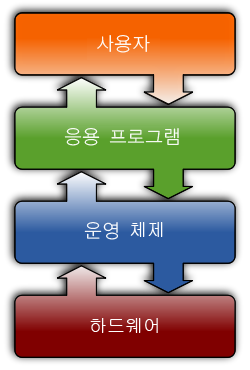
1. 운영체제(Operating System, OS)란?
-
시스템 소프트웨어(system software)
-
응용 소프트웨어를 실행하기 위한 플랫폼을 제공하고 컴퓨터 하드웨어를 동작, 접근할 수 있도록 설계된 컴퓨터 소프트웨어
-
시스템 소프트웨어에는 로더, 운영 체제, 장치 드라이버, 프로그래밍 도구, 컴파일러, 어셈블러, 링커, 유틸리티 등이 포함한다.
-
-
운영체제는 시스템의 자원과 동작을 관리하는 소프트웨어다.
- 시스템의 역할 구분에 따라 운영체제의 역할은 모두 다를 수 있다.
-
일반적으로 하드웨어를 관리하고, 응용 프로그램과 하드웨어 사이에서 인터페이스 역할을 하며 시스템의 동작을 제어하는 시스템 소프트웨어로 정의한다.
-
하드웨어를 움직이게 할 수 있는 권한은 운영체제만 가질 수 있다.
-
운영체제는 CPU 메모리, 하드디스크 등의 하드웨어를 관리해주고, 내 컴퓨터와 다른 컴퓨터들이 대화할 수 있도록 도와주는 등 많은 일들을 해주는 소프트웨어다.
-
-
운영체제가 있기 때문에 마우스가 어떻게 컴퓨터에서 인식되는지, 마우스 움직임이 모니터 화면에 어떻게 표시되는지, 카톡에서 보낸 메시지가 저 멀리 떨어진 다른 컴퓨터로 어떻게 보내지는지, 모니터에 사진이 어떻게 나타나는 지 신경 쓸 필요가 없다.
-
운영체제는 상용 소프트웨어인 윈도우(Window), 프리웨어인 리눅스(Linux) 등이 있다.
-
운영체제의 역할
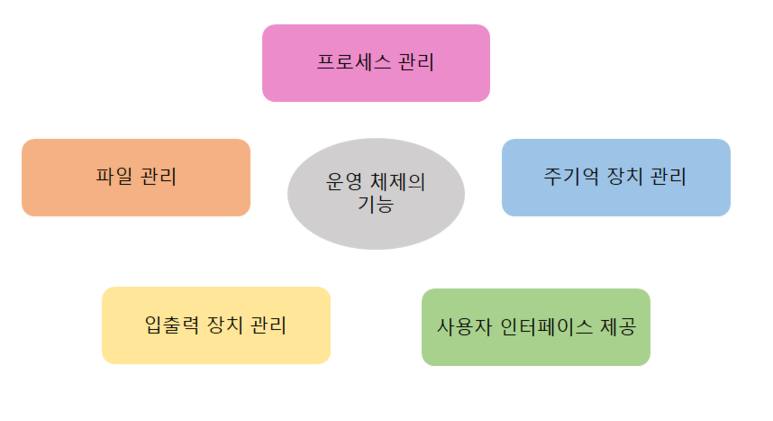
1) 프로세스 관리
-
프로세스, 스레드
-
스케줄링
-
동기화
-
IPC 통신
2) 저장장치 관리
-
메모리 관리
-
가상 메모리
-
파일 시스템
3) 네트워킹
-
TCP/IP
-
기타 프로토콜
4) 사용자 관리
-
계정 관리
-
접근권한 관리
5) 디바이스 드라이버
-
순차접근 장치
-
임의접근 장치
순차 접근 메모리: SAM = Sequential Access Memory.
임의 접근 메모리: RAM = Random Access Memory.
읽기 전용 메모리: ROM = Read Only Memory
읽기 쓰기 메모리: RWM = Read Write Memory -
네트워크 장치
-
1) 프로세스 관리
-
운영체제에서 작동하는 응용 프로그램을 관리하는 기능이다.
-
어떤 의미에서는 프로세서(CPU) 관리하는 것이라고 볼 수도 있다.
- 현재 CPU를 점유해야 할 프로세스를 결정하고, 실제로 CPU를 프로세스에 할당하며, 이 프로세스 간 공유 자원 접근과 통신 등을 관리하게 된다.
2) 저장장치 관리
- 1차 저장장치에 해당하는 메인 메모리와 2차 저장장치에 해당하는 하드디스크, NAND 등을 관리하는 기능이다.
-
1차 저장장치(Main Memory)
-
프로세스에 할당하는 메모리 영역의 할당과 해제
-
각 메모리 영역 간의 침범 방지
-
메인 메모리의 효율적 활용을 위한 가상 메모리 기능
-
-
2차 저장장치(HDD, NAND Flash Memory 등)
-
파일 형식의 데이터 저장
-
이런 파일 데이터 관리를 위한 파일 시스템을 OS에서 관리
-
FAT, NTFS, EXT2, JFS, XFS 등 많은 파일 시스템들이 개발되어 사용 중이다.
-
3) 네트워킹
-
네트워킹은 컴퓨터 활용의 핵심과도 같아졌다.
-
TCP/IP 기반의 인터넷에 연결하거나, 응용 프로그램이 네트워크를 사용하려면 운영체제에서 네트워크 프로토콜을 지원해야 한다.
- 현재 상용 OS들은 다양하고 많은 네트워크 프로토콜을 지원한다.
-
이처럼 운영체제는 사용자와 컴퓨터 하드웨어 사이에 위치해서, 하드웨어를 운영 및 관리하고 명령어를 제어하여 응용 프로그램 및 하드웨어를 소프트웨어적으로 제어 및 관리를 해야한다.
4) 사용자 관리
-
하나의 PC로도 여러 사람이 사용하는 경우가 많다. 그래서 운영체제는 한 컴퓨터를 여러 사람이 사용하는 환경도 지원해야 한다.
- 가족들이 각자의 계정을 만들어 PC를 사용한다면, 이는 하나의 컴퓨터를 여러 명이 사용한다고 말할 수 있다.
-
운영체제는 각 계정을 관리할 수 있는 기능이 필요하다.
- 사용자 별로 프라이버시와 보안을 위해 개인 파일에 대해선 다른 사용자가 접근할 수 없도록 해야 한다.
-
이 밖에도 파일이나 시스템 자원에 접근 권한을 지정할 수 있도록 지원하는 것이 사용자 관리 기능이다.
5) 디바이스 드라이버
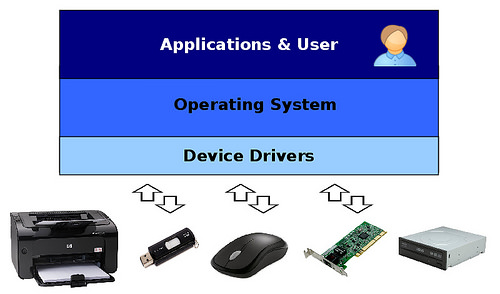
-
운영체제는 시스템의 자원, 하드웨어를 관리한다.
컴퓨터 시스템의 구성 요소
- 사용자(User) : 컴퓨터를 사용하여 원하는 결과를 얻는 대상.
주로 사람이지만, 때로는 컴퓨터, 기계, 통신장비, 로봇 등 일 수도 있다.
컴퓨터 시스템의 궁극적인 혜택을 보는 대상이라고 보면 쉽다.
- 하드웨어(Hardware) : 컴퓨터를 이루는 전자, 기계, 기구 장치 등을 말함.
우리가 눈으로 직접 보고 만질 수 있는 것이라고 보면 된다.
각 종 메뉴얼이나 데이터 매체(CD/DVD타이틀,디스켓...)는 하드웨어가 아니다.- 연산장치, 제어장치, 입력장치, 출력장치, 기억장치(5대장치) 또는,
- CPU, M/B, RAM, HDD, ODD, 비디오/사운드/네트워크 장치,
전원공급장치, 케이스, 키보드, 마우스, 모니터, 프린터 등으로 나누기도 함.
- 소프트웨어(Software) : 컴퓨터를 작동시키는데 필요한 총체적인 지식과 프로그램 등을 말함.
좁은 의미로는 운영체제(OS), 응용프로그램(Application Program), 유틸리티(Utility) 등의 실행 코드 및 파일을 말한다.
- 시스템에는 여러 하드웨어가 붙어있는데, 이들을 운영체제에서 인식하고 관리하게 만들어 응용 프로그램이 하드웨어를 사용할 수 있게 만들어야 한다.
- 사용자(User) : 컴퓨터를 사용하여 원하는 결과를 얻는 대상.
-
따라서, 운영체제 안에 하드웨어를 추상화 해주는 계층이 필요하다. 이 계층이 바로 디바이스 드라이버라고 불린다.
- 하드웨어의 종류가 많은 만큼, 운영체제 내부의 디바이스 드라이버도 많이 존재한다.
-
이러한 수많은 디바이스 드라이버들을 관리하는 기능 또한 운영체제가 맡고 있다.
2. 프로세스 vs 스레드
-
프로그램(Program) : 어떤 작업을 위해 실행할 수 있는 파일
-
프로세스(태스크) : 프로그램을 메모리 상에서 실행중인 작업
-
자원 저장소 (Resource Container)
-
사용자 문맥, 시스템 문맥
-
-
스레드 : 프로세스 안에서 실행되는 여러 흐름 단위
-
제어 흐름 (=경량 프로세스)
-
실행 정보, 레지스터 문맥
-
문맥 교환이 쓰레드 교환일 수 있다. 프로세스 교환보다 훨씬 비용이 적다.
(다른 프로세스 안에 쓰레드가 있을 땐 프로세스 교환일 수 있다. )
-
-
프로세스
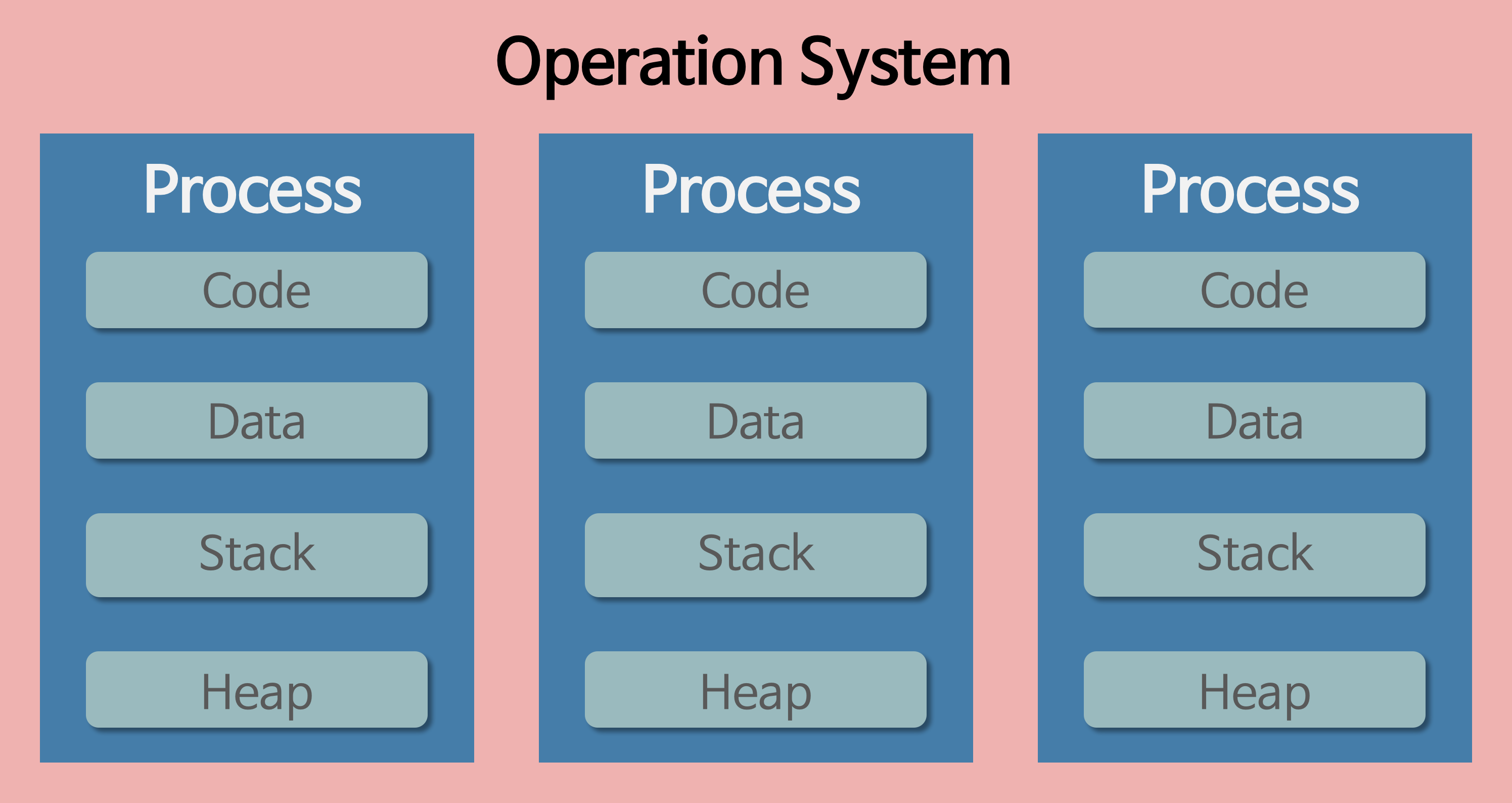
-
컴퓨터에서 연속적으로 실행되고 있는 컴퓨터 프로그램
-
메모리에 올라와 실행되고 있는 프로그램의 인스턴스(독립적인 개체)
-
운영체제로부터 시스템 자원을 할당받는 작업의 단위
- 즉, 동적인 개념으로는 실행된 프로그램을 의미한다.
-
특징
-
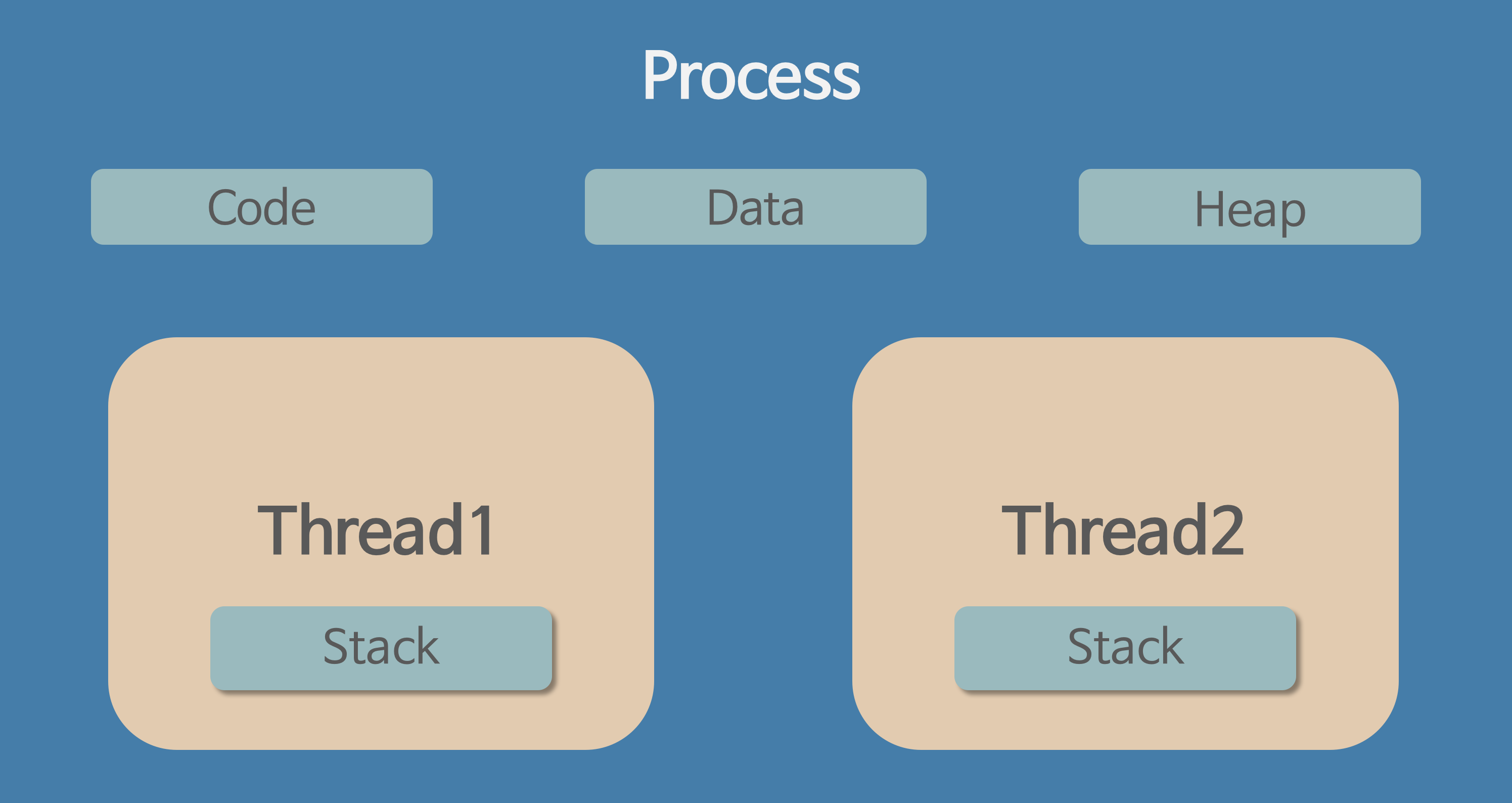
프로세스는 각각 독립된 메모리 영역(Code, Data, Stack, Heap의 구조)을 할당받는다.
-
Code : 코드 자체를 구성하는 메모리 영역(프로그램 명령)
-
Data : 전역변수, 정적변수, 배열 등
-
초기화 된 데이터는 data 영역에 저장
-
초기화 되지 않은 데이터는 bss(block started by symbol) 영역에 저장
- bss는 초기화가 되지 않은 공간을 한곳에 모아두는 곳
-
-
Heap : 동적 할당 시 사용 (new(), malloc() 등)
-
Stack : 지역변수, 매개변수, 리턴 값 (임시 메모리 영역)
-
-
-
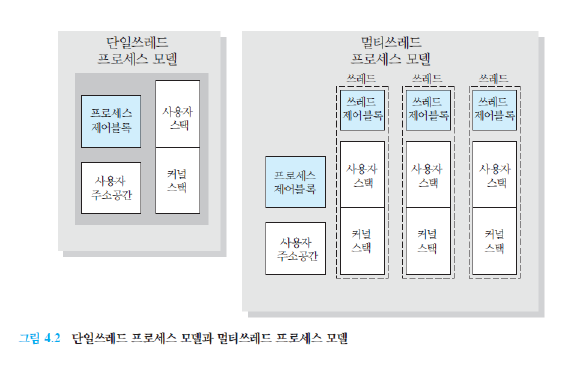
기본적으로 프로세스마다 최소 1개의 스레드 소유 (메인 스레드 포함)
- 하나의 프로세스가 생성될 때, 기본적으로 하나의 스레드 같이 생성
-
각 프로세스는 별도의 주소 공간에서 실행되며, 한 프로세스는 다른 프로세스의 변수나 자료구조에 접근할 수 없다.
-
한 프로세스가 다른 프로세스의 자원에 접근하려면 프로세스 간의 통신(IPC, inter-process communication)을 사용해야 한다.
