에어플로우는 데이터 엔지니어(DE)와 데이터 애널리틱스 엔지니어(DAE)라면 반드시 알아야 하는 툴 중 하나인데요. 데이터 파이프라인을 구축하고 운영하는 데 있어 핵심적인 역할을 하며, 복잡한 데이터 워크플로우를 효율적으로 관리할 수 있게 해주는 필수 도구입니다.
에어플로우(Airflow)란?

에어플로우는 ‘Job Orchestration tool’입니다. 즉, 복잡한 데이터 처리 작업을 자동화하고 관리하는 도구이다.
-
마치 오케스트라 지휘자처럼 여러 작업의 실행 순서와 의존성을 조율합니다.
-
에어플로우에선 데이터 파이프라인을 프로그래밍 방식으로 작성, 스케줄링 및 모니터링할 수 있습니다.
주로 데이터 엔지니어, 애널리틱스 엔지니어가 사용하며, 가장 큰 장점은 파이썬 코드로 파이프라인을 정의할 수 있다는 점입니다.
-
이는 단순히 설정 파일로 작업을 정의하는 것보다 훨씬 더 유연하고 강력한 기능을 제공하죠.
- 예를 들어, 조건문과 반복문을 사용해 동적으로 태스크를 생성할 수 있고, 기존 파이썬 라이브러리를 활용할 수도 있습니다.
에어플로우는 확장성도 뛰어납니다.
-
AWS, GCP, Azure 등 클라우드 서비스부터 Hadoop, Spark, Presto 같은 빅데이터 도구까지, 다양한 시스템과의 연동을 위한 수많은 플러그인을 제공합니다.
- 이러한 풍부한 생태계 덕분에 거의 모든 데이터 처리 작업을 에어플로우로 통합할 수 있습니다.
실제 운영 측면에서도 웹 기반의 직관적인 인터페이스를 통해 복잡한 파이프라인 상태를 한눈에 파악할 수 있고, 문제가 발생했을 때 빠르게 대응할 수 있습니다.
- 특히 실패한 태스크의 자동 재시도나 알림 설정 같은 기능들은 운영자의 부담을 크게 줄여주죠.
데이터, 그리고 데이터 파이프라인
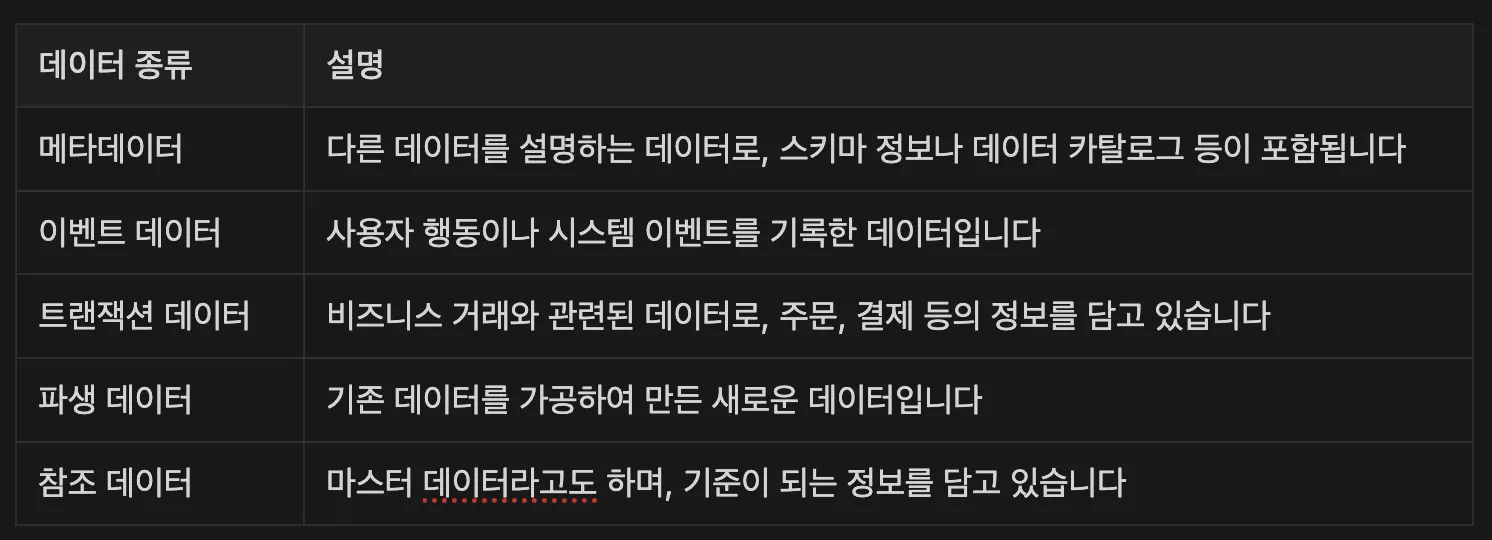
데이터의 종류
- 우리가 다루는 데이터는 크게 메타데이터와 이벤트 데이터로 나눌 수 있는데요. 그 역할에 따라 여러 종류로 분류할 수도 있습니다.
