- 중복된 문자를 제외하고 사전식 순서(Lexicographical Order)로 나열하라
1. 재귀를 이용한 분리 (52ms)
class Solution:
def removeDuplicateLetters(self, s: str) -> str:
#집합으로 정렬
for char in sorted(set(s)):
suffix = s[s.index(char):]
#전체 집합과 접미사 집합이 일치할 때 분리 진행
if set(s) == set(suffix):
return char + self.removeDuplicateLetters(suffix.replace(char,''))
return ''-
사전식 순서
: 글자 그대로 사전에서 가장 먼저 찾을 수 있는 순서-
bcabc에서 중복 문자를 제외하면 사전에서 가장 먼저 찾을 수 있는 문자열은 abc가 될 것이다.
-
만약, 앞에 e 문자가 하나 더 붙은 ebcabc가 입력값이라면 결과는 eabc가 될 것이다.
-
e 문자 자체는 해당 문자열 내에서 사전 순으로는 가장 뒤에 있지만, e는 입력값에서 딱 한 번만 등장하고 a, b, c는 뒤이어 등장하기 때문에 e의 위치를 변경할 수 없기 때문이다.
-
반면, 입력값이 ebcabce라면 첫 번째 e는 중복으로 제거할 수 있고, 마지막 e를 남겨서 결과는 abce가 될 수 있을 것이다.
-
-
-
중복 문자를 제외한(여기서는 집합으로 처리) 알파벳 순으로 문자열 입력값을 모두 정렬한 다음, 가장 빠른 a부터 접미사 suffix를 분리하여 확인한다.
-
다음 순서는 b인데, b의 경우 c,d가 뒤에 올 수 없기 때문에 이를 기준으로 분리할 수 없다.
-
분리 가능 여부는 이 코드와 같이 전체 집합과 접미사 집합이 일치하는지 여부로 판별한다.
- 집합은 중복된 문자가 제거된 자료형이므로, b를 기준으로 했을 때는 s = {'b', 'c', 'd'}, suffix = {'b', 'c'}가 되며 d를 처리할 수 없으므로 분리할 수 없다. 따라서 다음 순서인 c로 넘긴다.
- 이제 c는 s = {'b', 'c', 'd'}, suffix = {'b','c', 'd'}로 일치 여부를 판별하는 if문이 True이므로 분리할 수 있다.
-
-
이제 여기서 부터 실제로 분리를 처리하게 되는데, 현재 문자, 즉 c를 리턴하는 재귀호출 구조로 처리한다.
- 또한 c는 이미 분리되는 기준점이 되었으므로 이후에 이어지는 모든 c는 replace( )로 제거한다.
- 이렇게 하면 일종의 분할정복과 비슷한 형태로, suffix의 크기는 점점 줄어들게 되고 더 이상 남지 않을 때 백트래킹 되면서 결과가 조합된다.
<재귀를 이용한 분리>
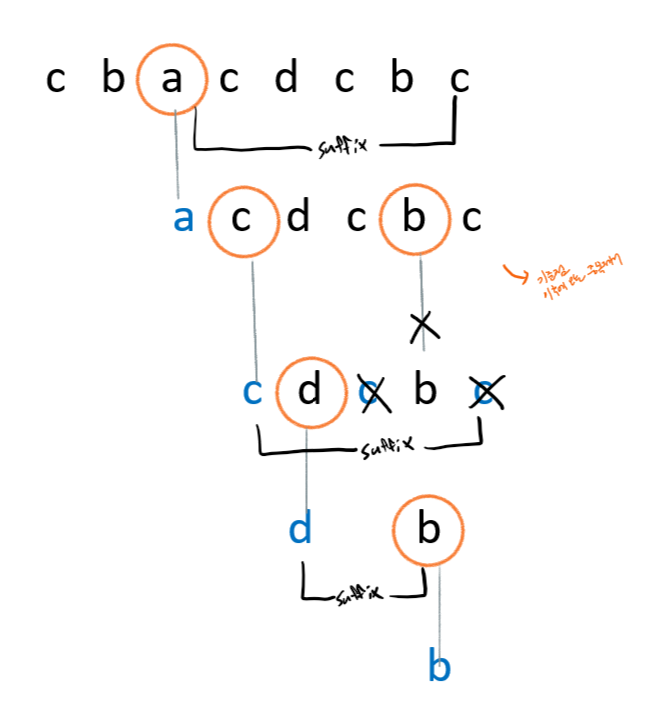
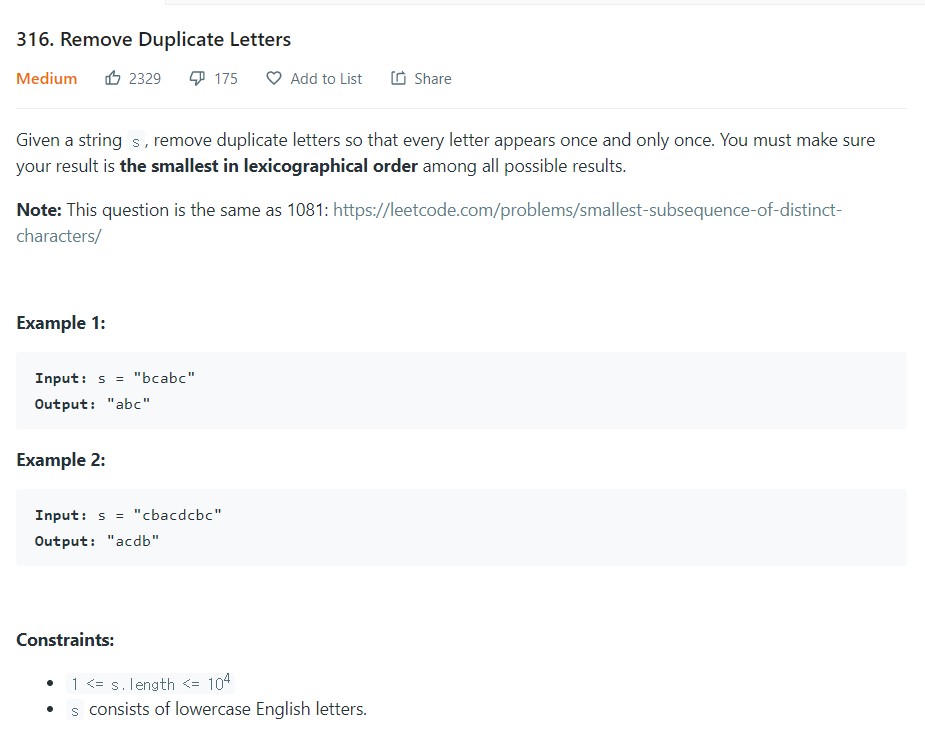
- cbacdcbc를 사전식 순서로 중복 문자를 제거하는 과정의 알고리즘은 다음과 같으며, 결과는 파란색 글자인 acdb가 된다.
