개요
프로젝트 진행도중
프로젝트 장이자 백엔드 담당하시는 팀장님께서 batch 및 배포 작업만 하는걸로 하시고 이외의 모든 개발 및 보수 작업을 내게 넘기셨다.
내 담당은 아니었지만 어쩌다 보니 전반적인 수정을 맡게되어 팀장님이 작성하신 API들이 문제가 생기면 수정해야 할 일이 생겼다.
오히려 개선점을 찾아볼 기회가 되어 나쁘지 않겠다고 생각했다.
하나씩 살펴보고 API테스트를 하는 도중 보낸 질문 및 받은 질문에 대한 API에 문제가 있었다.
해당 API는 보낸 질문 및 받은 질문에 대해 조회하는 API인데 무한스크롤 형태로 구현되어 있었으며 쿼리는 아래와 같이 네이티브 쿼리를 이용해 작성되어 있었고,
@Query(value = "SELECT cd.*, mi.avatar_path AS avatarPath, mi.nickname AS nickname " +
"FROM (" +
" SELECT a.id AS mstId, " +
" a.guest_id AS guestId, " +
" a.owner_id AS ownerId, " +
" b.id AS conId, " +
" b.content, " +
" CASE WHEN (SELECT COUNT(*) FROM recommend WHERE recommend_status = 'LIKES' AND user_id = :userId AND conversation_id = b.id) > 0 THEN true " +
" ELSE false END AS isGood, " +
" CASE WHEN (SELECT COUNT(*) FROM recommend WHERE recommend_status = 'THANKED' AND user_id = :userId AND conversation_id = b.id) > 0 THEN true " +
" ELSE false END AS isThanked, " +
" b.is_private AS isPrivate, " +
" b.is_question AS isQuestion, " +
" b.modified_at AS modifiedAt, " +
" b.writer_info_id AS writerId " +
" FROM conversation_mst a " +
" JOIN conversation b ON a.id = b.mst_id " +
" WHERE a.owner_id = :ownerId AND a.is_deleted = false AND b.is_deleted = false AND a.id IN ( " +
" SELECT id FROM conversation_mst " +
" WHERE owner_id = :ownerId AND is_deleted = false " +
" ORDER BY id DESC " +
" LIMIT :pageSize OFFSET :offset " +
" )" +
") cd " +
"LEFT JOIN member_info mi " +
"ON (cd.isQuestion = FALSE AND cd.ownerId = mi.id) " +
"OR (cd.isQuestion = TRUE AND cd.guestId = mi.id) " +
"WHERE cd.ownerId = :ownerId AND (cd.guestId IS NOT NULL AND mi.is_deleted = false OR cd.guestId IS NULL) " +
"ORDER BY cd.mstId DESC, cd.conId ASC",
nativeQuery = true)
List<ConversationDetailsResponse> findConversationByOwnerIdPaging(@Param("ownerId") Long ownerId, @Param("pageSize") int pageSize, @Param("offset") int offset, @Param("userId") Long userId);
서비스단의 메소드는 아래와 같이 되어있었다.
public ConversationPageResponse getConversationPage(Long ownerId, Integer page) {
Long userId = getCurrentUserId();
int pageNumber = (page != null) ? page - 1 : 0; // 페이지 인덱스
int pageSize = timelinePageSize; // 보여줄 블럭 수
int offset = pageNumber * pageSize; // 페이징 시작 위치
boolean lastPage = false; // 마지막 페이지 여부
long totalRecords = conversationMSTRepository.countByOwnerId(ownerId);
// 더이상 페이지가 없으면 마지막페이지
if(offset + pageSize > totalRecords) {
lastPage = true;
}
List<ConversationDetailsResponse> result = conversationRepository.findConversationByOwnerIdPaging(ownerId, pageSize, offset, userId);
return new ConversationPageResponse(result, lastPage);
}첫 번째 문제 및 해결
해당 api에는 문제가 있었는데, 첫 번째는 lastPage를 넘기는 과정에 문제가 있었다.
