C++ 표준 템플릿 라이브러리 (Standard Template Library - STL)
-
보통 C++ 템플릿 라이브러리(STL)를 일컫는다면 다음과 같은 세 개의 라이브러리들을 의미
-
임의 타입의 객체를 보관할 수 있는 컨테이너 (container)
-
컨테이너에 보관된 원소에 접근할 수 있는 반복자 (iterator)
-
반복자들을 가지고 일련의 작업을 수행하는 알고리즘 (algorithm)
-
-
각 라이브러리의 역할을 쉽게 생각하면 다음과 같이 볼 수 있습니다.
여러분이 우편 배달부가 되어서 편지들을 여러개의 편지함에 넣는다고 생각해봅시다. 편지를 보관하는 각각의 편지함들은 '컨테이너' 라고 생각하시면 됩니다.
그리고, 편지를 보고 원하는 편지함을 찾는 일은 '반복자' 들이 수행하지요.
마지막으로, 만일 편지들을 편지함에 날짜 순서로 정렬하여 넣는 일은 '알고리즘' 이 수행할 것입니다.
C++ STL 컨테이너 - 벡터 (std::vector)
-
C++ STL 에서 컨테이너는 크게 두 가지 종류가 있습니다.
-
시퀀스 컨테이너 (sequence container)
: 배열 처럼 객체들을 순차적으로 보관
- 시퀀스 컨테이너의 경우
vector, list, deque이렇게 3 개가 정의되어 있습니다.
- 시퀀스 컨테이너의 경우
-
연관 컨테이너 (associative container)
: 키를 바탕으로 대응되는 값을 찾아주는
-
-
벡터(vector)
-
쉽게 생각하면 가변길이 배열
-
벡터에는 원소들이 메모리 상에서 실제로 순차적으로 저장되어 있고, 따라서 임의의 위치에 있는 원소를 접근하는 것을 매우 빠르게 수행할 수 있습니다.
-
-
vector의 임의의 원소에 접근하는 것은 배열처럼[]를 이용하거나,at함수를 이용하면 됩니다. -
벡터의 크기를 리턴하는 함수인
size의 경우, 리턴하는 값의 타입은size_type멤버 타입으로 정의되어 있습니다. -
맨 뒤에 원소를 추가하거나 제거하기 위해서는
push_back혹은pop_back함수를 사용하면 됩니다. 아래 예를 보겠습니다.
#include <iostream>
#include <vector>
int main() {
std::vector<int> vec;
vec.push_back(10); // 맨 뒤에 10 추가
vec.push_back(20); // 맨 뒤에 20 추가
vec.push_back(30); // 맨 뒤에 30 추가
vec.push_back(40); // 맨 뒤에 40 추가
for (std::vector<int>::size_type i = 0; i < vec.size(); i++) {
std::cout << "vec 의 " << i + 1 << " 번째 원소 :: " << vec[i] << std::endl;
}
}
/*
vec 의 1 번째 원소 :: 10
vec 의 2 번째 원소 :: 20
vec 의 3 번째 원소 :: 30
vec 의 4 번째 원소 :: 40
*/
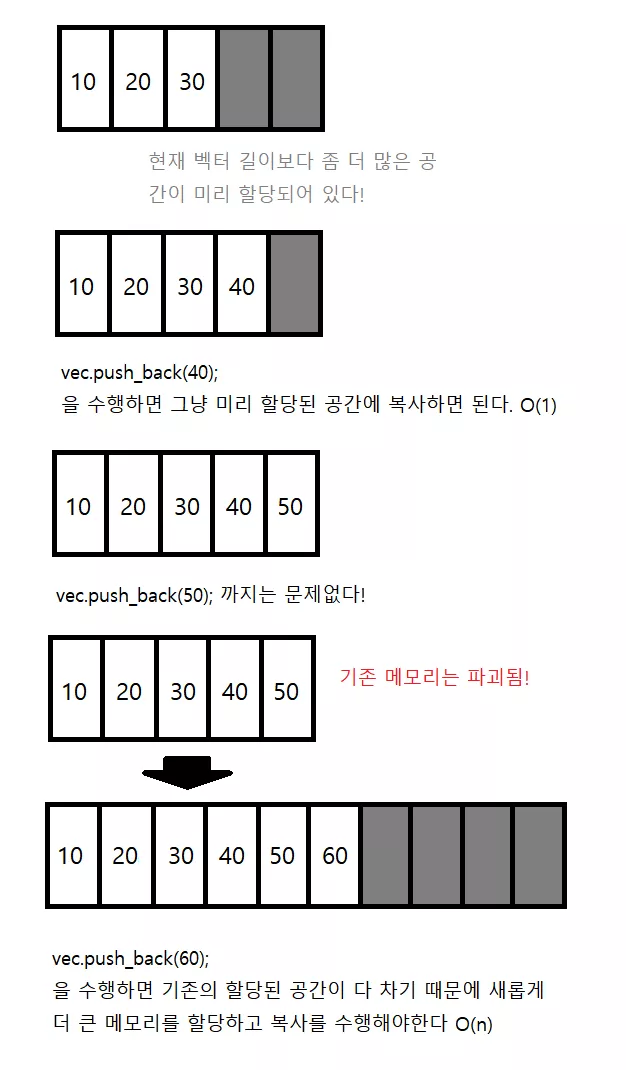
<vector 의 복잡도>
-
임의의 위치 원소 접근 ([], at) : O(1)
-
맨 뒤에 원소 추가 및 제거 (push_back/pop_back) : amortized O(1); (평균적으로 O(1) 이지만 최악의 경우 O(n) )
-
임의의 위치 원소 추가 및 제거 (insert, erase) : O(n)
반복자 (iterator)
-
vector의 경우 반복자를 얻기 위해서는begin()함수와end()함수를 사용할 수 있는데 이는 다음과 같은 위치를 리턴합니다.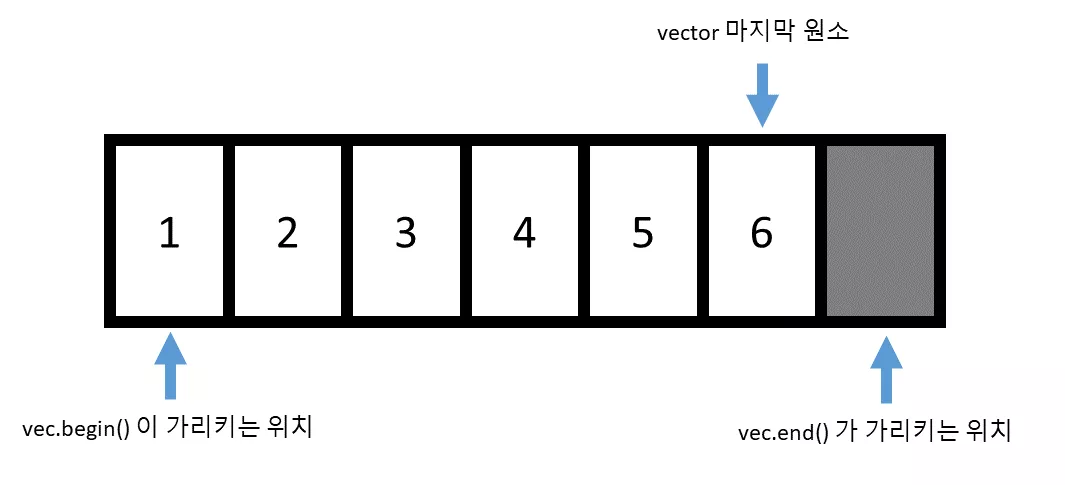
-
begin()함수는vector의 첫번째 원소를 가리키는 반복자를 리턴합니다. 그런데,end()의 경우vector의 마지막 원소 한 칸 뒤를 가리키는 반복자를 리턴하게 됩니다.-
이를 통해 빈 벡터를 표현할 수 있다는 점
-
begin() == end()라면 원소가 없는 벡터를 의미 -
vec.end()가 마지막 원소를 가리킨다면 비어있는 벡터를 표현할 수 없게 된다.
