시험 예정 3일 전에 계엄령 때문에 뉴스보느라 다시 공부합니다. ^^
[IT 현직자에게 묻다]Cloud Solutions Architect, 장준형님
1. 요약
-
AWS Detective와 GuardDuty의 차이점
-
GuardDuty: 위협을 탐지하고 경고를 생성 (탐지 중심)
-
Detective: GuardDuty 및 기타 로그에서 제공된 정보를 분석하여 위협의 원인을 조사 (조사 중심)
시간 최소화
-
프로덕션 데이터를 테스틑 환경에 복제하는 데 필요한 시간을 최소화 -> 스냅샷
-
밀리초 지연 시간으로 시간당 수백만개 요청 처리 -> DynamoDB
-
지연 시간 가장 짧은 리전으로 사용자를 라우팅 -> 각 리전에서 NLB를 AWS Global Accelerator 엔드포인트로 사용
비용 최소화
-
DB 인스턴스의 컴퓨팅 및 메모리 속성을 줄이지 않고 테스트 실행 비용을 줄이기 -> 스냅샷 보관 & 복원
-
(사전 구축된 정적)웹 사이트 호스팅 비용 효율적인 방법 -> S3 버킷 생성 후 웹사이트 호스팅S3에서 이미지 다운로드, EC2 고가용성 이미지 처리 어플리케이션 처리시 데이터 전송 요금 피하려면 -> S3 용 게이트웨이 VPC 엔드포인트를 배포
-
온디맨드 백업 복사, 할당 태그 추가 온디맨드 백업을 콜드 스토리지로 전환하여 비용 절감 가능 -> AWS Backup + DynamoDB
-
S3 버킷 간의 데이터 전송 비용 낮추려면 -> S3 교차 리전 복제(CRR)를 사용
확장성 관련
-
확장성이 뛰어남, 밀리초 지연 시간으로 시간당 수백만개 요청 처리 -> DynamoDB
-
대량의 데이터 처리 + 확장성 개선 -> SQS queue + Lambda 조합
-
수백만 건의 세부 정보를 내부 애플리케이션과 공유, 확장 가능한 실시간 솔루션 -> Kinesis Data Streams
-
필요에 따라 확장 가능한 파일 시스템(가용성, 내구성 뛰어남) -> Amazon EFS(Elastic File System)
고가용성 & 내구성
-
파일 액세스 방식 보전하는 윈도우용 스토리지 솔루션 -> Amazon FSx for Windows File Server
-
필요에 따라 확장 가능한 파일 시스템(가용성, 내구성 뛰어남) -> Amazon EFS(Elastic File System)
-
최소한의 가동 중지 시간과 최소한의 데이터 손실로 고가용성을 달성 -> 여러 가용 영역을 사용하도록 Auto Scaling 그룹을 구성
운영 오버헤드가 적은 솔루션
-
최소 운영 오버헤드로 처리 -> S3 + CloudFront (정적 웹 사이트),
-
운영 오버헤드 적은 EC2 비용 심층 분석 -> AWS Cost Explorer
-
트래픽이 웹 서버에 도달하기 전, 모든 트래픽을 검사 -> VPC에 Gateway Load Balancer 배포
-
회사 정책 준수 검사 운영 노력 최소화 -> AWS Config
-
SaaS와 AWS 서비스 간에 데이터를 안전하게 전송 -> Amazon AppFlow
-
기본 인프라 관리 책임 X, 컨테이너를 실행하기 위해 Amazon ECS 에 사용 -> AWS Fargate
-
많은 쿼리 수행으로 성능이 낮아지는 것을 방지 -> read replica 를 통해 쿼리 부하를 분산
데이터베이스 성능
-
일부 삽입 작업이 10 초 이상 걸리는 성능 문제 해결 -> 프로비저닝된 IOPS SSD로 변경 "I/O 집약적"
-
내부 사용자 인터넷 연결에 미치는 영향 최소화, 회사의 데이터 센터(온프레미스)와 AWS 간에 안전한 고속 연결을 제공 -> AWS Direct Connect (백업으로 VPN 연결을 프로비저닝) + AWS DataSync( 데이터 이동을 자동화 및 가속화하는 온라인 서비스 )
무단 구성 변경, 감사 관련
- S3 버킷에 무단 구성 변경 유무 확인 -> AWS Config
액세스 지정 & 계정 관리
-
제품 관리자의 CloudWatch 대시보드 액세스 -> 대시보드 공유링크를 제품 관리자에게 제공 (이메일 주소 지정 OR 단일 대시보드 공개 OR SSO 공급자 지정)
-
솔루션 설계자가 MSP 파트너의 AWS 계정과 AMI 를 공유하는 가장 안전한 방법 -> AMI의 LaunchPermission 속성 수정
자격 증명 & 인증서
-
데이터 베이스 자격 증명 자동 교체, API 호출 -> Secrets Manager.
-
AWS 서비스 및 연결된 내부 리소스에 공인 및 사설 SSL/TLS 인증서를 프로비저닝, 관리 및 배포 -> AWS Certificate Manager(ACM)
-
ACM으로 가져온 인증서의 만료 상태를 알림 -> AWS Config 규칙을 사용 + Amazon EventBridge와 연동
< 보안 관련 >
-
인스턴스에 원격으로 안전하게 액세스하고 관리 ->Session Manager
-
대규모 DDoS 공격 감지 및 보호 -> AWS Shield Advanced
-
최소한의 개발 노력으로 PII 가 다시 공유될 경우 관리자에게 경고를 주는 것을 자동화 -> Amazon Macie
-
최소한의 개발 노력으로 부적절한 콘텐츠 탐지 -> Amazon Rekognition
데이터 분석 관련
-
대량의 스트림 데이터 수집 => Kinesis Data Streams
-
(실시간 스트리밍 데이터를 http 엔드포인트 또는 대상(Datadog, MongoDB)에 데이터 전송 => Amazon Kinesis Data Firehose
-
데이터 웨어하우스를 구성하지 않아도 데이터를 액세스하고 분석 가능 => Amazon Redshift
머신 러닝
-
텍스트, 데이터 자동 추출 -> Amazon Textract
-
의료 텍스트에서 의료 데이터를 파악하고 추출 -> Amazon Comprehend Medical
-
Amazon FSx for Lustre: 컴퓨팅 집약적인 워크로드에 최적화된 고성능 파일 시스템
-
AWS Transfer Family: 고가용성, 자동 확장 기능 제공
-
AWS Elastic Beanstalk: 최소한의 운영 오버헤드&고가용성 관리 솔루션, 쉬운 배포와 확장이 가능 (URL 스와핑)
-
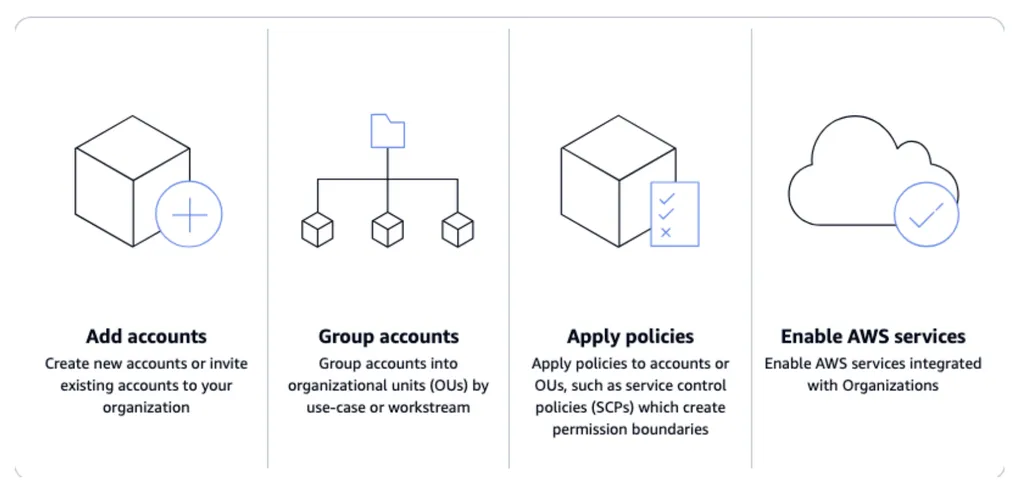
AWS Organizations
스토리지 - S3
-
S3 : 고가용성 & 내구성 & 비용 최적화 스토리지 옵션
-
S3 Transfer Acceleration: 장거리 데이터 전송 속도 가속화 가능, 엣지 로케이션 사용
-
S3 버킷정책 설정(aws:PrincipalOrgID): AWS Organizations 내의 계정 사용자들만 이 S3 버킷에 접근할 수 있도록 제한
-
S3 버킷 간의 데이터 전송 비용 낮추려면 -> S3 교차 리전 복제(CRR)를 사용
-
S3 Object Lock : 보관 기간 및 법적 보존 등 객체 보관을 관리하는 2가지 방법을 제공
-
규정준수 모드: 문서가 설정된 보존 기간 동안 객체 버전을 덮어쓰거나 삭제할 수 없도록 !!!
-
AWS 계정의 루트 사용자를 포함한 어떤 사용자도 덮어쓰거나 삭제할 수 없음
-
객체를 잠그면 보관 모드를 변경할 수 없으며 보관 기간을 줄일 수 없음
-
거버넌스 모드: 특별한 권한이 없는 한 사용자는 객체 버전을 덮어쓰거나 삭제하거나 잠금 설정을 변경할 수 없도록 !!!
-
필요에 따라 일부 사용자에게 보존 설정을 변경하거나 객체를 삭제할 수 있는 권한을 부여
S3 Object Lambda: 데이터를 검색할 때 필터링하고 처리, 변환된 데이터 복사본을 미리 처리하고 저장하여 운영 오버헤드 최소화
S3 Batch Operations
- 수백, 수백만 또는 수십억 개의 S3 객체를 간단하고 간편한 방식으로 처리할 수 있음
- 다른 버킷에 객체를 복사하거나, 태그 또는 ACL(액세스 제어 목록)을 설정하거나, Glacier에서 복원을 시작하거나, 각 객체별로 lambda 함수를 호출할 수 있음
데이터베이스 - DynamoDB (NoSQL)
-
밀리초 지연 시간으로 시간당 수백만개 요청 처리 -> DynamoDB
-
최소 대기 시간으로 고트래픽 쿼리에 응답 가능!
-
온디맨드 백업 복사, 할당 태그 추가 온디맨드 백업을 콜드 스토리지로 전환하여 비용 절감 가능 -> AWS Backup + DynamoDB
-
(AWS Backup: 전체 서비스, 클라우드 및 온프레미스에서 데이터 보호를 쉽게 중앙 집중화하고 자동화할 수 있는 완전 관리형 AWS 서비스 -> AWS Backup 를 사용하면 저렴한 콜드 스토리지 계층에 백업을 저장하여 백업 스토리지 비용을 최소화하면서 규정 준수 요구 사항을 충족할 수 있음 )
-
Dynamo TTL(시간제한): 지정된 타임스탬프의 날짜와 시간이 지나면 해당 항목을 테이블에서 자동으로 삭제
-
Amazon DynamoDB Accelerator (DAX): 재구성 없이 성능을 향상&읽기 지연을 크게 줄임
-
DynamoDB 시점 복구(Point-in-Time Recovery): 15분 이내의 RPO 충족
데이터 전송
-
AWS DataSync : 온프레미스 <-> S3, EFS, Amazon FSx for Windows File Server 간의 데이터 전송 간소화&자동화
-
AWS Snowball Edge Storage Optimized: 네트워크 대역폭이 부족한 상황에서 빠른 데이터 전송을 가능하게 함
-
AWS DMS(데이터 마이그레이션 서비스) 복제 서버생성: 데이터 전송 시, 동기화 유지
데이터 분석 관련
-
AWS Glue: 완전 관리형 ETL(추출, 데이터 변환 및 로드 간소화) 서비스, 작업 북마크: 상태 정보를 제공하고 오래된 데이터의 재처리를 방지
-
AWS Athena: 표준 SQL을 사용해 Amazon S3에 저장된 데이터를 간편하게 분석할 수 있는 대화식 쿼리 서비스
보안 관련
-
대규모 DDoS 공격 감지 및 보호 -> AWS Shield Advanced, CloudFront
-
AWS Firewall Manager: 여러 계정과 리전에서 중앙에서 AWS WAF 규칙을 구성하고 관리, SQL 인젝션 및 교차 사이트 스크립팅과 같은 공격으로부터 API를 보호 가능
-
오리진 액세스 아이덴티티(OAI): CloudFront와 S3 간의 보안 액세스를 제공
-
Amazon CloudFront + 필드 수준 암호화: 추가 보안 레이어를 추가하여 시스템 처리 전체에서 특정 데이터를 보호하고 특정 애플리케이션만 이를 볼 수 있도록 함
-
AWS WAF를 사용하여 Amazion API Gateway를 보호: SQL 인젝션으로 부터 보호
-
Amazon Macie: S3, 데이터베이스의 보안이나 프라이버시와 관련된 잠재적 문제를 탐지하면 Macie가 결과를 조사 생성하며, 필요에 따라 사용자가 검토하고 수정, 민감한 데이터(신용카드, 이름, 주소와 같은 개인식별정보[PII])의 검색 및 보고를 자동화
-
Amazon GuardDuty: 워크로드에 대한 위협을 적극적으로 모니터링하고 완화
-
IAM Access Analyzer: 리소스에 대한 의도하지 않은 액세스를 신속하게 식별
시간 최소화
-
각 리전에서 NLB를 AWS Global Accelerator 엔드포인트로 사용: 지연 시간 가장 짧은 리전으로 사용자를 라우팅
-
Amazon ElastiCache: 데이터 저장소에서 정보를 빠르게 검색, 읽는 시간을 단축
-
RDS Proxy: 예상치 못한 데이터베이스 트래픽 급증 처리가 가능, 많은 수의 연결 수 제어가능 (연결 관리를 최적화하여 성능과 가용성을 높임!)
-
프로덕션 데이터를 테스틑 환경에 복제하는 데 필요한 시간을 최소화 -> 스냅샷
-
DB 인스턴스의 컴퓨팅 및 메모리 속성을 줄이지 않고 테스트 실행 비용을 줄이기 -> 스냅샷 보관 & 복원
확장성 관련
- Amazon Elastic Container Service: 컨테이너화된 애플리케이션을 실행하기 위한 고도로 확장 가능하고 관리되는 환경을 제공하여 운영 오버헤드를 줄임
데이터베이스 비용 관련
-
RDS vs Aurora: RDS가 더 쌈!
-
Aurora: 고성능과 고가용성을 위해 설계된 MySQL 호환의 완전 관리형 RDBMS
머신 러닝
- Amazon Transcribe: 음성을 텍스트로 변환
운영 & 감사 및 규정 준수 정책 정의 및 시행
-
AWS CloudTrail: 모든 작업에 대한 중앙 로그 생성
-
AWS Config: 계정 및 AWS 리전에서 표준 리소스 구성을 보고 적용
-
AWS Backup: 일반 백업을 자동으로 적용
-
AWS Control Tower: AWS 워크로드의 보안, 운영 및 규정 준수에 대해 사전 패키징된 거버넌스 규칙 적용
AWS Pinpoint (SMS Service)
-
여러 메시징 채널에서 고객과 소통하는 데 사용할 수 있는 AWS 서비스
-
고객이 특정 키워드가 포함된 메시지를 보낼 때 자동 응답을 생성
-
메시징 캠페인 예약
-
분석 및 지표 보고 사용
-
푸시 알림, 이메일, SMS 문자 메시지 또는 음성 메시지를 보낼 수 있음
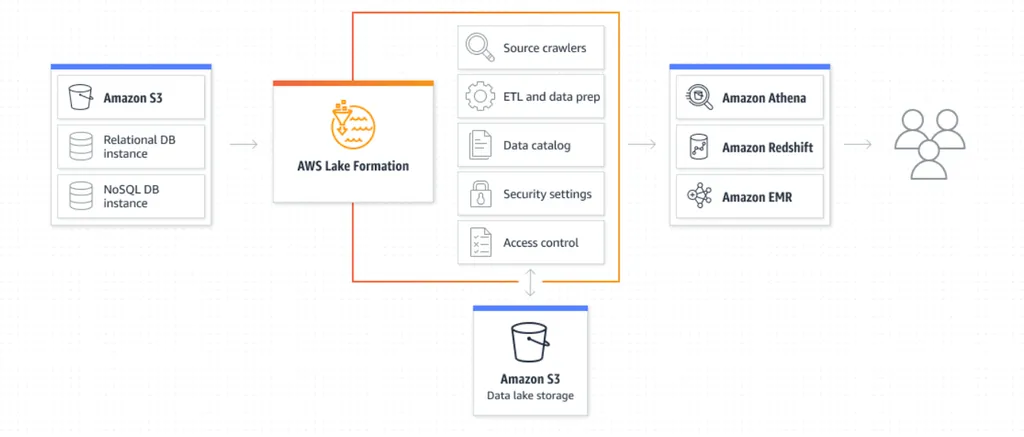
AWS Lake Formation
-
S3와 RDS 데이터 모두에 대한 중앙 집중식 액세스 제어를 제공
-
세분화된 데이터 액세스 권한을 중앙에서 관리 및 조정
-
조직 내부 및 외부의 데이터 공유를 단순화
Amazon EventBridge
- CloudWatch Events를 기반, CloudWatch Events의 API와 규칙 등을 계속해서 사용 가능
AWS Resource Groups
-
여러 서비스 및 리전에서 태그가 지정된 구성 요소에 대한 보고서를 생성하는 중앙 집중식의 효율적인 접근 방식을 제공
- 태그 지정 작동 방식
-
태그는 AWS 리소스 구성을 위한 메타데이터 역할을 하는 키와 값 쌍
-
Amazon EC2 인스턴스, Amazon S3 버킷, 기타 리소스 등 대부분의 리소스에서는 AWS 리소스를 생성할 때 태그를 추가할 수 있는 옵션이 있음
-
AWS CloudFormation
-
AWS 리소스를 모델링하고 설정하여 리소스 관리 시간을 줄이고 AWS에서 실행되는 애플리케이션에 더 많은 시간을 사용하도록 해 주는 서비스
- EC2 인스턴스에 CloudWatch 에이전트를 배포하면 애플리케이션 성능에 대한 중요한 통찰력을 제공할 수 있는 사용자 지정 애플리케이션 대기 시간 메트릭을 생성할 수 있음
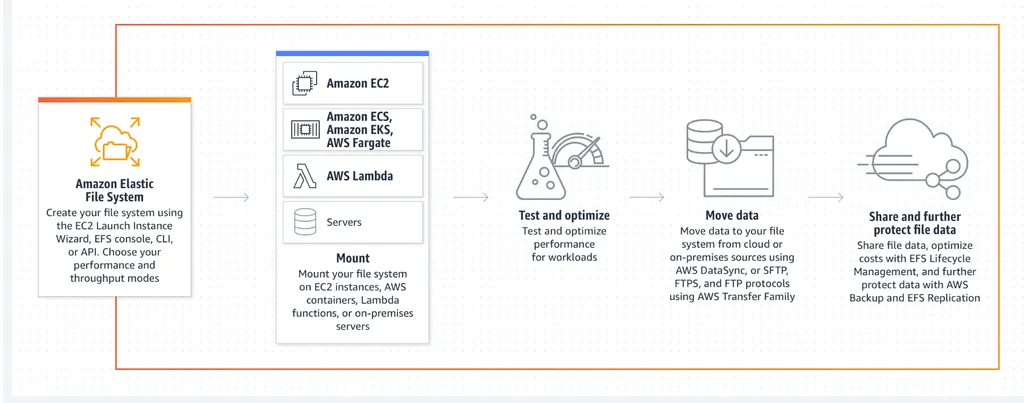
Amazon Elastic File System
-
여러 EC2 인스턴스에서 동시에 접근할 수 있는 확장 가능하고 완전 관리형 파일 스토리지 서비스를 제공
-
"서버리스 방식의 완전 탄력적인 파일 스토리지" 빠르고 손쉬운 생성 & 탄력적이고 확장 가능
- 여러 애플리케이션 서버에서 동시에 접근할 수 있어, 파일 수가 시간이 지남에 따라 증가할 때 높은 가용성과 확장성을 보장
AWS backup
-
데이터 보호를 중앙에서 관리하고 자동화, "정책을 기반으로 대규모 데이터를 간편하고 비용 효율적으로 보호할 수 있는 완전관리형 서비스"
- 여러 AWS 서비스 간에 버킷, 볼륨, 데이터베이스, 파일 시스템 등의 주요 데이터 스토어를 백업
AWS Directory
- 온프레미스 Active Direcotory를 Amazon RDS, FSx, EC2 같은 클라우드 서비스와 쉽게 통합 가능
Amazon ElastiCache
-
데이터베이스 앞에 배치하여 자주 액세스되는 데이터를 캐시
-
데이터베이스의 부하를 상당히 줄이고, 더 빠른 응답 시간을 제공하여 사용자 경험을 개선
-
반복적인 데이터베이스 읽기의 필요성을 줄여 성능을 최적화
-
데이터 저장소에서 정보를 빠르게 검색, 읽는 시간을 단축
-
복잡한 쿼리 또는 빈번한 데이터 업데이트가 포함되는 경우 RDS Proxy 와 동일한 수준의 읽기 성능 향상을 제공하지 못할 수 있음!!
AWS Global Accelerator
-
AWS 글로벌 네트워크를 사용하여 애플리케이션의 가용성, 성능, 보안을 개선 "네트워크 가속 서비스"
-
AWS Global Accelerator 에서 가속기를 구성하면, 트래픽을 건강한 엔드포인트로 최적화하여 전달
-
트래픽이 가장 가까운 건강한 엔드포인트로 전달되도록 보장하여 전체적인 사용자 경험을 개선하는 데 도움
-
각 리전에서 NLB를 AWS Global Accelerator 엔드포인트로 사용: 지연 시간 가장 짧은 리전으로 사용자를 라우팅
-
AWS Storage Gateway
-
데이터 전송 중, 로컬 접근 유지 가능
-
저장된 볼륨은 전체 데이터 세트를 온프레미스에 유지하므로 낮은 대기 시간으로 접근 가능
-
AWS로의 데이터 자동 전송, Storage Gateway는 온프레미스 게이트웨이와 AWS 스토리지 간의 암호화된 연결을 제공
Amazon FSx for NetApp ONTAP
-
ONTAP의 데이터 액세스 및 관리 기능을 제공하는 AWS 클라우드 기반의 인기 있는 완전관리형 공유 스토리지
-
데이터가 파일 시스템 전반에 걸쳐 동기화되고 최신 상태로 유지되도록 보장
VPC 간 피어링
-
AWS 인프라 내의 두 Virtual Private Cloud(VPC) 간에 안전하고 직접적인 통신을 가능하게 하는 네트워킹 기능
-
다양한 AWS 계정 또는 다양한 AWS 리전에 걸쳐 VPC를 연결 가능 (유연성)
-
피어링된 VPC의 리소스는 동일한 네트워크에 속한 것처럼 서로 상호 작용할 수 있어 퍼블릭 인터넷을 통과할 필요가 없음!!
- 비공개적으로 두 VPC 간에 트래픽을 라우팅할 수 있도록 하기 위한 두 VPC 사이의 네트워킹 연결
Amazon FSx for Lustre
-
SSD 스토리지를 사용할 경우 최대 260 GB/s의 집합 처리량과 서브 밀리초 대기 시간을 제공
-
Linux에서 실행되는 고성능 컴퓨팅 작업에 최적화
Amazon Aurora 글로벌 데이터베이스
-
전 세계적으로 분산된 애플리케이션을 위해 설계
-
각 리전에서 낮은 지연 시간으로 빠른 로컬 읽기를 지원
AWS Control Tower vs AWS Orgarnizations의 차이
-
AWS Control Towel는 AWS Orgarnization의 확장, 여러개의 AWS 계정을 관리하는 것이 가능 "중앙집중화된 관리"
- AWS Control Tower orchestration extends the capabilities of AWS Organizations
-
AWS Control Tower를 사용하여 잘 설계된 AWS Organizations 구조를 구축하면 확장 가능하고 안전하며 규정을 준수하는 AWS 환경을 빠르게 배포할 수 있음!
2. AWS EC2 & 배치 그룹(Placement Group)
EC2
- EC2는 Elastic Compute cloud의 약자이며, AWS에서 가장 인기 있고 핵심 서비스이며 AWS에서 제공하는 클라우드 컴퓨팅 서비스다.
- EC2는 하나의 서비스가 아닌 많은 것을 포함하고 있는 서비스다.
- 데이터를 가상 드라이브 EBS(Elastic Block Storage) 볼륨에 저장 가능
- ELB(Elastic Load Balancer)로 분산 가능
- Auto Scaling Group을 사용하여 서비스 확장 가능
AWS 예산 설정
- root 계정이 아닌 IAM 계정으로 예산 정보를 보기 위해서는 아래 설정을 활성화 시켜야 한
- 과금이 발생하면 노티를 받을 수 있도록 아래 설정을 통해 노티 설정을 할 수 있다.
- 일정 금액이 초과했을 시 이메일로 수신할 수 있도록한다.
EC2 설정 옵션과 크기
- EC2를 처음 생성할 때 다양한 설정 옵션(운영체제, RAM, Storage, 방화벽 등)이 존재한다.
- EC2를 생성할 때 아래 사진의 Quick Start 카탈로그를 보면 리눅스, 맥, 윈도우 등 운영체제를 선택할 수 있다.
- 인스턴스의 유형에따라 컴퓨팅 성능이 달라진다. CPU 코어 수, 메모리, 스토리지, 요금 등이 달라진다.
- 스토리지 설정을 구성할 수 있다. 프리티어 유형으로는 30GB의 EBS 스토리지(SSD)를 쓸 수 있다.
- 인스턴스 구성을 위해 부트스트랩 스크립트도 작성할 수 있다.
- 부트스트랩 스크리핑이란, 초기에 EC2가 수행할 명령을 미리 지정하는 것을 의미한다. 주로 운영 체제의 패치, 모듈의 설치 혹은 업데이트를 진행할 때 사용한다.
- 다만, 작업이 많아질수록 인스턴스 기동 시간이 늘어날 수 있다. EC2 사용자 데이터 스크립트는 root 계정에서 실행되기에 sudo 명령어를 붙여줘야 한다.
- EC2 인스턴스에 SSH 프로토콜을 이용해 접속하기 위해선 key pair를 생성해야 한다.
- 이때, 윈도우 7, 8 을 제외한 경우에는 대부분 .pem 방식을 사용한다.
EC2 인스턴스 종류, 타입
- EC2 인스턴스의 종류는 다양하게 구성되어있다.
- 인스턴스 유형을 확인하면 쉽게 이해되지 않는 이름들이다.
- 하지만, 여기에는 규칙들이 존재한다.
- m5.2xlarge 유형으로 확인해보자
- m: 인스턴스 클래스(m이 범용의 인스턴스 그룹에 포함된다.)
- 5: 인스턴스 세대(새로운 세대의 하드웨어)
- 2xlarge: 인스턴스 클래스 내에서 사이즈를 의미한다.
- 크기는 small부터 시작
- 크기가 클수록 메모리와 cpu가 커진다.
- m5.2xlarge 유형으로 확인해보자
범용 인스턴스(General Purpose)
- 보통 웹서비스나 코드 저장소와 같은 다양한 작업에 어울린다.
- 컴퓨팅, 메모리, 네트워크간의 밸런스도 잘 맞는다.
컴퓨팅 최적화 인스턴스(Compute Optimized)
- 컴퓨터 집약적인 작업에 최적화되어 있다.
- 주로 배치 프로세스, 미디어 트랜스 코딩, 고성능 웹서버, 머신 러닝, 전용 게임 서버 등에 사용될 수 있다.
- 인스턴스 유형은 c로 시작한다.
메모리 최적화 인스턴스(Memory Optimized)
- 메모리는 RAM을 가리키며 대규모 데이터 셋을 처리하는 유형의 작업에 빠른 성능을 제공한다.
- 주로 인 메모리 데이터베이스, 분산 웹 스케일 캐시 저장소, 비즈니스 인텔리전스(BI)에 최적화된 인 메모리 데이터베이스와 대규모 비정형 데이터의 실시간 처리를 진행하는 애플리케이션에서 사용
스토리지 최적화 인스턴스(Storage Optimized)
- 스토리지 최적화 인스턴스다.
- 로컬 스토리지에서 대규모의 데이터셋에 액세스할 때 적합한 인스턴스다.
- 주로 고주파 온라인 트랜잭션 처리인 OLTP 시스템에 사용, NoSQL DB에서 사용, Redis와 같은 메모리 기반의 데이터베이스나 데이터 웨어하우징 애플리케이션과 분산과 분산 파일 시스템에서 사용된다.
- 인스턴스 유형은 보통 I, G, H1으로 시작한다.
EC2 Hibernate 모드
- EC2 Hibernate 모드란, 절전 모드를 실행하여 EC2 인스턴스를 중지 상태로 전환한다. 이떄, RAM에 기록된 데이터는 EBS 불륨에 저장된다.
인스턴스 종료 과정
- 인스턴스가 종료될때 루트 볼륨이 삭제되게 활성화 되어있었다면, 인스턴스가 삭제시 루트 볼륨도 함께 삭제된다.
- 하지만 해당 설정을 하지 않은 다른 볼륨은 인스턴스 종료시 그대로 남게 된다.
- 인스턴스를 다시 시작하면 운영 체제가 먼저 부팅되기 시작하고 EC2 사용자 데이터 스크립트도 실행된다.
- 운영 체제가 부팅이 완료되고 애플리케이션도 실행된 후 캐시도 구성되기 시작하므로 과정이 끝날 때까지 시간이 다소 걸리게 된다.
절전 모드
- 인스턴스 절전 모드가 실행되면 RAM에 있던 상태는 그대로 보존된다.
- 즉, 인스턴스 부팅이 더 빨라지게 되는 것이다.
- 운영 체제를 완전히 중지하거나 다시 시작하지 않고 그대로 멈춰뒀으니까 절전 모드가 되고 백그라운드에서 RAM에 기록되었던 루트 경로의 EBS 볼륨에 기록되기 때문에 루트 EBS 볼륨을 암호화해야 하고 볼륨 용량도 RAM을 저장하기에 충분해야 한다.
