
애너그램이란
- 일종의 언어유희로 문자를 재배열하여 다른 뜻을 가진 단어로 바꾸는 것을 말한다.
1. 정렬하여 딕셔너리에 추가
class Solution:
def groupAnagrams(self, strs: List[str]) -> List[List[str]]:
anagrams = collections.defaultdict(list)
for word in strs:
#정렬하여 딕셔너리에 추가
anagrams[''.join(sorted(word))].append(word)
return anagrams.values()
-
애너그램을 판단하는 가장 간단한 방법은 정렬하여 비교하는 것으로 애너그램 관계인 단어들을 정렬하면, 서로 같은 값을 가게 되기 때문이다.
-
sorted() 는 문자열도 잘 정렬하며 결과를 리스트 형태로 리턴
-
이를 다시 키로 사용하기 위해 join() 으로 합쳐 이 값을 딕셔너리로 구성
-
애너그램끼리는 같은 키를 갖게 되고 여기에append() 하는 형태
-
defaultdict() 에러가 나지 않도록 다음과 같이 항상 디폴트를 생성
✔ 여러가지 정렬 방법
-
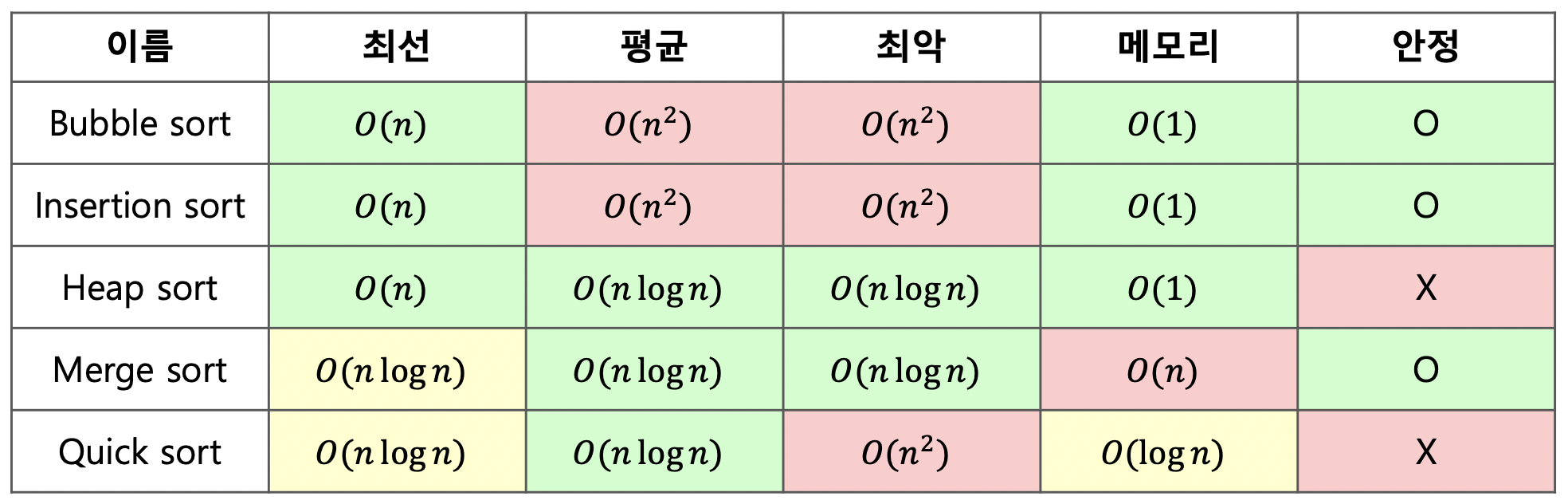
sort(): 제자리 정렬으로 일반적으로 제자리 정렬 알고리즘은 입력을 출력으로 덮어쓰기 때문에 별도의 추가 공간이 필요하지 않으며, 리턴 값이 없다.
-
sorted()는 정렬 결과를 별도로 리턴하므로 주의가 필요하다
-
key= 옵션을 지정해 정렬을 위한 키 또는 함수를 별도로 지정할 수 있다.
-
예: 정렬을 위함 함수로 길이를 구하는 len을 지정한 경우
-
>>> c = ['ccc', 'aaaa', 'd', 'bb']
>>> sorted(c, key=len)
['d', 'bb', 'ccc', 'aaaa']- 예: 함수를 이용해 첫 문자열(s[0])과 마지막 문자열(s[-1]) 순으로 정렬하도록 지정
a = ['cde','cfc','abc']
def fn(s):
return s[0],s[-1]
print(sorted(a, key=fn))
-------------------------
['abc', 'cfc', 'cde']➕ 람다(lamba) 사용
>>> a = ['cde', 'cfc'. 'abc']
>>> sorted(a, key=lambda s: (s[0], s[-1]))
['abc', 'cfc', 'cde']✔팀소트 정렬
(https://d2.naver.com/helloworld/0315536)
시간 복잡도가 O(n\log{}n)O(nlogn)이라는 말은 실제 동작 시간은 C × nlogn + α라는 의미이다. 상대적으로 무시할 수 있는 부분인 αα 부분을 제하면nlogn에는 앞에 C라는 상수가 곱해져 있어 이 값에 따라 실제 동작 시간에 큰 차이가 생긴다. 이 C라는 값에 큰 영향을 끼치는 요소로 '알고리즘이 참조 지역성(Locality of reference) 원리를 얼마나 잘 만족하는가'가 있다.
참조 지역성 원리란, CPU가 미래에 원하는 데이터를 예측하여 속도가 빠른 장치인 캐시 메모리에 담아 놓는데 이때의 예측률을 높이기 위하여 사용하는 원리이다. 쉽게 말하자면, 최근에 참조한 메모리나 그 메모리와 인접한 메모리를 다시 참조할 확률이 높다는 이론을 기반으로 캐시 메모리에 담아놓는 것이다. 메모리를 연속으로 읽는 작업은 캐시 메모리에서 읽어오기에 빠른 반면, 무작위로 읽는 작업은 메인 메모리에서 읽어오기에 속도의 차이가 있다.
팀소트의 등장
2002년 소프트웨어 엔지니어 Tim Peters에 의하여 Tim sort가 등장했다. 이 정렬 알고리즘은 Insertion sort와 Merge sort를 결합하여 만든 정렬이다.
실생활 데이터의 특성을 고려하여 더욱 빠르게 고안된 이 알고리즘은 최선의 시간 복잡도는 O(n), 평균은 O(nlogn), 최악의 경우 시간 복잡도는 O(nlogn)이다. Tim sort는 안정적인 두 정렬 방법을 결합했기에 안정적이며, 추가 메모리는 사용하지만 기존의 Merge sort에 비해 적은 추가 메모리를 사용하여 다른 O(nlogn) 정렬 알고리즘의 단점을 최대한 극복한 알고리즘이다. 현재 2.3 이후 버전의 Python, Java SE 7, Android, Google chrome (V8), 그리고 swift까지 많은 프로그래밍 언어에서 표준 정렬 알고리즘으로 채택되어 사용되고 있다.