-
-
-
// 반복자 사용 예시
#include <iostream>
#include <vector>
int main() {
std::vector<int> vec;
vec.push_back(10);
vec.push_back(20);
vec.push_back(30);
vec.push_back(40);
// 전체 벡터를 출력하기
for (std::vector<int>::iterator itr = vec.begin(); itr != vec.end(); ++itr) {
std::cout << *itr << std::endl;
}
// int arr[4] = {10, 20, 30, 40}
// *(arr + 2) == arr[2] == 30;
// *(itr + 2) == vec[2] == 30;
std::vector<int>::iterator itr = vec.begin() + 2;
std::cout << "3 번째 원소 :: " << *itr << std::endl;
}
-
vector의 반복자의 타입은 위 처럼std::vector<>::iterator멤버 타입으로 정의되어 있고,vec.begin()이나vec.end()함수가 이를 리턴합니다.end()가vector의 마지막 원소 바로 뒤를 가리키기 때문에 for 문에서vector전체 원소를 보고 싶다면vec.end()가 아닐 때 까지 반복하면 됩니다.
-
반복자를 마치 포인터 처럼 사용한다고 하였는데, 실제로 현재 반복자가 가리키는 원소의 값을 보고 싶다면 포인터로
*를 해서 가리키는 주소값의 값을 보았던 것처럼,*연산자를 이용해서itr이 가리키는 원소를 볼 수 있습니다.-
itr은 실제 포인터가 아니고*연산자를 오버로딩해서 마치 포인터 처럼 동작하게 만든 것입니다. -
*연산자는itr이 가리키는 원소의 레퍼런스를 리턴합니다.
-
-
반복자 역시
+연산자를 통해서 그 만큼 떨어져 있는 원소를 가리키게 할 수 도 있습니다.- 배열을 가리키는 포인터와 정확히 똑같이 동작한다.
- 반복자를 이용하면 아래와 같이
insert와erase함수도 사용할 수 있습니다.
#include <iostream>
#include <vector>
template <typename T>
void print_vector(std::vector<T>& vec) {
// 전체 벡터를 출력하기
for (typename std::vector<T>::iterator itr = vec.begin(); itr != vec.end();
++itr) {
std::cout << *itr << std::endl;
}
}
int main() {
std::vector<int> vec;
vec.push_back(10);
vec.push_back(20);
vec.push_back(30);
vec.push_back(40);
std::cout << "처음 벡터 상태" << std::endl;
print_vector(vec);
std::cout << "----------------------------" << std::endl;
// vec[2] 앞에 15 추가
vec.insert(vec.begin() + 2, 15);
print_vector(vec);
std::cout << "----------------------------" << std::endl;
// vec[3] 제거
vec.erase(vec.begin() + 3);
print_vector(vec);
}
-
vector에서 지원하는 반복자로const_iterator가 있습니다.-
const포인터를 생각하시면 됩니다. 즉,const_iterator의 경우 가리키고 있는 원소의 값을 바꿀 수 없습니다. -
cbegin()과cend()함수를 이용하여 얻을 수 있습니다.
-
#include <iostream>
#include <vector>
template <typename T>
void print_vector(std::vector<T>& vec) {
// 전체 벡터를 출력하기
for (typename std::vector<T>::iterator itr = vec.begin(); itr != vec.end();
++itr) {
std::cout << *itr << std::endl;
}
}
int main() {
std::vector<int> vec;
vec.push_back(10);
vec.push_back(20);
vec.push_back(30);
vec.push_back(40);
std::cout << "초기 vec 상태" << std::endl;
print_vector(vec);
// itr 은 vec[2] 를 가리킨다.
std::vector<int>::iterator itr = vec.begin() + 2;
// vec[2] 의 값을 50으로 바꾼다.
*itr = 50;
std::cout << "---------------" << std::endl;
print_vector(vec);
std::vector<int>::const_iterator citr = vec.cbegin() + 2;
// 상수 반복자가 가리키는 값은 바꿀수 없다. 불가능!
*citr = 30;
}
-
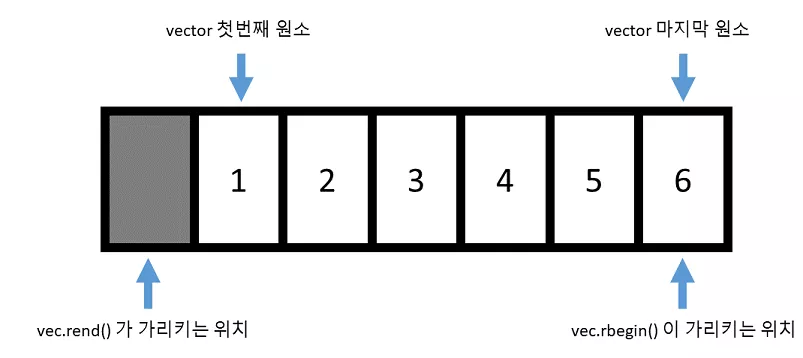
vector에서 지원하는 반복자 중 마지막 종류로역반복자 (reverse iterator)가 있습니다.- 반복자와 똑같지만 벡터 뒤에서 부터 앞으로 거꾸로 간다는 특징이 있습니다.
#include <iostream>
#include <vector>
template <typename T>
void print_vector(std::vector<T>& vec) {
// 전체 벡터를 출력하기
for (typename std::vector<T>::iterator itr = vec.begin(); itr != vec.end();
++itr) {
std::cout << *itr << std::endl;
}
}
int main() {
std::vector<int> vec;
vec.push_back(10);
vec.push_back(20);
vec.push_back(30);
vec.push_back(40);
std::cout << "초기 vec 상태" << std::endl;
print_vector(vec);
std::cout << "역으로 vec 출력하기!" << std::endl;
// itr 은 vec[2] 를 가리킨다.
std::vector<int>::reverse_iterator r_iter = vec.rbegin();
for (; r_iter != vec.rend(); r_iter++) {
std::cout << *r_iter << std::endl;
}
}
/*
실행 결과
초기 vec 상태
10
20
30
40
역으로 vec 출력하기!
40
30
20
10
*/
-
이전에 반복자의
end()가 맨 마지막 원소의 바로 뒤를 가리켰던 것처럼, 역반복자의rend()역시 맨 앞 원소의 바로 앞을 가리키게 됩니다.- 또한 반복자의 경우 값이 증가하면 뒤쪽 원소로 가는 것처럼, 역반복자의 경우 값이 증가하면 앞쪽 원소로 가게 됩니다.
for (std::vector<int>::size_type i = vec.size() - 1; i >= 0; i--) {
std::cout << vec[i] << std::endl;
}
-
vector의 index 를 담당하는 타입은 부호 없는 정수이다.-
i 가 0 일 때 i -- 를 하게 된다면 -1 이 되는 것이 아니라, 해당 타입에서 가장 큰 정수가 되버리게 된다.
따라서 for 문이 영원히 종료할 수 없게 된다.
-
이 문제를 해결하기 위해서는 부호 있는 정수로 선언해야 하는데, 이 경우 vector 의 index 타입과 일치하지 않아서 타입 캐스팅을 해야 한다는 문제 발생
-
가장 현명한 선택으로는 역으로 원소를 참조하고 싶다면, 역반복자를 사용하는 것입니다.