- 파이프, 파일, 소켓 등을 이용한 통신 방법 이용
스레드
-
프로세스 내에서 실행되는 여러 흐름의 단위
-
프로세스의 특정한 수행 경로
-
프로세스가 할당받은 자원을 이용하는 실행의 단위
-
특징
-
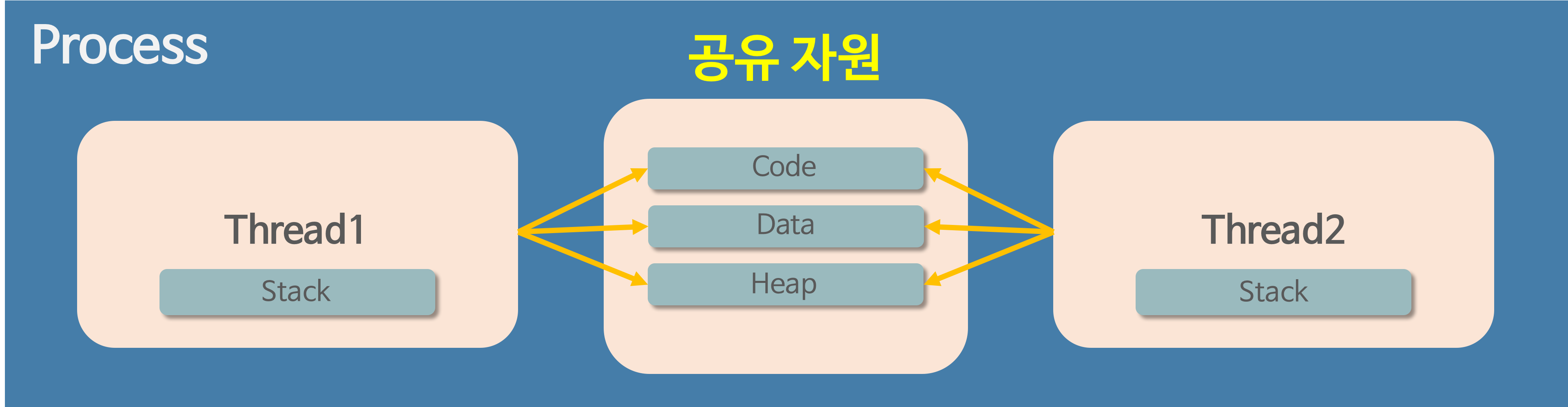
스레드는 프로세스 내에서 각각 Stack만 따로 할당받고 Code, Data, Heap 영역은 공유한다.
-
스레드는 한 프로세스 내에서 동작되는 여러 실행의 흐름으로, 프로세스 내의 주소 공간이나 자원들(힙 공간 등)을 같은 프로세스 내에 스레드끼리 공유하면서 실행된다.
-
같은 프로세스 안에 있는 여러 스레드들은 같은 힙 공간을 공유한다. 반면에 프로세스는 다른 프로세스의 메모리에 직접 접근할 수 없다.
-
각각의 스레드는 별도의 레지스터와 스택을 갖고 있지만, 힙 메모리는 서로 읽고 쓸 수 있다.
-
한 스레드가 프로세스 자원을 변경하면, 다른 이웃 스레드(sibling thread)도 그 변경 결과를 즉시 볼 수 있다.
-
멀티 프로세스
-
하나의 컴퓨터에 여러 CPU 장착 → 하나 이상의 프로세스들을 동시에 처리(병렬)
-
멀티 프로세싱
- 하나의 응용프로그램을 여러 개의 프로세스로 구성하여 각 프로세스가 하나의 작업(태스크)을 처리하도록 하는 것이다.
-
장점
-
안전성 (메모리 침범 문제를 OS 차원에서 해결)
- 여러 개의 자식 프로세스 중 하나에 문제가 발생하면 그 자식 프로세스만 죽는 것 이상으로 다른 영향이 확산되지 않는다.
-
-
단점
-
각각 독립된 메모리 영역을 갖고 있어, 작업량 많을 수록 오버헤드 발생.
-
문맥 교환(Context Switching)으로 인한 성능 저하
-
Context Switching 과정에서 캐쉬 메모리 초기화 등 무거운 작업이 진행되고 많은 시간이 소모되는 등의 오버헤드가 발생하게 된다.
-
프로세스는 각각의 독립된 메모리 영역을 할당받았기 때문에 프로세스 사이에서 공유하는 메모리가 없어, Context Switching가 발생하면 캐쉬에 있는 모든 데이터를 모두 리셋하고 다시 캐쉬 정보를 불러와야 한다.
-
-
-
프로세스 사이의 어렵고 복잡한 통신 기법(IPC)
- 프로세스는 각각의 독립된 메모리 영역을 할당받았기 때문에 하나의 프로그램에 속하는 프로세스들 사이의 변수를 공유할 수 없다.
-
Context Switching이란?
- 프로세스의 상태 정보를 저장하고 복원하는 일련의 과정
- 즉, 동작 중인 프로세스가 대기하면서 해당 프로세스의 상태를 보관하고, 대기하고 있던 다음 순번의 프로세스가 동작하면서 이전에 보관했던 프로세스 상태를 복구하는 과정을 말함
- 프로세스는 각 독립된 메모리 영역을 할당받아 사용되므로, 캐시 메모리 초기화와 같은 무거운 작업이 진행되었을 때 오버헤드가 발생할 문제가 존재함
멀티 스레드
-
멀티 스레딩
-
하나의 응용 프로그램에서 여러 스레드를 구성해 각 스레드가 하나의 작업을 처리하는 것
-
스레드들이 공유 메모리를 통해 다수의 작업을 동시에 처리하도록 해준다.
-
윈도우, 리눅스 등 많은 운영체제들이 멀티 프로세싱을 지원하고 있지만 멀티 스레딩을 기본으로 하고 있다.
-
웹 서버는 대표적인 멀티 스레드 응용 프로그램이다.
-
-
장점
-
시스템 자원 소모 감소 (자원의 효율성 증대)
- 프로세스를 생성하여 자원을 할당하는 시스템 콜이 줄어들어 자원을 효율적으로 관리할 수 있다.
-
시스템 처리량 증가 (처리 비용 감소)
-
스레드 간 데이터를 주고 받는 것이 간단해지고 시스템 자원 소모가 줄어들게 된다.
-
스레드 사이의 작업량이 작아 Context Switching이 빠르다.
-
-
간단한 통신 방법으로 인한 프로그램 응답 시간 단축
- 스레드는 프로세스 내의 Stack 영역을
-
-
단점
-
안전성 문제
- 멀티 스레드의 경우 자원 공유의 문제가 발생한다. (동기화 문제)
-
하나의 스레드가 데이터 공간 망가뜨리면, 모든 스레드가 작동 불능 상태
- 공유 메모리를 갖기 때문
-
멀티스레드의 안전성에 대한 단점은 임계 구역(Critical Section) 기법을 통해 대비
-
하나의 스레드가 공유 데이터 값을 변경하는 시점에 다른 스레드가 그 값을 읽으려할 때 발생하는 문제를 해결하기 위한 동기화 과정
-
임계 구역은 사용자 수준 쓰레드를 사용한다.
사용자 수준 스레드(User-level thread, ULT), 커널 수준 스레드(Kernel-level thread, KLT)
- 사용자 수준 스레드는 스레드 교환 / 교체 시에 커널 모드 권한이 불필요(두 번의 모드 전이 오버헤드 절약 가능)
- 쓰레드 관리를 위한 모든 자료구조가 프로세스의 사용자 주소 공간에 있기 때문
- 사용자 수준 스레드는 스레드 교환 / 교체 시에 커널 모드 권한이 불필요(두 번의 모드 전이 오버헤드 절약 가능)
-
-
상호 배제, 진행, 한정된 대기를 충족해야 한다.
-
-
3. 프로세스 주소 공간
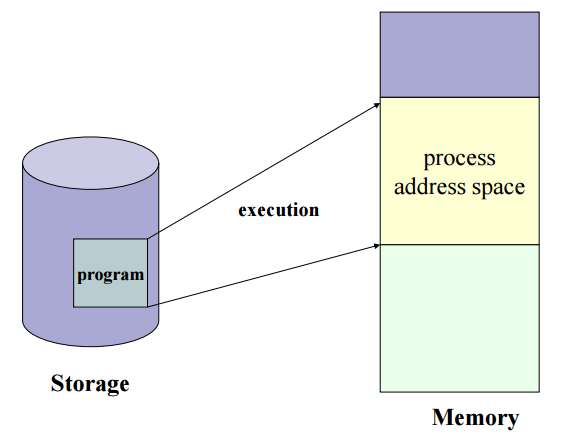
- 프로그램이 CPU에 의해 실행 → 프로세스가 생성되고 메모리에 프로세스 주소 공간이 할당
-
프로세스 주소 공간에는 코드, 데이터, 스택으로 이루어져 있다.
-
코드 Segment : 프로그램 소스 코드 저장
-
데이터 Segment : 전역 변수 저장
-
스택 Segment : 함수, 지역 변수 저장
-
-
구역을 구분하는 이유
-
최대한 데이터를 공유하여 메모리 사용량을 줄여야 한다.
-
Code는 같은 프로그램 자체에서는 모두 같은 내용이기 때문에 따로 관리하여 공유한다.
-
Stack과 data를 나눈 이유는, 스택 구조의 특성과 전역 변수의 활용성을 위한 것
-
프로그램의 함수와 지역 변수는, LIFO(가장 나중에 들어간게 먼저 나옴)특성을 가진 스택에서 실행된다.
-
이 함수들 안에서 공통으로 사용하는 '전역 함수'는 따로 지정해주면 메모리를 아낄 수 있다.
-
-
4. 인터럽트(Interrupt)
인터럽트
-
인터럽트란 CPU가 특정 기능을 수행하는 도중에 급하게 다른 일을 처리하고자 할 때 사용할 수 있는 기능이다.
-
대부분의 컴퓨터는 한 개의 CPU를 사용하므로 한 순간에는 하나의 일 밖에 처리할 수 없기 때문에 어떤 일을 처리하는 도중에 우선 순위가 급한 일을 처리할 필요가 있을 때 대처할 수 있는 방안이 필요하다.
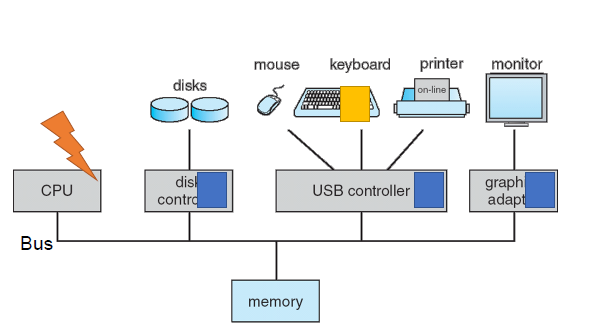
컴퓨터 시스템 구성
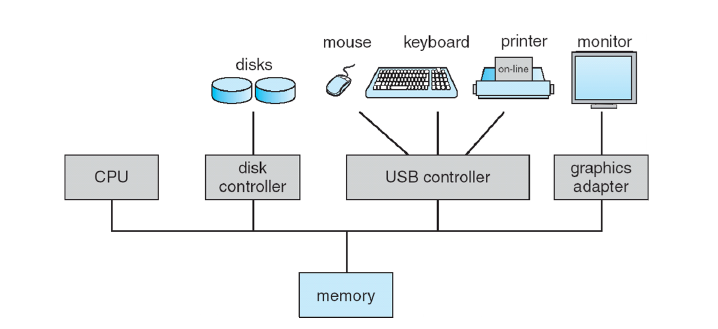
- 하나 이상의 CPU, 장치 컨트롤러는 공유 메모리에 대한 액세스를 제공하는 공통 버스를 통해 연결된다.
- CPU와 장치의 동시 실행은 메모리 주기를 놓고 경쟁한다.
컴퓨터 시스템 운영
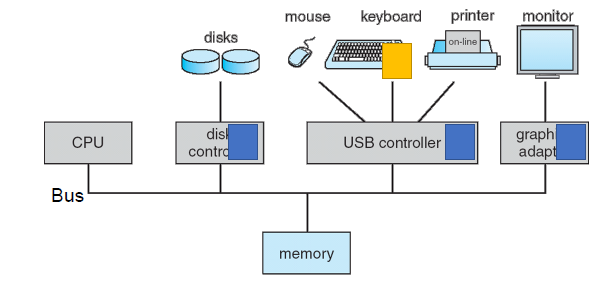
-
각 장치 컨트롤러(DC)는 특정 장치 유형을 담당한다.
-
각 장치 컨트롤러에는 로컬 버퍼가 있다.
-
I/O는 장치에서 컨트롤러의 로컬 버퍼로/에서 장치로 이루어진다.
-
CPU는 주 메모리에서 로컬 버퍼로 데이터를 이동한다.
예를 들면, 키보드의 키를 하나 누르면, 눌려진 키 코드 값이 키보드 버퍼에 입력된 후 CPU에 인터럽트가 걸린다.
그럼 현재 처리하던 작업에 대한 정보를 수집하여 저장한 뒤에 인터럽트 서비스 루틴(Interrupt Service Routine)을 수행한다.
- 이 경우에는 키보드 버퍼에 있는 키 코드 값을 가져가는 일을 한다.
인터럽트 처리를 마친 후에는 다시 이전에 처리하던 작업으로 돌아간다.
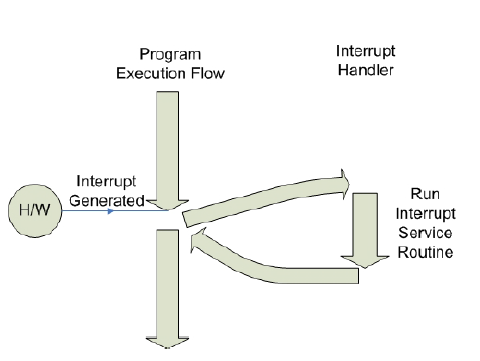
-
인터럽트는 CPU가 프로그램을 실행하고 있을 때, 입/출력 장치나 혹은 다른 예외상황이 발생하여 처리가 필요할 경우에 CPU에 알려서 처리하는 기술이다.
- 쉽게 말해 어느 한 순간에 CPU가 실행하는 명령은 하나인데 다른 장치와의 대화는 어떻게 이루어지는가?에 대한 답으로 말할 수 있다.
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int main() {
int fd;
fd = open("data.txt".O_RDONLY); // 해당 코드
if(fd == -1) {
printf("Error: can not open fileWn");
return 1;
} else {
printf("File opened and now close_Wn");
close(td);
return ();
}
}코드를 간단하게 보자면 주석처리가 되어 있는 부분의 코드에서는 변수가 선언이 끝나고 파일을 읽는 단계인걸 알 수 있다.
그렇다면 코드는 다음(조건문)으로 넘어가지 못한다. 해당 프로세스가 Block 처리(상태)가 되기 때문이다.
여기서 CPU의 입장에서보면 저장매체에서 파일을 다 읽었다면? 스케줄러에게 파일읽기를 완료했다고 알려줘야하지 않을까? 그래야 Block 상태에서 Ready상태로 변경하고 최종적으로는 Running상태까지 갈 수 있기 때문이다. 그것을 알려주는것이 인터럽트라는 것이다.
Device drivers
-
Device driver는 OS가 장치 컨트롤러와 통신하는 데 도움이 된다.
-
Device driver는 장치 컨트롤러(DC)의 기능을 추상화한다.
- 컨트롤러와 커널 간의 균일한 인터페이스 제공
-
I/O 작업을 시작하기 위해 Device driver는 DC 내의 레지스터를 설정한다.
-
DC는 레지스터 설정에 따라 작업을 수행한다.
-
-
DC는 Device와 Buffer 간에 데이터를 전송할 수 있다.
-
DC는 I/O 전송이 끝났음을 Device driver에 알린다.
인터럽트의 동작/처리
-
CPU가 프로그램을 실행하고 있을 때 하드웨어 등의 장치 이슈(ex 파일 처리 완료)가 발생한다면 그것을 운영체제에게 알려주고 운영체제는 해당 프로세스를 Block 상태에서 실행 대기(Ready state) 상태로 프로세스 상태를 변경합니다.
-
예외 상황이 발생할때의 동작/처리에서 코드 계산에 오류가 있을 경우 이러한 예외 발생을 운영체제에게 알려주고 전달받은 운영체제는 해당 프로세스를 중지하고 에러를 표시합니다.
-
시스템은 CPU의 현재 상태를 유지한다.
-
인터럽트 처리 후 복귀
-
인터럽트된 명령어의 레지스터와 주소 저장
-
하드웨어 또는 운영 체제에서 수행
-
-
지정된 Interrupt Service Routine (또는 interrupt handler)로 점프
- Interrupt vector 에는 모든 서비스 루틴의 주소가 포함된다.
-
레지스터를 복원하여 마지막 상태로 되돌리기
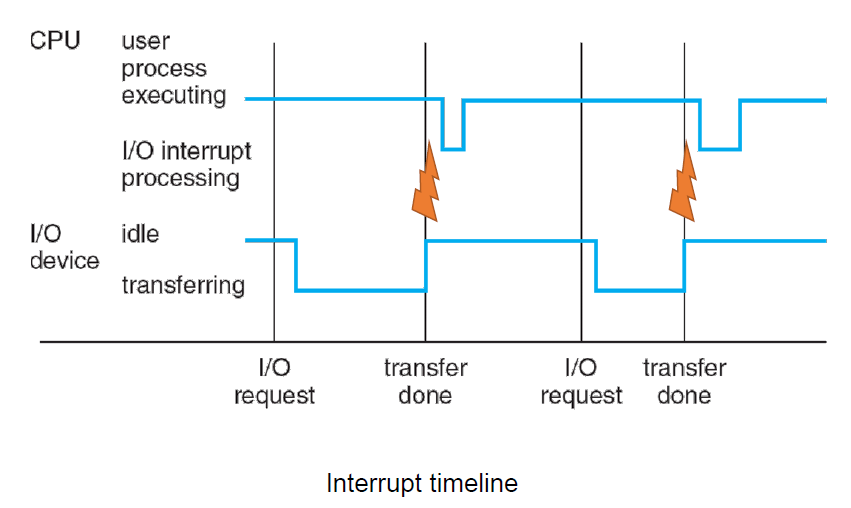
인터럽트는 왜 필요한가?
-
선점형 스케줄러를 예로 들면 프로세스가 Running 중에 스케줄러에 의해 중단되게 됩니다.
- 다른 프로세스로 교체하기 위해
-
그렇게 하기 위해서는 스케줄러의 코드가 실행이되서 현재 진행중인 프로세스를 중지시킬 수 있어야 합니다.
- 스케줄러도 하나의 프로그램이기 때문
프로세스가 스스로 결정하는것은 진행 중에 I/O장치 혹은 다른 작업을 진행해야 해서 Block 상태가 되는것과 프로세스가 종료되서 Exit상태가 되는것이지 Running 상태에서는 스케줄러에의해 강제로 Ready상태가 되는겁니다. 프로세스가 스스로 중단하는것이 아니라 스케줄러가 강제로 중단을 시키는것이고 인터럽트는 이러한 부분에서도 필요한 기능입니다.
-
선점형 스케쥴러 구현
- 하나의 프로세스가 실행중일때, 우선순위가 높은 다른 프로세스가 현재 프로세스를 중단시키고 실행되어질때.(인터럽트를 발생시켜 현재 실행중인 프로세스를 중단시키기 위함)
-
I/O event 처리
- 프로세스의 상태가 running -> waiting / ready-> running 으로 변경되어야할때 interrupt를 이용하여 CPU 가 해당 처리를 할 수 있도록 알림
-
예외 상황 핸들링
- CPU가 프로그램을 실행하고 있을 때, I/O event나 예외상황이 발생할 경우 CPU가 해당 처리를 할 수 있도록 알림
주요 인터럽트 종류
-
외부 인터럽트: 입출력 장치, 타이밍 장치, 전원 등의 외부적인 요인에 의해서 발생하는 인터럽트.
