정렬이란? 왜 중요한가?
정렬(Sorting)이란 데이터를 오름차순(작은 → 큰) 또는 내림차순(큰 → 작은)으로 정리하는 과정이다.
✔ 정렬이 필요한 이유
- 검색 속도를 빠르게 하기 위해 (O(N) → O(log N))
- 중복된 데이터를 쉽게 찾기 위해
- 데이터를 더 잘 분석하기 위해
📌 비유로 이해하기
- 정렬이 없는 데이터: "책이 엉망으로 쌓여 있는 도서관 📚"
- 정렬된 데이터: "책이 가나다 순으로 정리된 도서관 📖"
정렬이 잘 되어 있으면 검색, 탐색, 분석이 훨씬 쉬워진다 !
이제 정렬의 종류에 대해 알아보자
.
.
.
기본 정렬 알고리즘
버블 정렬 (Bubble Sort)
💡 가장 느린 정렬 방법!
def bubble_sort(arr): n = len(arr) for i in range(n): for j in range(n - i - 1): if arr[j] > arr[j + 1]: # 인접 요소 비교 후 교환 arr[j], arr[j + 1] = arr[j + 1], arr[j]
✅ 시간복잡도: O(N²) (느림)
- 매번 인접한 두 개를 비교하고, 큰 값을 뒤로 보냄 (거품이 올라가는 모습)
- 거의 정렬된 경우에도 느림 😢
선택 정렬 (Selection Sort)
💡 가장 작은/큰 값을 선택해 제자리에 놓는 방식
def selection_sort(arr): n = len(arr) for i in range(n): min_index = i for j in range(i + 1, n): if arr[j] < arr[min_index]: # 최소값 찾기 min_index = j arr[i], arr[min_index] = arr[min_index], arr[i] # 교환
✅ 시간복잡도: O(N²) (느림)
- 첫 번째 요소에 가장 작은 값을 배치 → 두 번째 요소에 그다음 작은 값 배치
- 버블 정렬보다 비교 횟수가 적음, 하지만 여전히 느림 😢
삽입 정렬 (Insertion Sort)
💡 손으로 카드 정렬하는 방식
def insertion_sort(arr): n = len(arr) for i in range(1, n): key = arr[i] j = i - 1 while j >= 0 and arr[j] > key: # 왼쪽 값과 비교하여 삽입 위치 찾기 arr[j + 1] = arr[j] j -= 1 arr[j + 1] = key
✅ 시간복잡도: O(N²), 하지만 거의 정렬된 경우 빠름!
- 왼쪽부터 점점 정렬 영역을 확장하는 방식
- 거의 정렬된 경우 O(N), 최악의 경우 O(N²)
- 작은 데이터에서 성능이 좋음 🚀
고급 정렬 알고리즘 (효율적인 정렬)
퀵 정렬 (Quick Sort)
💡 가장 많이 쓰이는 정렬!
def quick_sort(arr): if len(arr) <= 1: return arr # 기저 사례 (재귀 종료 조건) pivot = arr[len(arr) // 2] left = [x for x in arr if x < pivot] # 피벗보다 작은 값 middle = [x for x in arr if x == pivot] # 피벗과 같은 값 right = [x for x in arr if x > pivot] # 피벗보다 큰 값 return quick_sort(left) + middle + quick_sort(right) # 재귀적으로 정렬
✅ 시간복잡도: O(N log N), 최악의 경우 O(N²)
- 피벗(pivot)을 기준으로 작은 값과 큰 값을 분리 후 정렬
- 평균적으로 가장 빠름 → 실전에서 가장 많이 사용 🚀
병합 정렬 (Merge Sort)
💡 데이터가 랜덤하게 섞인 경우 퀵 정렬보다 안정적인 정렬
def merge_sort(arr): if len(arr) <= 1: return arr mid = len(arr) // 2 left = merge_sort(arr[:mid]) # 왼쪽 절반 정렬 right = merge_sort(arr[mid:]) # 오른쪽 절반 정렬 return merge(left, right) def merge(left, right): result = [] i = j = 0 while i < len(left) and j < len(right): if left[i] < right[j]: result.append(left[i]) i += 1 else: result.append(right[j]) j += 1 result += left[i:] + right[j:] return result
✅ 시간복잡도: O(N log N)
- 퀵 정렬과 달리 최악의 경우에도 O(N log N)을 보장
- 추가 메모리(O(N))가 필요하지만 안정적인 정렬
정렬 알고리즘 성능 비교
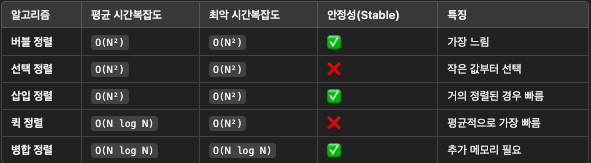
✅ 퀵 정렬(Quick Sort)이 일반적으로 가장 빠름!
✅ 거의 정렬된 데이터는 삽입 정렬(O(N))이 유리
✅ 안정적인 정렬이 필요하면 병합 정렬(Merge Sort) 사용
실전에서 정렬을 어떻게 사용해야 할까?
✔ Python의 sort()는 퀵 정렬과 병합 정렬을 혼합한 Timsort(O(N log N)) 사용
arr = [5, 3, 8, 1, 2] arr.sort() # 정렬된 리스트 반환 print(arr) # [1, 2, 3, 5, 8]
✔ 리스트 복사 없이 정렬하려면 sorted() 사용
arr = [5, 3, 8, 1, 2] sorted_arr = sorted(arr)
결론 (정리)
✅ 버블/선택 정렬 → 비효율적 (O(N²)) → 실제로 잘 안 씀
✅ 삽입 정렬 → 거의 정렬된 경우 빠름 (O(N))
✅ 퀵 정렬 → 실전에서 가장 많이 사용 (O(N log N))
✅ 병합 정렬 → 안정적이고 최악의 경우에도 O(N log N) 유지

Before Sunrise