Memory Virtualization: Segmentation
운영체제

Inefficiency of the Base and Bound Approach
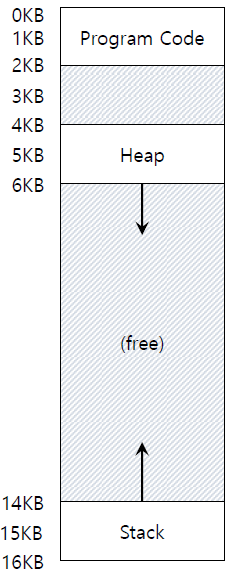 base/bound approach를 사용하면 영역 내부에 free space의 big chunk가 생긴다는 inefficiency가 있다.
base/bound approach를 사용하면 영역 내부에 free space의 big chunk가 생긴다는 inefficiency가 있다.
이미 한 process에게 할당된 address space는 다른 process가 침범할 수도, 사용할 수도 없기 때문에 사용되지 않은 그대로 남게 된다.
이 free space가 physical memory를 채우면 실제로 사용되는 공간이 많지 않음에도 process를 할당할 수 있는 공간이 부족해서 새로운 process를 실행할 수 없게 된다. 이것을 internal fragmentation 문제라고 한다.
각 process마다 address space가 있는데 어떤 프로세스냐에 따라 그 address space를 거의 다 사용할 수도 있고 빈 공간이 남을 수도 있다.
이러한 점이 under utilization, internal fragmentation을 유발한다.
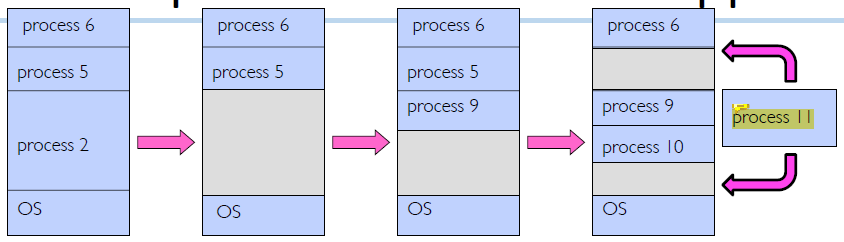 위의 그림을 보면 남은 공간 자체는
위의 그림을 보면 남은 공간 자체는 process 11을 넣을 수 있을 정도의 크기가 되는데 process 11을 contiguous하게 넣을 정도는 안됨.. 이것이 external fragmentation 문제이다.
free space의 total sum은 process 11의 memory로 사용할 수 있는데 physically contiguous해야 한다는 조건 때문에 이 공간을 사용할 수 없다.
Segmetation
segment는 address space에서 특정 length의 contiguous portion이다.
address space를 logically-different segment(code, stack, heap...
)로 나눈다.
fragmentation 문제가 발생한 이유는 전체 address space를 single base/bound pair를 사용해서 나타냈기 때문이다.
single base/bound pair를 사용해서 address space를 한 번 map하고 나면 그 address space는 각 process가 occupy해서 아무도 그 영역을 사용할 수 없게 되고 그 영역은 연속적이어야 했다.
이것을 극복하기 위해 전체 address space를 segment라는 더 작은 영역으로 쪼개서 사용하는 것이다. 이렇게 하면 전체 address space가 한번에 연속적으로 존재할 필요가 없고 segment만 연속적으로 존재하면 된다. 이렇게하면 external fragmentation 문제를 줄일 수 있다.
segmentation을 사용하면 각 process는 different multiple segment로 이루어지게 된다. 그리고 각 segment는 physical area에 contiguous하게 map되어야 한다.
virtual address를 physical address로 translate하기 위해서 base/bound pair를 여러 개 사용해야 한다. base/bound pair는 각 segment당 하나씩 존재한다.
segmentation을 사용하면 external, internal fragmentation을 모두 줄일 수 있다.