절전 모드 과정
- EC2 인스턴스를 절전 모드로 실행하게 된다면 인스턴스는 중지 상태로 전환된다.
- RAM의 내용은 EBS 볼륨에 덤프된다. 그리고 인스턴스를 종료하면 RAM은 사라지게 된다.
- 하지만 EBS 볼륨에는 여전히 RAM이 덤프된 게 있으니 인스턴스를 다시 실행마녀 디스크에서 RAM을 불러와 EC2 인스턴스 메모리로 가져간다.
- 이렇게 함으로써 EC2 인스턴스를 중지한 적이 없는 것처럼 된다.
특징
- 지원하는 제품군이 다양하다.
- 인스턴스의 램 크기는 최대 150GB
- 베어메탈 인스턴스는 지원하지 않는다.
- Linux, Windows 등 다양한 운영 체제에서 사용이 가능하다.
- 루트 볼륨, 즉 EBS 볼륨에만 사용가능하며 암호화가 필요하고 RAM 덤프를 위한 충분한 용량이 필요
- 모든 종류의 인스턴스에서 사용 가능하다.(On-demand, spot ..)
- 절전 모드는 최대 60일 사용 가능하다.
보안 그룹
- 보안 그룹은 AWS 클라우드에서 네트워크 보안을 실행하는데 핵심이 되는 부분이다.
- EC2로 접속할때 timeout이 발생하는 경우는 100퍼센트 보안그룹 즉, 방화벽 설정이 안되어 있어서 그렇다고 한다.
보안그룹 특징
-
EC2 인스턴스에 들어오고 나가는 트래픽을 제어한다.
-
보안 그룹은 간단한 허용 규칙만 포함한다.
- 출입이 허용된 것이 무엇인지 확인할 수 있고 IP 주소를 참조해 규칙을 만들 수 있다.
- 컴퓨터의 위치나 다른 보안 그룹을 참조한다.
- 보안 그룹끼리 서로 참조 가능하다.
- 외부에서 EC2 인스턴스로 들어오는 것이 허용되면 아웃 바운드 트래픽도 수행할 수 있다.
-
보안 그룹은 EC2 인스턴스의 방화벽이다.
- 포트로의 액세스를 통제하며 인증된 IP주소 범위를 확인해 IPv4, IPv6인지 확인한다.
- 외부에서 인스턴스로 들어오는 인바운드 네트워크를 통제한다.
- 인스턴스에서 외부로 나가는 아웃바운드 네트워크를 통제한다.
- EC2 인스턴스가 웹사이트에 액세스하고 연결을 시도하면 보안 그룹에서 허용하는 것이다.
보안 그룹 팁
- 여러 인스턴스에 동일한 보안 그룹을 연결할 수 있다.
- 하나의 인스턴스에 여러개의 보안 그룹을 연결할 수 있다.
- 보안 그룹은 Regions과 VPC 결합으로 통제되어 있다.
- 그래서 Regions을 변경하면 새 보안 그룹을 생성하거나 다른 VPC를 생성해야 한다.
- 보안 그룹은 EC2 외부에 존재하는 것이다.
- SSH 접근을 위해 별도의 보안 그룹을 생성하여 관리하는 것이 좋다.
- 아까 언급했듯이 타임아웃이 발생하면 보안 그룹의 문제로 생각하면 된다.
- 연결을 거부되었다는 응답을 받으면 보안 그룹은 통과했지만, 애플리케이션에 문제가 생긴 것으로 생각할 수 있다.
- 기본적으로 모든 아웃 바운드 트래픽은 허용하지만, 모든 인바운드 트래픽은 차단되어있다.
- 보안 그룹에 다른 보안 그룹을 참조하는 방법은 로드 밸런서에서 사용하기에 좋다.
- EC2 인스턴스의 IP와는 상관이 없다.
주요 포트
- 22: SSH(Scure Shell)
- 21: FTP(File Transfer Protocol)
- 22: SFTP(Secure File Transfer Protocol)
- 80: HTTP
- 443: HTTPS
- 3389: RDP(Remote Desktop Protocol)
EC2 구매 옵션
온디맨드(On-Demand)
- 사용한 만큼 비용을 지불하는 방식
- 단기적인 워크로드에 사용하기 적합하며 애플리케이션의 미래를 예측할 수 없을 때 좋다.
- 비용을 초단위로 요금을 지불한다,.
- Linux, Window는 1분 이후로 초단위로 청구한다.
- 외의 다른 운영체제는 1시간 단위로 청구한다.
- 비용이 가장 많이 발생하는 옵션이지만 바로 지불할 금액은 없고 장기적인 약정도 없다.
예약 인스턴스(Reserved)
- 오랫동안 사용할거면 해당 옵션이 온디맨드보다는 적합하다고 할 수 있다.
- On-Demand에 비해 72% 할인을 제공한다.
- 특정 인스턴스의 속성을 예약할 수 있다.
- 리전, 인스턴스, 운영체제, 테넌시
- 예약 기간을 1년, 3년으로 지정할 수 있으며 할인폭은 다르다.
- 전부 선결제, 부분 선걸졔, 선결제 없음 중 선택할 수 있다.
- 선 결제시 할인폭은 커진다.
- 예약 범위를 특정 Region, Zone으로 지정할 수 있다.
- DB같은 사용량이 일정한 애플리케이션에 예약 인스턴스를 사용하는 것이 좋다.
- 예약 인스턴스를 더 살 수 있고, 더이상 필요가 없을 경우 판매가 가능하다.
전환형 예약 인스턴스
- 인스턴스 타입, 패밀리 운영체제, 범위, 테넌시를 변경할 수 있다.
- 유연성이 존재하기에 할인은 적다.
- On-Demand에 비해 최대 66% 할인을 제공한다.
절약 플랜(Saving Plans)
- 절약 플랜은 특정한 인스턴스 유형을 약정하는 것이 아닌 달러 단위로 특정한 사용량을 약정하는 것이므로 좀 더 현대적인 방식이다.
- 절약 기간은 1년, 3년이 있다.
- 그러나 1년 내지 3년동안 시간당 10달러로 약정을 하게 된다.
- 장기적인 방식에 좋다.
- On-Demand이 비해 70% 할인을 제공한다.
- 사용량의 한도를 넘어서면 절약 플랜은 온디맨드 가격으로 청구가 된다.
- 절약 플랜은 특정 리전, 인스턴스, 패밀리로 고정된다.
- 인스턴스 사이즈, OS, 테넌스는 변경이 가능하다.
전용 호스트(Dedicated hosts)
- 전용으로 사용하는 EC2 인스턴스 용량이 있는 실제 물리적 서버를 제공받는다.
- 물리적 서버 전체를 예약해서 인스턴스 배치를 제어할 수 있다.
- 주로 법규 준수 요건이 있는 활용 사례나 소켓, 코어, VM 소프트웨어 라이센스 기준으로 청구되는 기존의 서버에 연결된 소프트웨어 라이센스가 있는 경우에 사용한다.
- On-Demand로 초당 비용을 지불하거나 1년, 3년 예약 가능하다.
- 실제로 물리 서버를 예약하기에 가장 비싼 유형이다.
전용 인스턴스(Dedicated Instances)
전용 인스턴스 즉 하드웨어를 갖게 되는 것이다.
물리적 서버 자체에 대한 접근권을 갖고 낮은 수준의 하드웨어에 대한 가시성을 제공해준다.
- 다른 고객이 하드웨어를 공유하지 않는다.
- 물리적 서버와는 다르다.
- 같은 계정에서 다른 인스턴스와 함께 하드웨어를 공유할 수 있다.
- 인스턴스 배치에 대한 통제권이 없다.
용량 예약(Capacity Reservations)
- 특정 AZ에 기간, 용량을 예약하는 방식이다.
- 설정한 기간동안 특정 AZ에 인스턴스를 예약한다.
- 기간 약정이 없다.
- 언제라도 용량을 예약, 취소 가능하다.
- 청구 할인이 없으며, 오직 예약만이 목적이다.
- 만약 청구 할인을 받고자 한다면 지역별 예약 인스턴스와 결합하거나 절약 플랜과 결합해야 한다.
- 인스턴스 실행과 무관하게 온디맨드 요금이 부과된다.
- 실행과 무관하게 비용 지불
- 특정 AZ에 있어야 하는 단기적이고 중단 없는 워크로드에 매우 적합
스팟 인스턴스(Spot Instances)
- 아주 짧은 워크로드를 위한 인스턴스 타입이다.
- 매우 저렴하다.
- 하지만, 언제라도 인스턴스 손실이 될 수 있기에 신뢰성이 매우 낮다.
- On-Demand에 비해 90% 할인이 가능하다.
- 최대 가격을 정의하게 되는데, 이를 넘길 시 인스턴스가 사라진다.
- 가장 비효율적인 인스턴스다.
- 이를 회복할 수 있는 전략이 있다면 좋은 선택이 될 수 있다.
- 주로 배치 작업, 데이터 분석, 이미지 처리, 모든 종류의 분산형 워크로드, 시작 시간 종료 시간이 유연한 워크로드에 해당한다.
- 실패해도 복원력이 있을 경우에 사용해야 한다.
- DB와 같은 작업에는 절대 사용하면 안된다.
- 사용한 비용이 정의된 최대 가격보다 낮다면 계속 인스턴스 사용 가능하다.
- 시간 당 비용은 오퍼 및 용량에 따라 다르다.
- 스팟 가격이 정의된 최대 가격을 넘기게 된다면 2개의 선택지가 주어지고 2분의 유예 시간이 주어진다.
- 중단 -> 스팟을 멈춘 후 최대 가격보다 낮아지면 다시 동작
- 종료 -> 아예 종료, 새로 생성
스팟 볼록
- AWS에게 스팟 인스턴스를 회수당할 일이 없게 하기 위한 전략이다.
- 스팟 블록이란 특정 기간(1~6시간)동안 인스턴스를 차단하는 기능이다.
- 하지만 2022년 12월 31일자로 종료되었다고 한다.
스팟 인스턴스 종료
- 스팟 요청에는 원하는 인스턴스의 개수, 최고 가격, AMI 등 요구되는 사양, 요청의 유효 기간이 있다.
- 스팟 요청이 취소되기 위해서는 open, active, disabled 상태여야 한다.
- failed, canceled, closed 경우는 안된다.
- 스팟 요청을 취소하더라도 인스턴스는 종료되지 않는다. 사용자가 직접해야 한다.
- 스팟 인스턴스를 제거하려면, 스팟 요청 취소 후 연결된 인스턴스를 꺼야 한다.
- 인스턴스를 사용자가 종료하게 되면 스팟 요청으로 인해 다시 실행된다.
스팟 요청 방법
일회성 요청
- 요청이 이행되는 즉시 인스턴스가 실행된다.
- 스팟 요청은 바로 사라진다.
- 스팟 요청이 사라져도 괜찮은 경우에 해당 방법을 사용한다.
지속적인 요청
- 스팟 요청의 유효 시작일자부터 종료일자까지 요청한 개수의 인스턴스들이 유효하게 된다.
- 최대 가격을 넘어 인스턴스가 없어져도 스팟 요청이 다시 연결되어 자동으로 인스턴스가 생긴다.
스팟 플릿(Spot Fleets)
- 스팟 플릿을 이용해 여러 런치풀과 인스턴스 유형을 다양한 형태로 정의할 수 있다.
- 스팟 플릿에 lowestPrice 전략을 사용하면 스팟 플릿이 자동으로 최저 가격의 스팟 인스턴스를 요청한다.
- 스팟 플릿을 사용하면 스팟 인스턴스에 따라 추가적으로 비용 절감이 가능하게 되는데, 적합한 스팟 인스턴스 풀을 선택해주기 때문이다.
- 인스턴스 유형, AZ만 선택하는 단순 스팟 요청과 달리 스팟 플릿은 사용자의 요구 즉 전략에 따라 모든 것을 최적화 해준다
- 최대 비용 절감을 위한 방안이 스팟 플릿이다.
- 한 세트의 스팟 인스턴스에 온디맨드 인스턴스를 선택적으로 조합해 사용하는 방법이다.
- 스팟 플릿은 정의된 비용 제한 내에서 대상 용량을 맞추려고 노력한다.
- 사용 가능한 런치 풀을 사용해서 실행된다.
- 인스턴스 유형, 운영체제, AZ 등 다양하게 가질 수 있다.
- 스팟 플릿이 정해진 예산이나 용량에 도달한 경우 인스턴스 실행을 멈춘다.
- 스팟 플릿내에서 스팟 인스턴스를 할당해 줄 전략을 정의한다.
- lowestPrice: 스팟 플릿이 가장 적은 비용을 가진 풀에서부터 인스턴스를 실행하여 비용을 절감한다. 아주 짧은 워크로드에 적합하다.
- diversified: 사용자가 정의한 모든 풀에 걸쳐 분산된다. 긴 워크로드에 적합하며 가용성이 뛰어나 특정 풀이 중단되더라도 다른 풀에서 동작한다.
- capacityOptimized: 인스턴스의 개수에 따라서 최적 용량으로 실행된다. 적절한 풀을 찾아준다.
- priceCapacityOptimized: 가격 용량 최적화는, 먼저 사용 가능 용량이 가장 큰 풀을 선택하고 그 중 가격이 가장 낮은 풀을 선택하는 전략이다. 때문에 대부분의 워크로드에 적합한 선택이다.
Placement Group(배치 그룹)
-
Placement Group이란 배치 그룹을 말한다.
- EC2 인스턴스가 AWS 인프라에 배치되는 방식을 제어하고자 할 때 쓰인다.
-
AWS 하드웨어와 직접적인 상호 작용을 하지는 않지만, EC2 인스턴스가 각각 어떻게 배치되기를 원하는지 AWS에 알려주는거다.
-
배치 그룹 종류
-
클러스터 배치 그룹(Cluster)
-
분산 배치 그룹(Spread)
-
분할 배치 그룹(Partition)
-
클러스터 배치 그룹(Cluster)
- 단일 가용 영역(Single AZ)에서 지연 시간이 짧은 그룹으로 인스턴스를 클러스터링한다.
- 모든 인스턴스가 동일한 하드웨어, 랙, 가용 영역에 존재한다.
- 엄청난 네트워크안에서 인스턴스가 동작하기에 높은 성능을 보이지만 위험성 또한 높다.
- 주로 빅데이터 작업, 극히 짧은 지연 시간과 높은 네트워크 처리량을 필요로 하는 애플리케이션에 적합하다.
분산 배치 그룹(Spread)
- 인스턴스가 서로 다른 하드웨어에 분산되어 배치된다.
- 모든 EC2 인스턴스가 서로 다른 하드웨어에 존재한다.
- 여러 가용 영역에 걸쳐 있기에 동시 실패의 위험성이 감소된다.
- 분산된 배치 그룹 당 가용 영역별로 최대 7개까지의 인스턴스만 가질 수 있다는 제한이 존재
- 가용성을 극대화하고 실패 위험을 줄이고자 하는 애플리케이션에 적절함
분할 배치 그룹(Partition)
- 여러 가용영역의 여러 파티션에 자체 랙세트에 인스턴스를 분할하여 각각 분산 배치
- 각 랙은 자체 네트워크 및 전원이 있습니다. 배치 그룹 내 두 파티션이 동일한 랙을 공유하지 않으므로 하드웨어 장애의 영향을 격리시킬 수 있다.
- 가용 영역 당 파티션을 최대 7개까지 가질 수 있다.
- 파티션은 동일한 리전의 여러 가용 영역에 걸쳐 있을 수 있으나 가용 영역 당 최대 7개의 파티션을 가질 수 있다.
- 그룹 당 수백개의 EC2 인스턴스를 통한 확장성이 큰 장점이다.
- 각 인스턴스가 어떤 파티션에 존재하는지 알기 위해 메타데이터 서비스를 사용할 수 있다.
- 파티션을 인식하는 애플리케이션에 주로 사용된다.
- HDFS, HBase, Cassandra 등 대규모 분산 및 복제 워크로드를 별개의 렉으로 분산해 배포하는데 사용할 수 있다.
3. AWS의 데이터베이스
Amazon RDS (Relational Database Service)
- 지원 DB 엔진: PostgreSQL, MySQL, Oracle, SQL Server, MariaDB, 사용자 지정 RDS.
- 구성 요소: RDS 인스턴스 크기, EBS 볼륨 유형 및 크기 프로비저닝.
- 스토리지 계층: 오토 스케일링 가능하나 여전히 프로비저닝 필요.
- 읽기 용량 확장: 읽기 전용 복제본 지원.
- 고가용성: 다중 AZ에 대기 데이터베이스 배치 가능, 재해 복구용으로 쿼리 불가.
- 보안
- IAM 인증 설정 가능.
- 네트워크 보안을 위한 보안 그룹 설정 가능.
- KMS와 SSL/TLS를 통한 암호화.
- 백업 및 복구
- 자동 백업(최대 35일) 지원, 지정 시간 복구 기능.
- 수동 DB 스냅샷으로 장기 보존 가능.
- 기타 기능
- RDS 프록시 사용하여 IAM 인증 추가 가능.
- Secrets Manager 통합 가능.
- Oracle 및 SQL 서버에서 DB 사용자 정의 가능.
Amazon Aurora
- 지원 DB 엔진: PostgreSQL 및 MySQL 호환.
- 특징
- 스토리지와 컴퓨팅 분리.
- 스토리지는 3개 가용 영역에 걸쳐 복제되어 고가용성 제공.
- 자동 스케일링 및 백그라운드 자가 복구 기능.
- 고가용성 및 확장성
- 읽기 전용 복제본으로 성능 확장.
- Aurora Multi-Master로 쓰기 고가용성 제공.
- 기능
- Aurora Serverless: 예측 불가능한 워크로드에 유용.
- Aurora Global: 글로벌 데이터베이스.
- Aurora Machine Learning 모듈 통합 가능.
- 데이터베이스 클로닝을 통한 빠른 복제.
- 성능: 높은 성능, 유연성, 내장된 기능들이 RDS보다 더 뛰어남.
Amazon ElastiCache
- 지원 캐시 엔진: Redis, Memcached.
- 특징
- 인메모리 데이터 스토어로 낮은 지연 시간(1ms 미만).
- EC2 인스턴스 유형 프로비저닝 필요.
- 복제 및 고가용성
- Redis는 다중 AZ, 샤딩 및 읽기 전용 복제본 지원.
- 보안 및 백업
- IAM 인증, 보안 그룹, KMS 및 Redis 인증 지원.
- 자동 백업 및 스냅샷 기능.
- 용도: 데이터베이스 쿼리 캐싱, 웹사이트 세션 데이터 저장.
- 제한 사항: SQL 쿼리 불가능, 코드 수정이 필요.
Amazon DynamoDB
- 특징
- 서버리스 NoSQL 데이터베이스, 밀리초 수준의 지연 시간 제공.
- 자동 스케일링, 온디맨드 용량 모드.
- 고가용성 제공(다중 AZ 복제).
- 기능
- 읽기 및 쓰기 완전 분리.
- DAX(DynamoDB Accelerator)를 통해 읽기 캐시 기능 제공.
- DynamoDB Streams로 데이터베이스 변경 사항을 스트리밍 가능.
- 백업 및 복구
- 자동 백업, 온디맨드 백업 기능.
- S3로 데이터 내보내기 가능.
- 용도: 작은 서버리스 애플리케이션, 키-값 스토어, 세션 데이터 저장.
- 제한 사항: SQL 쿼리 불가능.
Amazon S3 (Simple Storage Service)
- 특징
- 객체 기반 스토리지, 무한 확장성 제공.
- 객체의 최대 크기: 5TB.
- 스토리지 계층: S3 Standard, Infrequent Access, Intelligent-Tiering, Glacier.
- 보안 및 관리
- 버저닝, 암호화, 복제, 액세스 제어 및 로그 기능 제공.
- IAM 보안 및 버킷 정책 설정.
- 기능
- S3 Object Lambda로 객체 전송 전 수정 가능.
- 멀티파트 업로드 및 전송 가속화 기능 제공.
- S3 Event Notifications를 통한 자동화 가능.
- 용도: 대용량 파일 저장, 웹사이트 호스팅, 정적 파일 저장.
Amazon DocumentDB
- 특징
- MongoDB 호환 NoSQL 데이터베이스.
- 고가용성 제공(3개 AZ 복제).
- 자동 스토리지 확장(최대 64TB).
- 용도: 수백만 건의 요청을 처리하는 워크로드.
Amazon Neptune
- 특징
- 완전 관리형 그래프 데이터베이스.
- 소셜 네트워크, 추천 엔진, 지식 그래프 등에 적합.
- 고가용성
- 3 AZ에 걸친 복제(최대 15개 읽기 전용 복제본).
- 용도: 그래프 데이터 셋에서 복잡한 쿼리 실행, 관계형 데이터 저장.
Amazon Keyspaces
- 특징
- 관리형 Apache Cassandra 서비스.
- 서버리스, 고확장성 및 고가용성 제공.
- 쿼리: Cassandra 쿼리 언어(CQL) 사용.
- 용도: IoT 장치 정보, 시계열 데이터 저장.
Amazon QLDB (Quantum Ledger Database)
- 특징
- 완전 관리형 원장 데이터베이스, 불변 시스템.
- 금융 트랜잭션 기록 및 모든 변경 내역 추적.
- 암호화 서명 및 저널 기능 제공.
- 용도: 금융 트랜잭션 원장, 불변 데이터베이스 사용.
Amazon Timestream
- 특징
- 완전 관리형 시계열 데이터베이스.
- IoT 애플리케이션 및 실시간 분석에 최적화.
- 기능
- 자동 확장 및 축소.
- 과거 데이터를 비용 효율적인 스토리지 계층에 저장.
- 용도: IoT, 실시간 분석, 시계열 데이터 처리.
4. RDS, Aurora, ElasticCache
RDS
- Relational Database Service, AWS가 제공하는 관리형 서비스다. (프로비저닝과 OS가 자동화)
- 다양한 데이터베이스 엔진을 제공한다.
- Aurora
- Postgresql
- Mysql
- MariaDB
- Oracle
- Microsoft SQL Server
- 지속적으로 백업이 되므로, 특정 시점으로 복원이 가능하다.
- 데이터베이스의 성능을 대시 보드에서 모니터링 가능하다.
- 읽기 전용 복사본을 생성해 읽기 성능을 올릴 수도 있다.
- 재해 복구 목적으로 다중 AZ 설정 가능하다.
- 유지 관리 기간에 업그레이드도 가능하다.
- 수직 확장하거나 읽기 전용을 추가해 수평 확장도 가능하다.
- 파일 스토리지는 EBS에 구성된다. (gp2, io1)
- RDS 인스턴스는 ssh 액세스가 불가능하다.
- EC2 인스턴스에 데이터베이스 엔진을 배포할 때 설정할 모든 것을 AWS가 제공함 -> 완전 관리형
- RDS 스토리지 오토 스케일링 기능이 활성화되어 잇으면 RDS가 이를 감지해서 자동으로 확장한다.
- 디비 스토리지 용량을 늘리려고 디비를 다운시키는 등의 작업이 필요 없다.
- IO가 많으면 스토리지를 오토 스케일링 해야 하는데, 이를 위해 최대 스토리지 임계값을 정해야한다.
- 할당된 용량에서 남은 공간이 10% 미만이 되면 스토리지를 자동으로 수정한다.
- 스토리지 부족 상태가 5분이상 지속되거나 지난 수정으로부터 6시간이 지났을 경우에 오토 스케일링이 활성화되어 있다면 스토리지가 자동 확장된다.
- 워크로드를 예측할 수 없는 애플리케이션에서 굉장히 유용하다.
- 스토리지 오토 스케일링은 모든 RDS 디비 엔진에서 지원된다.
RDS 읽기 전용 복제본
- 읽기 전용 복제본은 최대 15개까지 생성 가능하다.
- 동일한 가용 영역 또는 가용 영역이나 리전을 걸쳐서 생성될 수 있다.
- 읽기 전용 복제본이 2개가 있고 메인 RDS가 있다면 두 읽기 전용 복제본 사이에 비동기식 복제가 발생한다.
- 비동기이므로 읽기가 일관적으로 유지된다.
- 읽기 전용 복제본을 마스터 데이터베이스로 승격시켜 사용할 수 있다.
사용 사례
- 운영 디비의 읽기 전용 복제본을 만들어서 분석 애플리케이션과 전용 복제본을 사용해 데이터를 분석할 수 있다.
- 클라이언트의 요청을 받는 운영DB에는 영향을 주지 않는다.
네트워크 비용
- AWS에서는 하나의 가용 영역에서 다른 가용 영역으로 데이터가 이동할 때 비용이 발생한다.
- 하지만 예외가 존재하며 보통 이 예외는 관리형 서비스다.
- RDS 읽기 전용 복제본은 관리형 서비스다.
- 읽기 전용 복제본이 다른 AZ지만 동일한 리전 내에 있을 때는 비용이 발생하지 않는다.
- 하지만 서로 다른 리전에 복제본이 존재하는 경우에는 이동할 때 네트워크에 대한 복제 비용이 발생한다.
Multi-AZ
- 다중 AZ는 주로 재해 복구에 사용된다.
- AZ A의 마스터 DB 인스턴스 AZ B의 스탠바이(대기) 인스턴스로 동기식 복제를 한다.
- 즉 마스터 DB의 모든 변화를 동기적으로 복제한다.
- 하나의 DNS 이름을 갖고 마스터에 문제가 생기면 스탠바이(대기) 인스턴스에도 자동으로 장애 조치가 수행된다.
- 전체 AZ 또는 네트워크가 손실될 때에 대비한 장애 조치이자, 마스터 DB가 고장나면 스탠바이 DB가 마스터 DB가 되도록 한다.
- 자동으로 장애 스탠바이가 마스터로 승격되기에 스케일링에 사용되지 않는다. 오로지 대기 목적이므로, 읽기 쓰기가 불가능하다.
- 읽기 전용 복제본을 다중 AZ로 설정할 수 있다.
- 단일 AZ에서 다중 AZ로 RDS 디비 전환이 가능한데 변환시에 다운 타임이 전혀 없다.
- 즉, DB를 중지할 필요가 없다
- 기본 DB의 RDS가 자동으로 스냅샷을 생성한다. -> 스탠바이 DB에 복원된다.
- 기존 DB를 읽기 전용 DB 복제본을 만들어 다중 AZ를 활성화하면 된다.
RDS Custom
- Oracle, Microsoft SQL Server에서만 가능하다.
- 기저 운영체제나 DB 사용자 지정 기능에 액세스할 수 있다.
- 내부 설정 구성, 패치 적용, 네이티브 기능 활성화, SSH 접근이 가능해진다.
Amazon Aurora
- AWS의 고유 기술로 Postgres 및 MySQL과 호환된다.
- RDS의 MySQL보다 5배 높은 성능, RDS의 Postgresql보다는 3배 높은 성능을 보장한다.
- Aurora 스토리지는 자동으로 확장된다. 10GB에서 시작하지만 디비에 더 많은 데이터를 넣을 수록 자동으로 128TB까지 커진다. (10GB ~ 128TB)
- 읽기 전용 복제본은 최대 15개의 복제본을 둘 수 있다. 복제 속도도 훨씬 빠르다.
- Aurora는 다중 AZ, MySQL RDS보다 훨씬 빠른 즉각적인 장애 조치를 취한다. 가용성도 높다.
- RDS에 비해 20% 비싸지만 스케일링 측면에서 훨씬 더 효율적이다.
높은 가용성과 읽기 스케일링
- Aurora는 특이하게 3 AZ에 걸쳐 데이터의 6개의 사본을 저장한다.
- 쓰기에는 6개 사본 중 4개가 필요하다.
- 읽기에는 6개 사본 중 3개만 있으면 된다.
- 일부 데이터가 손상되거나 문제가 있으면 백엔드에서 p2p 복제를 통한 자가 복구가 진행된다.
- 단일 볼륨에 의존하지 않고 수백개의 볼륨에 의존한다.
- 스토리지가 수백 개의 볼륨에 걸쳐 스트라이핑된다.
- 스트라이핑 : 스트라이핑(striping)은 데이터를 여러 개의 디스크나 스토리지 볼륨에 분산하여 저장하는 기술.
- 쓰기를 받는 인스턴스는 하나다.
- Aurora도 마스터가 존재하며 여기서 쓰기를 진행한다.
- 마스터가 작동하지 않으면 평균 30초 이내로 장애 조치가 시작된다. -> 매우 빠르게 장애 조치
- 마스터 외에 읽기를 제공하는 읽기전용 복제본은 최대 15개. 자동 스케일링도 설정 가능하다.
- 복제본을 많이 두고 읽기 워크로드를 스케일링할 수 있다.
- 마스터에 문제가 생기면 읽기 전용 복제본이 마스터로 대체된다.
- 이 복제본들은 리전 간 복제를 지원한다.
- 정리하면 마스터는 하나고 ,복제본은 여럿이며 스토리지가 복제된다.
- 작은 블록 단위로 자가 복구 또는 확장이 일어난다
Aurora DB cluster
- 마스터가 바뀌거나 장애조치가 실행될 수 있으므로 Aurora는 Writer 엔드포인트를 제공한다.
- Writer 엔드포인트는 DNS 이름으로 항상 마스터를 가리킨다.
- 따라서 장애 조치 후에도 클라이언트는 라이터 엔드포인트와 상호작용하게 되며 올바른 인스턴스로 자동으로 리다이렉트된다.
- 읽기 복제본도 오토 스케일링을 설정해 항상 적절한 수의 읽기 전용 복제본이 존재하도록 할 수 있다.
- Reader 엔드포인트도 존재한다. 모든 읽기 전용 복제본과 자동으로 연결된다.
- 따라서 클라이언트가 reader 엔드포인트에 연결될 때마다 읽기 전용 복제본 중 하나로 연결되며 이런 방식으로 로드 밸런싱을 도와준다.