데이터 파이프라인
데이터 파이프라인은 데이터가 소스에서 목적지까지 이동하는 전체 과정을 의미합니다.
-
현대의 데이터 파이프라인 두 가지 방식
-
ETL(Extract, Transform, Load)과
-
ELT(Extract, Load, Transform)
-
-
ETL은 전통적인 방식으로, 데이터를 추출하여 변환한 후 적재하는 방식입니다.
-
ELT는 먼저 데이터를 추출하여 적재한 후, 필요에 따라 변환하는 현대적인 접근 방식입니다.
- 특히 OLAP(Online Analytical Processing) 환경에서는 ELT가 선호되는데, 이는 대규모 데이터 웨어하우스의 강력한 처리 능력을 활용할 수 있기 때문입니다.
-
OLAP 시스템은 복잡한 분석 쿼리를 효율적으로 처리할 수 있도록 설계되었습니다.
-
Snowflake, Redshift, BigQuery 같은 현대적인 데이터 웨어하우스들은 컬럼 기반 저장소와 대규모 병렬 처리를 통해 빠른 분석을 가능하게 합니다.
-
현대의 데이터 파이프라인은 실시간 처리와 배치 처리를 모두 지원해야 하는데요. 실시간 처리는 Kafka, Spark Streaming 등을 통해 이루어지며, 배치 처리는 Airflow와 같은 도구를 통해 정기적으로 수행되죠.
-
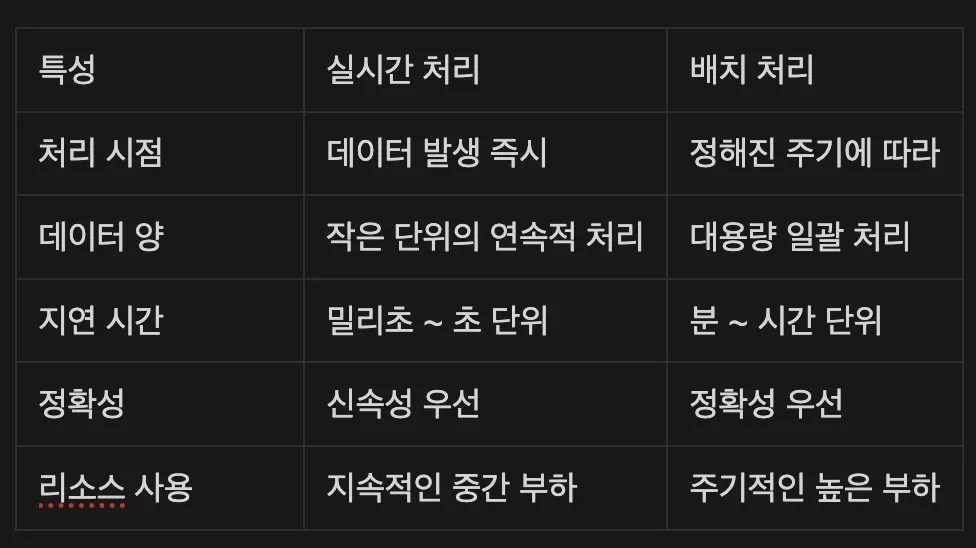
실시간 처리 vs 배치 처리
-
데이터 처리 방식
-
실시간
-
실시간 처리는 즉각적인 대응이 필요한 상황에서 필수적입니다.