- 전원 이상 인터럽트: 정전이나 전원이 이상이 있는 경우
- 기계 고장 인터럽트: CPU등의 기능적인 동작 오류가 발생한 경우
- 입출력 인터럽트(I/O Interrupt): 입출력의 종료 등의 이유로 CPU의 수행을 요청하는 인터럽트.
-
내부 인터럽트: 잘못된 명령이나 데이터를 사용할 때 발생하는 인터럽트
- 0으로 나누는 경우
- 오버플로우 또는 언더플로우가 발생한 경우
- 프로그램 상의 오류
- 프로그램에서 함수 등 명령어를 잘못 사용한 경우
- 소프트웨어 인터럽트: CPU가 인스트럭션을 수행하는 도중에 일어나는 인터럽트
💡 내부 인터럽트 = 소프트웨어 인터럽트 // 외부 인터럽트 = 하드웨어 인터럽트
1. 0으로 나누는 경우
Divide - dy - Zero Interrupt
#include <stdio.h>int main() {
printf("Hello World!\n");
int data;
int divider = 0;
data = 1 / divider; // 해당 부분에서 인터럽트가 발생합니다.
return 0;
}
//Hello World!
//Floating point exception (core dumped) // 이 오류는 나누기를 할 때 변수/0이 있으면 발생
위와 같이 간단한 코드는 컴파일 하는 과정에서는 에러가 나지 않지만 실행시켰을시에 결과는 Hello Wordl!가 나오고 위와 같은 오류를 표시합니다.
운영체제에서 보여주는 오류인데 주석의 내용과 같이 변수/0을 계산할 수 없기 때문에 변수/0의 인터럽트가 발생하고 운영체제는 사용자에게 인터럽트에게 받은 정보를 보여주는겁니다.
Exception vs Interrupt
1) exception
-
소프트웨어 실행 명령에 의해 생성됨
- 소프트웨어 오류(예: 0으로 나누기), 데이터 무단 액세스, 운영 체제 서비스, …
-
Synchronous
- CPU가 명령어를 실행할 때 발생
-
Trap (expected, intended) or fault(unexpected)
-
Handled like interrupts
2) interrupt
-
하드웨어 장치에서 생성
-
Occurs asynchronously (at any time)
2. 타이머 인터럽트 (선점형 스케줄러를 위해 필요)
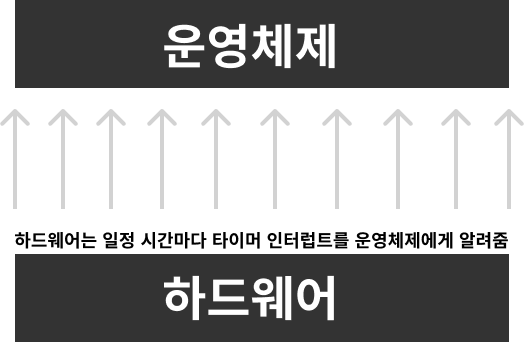
-
타이머 인터럽트를 발생시키는 장치가 컴퓨터 안에 칩으로 존재하는데 해당 칩에서 일정 간격으로 인터럽트를 계속해서 발생시킵니다.
- 여기서는 1초 주기로 발생시킨다고 가정
-
하드웨어에서는 1초 간격으로 운영체제에게 인터럽트를 발생시키고 그것을 받은 운영체제는 해당 인터럽트를 누적시켜서 가지고 있습니다.
-
선점형 스케줄러를 사용한다고 가정했을때 10초마다 프로세스를 교체한다고 한다면 운영체제는 하드웨어로부터 받은 인터럽트의 누적이 10초가 되는 순간 프로세스를 교체해야 한다는 시기를 알 수 있습니다.
-
이것이 외부 인터럽트 처리 방법이고 선점형 스케줄러에게 필요한 기능입니다.
-
3. 입출력 인터럽트 (I/O Interrupt)
키보드, 마우스, 저장장치, 프린터 등등 많겠지만 마우스로 예를 들면 마우스가 클릭이 될때마다 그것을 운영체제에게 알려줘야 할텐데 그것을 알려주는 인터럽트가 입출력 인터럽트라고 생각하면 됩니다.
I/O Process 처리
-
Programmed I/O
-
Interrupt-driven I/O
-
Direct Memory Access (DMA) I/O
1) Programmed I/O
- CPU는 DC를 통해 I/O 장치의 상태를 반복적으로 확인한다.
(ex) 장치가 I/O 작업을 수행할 준비가 되었는지 여부, 요청된 I/O 작업이 완료되었는지 여부…)
-
상태가 준비되면 CPU는 I/O 작업에 필요한 데이터를 직접 이동한다.
-
CPU는 항상 I/O 작업 처리에 관여해야 함 ——> CPU 자원을 비효율적으로 사용할 수 있음
-
CPU는 I/O 장치가 준비될 때까지 기다리는 데 상당한 시간을 낭비할 수 있다(busy waiting)
2) Interrupt-driven I/O
-
장치 컨트롤러는 인터럽트를 생성하여 CPU에 이벤트를 알린다.
-
I/O 장치에서 들어오는 요청이 도착할 때
-
작업이 완료될 때
-
3) Direct Memory Access (DMA) I/O

-
메모리 버퍼, 포인터, 카운터를 사용하여 장치 제어기가 CPU의 도움없이 DMA 컨트롤러를 이용하여 데이터를 직접 메모리로 전송하는 입출력 방식
-
CPU는 상태, 제어정보만을 교환하고 데이터 전송은 I/O와 메모리간에 직접교환
-
DMA 컨트롤러가 버스를 제어하고 I/O와 메모리가 정보를 집적 전송
-
중앙처리장치에게 PIO작업을 할당하지 않고 DMA라는 특수 프로세서에게 위임하여 메모리와 직접 데이터를 전송할 수 있게 하는 방법
-
-
동작 방식
1) I/O 인터페이스가 DMA 컨트롤러에게 DMA 서비스를 요청을 전송
2) CPU의 HOLD Pin에 Bus Request가 전송되어 버스에 대한 제어를 DMA가 획득 (Active High)
3) CPU의 HLDA(Hold Acknowledge) Pin으로부터 DMAC에 Bus grant가 리턴됨 (Active High)
4) DMAC는 Address bus에 Address Register의 Contents를 적재한다
5) DMAC는 I/O Interface에게 데이터를 데이터버스에 적재하도록 DMA Acknowledgement를 전송한다
6) Data Byte가 Address Bus에 의해 식별된 메모리 위치로 전송된다.
7) I/O Interface는 데이터를 지속적으로 전송유지 한다 (Latch)
8) Bus Request 가 Drop되어 HOLD가 Low 상태가 되어 DMAC는 Bus에 대한 사용권을 돌려준다.
9) BUS Grant가 Drop되어 HLDA가 Low 상태가 된다
10) 이후, Address Register가 1 증가되고, Byte Count는 1 감소된다
11) Byte Count가 0이 아니면 Step 1)로, 0이면 정지
System Call 인터럽트
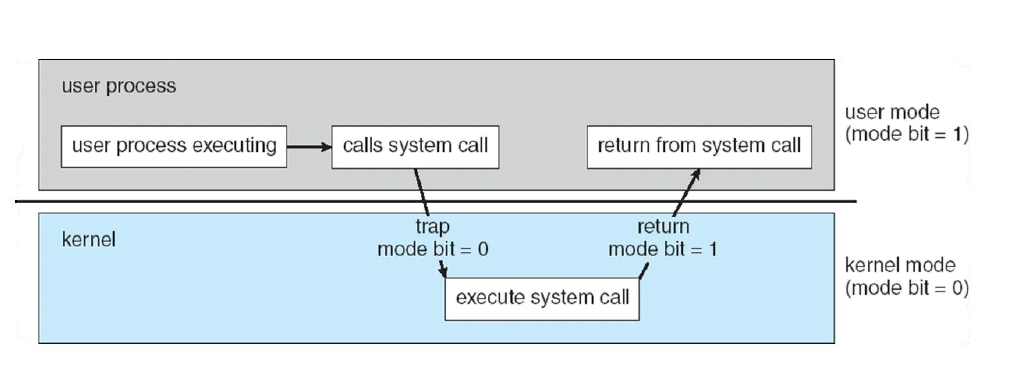
시스템 콜도 내부적으로는 인터럽트와 같은 방식으로 동작
-
open()-
open(data.txt".O_RDONLY);이라는 함수(시스템 콜)을 실행할때 해당 코드의 내부를 살펴보면 다시 말해 실제 기계어로 어떤 방식으로 컴파일이 되나 살펴보면 아래와 같습니다.-
eax 레지스터에 시스템 콜 번호를 넣고 (시스템 콜은 각각의 고유 번호를 가지고 있습니다.)
-
ebx 레지스터에는 시스템 콜에 해당 인자값을 넣고 (여기서는 ("data.txt".O_RDONLY) 부분을 인자로 볼 수 있습니다.)
-
소프트웨어(내부) 인터럽트 명령을 호출하면서 0x80값을 넘겨줍니다.
-
-
mov eax, 5 // 5는 시스템 콜 고유 번호입니다.
mov ebx, 0 // 0은 인자입니다.
int 0x80 // 소프트웨어 인터럽트 명령
-
마지막에
int 0x80명령어가 들어가는데 CPU가 제공하는OP code중int와 인터럽트의 번호를 넣어주는 것인데0x80이 의미하는것이 바로 시스템 콜의 번호입니다. -
인터럽트는 내부의 코드와 별개로 외부에서 실행이 되지만 해당 명령어를 통해 내부 코드안에서 강제로 실행을 시킬 수 있습니다. 다른 인터럽트와는 다르게 동작한다는 말입니다.
-
시스템 콜 인터럽트 명령을 호출하면서 0x80 값을 넘겨주면 어떤일이 일어날까?
-
해당 인터럽트를 받으면 첫 번째로 CPU는 사용자 모드를 커널 모드로 변경
- 위에서 얘기한
int라는OP code가 해당 역할을 수행합니다. 그래야 시스템 자원에 접근할 수 있겠죠.
- 위에서 얘기한
-
IDT(Interrupt Descriptor Table)라고 하는 주소에 접근합니다.
- 해당 주소에 인터럽트의 번호와 해당 번호에 맞는 코드가 들어가 있는 주소가 있기 때문입니다.
- 우리는 0x80 값을 넘겨주었기 때문에 그에 해당하는 주소(함수)를 찾아서 실행합니다.
- 해당 함수에는 system_call() 이라는 함수가 저장되어 있습니다.
- 즉, system_call() 함수를 실행한건데 해당 함수에서는 위에서 얘기한 eax로부터 받은 시스템 콜 번호에 해당하는 함수를 (call)호출합니다. 그리고 이때 ebx로 받은 인자 값을 같이 넘겨줍니다. 우리는 5와 (data.txt".O_RDONLY)를 넣어줬네요.
-
커널 모드에서 호출한 함수를 실행하게되고 실행이 완료되면 다시 사용자 모드로 변경되면서 다시 해당 프로세스의 다음 코드를 실행하게됩니다.
-
정리
-
프로세스 실행중 인터럽트 발생
-
현재 프로세스의 실행 중단
-
현재 수행중이었던 프로세스의 상태를 해당 프로세스의 PCB에 저장
-
발생한 인터럽트의 번호 를 IDT 에서 확인하여 해당하는 인터럽트 번호 에 해당하는 함수를 호출 해서 실질적인 작업을 수행
-
실행이 중단되었던 프로세스 의 PCB 를 불러와 CPU 레지스터에 초기화 시켜줌으로서 프로세스를 다시 수행
.png)
프로세스는 마치 계속 실행되고 있는것럼 보이지만 내부적으로는 사용자 모드와 커널 모드를 수도없이 왔다갔다하면서 실행된다.
인터럽트 그리고 IDT(Interrupt Descriptor Table)
IDT(Interrupt Descriptor Table) 란?
- 미리 정의되어 있는 인터럽트들의 번호 와 실행 코드를 가리키는 주소 들이 저장되어 있는 Table
-
컴퓨터 부팅 시 운영체제가 IDT에 인터럽트들을 기록
-
인터럽트가 발생하면 IDT를 확인하여 Interrupt 번호에 해당하는 함수를 호출해서 인터럽트를 처리
위에도 언급했지만 인터럽트는 각각의 고유 번호가 미리 정의되어 있습니다. 그래야 이전에 이야기했었던 수 많은 이벤트들을 각각 어떻게 처리할지 알 수 있으니까요. 그리고 수 많은 이벤트들을 어떻게 처리해야하는지에 대한 코드들이 운영체제에 구현이 되어있습니다. 그리고 해당 코드들은 IDT에 기록이 되어있습니다.
인터럽트의 번호(linux)
- 0 ~ 31 : 예외상황 인터럽트 (대부분 소프트웨어(내부) 인터럽트)
- 일부는 정의가 되지 않은 채로 남겨져 있습니다.
- 32 ~ 47 : 하드웨어 인터럽트
- 주변장치의 정류 혹은 개수에 따라 변경이 가능합니다.
- 128 : 시스템 콜
- 0x80(16진수)를 10진수로 전환하면 128입니다.
인터럽트 그리고 프로세스와 스케줄러
인터럽트는 고유의 번호가 있습니다. 해당 번호에 해당하는 코드들이 있으며 해당 코드들은 운영체제에 존재합니다.
그리고 그러한 코드와 번호들에 대한 정보가 IDT에 들어가 있다. 그래서 인터럽트가 발생하면 IDT를 참조해서 코드를 실행한다.
프로세스
프로세스와 인터럽트를 정리하자면 인터럽트가 발생하면 프로세스는 실행을 중단하게 됩니다. 그리고 커널 모드로 변경한 뒤에 위에 얘기한대로 IDT를 찾아가 해당 인터럽트에 해당하는 코드를 커널 모드에서 실행합니다. 그리고 실행이 끝나면 다시 사용자 모드로 변경됩니다.
스케줄러 (선점형)
스케줄러와 인터럽트를 정리하자면 하드웨어에서 일정 시간마다 타이머 인터럽트를 운영체제에게 알려줍니다. 그러면 운영체제는 해당 인터럽트 정보를 가지고 카운트등을 해서 누적시켜 가지고 있겠죠. 그 뒤에 인터럽트의 카운트가 스케줄러가 정해놓은 어떠한 규칙과 일치한다면 현재 프로세스를 다른 프로세스로 교체하게 됩니다.
5. 시스템 콜(System Call)
- 정식 명칭은 시스템 호출
운영체제는 커널 모드(Kernel Mode)와 사용자 모드(User Mode)로 나뉘어 구동된다.
운영체제에서 프로그램이 구동되는데 있어 파일을 읽어 오거나, 파일을 쓰거나, 혹은 화면에 메시지를 출력하는 등 많으 부분이 커널 모드를 사용한다.
시스템 콜은 이러한 커널 영역의 기능을 사용자 모드가 사용 가능하게, 즉 프로세스가 하드웨어에 직접 접근해서 필요한 기능을 사용할 수 있게 해준다.
-
통상적으로 시스템 콜은 여러 종류의 기능으로 나뉘어져 있다.
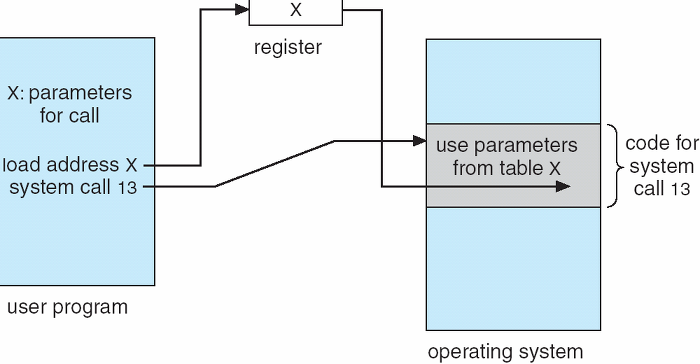
- 각 시스템 콜에는 번호가 할당되고 시스템 콜 인터페이스는 이러한 번호에 따라 인덱스 되는 테이블을 유지된다.
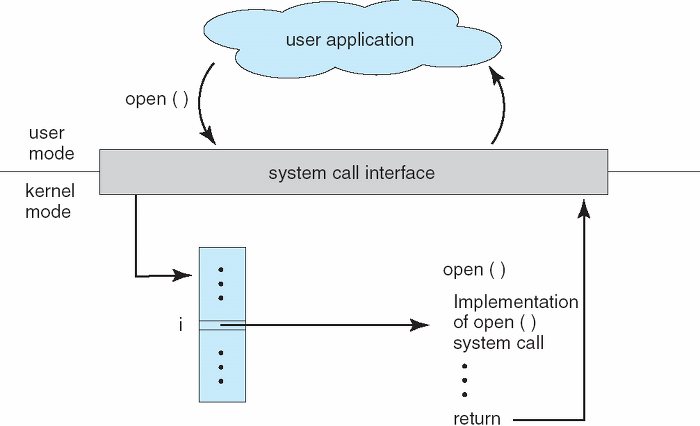
- open() 시스템 콜을 호출 했을 때 운영체제에서 어떻게 처리되는지를 보여준다.
필요한 기능이나 시스템 환경에 따라 시스템 콜이 발생할 때 좀 더 많은 정보가 필요할 수 있다.
-
정보가 담긴 매개변수를 운영체제에 전달하기 위해서는 대략 3가지 정도의 방법이 있다.
-
매개변수를 CPU 레지스터 내에 전달한다. 이경우에 매개변수의 갯수가 CPU 내의 총 레지스터 개수보다 많을 수 있다.
-
위와 같은 경우에 매개변수를 메모리에 저장하고 메모리의 주소가 레지스터에 전달된다. (아래 그림 참고)
-
매개변수는 프로그램에 의해 스택(stack)으로 전달(push) 될 수도 있다.
- 2, 3번 방법의 경우 전달되는 매개변수의 개수나 길이에 제한이 없기 때문에 몇몇 운영체제에서 선호하는 방식이다.
-
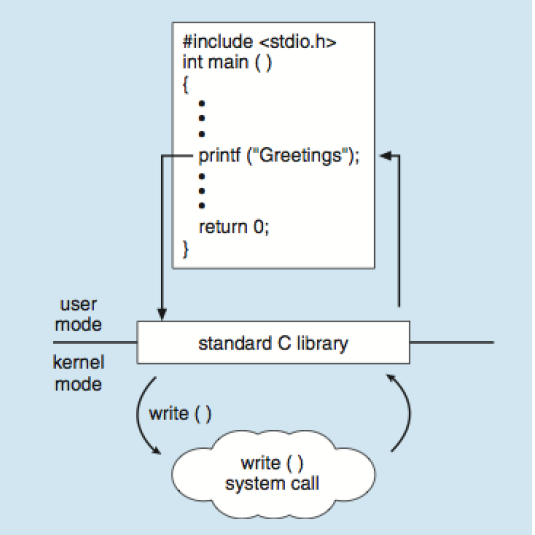
<C program invoking printf library call, which calls write() system call>
시스템 콜의 유형
시스템 콜은 다섯 가지의 중요한 범주로 나눌 수 있다.