-
-
반복자가 상수 반복자가 있는 것 처럼 역반복자 역시 상수 역반복자가 있습니다.
- 타입은
const_reverse_iterator타입이고,crbegin(), crend()로 얻을 수 있습니다.
- 타입은
범위 기반 for 문 (range based for loop)
#include <iostream>
#include <vector>
int main() {
std::vector<int> vec;
vec.push_back(1);
vec.push_back(2);
vec.push_back(3);
// range-based for 문
for (int elem : vec) {
std::cout << "원소 : " << elem << std::endl;
}
return 0;
}
-
elem에vec의 원소들이 매 루프 마다 복사되서 들어가게 됩니다. -
복사 하기 보다는 레퍼런스를 받고 싶다면 단순히 레퍼런스 타입으로 바꿔버리면 된다.
for (const auto& elem : vec) {
std::cout << elem << std::endl;
}
- 위와 같이
const auto&로elem을 선언하였으므로,elem은vec의 원소들을 상수 레퍼런스로 접근하게 됩니다.
리스트 (list)
-
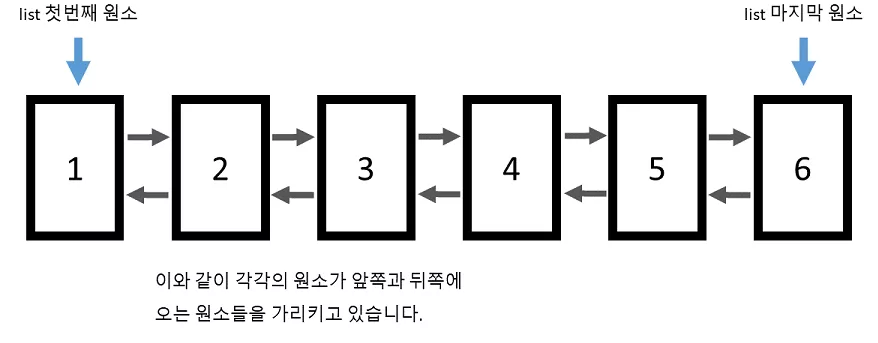
리스트(list)
: 양방향 연결 구조를 가진 자료형
-
vector와는 달리 임의의 위치에 있는 원소에 접근을 바로 할 수 없습니다.
-
list컨테이너 자체에서는 시작 원소와 마지막 원소의 위치만을 기억하기 때문에 임의의 위치에 있는 원소에 접근하기 위해서는 하나씩 링크를 따라가야 합니다.-
메모리 상에서 원소들이 연속적으로 존재하지 않을 수 있다.
-
리스트에는 아예
[]나at함수가 아예 정의되어 있지 않습니다.
-
itr++ // itr ++
itr-- // --itr 도 됩니다.
itr + 5 // 불가능!
-
vector의 경우 맨 뒤를 제외하고는 임의의 위치에 원소를 추가하거나 제거하는 작업이 O(n)이였지만 리스트의 경우 O(1) 으로 매우 빠르게 수행될 수 있다.- 원하는 위치 앞과 뒤에 있는 링크값만 바꿔주면 되기 때문입니다.
//insert
for (std::list<int>::iterator itr = lst.begin(); itr != lst.end(); ++itr) {
// 만일 현재 원소가 20 이라면
// 그 앞에 50 을 집어넣는다.
if (*itr == 20) {
lst.insert(itr, 50);
}
}
//erase
for (std::list<int>::iterator itr = lst.begin(); itr != lst.end(); ++itr) {
// 값이 30 인 원소를 삭제한다.
if (*itr == 30) {
lst.erase(itr);
break;
}
}
-
리스트의 경우는 벡터와는 다르게, 원소를 지워도 반복자가 무효화 되지 않는다.
- 각 원소들의 주소값들은 바뀌지 않기 때문
#include <iostream>
#include <list>
int main() {
std::list<int> lst;
lst.push_back(10);
lst.push_back(20);
lst.push_back(30);
lst.push_back(40);
for (std::list<int>::iterator itr = lst.begin(); itr != lst.end(); ++itr) {
std::cout << *itr << std::endl;
}
}
/*
10
20
30
40
*/
덱 (deque - double ended queue)
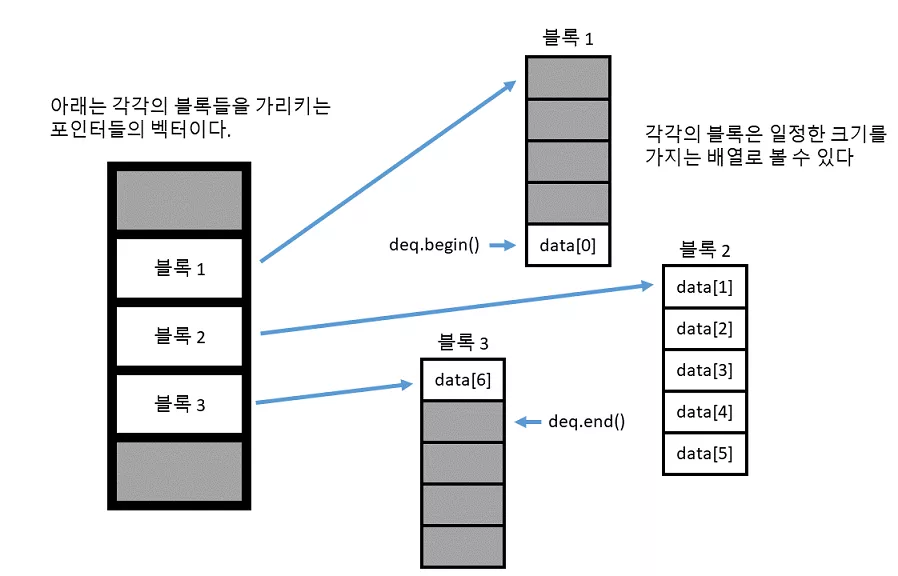
-
덱은 O(1) 으로 임의의 위치의 원소에 접근할 수 있으며,
맨 뒤에 원소를 추가/제거 하는 작업도 O(1) 으로 수행-
벡터와는 다르게 맨 앞에 원소를 추가/제거 하는 작업 까지도 O(1) 으로 수행 가능
-
임의의 위치에 있는 원소를 제거/추가 하는 작업은 벡터와 마찬가지로 O(n) 으로 수행 가능
- 속도도 벡터 보다 더 빠르다.
-
-
덱의 경우 원소들이 실제로 메모리 상에서 연속적으로 존재하지는 않습니다.
-
이 때문에 원소들이 어디에 저장되어 있는지에 대한 정보를 보관하기 위해 추가적인 메모리가 더 필요로 합니다.
- 예) 64 비트 libc++ 라이브러리의 경우 1 개의 원소를 보관하는 덱은 그 원소 크기에 비해 8 배나 더 많은 메모리를 필요로 합니다
-
즉 덱은 실행 속도를 위해 메모리를 (많이) 희생하는 컨테이너
-
-
원소들이 메모리에 연속되어 존재하는 것이 아니라 일정 크기로 잘려서 각각의 블록 속에 존재
- 이 블록들이 메모리 상에 어느 곳에 위치하여 있는지 저장하기 위해서 각각의 블록들의 주소를 저장하는 벡터가 필요
-
새로 할당 시에 앞쪽 및 뒤쪽 모두에 공간을 남겨놓는다.
-
벡터의 경우 뒤쪽에만 공간이 남는다.
-
이를 통해 맨 앞과 맨 뒤에 O(1) 의 속도로
insert및erase를 수행할 수 있다.- 기존의 원소들을 복사할 필요가 전혀 없다.
