Warning: data for page "/add" is 1.17 MB which exceeds the threshold of 128 kB, this amount of data can reduce performance.

개요 😎
개인 프로젝트로 대학 시간표 관련 서비스를 만들고 있다. 에브리타임(https://everytime.kr/)을 참고하여 시간표 추가 화면을 구현하던 중에 Next.js의 Large Page Data Warning이 발생하여 해결했는데, 해결 과정에서 배운 것이 많아 정리해 보았다.
문제 😇
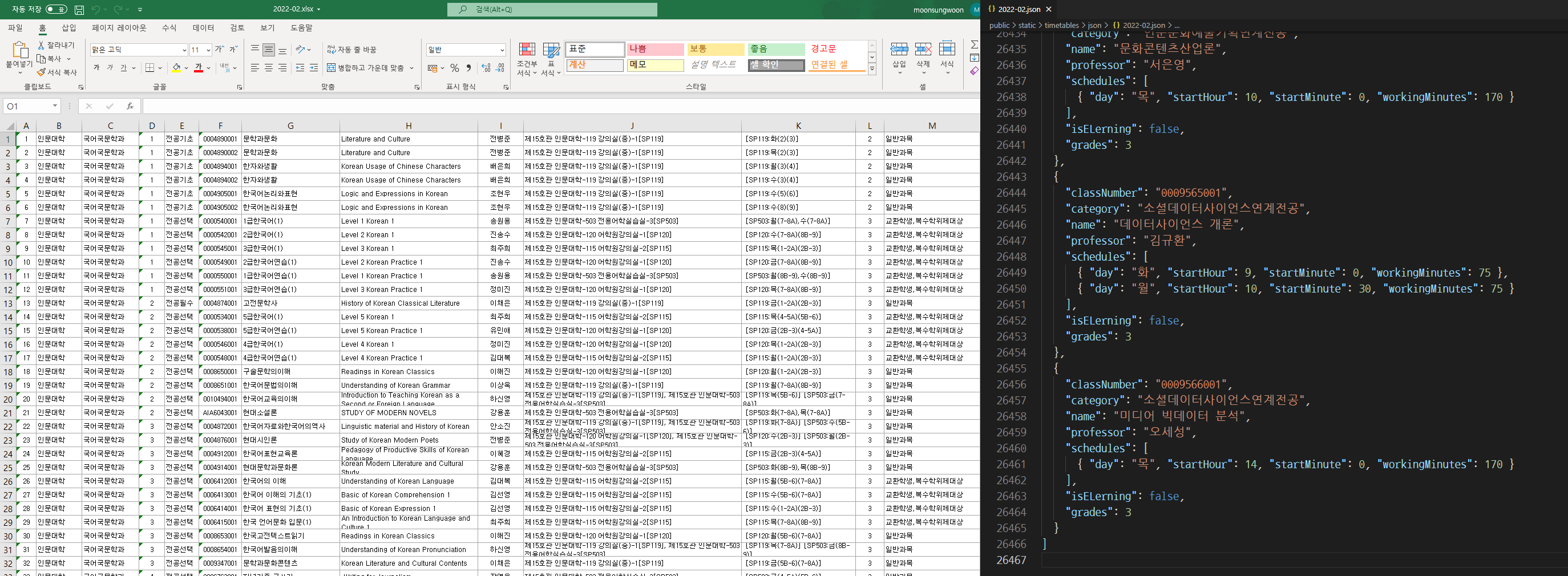
학교 홈페이지에 공개된 강의 시간표(.excel)를 필요한 정보만 추출하고 .json 파일로 만들어서 시간표 추가 화면에서 사용하였다.
강의 시간표는 학기가 시작되면 거의 바뀌지 않기 때문에, getStaticProps에서 .json 파일을 읽어와 pageProps를 통해 넘겨주는 방식으로 구현하였다. 이번 프로젝트를 통해 Next.js를 처음 사용해보았는데, getStaticProps를 사용하여 외부 데이터를 불러오니 컴포넌트에서 isLoading과 같은 비동기 서버 상태를 관리할 수고를 덜 수 있고 컴포넌트 내부 코드도 간결해져 굉장히 만족스러웠다.
술술 풀리나 했는데...
빌드 중에 Warning: data for page "/add" is 1.17 MB which exceeds the threshold of 128 kB, this amount of data can reduce performance. 경고 문구가 콘솔에 출력되는 것을 보았다. getStaticProps에서 2개 학기의 강의 시간표를 모두 불러왔더니 add.html 파일의 사이즈가 1 MB가 넘어버렸다. 128 KB를 초과하는 양의 데이터는 성능을 저하시킬 수 있다고 하여 LightHouse로 측정해보았다.
