



re
Have to understand about re library
참고
findall
- 내가 찾아야 하는 문자열이 얼마나 들어있는 지와 문자열을 다양한 방법으로 분리하고 싶을 때 이용한다.
import re
text = "this is String!!"
li = re.findall(r'[\s\S]*',text)
-
findall 을 쓰면 list로 반환해준다.
- 참고로 [\s\S]* 는 모든 문자(특수 + 공백 + ... )에 매치된다.
-
findall을 이용하면 문자열의 split도 쉽게 할 수 있다.
-
예를 들어,
text = "this is my birthday thank you"라는 text가 있고 공백 기준으로 나누려고 한다.즉, ["this","is","my","birthday","thank","you"] 로 결과를 얻고 싶다
-
re.findall(r'[a-zA-Z]+',text)
- 위 처럼하면 모든 영문자들만 찾아 골라서 list로 만들어 준다.
search
- 특정 문자들 사이에 있는 어떠한 문자열을 찾을때 쓰면 유용하다.
re.search(r'<meta[^>]*content="https://([\S]*)"/>',text).group(1)
-
만약 위와 같은 코드가 있다면 "https://(찾고자하는 문자열 그룹1번)" 에서 그룹 1번을 String 으로 반환해준다.
-
주소는 모르지만 주소만 쏙 빼서 준다는 것이다.
1. Python
import re
def solution(word, pages):
#기본점수 = 검색어가 등장하는 횟수
#외부 링크 수 = 다른 외부 페이지로 연결된 링크의 개수
#링크점수 = 해당 웹페이지로 링크가 걸린 다른 웹페이지의 기본점수 ÷ 외부 링크 수의 총합
#매칭점수 = 기본점수 + 링크점수
index = {} #for index -> 'a.com': 0
basic_out_link = {} #for [basic, out] -> 'a.com':[2, 1]
exlink = {} #for exlink -> 'a.com':['b.com', 'c.com']
word = word.lower()