- 프로세스 제어, 파일 조작, 장치 조작, 정보 유지보수, 통신과 보호

1) 프로세스 제어(Process Control)
-
끝내기(end), 중지(abort)
-
적재(load), 실행(execute)
-
프로세스 생성(create process)
-
프로세스 속성 획득과 설정(get process attribute and set process attribute)
-
시간 대기(wait time)
-
사건 대기(wait event)
-
사건을 알림(signal event)
-
메모리 할당 및 해제 : malloc, free
2) 파일 조작(File Manipulation)
-
파일 생성(create file), 파일 삭제(delete file)
-
열기(open), 닫기(close)
-
읽기(read), 쓰기(write), 위치 변경(reposition)
-
파일 속성 획득 및 설정(get file attribute and set file attribute)
3) 장치 관리(Devide Management)
-
장치를 요구(request devices), 장치를 방출release device)
-
읽기, 쓰기, 위치 변경
-
장치 속성 획득, 장치 속성 설정
-
장치의 논리적 부착(attach) 또는 분리(detach)
4) 정보 유지(Information Maintenance)
-
시간과 날짜의 설정과 획득(time)
-
시스템 데이터의 설정과 획득(date)
-
프로세스 파일, 장치 속성의 획득 및 설정
5) 통신(Communication)
-
통신 연결의 생성, 제거
-
메시지의 송신, 수신
-
상태 정보 전달
-
원격 장치의 부착 및 분리
일반적인 통신 모델에는 메시지 전달과 공유 메모리 두가지 가 있다. 메시지 전달 모델에서는 두 프로세스의 통신에 정보 교환을 위한 메시지를 주고 받는다. 공유 메모리 모델에서는 다른 프로세스가 소유한 메모리에 접근을 위해 특정 시스템 콜을 호출한다. 일반적으로 운영체제는 서로 다른 프로세스간의 메모리 접근을 차단한다. 공유 메모리 기법을 사용하기 위해서는 통신하려는 프로세스들이 이러한 차단을 풀어주는데 동의해야한다.
6. PCB와 Context Switching
Process Management
프로세스가 여러 개일 때, CPU 스케줄링을 통해 관리하는 것을 말합니다.
-
이때, CPU는 각 프로세스들이 누군지 알아야 관리가 가능합니다.
- 이러한 프로세스들의 특징을 갖고 있는 것이 바로 Process Metadata입니다.
-
Process Metadata
-
Process ID : PID(Process Identification Number) 라고도 합니다.
: 프로세스 고유 식별 번호 -
Process State(프로세스 상태)
: 프로세스의 현재 상태(준비, 실행, 대기 상태)를 기억시킵니다. -
Process Priority(스케줄링 정보)
: 프로세스 우선순위 등과 같은 스케줄링 관련 정보를 기억시킵니다. -
CPU Registers
: 프로세스의 레지스터 상태를 저장하는 공간 등. CPU 내 범용 레지스터(AX, BX, CX, DX), 데이터 레지스터(SP, BP, SI, DI), 세그먼트 레지스터(CS, DS, ES, SS) 등이 갖고 있는 값을 기억시킵니다. -
Owner(계정 정보)
: CPU 사용시간의 정보(Quantum), 각종 스케줄러에 필요한 정보를 기억시킵니다. -
기억장치 관리 정보
: 프로그램이 적재될 기억 장치의 상한치, 하한치, 페이지 테이블 등의 정보를 기억시킵니다. -
입출력 정보
: 프로세스 수행 시 필요한 주변 장치, 파일들의 정보를 기억시킵니다. -
프로그램 카운터(계수기)
: 다음에 실행되는 명령어의 주소를 기억시킵니다.
-
이러한 정보들이 담긴 메타데이터는 프로세스가 생성되면 PCB(Process Control Block)이라는 곳에 저장이 됩니다.
PCB(Process Controll Block)
-
프로세스 메타데이터들을 저장해 놓는 곳입니다.
-
하나의 PCB 안에는 하나의 프로세스의 정보가 담겨있습니다.
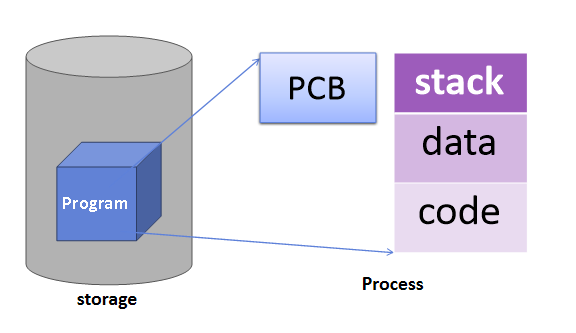
- 프로그램 실행 -> 프로세스 생성
-> 프로세스 주소 공간에 (코드, 데이터, 스택) 생성
-> 이 프로세스의 메타데이터들이 PCB에 저장
-
PCB(Process Control Block) 상세 구조
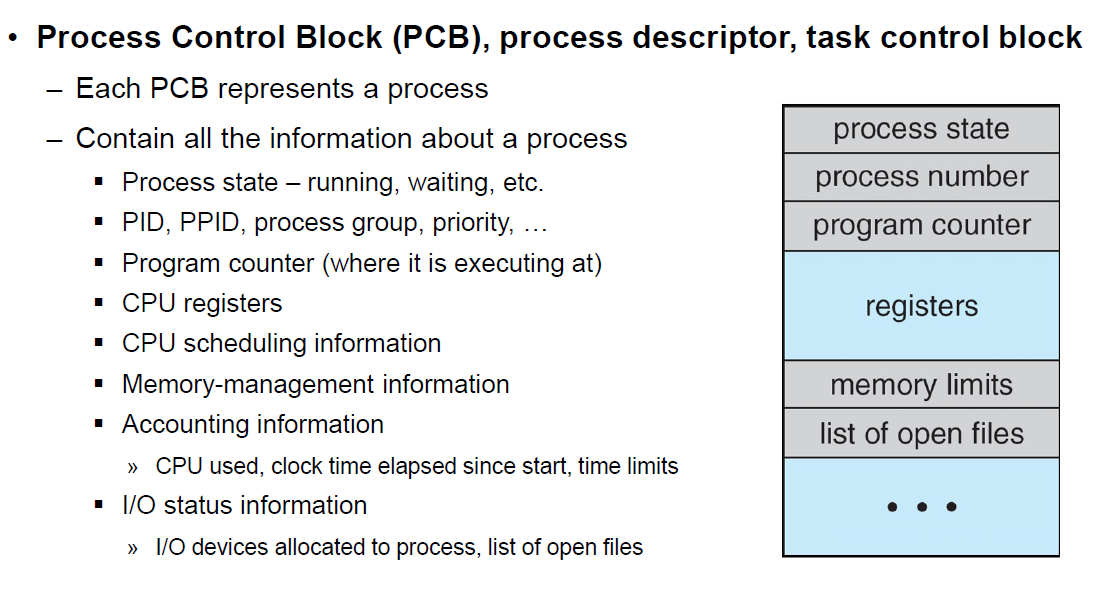
-
Process State : 프로세스 상태(Create, Ready, Running, Block, terminated)
-
Process Counter : 다음 실행할 명령어의 주솟값
-
CPU Registers : accumulator, index register, stack pointers, general purpose registers.
-
PCB가 필요한 이유
-
CPU에서는 프로세스의 상태에 따라 교체 작업이 이루어집니다. (인터럽트가 발생해서 할당받은 프로세스가 Block 상태가 되고 다른 프로세스를 running으로 바꿀 때)
-
이때, 앞으로 다시 수행할 Block 상태의 프로세스의 상태값을 PCB에 저장해두는 것**입니다.
-
PCB의 관리 방식
-
Linked List 방식으로 관리가 됩니다.
-
PCB List Head에 PCB들이 생성될 때마다 붙게 됩니다. 주솟값으로 연결이 이루어져 있는 연결 리스트 형태로, 삽입 삭제가 용이합니다.
- 즉, 프로세스가 생성되면 해당 PCB가 생성되고 프로세스 완료 시 제거가 됩니다.
-
이렇게 수행 중인 프로세스를 변경할 때, CPU의 레지스터 정보가 변경되는 것을 Context Switching이라고 합니다.
-
Context Switching이 필요한 이유
-
만약 컴퓨터가 매번 하나의 Task만 처리할 수 있다면?
- 다음 Task를 처리하기 위해서 현재 Task가 끝날 때까지 기다려야 합니다.
- 반응속도가 매우 느리고 사용하기 불편합니다.
-
다양한 사람들이 동시에 사용하는 것처럼 하기 위해서 Context Switching이 필요하게 되었습니다.
-
컴퓨터 멀티태스킹을 통해 빠른 반응속도로 응답 가능합니다.
-
빠르게 Task를 바꾸면서 실행하기에 사람은 실시간처리가 되는 것처럼 보입니다.
-
CPU가 Task를 바꿔가며 실행하기 위해 Context Switching이 필요하게 되었습니다.
-
Context Switching
-
CPU가 현재 실행하고 있는 Task(Process, Thread)의 상태를 저장하고, 다음 진행할 Task의 상태 및 Register 값들에 대한 정보(Context)를 읽어 새로운 Task의 Context 정보로 교체하는 과정
-
CPU가 이전의 프로세스 상태를 PCB에 보관하고, 또 다른 프로세스의 정보를 PCB에서 읽어서 레지스터에 적재하는 과정
-
다중 프로그래밍 시스템에서 CPU가 할당되는 프로세스를 변경하기 위해 현재 CPU를 사용하여 실행되고 있는 프로세서의 상태 정보를 저장하고 제어권을 인터럽트 서비스 루틴(ISR)에게 넘기는 작업
여기서 Context란 CPU가 다루는 Task(Process / Thread)에 대한 정보를 말하고, 대부분의 정보는 Register에 저장되고 PCB로 관리됩니다.
-
인터럽트가 발생하거나, 실행 중인 CPU 사용 허가 시간을 모두 소모하거나, 입출력을 위해 대기해야 하는 경우 Context Switching이 발생합니다.
- 즉, Context Switching은 프로세스가 Ready -> Running , Running -> Ready , Running -> Block 처럼 상태 변경 시에 발생합니다.
-
Context Switching 수행 과정
-
Task의 대부분 정보는 Register에 저장되고 PCB(Process Control Block)로 관리가 되고 있습니다.
-
현재 실행하고 있는 Task의 PCB 정보를 저장하게 됩니다.(Process Stack, Ready Queue)
-
다음 실행할 Task의 PCB 정보를 읽어 Register에 적재하고 CPU가 이전에 진행했던 과정을 연속적으로 수행할 수 있게 됩니다.
-
-
Context Switching Cost
-
Context Switching이 발생하게 되면 다음과 같은 Cost가 소요됩니다.
-
Cache 초기화
-
Memory Mapping 초기화
-
메모리의 접근을 위해서 Kernel은 항상 실행되어야 합니다.
-
-
💨 따라서 잦은 Context Switching은 성능 저하를 가져옵니다.
Context Switching과 Interrupt
- CPU는 하나의 프로세스 정보만을 기억합니다. 여러 개의 프로세스가 실행되는 다중 프로그래밍 환경에서 CPU는 각각의 프로세스의 정보를 저장했다 복귀하고 다시 저장했다 복귀하는 일을 반복합니다. 프로세스의 저장과 복귀는 프로세스의 중단과 실행을 의미합니다. 프로세스의 중단과 실행 시 인터럽트가 발생하므로, 문맥 교환이 많이 일어난다는 것은 인터럽트가 많이 발생한다는 것을 의미합니다.
-
Context Switching과 시간 할당량
-
프로세스들의 시간 할당량은 시스템 성능의 중요한 역할을 합니다.
- 시간 할당량이 적을수록 사용자 입장에서는 여러 개의 프로세스가 거의 동시에 수행되는 느낌을 갖지만 인터럽트의 수와 문맥 교환의 수가 늘어납니다.
- 프로세스의 실행을 위한 부가적인 활동을 오버헤드(간접 부담 비용)이라고 하는데, 이 또한 문맥 교환 수와 같이 늘어나게 됩니다. 정리하자면 다음과 같습니다.
-
시간 할당량이 적어지면 : 문맥 교환 수, 인터럽트 횟수, 오버헤드가 증가하지만 여러 개의 프로세스가 동시에 수행되는 느낌을 갖는다.
-
시간 할당량이 커지면 : 문맥 교환 수, 인터럽트 횟수, 오버헤드가 감소하지만 여러 개의 프로세스가 동시에 수행되는 느낌을 갖지 못한다.
-
프로세스를 수행하다가 I/O event가 발생하여 BLOCK 상태로 전환시켰을 때, CPU가 그냥 놀게 놔두는 것보다 다른 프로세스를 수행시키는 것이 효율적이므로, CPU에 계속 프로세스를 수행시키도록 하기 위해서 다른 프로세스를 실행시키고 Context Switching을 할 때 Overhead가 발생합니다.
CPU가 놀지 않도록 만들면서, 사용자에게 빠르게 일처리를 제공해 주기 위한 것입니다.
Process vs Thread
Context Switching 비용은 Process가 Thread보다 많이 듭니다. 그 이유는 Thread는 Stack 영역을 제외한 모든 메모리를 공유하기에 Context Switching 발생 시 Stack 영역만 변경하면 됩니다.
7. IPC(Inter Process Communication)
- 프로세스 간 통신프로세스들끼리 서로 데이터를 주고받는 행위 또는 그에 대한 방법을 뜻한다.

-
위 그림처럼 Process는 완전히 독립된 실행객체이다.
- 서로 독립되어 있다는 것은 다른 프로세스의 영향을 받지 않는다는 장점이 있다. 그러나 독립되어 있는 만큼 별도의 설비가 없이는 서로간에 통신이 어렵다는 문제가 있게 된다.
-
이를 위해서 커널 영역에서 IPC라는 내부 프로세스간 통신을 제공하게 되고, 프로세스는 커널이 제공하는 IPC설비를 이용해서 프로세스간 통신을 할 수 있게 된다.
-
커널(Kernel)이란?
-
운영체제 자체도 소프트웨어이기 때문에 메모리에 올라가야 사용할 수 있다. 하지만 메모리 공간의 제약으로 운영체제 중 항상 필요한 부분만을 메모리에 올려놓고, 그렇지 않은 부분은 필요할 때 메모리에 올려서 사용하게 된다.
-
이 때 메모리에 상주하는 운영체제의 부분을 커널이라 한다. (보통은 운영체제라고 하면 커널을 말하게 된다.)
- 즉, 커널은 메모리에 상주하는 부분으로써 운영체제의 핵심적인 부분을 뜻한다.
-
IPC의 종류
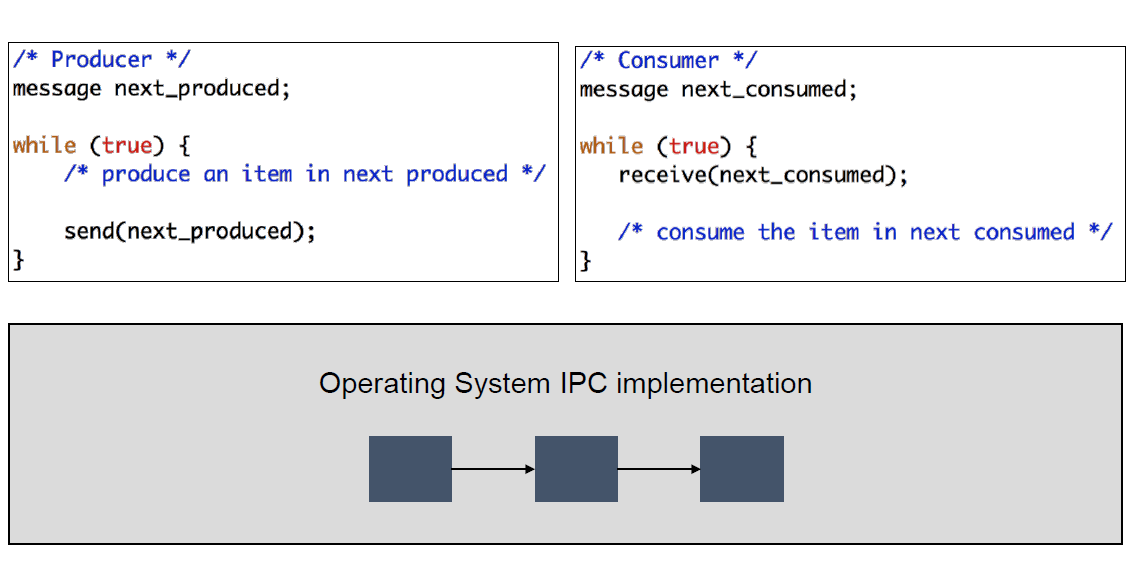
1. 메시지 전달 (Message Passing)
-
커널이 제공하는 API를 이용해서 커널 공간을 통해 통신한다. 메시지 큐(Mesage Queue)를 사용하여 송신 프로세스는 큐에 enqueue, 수신 프로세스는 큐에 dequeue 하며 상호간 통신한다. 메시지 큐는 커널 단에서 관리된다.
-
Processes communicate with each other through OS-provided IPC facility with two operations
-
send(message)
-
receive(message)
-
-
The message size is either fixed or variable
- Pros and Cons?
-
Effective in distributed environments
- Microkernel!!
2. 메모리 공유 (Shared Memory)
-
프로세스끼리 특정 공통의 메모리 영역을 공유하며 상호간 통신하는 방법이다.
-
데이터 자체를 공유하도록 지원하며, 한 프로세스에서 변경한 메모리 공간의 내용을 다른 프로세스에서 접근할 수 있다. 공유 메모리는 커널에서 관리된다.
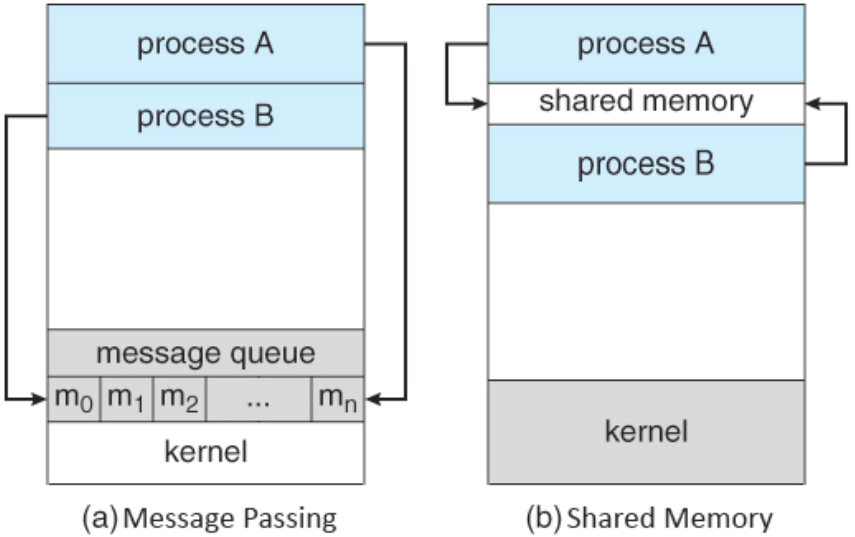
3) Sockets(TCP/IP)
- Network Communication의 종점(endpoint) IP address, Port를 이용한 직접적인 통신
4) Pipe
-
Message나 Shared memory는 서로 다른 process간 memory에서 구조체 또는 데이터를 주고받는 형태였지만 Pipe는 양방향 간의 버퍼를 통해 데이터를 읽거나 쓰는 구조 연속적인 바이트 스트림을 교환할 때 많이 사용함
-
파이프의 종류
-
Ordinary Pipe
- 저장장치에 실제로 있는 파일이 아니라 커널영역에 존재하는 가상 파일이다. - 일반적인 파일 입출력 함수(read/write)를 통해 데이터를 전달하기 때문에 비교적 사용이 간단하다. - 부모/자식 프로세스 관계에 있는 경우에만 사용할 수 있고, 통신 방향이 단방향이다. - ex) 부모 -> 자식 or 자식 -> 부모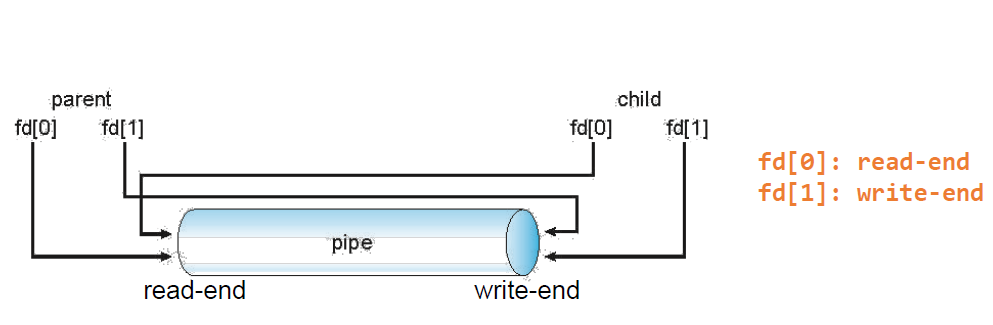
<일반적인 사용법>
부모 프로세스에서 파이프를 만들어두고 fork()를 통해 자식 프로세스를 생성하면 부모 프로세스의 메모리 내용과 PCB가 그대로 복제되고, 커널의 파일 테이블도 그대로 상속되기 때문에 동일 Pipe를 바라보게 된다.<참고>exec()를 하는 경우에도 그전에 미리 Pipe를 생성해두었다면 파일 테이블은 그대로 상속된다.) -
Named Pipe
-
특수한 파일을 이용하여 통신하는 방법이다.
