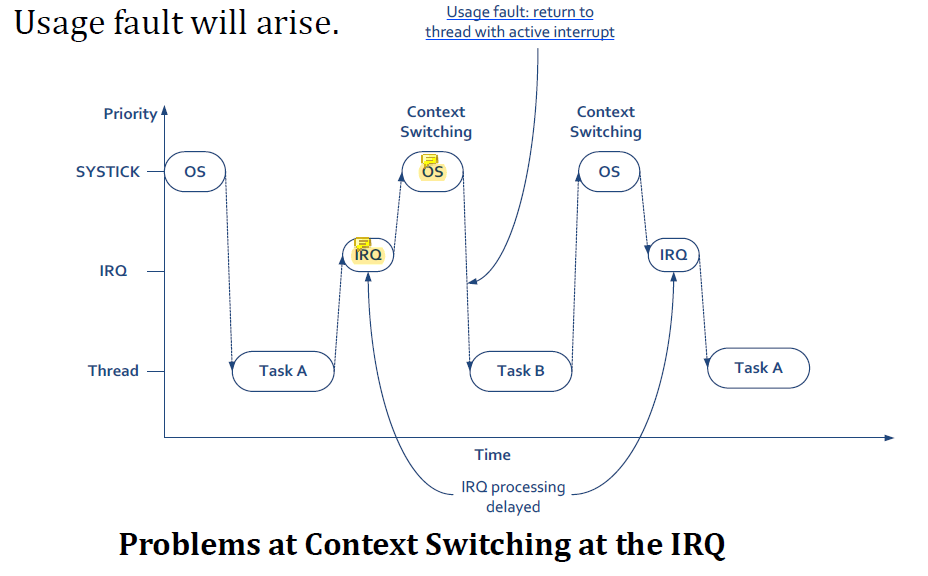 이 문제를 해결하기 위한 방법 중 하나는 OS가 실행되고 있는 interrupt handler가 없을 때만 context switching을 하는 것이다.
이 문제를 해결하기 위한 방법 중 하나는 OS가 실행되고 있는 interrupt handler가 없을 때만 context switching을 하는 것이다.
하지만 그렇게 해버리면 interrupt가 SYSTICK과 비슷한 frequency로 발생하면 context switching이 너무 오래 delay될 수 있다는 문제점이 있다.
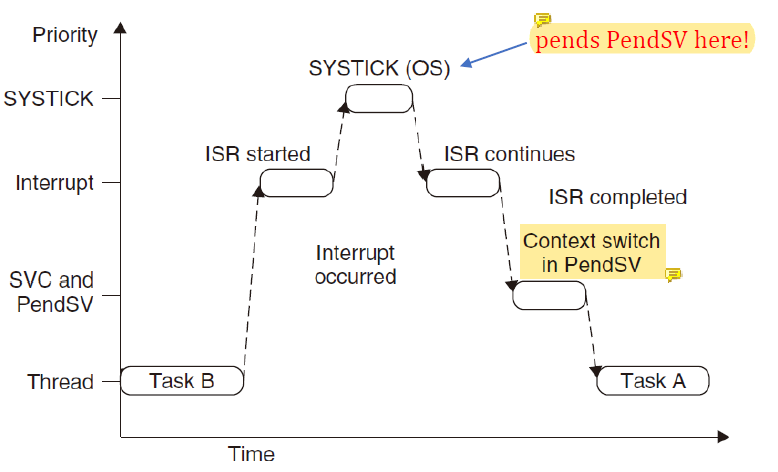 따라서 더 나은 solution은
따라서 더 나은 solution은 PendSV를 사용하는 것이다.
SYSTICK exception이 context switching을 스스로 하지 못하게 만든다.
SYSTICK은 가장 낮은 우선순위를 가진 PendSV exception을 pend하기만 한다.
더 높은 우선순위를 가진 모든 interrupt가 handle된 후에야 PendSV의 handler가 실행되고 안전하게 context switching을 할 것이다.