for i in range(len(pages)):
page = pages[i].lower()
url = re.search(r'<meta[^>]*content="https://([\S]*)"/>', page).group(1)
#print(url)
index[url] = i
word_cnt = 0
for find in re.findall(r'[a-zA-Z]+',page):
if find == word:
word_cnt += 1
s = set()
for e in re.findall(r'<a href="https://[\S]*">',page):
s.add(re.search(r'"https://([\S]*)"',e).group(1))
s = list(s)
basic_out_link[url] = list()
basic_out_link[url].append(word_cnt)
basic_out_link[url].append(len(s))
for e in s:
if e not in exlink:
exlink[e] = list()
exlink[e].append(url)
answer = []
for k, v in basic_out_link.items():
score = v[0]
if k in exlink:
for u in exlink[k]:
score += basic_out_link[u][0] / basic_out_link[u][1]
answer.append([score, index[k]])
return sorted(answer, key = lambda x: [-x[0], x[1]] )[0][1]
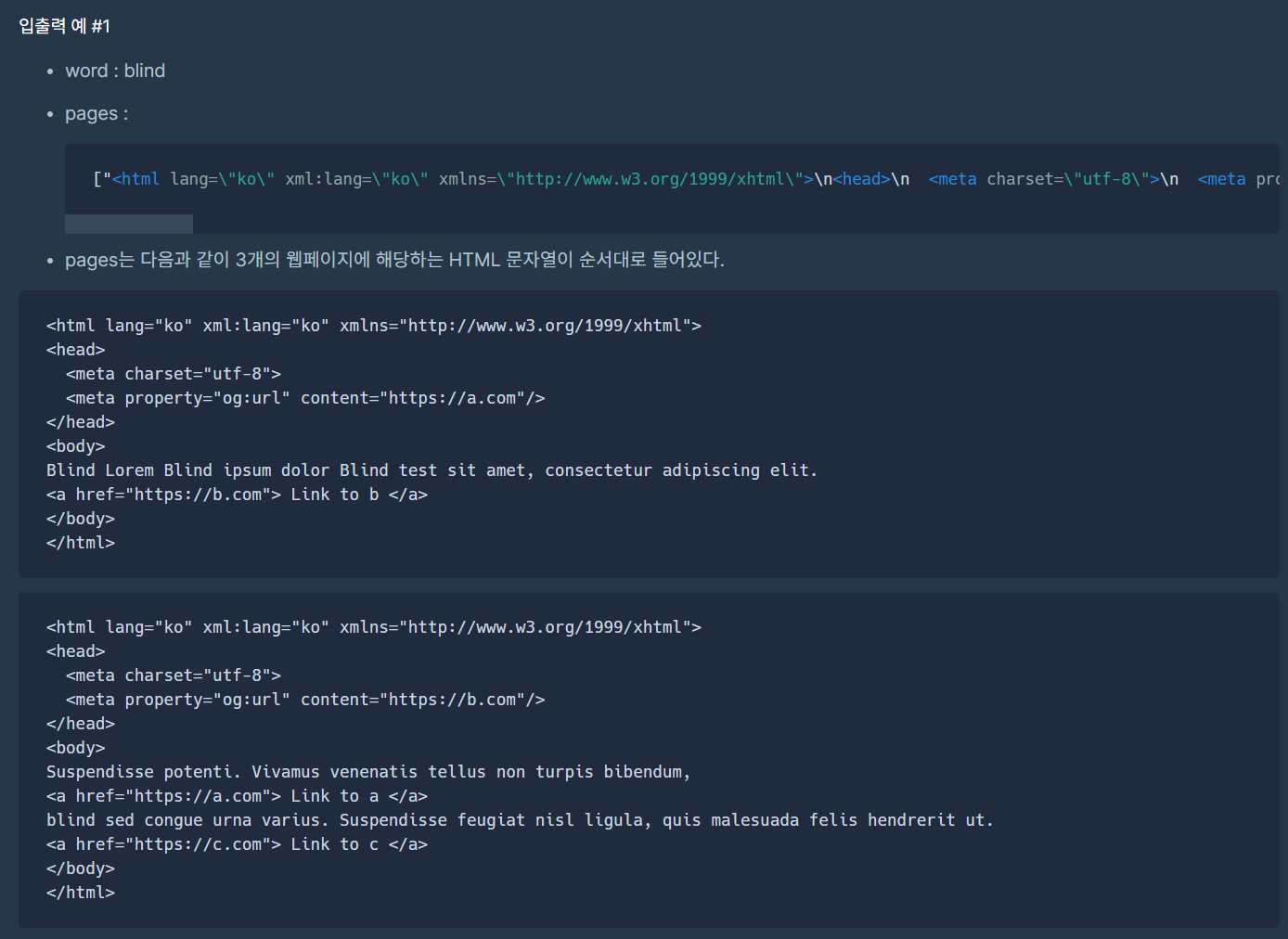
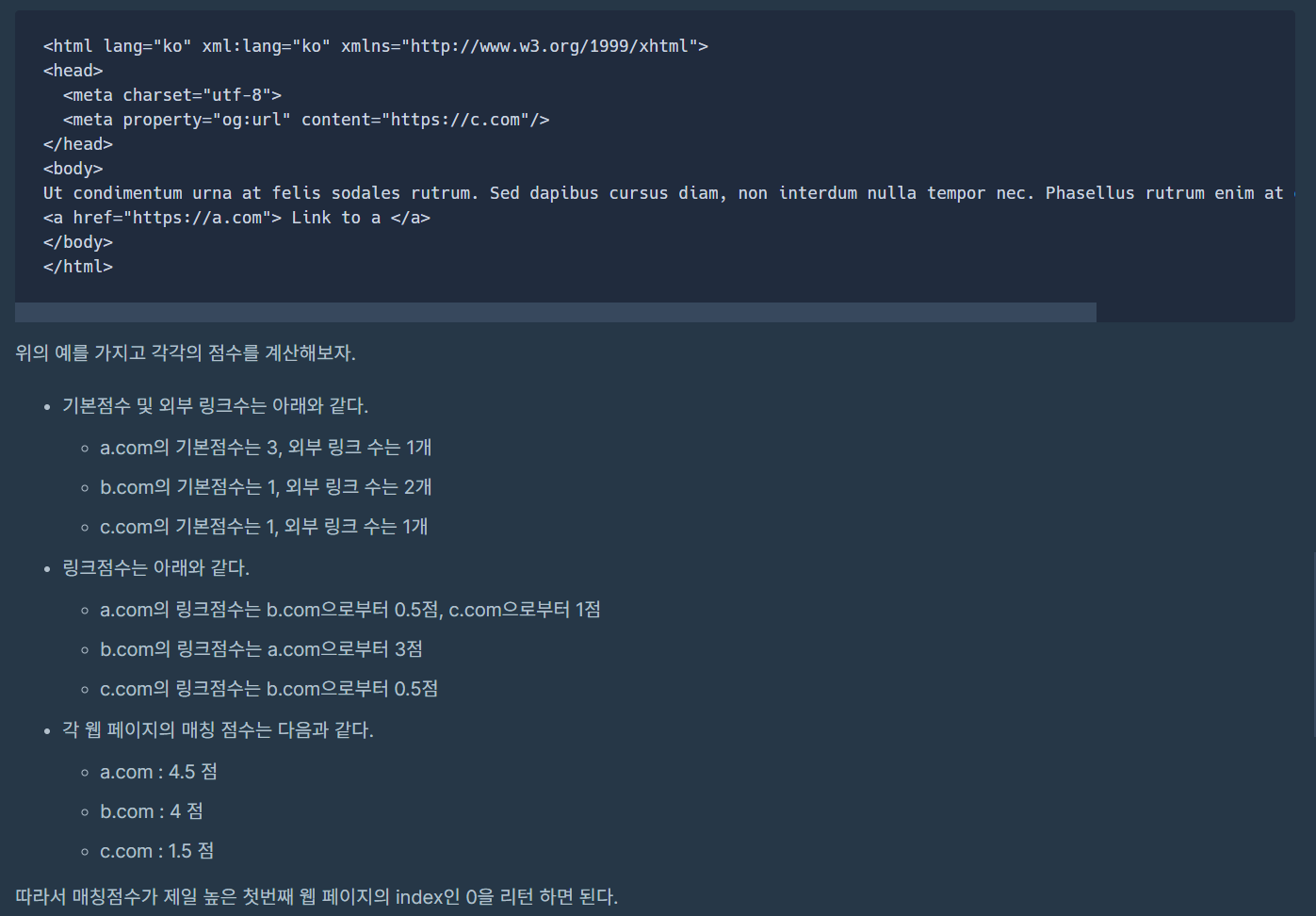
print(solution("word", ["<html lang=\"ko\" xml:lang=\"ko\" xmlns=\"http://www.w3.org/1999/xhtml\">\n<head>\n <meta charset=\"utf-8\">\n <meta property=\"og:url\" content=\"https://a.com\"/>\n</head> \n<body>\nBlind