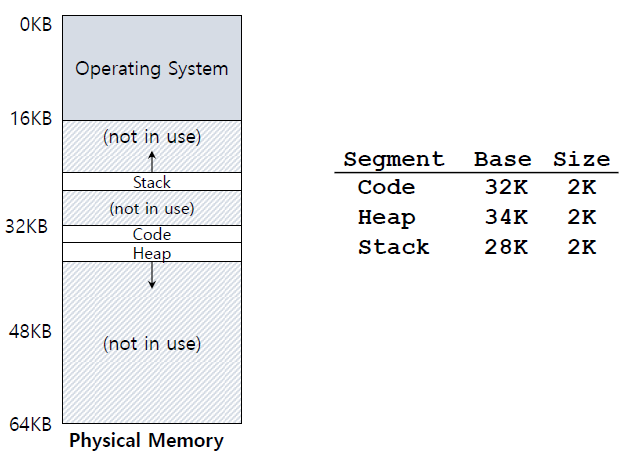
Address Translation on Segmentation
(physical address) = (offset) + (base)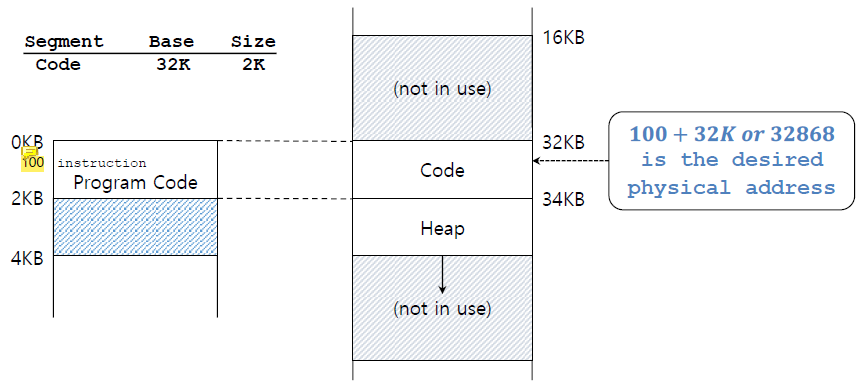 이 그림에서 virtual address
이 그림에서 virtual address 100의 offset은 100이다.
address space에서 code segment가 virtual address 0에서 시작하기 때문이다.
위의 경우에서는 code segment가 0에서 시작했기 때문에 이 offset을 그대로 사용해서 32K에 더해도 physical address를 구하는 데에 오류가 없었다.
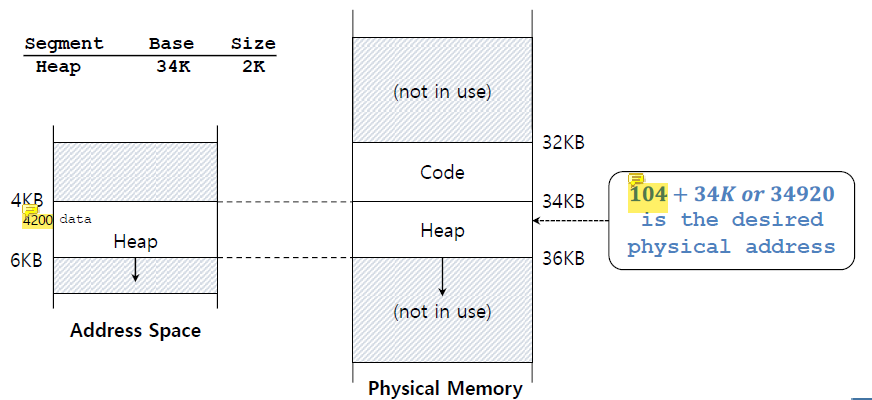 하지만 이 그림에서 virtual address
하지만 이 그림에서 virtual address 4200의 offset은 104이다.
heap segment가 0이 아닌 4KB에서 시작하므로 4200-4096을 한 값이 offset이기 때문이다.
Segmentation Fault or Violation
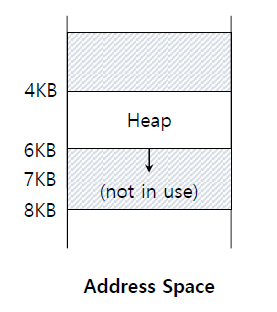 segmentation boundary를 벗어난 physical address에 접근하려고 하면 OS는 segmentation fault를 발생시킨다.
segmentation boundary를 벗어난 physical address에 접근하려고 하면 OS는 segmentation fault를 발생시킨다.
Referring to Segment
Explicit Approach
address space를 virtual address의 top few bits를 이용해 segment로 나눈다.