-
파일 이름만 알면 부모/자식 프로세스 외에도 정보를 공유하는 양방향 통신이 가능해진다.
-
-
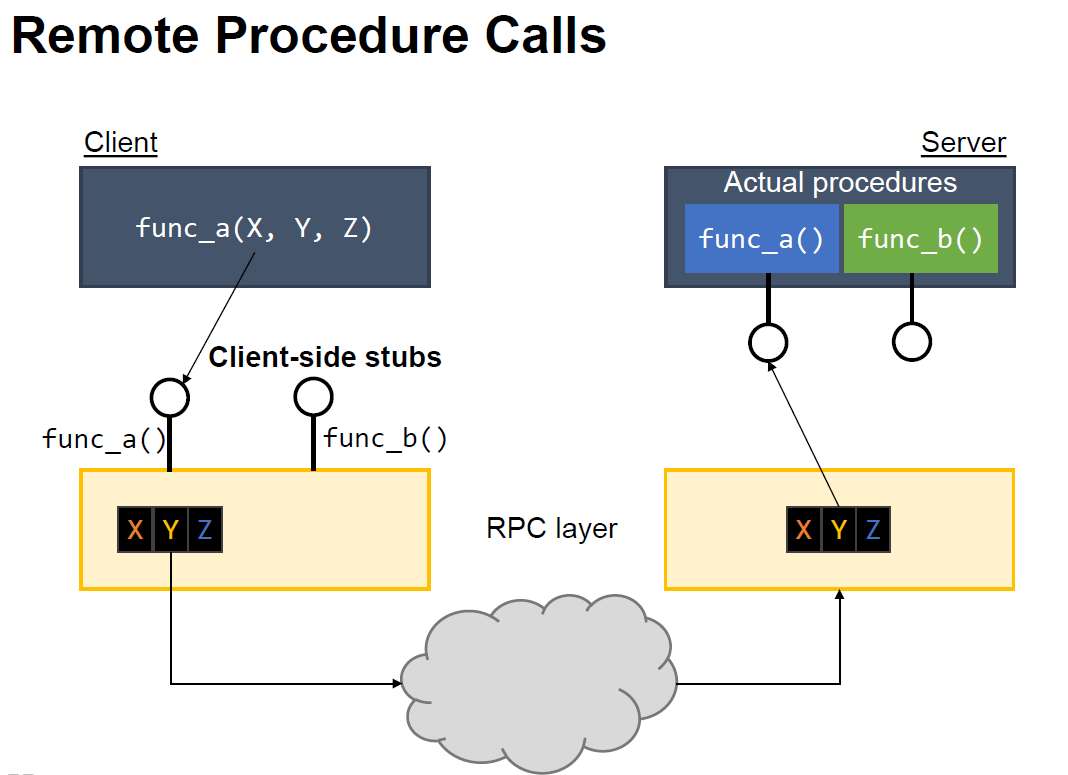
RPC(Remote Procedure Call)
- 컴퓨터 프로그램이 다른 주소공간에 원격제어를 위해 함수나 프로시저의 실행을 허용하는 기술(프로토콜)

Stub
-
원격지에 위치해있는 프로그램을 대리하는 작은 루틴.
-
RPC를 사용하는 프로그램이 컴파일되면 요청된 절차를 제공하는 프로그램의 대역을 한다.
-
클라이언트에서 요청하는 데이터를 Marshaling하고 작업이 완료된 데이터를 다시 UnMarshaling하는 역할
-
Skeleton Stub와 비슷한 역할로 서버의 보조 객체이다.
-
클라이언트의 Stub에서 데이터가 Marshaling되어 전송되면 Skeleton에서 UnMarshaling하여 원래의 형태로 복원한다.
-
RMI(Remote Method Invocation)
- RPC를 객체지향으로 구현함 서버와 클라이언트 모두 helper가 필요하다. (서버 측은 Skeleton, 클라이언트 측은 Stub)
Marshaling / UnMarshaling
- Marshaling은 데이터를 바이트로 쪼개서 TCP/IP같은 통신 채널을 통해 전송될 수 있는 형태로 바꿔주는 과정 UnMarshaling은 반대로 전송 받은 바이트를 원래의 형태로 복원하는 과정

8. CPU 스케줄링
스케줄링
CPU를 잘 사용하기 위해 프로세스를 배정하는 과정이다.
- 조건 : 오버헤드를 낮추고/ 사용률을 증가시키고/ 기아 현상을 낮추는 방향으로 한다.
- 목표 :
- Batch System : 가능하면 많은 일을 수행, 시간(time)보단 처리량(throughout)이 중요하다.
- Interactive System : 빠른 응답 시간, 적은 대기 시간이 들게 한다.
- Real-Time System : 기한(deadline)을 맞춰야한다.
선점/ 비선점 스케줄링
- 선점(preemptive) 스케줄링 : OS가 CPU의 사용권을 선점할 수 있고 강제로 회수할 수 있다.
- 비선점(nonpreemprive) 스케줄링 : 프로세스 종료 or I/O 등의 이벤트가 있을 때 까지 실행을 보장한다. (처리시간 예측이 어렵다)
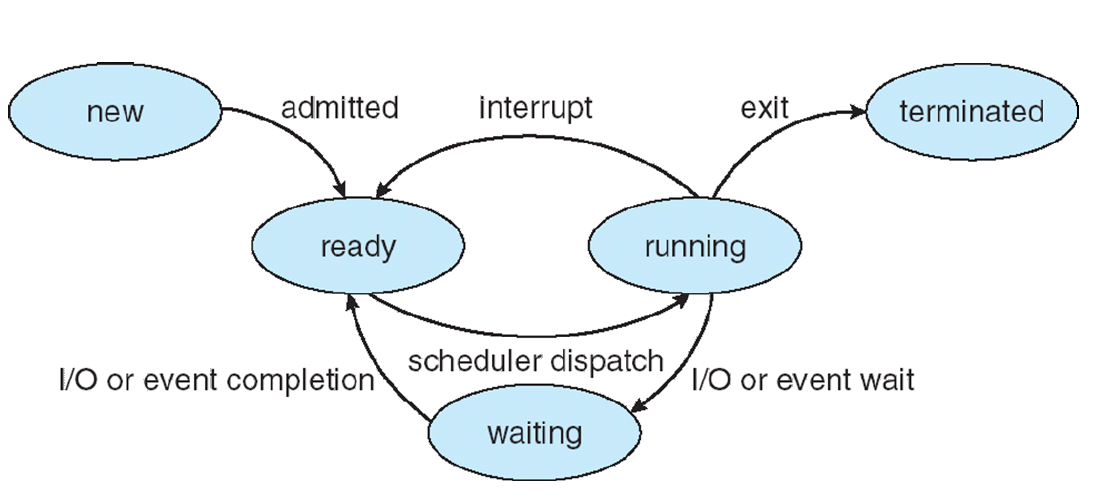
프로세스 상태
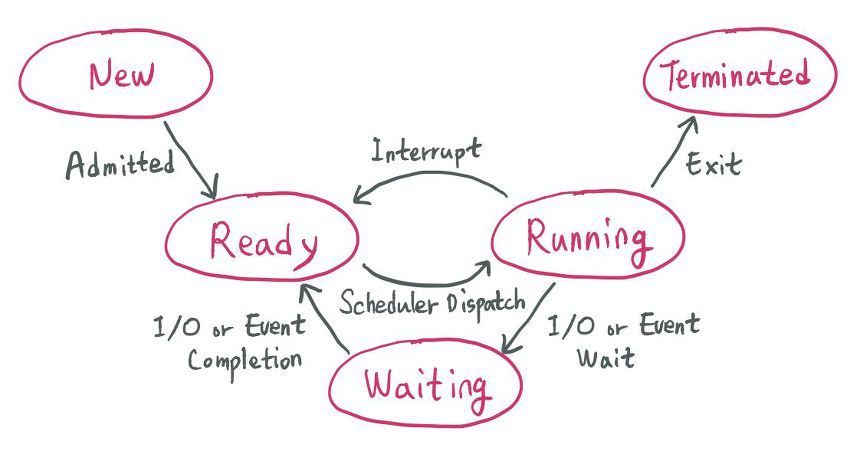
- 비선점 스케줄링 : Interrupt, Scheduler Dispatch
- Dispatcher은 스케줄러가 선택한 프로세스를 실질적으로 프로세서를 할당하는 역할을한다. 즉 프로세스의 레지스터를 적재하고(문맥교환), 운영체제 모드(kernel mode)에서 사용자 상태(user mode)로 전환시켜주고 프로세스가 다시 시작할 때 사용자 프로그램이 올바른 위치를 찾을 수 있도록 한다
- 이미 할당된 자원을 다른 프로세스가 강탈할 수 없다.
- 응답 시간의 예측이 편하며,일괄처리 방식에 적합하다.
- 덜 중요한 작업이 자원을 할당 받으면 중요한 작업이 와도 처리 될 수 없다.
- 선점 스케줄링 : I/O, Event Wait
- 우선순위가 높은 프로세스를 빠르게 처리할 수 있다.
- 어떤 프로세스가 자원을 사용하고 있을때 우선순위가 더 높은 프로세스가 올 경우 자원을 강탈할 수 있다.
- 빠른 응답 시간을 요구하는 시스템에서 사용한다.
- 오버헤드가 크다.
프로세스의 상태 전이
- 승인 (Admitted) : 프로세스 생성이 가능하여 승인된다.
- 스케줄러 디스패치(Scheduler Dispatch) : 준비 상태에 있는 프로세스 중 하나를 선택하여 실행시킨다.
- 인터럽트(Interrupt) : 예외, 입출력, 이벤트 등이 발생하여 현재 실행 중인 프로세스를 준비 상태로 바꾸고, 해당 작업을 먼저 처리한다.
- 입출력 또는 이벤트 대기 (I/O or Event Wait) : 실행 중인 프로세스가 입출력이나 이벤트를 처리해야 하는 경우이다. 입/출력, 이벤트가 모두 끝날 때까지 대기 상태로 만드는 것이다.
- 입출력 또는 이벤트 완료 (I/O or Event Completion) : 입/출력, 이벤트가 끝난 프로세스를 준비 상태로 전환하여 스케줄러에 의해 선택될 수 있도록 만드는 것이다.
CPU 스케줄링 종류
- 비선점 스케줄링
- FCFS (First Come First Served)
- FIFO라고도 한다.
- 큐에 도착한 순서대로 CPU를 할당한다.
- 실행 시간이 짧은게 뒤로 가면 평균 대기 시간이 길어진다.
- SJF (Shortest Job First)
- 수행시간이 가장 짧다고 판단되는 작업을 먼저 수행한다.
- FCFS 보다 평균 대기 시간이 감소하고 짧은 작업에 유리하다.
- 긴 수행시간을 갖는 프로세스는 실행이 안될 수 있다.
- HRN (Hightest Response-ratio Next)
- 우선순위를 계산하여 점유 불평등을 보완한 방법이다(SJF의 단점 보안)
- 우선순위 = (대기시간 + 실행시간) / (실행시간) 으로 두어 실행시간이 길어지더라도 대기를 오래 했으면 실행 될 수 있도록 한다.
- FCFS (First Come First Served)
- 선점 스케줄링
- Priority Scheduling
- 정적/동적으로 우선순위를 부여하여 우선순위가 높은 순서대로 처리한다.
- 우선 순위가 낮은 프로세스가 무한정 기다리는 Starvation이 발생할 수 있다.
- Aging 방법으로 Starvation 문제 해결 가능하다.
- Aging이란 시스템에서 어떤 자원을 기다린 시간에 비례하여 프로세스에게 우선 순위를 부여하는 것이다. HRN의 경우도 Aging기법이라 할 수 있다.
- Round Robin
- FCFS에 의해 프로세스들이 보내지면 각 프로세스는 동일한 시간의 Time Slice만큼 CPU를 할당 받는다.
- Time Slice: 실행의 최소 단위 시간이다.
- 할당 시간 (Time Slice)가 크면 FCFS와 같게 되고(모든 프로세스의 실행 시간이 Time Slice 보다 작거나 같으면), 작으면 문맥 교환이 잦아져서 오버헤드가 증가한다.
- FCFS에 의해 프로세스들이 보내지면 각 프로세스는 동일한 시간의 Time Slice만큼 CPU를 할당 받는다.
- Multilevel-Queue (다단계 큐)
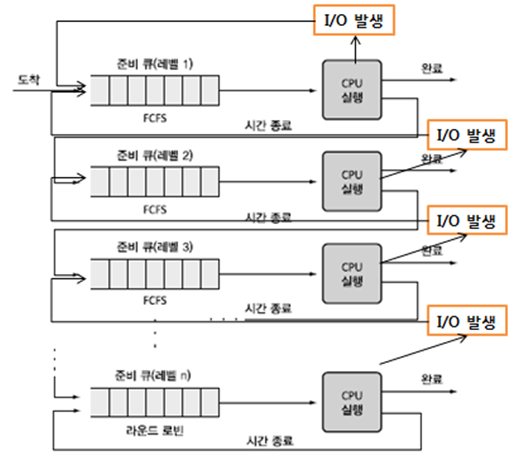
- 작업들을 여러 종류의 그룹으로 나누어 여러 개의 큐를 이용하는 기법이다.
- 우선순위가 낮은 큐들이 실행 못하는 걸 방지하고자 각 큐마다 다른 Time Slice를 설정해주는 방식이다.
- 우선순위가 높은 큐는 작은 Time Slice를 할당, 우선순위가 낮은 큐는 큰 Time Slice를 할당한다.
- 우선순위가 높은 큐는 자주 사용하는 큐이기 때문에 작은 Time Slice를 사용하여 여러 프로세스에게 공정하게 기회를 부여한다.
- 우선 순위가 낮은 큐는 Time Slice를 크게 하여 FCFS 방식으로 한번에 처리한다.
- Multilevel-Feedback-Queue (다단계 피드백 큐)
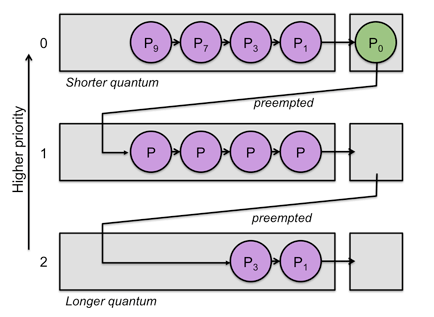
- Multilevel Queue에서 Time Slice를 다 채운 프로세스는 밑으로 내려가고 자신의 Time Slice를 다 채우지 못한 프로세스는 원래 큐 그대로 놓는 방식이다. → Time Slice를 다 채운 프로세스는 CPU burst 프로세스(게임 다운로드 같이 CPU를 계속 써야하는 프로세스)로 판단한다.
- 짧은 작업에 유리하고 입출력 위주(Interrupt가 잦은) 작업에 우선권을 준다.
- 처리 시간이 짧은 프로세스르 먼저 처리하기 때문에 Turnaround 평균 시간이 줄어든다.
- 우선순위가 낮을 수록 Time Slice를 크게 하고 이 Time Slice를 초과하면 또 밑의 큐로 보내는 방식을 반복한다.
- 즉, 다음 단계로 넘어갈 수록 CPU burst가 크다는 것이기 때문에 우선순위가 점점 낮아진다.
- Multilevel Queue에서 Time Slice를 다 채운 프로세스는 밑으로 내려가고 자신의 Time Slice를 다 채우지 못한 프로세스는 원래 큐 그대로 놓는 방식이다. → Time Slice를 다 채운 프로세스는 CPU burst 프로세스(게임 다운로드 같이 CPU를 계속 써야하는 프로세스)로 판단한다.
- Priority Scheduling
CPU 스케줄링 척도
- Response Time : 작업이 처음 실행되기까지 걸린 시간 → 대기 시간
- Turnaround Time : 실행시간과 대기 시간을 모두 합한 시간으로 작업이 완료될 때 걸린 시간 → 실행 시간 + 대기 시간
9. 데드락(DeadLock)
데드락이 일어나는 경우
-
멀티 프로그래밍 환경에서 한정된 자원을 얻기 위해 서로 경쟁하는 상황
-
한 프로세스가 자원을 요청했을 때, 동시에 그 자원을 사용할 수 없는 상황이 발생할 수 있다. 이때 프로세스는 대기 상태로 들어간다.
-
대기 상태로 들어간 프로세스들이 실행 상태로 변경될 수 없을 때 데드락이 발생한다.
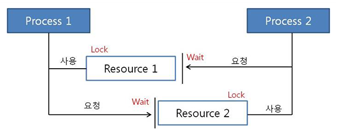
다음 사진에서 프로세스 1,2 가 자원 1,2를 모두 사용하려 한다.
-
Process1은 Resource1 획득/ Resource2 얻기 위해 대기
-
Process2은 Resource2 획득/ Resource1 얻기 위해 대기
현재 서로 원하는 자원이 상대방에게 할당되어 있어서 두 프로세스는 무한히 wait 상태에 빠지게 된다.
→ 이것이 바로 DeadLock이다.
DeadLock 발생 조건
4가지 모두 성립해야 데드락이 발생한다 → 하나라도 성립하지 않으면 데드락 문제 해결 가능
1. 상호 배제 (Mutual Exclusion)
- 자원은 한번에 한 프로세스만 사용할 수 있다.
2. 점유 대기 (Hold and Wait)
- 최소한 하나의 자원을 점유하고 있으면서 다른 프로세스에 할당되어 사용하고 있는 자원을 추가로 점유하기 위해 대기하는 프로세스가 존재해야 한다.
3. 비선점(No Preemption)
- 다른 프로세스에 할당된 자원은 사용이 끝날 때까지 강제로 뺏을 수 없다.
4. 순환 대기 (Circular Wait)
- 프로세스의 집합에서 순환 형태로 자원을 대기하고 있어야 한다.
DeadLock 처리
교착 상태를 예방 또는 회피한다.
1. 예방(Prevention)
-
교착 상태 발생 조건 중 하나를 제거하면서 해결한다 (자원 낭비가 엄청 심하다)
-
상호배제 부정 : 여러 프로세스가 공유 자원 사용하게 한다.
-
점유대기 부정 : 프로세스 실행 전 모든 자원을 할당한다.
-
비선점 부정 : 자원 점유 중인 프로세스가 다른 자원을 요구할 때 가진 자원을 반납하게 한다.
-
순환대기 부정: 자원에 고유번호 할당 후 순서대로 자원을 요구하게 한다.
-
2. 회피(Avoidance)
- 교착 상태 발생 시 피해나가는 방법이다.