if(offset + pageSize > totalRecords) {
lastPage = true;
}위 코드에서 totalRecords는 전체 데이터 갯수이고, offset + pageSize에서 pageSize는 limit를 의미하는데
offset + pageSize > totalRecords 의 경우 총 데이터 수 가 10개라 가정하고 offset이 7이고 limit가 3일 때 7 + 3 > 10 으로 마지막 페이지임에도 if문을 통과하지 못해 lastPage = false를 그대로 반환하게 된다.
따라서 해당 코드를 offset + pageSize >= totalRecords로 수정하여 간단히 해결하였다.
두 번째 문제
이후 테스트 중 우연히 두 번째 문제를 발견하였는데, 무한 스크롤을 사용하면서 첫 번째 페이지 조회 후 다음 페이지 조회하기 이전에 데이터가 추가 또는 삭제되는 경우 발생하였다.
- 첫 번째 페이지 조회 후 다음 페이지를 조회하기 전 데이터 추가 시
중복발생
조건: id값 auto-increment, 최신순 조회(desc, 내림차순)
초기 데이터: [10, 9, 8, 7, 6, 5, 4, 3, 2, 1]
1페이지 요청: [10, 9, 8] (offset=0, limit=3)
데이터 추가: [11, 10, 9, ..., 2, 1] -> 11추가
2페이지 요청: [8, 7, 6] (offset=3, limit=3)
무한 스크롤에 보이는 데이터 [10, 9, 8, 8, 7, 6] → 중복 데이터(8) 발생
- 첫 번째 페이지 조회 후 다음 페이지를 조회하기 전 데이터 삭제 시
누락발생
조건: id값 auto-increment, 최신순 조회(desc, 내림차순)
초기 데이터: [10, 9, 8, 7, 6, 5, 4, 3, 2, 1]
1페이지 요청: [10, 9, 8] (offset=0, limit=3)
데이터 삭제: [10, 8, 7, ..., 2, 1] -> 9 삭제
2페이지 요청: [6, 5, 4] (offset=3, limit=3)
무한 스크롤에 보이는 데이터 [10, 9, 8, 6, 5, 4] → 누락 데이터(7) 발생
무한 스크롤에 대해 학습하며 알게 된 점
무한 스크롤은 유저에게 연속적인 컨텐츠를 제공하기때문에 페이지간의 이동없이 부드럽고 중단되지않는 탐색 경험을 줄 수 있다는 장점이 있다.
또한 페이지의 전환없이 스크롤만으로 데이터가 자동 로딩 되므로 별다른 작업이 필요없어 유저의 편의성이 향상된다는 장점이 있다.
하지만 offset방식의 무한 스크롤을 사용하게 되면 이러한 장점들을 잃게 될 수 있다.
데이터의 양이 적다면 문제가 되지 않을 수 있지만, 대규모 데이터 처리 시 성능 저하 문제가 발생한다. Offset 방식은 페이지 번호에 따라 앞선 데이터를 건너뛰는 연산이 발생하는데, 해당 과정에서 앞선 데이터를 모두 스캔한 뒤 limit에 설정한 데이터만 남기고 버리기 때문에 데이터 양이 많아질수록 이 연산 비용이 증가한다.
데이터가 많아질수록 offset 값이 커지면서 스캔하는 데이터의 양이 늘어 스크롤을 내릴수록 처리 속도가 점점 느려지는 현상이 나타나며, 이는 무한 스크롤이 제공하는 ‘끊김 없는 경험’ 장점을 잃게될 것이다.
무한 스크롤에 대해 학습하며 offset 방식은 무한 스크롤에 적합하지 않다는것을 알게 되었고,
무한 스크롤 구현에 보다 적합한 방식은 무엇인지 찾다 아래와 같은 이유로 cursor 기반 방식을 채택하였다.