-
예를 들어, 금융 거래에서 부정 거래를 탐지하는 경우, 거래가 발생하는 순간 패턴을 분석하여 이상 징후를 감지해야 하죠.
-
또한 사용자의 현재 행동에 기반한 실시간 추천 시스템이나 서비스 장애를 감지하는 모니터링 시스템에서도 실시간 처리가 중요한 역할을 합니다.
-
-
배치
-
Airflow의 역할
-
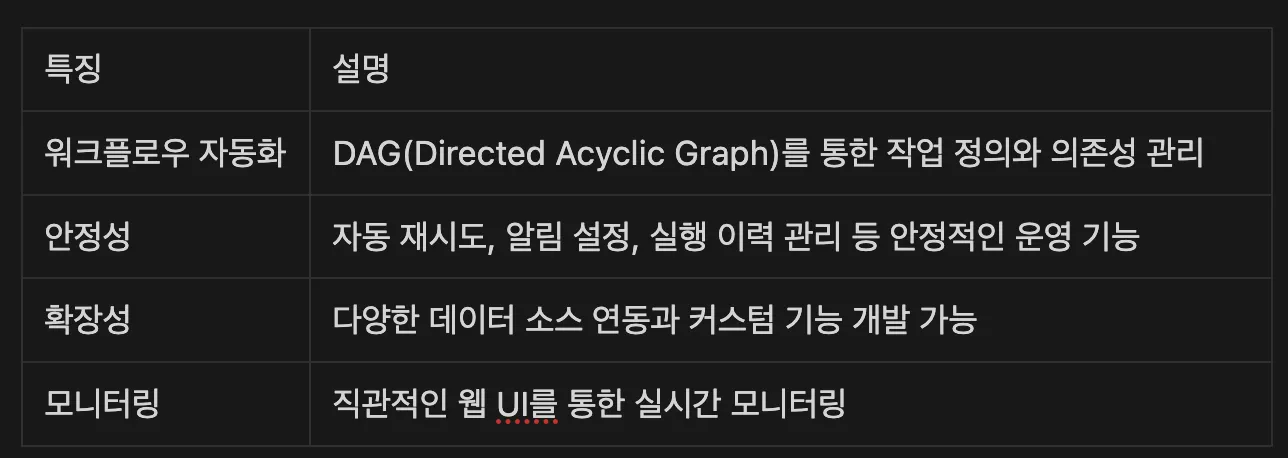
배치 처리 환경에서 Airflow는 데이터 파이프라인의 중추적인 역할을 담당합니다.
-
현재 데이터 엔지니어링 분야에서 가장 널리 사용되는 워크플로우 관리 도구로 자리 잡았는데, 이처럼 표준이 된 이유는 다음과 같습니다.
-
실제 기업들은 Airflow를 다음과 같은 배치 작업에 활용하고 있습니다.
-
데이터 웨어하우스 테이블 새로고침(Daily/Weekly)
-
비즈니스 인텔리전스 리포트 자동 생성
-
데이터 품질 검사 자동화
-
ML 모델 정기적인 재학습
-
로그 데이터 아카이빙
-
-
특히 분석 환경에서는 데이터의 신선도(Freshness)와 품질(Quality)이 매우 중요한데, Airflow는 이러한 요구사항을 효과적으로 충족시켜 줍니다.
- 예를 들어, 매일 아침 9시에 전날의 데이터를 집계하고, 품질 체크를 수행한 후 이상이 없다면, BI 대시보드를 갱신하는 일련의 과정을 자동화할 수 있습니다.
Airflow 전체 구성요소
앞서 설명한 DAG와 Task 외에도 Airflow는 다양한 구성 요소로 이루어져 있습니다. 마치 정교한 시계처럼 여러 부품이 조화롭게 작동하는 시스템이죠.
-
구성 요소들의 워크플로우를 시각화하면 다음과 같습니다.