-
은행원 알고리즘 (Banker's Algorithm)
- 은행에서 모든 고객의 요구가 충족되도록 현금을 할당하는데서 유래했다.
- 프로세스가 자원을 요구할 때, 시스템은 자원을 할당한 후에도 안정 상태로 남아있게 되는지 사전에 검사하여 교착 상태를 회피한다.
- 안정 상태면 자원을 할당하고, 아니면 다른 프로세스들이 자원을 해지할때까지 대기한다.
-
3. 발견
1) 탐지(Detection)
-
자원 할당 그래프를 통해 교착 상태를 탐지한다.
-
자원 요청 시, 탐지 알고리즘을 실행시켜 그에 대한 오버헤드가 발생한다.
2) 회복(Recovery)
-
교착 상태를 일으킨 프로세스를 종료하거나, 할당된 자원을 해제시켜 회복시키는 방법이다.
-
프로세스 종료 방법
- 교착 상태의 프로세스를 모두 중지한다.
- 교착 상태가 제거될 때까지 하나씩 프로세스를 중지한다.
- 교착 상태의 프로세스를 모두 중지한다.
-
자원 선점 방법
-
교착 상태의 프로세스가 점유하고 있는 자원을 선점해 다른 프로세스에게 할당한다.(해당 프로세스는 일시적으로 정지 시킨다.)
-
우선 순위가 낮은 프로세스나 수행 횟수가 적은 프로세스 위주로 프로세스 자원을 뺐는다.
-
-
10. Race Condition
두 개 이상의 프로세스가 공통 자원을 병행적으로(concurrently) 읽거나 쓰는 동작을 할 때, 공용 데이터에 대한 접근이 어떤 순서에 따라 이루어졌는지에 따라 그 실행 결과가 같지 않고 달라지는 상황을 말합니다. 간단히 말하면 경쟁하는 상태, 즉 두 개의 스레드가 하나의 자원을 놓고 서로 사용하려고 경쟁하는 상황을 말합니다.
Race Condition은 세 가지 제어 문제에 직면합니다. Mutual exclusion, deadlock, starvation 입니다.
Critical Section
-
임계 구역(Critical Section) 또는 공유 변수 영역은 병렬 컴퓨팅에서 둘 이상의 스레드가 동시에 접근해서는 안 되는 공유 자원을 접근하는 코드의 일부분을 말합니다.
-
임계 구역은 지정된 시간이 지난 후 종료됩니다. 때문에 어떤 스레드(Task 또는 Process)가 임계 구역에 들어가고자 한다면 지정된 시간만큼 대기해야 합니다.
-
스레드가 공유자원의 배타적인 사용을 보장받기 위해서 임계 구역에 들어가거나 나올 때는 세마포어나 뮤텍스 같은 동기화 메커니즘이 사용됩니다.
Mutual Exclusion
-
Race condition을 막기 위해서는 두 개 이상의 프로세스가 공용 데이터에 동시에 접근을 하는 것을 막아야 합니다.
- 즉, 한 프로세스가 공용 데이터를 사용하고 있으면 그 자원을 사용하지 못하도록 막거나, 다른 프로세스가 그 자원을 사용하지 못하도록 막으면 이 문제를 피할 수 있습니다.
-
이것을 상호 배제(mutual exclusion)라고 부릅니다.
DeadLock
-
위와 같은 상호 배제를 시행하면 추가적인 제어 문제가 발생합니다.
-
하나는 교착상태 즉 여기서 말하는 Deadlock입니다.
-
프로세스가 각자 프로그램을 실행하기 위해 두 자원 모두에 엑세스 해야 한다고 가정할 때 프로세스는 두 자원 모두를 필요로 하므로 필요한 두 리소스를 사용하여 프로그램을 수행할 때까지 이미 소유한 리소스를 해제하지 않습니다. 이러한 상황에서 두 프로세스는 교착 상태에 빠지게 되는 문제가 발생할 수 있습니다.
Starvation
-
이 제어 문제는 ‘기아 상태’라고도 합니다. 이러한 문제는 프로세스들이 더 이상 진행을 하지 못하고 영구적으로 블록되어 있는 상태로, 시스템 자원에 대한 경쟁 도중에 발생할 수 있고 프로세스 간의 통신 과정에도 발생할 수 있는 문제입니다. 두 개 이상의 작업이 서로 상대방의 작업이 끝나기만을 기다리고 있기 때문에 결과적으로는 아무것도 완료되지 못하는 상태가 되게 됩니다.
-
이렇게 race condition 인 경우에는 스레드의 실행 순서를 잘 조절해주지 않으면 이상한 상태, 비정상적인 상태가 나오게 됩니다. 이 문제는 항상 발생하는 것이 아니라 특정한 순서대로 수행되었을 때 발생하는 것입니다. 디버깅을 할 때에는 전혀 보이지 않는 문제점이고, 발생 시에 모든 프로세스에 원하는 결과가 발생하는 것을 보장할 수 없으므로 후에 더욱 큰 문제를 야기할 수 있으므로 반드시 피해야 하는 상황입니다.
-
이러한 문제가 발생하지 않도록, OS는 다른 프로세스의 의도하지 않은 간섭으로부터 각 프로세스의 데이터 및 물리적 자원을 보호해야 하며 여기에 메모리, 파일 및 I/O 장치와 관련된 내용이 포함됩니다.
-
그리고 프로세스에서 수행하는 내용과 프로세스가 생성하는 결과는, 다른 동시 프로세스의 실행 속도와 무관, 즉 기능과 결과는 서로 독립적이어야 합니다.
해결법
-
커널 내부에 있는 각 공유 데이터에 접근할 때마다 그 데이터에 대한 lock/unlock을 하는 방법으로 해결해 주어야 합니다.
-
대표적으로 세마포어와 뮤텍스가 있습니다.
2개의 프로세스의 Mutual Exclusion
-
2개 프로세스가 있다고 할 때 상호 배제를 구현하는 방법들을 각자의 단점과 발전과정을 중심으로 알아보겠습니다.
-
이해가 쉽도록 flag 값을 A, B라고 적었지만 실제로는 0과 1입니다.
Strict Alternation
//A 프로세스의 구조
while(1){
while(turn != A);
V++; //critical section
turn = B;
}Strict Alternation은 turn 변수를 이용해 A 프로세스와 B 프로세스 중 하나에 순서를 준다. 위 코드는 turn이 A일 때에 임계 영역에 들어가지 않고 while문으로 대기하다가 임계 영역에서 동작을 마치면 turn을 B로 준다. 따라서 상호 배제를 만족한다.
하지만 이 코드는 임계 영역의 실행 순서를 두 프로세스가 교대로 가져야만 한다. 예를 들어 turn이 A가 되어 임계 구역 내부 코드를 실행한 후 turn이 B가 되었는데 B 프로세스가 실행될 필요가 없다면, A 프로세스는 두 번 연속해서 임계 영역에 들어갈 수 없다.
Dekker's Algorithm
//A 프로세스의 구조
while(1){
flag[A] = true;
while(flag[B]){
if(turn == B){
flag[A] = false;
while(turn == B);
flag[A] = true;
}
}
V++; //critical section
flag[A] = false;
turn = B;
}데커의 알고리즘은 2개의 프로세스를 위한 최초의 정확한 상호 배제 해결법으로 알려져 있다. 구성요소는 다음과 같습니다.
- flag : 초기값은 flag [0] = flag [1] = false이고 임계 영역에 들어가겠다는 표시는 true로 한다.
- turn : 0 또는 1의 값을 갖는다. 0인 경우엔 A의 순서, 1인 경우엔 B의 순서이나 위 코드에는 이해를 위해 A, B로 표시한다.
두 프로세스는 동시에 진행하면서 자신의 flag를 true로 하고 상대방 flag를 검사한 다음 turn값에 따라서 if 이하 절을 수행하거나 수행하지 않을 수 있고, 결국 turn값이 A이면 A 프로세스가 진입하고 turn값이 B이면 B 프로세스가 진입하게 됩니다. 따라서 한 프로세스는 두 번 연속해서 임계 영역에 진입할 수 있습니다.
Peterson's Algorithm
//A 프로세스의 구조
while(1){
flag[A] = true;
turn = B;
while(flag[B] && turn == B);
V++; //critical section
flag[i] = false;
}피터슨의 알고리즘은 모든 상호 배제를 위한 추가 조건을 만족하고 데커의 알고리즘보다 단순하다. 구성요소는 데커의 알고리즘과 같습니다.
-
A 프로세스를 동작시키고 싶다면 임계 영역에 들어가고 싶다는 표시로 flag [A]를 true로 만든다.
-
turn 변수를 B로 설정하고 내부 while문을 수행한다.
-
이때 B 프로세스가 들어갈 의사표시를 하지 않았다면, 즉 flag [B]가 false라면 A 프로세스는 임계 영역에 바로 들어갈 수 있다.
-
그러나 만약 두 프로세스가 동시에 동작하려고 하면 turn 변수가 늦게 수행된 프로세스가 내부 while문에서 기다리며 순서를 양보한다.
-
먼저 임계 영역에 들어갔던 프로세스는 나오면서 자신의 flag를 false로 만들고 다른 프로세스가 임계 영역에 들어가는 것을 허용한다.
-
따라서 두 프로세스가 동시에 수행될 때 내부 while문의 turn값에 따라서 어떤 프로세스가 임계 영역에 들어갈지가 결정된다. turn이 A이면 B 프로세스가 수행되고 turn이 B이면 A 프로세스가 먼저 수행된다.
11. 세마포어(Semaphore) & 뮤텍스(Mutex)
세마포어(Semaphore)
공유된 자원에 여러 프로세스가 동시에 접근하면서 문제가 발생할 수 있다. 이때 공유된 자원의 데이터는 한 번에 하나의 프로세스만 접근할 수 있도록 제한을 두어야 한다. 이를 위해 나온것이 '세마포어' 이다.
멀티프로그래밍 환경에서 공유 자원에 대한 접근을 제한하는 방법이다.
임계 구역(Critical Section)
여러 프로세스가 데이터를 공유하며 수행될 때, 각 프로세스에서 공유 데이터를 접근하는 프로그램 코드 부분이다.
공유 데이터를 여러 프로세스가 동시에 접근할 때 잘못된 결과를 만들 수 있기 때문에, 한 프로세스가 임계 구역을 수행할 때는 다른 프로세스가 접근하지 못하도록 해야 한다.
세마포어 P, V 연산
- P : 임계 구역 들어가기 전에 수행 (프로세스 진입 여부를 자원의 개수(S)를 통해 결정한다.)
- V : 임계 구역에서 나올 때 수행 ( 자원 반납을 알리고, 대기 중인 프로세스를 깨우는 신호이다.)
P(S);
// --- 임계 구역 ---
V(S);procedure P(S) --> 최초 S값은 1임
while S=0 do wait --> S가 0면 1이 될때까지 기다려야 함
S := S-1 --> S를 0로 만들어 다른 프로세스가 들어 오지 못하도록 함
end P
--- 임계 구역 ---
procedure V(S) --> 현재상태는 S가 0임
S := S+1 --> S를 1로 원위치시켜 해제하는 과정
end V한 프로세스가 P 또는 V를 수행하고 있는 동안 프로세스가 인터럽트 당하지 않게 된다. P와 V를 사용하여 임계 구역에 대한 상호배제 구현이 가능하게 된다.
예시
최초 S 값은 1이고, 현재 해당 구역을 수행할 프로세스 A, B가 있다고 가정한다.
1. 먼저 도착한 A가 P(S)를 실행하여 S를 0으로 만들고 임계구역에 들어간다.
2. 그 뒤에 도착한 B가 P(S)를 실행하지만 S가 0이므로 대기 상태가 된다.
3. A가 임계구역 수행을 마치고 V(S)를 실행하면 S는 다시 1이 된다.
4. B는 이제 P(S)에서 while문을 빠져나올 수 있고, 임계구역으로 들어가 수행한다.
뮤텍스(Mutex)
임계 구역을 가진 스레드들의 실행시간이 서로 겹치지 않고 각각 단독으로 실행되게 하는 기술이다.
상호 배제 (Mutual Exclusion)의 약자이다
해당 접근을 조율하기 위해 Lock과 Unlock을 사용한다.
- Lock : 현재 임계 구역에 들어갈 권한을 얻어온다. (만약 다른 프로세스/ 스레드가 임계 구역 수행 중이면 종료할 때까지 대기한다.)
- Unlock : 현재 임계 구역을 모두 사용했음을 알린다. (대기 중인 프로세스/스레드가 임계 구역에 진입할 수 있다.)
뮤텍스는 상태가 0, 1로 이진 세마포어라고 부르기도 한다.
뮤텍스 알고리즘
-
데커(Dekker) 알고리즘
flag와 turn 변수를 통해 임계 구역에 들어갈 프로세스/스레드를 결정하는 방식이다.
- flag : 프로세스 중 누가 임계 영역에 진입할 것인지 나타내는 변수이다.
- turn : 누가 임계구역에 들어갈 차례인지 나타내는 변수이다.
while(true) {
flag[i] = true; // 프로세스 i가 임계 구역 진입 시도
while(flag[j]) { // 프로세스 j가 현재 임계 구역에 있는지 확인
if(turn == j) { // j가 임계 구역 사용 중이면
flag[i] = false; // 프로세스 i 진입 취소
while(turn == j); // turn이 j에서 변경될 때까지 대기
flag[i] = true; // j turn이 끝나면 다시 진입 시도
}
}
}
// ------- 임계 구역 ---------
turn = j; // 임계 구역 사용 끝나면 turn을 넘김
flag[i] = false; // flag 값을 false로 바꿔 임계 구역 사용 완료를 알림
-
피터슨(Peterson) 알고리즘
데커와 유사하지만, 상대방 프로세스/스레드에게 진입 기회를 양보하는 차이가 있다. 즉 나중에 들어온 것이 먼저 한다.
while(true) {
flag[i] = true; // 프로세스 i가 임계 구역 진입 시도
turn = j; // 다른 프로세스에게 진입 기회 양보
while(flag[j] && turn == j) { // 다른 프로세스가 진입 시도하면 대기
}
}
// ------- 임계 구역 ---------
flag[i] = false; // flag 값을 false로 바꿔 임계 구역 사용 완료를 알림
-
제과점(Bakery) 알고리즘
여러 프로세스/스레드에 대한 처리가 가능한 알고리즘이다. 가장 작은 수의 번호표를 가지고 있는 프로세스가 임계 구역에 진입한다.
while(true) {
isReady[i] = true; // 번호표 받을 준비
number[i] = max(number[0~n-1]) + 1; // 현재 실행 중인 프로세스 중에 가장 큰 번호 배정
isReady[i] = false; // 번호표 수령 완료
for(j = 0; j < n; j++) { // 모든 프로세스 번호표 비교
while(isReady[j]); // 비교 프로세스가 번호표 받을 때까지 대기
while(number[j] && number[j] < number[i] && j < i);
// 프로세스 j가 번호표 가지고 있어야 함
// 프로세스 j의 번호표 < 프로세스 i의 번호표
}
}
// ------- 임계 구역 ---------
number[i] = 0; // 임계 구역 사용 종료
12. 페이징 & 세그먼테이션
다중 프로그래밍 시스템에 여러 프로세스를 수용하기 위해 주기억장치를 동적으로 분할하는 메모리 관리 작업이 필요하다.
메모리 관리 기법
-
연속 메모리 관리
프로그램 전체가 하나의 커다란 공간에 연속적으로 할당된다.
- 고정 분할 기법 : 주기억장치가 고정된 파티션으로 분할된다. (내부 단편화 발생)

- 분할 된 메모리보다 프로세스의 메모리가 적으면 사용되지 않는 메모리가 생겨 내부 단편화가 발생한다.- 동적 분할 기법: 파티션들이 동적으로 생성되며 자신의 크기와 같은 파티션에 적재된다. (외부 단편화 발생)
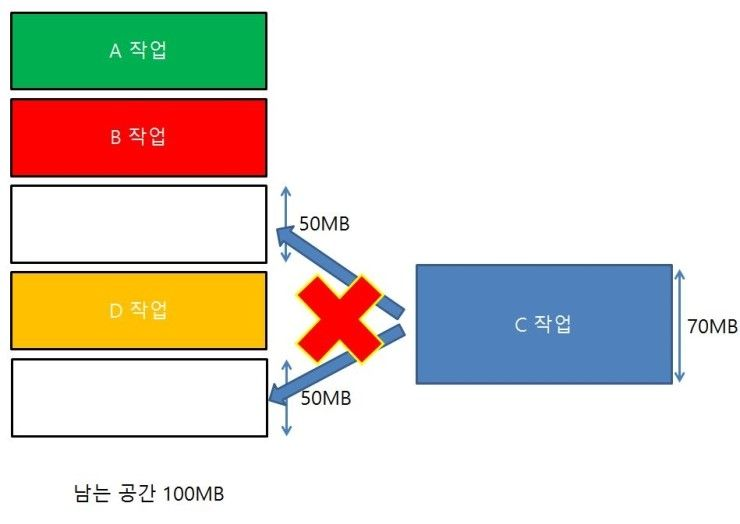 남은 공간은 100MB인데 70MB의 프로세스가 작동할 수 없는 것이 외부 단편화이다.
남은 공간은 100MB인데 70MB의 프로세스가 작동할 수 없는 것이 외부 단편화이다.
-
불연속 메모리 관리
프로그램의 일부가 서로 다른 주소 공간에 할당될 수 있는 기법이다.
- 페이지 : 고정 사이즈의 작은 프로세스 조각
- 프레임 : 페이지 크기와 같은 주기억장치 메모리 조각
- 단편화 : 기억 장치의 빈 공간 or 자료가 여러 조각으로 나뉘는 현상
- 세그먼트 : 서로 다른 크기를 가진 논리적 블록이 연속적 공간에 배치되는 것
페이지는 고정 크기를 갖고 세그멘테이션은 가변 크기를 갖는다.
페이징
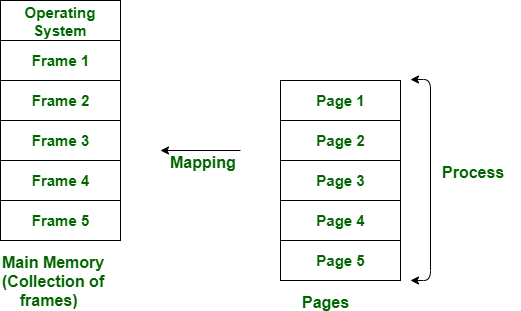
각 프로세스는 프레임들과 같은 길이를 가진 균등 페이지로 나뉜다. 외부 단편화는 생기지 않지만 소량의 내부 단편화가 존재한다.
논리 메모리는 Page라고 불리는 고정 크기의 블록으로 나누어지고, 물리 메모리는 Frame이라 불리는 페이지와 같은 크기의 블록들로 나누어진다. 보조 메모리 역시 프레임과 같은 블록들로 나눈다.
- 가상 메모리 페이징 프로세스 페이지를 전부 로드시킬 필요가 없다. 필요한 페이지가 있으면 나중에 자동으로 부른다.
세그멘테이션
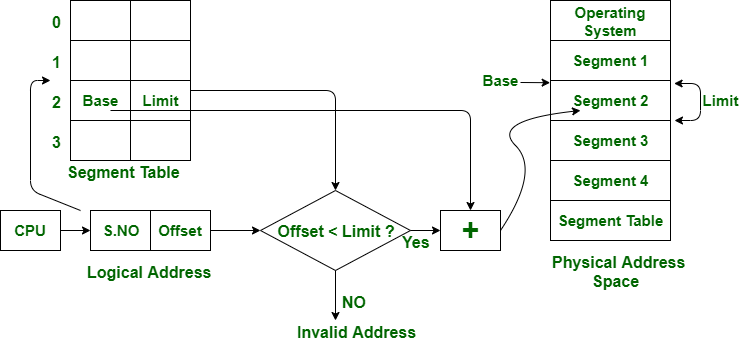
각 프로세스가 여러 세그먼트들로 나뉜다. 내부 단편화가 생기지 않지만 외부 단편화가 존재할 수 있다.