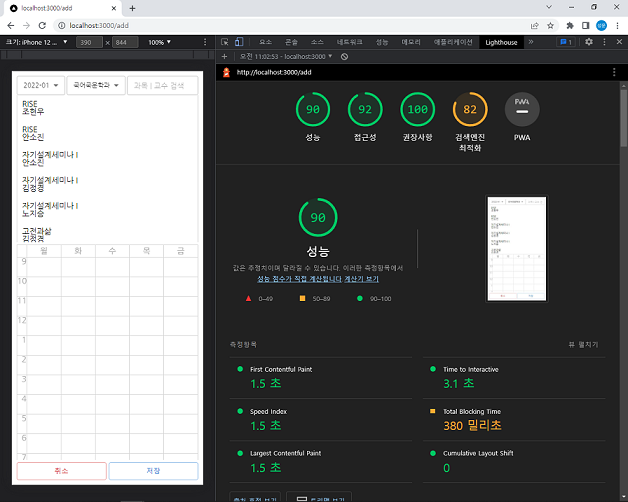
성능에는 큰 문제 없어 보이지만...
당장은 문제가 안되더라도 추후 서비스를 지속적으로 운영한다고 가정 했을 때 제공하는 모든 학기의 데이터를 하나의 HTML 파일에 모두 담는 것은 좋은 구현 방법이 아니라고 생각했다. (1년치 데이터가 1.17 MB, 10년치 데이터는 11 MB...?!)
우선 문제 해결에 앞서 정확히 어떤 문제인지 파악해야 하기 때문에 공식 문서를 찾아봤다. https://nextjs.org/docs/messages/large-page-data
SSR(Server-Side Rendering)의 구동 방식은 브라우저가 server-side에서 만들어진 정적 HTML을 먼저 받아 rendering 한 뒤, page 구동에 필요한 JS를 받는다. 이후 정적 HTML에 JS를 연결하는 과정을 거치는데, 이러한 과정을 수화(Hydration)라고 한다. 공식 문서를 확인해보면 client는 수화하기 전에 page data를 구문 분석한다고 명시되어 있다. page data가 커지면 커질수록 구문 분석에 많은 시간이 소요되고 그만큼 수화 과정이 지연될 수 있으므로 page data의 임계를 128 KB로 정한 것 같다.
강의 시간표 불러오는 방법을 개선하여 이 문제를 해결한다면 HTML이 가벼워져, FCP와 LCP 등의 성능 지표가 개선될 것이고 구문 분석에 소요되는 시간이 줄어 TTI 또한 개선되지 않을까? 하는 설레는 마음으로 개선 방법을 고민하였다.
해결 🤔
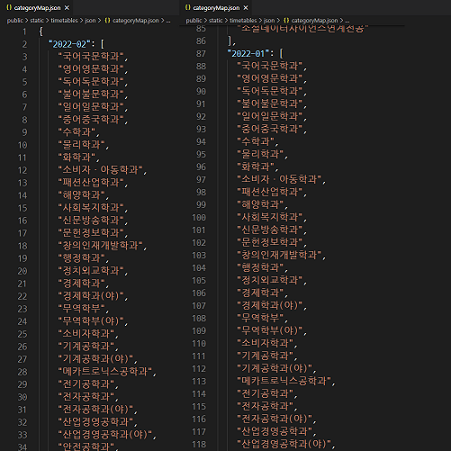
page data의 양이 임계를 초과하여 발생한 문제이므로, getStaticProps에서 불러올 데이터의 양을 줄여야 했다. 기존의 .json 파일에서 학기에 따른 카테고리(전공 or 교양) 목록을 분리하고 해당 파일만 불러와 HTML을 미리 만들어두고 카테고리에 해당하는 강의 목록은 프론트 단에서 react query를 사용하여 page가 rendering될 때 불러오는 방식으로 수정하였다.
export async function getStaticProps() {
const folderPath = path.join(process.cwd(), "/public/static/timetables/json");
const categoryFilePath = `${folderPath}/categoryMap.json`;
const categoryFileData = fs.readFileSync(categoryFilePath, "utf-8");
const categoryMap = JSON.parse(categoryFileData) as ICategoryMap;
const semesters = Object.keys(categoryMap);
return {
props: {
semesters,
categoryMap,
},
};
}// semesters와 categoryMap은 pageProps로 받아온다.
function useFilterTimetables(semesters: string[], categoryMap: ICategoryMap) {
const [semester, setSemester] = useState(semesters[0]);
const categories = categoryMap[semester];
const [category, setCategory] = useState(categories[0]);
const [keyword, setKeyword] = useState("");
const { data: filteredTimetables } = useTimetables(semester, category, keyword);
return {
semesters,
semester,
setSemester,
categories,
category,
setCategory,
keyword,
setKeyword,
filteredTimetables: filteredTimetables,
};
}성능을 측정 해볼까?!