Lorem Blind ipsum dolor Blind test sit amet, consectetur adipiscing elit. \n<a href=\"https://b.com\"> Link to b </a>\n</body>\n</html>", "<html lang=\"ko\" xml:lang=\"ko\" xmlns=\"http://www.w3.org/1999/xhtml\">\n<head>\n <meta charset=\"utf-8\">\n <meta property=\"og:url\" content=\"https://b.com\"/>\n</head> \n<body>\nSuspendisse potenti. Vivamus venenatis tellus non turpis bibendum, \n<a href=\"https://a.com\"> Link to a </a>\nblind sed congue urna varius. Suspendisse feugiat nisl ligula, quis malesuada felis hendrerit ut.\n<a href=\"https://c.com\"> Link to c </a>\n</body>\n</html>", "<html lang=\"ko\" xml:lang=\"ko\" xmlns=\"http://www.w3.org/1999/xhtml\">\n<head>\n <meta charset=\"utf-8\">\n <meta property=\"og:url\" content=\"https://c.com\"/>\n</head> \n<body>\nUt condimentum urna at felis sodales rutrum. Sed dapibus cursus diam, non interdum nulla tempor nec. Phasellus rutrum enim at orci consectetu blind\n<a href=\"https://a.com\"> Link to a </a>\n</body>\n</html>"]))

For the sake of someone who studies computer science