메모리 사용 효율이 개선되고 동적 분할을 통한 오버헤드가 감소한다.
페이징에서처럼 논리 메모리와 물리 메모리를 같은 크기의 블록이 아닌, 서로 다른 크기의 논리적 단위인 Segment로 분할한다.
세그먼트 테이블에는 각 세그먼트의 기준(세그먼트의 시작 물리 주소)와 한계(세그먼트의 길이)를 저장한다.
서로 다른 크기의 세그멘트들이 메모리에 적재되고 제거되는 일이 반복되다 보면, 자유 공간들이 많은 수의 작은 조각들로 나누어져 못 쓰게 될 수도 있다.(외부 단편화)
https://dull-telescope-c1b.notion.site/59c5a5be85d44fc9b7c6689752bf27f0
13. 페이지 교체 알고리즘
Page Fault가 발생했을 때 새로운 페이지를 할당해야 하는데 자리가 없을 때 현재 할당된 페이지 중 어떤 것을 교체할지 결정하는 알고리즘이다.
가상 메모리는 요구 페이지 기법을 통해 필요한 페이지만 메모리에 적재하고 사용하지 않는 부분은 그대로 둔다. 하지만 필요한 페이지만 올려 놓더라도 메모리는 결국 가득 차게 되고, 올라와있던 페이지가 사용이 다 된 후에도 자리만 차지하고 있을 수 있다. 따라서 메모리가 가득 차면, 추가로 페이지를 가져오기 위해 안쓰는 페이지는 out하고, 해당 공간에 현재 필요한 페이지를 in 해야 한다. 이때 out시키는 page는 victim page라고하고 페이지 교체 알고리즘은 이 victim page를 정하는 알고리즘이다.
-
비선점 스케줄링 은 이미 할당된 CPU를 다른 프로세스가 강제로 빼앗아 사용할 수 없는 스케줄링 기법입니다. 선점 방식보다 스케줄러 호출 빈도가 낮고 문맥 교환에 의한 오버헤드도 적습니다. 일괄처리 시스템에 적합하고, CPU 사용 시간이 긴 하나의 프로세스가 CPU 사용 시간이 짧은 여러 프로세스를 오랫동안 대기시킬 수 있으므로, 처리율이 떨어질 수 있다는 단점도 있습니다.
-
선점 스케줄링 은 하나의 프로세스가 CPU를 할당 받아 실행하고 있을 때 우선 순위가 높은 다른 프로세스가 CPU를 강제로 빼앗아 사용할 수 있는 기법입니다. 모든 프로세스에게 CPU 사용 시간을 동일하게 부여할 수 있으며, 빠른 응답시간을 요하는 대화식 시분할 시스템에 적합하며 긴급한 프로세서를 제어할 수 있습니다.
1. FIFO 알고리즘(비선점)
First in First Out으로 먼저 올라온 페이지를 먼저 내보내는 알고리즘

2. OPT 알고리즘(비선점)
Optimal Page Replacement 알고리즘으로, 앞으로 가장 사용하지 않을 페이지를 가장 우선적으로 내보냄
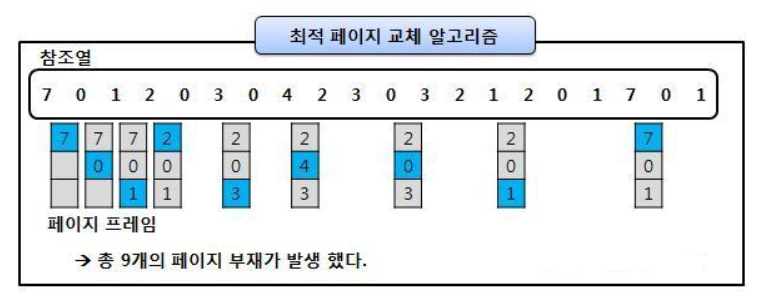
FIFO에 비해 page fault 횟수를 감소시킬 수 있음
하지만 실질적으로 페이지가 앞으로 잘 사용되지 않을 것이라는 보장이 없기 때문에 수행하기 어려운 알고리즘임
3. SJF(Shortest Remaining Time First Scheduling) (비선점)
평균 대기 시간을 최소화하기 위해 CPU 점유 시간이 가장 짧은 프로세스에 CPU를 먼저 할당하는 방식입니다. 실행 시간이 긴 프로세스는 실행 시간이 짧은 프로세스에게 할당 순위가 밀려 연기 상태에 빠질 수 있다는 단점이 있습니다.
4. HRN(Highest Response-ratio Next) (비선점)
실행시간이 긴 프로세스에 불리한 SJF기법을 보완하기 위한 것으로 대기 시간과 서비스 시간을 이용하는 방식입니다. '우선순위 = (대기시간+서비스시간)/서비스시간' 의 공식을 이용하여 우선순위를 계산하여 우선순위가 높은 것부터 실행하는 방식입니다.
5. LRU 알고리즘(비선점)
Lesat-Recently-Used, 최근에 사용하지 않은 페이지를 가장 먼저 내려보내는 알고리즘
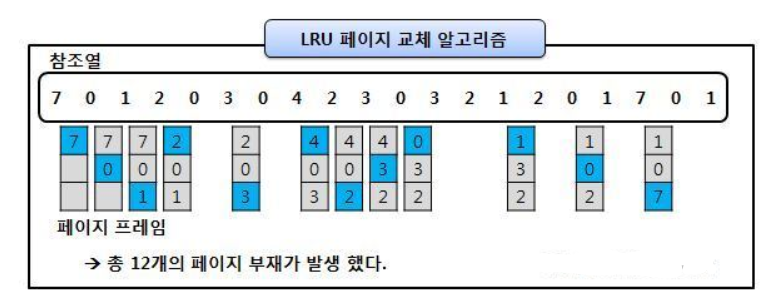
OPT보다는 페이지 결함이 더 일어날 수 있지만, 실제로 사용할 수 있는 페이지 교체 알고리즘에서는 가장 좋은 방법 중 하나이다.
6. Round Robin (선점 스케줄링)
프로세스들 사이에 우선순위를 두지 않고, 순서대로 시간단위로 CPU를 할당하는 방식입니다. 보통 시간 단위는 10ms ~ 100ms 정도이고 시간 단위동안 수행한 프로세스는 준비 큐의 끝으로 밀려나게 됩니다. 문맥 전환의 오버헤드가 큰 반면, 응답시간이 짧아지는 장점이 있어 실시간 시스템에 유리하고, 할당되는 시간이 클 경우 비선점 FIFO기법과 같아지게 됩니다.
7. SRT(선점 스케줄링)
비선점 스케줄링인 SJF 기법을 선점 형태로 변경한 기법입니다. SJF처럼 CPU 점유 시간이 가장 짧은 프로세스에 CPU를 먼저 할당하는 방식으로, 단지 차이점은 ‘선점형’으로 바뀌어 중요한 프로세스가 있으면 점유시간이 길어도 먼저 실행 시킬수 있는 권한이 생겼다는 것입니다.
8. MQ, Multi-level Queue(선점 스케줄링)
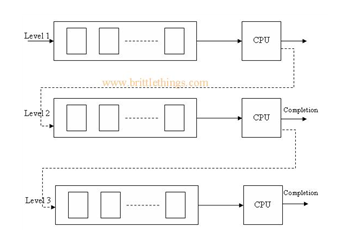
프로세스를 특정 그룹으로 분류할 수 있을 경우 그룹에 따라 각기 다른 분비 상태 큐를 사용하는 기법입니다. 프로세스가 특정 그룹의 준비상태 큐에 들어갈 경우 다른 준비상태 큐로 이동할 수 없습니다. 하위 준비 상태 큐에 있는 프로세스를 실행하는 도중이라도 상위 준비 상태 큐에 프로세스가 들어오면 상위 프로세스에게 CPU를 할당해야 합니다.
사진에 보이는 것처럼 Level 1, 2, 3으로 큐가 불리 되어 있습니다. 레벨 1의 큐가 모두 완료 되어야만 레벨 2의 큐로 넘어갈 수 있고 레벨2의 큐가 모두 완료되어야 그다음으로 넘어 갈수 있는 방식입니다
교체 방식
- Global 교체
메모리 상의 모든 프로세스 페이지에 대해 교체하는 방식
- Local 교체
메모리 상의 자기 프로세스 페이지에서만 교체하는 방식
다중 프로그래밍의 경우, 메인 메모리에 다양한 프로세스가 동시에 올라올 수 있음
따라서, 다양한 프로세스의 페이지가 메모리에 존재함
페이지 교체 시, 다양한 페이지 교체 알고리즘을 활용해 victim page를 선정하는데, 선정 기준을 Global로 하느냐, Local로 하느냐에 대한 차이
→ 실제로는 전체를 기준으로 페이지를 교체하는 것이 더 효율적이라고 함. 자기 프로세스 페이지에서만 교체를 하면, 교체를 해야할 때 각각 모두 교체를 진행해야 하므로 비효율적이다.
14. 메모리(Memory)
메모리 종류

- 레지스터
- 캐시 메모리
- 주 기억 장치
- 캐시 메모리
- 보조 기억 장치
메인 메모리(주 기억 장치)
메인 메모리는 CPU가 직접 접근할 수 있는 기억장치로 프로세스가 실행되려면 프로그램이 메모리에 올라와야 한다. 메인 메모리에는 CPU가 직접 접근이 가능하지만, 상수를 쓰는 것 이외의 연산은 CPU에서 바로 실행 할 수 없고 메모리의 값을 레지스터로 로드 → 연산 → 연산 결과 적용의 단계를 거쳐야 한다.
보조 기억 장치
CPU에서 직접 접근이 불가능한 메모리이다. 접근 하기 위해서는 디바이스 드라이버와 시스템 콜을 통하여 기억 장치의 특정 위치의 내용을 주 기억 장치로 로드한 뒤 읽어야 한다. 보조 기억 장치는 '저장 기능'만 갖고 있다.
시스템 콜 : '0번 디스크 8번 트랙 12번 섹터를 주기억장치 1024번지에 로드하라'
그 후 : '1024 + 16번지의 값을 레지스터 1번에 저장하라' (1024 썼으니깐 그 다음 번지 가야함)
MMU (Memory Management Unit)
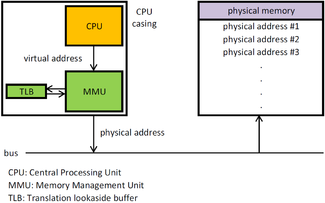
MMU는 메모리를 관리해주는 장치로 논리 주소를 물리 주소로 변환해준다. 또한 메모리 보호나 캐시 관리 등 CPU가 메모리에 접근하는 것을 총괄해주는 하드웨어이다.
MMU는 CPU 코어 안에 탑재되어 가상 주소를 실제 메모리 주소로 변환을 해준다.
-
Page Table : Virtual Address와 Physical Address 연결해주는 Table
-
Translation Table Base Address : MMU의 레지스터 중 하나에 저장되어 있는 Table이 존재하는 위치
MMU 동작
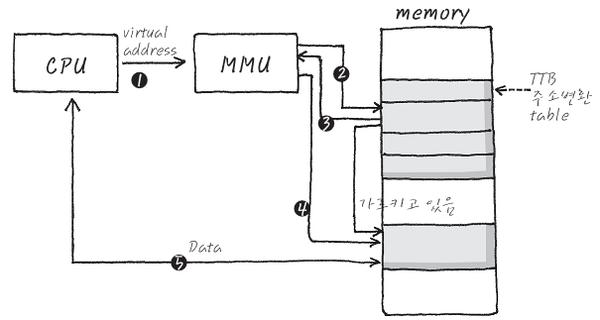
-
CPU는 Memeory의 어딘가에 Access하기 위해 Virtual Address 생성
-
MMU는 이 Virtual Address를 받아 Memory의 TTB에서부터 시작해서 존재하는 Page Table에 접근
-
찾아가 Page Table안에 Physical 주소를 찾아내어 주소 신호 발생
-
Memory는 해당 Physical 주소 안에 Data를 출력해서 CPU에게 전달
-
Data가 CPU에 전달 됨
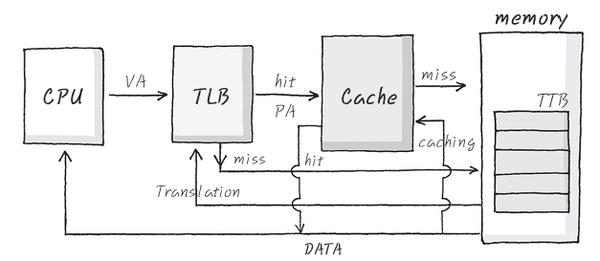
TLB(Translation Lookaside Buffer)
- 가상 주소 테이블의 캐시역할을 한다.
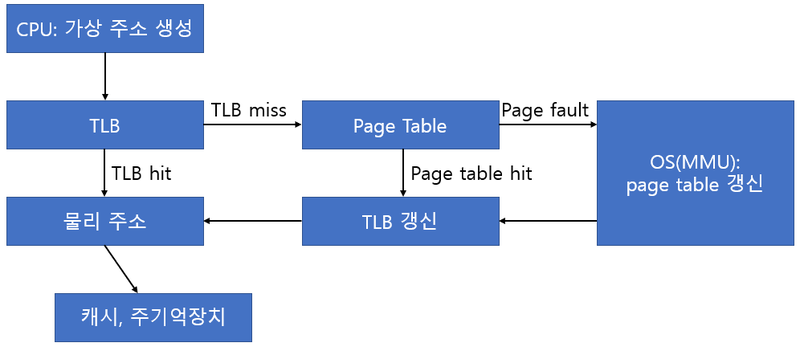
-
CPU가 생성한 가상 주소에 대한 페이지 정보가 TLB에 존재한다면 시간 지체 없이 바로 물리적 주소를 생성한다. (TLB HIT)
-
존재하지 않는다면 페이지 테이블을 참조하는데, 이때 테이블에서 적중하면 TLB를 갱신하는 작업을 한다. (TLB MISS)
-
페이지 테이블에서 Page Fault가 발생하는 경우, OS에서 그 처리를 담당하는데 특히 MMU가 가상 기억 장치 운영을 담당한다.
*PageFault : 메모리에 적재된 페이지 중에 사용 가능한 페이지가 없는 경우이다. 빈 페이지가 하나도 없거나 정한 수보다 적을 때 발생한다.
메모리 과할당(over allocating)
실제 메모리의 사이즈보다 더 큰 사이즈의 메모리를 프로세스에 할당한 상황
페이지 기법과 같은 메모리 관리 기법은 사용자가 눈치 채지 못하도록 눈속임을 통해 메모리를 할당해줄 수 있다. 가상 메모리를 사용하여 물리 메모리의 사용량보다 더 큰 사이즈의 메모리를 사용 할 수있는 것이다.
과할당 상황에 대해서 사용자를 속인 것을 들킬만한 상황이 존재함
-
프로세스 실행 도중 페이지 폴트 발생
-
페이지 폴트를 발생시킨 페이지 위치를 디스크에서 찾음
-
메모리의 빈 프레임에 페이지를 올려야 하는데, 모든 메모리가 사용중이라 빈 프레임이 없음
이러한 과할당을 해결하기 위해선, 빈 프레임을 확보할 수 있어야 함
-
메모리에 올라와 있는 한 프로세스를 종료시켜 빈 프레임을 얻음
-
프로세스 하나를 swap out하고, 이 공간을 빈 프레임으로 활용
swapping 기법을 통해 공간을 바꿔치기하는 2번 방법과는 달리 1번은 사용자에게 페이징 시스템을 들킬 가능성이 매우 높아서 하면 안됨
페이징 기법은 사용자 모르게 시스템 능률을 높이기 위해 선택한 일이므로 들키지 않게 처리해야 하기 때문에 2번과 같은 해결책을 통해 페이지 교체가 이루어져야 한다.
페이지 교체
메모리 과할당이 발생했을 때, 프로세스 하나를 swap out해서 빈 프레임을 확보하는 것
-
프로세스 실행 도중 페이지 부재 발생
-
페이지 폴트를 발생시킨 페이지 위치를 디스크에서 찾음
-
메모리에 빈 프레임이 있는지 확인
-
빈 프레임이 있으면 해당 프레임을 사용
-
빈 프레임이 없으면, victim 프레임을 선정해 디스크에 기록하고 페이지 테이블 업데이트
-
-
빈 프레임에 페이지 폴트가 발생한 페이지를 올리고, 페이지 테이블 업데이트
페이지 교체가 이루어지면 아무일이 없던것 처럼 프로세스를 계속 수행시켜주면서 사용자가 알지 못하도록 해야 함
이때, 아무일도 일어나지 않은 것처럼 하려면, 페이지 교체 당시 오버헤드를 최대한 줄여야 함
-
오버헤드
-
빈 프레임이 없는 상황에서 victim 프레임을 비울 때와 원하는 페이지를 프레임으로 올릴 때 두 번의 디스크 접근이 이루어진다.
-
페이지 교체가 많이 이루어지면, 이처럼 입출력 연산이 많이 발생하게 되면서 오버헤드 문제가 발생
1) 변경비트를 모든 페이지마다 둬서, victim 페이지가 정해지면 해당 페이지의 비트를 확인
-
해당 비트가 set 상태면? → 해당 페이지 내용이 디스크 상의 페이지 내용과 달라졌다는 뜻 (즉, 페이지가 메모리 올라온 이후 한번이라도 수정이 일어났던 것. 따라서 이건 디스크에 기록해야함)
-
bit가 clear 상태라면? → 디스크 상의 페이지 내용과 메모리 상의 페이지가 정확히 일치하는 상황 (즉, 디스크와 내용이 같아서 기록할 필요가 없음)
-
비트를 활용해 디스크에 기록하는 횟수를 줄이면서 오버헤드에 대한 수를 최대 절반으로 감소시키는 방법임
2) 페이지 교체 알고리즘을 상황에 따라 잘 선택해야 함
-
현재 상황에서 페이지 폴트를 발생할 확률을 최대한 줄여줄 수 있는 교체 알고리즘을 사용
-
FIFO, OPT, LRU
-
15. 파일 시스템
-
컴퓨터에서 파일이나 자료를 쉽게 찾을 수 있도록, 유지 및 관리하는 방법이다.
- 저장 매체에는 수많은 파일이 있기 때문에 이런 파일들을 관리하는 방법을 말한다.
-
특징
-
커널 영역에서 동작한다.
-
파일 CRUD 기능을 원활히 수행하기 위해 사용한다.
-
Create
-
Read
-
Update
-
Delete
-
-
계층적 디렉터리 구조를 가진다.
-
디스크 파티션 별로 하나씩 둘 수 있다
-
-
역할
-
파일 관리
-
보조 저장소 관리
-
파일 무결성 메커니즘
-
접근 방법 제공
-
-
개발 목적
-
하드디스크와 메인 메모리 속도차를 줄인다.
-
파일 관리
-
하드디스크 용량 효율적 이용한다.