- 중복/누락 방지: 마지막 데이터의 ID같은 고유값을 커서로 사용하여 변화된 데이터에도 일관성 있게 조회 가능
- 성능 안정성: WHERE id < ? LIMIT n 방식으로 필요한 데이터만 효율적으로 조회, 페이지가 깊어져도 성능 저하 없음
이처럼 cursor 방식은 성능 문제와 데이터 일관성 문제를 모두 해결할 수 있어, 무한 스크롤 구현에 있어 가장 적합한 방식이라고 판단하였다.
해결: no-offset(Cursor)방식의 무한 스크롤
문제를 해결하기 위해 no-offset(Cursor) 방식을 사용하기로 결정했는데,
데이터 중복 및 누락은 커서 기반을 사용하므로써 다음 페이지를 조회할 때 커서 다음 데이터를 조회하도록 하여 중복이나 누락이 되는 문제를 해결하였다.
작성한 코드는 아래와 같다.
public List<ReceiveConversationResponse> findReceiveConversations(Long ownerId, List<Long> conversationMstIds, Long currentMemberId) {
return jpaQueryFactory
.select(Projections.constructor(
ReceiveConversationResponse.class,
conversationMst.id,
conversationMst.guest.id,
conversationMst.owner.id,
conversation.id,
conversation.content,
JPAExpressions.select(
new CaseBuilder()
.when(recommend.count().gt(0))
.then(true) // 고마워요 상태에 대한 조건
.otherwise(false)
).from(recommend)
.where(
recommend.recommendStatus.eq(RecommendStatus.LIKES),
recommend.memberInfo.id.eq(currentMemberId),
recommend.conversation.id.eq(conversation.id)
),
JPAExpressions.select(
new CaseBuilder()
.when(recommend.count().gt(0))
.then(true) // 고마워요 상태에 대한 조건
.otherwise(false)
).from(recommend)
.where(
recommend.recommendStatus.eq(RecommendStatus.THANKED),
recommend.memberInfo.id.eq(currentMemberId),
recommend.conversation.id.eq(conversation.id)
),
conversation.isPrivate,
conversation.isQuestion,
conversation.modifiedAt,
memberInfo.avatarPath,
memberInfo.nickname,
memberInfo.id
))
.from(conversationMst)
.join(conversationMst.conversations, conversation)
.leftJoin(memberInfo).on(
(conversation.isQuestion.isFalse().and(conversationMst.owner.id.eq(memberInfo.id)))
.or(conversation.isQuestion.isTrue().and(conversationMst.guest.id.eq(memberInfo.id)))
)
.where(
conversationMst.owner.id.eq(ownerId),
conversation.isDeleted.isFalse(),
conversationMst.id.in(conversationMstIds)
)
.orderBy(conversationMst.id.desc(), conversation.id.asc())
.fetch();
}
public List<Long> findReceiveMstIdsByOwnerIdAndCursor(Long ownerId, Long cursor) {
return jpaQueryFactory
.select(conversationMst.id)
.from(conversationMst)
.where(
conversationMst.owner.id.eq(ownerId),
ltCursor(cursor)
)
.orderBy(conversationMst.id.desc())
.limit(PAGE_SIZE + 1)
.fetch();
}
private BooleanExpression ltCursor(Long cursor) {
return cursor != null ? conversationMst.id.lt(cursor) : null ;
}@Transactional(readOnly = true)
public ReceiveConversationPagingResponse getReceiveConversations(Long ownerId, Long lastIndex) {
Long userId = getCurrentUserId();
boolean lastPage = true; // 마지막 페이지 여부
List<Long> mstIds = conversationQuerydslRepository.findReceiveMstIdsByOwnerIdAndCursor(ownerId, lastIndex);
if (mstIds.isEmpty()) {
return new ReceiveConversationPagingResponse(Collections.emptyList(), lastPage);
}
if (mstIds.size() > timelinePageSize) { // mstId가 3개를 초과(4개 조회)하면 다음페이지 있음
lastPage = false;
mstIds.remove(mstIds.size() - 1); // 마지막 요소 제거
}
List<ReceiveConversationResponse> receiveConversations = conversationQuerydslRepository.findReceiveConversations(ownerId, mstIds, userId);
return new ReceiveConversationPagingResponse(receiveConversations, lastPage);
}기존 쿼리와 거의 동일하며 limit와 offset 부분을 제거하고 lastIndex를 받아 cursor로 사용하며 cursor를 기준으로 데이터를 조회하도록 하였다.