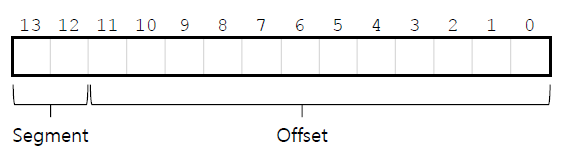 만약 virtual address가
만약 virtual address가 4200(01000001101000)이라면 다음과 같다.
 segment를 나타내는 bit으로 어떤 segment인지 나타내게 된다.
segment를 나타내는 bit으로 어떤 segment인지 나타내게 된다.
Referring to Stack Segment
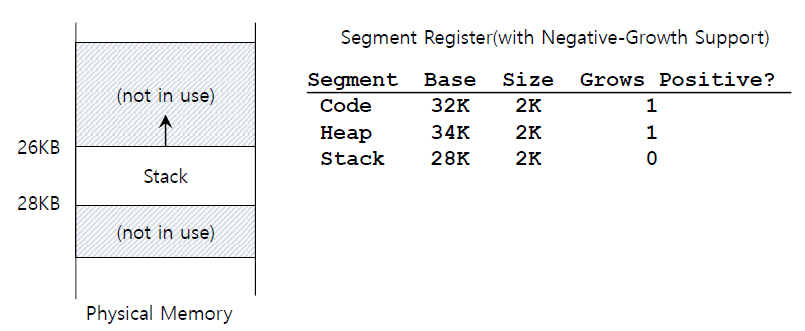
stack은 아래로 자라기 때문에 extra hardware support가 필요하다.
hardware는 segment가 어느 방향으로 자라는지 확인한다.
1은 positive direction, 0은 negative direction이다.
Support for Sharing
segment는 address space간에 share될 수 있다.
code sharing은 extra hardware support를 통해 요즘에도 사용한다.
protection bit을 위해 extra hardware support가 필요하다.
segment마다 read, write, execute에 대한 permission을 나타내기 위해 약간의 bits이 더 필요하다.
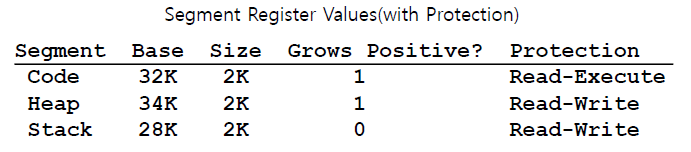
Implementation of Multi-Segment Model
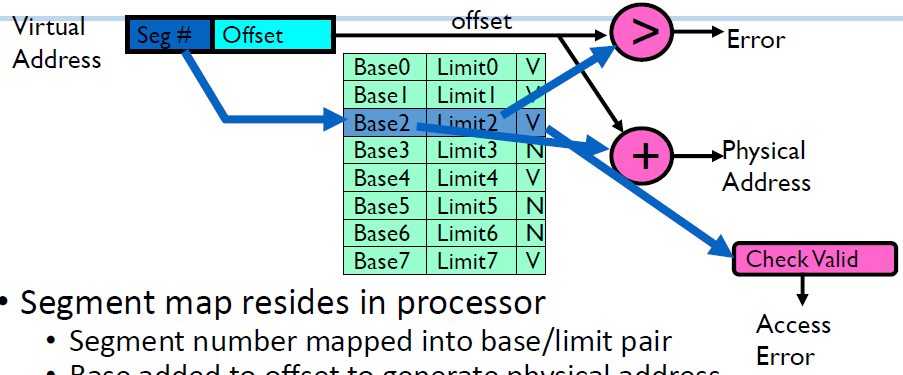 virtual address의 일부가 segment number로 base/limit pair로 mapping된다.
virtual address의 일부가 segment number로 base/limit pair로 mapping된다.
그렇게 얻어진 base에 offset을 더해서 physical address를 generate하는데 offset이 범위를 벗어나거나 valid하지 않은 영역이면 access error가 난다.
Fine-Grained and Coarse-Grained
-
Coarse-Grained : segmentation의 수가 적은 것을 말한다.
single base/bound도 여기에 속한다. hardware logic이 아주 간단하지만 여러가지 fragmentation 문제를 유발한다.
code, heap, stack으로 나누는 것도 coarse-grained이다. -
Fine-Grained : segment의 크기가 작고 수가 많은 것을 의미한다.
segment의 크기를 줄이면 utilization이 증가하고 fragmentation이 줄어들지만 hardware circuit의 complexity가 증가한다. 또한 segment table이 더 커져야 하는데 segment table size의 physical limit이 있다.