-
-
push_back과push_front를 이용해서 맨 앞과 뒤에 원소들을 추가 -
pop_front함수를 이용해서 맨 앞의 원소를 제거 -
덱 역시 벡터 처럼 임의의 위치에 원소에 접근할 수 있으므로
[]와at함수를 제공
#include <deque>
#include <iostream>
template <typename T>
void print_deque(std::deque<T>& dq) {
// 전체 덱을 출력하기
std::cout << "[ ";
for (const auto& elem : dq) {
std::cout << elem << " ";
}
std::cout << " ] " << std::endl;
}
int main() {
std::deque<int> dq;
dq.push_back(10);
dq.push_back(20);
dq.push_front(30);
dq.push_front(40);
std::cout << "초기 dq 상태" << std::endl;
print_deque(dq);
std::cout << "맨 앞의 원소 제거" << std::endl;
dq.pop_front();
print_deque(dq);
}
/*
초기 dq 상태
[ 40 30 10 20 ]
맨 앞의 원소 제거
[ 30 10 20 ]
*/
#include <bits/stdc++.h>
-
표준 라이브러리가 아니므로 파일을 따로 추가해 주어야 사용할 수 있다.
-
자주 사용하는 라이브러리들(vector, algorithm, string, 등..)을 컴파일하도록 함으로써 라이브러리들을 일일이 추가해야하는 번거로움을 없앨 수 있다.
-
단, 자주 사용하는 라이브러리들을 전부 컴파일함으로써, 사용하지 않거나 불필요한 라이브러리들도 컴파일이 되므로 그만큼 시간이나 공간이 낭비된다.
//stdc++.h
#pragma once
#include <cctype>
#include <cerrno>
#include <cfloat>
#include <ciso646>
#include <climits>
#include <clocale>
#include <cmath>
#include <csetjmp>
#include <csignal>
#include <cstdarg>
#include <cstddef>
#include <cstdio>
#include <cstdlib>
#include <cstring>
#include <ctime>
#include <ccomplex>
#include <cfenv>
#include <cinttypes>
#include <cstdalign>
#include <cstdbool>
#include <cstdint>
#include <ctgmath>
#include <cwchar>
#include <cwctype>
// C++
#include <algorithm>
#include <bitset>
#include <complex>
#include <deque>
#include <exception>
#include <fstream>
#include <functional>
#include <iomanip>
#include <ios>
#include <iosfwd>
#include <iostream>
#include <istream>
#include <iterator>
#include <limits>
#include <list>
#include <locale>
#include <map>
#include <memory>
#include <new>
#include <numeric>
#include <ostream>
#include <queue>
#include <set>
#include <sstream>
#include <stack>
#include <stdexcept>
#include <streambuf>
#include <string>
#include <typeinfo>
#include <utility>
#include <valarray>
#include <vector>
#include <array>
#include <atomic>
#include <chrono>
#include <condition_variable>
#include <forward_list>
#include <future>
#include <initializer_list>
#include <mutex>
#include <random>
#include <ratio>
#include <regex>
#include <scoped_allocator>
#include <system_error>
#include <thread>
#include <tuple>
#include <typeindex>
#include <type_traits>
#include <unordered_map>
#include <unordered_set>
이 파일을
C:\Program Files (x86)\Microsoft Visual Studio\2019\Community\VC\Tools\MSVC\14.24.28314\include
경로에서 bits 폴더를 생성한다. ( 해당 경로는 Visual studio가 설치된 기본적인 곳으로 없다면 본인이 찾아야 한다.)
그리고 생성한 bits 폴더 안에 다운 받은 stdc++.h 헤더 파일을 넣어주면 된다.
이제 #include <bits/stdc++.h> 를 선언하면 사용할 수 있다.
std::cout & std::cin
std::cout << /* 출력할 것 */ << /* 출력할 것 */ << ... << /* 출력할 것 */;
std::cout << std::endl; //엔터
- 예제
/* 1 부터 10 까지 합*/
#include <iostream>
int main() {
int i, sum = 0;
for (i = 1; i <= 10; i++) {
sum += i;
}
std::cout << "합은 : " << sum << std::endl;
return 0;
}
//합은 : 55
-
한 가지 달라진 점이 있다면 변수의 선언이 반드시 최상단에 있어야 되는 것은 아닙니다. 기존의 C 에서는 변수를 정의할 때 언제나 소스 맨 위부분에 선언을 하였습니다.
-
C++ 에서는 변수를 사용하기 직전 어느 위치에서 든지 변수를 선언할 수 있게 됩니다.
- 응용
// switch 문 이용하기
#include <iostream>
using std::cout;
using std::endl;
using std::cin;
int main() {
int user_input;
cout << "저의 정보를 표시해줍니다" << endl;
cout << "1. 이름 " << endl;
cout << "2. 나이 " << endl;
cout << "3. 성별 " << endl;
cin >> user_input;
switch (user_input) {
case 1:
cout << "Psi ! " << endl;
break;
case 2:
cout << "99 살" << endl;
break;
case 3:
cout << "남자" << endl;
break;
default:
cout << "궁금한게 없군요~" << endl;
break;
}
return 0;
}
참조자
#include <iostream>
int change_val(int *p) {
*p = 3;
return 0;
}
int main() {
int number = 5;
std::cout << number << std::endl;
change_val(&number);
std::cout << number << std::endl;
}
-
change_val함수의 인자p에number의 주소값을 전달하여,*p를 통해number를 참조하여number의 값을3으로 바꾸었습니다.-
C 언어에서는 어떠한 변수를 가리키고 싶을 땐 반드시 포인터를 사용해야만 했습니다.
-
그런데 C++ 에서는 다른 변수나 상수를 가리키는 방법으로 또 다른 방식을 제공하는데, 이를 바로 참조자(레퍼런스 - reference) 라고 부릅니다.
-
#include <iostream>
int main() {
int a = 3;
int& another_a = a;
another_a = 5;
std::cout << "a : " << a << std::endl;
std::cout << "another_a : " << another_a << std::endl;
return 0;
}
//a : 5
//another_a : 5
-
a의 참조자another_a를 정의-
이 때 참조자를 정하는 방법은, 가리키고자 하는 타입 뒤에
&를 붙이면 됩니다. -
위 처럼 int 형 변수의 참조자를 만들고 싶을 때에는
int&를, double 의 참조자를 만드려면double&로 하면 됩니다. -
int * 와 같은 포인터 타입의 참조자를 만드려면
int*&로 쓰면 됩니다.
-
포인터와 참조자의 차이점
-
레퍼런스는 반드시 처음에 누구의 별명이 될 것인지 지정해야 한다.
-
레퍼런스가 한 번 별명이 되면 절대로 다른 이의 별명이 될 수 없다.
int a = 10;
int &another_a = a; // another_a 는 이제 a 의 참조자!
int b = 3;
another_a = b; // ??
// another_a 에 무언가를 하는 것은 사실상 a 에 무언가를 하는 것과 동일
//문장은 그냥 a = b 와 동치
- 레퍼런스는 메모리 상에 존재하지 않을 수도 있다.
-
만일 내가 컴파일러라면
another_a위해서 메모리 상에 공간을 할당할 필요가 있을까요?
another_a가 쓰이는 자리는 모두a로 바꿔치기 하면 되니까요. 따라서 이 경우 레퍼런스는 메모리 상에 존재하지 않게 됩니다.- 물론 그렇다고 해서 항상 존재하지 않은 것은 아닙니다.