이 과정에서 데이터를 3개씩 넘겨줘야 하는데 마지막 페이지를 알려주기 위해 mstId를 4개씩 조회해 4개 조회되면 lastPage = false;로 변경하고 조회한 마지막 요소롤 제거하여 mstId 3개에 대한 값을 findReceiveConversations() 메소드로 조회하도록 작성하였다.
성능 테스트
데이터의 중복 및 누락문제를 해결하고, 마지막으로 학습하며 알게 된 offset 기반과 cursor기반 무한 스크롤의 성능 차이도 측정해 보기위해 성능을 테스트 해 봤다.
k6툴을 사용해 코드 변경전 후 각각의 성능 테스트를 진행하였다.
테스트환경은 다음과 같다.
데이터 수 10만개, 가상 사용자 수 20, 테스트 시간 1분
약 10만개의 더미데이터를 집어넣었다.
테스트 코드
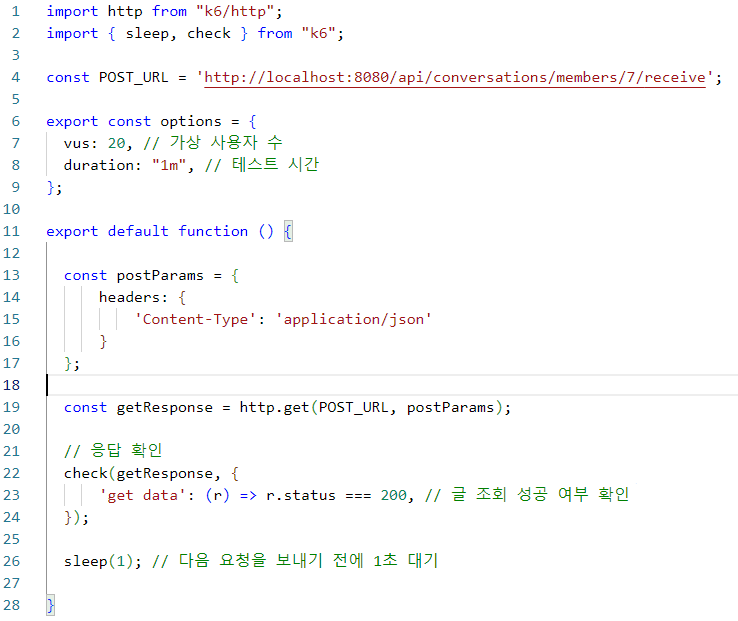
이는 많은 시행을 통해 API 속도의 정확성을 개선하기 위한 테스트이며, 부하 테스트가 아닌 단순 성능 비교를 목적으로 하므로 요청 간 1초의 텀을 두었다.