Aurora 특징
- 자동 장애 조치
- 백엽 및 복구
- 격리 및 보안
- 산업 규정 준수
- 자동 스케일링
- 제로다운 타임 자동 패치
- 고급 모니터링
- 통상 유지 관리
- 백트랙: 과거 어떤 시점의 데이터로도 복원 가능하게 해주는 기능. 백업에 의존 하지 않는다.
Amazon Aurora 고급 개념
- 복제본 자동 스케일링을 사용해 읽기 요청을 분산하고 CPU 사용량을 감소시킬 수 있다.
- 사용자 지정 엔드포인트를 정의하고 사용해 특정 복제본에서 작업이 가능하다.
- 일반적으로 사용자 지정 엔드포인트를 정의하면 Reader 엔드포인트가 동작하지 않는다.
- 실무에서는 여러 사용자 지정 엔드포인트를 만든다.
- 서버리스 기능을 사용해 실제 사용량에 기반한 자동 데이터베이스 인스턴스화와 오토 스케일링을 가능하게 해준다. 이는 비정기적, 간헐적 또는 예측 불허한 워크로드에 유용하다. 용량 계획을 세울 필요가 없고 각 Aurora 인스턴스에 대해 매 초당 비용을 지불한다. 비용면에서 효율적이다.
- 멀티 마스터: 라이터 노드에 대한 즉각적 장애 조치로 라이터 노드에서 높은 가용성을 갖추고자 할때 사용한다.
- 이 경우 Aurora 클러스터의 모든 노드에셔 읽기 및 쓰기가 가능하다
- Global Aurora
- 모든 쓰기 및 읽기가 진행되는 하나의 기본 리전이 있다.
- 복제 지연이 1초 미만인 보조 읽기 전용 리전을 다섯개까지 설정할 수 잇고, 각 보조 지역마다 읽기 전용 복제본을 16개까지 생성가능하다. 이렇게 하면 세계 각지의 있는 읽기 전용 복제본의 지연시간을 단축할 수 있다.
- 또한 한 리전의 데이터베이스가 작동 중단될 경우 재해 복구 목적으로 다른 지역을 승격하는데 필요한 RTO, 즉 복구 시간 목표는 1분 미만이다.
- 평균적으로 Aurora 글로벌 데이터베이스에서 한 리전에서 다른 리전으로 데이터를 복제하는데는 1초 이하의 시간이 걸린다. ->
글로벌 Aurora를 사용하라는 힌트
- Aurora는 AWS내의 머신 러닝 서비스와의 통합을 지원한다. (Amazon SageMaker, Amazon Comprehend와 통합 가능)
- 이를 통해 Aurora는 머신 러닝 서비스에 데이터를 보내고 Aurora는 쿼리 결과를 응용 프로그램에게 반환한다.
RDS & Aurora
RDS 백업
자동 백업
- 이는 RDS 서비스가 자동으로 디비 유지 관리 시간에 데이터베이스 전체를 백업한다는 의미다.
- 5분마다 트랜잭션 로그도 백업. 가장 최신 백업이 5분전 임을 의미한다.
- 이 자동 백업을 사용하면 5분 전 어떤 시점으로도 복구가 가능하다.
- 자동 백업 보유 기간은 1일에서 35일까지로 설정 가능하다. 이 기능은 비활성화도 가능하다.
수동 DB 스냅샷 생성
- 사용자가 수동으로 트리거해야 한다.
- 수동 백업은 원하는만큼 오랫동안 보유할 수 있다는 장점이 있다.
- 원하는 기간동안 보유가 가능하다.
Aurora 백업
자동 백업
- 하루에서 35일까지 보유 가능한 자동 백업이다. 비활성화가 불가능하다.
- 지정 시간 복구 기능이 있는데, 정해진 시간 범위 내의 어느시점으로도 복구가 가능하다.
수동 디비 스냅샷
- 사용자가 수동으로 만들고, 원하는 기간만큼 보유 가능하다. RDS와 매우 유사하다.
복원(Restore)
- 복원이 가능한 것은 RDS 및 Aurora 백업 또는 스냅샷이다.
- 이를 새로운 디비로 복원 가능 자동 백업이나 스냅샷을 복원할 때마다 새로운 디비가 생성된다.
- S3로부터 MySQL RDS 디비를 복원 가능하다.
- 기본적인 개념은 온프레미스 디비의 백업 파일을 객체스토리지인 S3에 업로드하고 백업 파일을 복원하는 것이다.
- S3로부터 MySQL Aurora 클러스터로 복원
- Percona XtraBackup 이라는 소프트웨어를 사용해 백업한 후에 S3에 업로드하고 백업 파일을 복원하면 된다.
Aurora DB 복제
- 기존의 디비로부터 새로운 Aurora DB 클러스터를 만들 수 있다.
- 기존 배포 디비에 영향을 주지 않고 복제하여 개발 또는 테스트 수행 가능하다.
- 실제로 스냅샷을 만들고 복원하는 것보다 복제한 Aurora를 사용하는 편이 더 빠르다.
- 이유: 복제는 copy-on-write 프로토콜을 사용한다.
- 새로운 디비는 같은 클러스터 볼륨을 사용하기 때문에 빠르고 효율적이다. 데이터를 복제하지 않기 때문에
- 그리고 시간이 흐름에 따라 새 디비로 업데이트되면 변경된다.
- 디비 복제는 매우 빠르고 비용 면에서 효율적이다
RDS & Aurora Security
- RDS 및 Aurora 디비에 저장된 데이터를 암호화할 수 있다. 데이터가 볼륨에 암호화된다.
- KMS를 사용해 마스터와 모든 복제본의 암호화가 이뤄지며 이는 디비를 처음 실행할 때 정의된다.
- 어떤 이유에서든 마스터 데이터베이스를 암호화하지 않았다면 읽기 전용 복제본을 암호화할 수 없다.
- 암호화 되어 있지 않은 기존 디비를 암호화하려면 암호화되지 않은 디비의 디비 스냅샷을 가지고 와서 암호화된 디비 형태로 데이터베이스 스냅샷을 복원해야 한다.
- RDS와 Aurora는 전송중 데이터 암호화라는 기능이 있다. 따라서 클라이언트는 AWS의 TLS 루트 인증서를 사용해야 한다.
- IAM 역할을 사용해서 디비에 접속하거나 사용자 이름/비밀번호로 접속 가능하다.
- 보안 그룹을 사용해 디비에 대한 네트워크 액세스를 통제할 수 있다.(포트, 아이피, 보안 그룹 등)
- RDS & AURORA는 SSH로 접근 불가능. custom RDS는 제외다.
- 감사 로그 작성을 활성화하면 시간에 따라 RDS 및 Aurora에서 어떤 쿼리가 생성되는지 확인 가능 장기관 보관하고 싶다면 CloudWatch Log 서비스로 전송해야 한다.
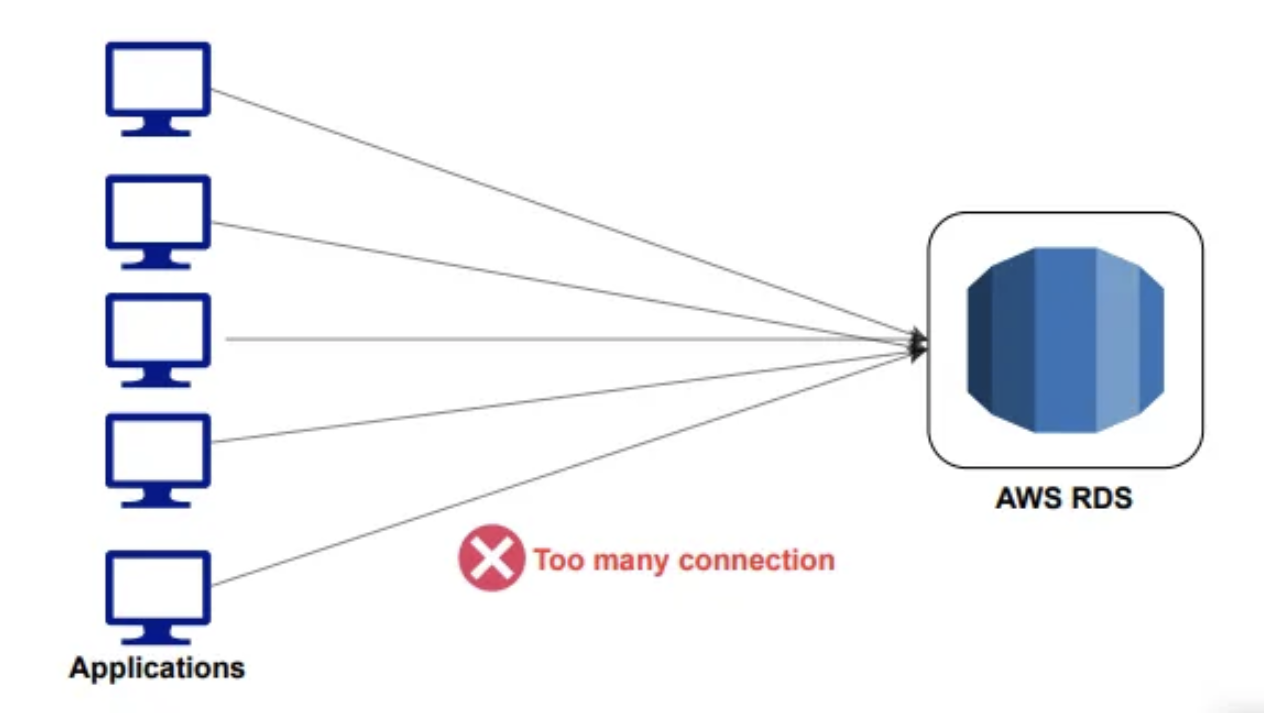
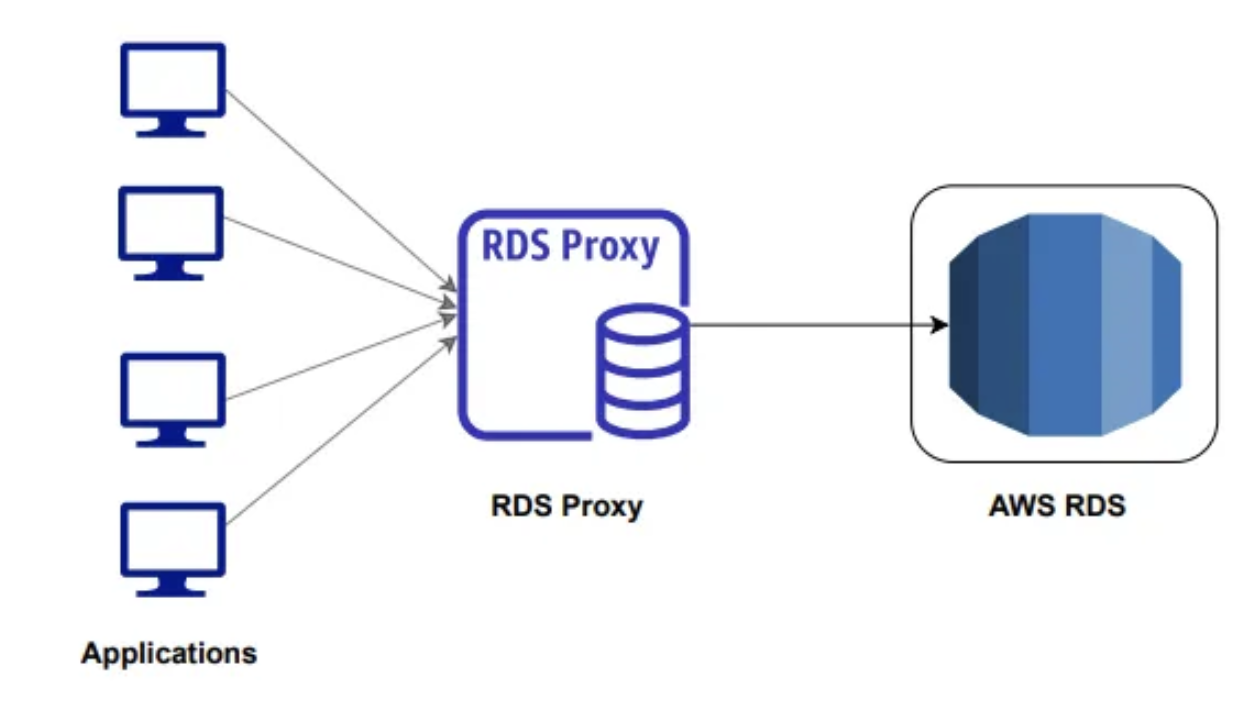
RDS Proxy
- 애플리케이션과 RDS 데이터베이스에 대한 연결을 최소화한다.
- RDS PRoxy는 완전한 서버리스로 오토 스케일링이 가능해 용량 관리가 필요 없고 가용성이 높다.(다중 AZ 지원)
- 장애 조치 시간을 66%까지 줄일 수 있다.
- RDS Proxy를 사용하면 애플리케이션은 장애와 무관한 RDS 프록시와 연결된다.
- RDS 프록시는 장애가 발생한 RDS 데이터베이스 인스턴스를 처리하므로 장애 조치 시간이 개선된다.
- RDS PROXY는 MySQL, PostgreSQL, MariaDB용 RDS를 지원하고 MySQL, PostgreSQL 용 Aurora를 지원한다.
- DB에 IAM 인증을 강제함으로써 IAM 인증을 통해서만 RDS 디비 인스턴스에 연결하도록 할 수 있다. 이때 자격증명은 AWS Secrets Manager 서비스에 안전하게 저장된다.
- RDS는 프록시는 퍼블릭 액세스가 절대 불가능하다. !https://velog.velcdn.com/images/jaymin_e/post/b2a647ce-444f-4b0b-a822-435d068cad97/image.png !https://velog.velcdn.com/images/jaymin_e/post/a6226457-e686-4cf4-a399-206463088c73/image.png
{kind=link}
{kind=link}
ElasticCache
- 모든 캐시는 IAM 인증을 지원하지 않는다.
- IAM 정책은 AWS API 수준의 보안에만 사용된다.
- RDS와 동일한 방식으로 관계형 디비를 관리할 수 있다.
- 레디스와 멤캐시 같은 캐시 기술을 관리한다
- 낮은 지연 시간을 가진 인 메모리 디비다.
- 엘라스틱 캐시를 사용해 읽기 집약적인 워크로드의 부하를 줄이는데 도움이 된다.
- 애플리케이션의 상태를 Amazon 엘라스틱 캐시에 저장해 애플리케이션을 무상태로 만들 수 있다
- RDS와 같은 장점을 갖기 때문에 AWS는 동일한 유지 보수를 수행한다.(운영체제, 패치, 최적화와 설정, 구성, 모니터링, 장애 회복 그리고 백업 수행한다.)
- 엘라스틱 캐시를 사용할 때 캐시의 정합성을 고려하면 어려운 부분이 존재한다.
- 엘라스틱 캐시를 디비 캐시, 유저 세션 스토어로 많이 사용한다.
- Redis는 자동 장애 조치와 함께 다중 AZ를 수행한다.
- Redis 읽기 전용 복제본은 읽기 스케일링에 사용되며 고가용성을 가짐 지속성으로 인해 데이터 내구성도 갖추고 있다. 백업, 복원이 가능하며 RDS와 유사하다.
- Memcached는 데이터 분할을 위해 멀티 노드(샤딩)를 사용한다.
- 고가용성이 없고 복제가 일어나지 않으며 영구 캐시가 아니다.
- 백업 및 복원의 기능이 없다.
- 멀티 스레드 아키텍처이다.
- Memcached에서는 여러 인스턴스가 모두 샤딩을 통해 작동한다.
- Redis는 고가용성, 백업, 읽기 복제본 등을 위해 존재
- 반면, Memcached는 분산되어 있는 순수한 캐시. 데이터 손실되어도 괜찮은 경우, 고가용성이 없으며 백업, 복원 기능 없다.
ElasticCache 보안
- Redis에서만 IAM 인증을 지원하며, 나머지 경우에는 사용자 이름과 비밀번호를 사용하면 된다.
- ElasticCache에서 IAM 정책을 정의하면 AWS API 수준 보안에만 사용된다.
- Redis AUTH라는 Redis 내 보안을 통해 비밀번호와 토큰을 설정할 수 있다. -> Redis 클러스트를 생성할때
- 이는 캐시에 사용할 수 있는 보안 그룹에 대한 추가적인 수준의 보안이다.
- 그리고 전송 중 암호화를 위해 SSL 보안을 지원할 수 있다.
- EC2 인스턴스와 클라이언트가 있는 경우 Redis AUTH를 사용하여 Redis 클러스터에 연결할 수 있다.
- 이는 Redis 보안 그룹에 의해 보호되는 것이다.
- 또한, in-flight 암호화 사용하거나, Redis에서 IAM 인증을 활용할 수 있다.
Memcached
- 좀 더 높은 수준인 SASL 기반 인증을 지원한다. 상당히 고급이라 다른 종류의 인증 메커니즘이다.
일래스틱 캐시의 패턴
일래스틱 캐시에 데이터를 불러오는 패턴에는 3가지 패턴이 있다.
1. 지연 로딩
- 모든 읽기 데이터가 캐시되고 데이터가 캐시에서 오래될 수 있다. (케케 묵을 수 있다.)
2. Write Through
- 데이터를 오래된 데이터가 없는 디비에 기록될때마다 캐시에 데이터를 추가하거나 업데이트하는 것이다.
3. 세션 저장소
- Time To Live 속성으로 세션을 만료시킬 수 있다.
5. 데이터 & 분석
Athena
Amazon Athena는 Amazon S3 버킷에 저장된 데이터를 분석하는 서버리스 쿼리 서비스입니다. Athena에 대한 핵심 포인트를 정리해 드리겠습니다:
- 기능 및 구성:
- Athena는 움직이는 데이터 없이 Amazon S3에 있는 데이터를 직접 쿼리하고 분석할 수 있습니다.
- SQL 표준 언어를 사용하여 쿼리를 작성하며, Presto 엔진을 기반으로 하고 있습니다.
- 데이터 형식:
- Athena는 CSV, JSON, ORC, Avro, Parquet 등 다양한 데이터 형식을 지원합니다.
- 비용 구조:
- 사용자는 스캔된 데이터에 대해 TB당 고정된 가격을 지불합니다. 불필요한 데이터 스캔을 줄이기 위해 파티셔닝 및 압축을 사용하는 것이 좋습니다.
- 서버리스 아키텍처:
- 서버리스 서비스인 Athena는 데이터베이스를 프로비저닝하거나 관리할 필요 없이 사용 가능합니다.
- 통합 및 사용 사례:
- Amazon QuickSight와 자주 함께 사용되며, 이를 통해 보고서와 대시보드를 생성할 수 있습니다.
- 임시 쿼리, 비즈니스 인텔리전스 분석 및 보고에 적합하며 AWS 서비스 로그(VPC 흐름 로그, 로드 밸런서 로그, CloudTrail 추적 등)를 쿼리하고 분석하는 데 유용합니다.
- 시험 대비 팁:
- Athena를 기억할 경우 서버리스 SQL 엔진을 사용하여 Amazon S3 데이터를 분석할 때 고려해야 한다는 점을 염두에 두십시오.
이런 특성들을 통해 Athena는 대규모 데이터 세트에 대한 분석 작업을 간소화하며, 인프라 관리 없이 빠르게 비즈니스 인텔리전스를 얻을 수 있는 도구입니다.
성능 향상
Amazon Athena를 효과적으로 사용하여 비용 절감과 성능 향상을 이루는 방법을 정리해 보겠습니다.
- 열 기반 데이터 형식 사용:
- Amazon Athena는 스캔된 데이터의 양에 따라 비용이 청구됩니다. 열 기반 데이터 형식을 사용하면 필요한 열만 스캔되어 비용을 줄일 수 있습니다.
- Apache Parquet과 ORC는 열 기반 형식으로, Athena에서 비용 효율적으로 데이터 처리를 할 수 있습니다.
ORC(Optimized Row Columnar) 형식은 대용량 데이터 처리와 분석을 위해 Apache Hadoop 에코시스템에서 개발된 컬럼 기반의 데이터 저장 형식입니다. ORC 파일 형식은 성능이 중요한 대규모 데이터 작업에서 뛰어난 압축과 빠른 쿼리 성능을 제공합니다. 다음은 ORC의 주요 특징입니다:
컬럼 기반 저장:
- 데이터를 각각의 열별로 저장하여, 쿼리 시 필요한 열만 읽는 것을 가능하게 합니다. 이는 쿼리를 더 빠르게 처리하고 I/O 비용을 줄이는 데 도움이 됩니다.
고효율 압축:
- 데이터가 열 단위로 저장되어 있어 특정 열의 데이터는 일반적으로 비슷한 형식을 가지므로 효율적인 압축이 가능합니다. 이는 저장 공간 절약과 더 빠른 데이터 처리 속도를 제공합니다.
인덱싱 및 메타데이터:
- ORC 파일은 자동으로 인덱스와 메타데이터를 생성하여 빠르고 효율적인 데이터 검색을 지원합니다. 이는 대규모 데이터 세트에서 성능을 더욱 향상시키는 역할을 합니다.
서식화된 대규모 처리:
- Apache Hive와 같은 데이터 처리 및 분석 도구와 잘 연동되며, 대규모 데이터 처리 작업에서 성능을 극대화합니다.
ORC 형식은 특히 Amazon Athena, Apache Hive, Apache Spark와 같은 데이터 분석 도구에서 데이터를 효율적으로 저장하고 쿼리하는 데 사용됩니다. Athena에서는 ORC를 사용함으로써 데이터 스캔 비용을 줄이고 쿼리 성능을 높일 수 있습니다.
- 데이터를 Apache Parquet이나 ORC 형식으로 변환하는 데 AWS Glue가 자주 사용됩니다.
- 데이터 압축(bzip2, gzip, lz4, snappy, zlib, zstd 등)을 통해 스캔되는 데이터의 양을 줄여 추가적인 비용 절감 효과를 볼 수 있습니다.
- 데이터 세트 분할(파티셔닝):
- 동일한 열을 자주 쿼리할 경우, 데이터를 S3 버킷의 경로를 기준으로 슬래시로 나누어 파티셔닝할 수 있습니다(예:
s3://bucket/year=2023/month=10/day=01/). - 이렇게 하면 쿼리 시 특정 폴더(경로)에서만 데이터를 읽기 때문에 성능을 향상시키고 비용을 절감할 수 있습니다.
- 동일한 열을 자주 쿼리할 경우, 데이터를 S3 버킷의 경로를 기준으로 슬래시로 나누어 파티셔닝할 수 있습니다(예:
- 큰 파일 사용:
- 많은 작은 파일 대신 큰 파일로 데이터를 저장하여 오버헤드를 최소화하면 Athena의 성능을 향상시킬 수 있습니다.
- 일반적으로 128MB 이상의 큰 파일을 사용하는 것이 좋습니다. 큰 파일은 스캔과 검색이 더 효율적이기 때문입니다.
이러한 최적화 기법들을 통해 Amazon Athena를 사용할 때 비용 효율성과 성능을 높일 수 있습니다. 이는 대량의 데이터를 다루는 작업 환경에서 특히 중요합니다.
연합 쿼리
Amazon Athena는 S3에 있는 데이터뿐만 아니라 다양한 데이터 소스에 대해 쿼리를 실행할 수 있으며, 이를 통해 데이터 분석의 유연성을 제공합니다. 아래는 Amazon Athena의 데이터 소스 확장 기능에 대한 설명입니다.
- 데이터 원본 커넥터:
- Athena는 Lambda 함수를 활용하여 다양한 데이터 소스에 대한 연합(Federated) 쿼리를 지원합니다.
- 데이터 원본 커넥터는 각 데이터 소스와 연동하여 쿼리를 실행하는 Lambda 함수입니다.
- 지원되는 데이터 소스:
- AWS 서비스: CloudWatch Logs, DynamoDB, RDS, ElastiCache, DocumentDB, Redshift, Aurora 등 다양한 AWS 서비스의 데이터에 쿼리를 실행할 수 있습니다.
- 온프레미스 데이터베이스: 자체 데이터 센터에 있는 온프레미스 데이터베이스도 쿼리가 가능합니다.
- 다양한 데이터베이스 시스템: SQL 서버, MySQL, EMR 서비스의 HBase 등 다양한 데이터베이스 시스템과도 연결할 수 있습니다.
- 쿼리 기능:
- 데이터 원본 커넥터를 통해 여러 다른 데이터 소스의 데이터를 연합 쿼리할 수 있으며, 이를 통해 다양한 데이터 세트 간의 관계를 분석할 수 있습니다.
- 쿼리 결과는 분석 및 보관을 위해 Amazon S3 버킷에 저장할 수 있습니다.
Athena의 이러한 확장성을 통해 조직은 AWS 내외의 다양한 데이터 소스를 통합적으로 분석하고 데이터 간의 관계를 효율적으로 이해할 수 있습니다. 이러한 기능은 데이터 분석 작업에서 큰 유연성을 제공하며, 다양한 데이터 소스에 대한 통찰을 얻는 데 매우 유용합니다.
Redshift
- Redshift는 PostgreSQL 기술 기반이지만 온라인 트랜잭션 처리(OLTP)에 사용되지 않는다.
- 온라인 분석 처리를 의미하는 OLAP 유형의 데이터베이스이며 분석과 데이터 웨어하우징에 사용한다.
- 다른 어떤 데이터 웨어하우징보다 성능이 10배 이상 좋고 데이터가 PB 규모로 확장되므로 모든 데이터를 Redshift에 로드하면 Redshift에서 빠르게 분석할 수 있다.
- Redshift는 성능 향상이 가능한데 이는 열 기반 데이터 스토리지를 사용하기 때문 (행 기반이 아니라 병렬 쿼리 엔진)
- Redshift 클러스터에서 프로비저닝한 인스턴스에 대한 비용만 지불하면 된다.
- 쿼리를 수행할 때 SQL 문을 사용할 수 있고, Amazon Quicksight 같은 BI 도구나 Tableau 같은 도구와 통합 가능
Athena vs Redshift
- Redshift는 먼저 Amazon S3에서 모든 데이터를 Redshift에 로드해야 한다.
- Redshift에 데이터를 로드하고 나면 Redshift의 쿼리가 더 빠르고 조인과 통합을 훨씬 더 빠르게 할 수 있다. (Redshift에는 인덱스가 있기에)
- Redshift는 데이터 웨어하우스가 높은 성능을 발휘하도록 인덱스를 빌드한다.
- Amazon S3의 ad hoc(즉선)쿼리라면 Athena가 좋은 사용 사례가 되지만, 쿼리가 많고 복잡하며 조인하거나 집계하는 등 집중적인 데이터 웨어하우스라면 Redshift가 더 좋다.
- ad hoc 네트워크는 중앙 통제 장치 없이 기기들이 직접 서로 연결되어 임시로 형성되는 네트워크를 말합니다. 가장 흔한 예로는 모바일 기기들 간의 직접 연결을 들어볼 수 있습니다.
Redshift Cluster
- Redshift 클러스터에는 두 노드가 있다.
- 리더 노드(쿼리 계획과 결과 집합을 시킴)와 계산노드(Compute Node)가 존재한다.
- 리더 노드에 쿼리를 SQL 형식으로 제출하면 백엔드에서 쿼리가 발생한다.
- 리더 노드는 쿼리를 계획하고 결과를 집계하며 계산 노드는 실제로 쿼리를 실행하고 결과를 리더 노드에 보낸다.
- Redshift 클러스터는 노드 사이즈를 사전에 프로비저닝해야 하고 비용을 절감하려면 예약 인스턴스를 사용하면 된다.
Snapshots & DR
- 멀티 AZ와 싱글 AZ:
- Redshift 클러스터는 대부분 싱글 AZ에 배포되지만, 일부 클러스터 유형은 멀티 AZ 모드가 지원됨.
- 멀티 AZ 모드에서는 자동으로 재해 복구가 가능하지만, 싱글 AZ에서는 스냅샷을 활용한 재해 복구 전략이 필요함.
- 스냅샷:
- 스냅샷은 특정 시점의 클러스터 백업으로, Amazon S3에 저장됨.
- 증분 스냅샷: 변경된 데이터만 저장하여 저장 공간을 절약함.
- 스냅샷 종류:
- 자동 스냅샷: 일정에 따라 8시간마다 또는 5GB마다 자동 생성됨. 자동 스냅샷은 보존 기간을 설정할 수 있음.
- 수동 스냅샷: 사용자가 수동으로 생성하며, 삭제 전까지 유지됨.
- 재해 복구 전략:
- 스냅샷은 다른 AWS 리전에 자동으로 복사할 수 있어, 재해 복구 전략을 더욱 강화할 수 있음.
- 원본 Redshift 클러스터의 스냅샷을 다른 리전에 복사하면, 해당 리전에서 새 클러스터를 복원할 수 있음.
핵심 포인트:
- Redshift 클러스터가 싱글 AZ일 경우, 스냅샷을 사용한 재해 복구 전략이 필요.
- 자동 스냅샷과 수동 스냅샷은 서로 다른 목적에 따라 사용 가능하며, 스냅샷은 다른 리전으로 복사하여 복원할 수 있음.
데이터 수집 방법
1. Amazon Kinesis Data Firehose
- 목적: 다양한 소스로부터 데이터를 받아 Amazon Redshift에 전달.
- 작동 방식:
- 데이터가 Amazon S3에 먼저 저장됨.
- Kinesis Data Firehose는 자동으로 S3에서 Redshift로 데이터를 복사하고 로드함.
2. S3 using COPY command
- 목적: 수동으로 데이터를 Redshift에 로드.
- 작동 방식:
- 데이터를 S3 버킷에 저장하고, Redshift에서 COPY 명령을 실행하여 데이터를 로드.
- IAM 역할을 사용하여 S3 버킷에서 Redshift 클러스터로 데이터를 복사.
- 네트워크:
- 인터넷을 통해 데이터를 전송할 수 있음, S3가 인터넷과 연결되기 때문.
- 향상된 VPC 라우팅을 사용하여 모든 네트워크 트래픽을 VPC로 비공개로 유지할 수 있음.
3. JDBC 드라이버
- 목적: 애플리케이션에서 EC2 인스턴스를 사용하여 Redshift 클러스터에 데이터를 쓰는 방식.