Fragmentation
-
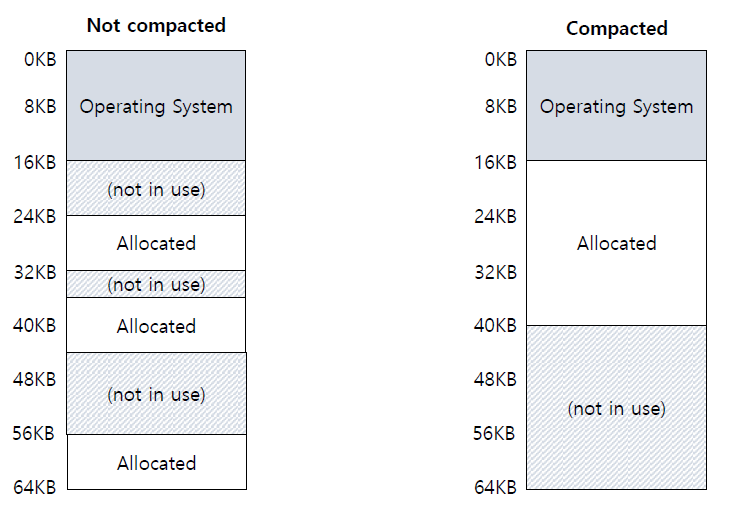
External Fragmentation : physical memory에 free space의 hole이 많이 생겨서 가용한 free space의 크기는 새로운 segment를 allocate하기에 충분하지만 free space의 조각이 흩어져 있어 새로운 segment를 할당할 수 없는 것을 말한다.
예를 들면24KB의 free space가 있는데 그 space가 contiguous하지 않아서20KB의 request를 satisfy하지 못하는 것이다. -
Compaction : physical memory에 존재하는 segment를 rearrange하는 것이다.
compaction은 cost가 꽤 드는 작업이다. 모든 process를 멈추고 data를 어딘가에 copy해둔 뒤 segment의 base/bound value를 조정해야하기 때문이다.
compaction은 그냥 주변에 있는 것을 합치기만 하는 coalescing과 완전히 다르고 옮긴 뒤 adjust하는 과정이 필요하기 때문에 매우 heavy하다.
그래서 OS는 compaction을 최대한 수행하지 않으려고 하지만 DBMS(Database management system)의 경우는 compaction이 종종 일어난다. DBSM에서의 compaction은 defragmentation이라고 한다.
compaction을 할 때 모든 process를 멈추는 이유는 compaction 도중에 race condition이 발생할 수 있기 때문이다.
Splitting
OS가 memory request를 받으면 request를 충족시키기 위해 free list의 free chunk를 사용될 부분과 그렇지 않은 부분으로 나누게 된다.
두 10-bytes의 free segment가 있고 1-byte request가 들어오면 다음과 같이 동작한다.
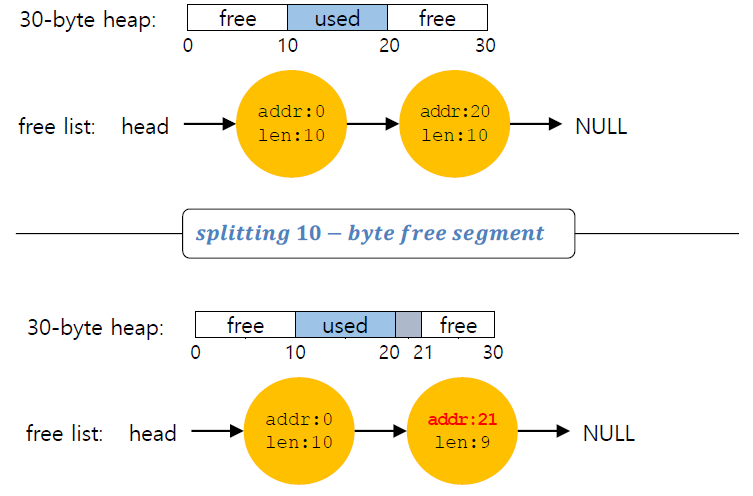 이 과정은 user 영역에서 볼 수 없다.