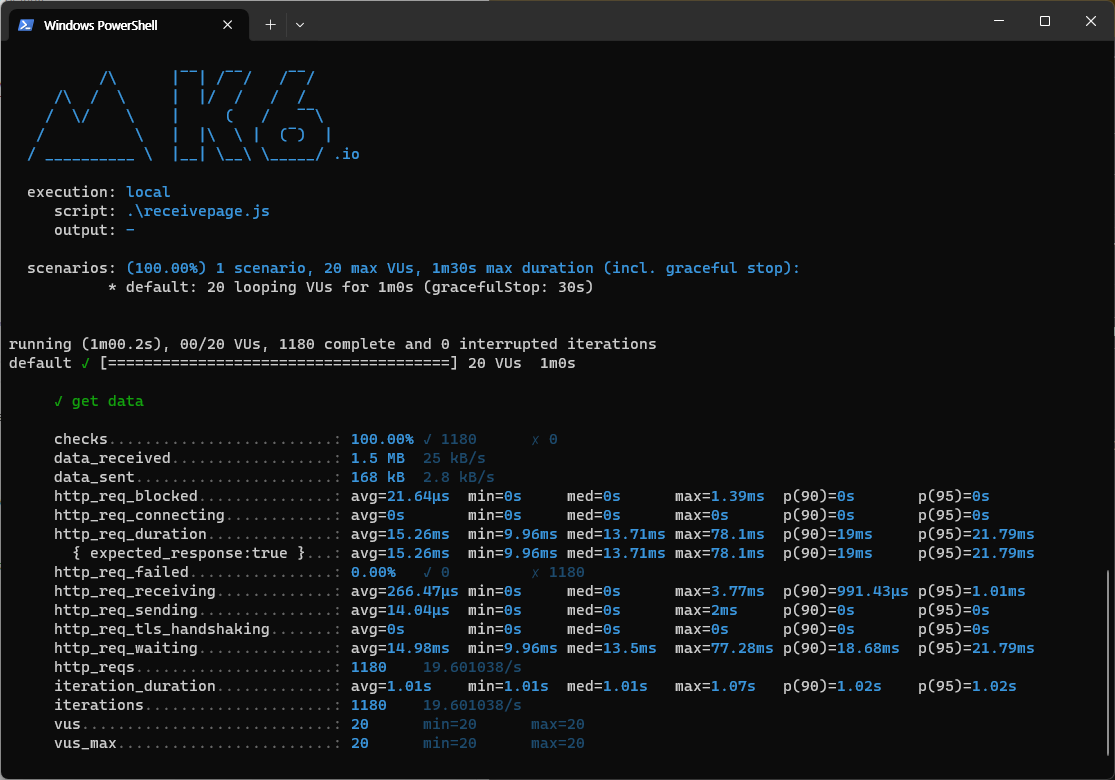
offset 1페이지
no-offset 1페이지
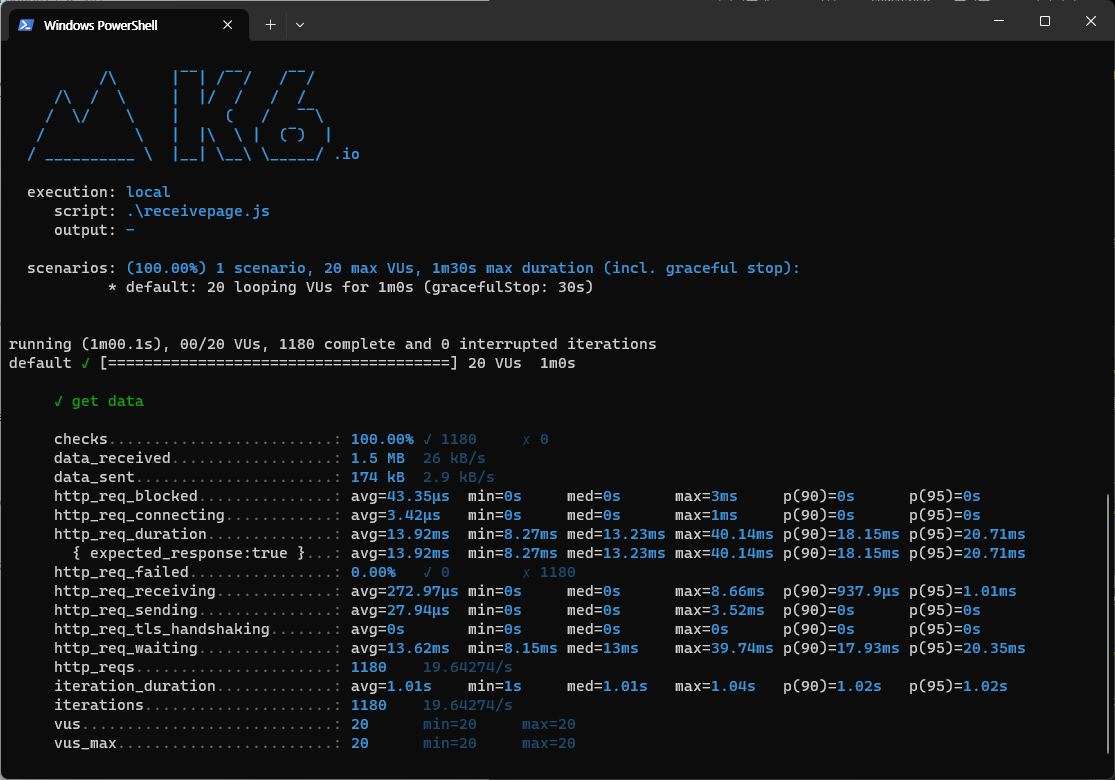
첫 페이지에는 성능에 큰 차이가 나지 않는다.
http_req_duration(총 응답시간)
평균 응답 시간 15.26ms -> 13.92ms