- 작동 방식:
- 배치 처리 방식이 효율적, 한 번에 여러 행을 쓰는 것이 좋음.
- 비효율적인 방식: 한 번에 한 행씩 쓰는 방식은 성능이 떨어짐.
4. Redshift Spectrum
- 목적: Amazon S3에 저장된 데이터를 Redshift 클러스터에 로드하지 않고 분석.
- 작동 방식:
- Redshift Spectrum은 Redshift 클러스터에서 쿼리를 시작하고, S3의 데이터에 대해 쿼리를 실행.
- S3에 있는 데이터에 대한 쿼리가 수천 개의 Redshift Spectrum 노드에서 실행되고, 결과는 Redshift 클러스터로 반환됨.
- 장점:
- 데이터를 Redshift로 로드하지 않고도 S3 데이터를 분석할 수 있음.
- 더 많은 처리 능력을 활용할 수 있어 대규모 데이터 분석에 유리함.
정리:
- Kinesis Data Firehose와 S3 COPY command는 데이터를 Redshift에 로드하는 방법이며, Kinesis는 자동화된 방식, COPY는 수동 방식.
- JDBC 드라이버는 EC2 인스턴스를 통해 애플리케이션에서 대량 데이터를 처리할 때 사용.
- Redshift Spectrum은 S3에 저장된 데이터를 Redshift에 로드하지 않고 분석할 수 있게 해주는 기능으로, 더 큰 처리 능력을 활용할 수 있는 방법.
OpenSearch Service
- 소개: Amazon OpenSearch는 이전의 Amazon ElasticSearch의 후속 서비스입니다. 서버리스 옵션도 제공하며, 검색 기능과 쿼리 분석에 주로 사용됩니다.
- 주요 특징:
- 검색 기능: DynamoDB와 비교할 때, OpenSearch는 부분 일치 검색 및 모든 필드 검색을 지원하여 더 정교한 검색 기능을 제공합니다.
- 쿼리 분석: 데이터를 검색하는 것뿐만 아니라 쿼리 분석을 통해 더 깊은 통찰을 얻을 수 있습니다.
- 두 가지 모드:
- 사용자가 물리적인 인스턴스를 프로비저닝하는 방법.
- 서버리스 경로를 선택해 자동으로 AWS에서 스케일링 및 운영되는 클러스터 생성.
- SQL 호환성: 자체 쿼리 언어를 사용하지만, SQL을 지원하지 않으며, Kinesis Data Firehose, AWS IoT, CloudWatch Logs 등의 데이터를 통해 SQL 호환성을 활성화할 수 있습니다.
- 보안: Cognito와 IAM을 통한 암호화(저장 데이터 및 전송 중 데이터 암호화).
- 시각화: OpenSearch Dashboards를 사용해 데이터를 시각화할 수 있습니다.
- 데이터 주입: DynamoDB, CloudWatch Logs 등에서 데이터를 OpenSearch로 주입할 수 있습니다.
EMR(Elastic MapReduce)
- 소개: Amazon EMR은 AWS에서 빅 데이터 작업을 위한 하둡 클러스터 생성 및 관리를 돕는 서비스입니다. 방대한 양의 데이터를 분석하고 처리할 수 있습니다.
- 주요 특징:
- 클러스터: EMR은 하둡 클러스터를 기반으로 하며, 수백 개의 EC2 인스턴스로 구성될 수 있습니다.
- 지원 도구:
- Apache Spark, HBase, Presto, Apache Flink 등과 같은 빅 데이터 처리 도구들이 함께 제공됩니다.
- Amazon EMR은 이 도구들의 설정과 프로비저닝을 대신 처리해 주므로 사용자가 별도로 설정할 필요가 없습니다.
- 자동 확장: 클러스터를 자동으로 확장할 수 있으며, 스팟 인스턴스와의 통합을 통해 비용 절감도 가능합니다.
- 사용 사례: 빅 데이터 작업, 데이터 처리, 기계 학습, 웹 인덱싱 등에 사용됩니다.
EMR Node 유형
Amazon EMR은 EC2 인스턴스를 기반으로 한 클러스터로 구성되며, 주요 노드 유형은 다음과 같습니다:
- 마스터 노드:
- 클러스터의 관리를 담당하며, 다른 노드들의 상태를 조정.
- 장기 실행되어야 합니다.
- 코어 노드:
- 데이터 저장과 태스크 실행을 담당.
- 장기 실행되어야 합니다.
- 태스크 노드:
- 테스트 및 분석 작업을 실행하며, 주로 스팟 인스턴스를 사용하여 비용 절감.
- 인스턴스 유형:
- 온디맨드 EC2 인스턴스: 신뢰할 수 있고 예측 가능한 워크로드를 제공하며, 절대 종료되지 않습니다.
- 예약 인스턴스: 장기 실행해야 하는 노드에 적합하며, 예약을 통해 비용 절감이 가능합니다.
EMR 배포 및 사용 방식
- 예약 인스턴스:
- 마스터 노드와 코어 노드에 적합하며, 비용을 절감할 수 있습니다.
- 장기 실행 클러스터에서는 예약 인스턴스를 사용하고, 임시 클러스터에서는 특정 작업을 위해 사용 후 삭제할 수 있습니다.
QuickSight
- 개요: Amazon QuickSight는 서버리스 머신 러닝 기반의 비즈니스 인텔리전스(BI) 서비스로, 데이터 분석과 시각화를 통해 비즈니스 인사이트를 얻을 수 있습니다. 대화형 대시보드를 생성하고 다양한 데이터 소스와 연결하여 시각화 및 분석을 수행할 수 있습니다.
- 주요 특징:
- 서버리스: 사용자가 인프라를 관리할 필요 없이, 자동으로 오토 스케일링되어 확장됩니다.
- 시각화: 데이터 시각화 및 분석을 빠르게 수행할 수 있으며, 대화형 대시보드를 제공하여 실시간으로 데이터를 탐색하고 분석할 수 있습니다.
- 임베드 기능: 웹사이트에 대시보드를 임베드할 수 있으며, 세션당 비용을 지불하는 방식입니다.
- 비즈니스 인사이트: 비즈니스 분석 시각화, 임시 분석, 데이터 기반 인사이트 획득 등 다양한 용도로 사용됩니다.
- 지원되는 데이터 소스:
- RDS, Aurora, Athena, Redshift, S3 등과 연결 가능합니다.
- SPICE 엔진을 사용하여 데이터를 빠르게 처리합니다.
- 타사 데이터 소스와의 통합도 가능, 예: Salesforce, Jira 등.
- 온프레미스 데이터베이스와도 JDBC 프로토콜을 통해 통합할 수 있습니다.
- Excel, CSV, JSON 파일 등을 직접 가져올 수 있습니다.
- SPICE 엔진:
- In-memory 연산 엔진: QuickSight에서 데이터를 처리할 때 사용하는 메모리 기반 엔진으로, 데이터의 빠른 처리 및 분석을 돕습니다.
- 제한: 다른 DB에 연결되어 있을 때는 SPICE 엔진이 작동하지 않습니다.
- 보안 기능:
- 열 수준 보안(CLS): QuickSight의 엔터프라이즈 에디션에서 제공되며, 사용자별로 열 접근 권한을 설정하여 민감한 데이터를 보호할 수 있습니다.
통합
QuickSight는 다양한 AWS 서비스 및 외부 소스와 통합 가능합니다:
- AWS 서비스 통합:
- RDS, Aurora, Redshift, S3 (Athena), OpenSearch, Timestream 등.
- Athena 및 Redshift와의 통합은 시험에서 자주 출제되는 사용 사례입니다.
- 타사 데이터 소스:
- Salesforce, Jira와 같은 서비스형 소프트웨어(SaaS)와 통합 가능합니다.
- 온프레미스 데이터베이스:
- JDBC 프로토콜을 사용하여 온프레미스 데이터베이스와도 통합할 수 있습니다.
- 파일 가져오기:
- Excel, CSV, JSON, TSV, ELF, CLF 등 다양한 파일 형식을 지원하며, 이를 QuickSight로 가져와 분석할 수 있습니다.
대시보드와 분석
- 대시보드 및 분석:
- 대시보드: 읽기 전용 스냅샷으로, 분석 결과를 사용자 또는 그룹과 공유할 수 있습니다. 대시보드에 필터와 매개변수가 포함되어, 다양한 분석 결과를 쉽게 확인할 수 있습니다.
- 분석: QuickSight에서 분석 작업을 통해 데이터를 시각화하고 대시보드로 저장할 수 있습니다.
- 사용자와 그룹: QuickSight에서 사용자와 그룹을 정의하여 특정 대시보드나 분석 결과에 대한 액세스 권한을 설정할 수 있습니다.
- QuickSight 버전:
- 스탠다드 버전: 사용자 정의가 가능하고, 대시보드 및 분석을 생성할 수 있습니다.
- 엔터프라이즈 버전: 그룹 기능을 추가로 지원하고, 열 수준 보안(CLS) 등을 제공하여 더 세밀한 권한 관리를 할 수 있습니다.
- IAM 사용자는 관리용으로만 사용되고, QuickSight 사용자는 실제 분석 작업에 사용됩니다.
정리:
- Amazon QuickSight는 서버리스 BI 서비스로, 다양한 AWS 데이터 소스와 통합하여 대시보드와 분석 작업을 수행할 수 있습니다.
- SPICE 엔진을 사용해 빠른 데이터 처리가 가능하며, 열 수준 보안(CLS) 기능을 통해 민감한 데이터에 대한 접근 제어도 가능합니다.
SPICE 엔진은 Amazon QuickSight에서 사용되는 데이터 계산 엔진으로, SPICE는 Super-fast, Parallel, In-memory Calculation Engine의 약자입니다. SPICE는 QuickSight의 성능과 확장성을 지원하는 핵심 기술로, 대규모 데이터를 빠르게 처리하고 효율적으로 분석할 수 있도록 설계되었습니다.
- 다양한 타사 서비스와 온프레미스 데이터베이스와도 통합할 수 있어, 폭넓은 데이터 소스에서 분석을 수행할 수 있습니다.
- 주요 사용 사례: QuickSight는 Athena, Redshift와 함께 사용하는 문제들이 자주 출제됩니다. 다른 통합과 관련된 문제도 출제될 수 있습니다.
Glue
AWS Glue는 완전 서버리스 ETL(추출, 변환, 로드) 서비스로, 분석을 위한 데이터 준비와 변환 작업에 유용합니다. 주요 기능은 다음과 같습니다:
AWS Glue 개요
- 서버리스 ETL 서비스: 데이터를 추출, 변환, 로드(ETL)하는 완전 서버리스 서비스로, 관리 부담 없이 ETL 작업을 자동화할 수 있습니다.
- 데이터 준비 및 변환: 분석을 위해 데이터를 준비하고 변환하는 데 매우 유용한 서비스입니다.
고급 기능
- Glue 작업 북마크
- 이전에 처리한 데이터를 재처리하지 않도록 하여 ETL 작업의 효율성을 높입니다. 새로운 ETL 작업을 실행할 때, 변경된 데이터만 처리하게 됩니다.
- Glue Elastic Views
- SQL을 사용해 여러 데이터 스토어의 데이터를 결합하고 복제할 수 있습니다.
- 예: RDS, Aurora, Amazon S3와 같은 데이터 스토어에 걸친 뷰(view)를 생성할 수 있습니다.
- Glue는 원본 데이터의 변경 사항을 자동으로 모니터링하며, 커스텀 코드는 지원하지 않습니다.
- 서버리스 서비스로 제공되며, 분산된 데이터 스토어 간 가상 테이블을 생성하여 데이터를 결합할 수 있습니다.
- SQL을 사용해 여러 데이터 스토어의 데이터를 결합하고 복제할 수 있습니다.
- Glue DataBrew
- 사전 빌드된 변환을 사용하여 데이터를 정리하고 정규화할 수 있습니다.
- 복잡한 변환 작업을 위한 코딩 없이 데이터 준비를 할 수 있습니다.
- Glue Studio
- Glue에서 ETL 작업을 생성, 실행 및 모니터링할 수 있는 GUI(그래픽 사용자 인터페이스)를 제공합니다.
- 직관적인 인터페이스를 통해 ETL 작업을 시각적으로 설정하고 관리할 수 있습니다.
- Glue 스트리밍 ETL
- Apache Spark Structured Streaming 위에 구축되어, 스트리밍 데이터를 실시간으로 처리하는 ETL 작업을 지원합니다.
- Kinesis Data Streaming, Kafka, MSK(AWS Managed Streaming for Kafka)에서 실시간으로 데이터를 읽어 처리할 수 있습니다.
정리:
- AWS Glue는 완전 서버리스 ETL 서비스로, 데이터를 추출하고 변환하여 분석을 위한 준비 작업을 효율적으로 수행할 수 있습니다.
- Glue Elastic Views와 Glue DataBrew는 데이터를 결합하고 정리하는 데 유용하며, Glue Studio는 ETL 작업의 시각적 관리와 모니터링을 제공합니다.
- Glue 스트리밍 ETL은 실시간 데이터 스트리밍 작업을 지원하여, 다양한 데이터 소스에서 데이터를 실시간으로 처리할 수 있습니다.
Lake Formation
AWS Lake Formation은 데이터 레이크를 쉽게 생성하고 관리할 수 있는 완전 관리형 서비스로, 데이터를 중앙 집중식 저장소에 모아 분석할 수 있게 도와줍니다. 주요 기능과 특징은 다음과 같습니다:
AWS Lake Formation 개요
- 데이터 레이크: 다양한 정형 및 비정형 데이터를 하나의 중앙 집중식 저장소(Amazon S3)로 모아 분석하는 구조입니다.
- Lake Formation은 데이터 레이크를 손쉽게 구축하고 운영할 수 있도록 도와주는 서비스로, 데이터 검색, 정제, 변환, 주입 등을 지원합니다.
- 기계 학습(ML) 변환 기능: 중복 제거와 같은 데이터 정제 작업을 자동화합니다.
- 복잡한 작업 자동화: 데이터 수집, 정제, 카탈로깅, 복제 등의 수작업을 자동화합니다.
주요 기능
- 데이터 소스 및 주입:
- 데이터 레이크에서는 정형 데이터(예: RDS, Aurora)와 비정형 데이터(예: Amazon S3, NoSQL 데이터베이스 등)를 결합할 수 있습니다.
- 블루프린트를 통해 데이터를 데이터 레이크로 이전하거나 주입할 수 있습니다.
- 블루프린트는 Amazon S3, RDS, 온프레미스 데이터베이스와 같은 다양한 소스에서 데이터를 주입하는 데 사용됩니다.
- 세분화된 액세스 제어:
- 행과 열 수준의 액세스 제어가 가능하여, 애플리케이션에서 세밀한 데이터 보안을 관리할 수 있습니다.
- Lake Formation을 사용하면 중앙 집중식으로 보안을 관리하고, 연결된 서비스에서는 읽기 권한이 있는 데이터만 볼 수 있습니다.
- 보안 설정 및 중앙화된 권한 관리:
- 데이터 레이크의 보안 설정은 Lake Formation 내에서 관리됩니다.
- S3 버킷 정책, RDS 및 Aurora의 보안 설정도 포함되며, 이 모든 것이 Lake Formation을 통해 중앙에서 관리됩니다.
- Athena, QuickSight 등 분석 도구는 Lake Formation을 통해 보안을 관리하며, 사용자가 허용된 데이터만 볼 수 있도록 합니다.
- Lake Formation의 서비스 통합:
- Glue는 Lake Formation의 기본 서비스로, ETL 및 데이터 준비, 카탈로깅 등을 담당합니다.
- 데이터 분석 도구인 Athena, Redshift, EMR (Apache Spark 프레임워크) 등이 Lake Formation과 통합되어 데이터를 분석할 수 있습니다.
Lake Formation의 역할
- 데이터 레이크 생성: 데이터 레이크를 구축하고 Amazon S3에 데이터를 저장하는 작업을 돕습니다.
- 보안 및 액세스 제어: 데이터에 대한 행/열 수준 보안을 통해 세분화된 접근 권한을 관리하고, 중앙화된 권한 관리를 제공합니다.
- 자동화 및 관리: 데이터 수집, 정제, 카탈로깅, 복제와 같은 복잡한 수작업을 자동화하여 데이터 처리 효율을 높입니다.
중앙화된 권한 관리
- Athena, QuickSight와 같은 도구에서 사용자가 허용된 데이터만 볼 수 있도록 하며, 읽기 권한을 설정할 수 있습니다.
- S3 버킷 정책이나 RDS의 보안을 Lake Formation 내에서 관리하면 여러 시스템에서 보안 관리가 일관되게 유지됩니다.
정리
- AWS Lake Formation은 데이터 레이크 생성을 쉽게 하고, 데이터 보안과 액세스 제어를 중앙에서 관리할 수 있는 서비스입니다.
- 세분화된 액세스 제어와 보안 관리를 통해 사용자는 허용된 데이터만 볼 수 있으며, 다양한 AWS 서비스(Athena, QuickSight 등)와 통합되어 데이터를 안전하게 분석할 수 있습니다.
- Lake Formation은 Glue와 함께 데이터를 정리, 변환, 주입하는 작업을 자동화하고 효율화할 수 있습니다.
Kinesis Data Analytics
Kinesis Data Analytics는 실시간 스트리밍 데이터 분석을 위한 AWS 서비스로, 두 가지 주요 애플리케이션 유형을 지원합니다: SQL 애플리케이션과 Apache Flink 애플리케이션.
1. SQL 애플리케이션용 Kinesis Data Analytics
- 데이터 소스: Kinesis Data Streams와 Kinesis Data Firehose에서 데이터를 읽어옵니다.
- 실시간 분석: SQL 쿼리를 사용하여 실시간 데이터를 분석할 수 있습니다.
- 참조 데이터: Amazon S3의 데이터를 참조하여 스트리밍 데이터와 조인할 수 있습니다.
- 출력 대상: 분석 결과를 Kinesis Data Streams, Kinesis Data Firehose, Amazon S3, Redshift, OpenSearch 등 다양한 대상에 전송할 수 있습니다.
- 완전 관리형 서비스: 서버 프로비저닝이 필요 없으며, 오토 스케일링을 통해 자동으로 리소스를 확장합니다.
- 비용: Kinesis Data Analytics에 전송된 데이터만큼 비용을 지불합니다.
- 사용 사례: 시계열 분석, 실시간 대시보드, 실시간 지표 등을 생성하는 데 적합합니다.
2. Apache Flink용 Kinesis Data Analytics
- 애플리케이션 작성: Java, Scala, SQL을 사용하여 스트리밍 데이터를 처리하는 Flink 애플리케이션을 작성합니다.
- 데이터 소스: Kinesis Data Streams나 Amazon MSK에서 데이터를 읽을 수 있습니다. Kinesis Data Firehose는 지원하지 않습니다.
- 강력한 쿼리 능력: Flink는 표준 SQL보다 강력한 쿼리 능력을 제공하여 고급 쿼리가 필요하거나, Kinesis Data Streams나 Amazon MSK와 같은 서비스를 통해 스트리밍 데이터를 처리하는 데 적합합니다.
- 자동 리소스 관리: 자동 프로비저닝, 병렬 연산 및 오토 스케일링을 지원하여 클러스터 리소스를 관리합니다.
- 체크포인트 및 스냅샷: 애플리케이션 백업 기능을 제공하며, Flink 프로그래밍 기능을 활용할 수 있습니다.
- 주요 제한 사항: Kinesis Data Firehose의 데이터를 읽을 수 없으며, 실시간 분석을 위해서는 SQL 애플리케이션용 Kinesis Data Analytics를 사용해야 합니다.
정리
- SQL 애플리케이션: 실시간 데이터 분석을 위해 SQL 쿼리를 사용하고, 다양한 데이터 소스로부터 데이터를 읽어 실시간으로 분석합니다.
- Apache Flink 애플리케이션: Java, Scala, SQL을 사용해 복잡한 스트리밍 분석을 수행하며, Kinesis Data Streams나 MSK에서 데이터를 읽습니다. 고급 쿼리 및 백엔드 애플리케이션 개발에 유용합니다.
MSK
MSK (Amazon Managed Streaming for Apache Kafka)
Amazon MSK는 AWS의 완전 관리형 Kafka 클러스터 서비스로, Kafka를 사용하여 실시간 데이터 스트리밍을 처리할 수 있습니다. 주요 특징과 Kinesis와의 비교는 다음과 같습니다.
특징
- 완전 관리형 서비스: MSK는 클러스터를 자동 생성, 업데이트, 삭제하며, 서버 프로비저닝이나 용량 관리를 필요로 하지 않습니다.
- 브로커 관리: Kafka 브로커 노드와 Zookeeper 브로커 노드를 생성 및 관리합니다.
- 고가용성: VPC 내에서 최대 3개의 다중 AZ로 클러스터를 배포하여 장애 복구 및 가용성을 보장합니다.
- 자동 복구: Kafka 장애를 자동으로 복구하는 기능을 제공합니다.
- 서버리스 옵션: MSK 서버리스를 사용할 수 있어, 리소스를 자동으로 프로비저닝하고 컴퓨팅 및 스토리지를 스케일링합니다.
- 데이터 저장: EBS 볼륨에 데이터를 저장할 수 있습니다.
- 장기 보관: 데이터를 1년 이상 보관할 수 있으며, EBS 스토리지 비용을 지불합니다.
MSK vs Kafka (차이점)
- 메시지 크기
- Kinesis Data Streams: 1MB의 메시지 크기 제한.
- Amazon MSK: 기본 1MB, 최대 10MB까지 설정 가능.
- 데이터 스트리밍 방식
- Kinesis Data Streams: 데이터를 샤드로 스트리밍합니다.
- Amazon MSK: 파티션을 이용한 Kafka 토픽으로 스트리밍합니다.
- 용량 확장
- Kinesis Data Streams: 샤드 분할 또는 샤드 병합으로 용량을 조정합니다.
샤드(Shard)의 정의
- 샤드는 데이터의 물리적 또는 논리적 파티션을 의미하며, 데이터를 여러 개의 독립적인 단위로 나누어 병렬로 처리할 수 있게 합니다.
- 샤드마다 독립적인 처리 리소스를 할당하며, 각 샤드는 데이터의 일부분만을 저장하거나 처리합니다.
- Amazon MSK: 파티션 추가로만 주제를 확장할 수 있으며, 파티션 제거는 불가능.
- Kinesis Data Streams: 샤드 분할 또는 샤드 병합으로 용량을 조정합니다.
- 전송 암호화
- Kinesis Data Streams: TLS 전송 중 암호화.
- Amazon MSK: 평문과 TLS 전송 중 암호화 모두 지원.
- 저장 데이터 암호화
- 두 클러스터 모두 저장 데이터 암호화 기능이 있습니다.
- 데이터 보존 기간
- Kinesis Data Streams: 기본적으로 90일 데이터 보존.
- Amazon MSK: 원한다면 1년 이상 데이터를 보관할 수 있습니다.
정리
- MSK는 Kafka 기반의 스트리밍 서비스로 완전 관리형이며, 서버리스 옵션도 제공. Kinesis Data Streams와 유사하지만, 파티션과 주제 확장 방식에서 차이를 보이며, 더 큰 메시지 크기와 장기 데이터 보관 옵션을 제공합니다.
- Kinesis는 샤드 기반의 스트리밍 방식이며, 실시간 분석과 저장된 데이터 암호화 등을 지원합니다.
6. AWS의 컨테이너
ECS (Elastic Container Service)
EC2 시작 유형
- AWS에서 컨테이너를 실행하면 ECS 클러스터에 이른바 ECS 태스크를 실행하는 것이다.
- ECS 클러스터에는 들어있는 게 있는데 EC2 시작 유형을 사용하면 EC2 인스턴스가 들어있는 것이다.
- EC2 시작 유형으로 EC2 클러스터를 사용할 때는 인프라를 직접 프로비저닝하고 유지해야 한다.
- 즉 Amazon ECS 및 ECS 클러스터가 여러 EC2 인스턴스로 구성된다.
- 이때 ECS 인스턴스는 특별하게 각각 ECS 에이전트(Agent)를 실행해야 한다.
- 그럼 ECS 에이전트가 각각의 EC2 인스턴스를 Amazon ECS 서비스와 지정된 ECS 클러스터에 등록한다.
- 이후에 ECS 태스크를 수행하기 시작하면 AWS가 컨테이너를 시작하거나 멈춘다.
- 즉 새 컨테이너가 생기면 미리 프로비저닝한 EC2 인스턴스에 지정된다.
- ECS 태스크를 시작하거나 멈추면 자동으로 위치가 지정된다.
Fargate 시작 유형
- Fargate 유형은 AWS에 컨테이너를 실행하는데 인프라를 프로비저닝 하지 않아 관리할 EC2 인스턴스가 없다.
- 서버를 관리하지 않아 서버리스라 부르는데 서버가 없는 건 아니다.
- Fargate 유형은 ECS 클러스터가 있을 때 ECS 태스크를 정의하는 태스크 정의만 생성하면 필요한 CPU나 RAM에 따라 ECS 태스크를 AWS가 대신 실행한다.
- 즉 새 도커 컨테이너를 실행하면 어디서 실행되는지 알리지 않고 그냥 실행된다.
- 작업을 위해 EC2 인스턴스가 생성, 관리할 필요도 없고, 확장하려면 간단하게 태스크 수만 늘리면 된다.
- 시험에서는 서버리스인 Fargate를 사용하라는 게 자주 나온다.
IAM Roles for ECS
EC2 Instance Profile
- EC2 시작 유형에서만 사용 가능하다.
- 먼저 EC2 인스턴스가 도커에 ECS 에이전트를 실행한다.
- EC2 시작 유형을 사용한다면 EC2 인스턴스 프로필을 생성한다.
- ECS 에이전트 만이 EC2 인스턴스 프로필을 사용하며 그 EC2 인스턴스 프로필을 이용해 API 호출 한다.
- 그럼 인스턴스가 저장된 ECS 서비스가 CloudWatch 로그에 API 호출을 해서 컨테이너 로그를 보내고 ECR로부터 도커 이미지를 가져온다.
- Secrets Manager나 SSM Parameter Store에서 민감한 데이터를 참고하기도 한다.
EC2 인스턴스 프로필(Instance Profile)은 AWS에서 EC2 인스턴스에 특정 IAM 역할(Role)을 부여하기 위한 메커니즘입니다. 이를 통해 인스턴스 내에서 실행 중인 애플리케이션이 AWS 서비스에 안전하게 접근할 수 있습니다. 주요 개념과 동작 방식을 정리하면 다음과 같습니다.
- IAM 역할(Role)
- IAM 역할은 특정 AWS 서비스에 대한 액세스 권한을 정의하는 엔터티로, EC2 인스턴스가 역할을 통해 서비스에 접근할 수 있습니다.
- 역할은 특정 정책을 통해 명시된 권한으로 구성됩니다.
- 인스턴스 프로필(Instance Profile):
- 인스턴스 프로필은 역할을 EC2 인스턴스에 부착하는 방법입니다.
- 하나의 인스턴스 프로필은 하나의 IAM 역할과 연결됩니다.
- 인스턴스 프로필은 EC2 인스턴스를 생성하거나 이미 존재하는 인스턴스에 역할을 연결할 때 사용됩니다.
- 사용 방법
- EC2 인스턴스를 생성할 때, 필요한 IAM 역할을 인스턴스 프로필로 지정하여 인스턴스와 연결할 수 있습니다.
- 이렇게 지정된 IAM 역할에 따라 인스턴스 내 애플리케이션이 다른 AWS 서비스(S3, DynamoDB 등)에 대한 액세스를 할 수 있습니다.
- 별도의 액세스 키와 시크릿 키를 코드에 포함시키지 않고 안전하게 AWS 리소스에 접근할 수 있게 해줍니다.
- 적용 사례
- EC2 인스턴스에서 실행되는 어플리케이션이 특정 S3 버킷에 파일을 읽거나 쓰는 경우, 적절한 권한을 가진 IAM 역할을 인스턴스 프로필로 지정하여 해당 권한을 위임할 수 있습니다.
- 애플리케이션이 DynamoDB 테이블에 데이터를 읽거나 쓸 때도 마찬가지로 해당 역할을 통해 안전하게 권한을 관리할 수 있습니다.
- 메타데이터 서비스
- EC2 인스턴스는 AWS의 인스턴스 메타데이터 서비스를 통해 할당된 IAM 역할의 임시 자격 증명을 자동으로 획득할 수 있습니다. 이러한 자격 증명을 통해 AWS SDK 또는 CLI를 사용할 때 자동으로 AWS에 접근할 수 있습니다.
이러한 역할과 인스턴스 프로필을 통해 EC2 인스턴스에서 실행되는 서비스가 안전하고 쉽게 다른 AWS 리소스에 접근할 수 있게 하여, 보안 문제를 최소화하고 관리의 복잡성을 줄일 수 있습니다.
EC2 Task Role
- ECS 태스크는 ECS 태스크 역할을 가진다.
- EC2와 Fargate 시작 유형에 모두 해당되며 두 개의 태스크가 있다면 각자의 특정 역할을 만들 수 있다.
- 역할을 다르게 하는 이유는 무엇일까? 역할이 각자 다른 ECS 서비스에 연결할 수 있기 위함이다.
- ECS 서비스의 태스크 정의에서 태스크의 역할을 정의한다.
로드 밸런서와 통합
- HTTP나 HTTPS 엔드 포인트로 태스크를 활용하기 위해 애플리케이션 로드 밸런서(ALB)를 앞에서 실행하면 모든 사용자가 ALB 및 백엔드의 ECS 태스크에 직접 연결된다.
- NLB는 처리량이 매우 많거나 높은 성능이 요구될 때만 권장한다. AWS Private Link와 사용할 때도 권장되는 옵션이다.
- ALB는 Fargate와도 사용 가능. CLB는 불가능.
Data Volumes
- EFS가 자주 사용된다.
- 네트워크 파일 시스템이라 EC2와 Fargate 시작 유형 모두 호환이 되며 EC2 태스크에 파일 시스템을 직접 마운트할 수 있다.
