-
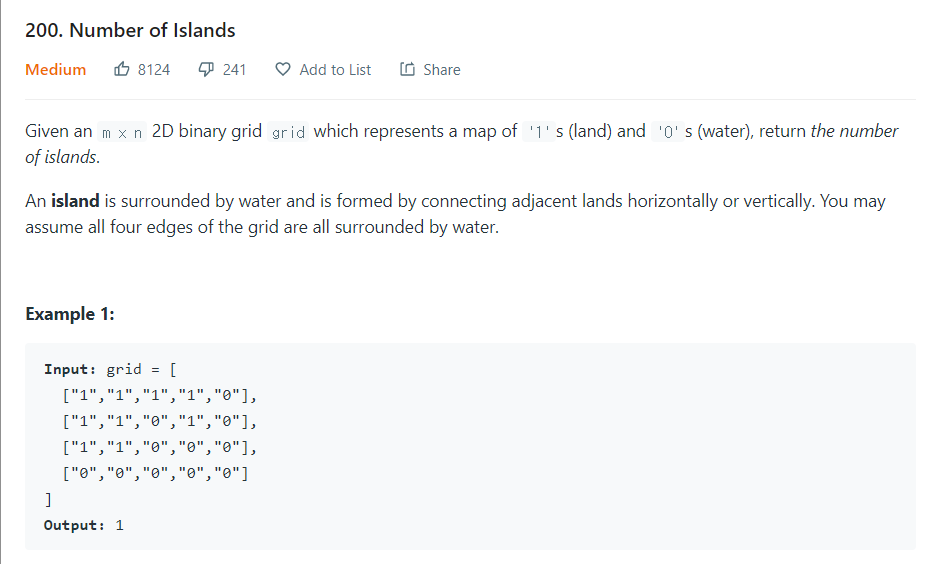
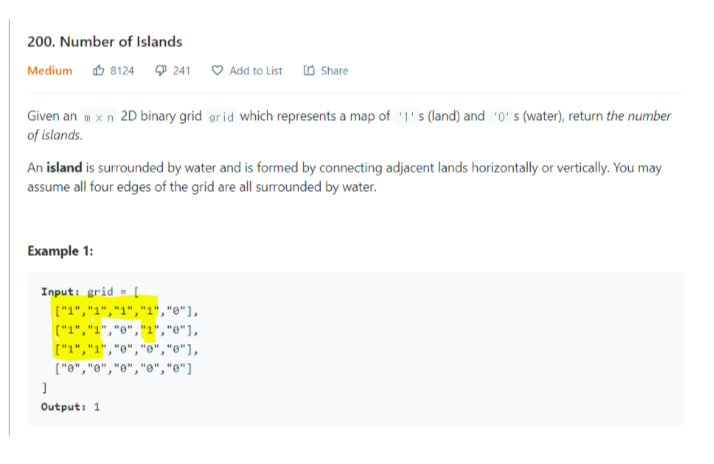
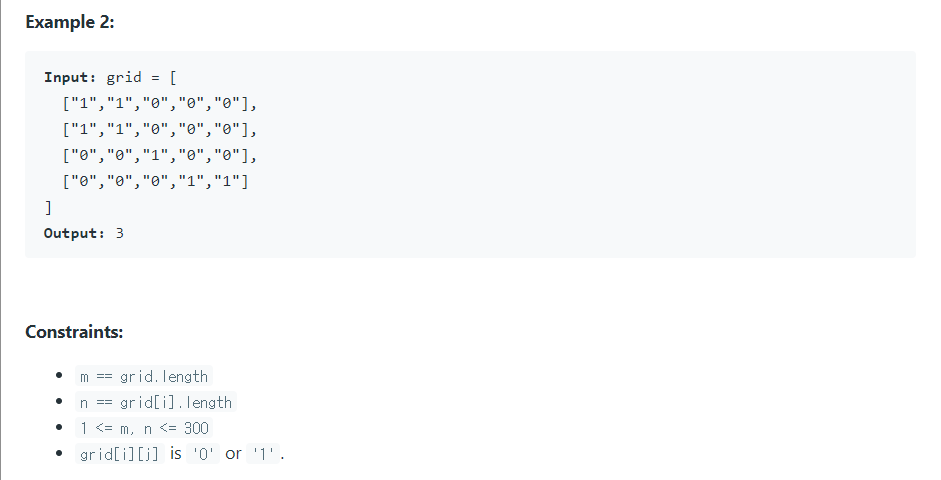
1을 육지로, 0을 물로 가정한 2D 그리드 맵이 주어졌을 때, 섬의 개수를 계산하라.