<함수인자로 참조자(레퍼런스) 받기>
#include <iostream>
int change_val(int &p) { //함수 인자로 참조자
p = 3;
return 0;
}
int main() {
int number = 5;
std::cout << number << std::endl;
change_val(number);
std::cout << number << std::endl;
}
-
포인터가 인자일 때와는 다르게
number앞에&를 붙일 필요가 없다는 점입니다. 이는 참조자를 정의할 때 그냥int& a = b와 같이 한 것과 일맥상통합니다. -
그 후
change_val안에서p = 3;이라 하는 것은main함수의number에number = 3;을 하는 것과 정확히 같은 작업입니다.
상수의 참조자
-
C++ 문법 상 상수 리터럴을 일반적인 레퍼런스가 참조하는 것은 불가능하게 되어 있습니다.
-
상수 참조자로 선언한다면 리터럴도 참조 할 수 있습니다.
const int &ref = 4;
int a = ref;
//a = 4; 와는 문장과 동일하게 처리
참조자의 배열과 배열의 참조자
There shall be no references to references, no arrays of references, and no pointers to references
레퍼런스의 레퍼런스,레퍼런스의 배열, 레퍼런스의 포인터는 존재할 수 없다.
int& arr[2] = {a, b};
-
C++ 상에서 배열이 어떤 식으로 처리되는지 생각해봅시다.
-
문법 상 배열의 이름은 (
arr) 첫 번째 원소의 주소값으로 변환이 될 수 있어야 합니다. 이 때문에arr[1]과 같은 문장이*(arr + 1)로 바뀌어서 처리될 수 있기 때문이죠. -
그런데 주소값이 존재한다라는 의미는 해당 원소가 메모리 상에서 존재한다 라는 의미와 같습니다.
-
하지만 레퍼런스는 특별한 경우가 아닌 이상 메모리 상에서 공간을 차지 하지 않습니다.
-
따라서 이러한 모순 때문에 레퍼런스들의 배열을 정의하는 것은 언어 차원에서 금지가 되어 있는 것입니다.
-
- 그와 반대인 배열들의 레퍼런스 가 불가능 한 것은 아닙니다.
#include <iostream>
int main() {
int arr[3] = {1, 2, 3};
int(&ref)[3] = arr;
ref[0] = 2;
ref[1] = 3;
ref[2] = 1;
std::cout << arr[0] << arr[1] << arr[2] << std::endl;
return 0;
}
//231
-
위와 같이
ref가arr를 참조하도록 하였습니다.-
따라서
ref[0]부터ref[2]가 각각arr[0]부터arr[2]의 레퍼런스가 됩니다.- 포인터와는 다르게 배열의 레퍼런스의 경우 참조하기 위해선 반드시 배열의 크기를 명시해야 합니다.
-
따라서
int (&ref)[3]이라면 반드시 크기가3인int배열의 별명이 되어야 하고int (&ref)[5]라면 크기가5인int배열의 별명이 되어야 합니다.
-
<레퍼런스를 리턴하는 함수>
int function() {
int a = 2;
return a;
}
int main() {
int b = function();
return 0;
}
-
function안에 정의된a라는 변수의 값이b에 복사 되었습니다. 여기서 주목할 점은 복사 되었다는 점입니다.function이 종료되고 나면a는 메모리에서 사라지게 됩니다. 따라서 더 이상main안에서는a를 만날 길이 없습니다.
<지역변수의 레퍼런스를 리턴?>
int& function() {
int a = 2;
return a;
}
int main() {
int b = function();
b = 3;
return 0;
}
-
function의 리턴 타입은int&입니다. 따라서 참조자를 리턴하게 됩니다. 그런데 문제는 리턴하는function안에 정의되어 있는a는 함수의 리턴과 함께 사라진다는 점입니다.- 쉽게 말해 본체는 이미 사라졌지만 별명만 남아 있는 상황입니다.
-
이와 같이 레퍼런스는 있는데 원래 참조 하던 것이 사라진 레퍼런스를 댕글링 레퍼런스 (Dangling reference) 라고 부릅니다.
- Dangling 이란 단어의 원래 뜻은 약하게 결합대서 달랑달랑 거리는 것을 뜻하는데, 레퍼런스가 참조해야 할 변수가 사라져서 혼자서 덩그러니 남아 있는 상황과 유사하다고 보시면 됩니다.
-
따라서 위 처럼 레퍼런스를 리턴하는 함수에서 지역 변수의 레퍼런스를 리턴하지 않도록 조심해야 합니다.
<외부 변수의 레퍼런스를 리턴>
int& function(int& a) {
a = 5;
return a;
}
int main() {
int b = 2;
int c = function(b);
return 0;
}
-
위와 같이 인자로 받은 레퍼런스를 그대로 리턴 하고 있습니다.
-
function(b)를 실행한 시점에서a는main의b를 참조하고 있게 됩니다.- 따라서
function이 리턴한 참조자는 아직 살아있는 변수인b를 계속 참조 합니다.
- 따라서
-
참조자를 리턴하는 경우의 장점
-
C 언어에서 엄청나게 큰 구조체가 있을 때 해당 구조체 변수를 그냥 리턴하면 전체 복사가 발생해야 해서 시간이 오래걸리지만, 해당 구조체를 가리키는 포인터를 리턴한다면 그냥 포인터 주소 한 번 복사로 매우 빠르게 끝납니다.
-
마찬가지로 레퍼런스를 리턴하게 된다면 레퍼런스가 참조하는 타입의 크기와 상관 없이 딱 한 번의 주소값 복사로 전달이 끝나게 됩니다.
-
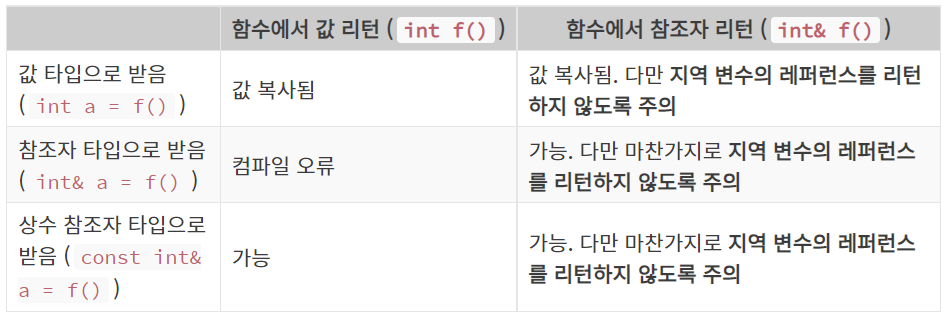
<참조자가 아닌 값을 리턴하는 함수를 참조자로 받기>
int function() {
int a = 5;
return a;
}
int main() {
int& c = function();
return 0;
}
-
함수의 리턴값은 해당 문장이 끝난 후 바로 사라지는 값이기 때문에 참조자를 만들게 되면 바로 다음에 댕글링 레퍼런스가 되어버린다.
-
하지만 C++ 에서 중요한 예외 규칙이 있습니다.
#include <iostream>
int function() {
int a = 5;
return a;
}
int main() {
const int& c = function();
std::cout << "c : " << c << std::endl;
return 0;
}
//c : 5
-
원칙상 함수의 리턴값은 해당 문장이 끝나면 소멸되는 것이 정상입니다.
-
따라서 기존에
int&로 받았을 때에는 컴파일 자체가 안되었습니다. -
하지만 예외적으로 상수 레퍼런스로 리턴값을 받게 되면 해당 리턴값의 생명이 연장됩니다. 그리고 그 연장되는 기간은 레퍼런스가 사라질 때 까지 입니다.
-
new, delete
-
C 언어에서는
malloc과free함수를 지원하여 힙 상에서의 메모리 할당을 지원하였습니다. C++ 에서도 마찬가지로malloc과free함수를 사용할 수 있습니다. -
하지만, 언어 차원에서 지원하는 것으로 바로
new와delete라고 할 수 있습니다.-
new는 말 그대로malloc과 대응되는 것으로 메모리를 할당 -
delete는free에 대응되는 것으로 메모리를 해제합니다.