- 어느 AZ에 실행되는 태스크든 Amazon EFS에 연결되어 있다면 데이터를 공유할 수 있고 원한다면 파일 시스템을 통해 다른 태스크와 연결할 수 있다.
- Fargate로 서버리스 방식으로 ECS 태스크를 실행하고 파일 시스템 지속성을 위해서는 Amazon EFS를 사용하는 방식이 좋다.
- EFS 역시 서버리스이기 때문에 서버를 관리할 필요 없고 미리 비용을 지불한다. 미리 프로비저닝하기만 하면 바로 사용할 수 있다.
- 사용 사례로는 EFS와 ECS를 함께 사용해서 다중 AZ가 공유하는 컨테이너의 영구 스토리지가 있다.
- Amazon S3는 ECS 태스크에 파일 시스템으로 마운트될 수 없다.
- EBS는 특정 인스턴스에 연결되어, 고성능을 요구하는 단일 인스턴스의 저장소가 필요한 경우 적합합니다.
- EFS는 파일 저장 및 공유가 중요한, 다수 인스턴스에서 동시에 접근해야 하는 경우에 유리합니다.
ECR (Elastic Container Registry)
- AWS에 도커 이미지를 저장하고 관리하는 데 사용되며, ECR에는 두 가지 옵션이 있다.
- 첫 번째는 계정에 한 해 이미지를 비공개로 저장하는 건데 여러 계정으로 설정할 수도 있다.
- 혹은 퍼블릭 저장소를 사용해 Amazon ECR Public Gallery에 게시하는 방법이 있다.
- ECR은 Amazon ECS와 완전히 통합되어 있고 이미지는 백그라운드에서 Amazon S3에 저장된다.
- ECR 저장소에 여러 도커 이미지가 있는데 ECS 클러스터의 EC2 인스턴스에 이미지를 끌어오기 위해서는 EC2 인스턴스에 IAM 역할을 지정하면 된다.
- IAM 역할이 도커 이미지를 인스턴스에 끌어온다. ECR에 대한 모든 접근은 IAM이 보호하고 있다.
- ECR에 권한 에러가 생긴다면 정책을 살펴봐야 한다.
- EC2 인스턴스에 이미지를 끌어온 후에는 컨테이너가 시작된다.
- Amazon ECR은 단순히 저장하는 리포지토리에 그치지 않고 이미지의 취약점 스캐닝, 버저닝 태그 및 수명 주기 확인을 지원한다.
EKS (Elastic Kubernetes Service)
- AWS에 관리형 Kubernetes 클러스터를 실행할 수 있는 서비스다.
- EKS에는 두 가지 실행 모드가 있다.
- EC2 시작 모드는 EC2 인스턴스에서처럼 작업자 모드를 배포할 때 사용하고
- Fargate 모드는 EKS 클러스터에 서버리스 컨테이너를 배포할 때 사용한다.
- 클라우드 또는 컨테이너 간 마이그레이션을 실행하는 경우 Amazon EKS가 솔루션이 될 수 있다.
- EKS Node는 ASG(Auto Scaling Group)로 관리할 수 있다.
- EKS 서비스나 Kubernetes 서비스를 노출할 때는 프라이빗 로드 밸런서나 퍼블릭 로드 밸런서를 설정해 웹에 연결해야 한다.
EKS 노드 유형
-
관리형 노드 그룹은 AWS로 노드, 즉 EC2 인스턴스를 생성하고 관리한다.
- 노드는 EKS 서비스로 관리되는 오토 스케일링 그룹의 일부다.
- 온디맨드 인스턴스와 스팟 인스턴스를 지원한다.
-
자체 관리형 노드 그룹은 사용자 지정 사항이 많고 제어 대상이 많은 경우 직접 노드를 생성하고 EKS 클러스터에 등록한 다음 ASG의 일부로 관리해야 한다.
- 사전 빌드된 AMI인 Amazon EKS 최적화 AMI를 사용하면 시간을 절약할 수 있다.
- 자체 AMI를 빌드해도 되지만 복잡하다.
- 온디맨드 인스턴스와 스팟 인스턴스를 지원한다.
-
끝으로 노드를 원치 않는 경우에는 Amazon EKS가 지원하는 Fargate 모드를 선택하면 유지 관리도 필요 없고 노드를 관리하지 않아도 되며 Amazon EKS에서 컨테이너만 실행하면 된다.
-
Amazon EKS 클러스터에 데이터 볼륨을 연결하려면 EKS 클러스터에 스토리지 클래스 매니페스트를 지정해야 한다.
-
컨테이너 스토리지 인터페이스(CSI)라는 규격 드라이버를 활용하는데 시험에 나올 만한 키워드다.
-
Amazon EBS와 Fargate 모드가 작동하는 유일한 스토리지 클래스 유형인 Amazon EFS를 지원하고 Amazon FSx for Lustre와 Amazon FSx for NetApp ONTAP을 지원한다.
App Runner
- 이 서비스로는 누구나 AWS에 배포를 할 수 있다. 인프라나 컨테이너, 소스 코드 등을 알 필요가 없기 때문이다.
- 먼저 소스 코드나 Docker 컨테이너 이미지를 가지고 원하는 구성을 설정한다.
- vCPU의 수나 컨테이너 메모리의 크기 오토 스케일링 여부 상태 확인을 설정하면 된다.
- 웹 애플리케이션이나 API에 들어갈 기본 설정을 설정하는 것이다.
- 다음 작업은 자동으로 이뤄진다.
- App Runner 서비스가 웹 앱을 빌드하고 배포한다. 또는 컨테이너가 생성되고 배포된다.
- API나 웹 앱이 배포된 다음엔 URL을 통해 바로 액세스할 수 있다.
- 배후에서 AWS 서비스가 사용되는 것이겠지만 사용자는 굳이 몰라도 빠른 배포를 할 수 있다.
- 오토 스케일링이 가능하고 가용성이 높으며 로드 밸런싱 및 암호화 기능을 지원한다.
- 애플리케이션, 즉 컨테이너가 VPC에 액세스할 수도 있어서 데이터베이스와 캐시 메시지 대기열 서비스에 연결할 수 있다.
- 사용 사례로는 빨리 배포해야 하는 웹 앱, API 그리고 마이크로서비스가 있다.
- 신속한 프로덕션 배포가 필요할 때도 가장 좋은 방법은 AWS App Runner 서비스를 사용하는 것이다.
7. 고가용성, 스케일링(ELB, ASG)
고가용성
- 고가용성은 애플리케이션 또는 시스템을 적어도 둘 이상의 AZ나 데이터 센터에서 가동하는 것이다.
- 고가용성은 데이터 센터에서의 손실에서 살아남아야 한다.
- 즉, 가동중인 데이터센터에 문제가 생겨도 다른 데이터센터에서 정상적으로 돌아가야 한다.
- 동일한 애플리케이션의 동일한 인스턴스를 멀티AZ에서 가동해야 한다.
- 멀티AZ가 활성화된 오토 스케일링 그룹이나 로드밸런서에서도 사용한다.
- 고가용성은 수동적일 수도 있다(ex. RDS Multi AZ)
- 활성형도 존재한다.(수평 확장의 경우)
확장성
수직 확장성
- 수직 확장성은 인스턴스의 스펙을 확장한다. 시스템의 스펙을 향상시키는 것이다.
- 데이터베이스와 같이 분산되지 않은 시스템에서 주로 사용한다.
- 하드웨어 제한이 걸려있기 때문에 한계가 존재한다.
수평 확장성
- 수평 확장성은 애플리케이션에서 인스턴스의 수를 늘리는 방법이다.
- 현대 애플리케이션은 대부분 분배 시스템이므로 해당 방식이 적절하다.
- 요즘은 클라우드 제공 업체 덕분에 수평적으로 확장이 수월하다.
ELB(Elastic Load Balancer)
Load Balancing
- 로드밸런서는 다수의 서버에게 트래픽을 전달하는 서버이다.
- 사용자는 로드밸런서를 사용하므로 어떤 서버를 사용하고 있는지 구체적인 동작은 모른다.
Load Balaner
-
로드밸런서는 부하를 다수의 다운 스트림 인스턴스로 분산하기 위해서 사용한다.
-
애플리케이션에 단일 액세스 지점(DNS)를 노출하고 다운 스트림 인스턴스의 장애를 원활하게 처리할 수 있다.
마이크로서비스 아키텍처
- 업스트림 서비스: 사용자 요청을 처리하고 데이터를 가공한 후,
- 다운스트림 서비스: 가공된 데이터를 저장하거나 추가 처리를 수행.
ex)
- AWS 환경에서의 다운스트림 인스턴스
- 업스트림: API Gateway → Lambda Function.
- 다운스트림: Lambda → DynamoDB 또는 S3로 데이터 저장.
- CDN(Content Delivery Network)
- 웹 서버(업스트림) → CDN 서버(다운스트림).
- CDN 서버는 최종 사용자에게 콘텐츠를 전달.
- 로그 수집 시스템
- 업스트림: 로그 수집기(Fluentd).
- 다운스트림: 로그 저장소(Elasticsearch, S3).
-
헬스 체크 메커니즘을 사용해 인스턴스의 상태를 확인하고 요청을 보낸다.
-
SSL 종료도 가능하므로 HTTPS 트래픽을 받을 수 있다.
-
쿠키로 고정도를 강화할 수 있고 영역에 걸친 고가용성을 가지며 클라우드 내에서 개인 트래픽과 공공 트래픽을 분리할 수 있다.
ELB 소개
- ELB는 관리형 로드 밸런서다. AWS가 관리하는 서비스이며 어떤 경우에도 작동할 것을 보장한다.
- AWS가 업그레이드와 유지 관리 및 고가용성을 책임지며 로드 밸런서의 작동 방식을 수정할 수 있게 일부 구성 knobs도 제공한다.
- 자체 로드밸런서를 만드는 것보다 저렴하고 확장성 측면에서 유리하다.
- 로드밸런서는 다수의 aws 서비스랑 묶이는 EC2인스턴스, 스케일링 그룹, 아마존 EC2와 인증서 관리(ACM), 클라우드 워치, Rout53, AWS WAF, AWS Global Accelerator 등
- 헬스 체크는 ELB가 EC2에 동작이 올바르게 작동하고 있는지를 확인한다.
관리형 로드 밸런서 종류
로드밸런서 보안
- 유저는 http, https를 사용해 어디서든 로드밸런서에 접근이 가능하다.
- 로드밸런서도 보안그룹 규칙 적용 가능하다.
- 로드밸런서를 사용하는 이상적인 EC2의 인스턴스 보안은 오직 로드밸런서와 연결하는 것이다.
- 즉 EC2 인스턴스의 보안 그룹을 로드밸런서의 보안 그룹으로 연결하면 된다.
- 그러면 EC2 인스턴스는 로드밸런서에서 온 트래픽만을 허용한다.
- 로드밸런서의 다양한 리스너 규칙을 정의할 수 있다.
- 리다이렉트, path에 따른 응답 코드 정의
1. CLB(클래식 로드밸런서)
- CLB는 현재 거의 사용하지 않기에 생략한다.
2. ALB(애플리케이션 로드밸런서)
- HTTP, HTTPS, WEBSOCKET에 특화되어있다.
- OSI 7계층(응용)에서 동작한다.
- 즉 HTTP 전용 로드밸런서다.
- 로드밸런서의 라우팅 타겟 머신들은 타겟 그룹이라는 그룹으로 묶인다.
- 리스너 규칙을 정할 수 있다.
- PATH를 지정하면 라우팅을 지원한다.
- URL의 호스트 이름에 기반한 라우팅을 지원한다.
- 쿼리 문자열과 헤더에 기반한 라우팅을 지원한다.
- 컨테이너 기반 애플리케이션에 가장 좋은 로드밸런서이다.
- 포트 매핑 기능이 있어 ECS 인스턴스의 동적 포트로의 리다이렉션을 가능하게 해준다.
2-1 ALB의 Target Group
- EC2 인스턴스, ECS, 람다가 타겟 그룹이 될 수 있다.
- 타겟 그룹들은 오토스케일링 그룹에 의해 관리될 수 있다.
- ALB는 IP주소들의 앞에도 위치할 수 있다. 하지만 이때 꼭 사설IP주소여야 한다.
- ALB는 여러 타겟 그룹으로 라우팅할 수 있으며 상태 확인은 타겟 그룹 레벨에서 이뤄진다.
- 온프레미스 환경과 클라우드를 섞어서도 ALB를 사용할 수 있다.
- 해당 경우 에어 쿼리 문자열이나 매개변수 라우팅을 사용하면 된다.
- ALB를 사용하는 경우에도 CLB와 마찬가지로 고정 호스트 네임이 부여된다.
- 애플리케이션 서버는 클라이언트의 IP를 직접 보지 못하며 클라이언트의 실제 IP는 X-Forwarded-For라고 불리는 헤더에 삽입된다. X-Forwarded-Port를 사용하는 포트와 X-Forwarded-Proto에 의해 사용되는 프로토콜도 얻게된다.
3. NLB(네트워크 로드밸런서)
- TCP, TLS, Secure TCP, UDP에 특화되어있다.
- L4 로드 밸런서이기에 TCP, UDP 트래픽을 다룰 수 있다.
- 성능이 매우 뛰어나며 초당 수백만건의 요청을 처리 할 수 있다.
- ALB보다 지연 시간도 짧다. ALB는 400ms, NLB는 100ms
- NLB의 특징은 가용 영역 별로 하나의 고정 IP를 갖게 된다.
- 탄력적 IP 주소를 각 AZ에 할당 할 수 있다.
- 여러개의 고정 IP를 가진 애플리케이션을 노출할 때 유용하다. 탄력적 IP 사용 가능하다.
1~3개의 IP로만 액세스할 수 있는 애플리케이션을 설계하라는 문제는 NLB 고려!, TCP, UDP, 정적IP가 있어도 NLB 고려
3-1 NLB의 Target Group
- EC2 인스턴스들이 타겟 그룹이 될 수 있다.
- NLB가 TCP, UDP 트래픽을 EC2 인스턴스로 리다이렉트할 수 있다.
- IP 주소를 등록할 수 있는데 IP주소는 반드시 하드 코딩 되어야 하며 private IP만 가능하다.
- 자체 데이터 센터의 private IP도 사용할 수 있다.
- 온프레미스, 클라우드 둘 다 같은 네트워크 밸런서를 앞 단에 두고 사용할 수 있다.
- ALB 앞에 NLB를 사용할 수 있다.
- NLB 덕분에 고정 IP 주소를 얻을 수 있고 ALB를 이용해 HTTP 유형의 트래픽을 처리하는 규칙을 정의할 수 있다
- 네트워크 로드 밸런서 타겟 그룹이 수행하는 상태 확인이 중요하다.
4. GWLB(게이트웨이 로드밸런서)
- 6081 포트의 GENEVE 프로토콜을 사용한다.
- 다른 로드밸런서보다 낮은 수준에서 실행된다. 3계층에서 실행된다.
- IP 패킷의 네트워크 계층의 L3에서 동작한다.
- GWLB는 배포 및 확장과 AWS의 타사 네트워크 가상 어플라이언스의 플릿 관리에 사용된다.
- GWLB는 네트워크의 모든 트래픽이 방화벽을 통과하게 하거나 침입 탐지 및 방지 시스템에 사용한다.
- 그래서 IDPS나 심층 패킷 분석 시스템 또는 일부 페이로드를 수정할 수 있지만 네트워크 수준에서 가능하다.
- GWLB의 동작과정
- GWLB를 생성하면 VPC 내부에서 라우팅 테이블이 업데이트 된다.
- 라우팅 테이블이 수정되면, 먼저 모든 사용자 트래픽은 GWLB를 통과한다.그리고 GWLB는 가상 어플라이언스의 대상 그룹 전반으로 트래픽을 확산한다.그래서 모든 트래픽은 어플라이언스에 도달하고 어플라이언스는 트래픽을 분석하고 처리한다(방화벽, 침입탐지)
- 이상이 없으면 다시 GWLB로 보내고 이상이 있으면 트래픽을 드롭한다.
- GWLB를 통과하면 GWLB에서는 트래픽을 애플리케이션으로 보낸다.모든 트래픽이 GWLB를 통과해 타사 가상 어플라이언스를 통과해 애플리케이션으로 보내진다.
- GWLB 기능은 네트워크 트래픽을 분석하여 애플리케이션으로 진입시킬지 확인한다.
4-1 GWLB의 Target Group
- 타사 어플라이언스가 있다.
- EC2 인스턴스일 수도 있고 인스턴스 id로 등록하거나 ip 주소일 수도 있다. 이 경우는 private IP여야 한다
- 자체 네트워크나 자체 데이터 센터에서 이런 가상 어플라이언스를 실행하면 IP로 수동 등록할 수 있다.
ELB Sticky Session
- 고정 세션을 실행하는 것으로 로드 밸런서에 2가지 요청을 수행하는 클라이언트가 요청에 응답하기 위해 백엔드에 동일한 인스턴스를 갖는 것이다.
- 첫번째 클라이언트가 특정 인스턴스에 첫 요청을 보내면 두 번째 요청도 동일한 인스턴스로 이동해야 한다.
- 타겟 그룹에서 설정이 가능하다.
- 보통 고정 세션은 사용자의 로그인과 같은 중요한 정보를 취하는 세션 데이터를 잃지 않기 위해 사용자가 동일한 백엔드 인스턴스에 연결하기 위해 사용한다.
- 그러나 고정성을 활용하면 백엔드 ec2 인스턴스 부하에 불균형을 초래할 수 있다. 일부 인스턴스가 고정 사용자를 갖게 되기 때문이다.
- 고정 세션에는 애플리케이션 기반의 쿠키와, 기간 기반의 쿠키 2가지 유형이 있다.
애플리케이션 기반 쿠키
애플리케이션 기반의 쿠키는 애플리케이션에서 기간을 지정.
- 커스텀 쿠키
- 애플리케이션 기반의 쿠키는 대상으로 생성된 사용자 정의 쿠키로 애플리케이션에서 생성된다.
- 애플리케이션에 필요한 모든 사용자 정의 속상을 포함할 수 있다
- 쿠키 이름은 각 대상 그룹별로 개별적으로 지정하는데, 다음과 같은 이름은 사용하면 안된다.
- AWSALB, AWSALBAPP, AWSALBTG는 ELB에서 사용하기 때문이다.
- 애플리케이션 쿠키
- 애플리케이션 쿠키가 될 수도 있는데 지금은 로드밸런서 자체에서 생성된다.
- ALB의 쿠키 이름은 AWSALBAPP.
기간 기반 쿠키
- 로드 밸런서에서 생성되는 쿠키로 ALB에서는 AWSALB이다 CLB는 AWELB
- 특정 기간을 기반으로 만료되며 그 기간이 로드 밸런서 자체에서 생성된다.
ELB Cross Zone 로드밸런싱
- 교차 영역 로드밸런싱을 쓰면, 각각 로드 밸런서 인스턴스가 모든 가용 영역에 등록된 모든 인스턴스에 부하를 고르게 분배한다.
- ALB는 교차 영역 로드밸런성이 기본으로 활성화되어 있다. 데이터를 다른 가용 영역으로 옮기는데 비용이 들지 않는다.
- NLB와 GWLB는 기본으로 교차 영역 로드 밸런싱이 비활성화되어 있다. 따라서 활성화하면 비용을 내야한다.
ELB SSL TLS
- SSL 인증서는 클라이언트와 로드 밸런서 사이에서 트래픽이 이동하는 동안 암호화 해준다. 이를 전송중(in-flight) 암호화라고 한다.
- 데이터는 네트워크를 이동하는 동안 암호화되고, 송신자와 수신자측에서만 이를 복호화할 수 있다.
- 퍼블릭 SSL 인증서를 로드밸런서에 추가하면, 클라이언트와 로드 밸런서 사이의 연결을 암호화할 수 있다.
- 로드 밸런서는 X.509 인증서를 사용하는데, 이걸 SSL 또는 TLS 서버 인증서라고 부른다
- AWS에는 이 인증서들을 관리할 수 있는 ACM이란게 있다. AWS 인증서 관리자의 역할이다.
- 우리가 가진 인증서를 ACM에 업로드하여 사용할 수도 있다.
- HTTP 리스너를 구성할 때 반드시 HTTPS 리스너로 해야 한다.
- 기본 인증서를 지정해줘야 한다.
- 다중 도메인을 지원하기 위해 다른 인증서를 추가할 수 있다. 도메인별로 인증서를 사용할 수 있기 때문이다.
- 클라이언트는 SNI(서버 이름 지정)라는 걸 써서 접속할 호스트의 이름을 알릴 수 있다.
- 이렇게 SNI, 즉 서버 이름 지정을 써서 여러 개의 대상 그룹과 웹사이트를 지원할 수 있습니다, 다중 SSL 인증서를 사용해서요
- 우리가 원하는 대로 보안 정책을 지정할 수 있다. 구 버전의 SSL과 TLS, 즉 레거시 클라이언트를 지원할 수도 있다.
SNI
- Server Name Indication의 약어다.
- 여러개의 SSL 인증서를 하나의 웹 서버에 로드해 하나의 웹 서버가 여러 개의 웹사이트를 지원할 수 있게 해준다.
- 이것은 확장된 프로토콜로 최초 SSL 핸드세이크 단계에서 클라이언트가 대상 서버의 호스트 이름을 지정하도록 한다.
- 그러면 클라이언트가 접속할 웹사이트를 말했을 때, ALB는 어떤 인증서를 로드해야 하는지 알 수 있다.
- 이건 새롭게 확장된 프로토콜로 모든 클라이언트가 지원하지 않는다.
- 이 프로토콜은 ALB와 NLB 그리고 cloudFront에서만 동작한다.
- 어떤 로드밸런서에 SSL 인증서가 여러개 있다면 ALB나 NLB 둘중 하나다.
연결 드레이닝 (Connection Draining)
- CLB를 사용하면 연결 드레이닝이라고 부르고 ALB, NLB를 쓰면 등록 취소 지연이라고 부른다.
- 인스턴스가 등록 취소, 혹은 비정상인 상태에 있을 때 인스턴스에 어느 정도의 시간을 준다. 이를 드레이닝이라고 부른다.
- 즉 인스턴스가 드레이닝 되면 ELB는 등록 취소 중인 Ec2 인스턴스로 새로운 요청을 보내지 않는다.
- 연결 드레이닝 파라미터는 매개변수로 표시할 수 있다. 1부터 36000초 사이의 값을 설정 가능하다. 기본은 5분이다.
- 이 값을 0으로 설정하면 전부 다 비활성화 한다는 값이 0 이면 드레이닝도 일어나지 않는다
- 짧은 요청의 경우에는 낮은 값으로 설정하면 좋다.
- 예를 들어 1초보다 적은 아주 짧은 요청인 경우에는 연결드레이닝 파라미터를 30초 정도로 설정하면 된다.
- 그래야 EC2 인스턴스가 빠르게 드레이닝될 테고 그 후의 오프라인 상태가 되어 교체 등의 작업을 할 수 있다.
- 요청 시간이 매우 긴 업로드 또는 오래 지속되는 요청 등의 경우에는 어느 정도 높은 값으로 설정하면 된다.
- 그러면 EC2 인스턴스가 바로 사라지지 않음
- 연결 드레이닝 과정이 완료되기를 기다려야 한다.
ASG(Auto Scaling Group)
- ASG의 목표는 스케일 아웃, 즉 증가한 로드에 맞춰 EC2 인스턴스를 추가하거나 감소한 로드에 맞춰 EC2 인스턴스를 제거한다.
- ASG에서 실행되는 EC2 인스턴스의 최소 및 최대 개수를 보장하기 위해 매개변수를 전반적으로 정의할 수 있다.
- 로드밸런서와 페어링하는 경우 ASG에 속한 모든 EC2 인스턴스가 로드 밸런서에 연결된다.
- 한 인스턴스가 비정상이면 종료하고 이를 대체할 새 EC2 인스턴스르 생성할 수 있다.
- ASG는 무료이며 EC2 인스턴스와 같은, 생성된 하위 리소스에 대한 비용만 내면 된다.
- cloudwatch 경보를 기반으로 ASG를 스케일인, 스케일 아웃할 수 있다.
- 클라우드 워치에서 경보가 울리면 스케일 아웃이 발생한다. 경보에 의해 내부에서 자동으로 스케일링이 이루어질 수 있다.
- 경보를 기반으로 정책을 만들면 좋다.
AWS Auto Scaling Group(ASG) 조정 정책(Scaling Policies)
AWS Auto Scaling Group(ASG)에서 조정 정책(Scaling Policies)은 EC2 인스턴스의 수를 자동으로 조정하는 데 사용됩니다. Auto Scaling을 사용하면 애플리케이션의 수요 변화에 맞춰 인스턴스를 동적으로 추가하거나 제거할 수 있어 리소스를 효율적으로 관리하고 비용을 최적화할 수 있습니다.
이 조정 정책은 크게 동적 스케일링(Dynamic Scaling)과 예측 스케일링(Predictive Scaling)으로 나눌 수 있으며, 각각의 방식에 따라 설정할 수 있는 다양한 스케일링 정책이 존재합니다.
AWS Auto Scaling Group의 주요 스케일링 정책
- Simple Scaling Policy (단순 스케일링 정책)
- 동적 스케일링의 한 예로, 인스턴스를 한 번에 추가하거나 제거하는 단순한 방식입니다. 특정 조건을 충족할 때 Auto Scaling Group의 인스턴스 수를 지정한 수치만큼 증가시키거나 감소시킵니다.
- 동작 흐름: CloudWatch 경고가 발생하면 Auto Scaling Group이 인스턴스를 추가하거나 제거합니다. 설정된 쿨다운 시간 동안 추가적인 스케일링이 발생하지 않도록 합니다.
- 설정 예시: CPU 사용률이 80%를 초과하면 EC2 인스턴스를 1개 추가, CPU 사용률이 30% 이하로 떨어지면 EC2 인스턴스를 1개 제거
- Target Tracking Scaling Policy (목표 추적 스케일링 정책)
- 동적 스케일링을 기반으로 지속적으로 목표값을 유지하려는 방식으로 작동합니다. 예를 들어, CPU 사용률을 50%로 유지하는 것이 목표라면, Auto Scaling Group이 이를 자동으로 조정합니다.
- 동작 흐름: CloudWatch 경고가 발생하면, Auto Scaling Group은 지정된 목표값을 유지하려고 시도합니다. 목표 값에 도달하기 위해 인스턴스를 늘리거나 줄이는 작업이 지속적으로 이루어집니다.
- 설정 예시: 목표값을 CPU 사용률 50%로 설정하고, 이를 유지하려면 인스턴스를 추가하거나 제거합니다.
- Step Scaling Policy (단계적 스케일링 정책)
- 동적 스케일링의 또 다른 예로, 트리거된 경고의 강도에 따라 단계별로 EC2 인스턴스의 수를 조정하는 방식입니다. 예를 들어, CPU 사용률이 50% 이상이면 인스턴스를 1개 추가하고, 70% 이상이면 3개 추가하는 방식입니다.
- 동작 흐름: CloudWatch 경고가 발생하고, 경고의 수준에 따라 인스턴스를 추가하거나 제거합니다.
- 설정 예시: CPU 사용률이 50%일 때: 인스턴스를 1개 추가, CPU 사용률이 70%일 때: 인스턴스를 3개 추가
- Scheduled Scaling Policy (예약 스케일링 정책)
- 예측 스케일링에 가까운 방식으로, 예정된 시간에 스케일링을 수행하는 방식입니다. 특정 시간대나 일정을 기준으로 EC2 인스턴스를 미리 증가시키거나 감소시킬 수 있습니다.
- 동작 흐름: 특정 시간에 Auto Scaling Group이 트리거되어 설정된 대로 인스턴스의 수를 조정합니다. 주기적인 패턴을 설정하여 반복적으로 적용할 수 있습니다.
- 설정 예시: 매일 오전 9시에는 5개의 인스턴스를 실행하도록 설정, 매일 오후 6시에는 인스턴스 수를 2개로 줄이도록 설정
동적 스케일링(Dynamic Scaling)과 예측 스케일링(Predictive Scaling)의 차이점
- 동적 스케일링 (Dynamic Scaling)
- 실시간 트래픽 변화에 반응하여 EC2 인스턴스를 즉시 추가하거나 제거하는 방식입니다. CPU 사용률, 메모리 사용량, 네트워크 트래픽 등 실시간 모니터링 데이터를 기반으로 동작합니다.
- 특징: CloudWatch 경고에 기반해 설정된 임계값을 초과할 때 인스턴스를 동적으로 조정합니다. 예를 들어, CPU 사용률이 80%를 초과하면 1개의 인스턴스를 추가하는 방식입니다.
- 사용 상황: 트래픽 변화가 갑작스럽고 예측하기 어려운 경우에 유용합니다.
- 예측 스케일링 (Predictive Scaling)
- 과거 데이터를 기반으로 미래 수요를 예측하여 EC2 인스턴스를 미리 준비하는 방식입니다. 예측 가능한 부하 변화를 다루는데 유용합니다.
- 특징: 과거의 트래픽 패턴을 분석하여 예측된 시간에 맞춰 미리 인스턴스를 추가합니다. 예를 들어, 특정 시간대에 트래픽이 증가할 것으로 예상되는 경우, 그에 맞춰 인스턴스를 미리 준비합니다.
- 사용 상황: 예측 가능한 트래픽 패턴이 있는 경우, 예를 들어 온라인 쇼핑몰에서 특정 시간대나 시즌에 트래픽이 증가할 때 유용합니다.
스케일링 정책 설정 시 고려사항
- 쿨다운 시간(Cooldown Time)
- Auto Scaling Group이 스케일링 작업을 수행한 후, 추가적인 스케일링을 잠시 멈추는 시간입니다. 이는 과도한 스케일링을 방지하기 위해 필요하며, 쿨다운 시간이 너무 짧으면 불필요한 스케일링이 발생할 수 있습니다.
- CloudWatch 경고(Alarms)
- 스케일링 정책은 기본적으로 CloudWatch 경고를 기반으로 트리거됩니다. 알람을 정확히 설정하여 시스템 상태에 맞는 적절한 트리거 조건을 설정하는 것이 중요합니다.