- 연결되어 있는 1의 덩어리 개수를 구하라
1. DFS 재귀를 이용
class Solution:
def dfs(self, grid: List[List[str]], i:int, j:int):
#더 이상 땅이 아닌 경우 종료 #'\'기호는 다음줄로 이어진다는 표시
if i < 0 or i >= len(grid) or \
j < 0 or j >= len(grid[0]) or \
grid[i][j] != '1':
return
grid[i][j] = '0' #마킹
#동서남북 탐색
self.dfs(grid, i+1, j)
self.dfs(grid, i-1, j)
self.dfs(grid, i, j+1)
self.dfs(grid, i, j-1)
def numIslands(self, grid: List[List[str]]) -> int:
#예외 처리
if not grid:
return 0
count = 0
for i in range(len(grid)):
for j in range(len(grid[0])):
if grid[i][j] == '1':
self.dfs(grid, i, j)
#모든 육지 탐색 후 카운트 1증가
count +=1
return count
-
이 문제는 반드시 그래프 모양이 아니더라도 그래프형으로 변환해서 풀이할 수 있음을 확인해보는 좋은 문제다.
-
입력값이 정확히 그래프는 아니지만 사실상 동서남북이 모두 연결된 그래프로 가정하고 동일한 형태로 처리할 수 있으며, 네 방향 각각 DFS 재귀를 이용해 탐색으 끝마치면 1이 증가하는 형태로 육지의 개수를 파악할 수 있다.
-
먼저, 행렬(Matrix) 입력값인 grid의 행(Rows), 열(Cols) 단위로 육지(1)인 곳을 찾아 진행하다가 육지를 발견하면 그때부터 self.dfs()를 호출해 탐색을 시작한다.
-
DFS 탐색을 하는 dfs( )함수는 동서남북을 모두 탐색하면서 재귀호출한다.
-
함수 상단에는 육지가 아닌 곳은
return으로 종료 조건을 설정해둔다. -
이렇게 재귀 호출이 백트래킹으로 모두 빠져 나오면 섬 하나를 발견한 것으로 간주한다.
-
이미 방문했던 곳은 1이 아닌 값으로 마킹한다.
-
여기서는
grid[i][j] = '0'을 통해 다시 0으로 설정했으나 #이나 0 등 육지가 아닌 것으로 만들기만 하면 된다. -
그래야만 다음에 다시 계산하는 경우가 생기지 않는다. 일종의 가지치기다.
-
-
간혹 또 다른 행렬을 생성해 그곳에 방문했던 경로를 저장하는 형태로 풀이하는 경우가 있는데, 이 문제는 그렇게 풀이할 필요가 없다.
- 별도의 행렬을 생성할 경우 공간 복잡도가 O(n)이 되기 때문에 공간의 활용 또한 비효율적이다.
-
-
dfs( )함수를 빠져 나온 후에는 해당 위치에서 탐색할 수 있는 모든 육지를 탐색한 것이므로, 카운트를 1 증가시킨다.
2. 코드 리팩토링
...
#동서남북 탐색
self.dfs(grid, i+1, j)
self.dfs(grid, i-1, j)
self.dfs(grid, i, j+1)
self.dfs(grid, i, j-1)
...
-
다음과 같이 dfs( ) 함수를 호출할 때마다
self.sfs(grid, i+1, j)와 같은 형태로 grid 변수를 매번 넘기는 것을 확인할 수 있다.이 부분을 개선해보자.
1) 클래스의 멤버 변수로 선언
class Solution:
grid: List[List[str]] #클래스 멤버 변수로 선언
def dfs(self, i:int, j:int):
#더 이상 땅이 아닌 경우 종료 #'\'기호는 다음줄로 이어진다는 표시
if i < 0 or i >= len(grid) or \
j < 0 or j >= len(grid[0]) or \
grid[i][j] != '1':
return
...
def numIslands(self, grid: List[List[str]]) -> int:
self.grid = grid
...
self.dfs(grid, i, j)
...
return count
-
grid를 클래스 멤버 변수로 선언하여 클래스 내에서 모두 공유하게 되면 더 이사아 grid를 매번 넘기지 않아도 된다.
-
하지만 여전히 함수 호출 시 매번
self.가 따라 붙는 등 보기가 좋지 않다.
다른 방법을 알아보자.
2) 파이썬의 중첩함수(Nested Function)
class Solution:
def numIslands(self, grid: List[List[str]]) -> int:
def dfs(i, j):
#더 이상 땅이 아닌 경우 종료 #'\'기호는 다음줄로 이어진다는 표시
if i < 0 or i >= len(grid) or \
j < 0 or j >= len(grid[0]) or \
grid[i][j] != '1':
return
grid[i][j] = '0' #마킹
#동서남북 탐색
dfs(i+1, j)
dfs(i-1, j)
dfs(i, j+1)
dfs(i, j-1)
#예외 처리
if not grid:
return 0
count = 0
for i in range(len(grid)):
for j in range(len(grid[0])):
if grid[i][j] == '1':
dfs(i, j)
#모든 육지 탐색 후 카운트 1증가
count +=1
return count
-
numIslands( ) 함수 내에 dfs( ) 함수 전체가 중첩 함수로 들어갔다.
-
이렇게 할 시, numIslands( ) 함수에서만 dfs( ) 함수 호출이 가능한 제약이 생긴다.