이 과정은 user 영역에서 볼 수 없다.
user program은 그저 request한 memory area에 대한 pointer만 return받는다.
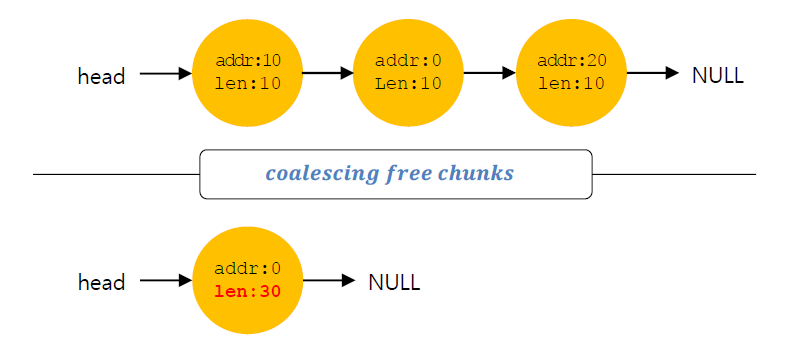
Coalescing
근처에 존재하는 free area를 merge하는 것이다. 바로 옆에 있는 영역을 합쳐서 하나의 chunk로 만들기!
만약 user가 request한 memory가 chunk size보다 크다면 적절한 free chunk를 찾을 수 없기 때문에 근처에 있는 free chunk를 합친다.
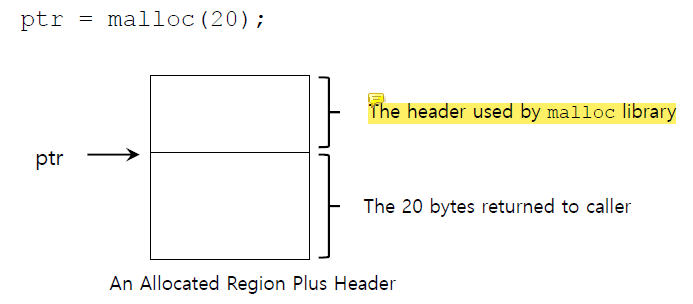
The Header of Allocated Memory Chunk
우리가 allocate했던 memory를 free할 때에 free는 size parameter를 받지 않는다.
free(void *ptr)library는 어떻게 size parameter 없이 free list에 반환해야하는 memory region의 size를 알 수 있을까?
답은 memory chunk의 header에 있다.
대부분의 allocator는 header block에 extra information을 담고 있다.
 header에는 allocated된 memory region의 size를 담고 있다.
header에는 allocated된 memory region의 size를 담고 있다.
추가적으로 deallocation을 가속화해줄 추가적인 pointer나 integrity checking을 위한 magic number가 있을 수 있다.
typedef struct __header_t {
int size;
int magic;
} header_t;
void free(void *ptr) {
header_t *hptr = (void *)ptr - sizeof(header_t);
}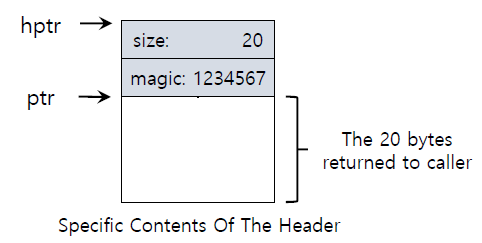 어떤 내용이 allocate된 영역을 넘어서 쓰이게 되면 magic number와 같은 meta data 영역의 값이 변하게 된다. 이런 것을 magin number가 바뀌었는지 아닌지 check해서 detect할 수 있다.
어떤 내용이 allocate된 영역을 넘어서 쓰이게 되면 magic number와 같은 meta data 영역의 값이 변하게 된다. 이런 것을 magin number가 바뀌었는지 아닌지 check해서 detect할 수 있다.
Embedding A Free List
free list의 node는 다음과 같은 방법으로 표현한다.
typedef struct __node_t {
int size;
struct __node_t *next;
} node_t;여기서 next는 pointer로, node로 사용할 수도 있고 header로 사용할 수도 있다.