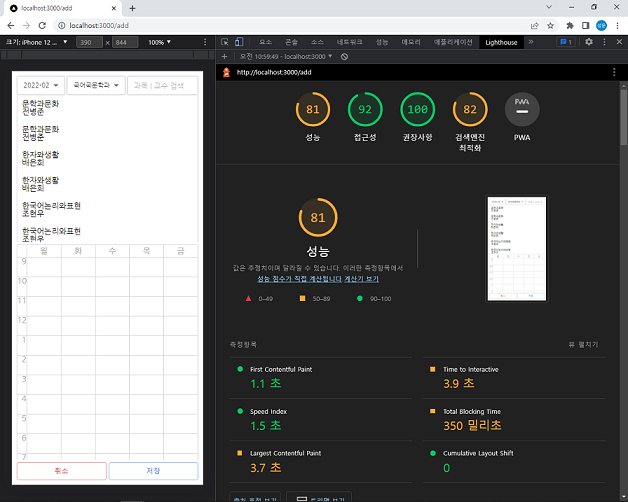
getStaticProps에 모든 데이터를 몰아 넣어 Large Page Data Warning이 발생했을 때보다 성능이 낮게 측정되었다. 가장 크게 문제가 되는 LCP는, HTML rendering --> JS Download --> Hydration 의 모든 과정을 거치고 나서야 react query를 통해 강의 목록 data를 불러오는 것이기 때문에, 강의 목록이 기존보다 늦게 rendering 되어서 발생한 것이다.
풀 다운 메뉴로 선택하는 학기와 카테고리(전공 or 교양)는 고정된 값이기 때문에 첫 번째 학기(2022-02)와 첫 번째 카테고리(국어국문학과)의 강의 목록 또한 고정된 값이다. 따라서 가장 먼저 표시되는 2022-02 학기의 국어국문학과 강의 목록 또한 getStaticProps에서 불러온 뒤 pageProps로 넘겨주는 것이 성능 개선에 도움 될 것이라고 생각되어 수정하였다.
export async function getStaticProps() {
const folderPath = path.join(process.cwd(), "/public/static/timetables/json");
const categoryFilePath = `${folderPath}/categoryMap.json`;
const categoryFileData = fs.readFileSync(categoryFilePath, "utf-8");
const categoryMap = JSON.parse(categoryFileData) as ICategoryMap;
const semesters = Object.keys(categoryMap);
const semester = semesters[0];
const categories = categoryMap[semester];
const category = categories[0];
const timetablesFilePath = `${folderPath}/${semester}.json`;
const timetablesFileData = fs.readFileSync(timetablesFilePath, "utf-8");
const timetables = JSON.parse(timetablesFileData) as ITimetable[];
const firstIndexTimetables = timetables.filter(
(timetable) => timetable.category === category
);
return {
props: {
semesters,
categoryMap,
firstIndexTimetables,
},
};
}현재 react query는 아래와 같이 사용하고 있는데, query key ['2022-02', '국어국문학과', '']의 데이터는 pageProps를 통해 받아오는 것으로 수정했기 때문에 초기 query key에서는 fetch를 할 필요가 없다.
const queryString = `?semester=${semester}&category=${category}&keyword=${keyword}`;
const filteredTimetables = useQuery<ITimetable[]>(
[semester, category, keyword],
() => get(timetablesService, queryString),
{ staleTime: 60 * 1000 * 60 }
);불필요한 네트워크 요청을 막기 위해 아래와 같은 방법으로 initialData를 추가하였다.
export function useTimetables(
semester: string,
category: string,
keyword: string,
useInitialData: boolean,
initialData: ITimetable[]
) {
const queryString = `?semester=${semester}&category=${category}&keyword=${keyword}`;
const filteredTimetables = useQuery<ITimetable[]>(
[semester, category, keyword],
() => get(timetablesService, queryString),
{ initialData: useInitialData ? initialData : undefined, staleTime: 60 * 1000 * 60 }
);
return filteredTimetables;
}결과는?!
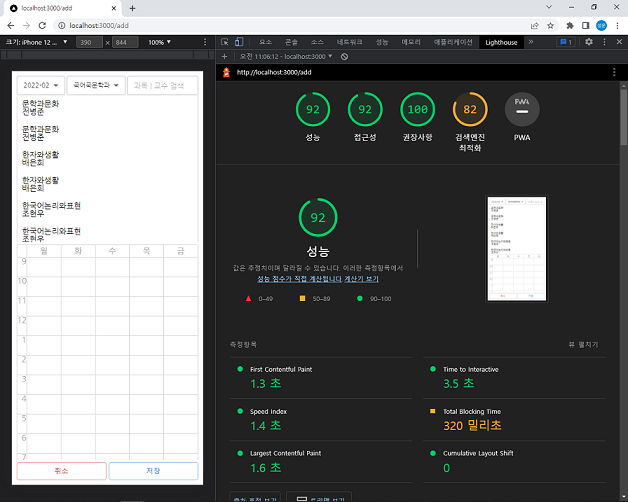
의도했던 대로 LCP가 개선되었다!
이렇게 강의 목록을 불러오는 방식을 변경하여 Large Page Data Warning을 해결하고 1 MB가 넘던 HTML 파일의 크기를 140 KB로 줄일 수 있었다. 😀