- 스케일링 한도(Scaling Limits)
- Auto Scaling Group의 최소 및 최대 인스턴스 수를 설정하여 과도한 스케일링을 방지할 수 있습니다. 스케일링 한도를 설정하면 리소스 관리를 보다 효율적으로 할 수 있습니다.
종합적인 스케일링 전략
- Target Tracking Scaling은 소프트웨어 기반의 부하 변화에 적합합니다. 실시간 부하를 자동으로 조정하려면 이 정책을 사용하는 것이 좋습니다.
- Scheduled Scaling은 예측 가능한 부하에 적합합니다. 일정 시간대에 트래픽이 증가할 것으로 예상되는 경우에 유용합니다.
- Step Scaling은 다양한 조건에 따른 조정이 필요할 때 유용합니다. 예를 들어, 부하가 증가함에 따라 점진적으로 리소스를 추가할 수 있습니다.
AWS Auto Scaling Group의 조정 정책을 잘 활용하면 리소스를 효율적으로 관리하고, 트래픽 변화에 빠르게 대응할 수 있습니다. 동적 스케일링과 예측 스케일링을 결합하여 예기치 않은 변화와 예측 가능한 수요를 모두 관리할 수 있습니다.
8. AWS IAM (Identity and Access Management)
IAM
IAM란, Identity And Access Management의 약자이다.
- AWS 계정과 권한을 제어하고 사용자를 관리하는 기능을 제공하는 보안 서비스이다.
- AWS 리소스에 대한 액세스를 안전하게 제어할 수 있다.
- IAM은 글로벌 서비스에 해당한다.
- 처음 계정을 생성하면 루트 사용자가 배치되고 이를 기본으로 사용하게 되지만, 루트 계정은 사용자(계정)을 생성할 때만 사용하고 루트 계정을 직접적으로 사용하게 둬서는 안된다.
그룹, 사용자
- IAM 서비스로 사용자를 생성할 수 있다.
- 여러 사용자들을 그룹으로 묶을 수 있으며, 그룹에 포함되지 않는 사용자도 존재할 수 있다.
- 한명의 사용자는 여러 그룹에 포함 될 수 있다.
- 다만, 그룹은 그룹에 포함될 수 없다.
- 이렇게 IAM 서비스를 이용해 사용자와 그룹을 생성하는 이유는 사용자, 그룹에 모든 권한을 허용하지 않으면서 보안 문제를 예방하기 위함이다.
- 즉, 최소 권한 원칙을 지키기 위해서다.
- 사용자와 그룹에게는 반드시 필요한 권한만 부여하는 것이다.
IAM 정책
- IAM 글로벌 서비스를 이용해서 사용자와 그룹을 생성할 수 있다.
- 그룹에 속하지 않은 특정 사용자에게는 inline 정책을 부여할 수 있다
- iam 정책 구조
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "iam:GenerateCredentialReport", "iam:GenerateServiceLastAccessedDetails", "iam:Get*", "iam:List*", "iam:SimulateCustomPolicy", "iam:SimulatePrincipalPolicy" ], "Resource": "*" } ] } - Version: 정책 언어 버전
- Statements: 정책 구성 요소의 컨테이너
- Sid(Optional): 선택 설명문 ID를 포함하여 설명문들을 구분한다.
- Effect: 특정 api에 접근하는 것을 허용할 것인지 거부할 것인지를 정할 수 있다.
- Principal(특정 상황에서 필요): 계정, 사용자, 권한 등 어느 정책에 적용할 것인지를 정할 수 있다.
- Action: Effect에 기반하여 허용 및 거부되는 API 호출 목록이다.
- Resource: 적용될 Action의 리소스 목록
- Condition: Statement가 언제 적용될지를 결정하는 조건
MFA
사용자 정보 방어 메커니즘이고 크게 2가지가 있다.
1. 비밀번호 정책 정의
- AWS에서는 다양한 옵션을 이용해 비밀번호 정책 생성 가능
- 비밀번호 최소 길이 설정 가능
- 특정 유형의 글자 사용을 요구할 수 있다
- ex) 대/소문자, 숫자, 물음표와 같은 특수 문자
- IAM 사용자들의 비밀번호 변경을 허용 또는 금지 가능
- 일정 기간이 지나면 비밀번호 만료 시킬 수 있음
- 비밀번호 변경 시 이전 비밀번호를 사용하지 못하게 할 수 있음
2. MFA(Multi Factor Authentication)
- AWS에서는 MFA 메커니즘을 필수적으로 사용하도록 권장
- MFA란, 비밀번호와 보안 장치를 함께 사용하는 것
- 비밀번호가 누출되어도, 휴대전화와 같은 물리적 장치가 필요하기에 계정 침해의 가능성이 낮아짐
- AWS에서의 MFA 장치 옵션
- Virtual MFA device(가상 MFA)
- Authy는 하나의 장치에서 여러개의 토큰을 지원한다.
- 루트 계정, IAM 사용자 또 다른 계정, 그리고 또 다른 IAM 사용자가 지원되는 식
- Universal 2nd Factor Security Key(U2F 보안 키)
- 이는 물리적 장치
- 하나의 키에 여러 루트 계정, IAM 사용자 지원이 가능하기에 1개의 키로 충분하다
- Virtual MFA device(가상 MFA)
AWS 접근 방법
AWS 서비스에 접근할 수 있는 방법은 크게 3가지가 있다.
1. Password + MFA
- AWS 관리 콘솔에 접근하는 것이다.(웹)
2. AWS CLI 사용
- 액세스 키로 보호되며 액세스키, 시크릿 키를 사용하여 터미널에서 aws 서비스에 접근이 가능하다.
3. AWS SDK
- 코드에서 API를 호출할 때 사용하며 코드를 통해 접근할 수 있다.
AM Security Tools
1. IAM Credentials Report (access-level)
- 자격 증명 보고서 생성 - 계정 수준에서 가능
- 보고서에는 모든 계정의 사용자와 다양한 자격 증명 상태를 포함한다.
- 보안 인증 보고서에는 이 계정의 모든 IAM 사용자와 해당 사용자의 다양한 보안 인증 상태를 확인할 수 있다.
- 보고서가 생성되면 최대 4시간 동안 저장된다.
2. IAM Access Advisor(user-level)
- 액세스 관리자 - 사용자 수준에서 가능
- 사용자에게 부여된 서비스 권한과 해당 서비스에 마지막으로 액세스한 시간이 보인다.
- 사용자의 권한을 파악하여 최소 권한 원칙을 준수할 수 있다.
- 해당 도구를 통해 어떠한 권한이 사용되지 않는지 확인할 수 있다.
- 최소 권한 원칙을 준수할 수 있다.
- 사용자에서 액세스 관리자로 들어가기에 최근 4시간의 활동내역을 확인해볼 수 있다.
IAM Guidelines & Best Practices
Guidelines
- 루트 계정은 AWS 계정을 설정할 때를 제외하고 사용하지 않기
- 하나의 AWS 사용자는 한 명의 실제 사용자를 의미
- 제 3자에게 계정을 부여할때는 유저 그룹에 할당하고 그룹에 권한을 부여해야한다.
- 강력한 비밀번호 설정을 권장한다.
- MFA(Multi Factor Authentication)을 사용한다면 더욱 계정을 지킬 수 있다.
- AWS 서비스에 권한을 주기 위해서는 역할을 만들고 사용해야 한다.
- 가상 서버인 EC2 인스턴스, Lambda를 포함해서
- CLI or SDK를 사용하기 위해서는 반드시 액세스 키를 만들어야 한다.
- 계정의 권한을 감시하기 위해서는 IAM 자격 증명 보고서와 IAM 액세스 분석기를 사용할 수 있다.
- IAM 액세스키는 절대 공유하는 것이 아니다.
Best Practices
- 실제 사용자마다 Users에 매핑하는 것이다.
- 사용자를 그룹에 두는 것이다.
- 사용자나 그룹에 권한을 부여하는 것이다.
- 역할을 사용한다.
- EC2 인스턴스를 생성하거나 AWS 서비스가 다른 AWS 서비스에 무언가를 하게 하는 어떤 권한을 주려고 할 때 IAM 역할을 만들어야 한다.
- MFA를 이용해 두번째 창지로 사용하고 강력한 비밀번호 정책을 가져야 한다.
- CLI 혹은 SDK를 이용해 AWS를 사용하고자 한다면 반드시 액세스키를 만들어야 한다.
9.AWS VPC와 네트워크
VPC란
- 가상 프라이빗 클라우드(VPC)는 퍼블릭 클라우드 내에서 호스팅되는 안전하고 격리된 프라이빗 클라우드이다.
- VPC가 없다면 AWS Cloud 안의 리소스들을 연결하기 위해 많은 작업들이 생길 것이고 시스템의 복잡도는 높아질 것이다.
- 하지만, VPC를 이용하면 위 이미지와 같이 리소스들을 쉽게 관리할 수 있을 것이다.
- 이렇게 대부분의 AWS 서비스들은 VPC에 의존적이기 때문에 VPC에 대한 이해는 중요한 요소 중 하나이다.
네트워크 선수 지식
- 사용자가 AWS VPC에 서브넷 생성, 라우팅 테이블 구성 등 네트워킹 환경을 원하는 대로 제어 및 구성하려면 아래의 선수 지식들이 필수이다.
- IP 클래스, 서브넷, 서브넷팅, 네브넷 마스크
- CIDR
IP 주소
IP 주소란
- IP는 네트워크 장비 식별을 위해 개별 장비에 부여되는 고유 주소이다.
- 일반적으로
192.168.0.1과 같이 마침표로 구분된 4개의 10진수로 표기하고 이를 2진수로 변환하면 32비트의11000000.10101000.00000000.00000001와 같이 표현할 수 있다. - IP 주소는 총 32비트로 구성되어 있으며 (8bit = 1byte = 1옥텟)을 10진수로 표기하고 2^32이므로 약 43억 개의 주소를 가진다.
IP 주소의 구성
- IP 주소는 네트워크 ID와 호스트 ID로 구성되어 있다.
- 네트워크ID는 다른 네트워크와 구분하는 역할을 하게된다.
- 호스트ID는 해당 네트워크의 어느 호스트인지를 나타내어 다른 호스트와 구분하는 역할을 한다.
IP 주소 클래스
- IP클래스는 IP주소를 효율적으로 나누어 놓은 범위이고 예전에 IP를 할당하는 방식이었다.
- 하지만 지금은 더 이상 사용되지 않고 CIDR 방식으로 할당되도록 바뀌었다.
- 위에서 말했듯이 8bit는 1옥텟이며 32비트는 4개의 옥텟으로 나눌 수 있다. 각 옥텟은 0부터 255까지의 범위를 가지어 총 256개의 값을 표현할 수 있다.
A 클래스
- A 클래스의 경우 처음 8비트가 네트워크 ID이며, 나머지 24비트가 호스트 ID로 사용된다.
- A 클래스의 첫번째 옥텟의 비트는 0으로 고정되어 있다.
- 따라서 A 클래스의 첫 옥텟이 1 ~ 126 사이의 숫자로 시작한다.
- 00000000(2) ~ 01111111(2)
- 호스트 ID는 24비트로 구성되어 있으므로 네트워크 당 나올 수 있는 호스트 개수는 1670만개 이므로 대규모 네트워크에 적합하다.
IP 주소에서 첫 옥텟이 0과 127로 시작할 수 없는 이유는 예약되어 있는 주소가 존재하기 때문이다.
0.0.0.0 : 미지정 주소
127.0.0.0 : 루프백 주소
B 클래스
- B 클래스의 경우 처음 16비트가 네트워크 ID이며, 나머지 16비트가 호스트 ID로 사용된다.
- B 클래스의 첫 번째 옥텟의 두개의 비트가 10으로 고정 있다.
- 따라서 B 클래스의 첫 옥텟이 128 ~ 191 사이의 숫자로 시작한다.
- 10000000(2) ~ 10111111(2)
- 호스트 ID는 16비트로 구성되어 있으므르 네트워크 당 나올 수 있는 호스트 개수는 65000개 이므로 중규모 네트워크에 적합하다.
C 클래스
- C 클래스의 경우 처음 24비트가 네트워크 ID이며, 나머지 8비트가 호스트 ID로 사용된다.
- B 클래스의 첫 번째 옥텟의 세개의 비트가 110으로 고정 있다.
- 따라서 B 클래스의 첫 옥텟이 192 ~ 223 사이의 숫자로 시작한다.
- 11000000(2) ~ 11011111(2)
- 호스트 ID는 8비트로 구성되어 있으므르 네트워크 당 나올 수 있는 호스트 개수는 256개 이므로 소규모 네트워크에 적합하다.
D 클래스
- D 클래스의 첫 번째 옥텟의 네개의 비트가 1110으로 고정 있다.
- 따라서 D 클래스의 첫 옥텟이 224 ~ 239 사이의 숫자로 시작한다.
- 11100000(2) ~ 11101111(2)
- 멀티캐스트용 대역으로 IP주소 할당에 사용되지 않는다.
E 클래스
- E 클래스의 첫 번째 옥텟의 네개의 비트가 1111으로 고정 있다.
- 따라서 D 클래스의 첫 옥텟이 240 ~ 255 사이의 숫자로 시작한다.
- 11110000(2) ~ 11111111(2)
- 연구용 예약된 주소 대역으로 IP주소 할당에 사용되지 않는다.
네트워크 주소와 브로그 캐스트 주소
- 하나의 네트워크에서 사용할 수 있는 IP 주소에서 사용할 수 없는 주소가 2가지 존재한다.
- IP 주소의 맨 첫 번째 주소와 맨 마지막 주소는 호스트 주소로 사용할 수 없다.
- 예를 들어
192.168.100네트워크가 있다면 첫 번째 IP 주소인192.168.100.0과 마지막 주소인192.168.100.255는 사용할 수 없다.
- 예를 들어
- 이유는 사회적으로 첫 번째는 네트워크 그 자체의 주소, 마지막은 브로드캐스트를 위한 주소이기 때문이다.
- 네트워크 주소는 말 그대로 네트워크 자체를 나타내는 것이고, 브로드 캐스트 주소는 인터넷 데이터를 전달하기 위한 주소로서 모든 네트워크 아이피 클래스에 동일하게 적용되는 것이다.
- IP 주소의 맨 첫 번째 주소와 맨 마지막 주소는 호스트 주소로 사용할 수 없다.
서브넷과 서브네팅 그리고 서브넷 마스크
서브넷
-
IPv4는 초기에 부족한 아이피 주소 문제를 해결하기 위해 IP 클래스로 효율적으로 나눠 할당하는 방법을 택하였다.
- 하지만, 해당 방법은 비효율적이었다.
- 예를 들어 B 클래스 를 소규모 회사에게 할당하였을 경우 B 클래스 호스트 주소의 개수인 65,000개의 아이피를 다 활용하지 못하고 10,000개의 아이피만 사용한다고 가정했을 때, 나머지 55,000개의 IP는 쓰지 않은 채 회사는 클래스 B의 하나를 점유하고 있는 상태가 되어버린다.
- 그렇다고 C 클래스 IP를 할당하자니 IP 자원이 부족한 상태가 되어버린다.
- 이렇게 IP를 클래스 별로 나누어 놓았지만 낭비가 발생하게 되었다.
- 문제를 해결하고자 IP를 네트워크 장치 수에 따라 효율적으로 사용할 수 있는 서브넷 개념이 등장하였다.
-
서브넷이란
- 하나의 네트워크가 분할되어 나눠진 작은 네트워크
- 서브넷을 만들기 위해 네트워크를 분할하는 것을 서브네팅이라고 한다.
- 이 서브네팅을 서브넷 마스크를 통해 계산된다.
서브네팅
- 서브네팅은 IP 주소를 효율적으로 나누어 네트워크에 할당하는 방법을 말한다.
- 위 그림을 보면192.168.10.0/24 의 C 클래스 네트워크 주소를 사용한다고 했을때, 256개의 Host ID 개수를 잘게 나눠 128,128
- 이를 한 번 더 나눠 64, 64, 64, 64 개의 Host ID를 나눴다면 나누어진 64개를 특정 네트워크에게 할당해주는 것을 서브네팅의 예시다.
- 2등분을 하기 위해서 호스트 ID의 가장 왼쪽 비트를 서브넷 구분 비트로 지정하여야한다.
- 가장 왼쪽 비트 1개를 서브넷 구분 비트로 설정하였기에 두개의 영역으로 나눠질 수 있다. (서브넷 구분 비트가 달라지면 나눌 수 있는 영역도 달라진다)
00000000 ~ 0111111 (0 ~ 127)10000000 ~ 1111111 (128 ~ 255)
- 가장 왼쪽 비트 1개를 서브넷 구분 비트로 설정하였기에 두개의 영역으로 나눠질 수 있다. (서브넷 구분 비트가 달라지면 나눌 수 있는 영역도 달라진다)
- 이렇게 나눈 서브넷 부분을 회사의 네트워크에 할당하면 됩니다.
- 하지만, 앞서 설명했듯이 네트워크 주소와 브로드캐스트 주소를 제외한 범위만 가능하다.
서브넷 마스크
- 서브넷 마스크는 IP주소에서 네트워크 ID와 호스트 ID로 어느 클래스 주소인지 구분하기 위한 목적으로 만들어졌다.
- IP주소마다 해당 주소의 범위를 보고 어느 클래스인지 판별할 수 있지만, 더 쉽게 구분하기 위해 서브넷 마스크를 사용한다고 생각하면 된다.
- 서브넷 마스크는 IP주소와 다르게 연속된 1과 연속된 0으로 구성되어 있다는 것이다.
- ex)
1111 1111 . 1111 1111 . 1111 1111 . 0000 0000→255.255.255.0(서브넷 마스크)
- ex)
AWS VPC 구성도
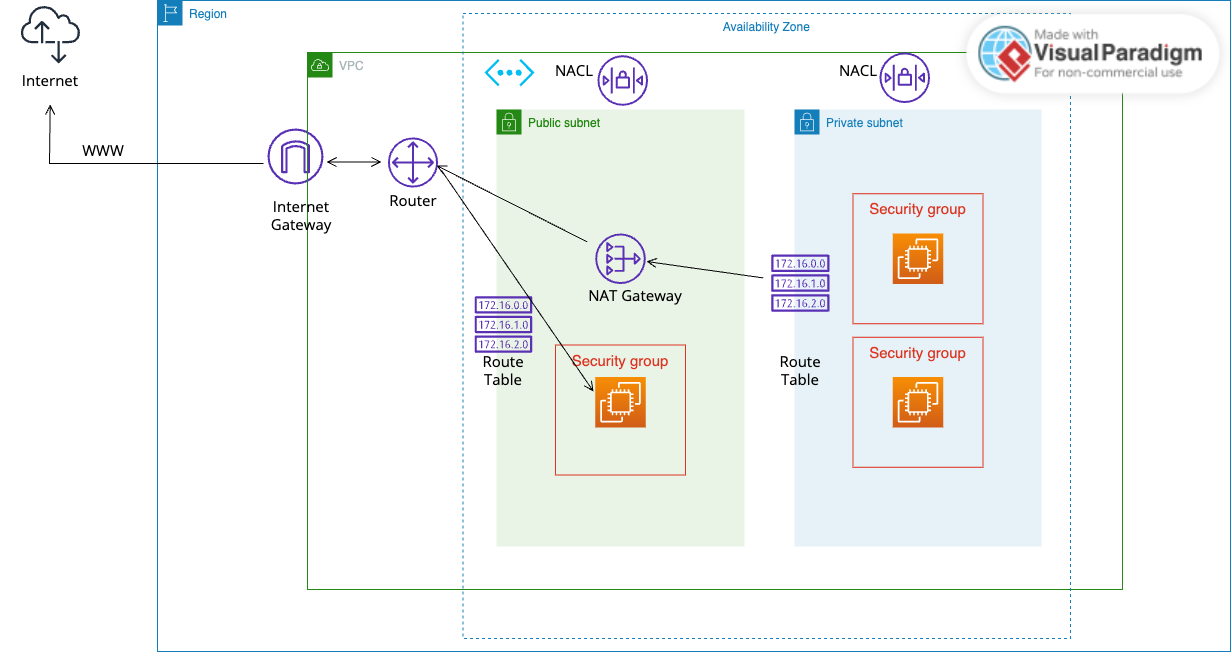
VPC
- AWS VPC를 구성하기 위해서는 VPC의 IP 범위를 REC1918이라는 사설 IP 대역에 맞춰서 설계해야 한다.
- VPC는 각 Region에 종속되어야 하며 한 Region에 여러개의 VPC를 생성할 경우 서로 아이피는 겹쳐서는 안된다. DNS IP를 잡지 못하는 에러가 발생하기 때문이다.
- VPC내에서 한 번 설정된 IP 대역은 수정할 수 없다.
AWS 서브넷 구성
- VPC를 생성하였다면 서브넷을 생성하여야 한다.
- 서브넷은 VPC 내부에 있는 IPv4 주소의 부분 범위이다. 즉, VPC를 더 작은 네트워크 단위로 세분화하는 것이다.
- 각 서브넷은 특정 AZ에 위치해야 하며 여러 AZ에 걸쳐서 서브넷을 생성할 수 없다. 그리고 AWS가 각 서브넷의 IP 주소 5개를 예약하여 사용하고 있다.
- 그렇기에 아래 예약된 주소를 고려하여 적절한 IPv4 CIDR Block을 생성해야 한다.
10.0.0.0: 네트워크 주소10.0.0.1: VPC 라우터를 위해 예약된 주소10.0.0.2: Amazon에서 제공된 DNS에 매핑되기 위해 예약된 주소10.0.0.3: 당장 사용하지는 않지만 미래에 사용될 수도 있기에 예약된 주소10.0.0.255: 네트워크 브로드캐스트 주소 하지만 AWS는 VPC에서 브로드캐스트를 지원하지 않기에 예약은 되지만 사용하는건 안된다.
서브넷 구분
Public Subnet
- 외부에서 접근이 가능한 네트워크영역이다.
- 서브넷이 인터넷 게이트웨이로 향하는 라우팅이 있는 라우팅 테이블과 연결되어 있는 경우 퍼블릭 서브넷이라고 한다.
- 해당 서브넷은 인터넷과 연결이 가능하므로 퍼블릭 서브넷에 위치한 AWS 리소스들은 공인IP를 가질 수 있다.
Private Subnet
- 외부에서 다이렉트로 접근이 불가능한 네트워크 영역이다. 즉, 인터넷과 연결되지 않은 서브넷이라고 생각하면 된다.
- 하지만, 특정 리소스가 인터넷 연결이 필요할 수 있다. 이럴 경우 NAT 게이트웨이를 이용하여 내부에서 외부로 접근이 가능하게 만들어준다.
- 또한, 같은 vpc 영역에 있으면 private subnet으로 접근이 가능하다.
- 이로써 엄격하게 다뤄야 하는 리소스들을 안전하게 관리할 수 있다.
네트워크 ACL과 보안그룹
- 네트워크 ACL(Network Access Control List)와 보안그룹(Security Group)은 VPC 내에서 인바운드, 아웃바운드 트래픽에 대한 보안 정책을 설정하고 관리합니다.
- NACL과 Securiy Group은 비슷하지만 다른 차이점을 갖고 있다.
네트워크 ACL
- NACL은 상태 비저장(Stateless) 방식으로 동작하여 인바운드와 아웃바운드 규칙을 독립적으로 처리한다.
- 즉, 특정 트래픽이 인바운드 규칙에 허용되어 진입하더라도 상태 비저장 특성 때문에(기억하지 않음) 아웃바운드 규칙에 의해 허용된 트래픽이 거절될 수도 있다는 것이다.
- 모든 트래픽이 기본적으로 허용되는 것이 아니기에 명시적으로 트래픽을 제한하거나 허용하는 규칙을 설정해야 한다.
- NACL은 서브넷 단위로 적용되며 각 서브넷마다 하나의 NACL이 할당된다.
- 새로운 서브넷을 생성하게되면 기본 NACL로 설정되며 모든 트래픽을 허용하는 설정을 가지고 있다.
- NACL에는 규칙 정의가 있다. 규칙에는 숫자가 있고 1~32766까지 정의할 수 있다. 숫자가 높을 수록 우선순위가 높다. ALLOW, DENY를 구성할 수 있다.
보안 그룹
- 보안 그룹(Security Group)은 상태 유지(Stateful) 방식으로 동작하기에 트래픽이 허용되면 반환 트래픽도 자동으로 허용된다.
- 즉, 특정 트래픽이 인바운드 규칙에 허용되어 진입한다면 상태 저장 특성 때문에(기억하고 있음) 아웃바운드 규칙과 상관없이 아웃바운드를 통과하게 된다.
- 보안 그룹은 트래픽의 거부 규칙을 지원하지 않는다.
네트워크 ACL과 보안 그룹 차이점
- NACL은 상태 비저장, 보안그룹은 상태 저장 특성을 가진다.
- 보안 그룹은 인스턴스 수준에서 동작하지만 NACL은 서브넷 수준에서 동작한다.
- 보안 그룹은 허용 규칙을 지원하지만 NACL은 허용, 거부 2가지 규칙을 모두 지원한다.
- NACL에서는 특정 IP를 거부할 수 있다.
- 보안 그룹에서는 모든 규칙이 평가되고 트래픽 허용 여부를 결정하지만, NACL에서는 가장 높은 우선순위를 가진 것이 먼저 평가된다.
- 보안 그룹은 할당된 EC2 인스턴스에 지정되지만 NACL은 연결된 서브넷의 모든 EC2 인스턴스에 적용된다.
인터넷 게이트웨이
- 인터넷 게이트웨이는 VPC와 인터넷 사이에 통신을 가능하게 하는 고가용성 VPC 컴포넌트이다.
- 수평 확장되고 가용성이 높은 중복 VPC 구성 요소로 VPC의 인스턴스와 인터넷 간에 통신할 수 있게 해준다.
- 따라서 네트워크 트래픽에 가용성 위험이나 대역폭 제약 조건이 발생하지 않는다.
- 인터넷 게이트웨이는 2가지 용도로 제공된다.
- 인터넷 트래픽 라우팅
- NAT 수행
인터넷 게이트웨이는 2가지 용도
1. 인터넷 트래픽 라우팅
- 인터넷 게이트웨이는 VPC의 라우팅 테이블에서 인터넷으로의 트래픽을 전송할 수 있는 대상 역할을 한다.
- 예를 들어 퍼블릭 서브넷의 트래픽이 인터넷으로 나가야 하는 경우, 해당 서브넷의 라우팅 테이블에 "인터넷 게이트웨이를 통해 모든 트래픽(0.0.0.0/0)을 인터넷으로 보낸다" 라는 규칙을 할당하면 된다.
- 퍼블릭 서브넷의 라우팅 테이블에 아래와 같은 규칙이 있으면 된다.
- Range: 0.0.0.0/0 (모든 IPv4 주소)
- target: igw-xxxxxx(인터넷 게이트웨이 ID)
2. NAT 수행
- 인터넷 게이트웨이는 VPC 내의 퍼블릭 IPv4 주소를 가진 인스턴스가 인터넷과 통신할 수 있도록 네트워크 주소 변환(NAT)를 수행한다.
- 퍼블릭 IPv4 주소를 가진 인스턴스의 네트워크 주소 변환을 관리하여 프라이빗 IP와 퍼블릭 IP 간의 트래픽을 올바르게 라우팅해준다.
NAT Gateway
- NAT 게이트웨이는 프라이빗 서브넷 내 리소스가 인터넷과 통신할 수 있도록 하는 AWS 관리형 서비스이다.
- 위와 같은 특징 덕분에 프라이빗 서브넷의 인스턴스는 인터넷을 통해 외부 서비스를 호출하거나 데이터 업데이트, 다운로드를 할 수 있지만, 외부에서는 직접 접속할 수는 없다.
- 이를 통해 보안을 높일 수 있다.
- 프라이빗 서브넷내의 리소스가 외부 인터넷에 접근하는 과정은 다음과 같다.
- NAT 게이트웨이를 생성 시 퍼블릭 서브넷과 연결해야 하며, 탄력적 IP(EIP) 주소를 할당받는다.
- EC2 인스턴스가 프라이빗 IP 주소를 통해 라우터에 데이터를 전송한다.
- 프라이빗 라우팅 테이블을 참고하여 NAT 게이트웨이로 향한다. (프라이빗 서브넷의 트래픽을 NAT 게이트웨이로 향하도록 라우팅 테이블 설정)
- NAT 게이트웨이는 프라이빗 IP 주소를 퍼블릭 IP 주소로 변환하여 인터넷 게이트웨이를 거친 후 외부 인터넷으로 데이터를 전송한다.
- 사용자는 NAT 게이트웨이에서 변환된 퍼블릭 IP 주소로 전달받는다.
정리
- 추가 기능
- VPC 피어링: 서로 다른 VPC 간의 네트워크 트래픽을 연결해주는 기능.
- Bastion 서버: 외부에서 프라이빗 서브넷에 안전하게 접속할 수 있도록 해주는 점프 서버.
- VPC 엔드포인트: 퍼블릭 인터넷을 경유하지 않고도 프라이빗 서브넷에서 AWS 서비스에 직접 접근할 수 있도록 해주는 구성 요소. 인터페이스(Interface) 엔드포인트와 게이트웨이(Gateway) 엔드포인트로 나뉩니다.
ENI(Elastic Network Interfaces)
- ENI란, Elastic Network Interfaces의 약자이며 VPC의 논리적 구성 요소이고 가상 네트워크 카드를 나타낸다.
ENI 특징
- ENI는 EC2 인스턴스가 네트워크에 액세스할 수 있게 해준다.
- EC2 인스턴스와 독립적으로 생성하고 연결할 수 있다.
- 장애 조치를 위해 EC2 인스턴스에서 이동시킬 수 있음
- 두 개의 EC2 인스턴스에서 동일한 하나의 애플리케이션을 가동중일 때, 사설 네트워크를 두 인스턴스 사이에서 자유롭게 이동시켜 오류 조치를 쉽게 수행할 수 있다.
- 특정 AZ에서 ENI를 생성하면 해당 AZ에서만 할당할 수 있다.