Allocation
memory chunk가 request되면 library는 request를 수행할 수 있는 충분한 크기의 free chunk를 찾는다.
그리고 library는 free chunk를 둘로 나눠서 하나는 request를 수행하고 하나는 free chunk로 내버려두며 free list의 free chunk의 크기를 줄인다.
ptr = malloc(100)으로 100-bytes를 request한다면 헤더까지 포함해 108-bytes를 allocate하고 free chunk의 크기를 줄인다.
아래의 예제에서는 4088 bytes였던 free chunk를 3980(4088-108) bytes로 줄이고 있다.
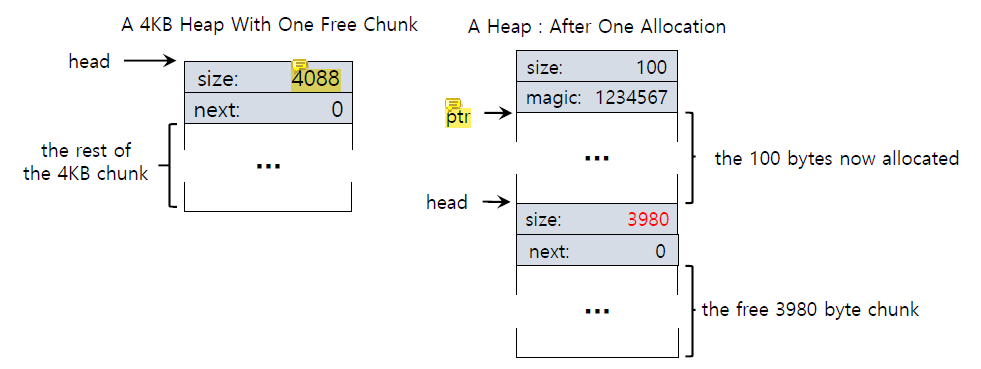 allocation을 반복하면 다음과 같이 된다.
allocation을 반복하면 다음과 같이 된다.
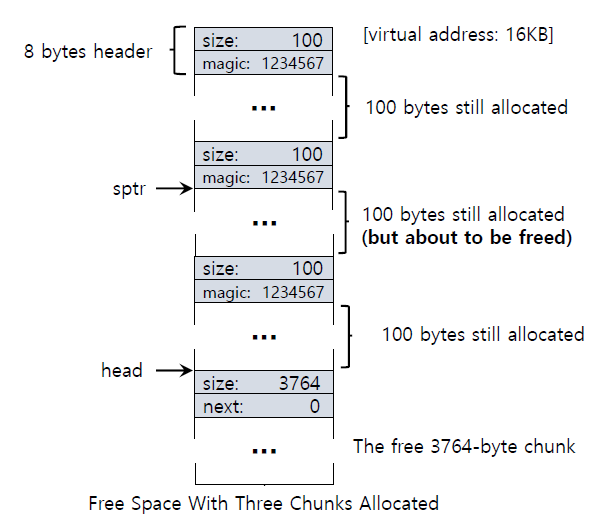
Free Space With free()
위의 예제에서 free(sptr)를 수행해보자.
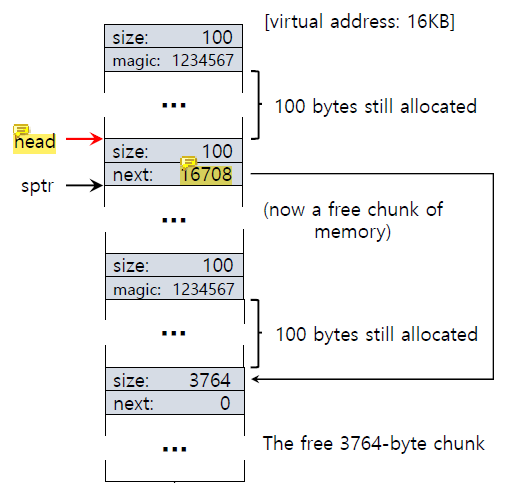
100 byte chunk는 다시 free list로 돌아간다.
memory space가 free되면 head가 가장 최근에 free된 memory chunk를 가리키도록 옮겨간다. 그리고 magic number로 사용되던 magic 필드가 다음 free chunk를 가리키는 pointer(next)로 사용된다.