-
-
new의 경우 객체를 동적으로 생성하면서와 동시에 자동으로 생성자도 호출해준다.
/* new 와 delete 의 사용 */
#include <iostream>
int main() {
int* p = new int; // 공간 할당
*p = 10;
std::cout << *p << std::endl;
delete p; // 해제
return 0;
}
<new로 배열 할당하기>
/* new 로 배열 할당하기 */
#include <iostream>
int main() {
int arr_size;
std::cout << "array size : ";
std::cin >> arr_size;
int *list = new int[arr_size]; //공간 할당
for (int i = 0; i < arr_size; i++) {
std::cin >> list[i];
}
for (int i = 0; i < arr_size; i++) {
std::cout << i << "th element of list : " << list[i] << std::endl;
}
delete[] list; //해제
return 0;
}
- 예제
#include <iostream>
typedef struct Animal {
char name[30]; // 이름
int age; // 나이
int health; // 체력
int food; // 배부른 정도
int clean; // 깨끗한 정도
} Animal;
void create_animal(Animal *animal) {
std::cout << "동물의 이름? ";
std::cin >> animal->name;
std::cout << "동물의 나이? ";
std::cin >> animal->age;
animal->health = 100;
animal->food = 100;
animal->clean = 100;
}
void play(Animal *animal) {
animal->health += 10;
animal->food -= 20;
animal->clean -= 30;
}
void one_day_pass(Animal *animal) {
// 하루가 지나면
animal->health -= 10;
animal->food -= 30;
animal->clean -= 20;
}
void show_stat(Animal *animal) {
std::cout << animal->name << "의 상태" << std::endl;
std::cout << "체력 : " << animal->health << std::endl;
std::cout << "배부름 : " << animal->food << std::endl;
std::cout << "청결 : " << animal->clean << std::endl;
}
int main() {
Animal *list[10];
int animal_num = 0;
for (;;) {
std::cout << "1. 동물 추가하기" << std::endl;
std::cout << "2. 놀기 " << std::endl;
std::cout << "3. 상태 보기 " << std::endl;
int input;
std::cin >> input;
switch (input) {
int play_with;
case 1:
list[animal_num] = new Animal;
create_animal(list[animal_num]);
animal_num++;
break;
case 2:
std::cout << "누구랑 놀게? : ";
std::cin >> play_with;
if (play_with < animal_num) play(list[play_with]);
break;
case 3:
std::cout << "누구껄 보게? : ";
std::cin >> play_with;
if (play_with < animal_num) show_stat(list[play_with]);
break;
}
for (int i = 0; i != animal_num; i++) {
one_day_pass(list[i]);
}
}
for (int i = 0; i != animal_num; i++) {
delete list[i];
}
}
객체지향 프로그래밍
class Animal {
private:
int food;
int weight;
public:
void set_animal(int _food, int _weight) {
food = _food;
weight = _weight;
}
void increase_food(int inc) {
food += inc;
weight += (inc / 3);
}
void view_stat() {
std::cout << "이 동물의 food : " << food << std::endl;
std::cout << "이 동물의 weight : " << weight << std::endl;
}
};
접근 지시자
-
외부에서 이러한 멤버들에 접근을 할 수 있냐 없냐를 지시해주는 것입니다.
-
참고로 키워드 명시를 하지 않았다면 기본적으로 private 로 설정됩니다. 즉, 맨 위의 private 키워드를 지워도 상관이 없다는 것이지요.
-
private 키워드
-
아래에 쓰여진 것들은 모두 객체 내에서 보호되고 있다 라는 의미
-
private 되고 있는 모든 것들은 자기 객체 안에서만 접근할 수 있을 뿐 객체 외부에서는 접근할 수 없게 됩니다.
-
-
public 키워드
- public 이라는 것은 말 그대로 공개된 것으로 외부에서 마음껏 이용할 수 있게 됩니다.
- 예제
#include <iostream>
class Date
{
int year;
int month; // 1부터 12 까지
int day; // 1부터 31 까지
public:
void SetDate(int _year, int _month, int _date)
{
year = _year;
month = _month;
day = _date;
}
void AddDay(int inc)
{
int temp;
tryAgain: //Goto 문 활용
switch (month)
{
// 31일 까지 있는 달 : 1,3,5,7,8,10,12
case 1:
case 3:
case 5:
case 7:
case 8:
case 10:
if (day + inc > 31)
{
// inc를 더했는데 달이 넘어가면, month를 1 올려주고 day를 0으로 만든다. 현재 day와 31일만큼의 차이를 inc에서 차감하고 다시 switch 문을 돌린다.
month++;
inc = inc - (31 - day);
day = 0;
goto tryAgain;
}
else
{
// inc를 더했는데 31일이 안넘으면 month에 영향이 없으므로 그냥 더하고 swith 문을 나간다.
day = day + inc;
break;
}
// 12월에는 inc를 더했을 때 년도가 바뀌는 경우가 생기므로 일종의 예외처리.
case 12:
if (day + inc > 31)
{
month = 1;
year++;
inc = inc - (31 - day);
day = 0;
goto tryAgain;
}
else
{
day = day + inc;
break;
}
// 30일 까지만 있는 달 : 4,6,9,11
case 4:
case 6:
case 9:
case 11:
if (day + inc > 30)
{
month++;
inc = inc - (30 - day);
day = 0;
goto tryAgain;
}
else
{
day = day + inc;
break;
}
// 28일까지만 있는 달 : 2
case 2:
if (day + inc > 28)
{
month++;
inc = inc - (day + inc) % 28;
day = 0;
goto tryAgain;
}
else
{
day = day + inc;
break;
}
}
}
void AddMonth(int inc)
{
// 12를 초과하면 year 올리기
if (month + inc > 12)
{
year = year + (month + inc) / 12;
month = (month + inc) % 12;
}
else
{
month += inc;
}
}
void AddYear(int inc)
{
year += inc;
}
void ShowDate()
{
std::cout << year << "년" << month << "월" << day << "일" << std::endl;
}
};
int main()
{
Date date;
date.SetDate(2021, 01, 30);
std::cout << "현재 날짜는 ";
date.ShowDate();
// 3년 더하기
date.AddYear(3);
std::cout << "3년 더한 후 : ";
date.ShowDate();
// 4개월 더하기
date.AddMonth(4);
std::cout << "4개월 더한 후 : ";
date.ShowDate();
// 14개월 더하기
date.AddMonth(14);
std::cout << "14개월 더한 후 : ";
date.ShowDate();
// 1일 더하기
date.AddDay(1);
std::cout << "1일 더한 후 : ";
date.ShowDate();
// 30일 더하기
date.AddDay(30);
std::cout << "30일 더한 후 : ";
date.ShowDate();
// 100일 더하기
date.AddDay(200);
std::cout << "200일 더한 후 : ";
date.ShowDate();
}
함수의 오버로딩 (Overloading)
/* 함수의 오버로딩 */
#include <iostream>
void print(int x) { std::cout << "int : " << x << std::endl; }
void print(char x) { std::cout << "char : " << x << std::endl; }
void print(double x) { std::cout << "double : " << x << std::endl; }
int main() {
int a = 1;
char b = 'c';
double c = 3.2f;
print(a);
print(b);
print(c);
return 0;
}
-
C++ 에서는 함수의 이름이 같더라도 인자가 다르면 다른 함수 라고 판단하기 때문에 오류가 발생하지 않는 것입니다.