ENI가 가질 수 있는 속성
- 주요 Private IPv4와 여러 보조 Private IPv4
- Private IPv4당 Elastic IPv4
- 하나의 Public IPv4
- 하나 이상의 시큐리티 그룹
- MAC Address
10. AWS Route 53
Route 53
- 고가용성, 확장성을 갖춘, 완전히 관리되며 권한있는 DNS다.
- 권한이 있다라는 뜻은 고객인 우리가 DNS 레코드를 업데이트 할 수 있다는 의미다.
- 즉, DNS에 대해 완전히 제어할 수 있다.
- Route 53 역시 도메인 이름 레지스트라로 도메인 이름을 등록할 수 있다.
- Route 53의 리소스 관련 상태 확인을 확인할 수 있다.
- 100% SLA 가용성을 제공하는 유일한 AWS 서비스입니다
- Route 53에서 여러 DNS 레코드를 정의하고 레코드를 통해 특정 도메인으로 라우팅하는 방법을 정의한다.
레코드가 갖고 있는 속성
- 도메인/서브도메인 이름
- 레코드 타입
- A: 호스트 이름과 IPv4 IP를 매핑
- AAAA: 호스트 이름과 IPv6 매핑
- CNAME: 호스트 이름을 다른 호스트 이름과 매핑
- 대상 호스트 이름은 A나 AAAA 레코드가 될 수 있다.
- Route 53에서 DNS 이름 공간 또는 Zone Apex의 상위 노드에 대한 CNAMES를 생성할 수 없다.
- ex) example.com에 CNAME을 만들 수는 없지만 www.example.com에 대한 CNAME 레코드는 만들 수 없다.
- 즉, 루트 도메인 이름이 아닌 경우에만 사용할 수 있다.
- NS: 호스팅 영역의 네임 서버다. 트래픽이 도메인으로 라우팅 되는 방식을 제어한다.서버의 DNS이름 또는 IP주소로 호스팅 존에 대한 DNS 쿼리에 응답이 가능하다.
- CAA, DS. MX, NAPTR, PTR, SOA, TXT, SPF, SRV 등
- Value: IP
- 라우팅 정책: Route 53이 쿼리에 응답하는 방식
- TTL: DNS 리졸버에서 레코드가 캐싱되는 시간.
호스팅 존
- 호스팅 존은 레코드의 컨테이너다.
- 도메인과 서브도메인으로 가는 트래픽의 라우팅 방식을 정의한다.
- 호스팅 존에 두 종류가 있는데 퍼블릭 호스팅 존과 프라이빗 호스팅 존이 있다.
- 프라이빗 호스팅 존: 가상 프라이빗 클라우드(VPC)만이 URL을 리졸브 할 수 있다.
- 퍼블릭 호스팅 존 : 퍼블릭 호스팅 존은 공개된 클라이언트로부터 온 쿼리에 응답할 수 있다.
CNAME vs Alias
- 로드밸런서나 CloudFront 등 AWS 리소스를 사용하는 경우 호스트 이름이 노출된다.
- 도메인에 호스트 이름을 매핑할 수 있다.
- 도메인에 AWS 리소스를 매핑하는 경우는 CNAME, Alias 2가지 옵션이 있을 수 있다.
1. CNAME
- CNAME 레코드로 호스트 이름이 다른 호스트 이름으로 향하도록 할 수 있다.
- ex) app.mydomain.com -> blabla.anything.com
- 이건 루트 도메인 이름이 아닌 경우에만 가능해서 mydomain.com 앞에 뭔가 붙어야 한다.
2. Alias
- 호스트 이름이 특정 AWS 리소스로 향하도록 할 수 있다.
- ex) app.mydomain.com -> blabla.amazonaws.com
- 루트 및 비루트 도메인 모두에 작동한다.
- Alias는 무료다.
- 자체적으로 상태 확인이 가능하다.
- AWS의 리소스에만 매핑되어 있다.
- CNAME과 달리 Alias는 Zone Apex라는 DNS 네임스페이스의 상위 노드로 사용될 수 있다.
- Alias 레코드를 사용하면 TTL을 설정할 수 없다.
- 대신, Route 53에 의해 자동으로 설정된다.
- Alias 대상은 다음과 같다.
- ELB, CloudFront 배포, API Gateway, Elastic beanstalk, S3 웹사이트, S3 버킷은 불가, VPC 인터페이스 엔드포인트 Global Accelerator 등이 있다.
- EC2의 DNS 이름에 대해서는 Alias 레코드 설정할 수 없다.
Route 정책
- 라우팅 정책은 Route 53이 DNS 쿼리에 응답하는 것을 돕는다.
단순 라우팅 정책(Simple)
- 트래픽을 단일 리소스로 보낸다.
- 동일한 레코드에 여러 개의 ip 지정할 수도 있다.
- 그럼 DNS가 다중 값을 응답하고 클라이언트가 랜덤으로 골라서 라우팅에 적용한다.
가중치 기반 정책(Weighted)
- 가중치를 활용해 요청의 일부 비율을 특정 리소스로 보낸다.
- 각 레코드에 상대적으로 가중치를 할당한다.
- DNS 레코드들은 동일한 이름과 유형을 가져야 하며 상태 확인과도 관련될 수 있다.
- 서로 다른 지역들에 걸쳐 로드 밸런싱을 할 때나 적은 양의 트래픽을 보내 새 애플리케이션을 테스트하는 경우에 사용한다.
대기 시간 기반 정책(Latency-based)
- 가장 가까운 리소스로 리다이렉팅을 한다.(지연 시간이 가장 짧은)
- 지연 시간은 유저가 레코드로 가장 가까운 식별된 AWS 리전에 연결하기까지 걸리는 시간을 기반으로 측정된다.
장애 조치 정책(Failover)
- 상태확인과 DNS 레코드를 묶은 방식이다.
- 세 가지의 상태 확인이 가능하다.
- 공용 엔드 포인트를 모니터링(애플리케이션, 서버, 혹은 다른 AWS 리소스가 될 수 있다.)
- 계산된 상태 확인(다른 상태 확인을 모니터링)
- CloudWatch 경보의 상태를 모니터링
- Primary 리소스 / Secondary - Disaster Recovery 리소스가 필요하다.
- Primary에 에러가 발생하면 Disaster Recovery로 쿼리한다.
지리적 위치 (Geolocation)
- 사용자의 실제 위치를 기반으로 합니다. 즉 가장 가까운 곳 IP로 응답한다.
- 사용 사례로는 콘텐츠 분산을 제한하고 로드 밸런싱 등을 실행하는 웹사이트 현지화가 있다.
지리 근접 (GeoProximity)
- 사용자와 리소스의 지리적 위치를 기반으로 트래픽을 리소스로 라우팅한다.
- 편향값을 사용해 특정 위치를 기반으로 리소스를 더 많은 트래픽을 이동시킨다.
- 지리 근접 라우팅은 편향을 증가시켜 한 리전에서 다른 리전으로 트래픽을 보낼 때 유용하다.
IP 기반 (IP-based)
- 클라이언트 IP 주소를 기반으로 라우팅한다.
- Route 53에서 CIDR 목록을 정의(클라이언트의 IP 범위)
- CIDR에 따라 트래픽을 어느 로케이션으로 보내야 하는지 정한다.
- 이걸 사용해 성능 최적화, 네트워크 비용 절감이 가능하다.
- IP를 미리 알고 있으니까 가능, IP가 어디서 오는지 알고 있으니까
다중 값 (Multi-Value)
- 트래픽을 다중 리소스로 라우팅할 때 사용한다.
- Route 53은 다중 값과 리소스를 반환한다.
- 상태 확인과 연결하면 다중 값 정책에서 반환되는 유일한 리소스는 정상 상태 확인과 관련이 있다.
- 각각의 다중 값 쿼리에 최대 8개의 정상 레코드가 반환된다.
- ELB와 유사해 보이지만 ELB를 대체할 수는 없다.
- 클라이언트 측면의 로드 밸런싱이다.
- 다중 값이 있는 단순한 라우팅의 경우에는 단순 라우팅 정책은 상태 확인을 허용하지 않기 때문에 단순 라우팅 정책의 쿼리가 반환하는 리소스 중 하나는 비정상일 가능성이 있다.
- 다중 라우팅은 정상 상태 확인과 연동되며, 정상인 리소스를 반환할 수 있다.
11. AWS 보안 및 암호화
암호화
- 전송 중 암호화 (SSL)
- 전송 중 암호화는 데이터가 전송되기 전 암호화되고 서버가 데이터를 받으면 복호화한다.
- SSL 인증서가 암호화를 해주고 다른 방법은 HTTPS가 있다.
- Amazon 서비스를 다룰 때마다 HTTPS 엔드포인트가 있어서 전송 중 암호화가 됐음을 보장한다.
- 기본적으로 전송 중 암호화를 활성화하면 '중간자' 공격으로부터 보호된다.
서버 측 저장 데이터 암호화
- 데이터가 서버에 수신 된 후 암호화하는 것
- 서버가 데이터를 암호화된 형태로 저장하고 있다는 점이 중요하다.
- 데이터는 클라이언트로 다시 전송되기 전에 복호화 된다.
- 즉, 데이터 키라고 불리는 키 덕분에 데이터는 암호화된 형태로 저장되고 암호 키와 해독 키는 주로 KMS(Key Management Service) 같은 곳에 따로 관리된다.
- 따라서 서버는 KMS와 통신할 수 있어야 한다.
클라이언트 측 암호화
-
클라이언트 측 암호화에서 데이터는 클라이언트가 암호화하고 여기서 클라이언트는 우리고 서버는 그 데이터를 절대 복호화 할 수 없고 데이터를 받는 클라이언트에 의해 복호화 된다.
- 전체적으로 데이터는 서버에 저장되지만 서버는 데이터의 내용을 알 수 없다.
-
서버는 데이터를 복호화 할 수 없어야 한다.
-
봉투 암호화의 간단한 예시
- 여기 객체가 있고 클라이언트는 데이터 키를 사용해서 클라이언트 측의 데이터를 암호화한다.
- 이제 해당 데이터를 원하는 데이터 저장소로 보낸다. FTP가 될 수도 있고 S3도 될 수 있고 무엇이든 상관 없다.
- 그리고 데이터를 받으면 클라이언트는 암호화된 객체를 받고 데이터 키에 액세스가 있거나 다른 곳으로부터 데이터 키를 찾을 수 있으면 받은 데이터를 복호화하여 복호화된 객체를 얻게 된다.
- 서버 데이터 저장소는 데이터를 암호화하거나 복호화할 수 없고 그저 암호화된 데이터를 받기만 할 수 있다.
KMS (Key Management Service)
- AWS 서비스로 암호화한다고 하면 KMS 암호화일 가능성이 크다.
- KMS 서비스를 사용하면 AWS에서 암호화 키를 관리한다.
- KMS는 권한 부여를 위해 IAM과 완전히 통합되고 KMS로 암호화한 데이터에 관한 액세스를 더 쉽게 제어하도록 한다.
- AWS KMS를 사용의 장점으로는 CloudTrail을 통해 키를 사용하기 위해 호출한 모든 API를 감사할 수 있다는 점이다. (중요)
- 저장 데이터를 EBS 볼륨에서 암호화하려면 KMS 통합을 활성화하면 된다. S3, RDS, SSM도 동일
- KMS을 직접 적용할 수도 있다. (API 호출, AWS CLI, SDK)
- 암호 데이터는 절대로 평문으로 저장하면 안 된다. 특히 코드에는 남기면 안된다.
대칭키(Symmetric)
- 대칭 KMS 키에는 데이터 암호화와 복호화에 사용하는 단일 암호화 키만 있어서 KMS와 통합된 모든 AWS 서비스는 대칭 키를 사용
- KMS 대칭 키를 생성하거나 사용하면 키 자체에는 절대로 액세스할 수 없고 키를 활용 또는 사용하려면 KMS API를 호출해야 한다.
비대칭키(Asymmetric), 공개키
- KMS에서 사용 가능한 두 번째 키는 바로 비대칭 키라고 한다.
- 2개의 키를 의미
- 데이터 암호화에 사용하는 퍼블릭 키와 데이터 복호화에 사용하는 프라이빗 키
- 따라서 암호화, 복호화와 작업 할당 및 검증에 사용
- 이 경우에는 KMS에서 퍼블릭 키를 다운로드 할 수 있지만 프라이빗 키에는 액세스할 수 없다.
- 프라이빗 키에 액세스하려면 API 호출로만 가능
KMS 키 타입7
- KMS로 호출하는 모든 API도 비용을 지불해야 한다.
- API 호출 10,000건당 약 3센트
AWS 관리형 키
- 이 키는 aws/rds나 aws/ebs와 같이 이름이 지정된다.
- AWS 서비스와 통합되어 있으며 무료 서비스이므로 AWS에서 관리하며 특정 서비스에 관한 저장 데이터 암호화에 사용할 수 있다.
고객 관리형 키 (CMK)
- KMS를 사용해 생성 가능하고 키 하나에 매달 1달러의 비용이 든다.
외부에서 가져온 고객 관리형 키
- 자체 키 구성 요소를 KMS에 가져올 수 있다.
- KMS에서 생성할 수 있고 동일하게 매달 1달러의 비용이 든다.
키 교체
- 보안을 위해서 자동으로 키를 교체하도록 설정할 수 있다.
- AWS 자동 관리형 키를 사용하면 자동으로 1년에 한 번씩 교체되며 고객 관리형 KMS 키를 사용하면 반드시 교체되도록 활성화해야 한다.
- 활성화한 후에는 자동으로 1년에 한 번씩 교체되며 교체 빈도를 변경할 수는 없다.
- 자체 키 구성 요소를 KMS로 보내려면 수동으로만 키를 교체할 수 있고 올바르게 키를 교체하려면 반드시 KMS 키 별칭을 사용해야 한다.
키 정책
- KMS 키에 관한 액세스를 제어하는 것으로 S3 버킷 정책과 비슷하지만 차이점이 있는데 KMS 키에 KMS 키 정책이 없으면 누구도 액세스할 수 없다.
- 이와 관련해 2가지 유형의 KMS 키 정책이 있다.
기본 정책
- 기본 정책은 사용자 지정 키 정책을 제공하지 않으면 생성된다.
- 기본적으로 계정의 모든 사람이 키에 액세스하도록 허용
- 즉, 사용자 또는 키 정책의 액세스를 허용하는 IAM 정책이 있으면 된다.
사용자 지정 키 정책
- 제어를 조금 더 특정하고자 할 때 KMS 키에 액세스할 수 있는 사용자 또는 역할을 정의하고 키 관리자를 정의할 수 있는 정책
- KMS 키에 관한 교차 계정 액세스 시 매우 유용
- 다른 계정이 KMS 키를 사용하도록 권한을 부여하기 때문
- 사용 사례는 계정 간에 스냅샷을 복사할 때 자체 KMS 키로 암호화한 스냅샷을 생성하면 고객 키 정책을 연결해야 하므로 고객 관리형 키가 되며 교차 계정 액세스 권한 부여를 위해 KMS 키 정책을 연결
- 암호화된 스냅샷을 대상 계정에 공유하면 대상 계정에서는 스냅샷 복제본을 생성하고 해당 대상 계정에서 다른 고객 관리형 키로 암호화한다.
- 이렇게 대상 계정의 스냅샷에서 볼륨을 생성하면 끝이다.
KMS Multi Region Keys
- AWS KMS에는 다중 리전 키를 둘 수 있다. 선택된 한 리전에 기본 키를 갖는다는 의미
- 다른 리전도 동일한 키를 갖게 되는데 키 ID와 구성 요소가 완전히 똑같다.
- KMS 다중 리전 키는 다른 AWS 리전에서 사용할 수 있는 KMS 키 세트로 서로 교차해서 사용할 수 있다.
- 한 리전에서 암호화한 다음 다른 리전에서 복호화 할 수 있다.
- 핵심은 한 리전에서 암호화하고 다른 리전에서 복호화해 다음 리전으로 복제할 때나 교차 리전 API 호출을 실행할 때 데이터를 재 암호화하지 않아도 된다는 점
- 하지만 KMS 다중 리전 키는 전역으로 사용할 수 없다.
- 기본 키가 있고 복제본이 있는 것
- 각 다중 리전 키는 자체 키 정책 등으로 각각 독립적으로 관리
- 따라서 특정 사용 사례를 제외하고는 다중 리전 키 사용을 권장하지 않는다.
- 다중 리전 키의 사용 사례에는 전역 클라이언트 측 암호화가 있다.
S3 암호화 복제
-
한 버킷에서 다른 버킷으로 S3 복제를 활성화하면 암호화되지 않은 객체와 SSE-S3로 암호화된 객체가 기본으로 복제
- 고객 제공 키인 SSE-C로 객체를 암호화하면 복제되지 않는다.
-
SSE-KMS로 암호화된 객체도 있다.
- 기본적으로 복제되지 않지만 만약 객체를 복제하려면 옵션을 활성화해야 한다.
- 따라서 어떤 KMS 키로 대상 버킷 내 객체를 암호화하는지 지정해야 합니다.
- 그리고 이 KMS 키 정책을 대상 키에 적용해야 하고 S3 복제 서비스를 허용하는 IAM 역할을 생성해서 소스 버킷의 데이터를 먼저 복호화 하도록 한 뒤 대상 KMS 키로 대상 버킷의 데이터를 다시 암호화한다.
- 이렇게 하면 복제가 활성화되는데 이는 수많은 암호화와 복호화가 발생하기 때문
- KMS 스로틀링 오류가 발생한 경우는 서비스 할당량을 요청해야 한다.
-
여기서 S3 복제에 다중 리전 키를 사용해야 할까?
- 공식 문서에 따르면 S3 복제에 다중 리전 키를 사용할 수 있으나 현재는 Amazon S3 서비스에서 독립 키로 취급하고 있으므로 객체는 여전히 복호화될 것이고 다중 리전 키인 경우에도 동일한 키로 암호화된다.
암호화된 AMI 공유 프로세스
-
AMI는 KMS 키로 암호화 되어 있습니다
- AMI는 소스 계정에 있고 KMS 키로 암호화된 것
-
어떤 방식으로 A 계정의 AMI에서 B 계정의 EC2 인스턴스를 시작할 수 있을까?
- 먼저, 시작 권한으로 AMI 속성을 수정해야 하는데 이 시작 권한은 B 계정에서 AMI를 시작하도록 허용한다.
- 시작 권한을 수정하고 특정 대상인 AWS 계정 ID를 추가하는 것으로 AMI를 공유한다.
- 그런 다음 B 계정에서 사용하도록 KMS 키도 공유해야 하므로 일반적으로 키 정책으로 실행
- 이제 B 계정에서 KMS 키와 AMI를 모두 사용할 수 있는 충분한 권한을 가진 IAM 역할이나 IAM 사용자를 생성
- 따라서 DescribeKey API 호출과 ReEncrypted API 호출 CreateGrant, Decrypt API 호출에 관한 KMS 측 액세스 권한이 있어야 한다.
- 모두 완료된 후에는 AMI에서 EC2 인스턴스를 시작하면 되는데 선택 사항으로 대상 계정에서 자체 계정의 볼륨을 재암호화하는 KMS 키를 이용해 전체를 재암호화할 수 있다.
- 이제 EC2 인스턴스를 실행할 수 있다.
- 먼저, 시작 권한으로 AMI 속성을 수정해야 하는데 이 시작 권한은 B 계정에서 AMI를 시작하도록 허용한다.
SSM 매개변수 저장소 (SSM Parameter Store)
- 구성 및 암호를 위한 보안 스토리지
- 구성을 암호화할지 선택할 수 있으므로 KMS 서비스를 이용해 암호를 만들 수 있다.
- SSM Parameter Store는 서버리스이며 확장성과 내구성이 있고 SDK도 사용이 용이
- 또한 매개변수를 업데이트할 때 구성과 암호의 버전을 추적할 수도 있다.
- IAM을 통해 보안이 제공되며 특정한 경우에는 Amazon EventBridge로 알림을 받을 수도 있다.
- CloudFormation이 Parameter Store의 매개변수를 스택의 입력 매개변수로 활용할 수 있다.
Paramters Policies
- 고급 매개변수에서만 사용할 수 있다.
- 매개변수 정책을 통해 만료 기한을 뜻하는 타임 투 리브(TTL)를 매개변수에 할당할 수 있다.
- 비밀번호 등의 민감한 정보를 업데이트 또는 삭제하도록 강제한다.
- 한 번에 여러 정책을 할당할 수도 있다.
AWS Secrets Manager
- 암호를 저장하는 최신 서비스로 SSM Parameter Store와는 다른 서비스
- Secrets Manager는 X일마다 강제로 암호를 교체하는 기능이 있어 암호 관리를 더 효율적으로 할 수 있다.
- 또한 AWS Secrets Manager로 교체할 암호를 강제 생성 및 자동화할 수 있다.
- 이를 위해 새 암호를 생성할 Lambda 함수를 정의해야 한다.
- AWS Secrets Manager는 AWS가 제공하는 다양한 서비스와도 아주 잘 통합된다. (RDS, MySQL,PostgreSQL, Aurora 등)
- AWS 외 여러 서비스와 데이터베이스에도 즉시 통합할 수 있다.
- 데이터베이스에 접근하기 위한 사용자 이름과 비밀번호가 AWS Secrets Manager에 바로 저장되고 교체 등도 가능하다.
- 암호는 KMS 서비스를 통해 암호화된다.
- RDS와 Aurora의 통합 혹은 암호에 대한 내용이 시험에 나오면 AWS Secrets Manager를 떠올려야 한다.
다중 리전 암호
- 복수 AWS 리전에 암호를 복제할 수 있고 AWS Secrets Manager 서비스가 기본 암호와 동기화된 읽기 전용 복제본을 유지한다는 개념
- 이렇게 두 리전이 있을 때 기본 리전에 암호를 하나 만들면 보조 리전에 동일한 암호가 복제된다.
- 이렇게 하는 데에는 여러 이유가 있다.
- 첫째, us-east-1에 문제가 발생하면 암호 복제본을 독립 실행형 암호로 승격할 수 있다.
- 그리고 여러 리전에 암호가 복제되니 다중 리전 앱을 구축하고 재해 복구 전략도 짤 수 있다.
- 한 리전에서 다음 리전으로 복제되는 RDS 데이터베이스가 있다면 동일한 암호로 동일한 RDS 데이터베이스 즉 해당 리전의 해당 데이터베이스에 액세스할 수 있다.
AWS SSM Parameter Store VS AWS Secrets Manager
AWS Systems Manager Parameter Store와 AWS Secrets Manager는 모두 민감한 정보를 안전하게 저장하고 관리하는 서비스이지만, 각기 다른 기능과 사용 사례를 제공하며, 주로 다음과 같은 차이점이 있습니다.
AWS Systems Manager Parameter Store
- 목적 및 기능:
- 일반적인 구성 데이터 뿐만 아니라 암호화된 비밀 정보도 관리할 수 있습니다.
- 주로 애플리케이션 구성 데이터를 관리하는 데 사용됩니다.
- 비용:
- 표준 매개변수 사용은 무료입니다.
- 고급 매개변수(추가 보안 및 기능이 필요한 경우)에 대한 요금은 별도로 부과됩니다.
- 통합:
- 여러 AWS 서비스와 직접 통합되며, 특히 애플리케이션 및 시스템 구성 데이터를 안전하게 주고받기 위한 용도로 사용됩니다.
- 버전 관리:
- 매개변수의 여러 버전을 지원하며, 특정 버전으로 쉽게 참조할 수 있습니다.
- 암호화:
- AWS Key Management Service(KMS)를 통해 매개변수를 암호화할 수 있습니다.
AWS Secrets Manager
- 목적 및 기능:
- 민감한 비밀 정보를 안전하게 저장하고 관리하는 데 주로 사용됩니다.
- 데이터베이스 자격 증명, API 키 등 비밀 정보의 주기적인 회전 기능을 제공합니다.
- 비용:
- 사용자는 비밀 정보의 저장 및 호출 횟수에 따라 비용을 지불합니다.
- 비밀 회전:
- 자동 비밀 회전 기능을 제공하여, 자격 증명이 정기적으로 변경되고 최신 상태로 유지되도록 할 수 있습니다.
- 통합:
- 데이터베이스 자격 증명 등의 자동 회전을 지원하며, AWS Lambda와 같은 서비스를 통해 사용자 정의 회전 로직을 구현할 수 있습니다.
- 버전 관리 및 암호화:
- 비밀의 모든 버전을 개별적으로 관리하며 버전별로 필요에 따라 암호화됩니다.
정리
- Parameter Store는 일반 구성 데이터와 보안이 필요한 매개변수를 중앙에서 관리할 때 유용합니다. 이는 또한 개발/테스트 환경과 같은 크게 민감하지 않은 정보에 적합합니다.
- Secrets Manager는 비밀 정보의 회전 및 강력한 보안 관리가 필수적인 경우에 적합하며, 주로 민감한 데이터의 주기적 갱신이 필요한 프로덕션 환경에 사용됩니다.
둘 다 AWS IAM 정책을 통해 액세스 제어가 가능하며, 필요에 맞는 서비스를 선택하거나 상황에 따라 두 서비스를 함께 사용하는 것도 가능합니다.
AWS Certificate Manager(ACM)
- ACM은 TLS 인증서를 AWS에서 프로비저닝, 관리 및 배포하게 해준다.
- ACM은 퍼블릭과 프라이빗 TLS 인증서를 모두 지원하며 퍼블릭 TLS 인증서 사용 시에는 무료로 이용할 수 있다.
- 인증서를 자동으로 갱신하는 기능도 있다.
- 그리고 여러 AWS 서비스와 통합되어 있어 Elastic Load Balancer(ELB)에 TLS 인증서를 불러올 수 있다. (ALB, NLB)
- CloudFront 배포나 API Gateway의 모든 API에서도 불러올 수 있다.
- 다만 ACM을 사용할 수 없는 곳이 하나 있는데 바로 EC2 인스턴스
엔드 포인트 유형
엣지 최적화(edge-optimized) 유형
- 글로벌 클라이언트를 위한 유형으로 먼저 CloudFront 엣지 로케이션으로 요청을 라우팅하여 지연을 줄이는 방법으로 하나의 리전에만 있는 API Gateway로 보내지는 경우
리전(regional) 엔드 포인트 유형
- 클라이언트가 API Gateway와 같은 리전에 있을 때를 쓰인다.
- 이 경우 CloudFront는 사용할 수 없지만 자체 CloudFront 배포를 생성하여 캐싱 및 배포 전략을 제어할 수 있다
프라이빗(private) API Gateway 엔드포인트 유형
- 인터페이스 VPC 엔드 포인트(ENI)를 통해 VPC 내부에만 액세스할 수 있다.
- 또한 프라이빗 모드에서는 API Gateway에 대한 액세스를 정의하는 리소스 정책이 필요하다.
- ACM은 엣지 최적화 및 리전 엔드포인트에 적합하다.
웹 애플리케이션 방화벽 (WAF)
- WAF는 7계층에서 일어나는 일반적인 웹 취약점 공격으로부터 웹 애플리케이션을 보호한다.
- 계층 7은 HTTP이니 HTTP 취약점 공격을 막아주는 것
- 웹 애플리케이션 방화벽(WAF)의 배포는 애플리케이션 로드 밸런서, API Gateway, CloudFront, AppSync GraphQL API, Cognito 사용자 풀에 할 수 있다.
- WAF의 배포가 어디에 되는 지 꼭 기억해야한다.
- WAF를 NLB에 배포한다는 것은 틀렸다. 이는 4계층
- 이러한 서비스에 방화벽을 배포한 후에는 웹 액세스 제어 목록(ACL)과 규칙을 정의해야 한다.
- 이 규칙이란 IP 주소를 기반으로 필터링하는 등의 규칙
- IP 세트를 정의할 수 있으며 각 IP 세트는 최대 10,000개의 IP 주소를 가질 수 있다.
- 또한 HTTP 헤더와 본문에 기반해 필터링할 수도 있고 URI 문자열을 조건으로 두어 SQL 주입, 크로스 사이트 스크립팅(XSS) 등의 일반적인 공격을 차단할 수도 있다.
- 용량에 제약을 걸어 요청이 최대 2MB를 넘지 않게 하거나 지역 일치(Geo-match) 조건을 두어 특정 국가를 허용 또는 차단 가능
- 속도 기반 규칙을 설정하면 IP당 요청 수를 측정하여 디도스 공격을 막을 수도 있다.
- 웹 ACL은 리전에만 적용되며 CloudFront는 글로벌로 정의됩니다.
- 규칙 그룹은 여러 웹 ACL에 추가할 수 있는 재사용 가능한 규칙 모음
- 이 규칙이란 IP 주소를 기반으로 필터링하는 등의 규칙
AWS Shield
- AWS Shield는 디도스 공격으로부터 스스로를 보호하기 위한 서비스
- 디도스란 분산 서비스 거부 공격이라는 뜻.
- 인프라에 동시에 엄청난 양의 요청이 세계 곳곳의 여러 컴퓨터에서 유입되는 공격
- 그 목적은 인프라에 과부하를 일으키는 것으로 실제 사용자들에게 서비스를 제공할 수 없게 만든다. 즉 분산 서비스 거부가 발생
- 디도스란 분산 서비스 거부 공격이라는 뜻.
- 디도스 공격을 방어하려면 AWS Shield 스탠다드 서비스를 이용하면 된다.
- 이 서비스는 모든 AWS 고객에게 무료로 활성화되어 있는 서비스로 SYN/UDP Floods나 반사 공격 및 L3/L4 공격으로부터 고객을 보호해 준다.
- 고급 보호가 필요한 고객을 위한 AWS Shield 어드밴스드 서비스도 있는데 어드밴스드는 선택적으로 제공되는 디도스 완화 서비스로 조직 당 월 3,000달러를 지불해야 한다.
- 어드밴스드에서는 더욱 정교한 디도스 공격을 막아주며 Amazon EC2, ELB Amazon CloudFront AWS Global Accelerator 그리고 Route 53를 보호한다.
- 또한 AWS 디도스 대응 팀이 항시 대기하고 있어 공격을 받았을 때 지원을 받을 수 있다.