-
하지만, 중첩 함수는 부모 함수에서 선언한 변수도 유효한 범위 내에서 사용할 수 있다.
- 여기서 dfs( ) 함수는 numIslands( ) 함수에서 선언된 변수를 자유롭게 사용 가능하다.
-
-
덕분에 grid 변수뿐만 아니라 지저분하게 매번 따라다니던
self.구문 또한 제거할 수 있어 dfs( ) 함수가 깔끔해졌고, 코드 전체가 훨씬 더 깔끔해졌다.
✔ 그래프 순회
-
그래프 순회
- 그래프 탐색(Search)라고도 불리우며, 그래프의 각 정점을 방문하는 과정을 말한다.
그래프의 각 정점을 방문하는 그래프 순회에는 크게 2가지 알고리즘이 있다.
-
깊이 우선 탐색(Depth-First Search)
-
주로, 스택으로 구현하거나 재귀로 구현하며, 백트래킹을 통해 뛰어난 효용을 보인다.
-
일반적으로 BFS에 비해 더 널리 쓰인다.
-
코딩 테스트 시에도 대부분의 그래프 탐색은 DFS로 구현하게 될 것이다.
-
-
너비 우선 탐색(Breadth-First Search)
- 주로, 큐로 구현하며 그래프의 최단 경로를 구하는 문제 등에 사용된다.
그래프를 표현하는 방법에는 2가지 방법이 있다.
-
인접 행렬(Ajacency Matrix)
-
인접 리스트(Ajacency List)
-
출발 노드를 키로, 도착 노드를 값으로 표현할 수 있다.
-
도착 노드는 여러 개가 될 수 있으므로 리스트 형태가 된다.
- 파이썬의 딕셔너리 자료형으로 다음과 같이 나타낼 수 있다.

-
graph = {
1: [2, 3, 4],
2: [5],
3: [5],
4: [],
5: [6, 7],
6: [],
7: [3],
}DFS(깊이 우선 탐색)
재귀 구조로 표현
<재귀를 이용한 DFS 구현 수도코드>
DFS(G, v)
label v as discovered
for all directed edges from v to w that are in G.adjacentEdges(v) do
if vertex w is not labeled as discovered then
recursively call DFS(G, w)
- 이 수도코드에는 정점 v의 모든 인접 유향(Directed) 간선들을 반복하라고 표기되어 있다.
<수도코드의 알고리즘을 파이썬 코드로 구현>
def recursive_dfs(v, discovered=[]):
discovered.append(v)
for w in graph[v]:
if not w in discovered:
discovered = recursive_dfs(w, discovered)
return discovered
- 방문했던 정점, 즉 discovered를 계속 누적된 결과로 만들기 위해 리턴하는 형태만 받아오도록 처리했을뿐, 나머지는 수도코드와 동일하다.
- 위의 그래프를 입력값으로 한 탐색결과는 다음과 같다.
>>> f'recursive dfs: {recursive_dfs(1)}'
'recursive dfs: [1, 2, 5, 6, 7, 3, 4]'

BFS(너비 우선 탐색)
- BFS는 DFS보다 쓰임새는 적지만, 최단 경로를 찾는 다익스트라 알고리즘 등에 매우 유용하게 쓰인다.
큐를 이용한 반복 구조로 표현
<큐를 이용한 BFS 수도코드>
BFS(G, start_v)
let Q be a queue
label start_v as discovered
Q.enqueue(start_v)
while Q is not empty do
v := Q.dequeue()
if v is the goal then
return v
for all edges from v to w in G.adjacentEdges(v) do
if w is not labeled as discovered then
label w as discovered
w.parent := v
Q.enqueue(w)- 모든 인접 간선을 추출하고 도착점인 정접을 큐에 삽입하는 수도코드다.
<수도코드의 알고리즘을 파이썬 코드로 구현>
def iterative_bfs(start_v):
discovered = [start_v]
queue = [start_v]
while queue:
v = queue.pop(0)
for w in graph[v]:
if w not in discovered:
discovered.append(w)
queue.append(w)
return discovered
-
리스트 자료형을 사용했지만 pop(0)과 같은 큐의 연산만을 사용했다.
-
따라서 큐를 사용하는 것과 사실상 동일하다.
-
최적화를 위해서는 데크 같은 자료형을 사용해 보는 것을 고려할 수 있다.
-
-
위의 그래프를 입력값으로 한 탐색결과는 다음과 같다.
>>> f'iterative bfs: {iterative bfs(1)}'
'recursive dfs: [1, 2, 3, 4, 5, 6, 7]'
- BFS의 경우 단계별 차례인 숫자 순으로 실행됐으며, 1부터 순서대로 각각의 인접 노드를 우선으로 방문하는 너비 우선 탐색이 잘 실행됐음을 확인할 수 있다.
➕ BFS는 재귀로 동작하지 않는다. 큐를 이용하는 반복 구현만 가능하다.