-
C 언어였을 경우
int, char, double타입에 따라 함수의 이름을 제각각 다르게 만들어서 호출해 주어야 했던 반면에C++ 에서는 컴파일러가 알아서 적합한 인자를 가지는 함수를 찾아서 호출해 주게 됩니다.
-
/* 함수의 오버로딩 */
#include <iostream>
void print(int x) { std::cout << "int : " << x << std::endl; }
void print(double x) { std::cout << "double : " << x << std::endl; }
int main() {
int a = 1;
char b = 'c';
double c = 3.2f;
print(a);
print(b);
print(c);
return 0;
}
-
int타입의 인자나double타입의 인자를 하나 받는 함수 하나 밖에 없습니다.-
하지만
main에서 각기 다른 타입의 인자들 (int, char, double) 로 print 함수를 호출하게 됩니다. -
물론
a나c의 경우 각자 자기를 인자로 하는 정확한 함수들이 있어서 성공적으로 호출 될 수 있겠지만,char의 경우 자기와 정확히 일치하는 인자를 가지는 함수가 없기 때문에 '자신과 최대로 근접한 함수'를 찾게 됩니다.
-
<C++ 컴파일러에서 함수를 오버로딩하는 과정>
1. 자신과 타입이 정확히 일치하는 함수를 찾는다.
2. 정확히 일치하는 타입이 없는 경우 아래와 같은 형변환을 통해서 일치하는 함수를 찾아본다.
-
Char, unsigned char, short는int로 변환된다. -
Unsigned short는int의 크기에 따라int혹은unsigned int로 변환된다. -
Float은double로 변환된다. -
Enum은int로 변환된다.
3. 위와 같이 변환해도 일치하는 것이 없다면 아래의 좀더 포괄적인 형변환을 통해 일치하는 함수를 찾는다.
-
임의의 숫자(
numeric) 타입은 다른 숫자 타입으로 변환된다. (예를 들어 float -> int) -
Enum도 임의의 숫자 타입으로 변환된다 (예를 들어 Enum -> double) -
0은 포인터 타입이나 숫자 타입으로 변환된다 -
포인터는
void포인터로 변환된다.
4. 유저 정의된 타입 변환으로 일치하는 것을 찾는다.
-
만약에 컴파일러가 위 과정을 통하더라도 일치하는 함수를 찾을 수 없거나 같은 단계에서 두 개 이상이 일치하는 경우에 모호하다 (ambiguous) 라고 판단해서 오류를 발생하게 됩니다.
-
예)
double로 호출했지만,char, int만 선언되어 있는 경우 오류 발생- 두 개 이상의 가능한 일치가 존재
-
생성자 & 디폴트 생성자
include<iostream>
class Date {
int year_;
int month_; // 1 부터 12 까지.
int day_; // 1 부터 31 까지.
public:
void SetDate(int year, int month, int date);
void AddDay(int inc);
void AddMonth(int inc);
void AddYear(int inc);
// 해당 월의 총 일 수를 구한다.
int GetCurrentMonthTotalDays(int year, int month);
void ShowDate();
};
void Date::SetDate(int year, int month, int day) {
year_ = year;
month_ = month;
day_ = day;
}
int Date::GetCurrentMonthTotalDays(int year, int month) {
static int month_day[12] = {31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31};
if (month != 2) {
return month_day[month - 1];
} else if (year % 4 == 0 && year % 100 != 0) {
return 29; // 윤년
} else {
return 28;
}
}
void Date::AddDay(int inc) {
while (true) {
// 현재 달의 총 일 수
int current_month_total_days = GetCurrentMonthTotalDays(year_, month_);
// 같은 달 안에 들어온다면;
if (day_ + inc <= current_month_total_days) {
day_ += inc;
return;
} else {
// 다음달로 넘어가야 한다.
inc -= (current_month_total_days - day_ + 1);
day_ = 1;
AddMonth(1);
}
}
}
void Date::AddMonth(int inc) {
AddYear((inc + month_ - 1) / 12);
month_ = month_ + inc % 12;
month_ = (month_ == 12 ? 12 : month_ % 12);
}
void Date::AddYear(int inc) { year_ += inc; }
void Date::ShowDate() {
std::cout << "오늘은 " << year_ << " 년 " << month_ << " 월 " << day_
<< " 일 입니다 " << std::endl;
}
int main() {
Date day;
day.SetDate(2011, 3, 1);
day.ShowDate();
day.AddDay(30);
day.ShowDate();
day.AddDay(2000);
day.ShowDate();
day.SetDate(2012, 1, 31); // 윤년
day.AddDay(29);
day.ShowDate();
day.SetDate(2012, 8, 4);
day.AddDay(2500);
day.ShowDate();
return 0;
}
-
Date::을 함수 이름 앞에 붙여주게 되면 이 함수가 "Date 클래스의 정의된 함수" 라는 의미를 부여하게 됩니다.- 너무 길어지는 것을 방지하기 위해 바깥에 정의
생성자
#include <iostream>
class Date {
int year_;
int month_; // 1 부터 12 까지.
int day_; // 1 부터 31 까지.
public:
void SetDate(int year, int month, int date);
void AddDay(int inc);
void AddMonth(int inc);
void AddYear(int inc);
// 해당 월의 총 일 수를 구한다.
int GetCurrentMonthTotalDays(int year, int month);
void ShowDate();
Date(int year, int month, int day) { //여기가 생성자
year_ = year;
month_ = month;
day_ = day;
}
};
// 생략
void Date::AddYear(int inc) { year_ += inc; }
void Date::ShowDate() {
std::cout << "오늘은 " << year_ << " 년 " << month_ << " 월 " << day_
<< " 일 입니다 " << std::endl;
}
int main() {
Date day(2011, 3, 1);
day.ShowDate();
day.AddYear(10);
day.ShowDate();
return 0;
}
-
만일 SetDate 를 하지 않았더라면 초기화 되지 않은 값들에 덧셈 과 출력 명령이 내려져서 쓰레기 값이 출력
- C++ 에서는 이를 언어 차원에서 도와주는 장치가 있는데 바로 생성자(constructor)
-
생성자는 기본적으로 "객체 생성시 자동으로 호출되는 함수" 라고 볼 수 있습니다. 이 때 자동으로 호출 되면서 객체를 초기화 해주는 역할을 담당하게 됩니다.
-
생성자는 아래와 같이 정의합니다.
// 객체를 초기화 하는 역할을 하기 때문에 리턴값이 없다! 클래스 이름 (인자) {}
-
디폴트 생성자
// 디폴트 생성자 정의해보기
#include <iostream>
class Date {
int year_;
int month_; // 1 부터 12 까지.
int day_; // 1 부터 31 까지.
public:
void ShowDate();
Date() { //디폴트 생성자
year_ = 2012;
month_ = 7;
day_ = 12;
}
};
void Date::ShowDate() {
std::cout << "오늘은 " << year_ << " 년 " << month_ << " 월 " << day_
<< " 일 입니다 " << std::endl;
}
int main() {
Date day = Date();
Date day2;
day.ShowDate();
day2.ShowDate();
return 0;
}
-
Date day3();-
이와 같이 선언하면,
day3객체를 디폴트 생성자를 이용해서 초기화 하는 것이 아니라, 리턴값이Date이고 인자가 없는 함수day3을 정의하게 된 것으로 인식합니다.- 이는 암시적 표현으로 객체를 선언할 때 반드시 주의해 두어야 할 사항입니다.
-
해당 문장은
A를 리턴하는 함수a를 정의한 문장 입니다. 반드시 그냥A a와 같이 써야 합니다.