2. 스택을 이용한 문자 제거 (32ms)
class Solution:
def removeDuplicateLetters(self, s: str) -> str:
counter, seen, stack = collections.Counter(s), set(), []
for char in s:
counter[char] -= 1
if char in seen:
continue
#뒤에 붙일 문자가 남아 있다면 스택에서 제거
while stack and char < stack[-1] and counter[stack[-1]] > 0:
seen.remove(stack.pop())
stack.append(char)
seen.add(char)
return ''.join(stack)
-
먼저 스택에는 앞에서부터 차례대로 쌓아 나간다
-
만약, 현재 문자 char가 스택에 쌓여 있는 문자 (이전 문자보다 앞선 문자)이고, 뒤에 다시 붙일 문자가 남아 있다면(카운터가 0 이상이라면), 쌓아둔 걸 꺼내서 없앤다.
-
카운팅에는 collections.Counter()를 이용한다.
- 이 모듈은 문자별 개수를 자동으로 카운팅해주기 때문에 다른 장에서도 여러 문제에 다양하게 활용된다.
-
-
seen은 집합 자료형(set)으로 이미 처리된 문자 여부를 확인하기 위해 사용했으며, 이처럼 이미 처리된 문자는 스킵한다.
-
처리된 문자 여부를 확인하기 위해 in을 이용한 검색 연산으로 찾아냈다.
-
해당 기능은 스택에는 존재하지 않는 연산이기 때문에 별도의 집합 자료형에만 사용했다.
-
리스트는 검색도 잘 지원하기 때문에 굳이 스택이라는 자료구조로 한정짓지 않고 풀이한다면 seen변수 없이도 다음과 같은 형태로 얼마든지 풀이가 가능하다.
-
def removeDuplicateLetters(self, s:str) -> str:
counter, stack = collections.Counter(s), []
for char in s:
counter[char] -= 1
if char in stack:
continue
# 뒤에 붙일 문자가 남아 있다면 스택에서 제거
while stack and char < stack[-1] and counter[stack[-1]] > 0:
stack.pop()
stack.append(char)
return ''.join(stack)
- 하지만, 다음과 같은 방식은 스택에 없는 검색 연산을 수행한 변칙적인 풀이 방법이기 때문에, 여기서는 정석대로 스택에서 가능한 연산만을 수행하고 검색 기능은 seen 변수에서 실행되게 하여 다음과 같이 풀이한다.
<스택 문자 제거 풀이>
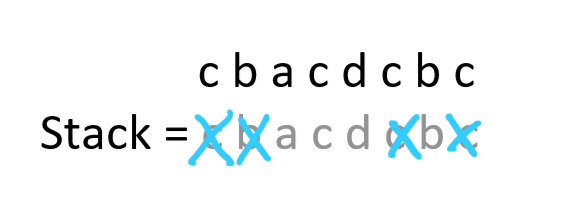
-
cbacdcba에서 a가 들어올 때, 이미 이전에 들어와 있던 c와 b는 다음과 같이 제거된다.
- 카운터가 0 이상인 문자인 c와 b는 뒤에 다시 붙일 문자가 남아 있기 때문이다.