-
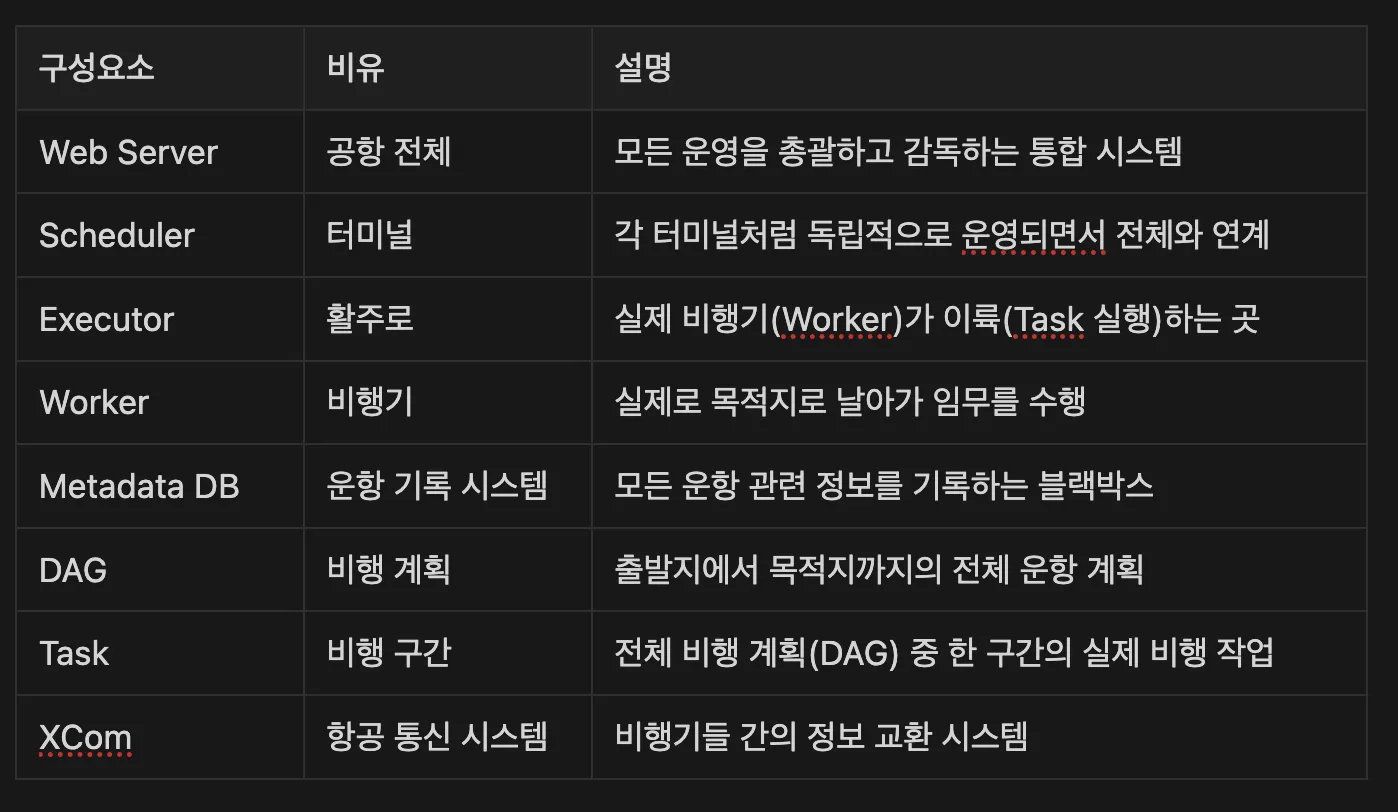
Airflow는 인천공항과 같은 곳으로, 각 구성 요소가 맡은 역할이 있고, 이들이 서로 협력하면서 안정적인 워크플로우 실행을 가능하게 만들어 줍니다.