이 과정이 반복되면 physical memory가 다음과 같은 형태가 된다.
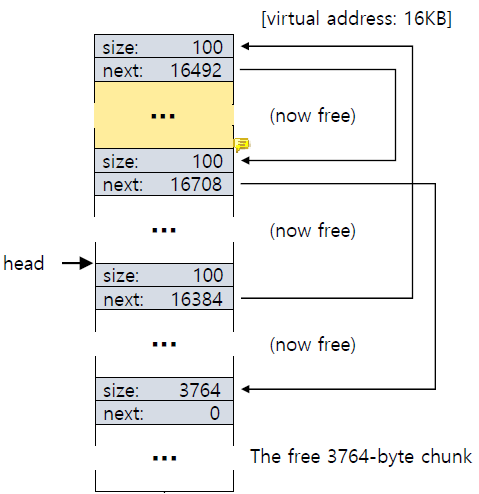 중간중간에 빈 공간이 생기면서 나중에 큰 memory request가 발생했을 때 어떤 memory chunk도 request를 만족할 수 없는 상황이 발생한다.
중간중간에 빈 공간이 생기면서 나중에 큰 memory request가 발생했을 때 어떤 memory chunk도 request를 만족할 수 없는 상황이 발생한다.
즉, external fragmentation이 발생하는 것이다.
이를 피하기 위해 coalescing이 수행되어야 한다.
Growing The Heap
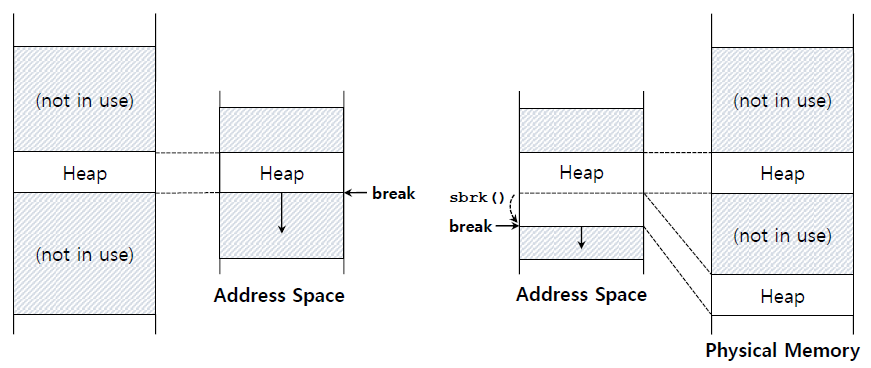 대부분의 allocator들은 small-sized heap을 생성하고 그 공간을 다 사영했을 때 OS로부터 더 많은 memory를 request하게 된다.
대부분의 allocator들은 small-sized heap을 생성하고 그 공간을 다 사영했을 때 OS로부터 더 많은 memory를 request하게 된다.
이 때 malloc등을 이용하면 libc라이브버리가 모든 free list를 확인하고 heap area를 증가시키기 위해 내부적으로 sbrk나 brk를 호출한다.
heap area가 top of stack에서부터 아래로 자라기 때문에 logically하게는 address space상에서 연속적이지만 실제로 physical memory에서는 연속적이지 않게 different physical area로 mapping할 수도 있다.
Managing Free Space
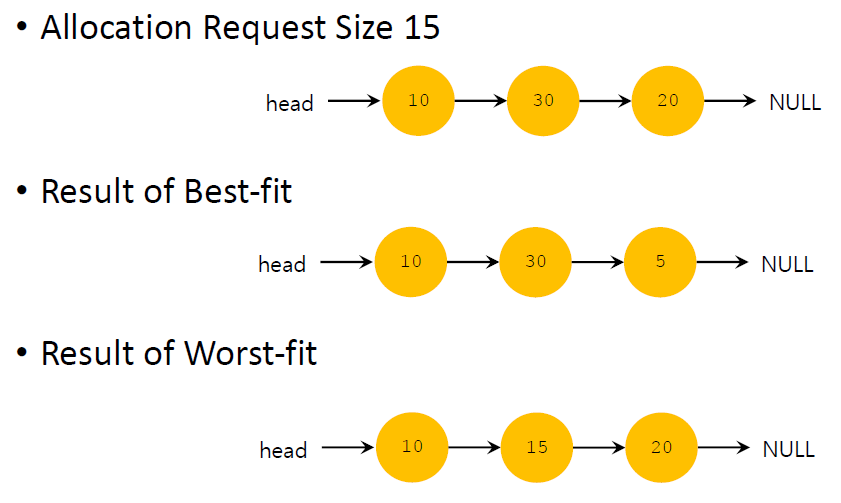
Best Fit
모든 memory free list를 traverse해서 request보다 같거나 큰 chunk중 가장 작은 free chunk를 return한다.