- 따라서 디도스 공격으로 인한 요금 상승을 AWS Shield 어드밴스드를 통해 방지할 수 있겠다.
- 또 Shield 어드밴스드는 자동 애플리케이션 계층 디도스 완화도 제공하여 자동으로 WAF 규칙을 생성, 평가, 배포함으로써 L7 공격을 완화할 수 있다.
- 즉, 웹 애플리케이션 방화벽이 L7에서 일어나는 디도스 공격을 완화하는 규칙을 자동으로 갖게 된다는 뜻
AWS Firewall Manager
- AWS Organizations에 있는 모든 계정의 방화벽 규칙을 관리하는 서비스
- 여러 계정의 규칙을 동시에 관리할 수 있다.
- 또한 보안 규칙의 집합인 보안 정책을 설정할 수 있는데 여기에는 ALB, API Gateway CloudFront 등에 적용되는 웹 애플리케이션 방화벽(WAF) 규칙이나 ALB, CLB, NLB, 엘라스틱 IP CloudFront를 위한 AWS Shield 어드밴스드 규칙 등이 포함된다.
- 또 EC2, 애플리케이션 로드 밸런서 VPC의 ENI 리소스를 위한 보안 그룹을 표준화하는 보안 정책과 아직 다룬 적은 없지만 VPC 수준의 AWS Network Firewall도 해당된다.
- 그리고 Amazon Route 53 Resolver DNS Firewall도 포함된다.
- AWS Firewall Manager는 이와 같은 모든 방화벽을 한 곳에서 관리할 수 있도록 지원해 준다.
- 정책은 리전 수준에서 생성되며 조직에 등록된 모든 계정에 적용된다.
WAF, Firewall Manager, Shield 차이
- WAF, Shield Firewall Manager는 모두 포괄적인 계정 보호를 위한 서비스
- 일단 WAF에서는 웹 ACL 규칙을 정의하는데 리소스별 보호를 구성하는 데에는 WAF가 적절합니다.
- 여러 계정에서 WAF를 사용하고 WAF 구성을 가속하고 새 리소스 보호를 자동화하려면 Firewall Manager로 WAF 규칙을 관리
- Firewall Manager는 이러한 규칙들을 모든 계정과 모든 리소스에 자동으로 적용해준다.
- Shield 어드밴스드는 디도스 공격으로부터 고객을 보호하고 WAF의 기능 외에도 더 많은 기능을 제공
- 예를 들어 Shield 대응 팀 지원 고급 보고서 제공 그리고 WAF 규칙 자동 생성 등의 기능을 추가로 이용할 수 있다.
- 디도스 공격을 자주 받는다면 Shield 어드밴스드를 사용하는 것도 좋은 선택지가 될 수 있다.
- Firewall Manager는 모든 계정에 Shield 어드밴스드를 배포에도 도움을 준다.
GuardDuty
-
AWS 계정을 보호하는 지능형 위협 탐지 서비스
- 백엔드에서 머신 러닝 알고리즘을 사용하여 이상 탐지를 수행하고 타사 데이터를 이용하여 계정에 대한 공격을 탐지한다.
-
Amazon GuardDuty는 여러 소스에서 입력 데이터를 얻는다.
- CloudTrail 이벤트 로그의 입력 데이터를 가지고 비정상적 API 호출과 무단 배포 등을 탐지한다.
- 관리 이벤트에서 사용하여 해당 이벤트가 VPC 서브넷을 만들 때 생기는지 API가 계정에 호출하는 추적 생성 시 생기는지 확인한다.
- CloudTrail S3 데이터 이벤트를 확인한다. 예를 들어 버킷에서 발생하는 이벤트인 API 호출, 즉 get object, list objects delete object 등
- VPC 흐름 로그를 통해 비정상적인 인터넷 트래픽과 IP 주소를 찾고 또한 DNS 로그는 DNS 쿼리에서 인코딩된 데이터를 전송할 EC2 인스턴스가 손상되었는지 확인할 수 있다.
- Kubernetes 감사 로그를 확인하여 의심스러운 활동 및 잠재적인 EKS 클러스터 손상을 감지한다.
- 이 모든 작업이 내부적으로 이루어진다.
-
그리고 CloudWatch 이벤트 규칙을 설정하여 탐색 결과가 나타나면 알림을 받을 수 있다.
-
마지막으로 시험에 나올 수 있는 내용은 GuardDuty로 암호 화폐 공격을 보호할 수 있다는 점
-
요약하면 GuardDuty는 VPC 흐름 로그, CloudTrail 로그 DNS 로그 및 EKS 감사 로그를 모두 GuardDuty로 가져온다.
- 그리고 CloudWatch 이벤트 규칙 덕분에 Lambda 함수나 SNS 주제 알림을 받을 수 있다.
Amazon Inspector
- Amazon Inspector는 몇 군데에서 자동화된 보안 평가를 실행할 수 있는 서비스
EC2 인스턴스 경우
- EC2 인스턴스에서 시스템 관리자 에이전트를 활용하면 Amazon Inspector가 해당 EC2 인스턴스의 보안을 평가하기 시작한다.
- 의도되지 않은 네트워크 접근 가능성에 대해 분석하고, 실행 중인 운영 체제에서 알려진 취약점을 분석한다.
- 이건 연속적으로 수행된다.
컨테이너 이미지를 Amazon ECR로 푸시할 때 실행
- 예를 들어 도커 이미지
- 컨테이너 이미지가 Amazon ECR로 푸시되면 Amazon Inspector가 알려진 취약점에 대해 검사
- Lambda 함수에 대해서도 사용 가능
- Amazon Inspector는 Lambda 함수가 배포될 때 함수 코드 및 패키지 종속성에서 소프트웨어 취약성을 다시 분석
- 즉, 함수가 배포될 때 평가
- Amazon Inspector는 Lambda 함수가 배포될 때 함수 코드 및 패키지 종속성에서 소프트웨어 취약성을 다시 분석
- Amazon Inspector가 작업을 완료하면 결과를 AWS 보안 허브에 보고한다.
- 또한 이러한 결과 및 결과 이벤트를 Amazon Event Bridge로 보낸다.
- 이를 통해 인프라에 있는 취약점을 모아서 볼 수 있다.
- Inspector는 실행 중인 EC2 인스턴스, Amazon ECR의 컨테이너 이미지, Lambda 함수에만 사용된다.
AWS ECS VS AWS EKS
Amazon ECS(Amazon Elastic Container Service)와 Amazon EKS(Amazon Elastic Kubernetes Service)는 둘 다 AWS에서 제공하는 컨테이너 관리 서비스입니다. 하지만 각 서비스는 서로 다른 오케스트레이션 엔진을 기반으로 하며, 그에 따라 특징과 사용 사례도 다릅니다. 다음은 ECS와 EKS의 주요 비교입니다:
Amazon ECS (Elastic Container Service)
- 기반 기술:
- ECS는 AWS에서 자체 개발한 컨테이너 오케스트레이션 서비스입니다. AWS에 깊이 통합되어 있으며, 독립적인 표준 기반의 플랫폼이 아닌 AWS 고유의 솔루션입니다.
- 사용의 용이성:
- AWS 환경에 최적화되어 있으며, 설정과 사용이 비교적 간단합니다. 자동화된 태스크 관리와 쉽게 통합되는 AWS 서비스 덕분에 사용자 경험이 원활합니다.
- 통합:
- IAM, ELB, CloudWatch, VPC 등 여러 AWS 서비스와의 강력한 통합 기능을 제공합니다.
- 운영 및 관리:
- 사용자는 컨테이너 정의와 클러스터 설정에 집중할 수 있으며, 인프라 운영에 있어 AWS가 많은 작업을 대신 관리해 줍니다.
- 유연성:
- AWS에 의존적이며, 멀티클라우드 및 온프레미스 환경에서의 이동성은 제한적입니다.
Amazon EKS (Elastic Kubernetes Service)
- 기반 기술:
- EKS는 오픈 소스 컨테이너 오케스트레이션 플랫폼인 Kubernetes를 기반으로 합니다. Kubernetes는 컨테이너화된 애플리케이션을 관리하기 위한 사실상 업계 표준입니다.
- 사용의 용이성:
- Kubernetes의 복잡한 설정과 유지 관리가 필요하며, 이로 인해 처음 학습하는 데 더 많은 시간이 걸릴 수 있습니다.
- 통합:
- 역시 AWS 서비스와 통합되지만, Kubernetes의 특성상 AWS 외 다른 환경에서도 사용할 수 있습니다. 이는 멀티클라우드 및 온프레미스 환경에서의 유연성을 제공합니다.
- 운영 및 관리:
- EKS는 Kubernetes의 모든 기능을 가져오며, 클러스터 관리를 통해 고급 사용자 설정을 직접 제어할 수 있습니다. 이는 고도의 맞춤형 아키텍처를 구축하는 데 유리합니다.
- 유연성:
- EKS는 Kubernetes 생태계의 모든 도구와 호환되며, 이를 통해 커뮤니티의 다양한 추가 기능을 활용할 수 있습니다.
정리
- ECS는 AWS 환경에 깊이 통합된 관리형 서비스로, AWS에서 모든 것을 운영할 계획이라면 상대적으로 간단하고 빠르게 시작할 수 있는 선택입니다.
- EKS는 Kubernetes를 표준 오케스트레이션 엔진으로 사용하기에 적합하며, 복잡하고 크로스플랫폼 솔루션이 필요한 경우, 특히 멀티클라우드 및 하이브리드 클라우드 전략의 일환으로 고려될 수 있는 서비스입니다.
각 서비스는 이러한 장단점을 바탕으로 특정 상황에 맞게 선택되어야 합니다. 두 서비스 모두 컨테이너 배포, 확장, 관리에 있어서 강력한 기능을 제공합니다.
Macie
- Macie는 완전 관리형의 데이터 보안 및 데이터 프라이버시 서비스이며 머신 러닝과 패턴 일치를 사용하여AWS의 민감한 정보를 검색하고 보호한다.
- 구체적으로 말하면 민감한 데이터를 경고하는데 예를 들면, 개인 식별 정보 즉, PII(개인 식별 정보, Personally Identifiable Information) 같은 정보다.
- ex) S3버킷에 PII가 있다면 Macie에 의해 분석되고 어떤 데이터를 PII로 분류할 수 있는지 알아낸 후 EventBridge를 통해 발견 결과를 알려준다.
12. 인스턴스 스토리지
EBS(Elastic Block Store)
- EC2 인스턴스에 사용할 블록 수준 스토리지 볼륨을 제공한다.
EBS Volume 특징
- 인스턴스가 종료된 후에도 데이터를 유지할 수 있다.
- 한 번에 하나의 인스턴스에만 마운트할 수 있다.
- 더 높은 수준의 유형(io1/io2)는 하나의 EBS가 여러개의 인스턴스에 연결 가능하다.(최대 16개)
- 특정 가용 영역에서만 사용할 수 있다.
- 연결하고자 하는 인스턴스의 가용 영역과 맞춰 볼륨을 생성해야 한다.
- 스냅샷을 이용하면 다른 가용 영역으로 볼륨을 옮길 수 있다.
- 네트워크 드라이브이다.(물리적 드라이브가 아니다.)
- USB 모양의 물리적 장치이지만, 실제로는 물리적 연결은 없으며 네트워크를 통해 연결된다.
- 네트워크를 이용해 인스턴스와 통신하기에 약간의 대기 시간이 있을 수 있다.
- 프로비저닝된 용량이 있어야 한다.
- 프로비저닝된 모든 용량에 대해 요금이 청구된다.
- 시간이 지남에 따라 드라이브 용량을 늘리 수 있다.
- EC2 인스턴스 종료시 EBS 볼륨 제어
- 루트 EBS는 기본적으로 삭제된다. 해당 속성을 변경할 수 있다.
- 루트 EBS를 제외한 다른 EBS 볼륨은 삭제되지 않는다.
EBS 스냅샷
EBS 스냅샷
- EBS 볼륨의 특정 시점에 대한 백업
- EC2 인스턴스에서 EBS 볼륨을 분리할 필요는 없지만 권장 사항이다.
- 다른 가용 영역 혹은 다른 리전에 복사할 수 있다.
- EBS 볼륨의 스냅샷을 찍고 다른 AZ에 복원할 수 있다.
- 해당 방식을 이용해 AZ -> AZ로 전송 가능하다.
EBS 스냅샷 기능
아카이브
- 최대 75%까지 저렴한 아카이브 티어로 스냅샷을 옮길 수 있는 기능
- 아카이브 복원시 최소 24, 최대 72시간이 소요된다.
휴지통
- EBS 스냅샷을 영구 삭제하는 대신 휴지통에 넣을 수 있다.
- 기간은 1일 ~ 1년이다.
빠른 스냅샷 복원(FSR, Fast Snapshop Restore)
- 스냅샷을 완전 초기화해 첫 사용에서의 지연 시간을 업애는 기능이다.
- 스냅샷이 아주 크고 EBS 볼륨 또는 EC2 인스턴스를 빠르게 초기화해야 할 때 특히 유용하다.
- 하지만 비용이 많이 발생해 주의해야한다.
EBS Volume 유형
- 총 6개의 유형으로 구분된다.
General Purpose SSD
- gp2, gp3 유형이 존재한다.
- 범용적인 목적의 SSD 볼륨
- 다양한 워크로드에서 활용된다.
- 가격과 성능의 절충안이 되어 준다.
- 범용 SSD 볼륨
- 특징
- gp2, gp3가 비용 효과적인 스토리지이며 gp3는 최신 세대의 볼륨으로 IOPS와 처리량을 독자적으로 설정할 수 있는 반면, gp2에서는 그 둘이 연결되어 있다는 점이다.
- gp3의 기본 성능은 3,000IOPS, 125MB/s 이다.
- 최대 IOPS는 16,000(초당 I/O 작업 수 의미), 최대 처리량은 1,000MB/s
Provisioned IOPS(PIOPS) SSD
- io1, io2 유형이 존재한다.
- 16,000 IOPS 이상을 요구하는 애플리케이션에 적합
- ex) 스토리지를 이용하는 데이터베이스 워크로드
- 스토리지의 퍼포먼스와 일관성에 매우 민감하다.
- EBS의 다중 연결을 지원한다.
- 특징
- io1과 동일한 비용으로 내구성과 기가 당 IOPS의 수가 더 높기에 현재까지는 io2를 사용하는 것이 더 합리적이다.
- Nitro EC2 인스턴스의 경우 최대 64,000 IOPS 지원, 아닌 경우 32,000 IOPS까지 지원한다. 처리량은 4~16TB
Hard Disk Drives(HDD)
- st1, sc1 유형이 존재한다.
- 부팅 볼륨이 아니다. << 중요
- 최대 16TB까지 확장된다.
- st1
- 저비용의 HDD 볼륨
- 잦은 접근과 처리량이 많은 워크로드에 사용(빅데이터, 데이터 웨어하우징 로그 처리에 적합하다.)
- 최대 500IOPS, 500MB/s
- sc1
- 가장 비용이 적게 드는 HDD 볼륨
- 아카이브 데이터용으로 접근 빈도가 낮은 데이터에 적합하다.
- 최대 250IOPS, 250MB/s
EBS 다중 연결
-
특징
- 하나의 EBS 볼륨을 같은 가용 영역에 있는 여러 EC2 인스턴스에 연결할 수 있는 기능
- EBS 볼륨 중 오직 io1, io2 만 가능하다.
- 각 인스턴스는 볼륨에 대해서 동시에 읽기, 쓰기가 가능하다.
-
주의사항
- 같은 가용영역내에 존재하는 인스턴스만 연결이 가능하다.
- 하나의 EBS 볼륨은 최대 16개의 EC2 인스턴스만 연결 가능하다. << 중요
- 다중 연결 실행을 위해서는 반드시 클러스터 인식 파일 시스템을 사용해야 한다.
EBS Encryption
- 암호화는 EC2 인스턴스를 호스팅하는 서버에서 수행되므로 EC2 인스턴스에서 EBS 스토리지로 전송되는 데이터가 암호화된다.
- 암호화가 동시다발적으로 발생
- 암호화는 AES-256, AMS 서비스(AMS Key Management Service)의 CMK(Customer Master Keys)가 사용될 수 있다.
- 모든 EBS 볼륨 타입은 암호화 가능하다.
- 암호화된 볼륨의 스냅샷과 암호화된 스냅샷에서 생성된 볼륨은 같은 볼륨 암호키를 사용해서 자동으로 암호화된다.
AMI
AMI란
- AMI란 Amazon Machine Image이며 EC2 인스턴스를 통해 만든 이미지를 말한다.
- AMI로 AWS를 구축할 수도 있고 커스텀 할 수도 있다.
- AMI에 원하는 소프트웨어 또는 설정 파일을 추가하거나 별도의 운영 체제를 설치할 수도 있다.
- 모니터링 툴을 추가할 수도 있다.
- AMI를 따로 구성하면 부팅 및 설정에 드는 시간을 줄일 수 있다.
- EC2 인스턴스에 설치하고자 하는 모든 SW를 AMI가 미리 패키징하기 때문에
- AMI를 특정 리전에 구축한 다음 다른 리전으로 복하새허 사용할 수 있다.
EC2 Instance Store
EC2 Instance Store란
-
물리적 서버에 연결된 하드웨어 드라이브를 가리킨다.
-
EC2에 물리적으로 연결된다.
-
특징
- EC2 인스턴스 스토어는 I/O 성능 향상을 위해 활용할 수 있다.
- 버퍼, 캐시 혹은 스크래치 데이터, 임시 콘텐츠를 사용하려는 경우 보관하기 좋다.
- 하지만, EC2 인스턴스 중지 혹은 종료시 해당 스토리지 또한 손실된다.
- 따라서 비지속형 스토리지, 임시 스토리지라고 불린다.
- 이와 같은 이유로 EC2 인스턴스 스토어가 장기적으로 데이터를 보관할 만한 장소가 될 수 없음을 보여 준다.
- 데이터 백업 혹은 복제가 필요하다.
Amazons EFS
EFS(Elastic File System)
- 관리형 FNS이다.
- 네트워크 파일 시스템이므로 많은 EC2 인스턴스에 마운트될 수 있다.
- EC2 인스턴스는 서로 다른 가용 영역에 있을 수 있다.
- 이것이 EFS의 장점이다.
- 가용성이 높고 확장성이 뛰어나지만 비싸다.
- GP2 EBS 볼륨의 약 3배다.
- 사용량에 따라 비용을 지불하므로 미리 용량을 프로비저닝할 필요가 없다.
- 사용 사례
- 콘켄츠 관리, 웹 서빙, 데이터 공유, Wordpress
- 내부적으로 NFS 프로토콜을 사용하며 EFS에 대한 액세스를 제어하려면 보안 그룹을 설정해야 한다.
- 보안그룹으로 둘러싸여있기 때문에
- 중요한 점은 윈도우가 아닌 Linux 기반의 AMI와만 호환된다.
- KMS를 사용해 EFS 드라이브에서 미사용 암호화를 활성화할 수 있다.
옵션
Performance Mode(성능 모드)
- General Purpose(default)
- 범용 목적으로 사용되고 지연 시간에 민감한 사용 사례에 사용된다. 웹 서버, CMS ...
- 하지만 처리량을 최대화하려면 최대 I/O 모드를 선택해야 한다.
- Max I/O
- 지연 시간이 더 긴 네트워크 파일 시스템이지만 처리량이 높고 병렬성이 높다.
- 빅 데이터 애플리케이션이나 미디어 처리가 필요한 경우 유용하다.
처리량 모드
- Bursting
- 1TB인데, 초당 50MiB에 초당 100MiB 버스트까지 더한 것이다.
- Provisioned
- 1TB 스토리지에서 초당 1GiB를 처리할 수 있다.
- 스토리지와 처리량을 분리했기에 괜찮다.
- Elastic
- 워크로드에 따라 처리량을 자동으로 조절할 수 있다.
- 워크로드를 예측하기 어려울때 사용
Storage Classes
스토리지 계층
- 스토리지 계층을 설정할 수 있다.
- 며칠 후 파일을 다른 계층으로 옮길 수 있는 기능이다.
- 표준 계층: 자주 액세스 하는 계층
- EFS-IA: 자주 액세스하지 않는 계층
- 위 계층에서 파일을 검색할 경우 비용이 발생한다,.
- EFS-IA에 정하면 비용이 감소된다. 대신 수명 주기 정책을 사용해야 한다.
가용성과 내구성
- Multi-AZ
- 프로덕션 사용 사례에 적합하다.
- 가용 영역 하나가 다운되더라도 EFS 파일 시스템에 영향을 미치지 않는다.
- One Zone
- 개발용으로는 적합할 수 있다.
- 하나의 AZ에만 있고 백업은 기본적으로 활성화되도록 설정되어 있으며 액세스 빈도가 낮은 스토리지 계층과 호환된다.
- 때문에 비용이 많이 할인됨. 약 90%정도
EBS vs EFS
EBS vs EFS
- EBS 볼륨은 io1/io2 유형 볼륨의 다중 첨부 기능을 사용하는 것 외에는 한 번에 하나의 인스턴스에 첨부된다.
- EBS 루트 볼륨은 EC2 인스턴스가 종료되면 기본적으로 종료되지만, 이 동작은 비활성화가 가능하다.
- AZ간의 EBS 볼륨을 마이그레이션하기 위해선, EBS 스냅샷을 만들어야한다.
- EBS 볼륨 백업은 I/O를 사용하므로, 애플리케이션이 많은 트래픽을 처리한다면 인스턴스의 성능을 위해 실행하지 않는 것이 좋다.
- EFS는 하나의 파일 시스템으로 서로 다른 AZ에서 서로 다른 마운트 대상을 가질 수 있다.
- EFS는 여러 인스턴스가 하나의 파일 시스템을 공유할 수 있다.
- EFS는 EBS보다 가격대가 높지만, EFS-IA 기능을 활용하여 비용을 절감할 수 있다.
- Posix 시스템을 사용하는 WordPress가 있는 경우에 사용하기 적합하다.
- Posix(포직스), Portable Operating System Interface + UniXUnix를 기반으로 만든 수많은 Linux 기반 운영체제들의 단일 포괄적 표준(Competing Standard)을 만들기 위한 목적으로 제작된 것
13. AWS S3
S3
- S3는 파일을 버킷에 저장한다.
- 버킷은 상위 레벨 디렉토리로 표시된다. 사실 S3 그 자체는 디렉토리의 개념은 없다.
- S3 버킷의 파일은 객체라고 하며, 이 버킷은 계정 안에 생성된다. 즉 객체란 S3 저장소에 저장되는 데이터를 의미한다.
- 버킷 이름은 계정에 있는 모든 리전과 AWS에 존재하는 모든 계정에서 유니크해야 한다.
- 버킷은 리전 수준에서 정의되므로, 반드시 특정 AWS 리전에서 정의되어야 한다.
- 객체나 파일에는 키가 있으며, 키는 Amazon S3 키는 파일의 전체 경로다.
- 키는 접두사와 객체 이름으로 구성되며, 키는 길이가 굉장히 긴 이름으로 슬래시를 포함하며, 키는 접두사와 객체 이름으로 만들어진다.
- 파일 등 원하는 것은 뭐든지 업로드 가능하며, 최대 객체 크기는 5TB이다.
- 업로드하는 것이 5TB 보다 크다면 이때는 멀티 파트 업로드를 사용해서 해당 파일을 여러 부분으로 나눠 업로드한다.
- 보통 100MB가 넘는 경우에는 멀티파트 업로드를 권장한다.
- 객체에는 메타 데이터가 있는데, 객체의 키-값 쌍 리스트를 말한다.
- 메타데이터 시스템이나 사용자에 의해 설정되어 파일에 관한 요소나 메타데이터를 나타낼 수 있다.
- 태그는 가령 유니코드 키-값 쌍은 최대 10개까지 가능하며, 태그는 보안과 수명 주기에 유용하다.
S3 사용 용도
- 백업과 스토리지
- 재해 복구 용도
- 아카이브
- 하이브리드 클라우드 스토리지
- 애플리케이션 호스팅, 미디어 호스팅
- 데이터 레이크, 빅데이터 분석
- 정적 웹사이트 호스팅
S3 보안
사용자 기반
- 사용자에게 IAM 정책이 주어진다.
- 참고로 IAM 정책 내의 DENY은 S3 버킷 정책보다 우선적으로 고려된다.
리소스 기반
- S3 버킷 정책
- 이 정책은 S3 콘솔에서 직접 할당할 수 있는 전체 버킷 규칙이다.
- 특정 사용자가 들어올 수 있게 하거나 다른 계정의 사용자를 허용할 수 있다.
- 이를 S3 버킷에 액세스할 수 있는 교차 계정이라고 한다.
- 객체 액세스 제어 목록(ACL)
- 이 목록은 보다 세밀한 보안이며 비활성화할 수 있다.
- 버킷 액세스 제어 목록
- 버킷이 퍼블릭으로 오픈되어있어도 해당 설정이 안되어있으면 버킷은 공개되지 않는다.
- 버킷 수준에서 살펴보면 버킷 ACL이 있는데 훨씬 덜 일반적. 비활성화가 가능하다.
암호 키를 사용한 객체 암호화
S3 버전 관리
- Amazon S3에서는 파일을 버전 관리할 수 있다.
- 해당 설정은 버킷에서 허용을 해야 한다.
- 사용자가 파일을 업로드할 때마다 선택 키에서 해당 파일의 버전이 생성된다.
- 동일한 키를 업로드하고 해당 파일을 덮어쓰는 경우 버전 2, 버전 3 등을 생성하게 된다.
- 버킷을 버전 관리하는 것이 좋다. 이 방법은 의도하지 않게 삭제하지 않도록 보호해주기 때문이다.
- 이전 버전으로 복구 가능하다. 버전을 제거하면 삭제 마커가 붙게 되는데, 삭제 마커를 제거하면 이전 버전으로 복구 가능하다.
- 버전 관리를 활성화하기 전에 버전 관리가 적용되지 않은 모든 파일은 널(null) 버전을 갖게 된다.
- 버전 관리를 중단해도 이전 버전을 삭제하지 않는다.
S3 복제
- 교차 리전 복제 CPR: 두 리전이 다를 때 사용한다.
- 같은 리전 복제 SRR: 두 리전이 같을 때 사용한다.
- 버킷은 서로 다른 AWS 계정간에도 사용할 수 있다. 복제는 비동기식으로 이루어진다. 복제 과정은 백그라운드에서 이루어진다.
- 복제 기능이 정상적으로 실행되려면, S3에 올바른 IAM 권한, 즉 읽기, 쓰기 권한을 S3에 부여해야 한다.
- 복제를 활성화한 후에는 보셨다시피 새로운 객체만 복제 대상이 된다.
- 기존의 객체를 복제하려면 S3 배치 복제 기능을 사용해야 한다.
- 기존 객체부터 복제에 실패한 객체까지 복제할 수 있는 기능이다.
- 체이닝 복제는 불가능하다.
- ex) A Bucket -> B Bucket 복제 설정, B Bucket -> C Bucket 복제 설정을 했을때, A Bucket의 내용이 C Bucket 내용으로 복제되지 않는다.
스토리지 클래스
S3 standard - General Purpose
- 제일 기본 클래스
- 99.99% 가용성
- 자주 액세스하는 데이터에 사용한다.
- 지연 시간이 짧고 처리량이 높다.
- AWS에서 두 개의 기능 장애를 동시에 버틸 수 있다.
- 사용 사례는 빅데이터 분삭, 모바일, 게임 애플리케이션, 그리고 콘텐츠 배포다.
S3 standard-Infrequent Access (IA)
- 자주 액세스하지는 않지만 필요한 경우 빠르게 액세스해야하는 데이터에서 사용한다.
- 99.9% 가용성
- 스탠다드보다는 비용이 적게 들지만 검색 비용이 발생한다.
- 재해 복구와 백업에서 많이 사용한다.
S3 One Zone-Infrequent Access
- 단일 AZ 내에서는 높은 내구성을 갖지만 AZ가 파괴된 경우 데이터를 잃는다.
- 가용성은 99.5%
- 온프레미스 데이터를 2차 백업하거나 재생성 가능한 데이터를 저장하는데 사용하는 경우가 있다.
S3 Glacier Instant Retrieval
- 밀리초 단위로 검색이 가능하다.
- 분기에 한 번 액세스하는 데이터에 아주 적합하다.
- 최소 보관기간이 90일. 백업이지만 밀리초 이내에 액세스해야하는 경우 적합하다.
S3 Glacier Flexible Retrieval
- Flexible는 데이터를 검색하는 데 최대 12시간까지 기다려야 한다는 의미다.
- 3가지 옵션이 있다. 최소 보관 기간은 역시 90일
- Expedited: 데이터를 1 ~ 5분 이내에 받을 수 있다.
- Standard: 데이터를 돌려 받는데 3 ~ 5시간이 걸린다.
- Bulk: 무료지만 5 ~ 12시간이 소요된다.
S3 Glacier Deep Archive
- 장기 보관을 위한 스토리지 클래스. 두 가지 검색 티어가 있다.
- Standard: 12시간
- Bulk: 48시간
- 최소 보관기간도 180일, 오래 걸리지만 가장 저렴하다.
글래시어 스토리지 클래스는 아카이빙과 백업을 위한 저비용 객체 스토리지다.
비용은 스토리지 비용과 검색 비용이 들어간다.
S3 Intelligent Tiering
- 사용 패턴에 따라 액세스된 티어 간에 객체를 이동할 수 있게 해준다.
- 소액의 월별 모니터링 비용과 티어링 비용이 발생하지만 검색 비용이 없다.
- FrequentAccess 티어는 자동이고 기본 티어다.
- Infrequent Access 티어는 30일 동안 액세스하지 않는 객체 전용 티어
- Archive Instant Access 티어도 자동이지만 90일 동안 액세스하지 않는 티어 전용
- Archive Access 티어는 선택 사항이며 90일에서 700일 이상까지 구성할 수 있고
- 선택 사항인 Deep Archive Access 티어는 180일에서 700일 이상 액세스하지 않는 객체에 구성할 수 있다.
- S3 Intelligent Tiering은 알아서 객체를 이동시켜