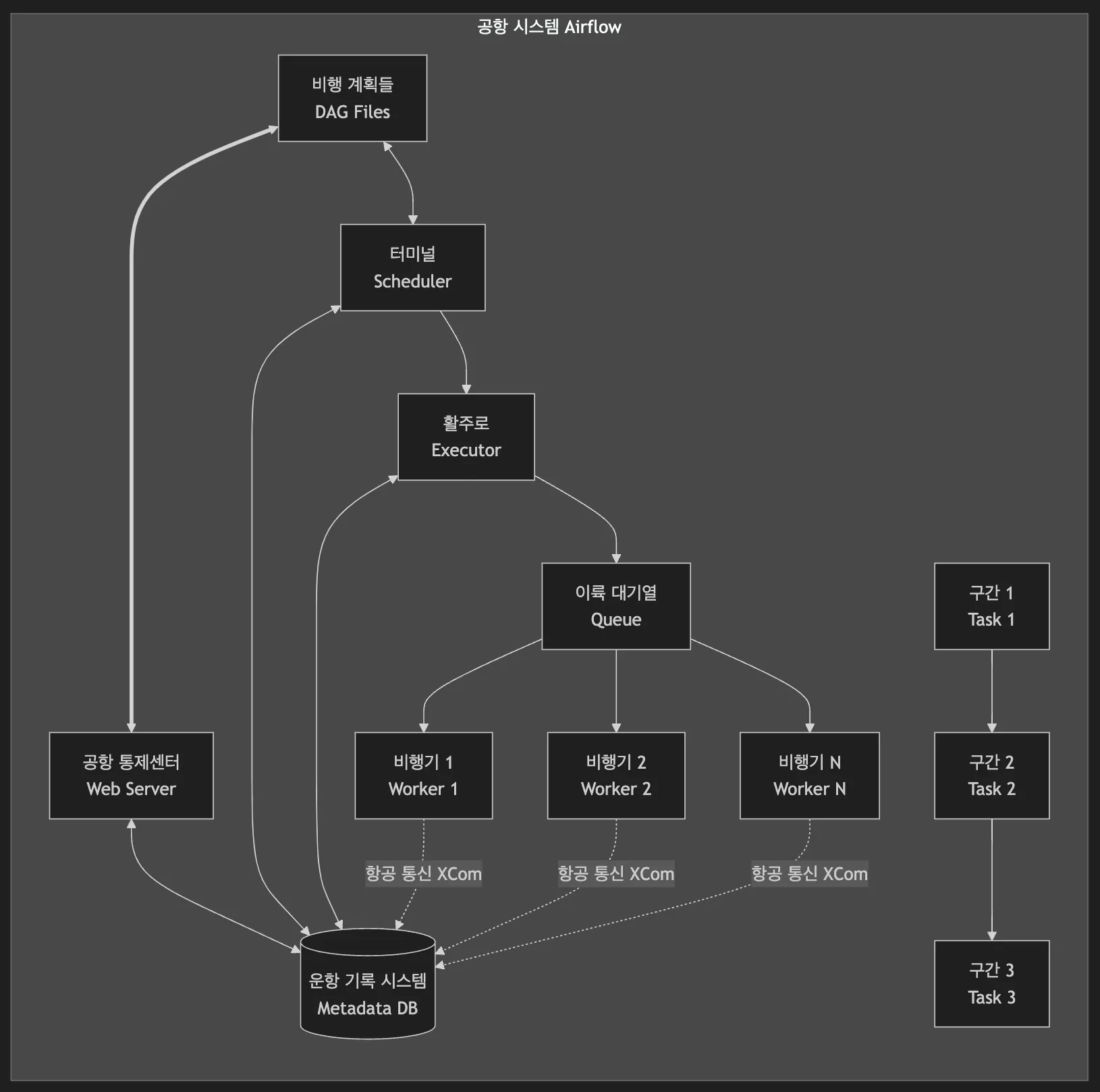
-
Web Server(웹 서버): 공항 전체
-
웹 서버는 인천공항과 같은 공항 전체라고 생각하면 됩니다.
-
하나의 거대한 시스템으로서, 모든 운영을 총괄하고 감독하는 역할을 하죠.
-
공항이 터미널, 활주로, 관제탑을 통합 관리하듯이, 웹 서버도 여러 스케줄러, Executor, Worker를 하나의 시스템으로 통합해서 관리합니다.
-
모든 운영 현황은 대시보드(공항의 중앙 관제 시스템)를 통해 한눈에 파악할 수 있죠.
-
-
Scheduler(스케줄러): 터미널
-
스케줄러는 공항의 터미널과 같습니다.
-
인천공항의 T1, T2처럼 여러 개의 터미널이 동시에 운영될 수 있죠.
- 각 터미널은 독립적으로 운영되면서도 전체 공항 시스템과 긴밀하게 연계됩니다.
-
각 터미널이 자신의 게이트와 비행기들을 관리하듯이, 각 스케줄러도 자신에게 할당된 DAG를 독립적으로 관리합니다.