최소 응답 시간 : 9.96ms -> 8.27ms
최대 응답 시간 : 78.1ms -> 40.14ms
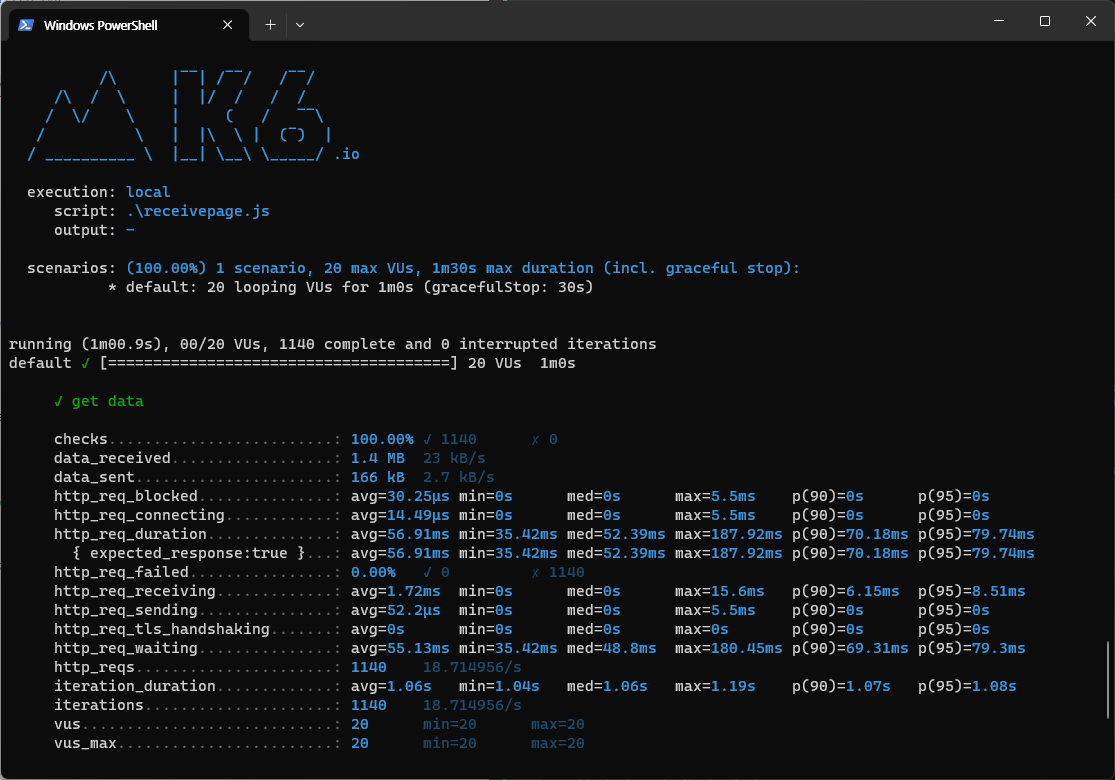
offset 마지막 페이지
no-offset 마지막 페이지
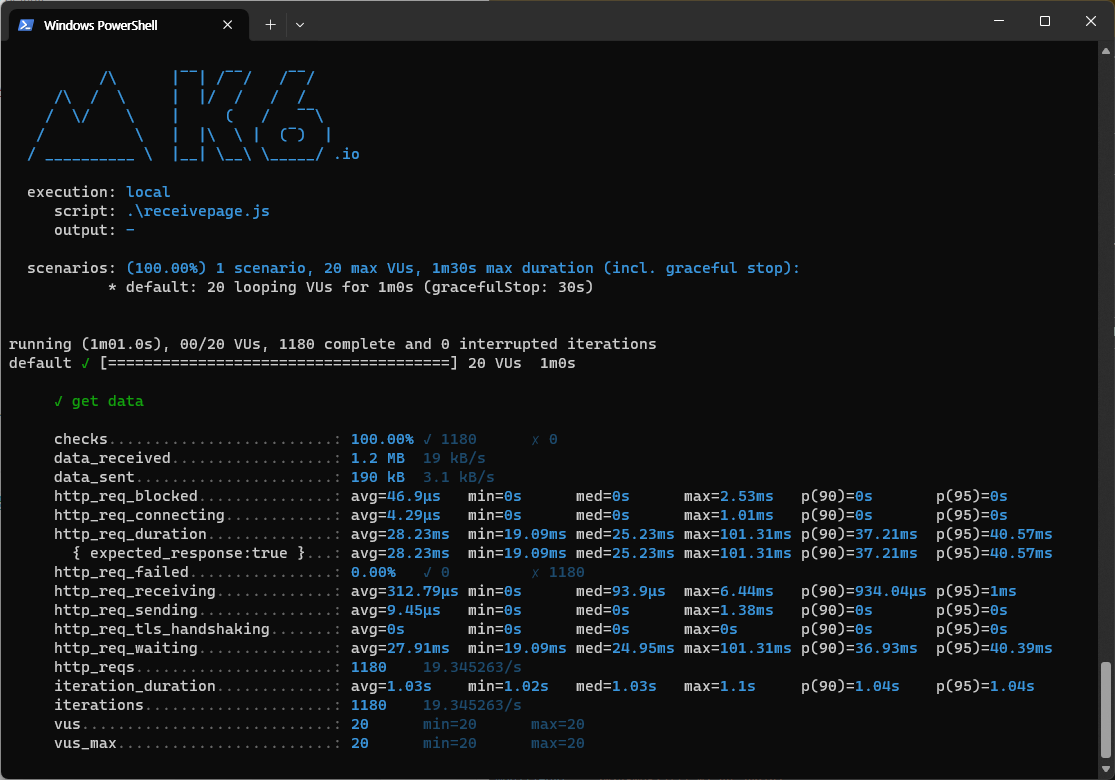
http_req_duration(총 응답시간)
평균 응답 시간 56.91ms -> 28.23ms
최소 응답 시간 : 35.42ms -> 19.09ms
최대 응답 시간 : 187.92ms -> 101.31ms
하지만 데이터 10만개 기준 마지막 페이지에선 평균 응답 시간이
56.91ms -> 28.23ms
2배이상 성능차이를 보여주고 있다.