-
-
구조
-
메타 영역 : 데이터 영역에 기록된 파일의 이름, 위치, 크기, 시간정보, 삭제유무 등의 파일 정보
-
데이터 영역 : 파일의 데이터
-
접근 방법
- 순차 접근(Sequential Access)
가장 간단한 접근 방법으로, 대부분 연산은 read와 write

현재 위치를 가리키는 포인터에서 시스템 콜이 발생할 경우 포인터를 앞으로 보내면서 read와 write를 진행. 뒤로 돌아갈 땐 지정한 offset만큼 되감기를 해야 한다. (테이프 모델 기반)
- 직접 접근(Direct Access)
특별한 순서없이, 빠르게 레코드를 read, write 가능
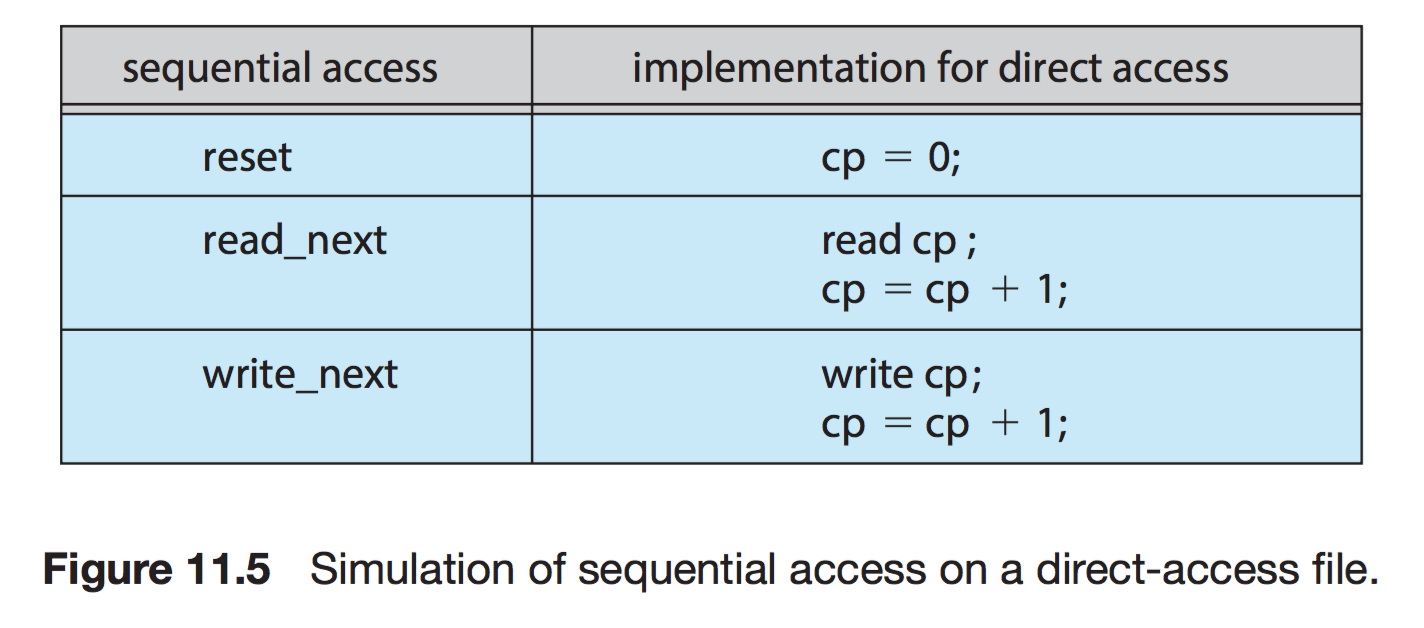
현재 위치를 가리키는 cp 변수만 유지하면 직접 접근 파일을 가지고 순차 파일 기능을 쉽게 구현이 가능하다.
무작위 파일 블록에 대한 임의 접근을 허용한다. 따라서 순서의 제약이 없음
대규모 정보를 접근할 때 유용하기 때문에 '데이터베이스'에 활용된다.
3. 기타 접근
직접 접근 파일에 기반하여 색인 구축
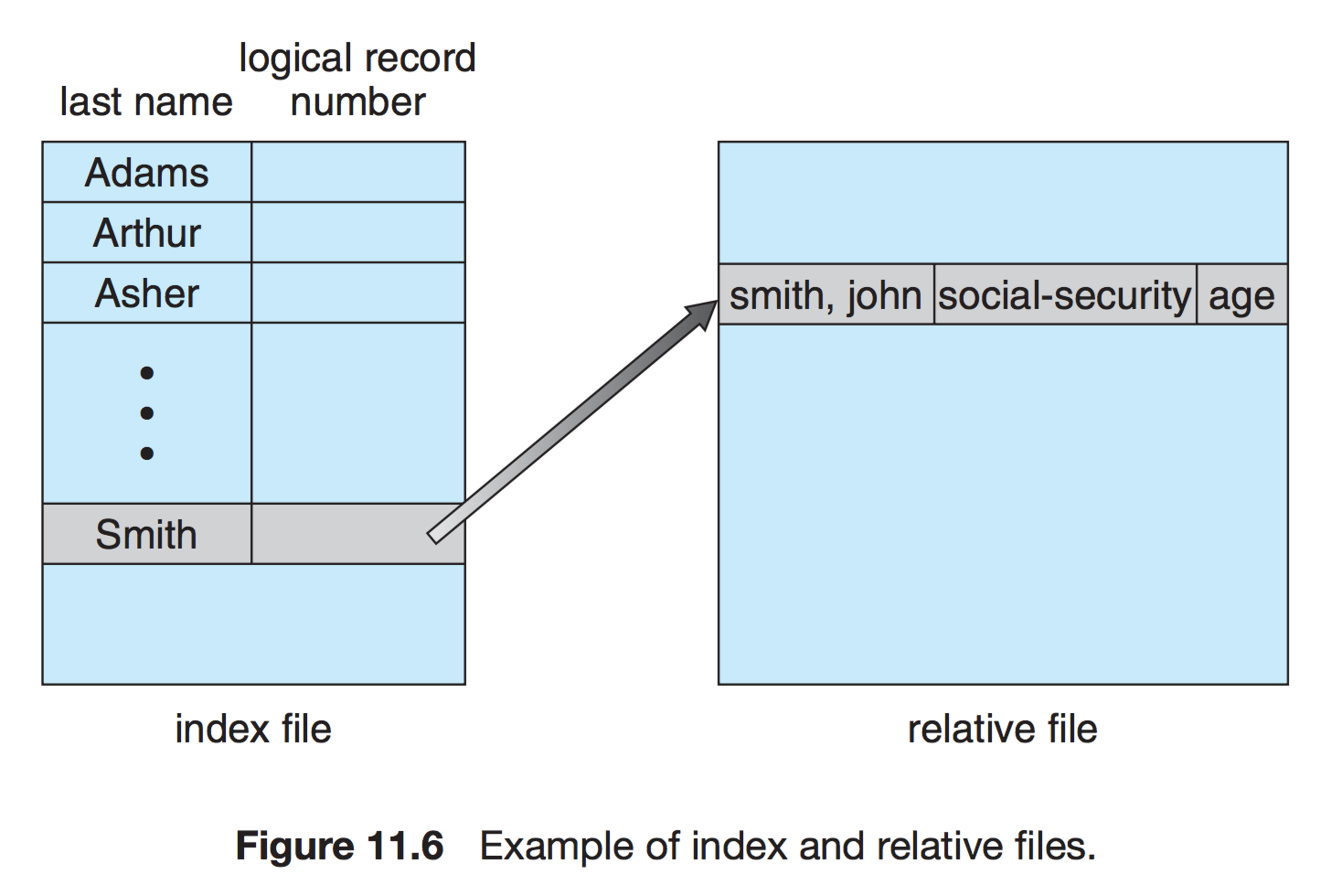
크기가 큰 파일을 입출력 탐색할 수 있게 도와주는 방법이다.
디렉터리와 디스크 구조
- 1단계 디렉터리
- 가장 간단한 구조
- 파일들은 서로 유일한 이름을 가짐. 서로 다른 사용자라도 같은 이름 사용 불가
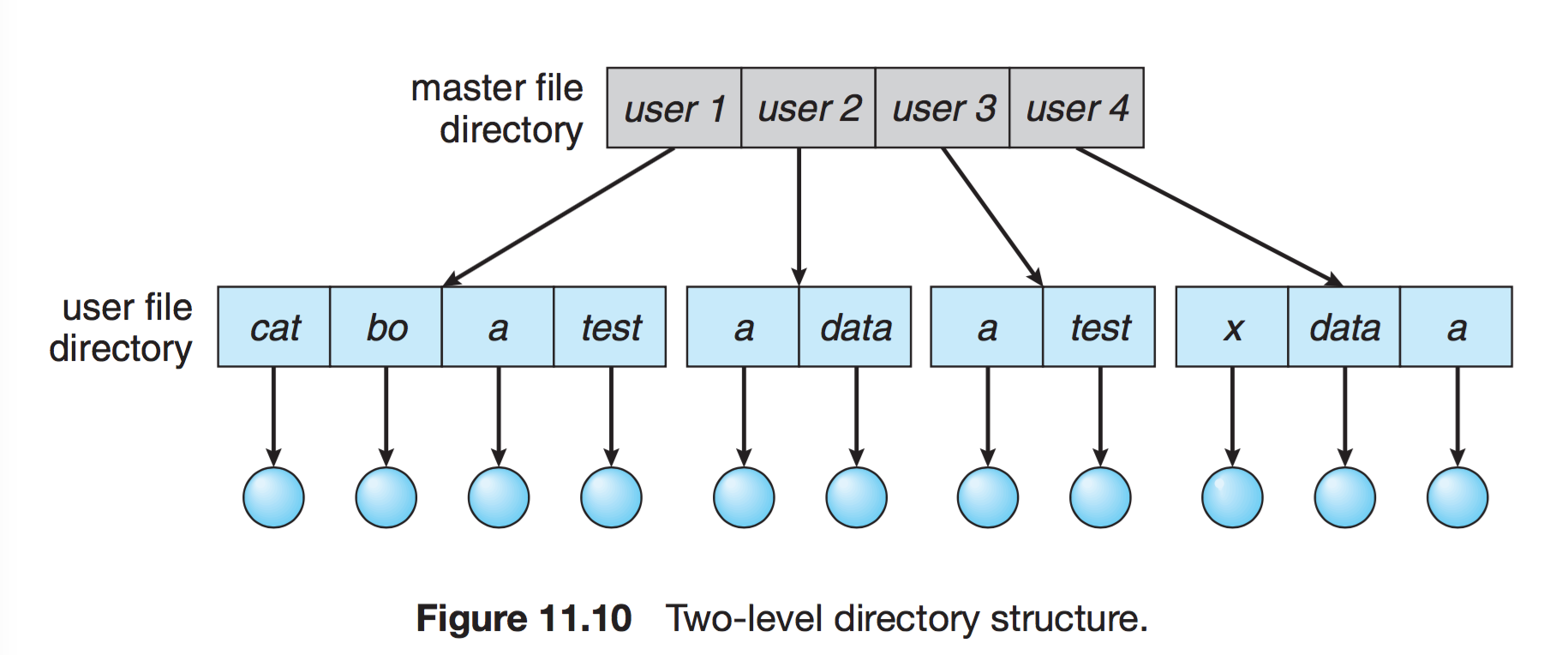
- 2단계 디렉터리
- 사용자에게 개별적인 디렉터리 만들어줌
- UFD : 자신만의 사용자 파일 디렉터리
- MFD : 사용자의 이름과 계정번호로 색인되어 있는 디렉터리
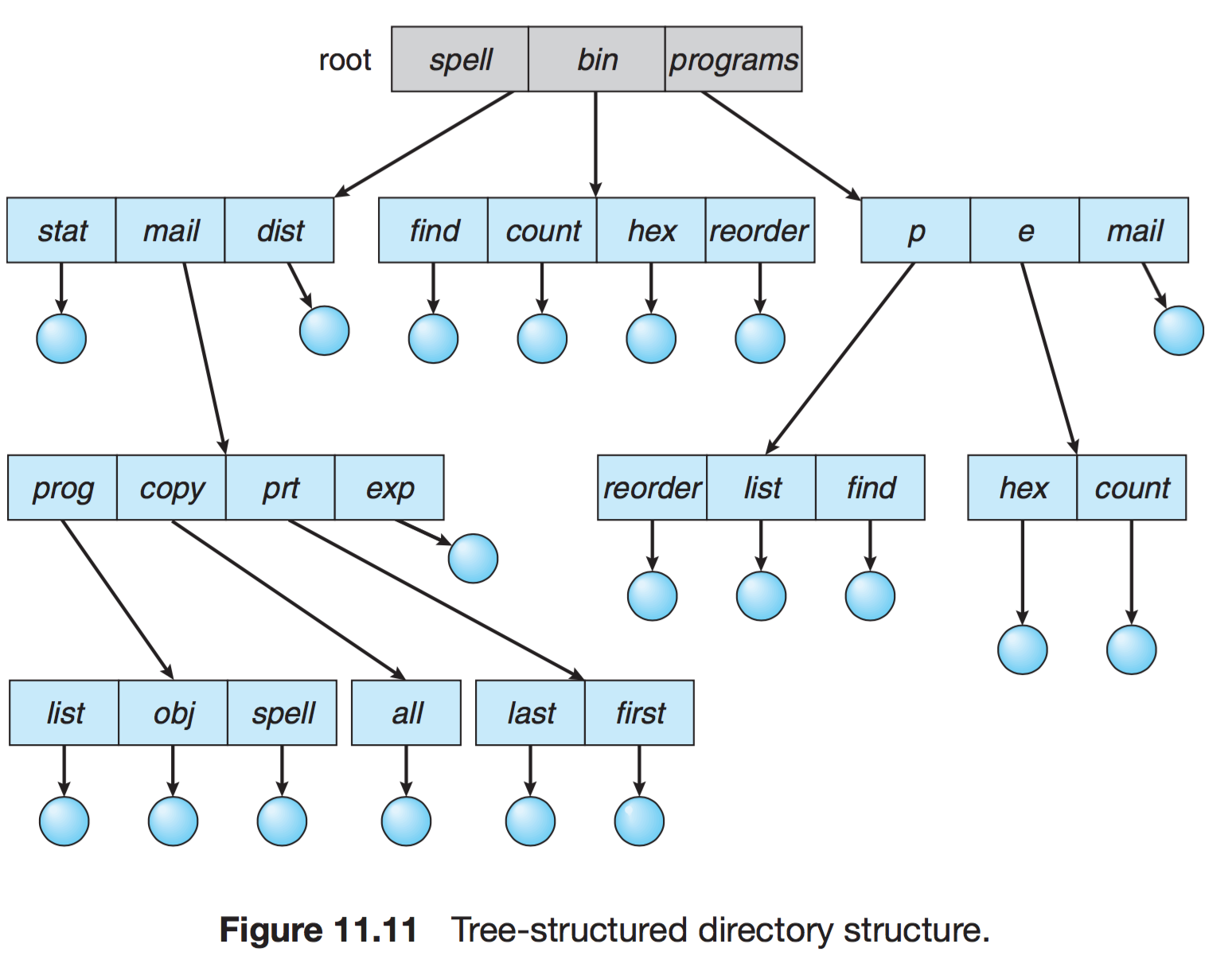
- 트리 구조 디렉터리
- 2단계 구조 확장된 다단계 트리 구조
- 한 비트를 활용하여, 일반 파일(0)인지 디렉터리 파일(1) 구분
- 그래프 구조 디렉터리
- 순환이 발생하지 않도록 하위 디렉터리가 아닌 파일에 대한 링크만 허용하거나, 가비지 컬렉션을 이용해 전체 파일 시스템을 순회하고 접근 가능한 모든 것을 표시
- 링크가 있으면 우회하여 순환을 피할 수 있다

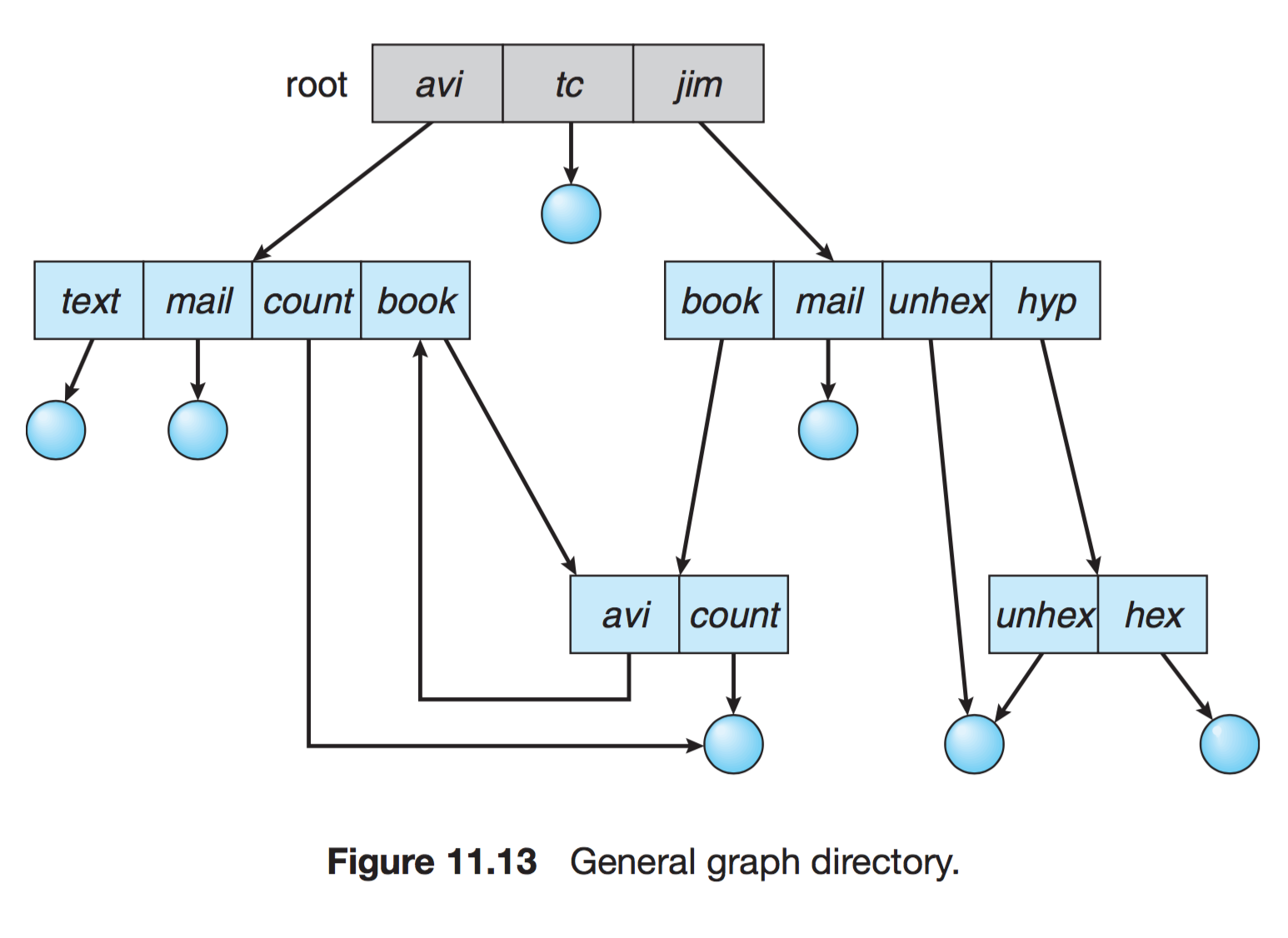
- 심볼릭 링크 (Symbolic Link) : 파일 또는 디렉토리에 대한 포인터로, 심볼릭 링크를 삭제해도 이는 파일에 영향을 주지 않는다. 윈도우에서 일반적으로 사용하는 바로가기 아이콘과 같다.
- 하드 링크 (Hard Link) : 파일에 대해서만 가능하고, 한 파일 시스템에서만 가능하다. 하드 링크는 원본 파일과 직접 연결된 복사본을 생성하는 것과 같다. 즉 하드 링크를 통해 파일을 수정하면 원본 파일도 수정된다.