- 한 터미널에 문제가 생겨도 다른 터미널은 정상 운영될 수 있는 것처럼, 여러 스케줄러를 운영하면 시스템의 안정성과 확장성을 높일 수 있습니다.
-
-
Worker(작업자): 비행기
-
Worker는 실제로 하늘을 나는 비행기입니다.
-
활주로를 통해 이륙한 비행기들이 각자의 목적지를 향해 날아가듯이, Worker는 각자 할당받은 Task를 수행합니다.
-
각 비행기가 독립적으로 운항하면서도 관제 시스템과 지속적으로 통신하듯이, Worker도 독립적으로 작업을 수행하면서 중앙 시스템과 상태를 공유하죠.
-
-
Executor(실행기): 활주로
-
Executor는 터미널에 속한 활주로입니다.
-
각 터미널마다 여러 개의 활주로를 가질 수 있고, 이 활주로를 통해 실제 비행기(Worker)들이 이륙(Task)하게 됩니다.
-
공항마다 활주로 운영 방식이 다르듯이, Airflow도 상황에 맞는 다양한 Executor를 선택할 수 있습니다.
-
가장 기본이 되는 SequentialExecutor는 작은 지방 공항처럼 활주로가 하나밖에 없습니다.
- 비행기가 아무리 많아도 한 번에 한 대씩만 이륙할 수 있죠. 개발 환경이나 테스트용으로는 충분하지만, 실제 운영 환경에서는 비효율적일 수도 있습니다.
-
CeleryExecutor는 인천공항처럼 대형 국제공항입니다. 여러 터미널에 많은 활주로가 있어서 수많은 비행기를 동시에 처리할 수 있습니다. 다른 지역의 공항과도 긴밀하게 협력하면서 운영됩니다.
-
KubernetesExecutor는 미래의 스마트 공항이라고 할 수 있는데요. 필요할 때마다 활주로를 자동으로 만들고, 사용이 끝나면 다른 용도로 전환할 수 있습니다. 각 비행기는 완벽하게 독립된 공간에서 운영되며, 자원도 효율적으로 관리되죠.
-
-
Metadata Database(메타데이터 데이터베이스): 항공 운항 기록 시스템
-
메타데이터 데이터베이스는 공항의 운항 기록 시스템입니다.
-
모든 비행기의 이착륙 시간, 운항 경로, 특이 사항 등을 꼼꼼히 기록하는 블랙박스와 같은 역할을 합니다.
-
마치 항공사가 과거 운항 기록을 분석하여 더 효율적인 스케줄을 짜고 안전성을 높이듯이, 이 기록들은 파이프라인 최적화와 문제 해결에 귀중한 자료가 됩니다.
-
예를 들어, 특정 노선(Task)에서 지연이 자주 발생한다면, 그 원인을 파악하고 개선할 수 있죠. 중요한 점은 운영 환경에서는 반드시 PostgreSQL이나, MySQL과 같은 프로덕션급 데이터베이스를 사용해야 한다는 것입니다.
-
기본으로 설정되는 SQLite는 개발 환경에서만 사용해야 합니다. SQLite는 동시 접근을 제대로 처리하지 못하기 때문에, 여러 스케줄러나 워커가 동시에 접근하면 데이터베이스 잠금 문제가 발생할 수 있습니다. 특히 CeleryExecutor, KubernetesExecutor를 사용할 때는 PostgreSQL 또는 MySQL 사용이 필수적입니다. 이러한 분산 환경에서는 안정적인 동시성 제어와 트랜잭션 관리가 매우 중요하기 때문이죠.
-
-
-
실제 운영 환경에서는 단순히 기능을 아는 것을 넘어, 시스템 아키텍처에 대한 이해가 매우 중요합니다. Web Server, Scheduler, Worker, Executor 등 각 구성 요소들이 어떻게 협력하여 작동하는지 이해함으로써, 더 안정적이고 효율적인 파이프라인을 구축할 수 있습니다.
- 2025년 3.0 버전 출시를 계획 중인 Airflow는 계속해서 발전하고 있는 도구입니다. 꾸준히 새로운 기능을 선보이고 있고, 커뮤니티도 활발하게 운영되죠. 앞으로 데이터 파이프라인의 복잡성은 더 증가할 것으로 보여, Airflow 같은 워크플로우 관리 도구의 중요성도 커질 것입니다.