모든 free list를 탐색하기 때문에 시간이 오래 걸리지만 가장 tight하게 fit하는 chunk를 찾을 수 있다는 장점이 있다.
만약 internal memory space가 huge한 process가 있다면 전체 free list를 다 돌아서 가장 적합한 chunk를 찾는 best fit은 시간이 너무 많이 소모된다. 이런 경우에는 first fit이나 next fit이 더 적합할 수 있다.
Worst Fit
free list에서 가장 큰 free chunk를 찾아서 return한다.
allocate하고 남은 chunk는 free list에 유지한다.
First Fit
request를 충족할 수 있는 가장 첫번째 free chunk를 찾아 return한다.
Next Fit
request를 충족할 수 있는 가장 첫번째 free chunk를 찾아 return한다.
next fit은 first fit처럼 매번 free list의 처음에서 free chunk를 찾는 것이 아니라 이전에 멈췄던 곳에서부터 찾기 시작해서 첫번째로 적합한 것을 찾는다. searching time을 줄일 수 있는 여지가 있다.
Segregated List
자주 request되는 여러 size로 각각 list를 만들어 free chunk를 관리한다.
이 방법은 주어진 크기의 specialized request를 처리하는 메모리 풀에 얼마나 많은 메모리를 할당해야 하는지를 정확히 모른다는 문제가 있다.
이 문제는 slab allocator를 통해 해결할 수 있다.
Slab Allocator
- Slab : a pool of same-sized and preallocated memory chunk
process는 서로 다른 size의 request를 할 수 있지만 많은 경우에 DBMS나 OS같은 long running process는 내부적으로 same size를 가진 많은 object를 가지고 있는 경우가 많다. page structure, buffer structure, file structure같은 것들..
그래서 이런 경우에는 chunk를 임의의 size로 나누는 것보다 same size로 나누는 것이 효과적이다.
slab allocator를 사용하면 fragmentation 문제가 없다. 이미 많은 slab object들을 preallocate했기 때문이다.
같은 size의 request가 들어오면 그냥 pool로 관리하고 있던 slab 중 하나를 골라서 주기만 하면 된다. chunk를 다른 size로 나누거나 나중에 coalesce할 필요가 없다. 이미 같은 종류의 object를 manage하는 pool이 있기 때문이다.
Buddy Allocation
- Binary Buddy Allocation : block이 request를 만족할 수 있을 때까지 free space를 절반으로 나눈다.
request가 들어오면 어떤 memory region이든 반으로 나누는 것이다. 이것이 나중에 memory region을 combine하는 데에 도움이 되기 때문이다.
그냥 바로 근처에 있는 chunk가 free되었는지 아닌지만 확인하면 이전의 크기의 2배인 chunk를 만들 수 있다.
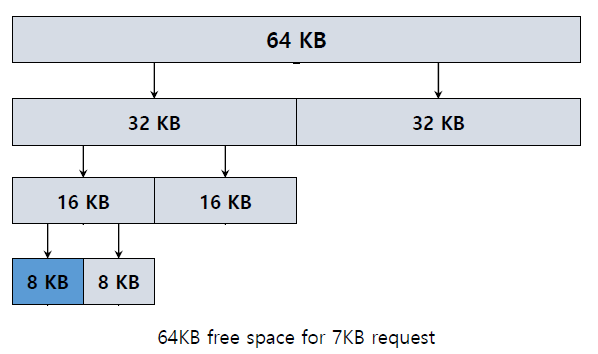 buddy allocation은 internal fragmentation 문제가 생길 수 있다. 하지만 coalescing이 쉽다.
buddy allocation은 internal fragmentation 문제가 생길 수 있다. 하지만 coalescing이 쉽다.
