-
일괄 처리(batch processing)란 컴퓨터 프로그램 흐름에 따라 순차적으로 자료를 처리하는 방식을 뜻한다.
- 초기의 일괄처리 방식은 사용자와 상호작용하는 것이 불가능했지만, 운영 체제가 발전함에 따라 프로그램 입출력을 통해 상호작용하는 것이 가능해졌다. 일괄 처리는 1950년대 전자 컴퓨팅 초기 시절 이후 메인프레임 컴퓨터와 함께하고 있다.
-
개별적으로 어떤 요청이 있을 때마다 실시간으로 통신하는 것이 아닌 한꺼번에 일괄적으로 대량 건을 처리하는 것입니다.
- 특히 배치는 보통 정해진 특정한 시간에 실행됩니다.
사실 배치를 구현하기 위한 다양한 방법들이 있습니다. shell 스크립트로도 가능하고, 스프링에서도 가능합니다.
-
배치의 특징
-
대량건의 데이터를 처리한다.
-
특정 시간에 실행된다.
-
일괄적으로 처리한다.
-
-
배치프로그램을 사용하는 이유
- 업무의 효율성과 비효율적인 시스템의 과부하를 줄이기 위해서입니다.
예시
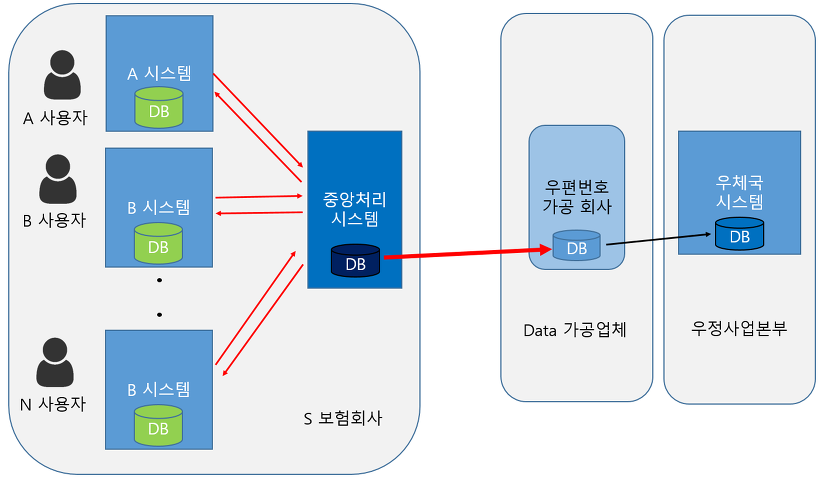
S라는 보험회사 안에 있는 다양한 시스템들이 수십 아니 수백 개 존재한다고 생각해봅시다.
-
이 모든 시스템들은 고객의 우편번호를 알아야 합니다. 또한, S보험은 수백만명의 고객들을 보유하고 있습니다.
-
예를 들어 매일매일 우편번호가 조금씩 수정되고 바뀐다고 가정해봅시다.
-
더 구체적으로 상황을 설정해 봅시다. 주택 하나를 허물고 그자리에 2개의 건물이 지어진다면, 다시 기존 우편번호를 회수하거나 없애고 새로 지어진 건물 2개에 대한 우편번호를 국가에서 발급해줘야 합니다.
- 이런 일들이 매일 일어날수도 있고, 가끔 일어날 수 있지만, S보험회사에선 그거까지 알 필요가 없습니다. 다만 매일 우편번호에 대한 최신 데이터를 가져와야합니다.
-
-
자 보험회사 업무시간에 또는 시스템이 정상적인 업무에 이용되는 시간인 09:00~20:00시에 이런 작업을 하면 좋을까요? 당연히 좋지 않습니다. 시스템의 과부하를 주기 때문이죠
- 그렇다면, 아무도 시스템을 사용하지 않는 새벽시간에 조용히 우체국 시스템에 DB를 조회해 우편번호를 가져오면 됩니다.
-
여기서 배치의 특징이 나옵니다. 소량이 아닌 대량건의 데이타를 특정시간(여기서는 새벽시간)에 가져오는 것입니다.
-
또한, S보험시스템엔 A, B, C 등 여러개의 시스템이 있지만 이 시스템이 개별적으로 우체국 시스템 DB에 접근한다면, 비효율적일 것입니다.
-
따라서 이를 대표할 수 있는 중앙처리 시스템이 대표로 한번만 우체국 시스템의 DB에 접근해 우편번호를 가져오는 것입니다! <- 일괄처리 개념
-
여기서 우편번호 가공회사를 거치는 이유
- 우체국시스템은 정말 낱개의 우편번호 즉 한자리 한자리만 저장합니다.
- 알아서 가져다 쓰라는 것이지요
- 만약 S보험회사, K보험회사, H보험회사 마다 우편번호가 필요한데 각각 우편번호의 형식을 다르게 가져오고 싶은 것입니다.
- S보험회사는 000-000 같은 형식
- K보험회사는 000000 같은 형식
- H보험회사는 00-00-00 같은 형식으로 말이죠.
- 그러면 이를 우체국시스템이 모두 커버해 줄 수 없습니다. 따라서 우편번호를 가공해주는 제3의 데이터가공 회사가 우편번호를 찾는 고객에 맞게 내가 대신 우편번호를 가공해줄께 하고 가공한 데이터를 제공합니다. 대신 비용을 청구
-
S보험회사의 대표인 중앙처리시스템이 대표로 S보험회사가 보유하고 있는 수백만명의 고객의 우편번호를 가져옵니다
- 1차적으로 배치프로그램이 작동한 것
-
이제 중앙처리시스템이 가져왔으니, S보험회사 안에 있는 모든 시스템들에게 필요하면 너네가 알아서 새벽에 적당한 시간에 가져가 라고 말합니다.
- 그럼 A, B, C .... 등등 의 시스템들이 2차적으로 배치프로그램 돌려 자신의 시스템에 우편번호를 업데이트 합니다.
💨대규모 시스템에서 배치는 필수이고, 반드시 알아야 할 개념