-
다행이도 C++ 11 부터 명시적으로 디폴트 생성자를 사용하도록 명시할 수 있습니다.
class Test {
public:
Test() = default; // 디폴트 생성자를 정의해라
};
생성자 오버로딩
#include <iostream>
class Date {
int year_;
int month_; // 1 부터 12 까지.
int day_; // 1 부터 31 까지.
public:
void ShowDate();
Date() {
std::cout << "기본 생성자 호출!" << std::endl;
year_ = 2012;
month_ = 7;
day_ = 12;
}
Date(int year, int month, int day) {
std::cout << "인자 3 개인 생성자 호출!" << std::endl;
year_ = year;
month_ = month;
day_ = day;
}
};
void Date::ShowDate() {
std::cout << "오늘은 " << year_ << " 년 " << month_ << " 월 " << day_
<< " 일 입니다 " << std::endl;
}
int main() {
Date day = Date();
Date day2(2012, 10, 31);
day.ShowDate();
day2.ShowDate();
return 0;
}
소멸자
-
main함수 끝에서Marine이delete될 때, 즉 우리가 생성했던 객체가 소멸 될 때 자동으로 호출되는 함수 - 마치 객체가 생성될 때 자동으로 호출 되었던 생성자 처럼 소멸 될 때 자동으로 호출되는 함수가 있다면 얼마나 좋을까요?- C++ 에서는 이 기능을 지원하고 있습니다. 바로 소멸자(Destructor) 이죠.
-
생성자가 클래스 이름과 똑같이 생겼다면 소멸자는 그 앞에
~만 붙여주시면 됩니다.
~(클래스의 이름)- 생성자와 한 가지 다른 점은, 소멸자는 인자를 아무것도 가지지 않는다는 것입니다.
- 예제
#include <string.h>
#include <iostream>
class Marine {
int hp; // 마린 체력
int coord_x, coord_y; // 마린 위치
int damage; // 공격력
bool is_dead;
char* name; // 마린 이름
public:
Marine(); // 기본 생성자
Marine(int x, int y, const char* marine_name); // 이름까지 지정
Marine(int x, int y); // x, y 좌표에 마린 생성
~Marine();
int attack(); // 데미지를 리턴한다.
void be_attacked(int damage_earn); // 입는 데미지
void move(int x, int y); // 새로운 위치
void show_status(); // 상태를 보여준다.
};
Marine::Marine() {
hp = 50;
coord_x = coord_y = 0;
damage = 5;
is_dead = false;
name = NULL;
}
Marine::Marine(int x, int y, const char* marine_name) {
name = new char[strlen(marine_name) + 1];
strcpy(name, marine_name);
coord_x = x;
coord_y = y;
hp = 50;
damage = 5;
is_dead = false;
}
Marine::Marine(int x, int y) {
coord_x = x;
coord_y = y;
hp = 50;
damage = 5;
is_dead = false;
name = NULL;
}
void Marine::move(int x, int y) {
coord_x = x;
coord_y = y;
}
int Marine::attack() { return damage; }
void Marine::be_attacked(int damage_earn) {
hp -= damage_earn;
if (hp <= 0) is_dead = true;
}
void Marine::show_status() {
std::cout << " *** Marine : " << name << " ***" << std::endl;
std::cout << " Location : ( " << coord_x << " , " << coord_y << " ) "
<< std::endl;
std::cout << " HP : " << hp << std::endl;
}
Marine::~Marine() {
std::cout << name << " 의 소멸자 호출 ! " << std::endl;
if (name != NULL) { //NULL이 아닐 때, 즉 동적으로 할당된 경우에만
delete[] name;
}
}
int main() {
Marine* marines[100];
marines[0] = new Marine(2, 3, "Marine 2");
marines[1] = new Marine(1, 5, "Marine 1");
marines[0]->show_status();
marines[1]->show_status();
std::cout << std::endl << "마린 1 이 마린 2 를 공격! " << std::endl;
marines[0]->be_attacked(marines[1]->attack());
marines[0]->show_status();
marines[1]->show_status();
delete marines[0];
delete marines[1];
}
복사 생성자
// 포토캐논
#include <string.h>
#include <iostream>
class Photon_Cannon {
int hp, shield;
int coord_x, coord_y;
int damage;
public:
Photon_Cannon(int x, int y);
Photon_Cannon(const Photon_Cannon& pc);
void show_status();
};
Photon_Cannon::Photon_Cannon(const Photon_Cannon& pc) {
std::cout << "복사 생성자 호출 !" << std::endl;
hp = pc.hp;
shield = pc.shield;
coord_x = pc.coord_x;
coord_y = pc.coord_y;
damage = pc.damage;
}
Photon_Cannon::Photon_Cannon(int x, int y) {
std::cout << "생성자 호출 !" << std::endl;
hp = shield = 100;
coord_x = x;
coord_y = y;
damage = 20;
}
void Photon_Cannon::show_status() {
std::cout << "Photon Cannon " << std::endl;
std::cout << " Location : ( " << coord_x << " , " << coord_y << " ) "
<< std::endl;
std::cout << " HP : " << hp << std::endl;
}
int main() {
Photon_Cannon pc1(3, 3);
Photon_Cannon pc2(pc1);
Photon_Cannon pc3 = pc2;
pc1.show_status();
pc2.show_status();
}
-
복사 생성자는 어떤 클래스
T가 있다면 다른T의 객체a를 상수 레퍼런스로 받는 다는 이야기 입니다.- 여기서
a가const이기 때문에 우리는 복사 생성자 내부에서a의 데이터를 변경할 수 없고, 오직 새롭게 초기화 되는 인스턴스 변수들에게 '복사' 만 할 수 있게 됩니다.
- 여기서
T(const T& a);
- 즉, 다음과 같이 복사 생성자 내부에서
pc의 인스턴스 변수들에 접근해서 객체의shield, coord_x, coord_y등을 초기화 할 수 는 있지만,
Photon_Cannon::Photon_Cannon(const Photon_Cannon& pc) {
std::cout << "복사 생성자 호출 !" << std::endl;
hp = pc.hp;
shield = pc.shield;
coord_x = pc.coord_x;
coord_y = pc.coord_y;
damage = pc.damage;
}
pc.coord_x = 3; 처럼 pc 의 값 자체는 변경할 수 없다는 이야기 입니다.
🛑 인자로 받는 변수의 내용을 함수 내부에서 바꾸지 않는다면 앞에 const 를 붙여 주는 것이 바람직합니다.
- 사용 예시
//1)
Photon_Cannon pc1(3, 3);
Photon_Cannon pc2(pc1);
//2)
Photon_Cannon pc3 = pc2;
//3)
Photon_Cannon pc3(pc2);
**복사 생성자는 오직 '생성' 시에 호출된다**
-
사실 디폴트 생성자와 디폴트 소멸자 처럼, C++ 컴파일러는 이미 디폴트 복사 생성자(Default copy constructor) 를 지원해 주고 있습니다.
-
위 코드에서 복사 생성자를 한 번 지워보시고 실행해보면, 이전과 정확히 동일한 결과가 나타남을 알 수 있습니다.
-
디폴트 복사 생성자의 경우 기존의 디폴트 생성자와 소멸자가 하는 일이 아무 것도 없었던 것과는 달리 실제로 '복사' 를 해줍니다.
-
디폴트 복사 생성자의 한계
// 디폴트 복사 생성자의 한계
#include <string.h>
#include <iostream>
class Photon_Cannon {
int hp, shield;
int coord_x, coord_y;
int damage;
char *name;
public:
Photon_Cannon(int x, int y);
Photon_Cannon(int x, int y, const char *cannon_name);
~Photon_Cannon();
void show_status();
};
Photon_Cannon::Photon_Cannon(int x, int y) {
hp = shield = 100;
coord_x = x;
coord_y = y;
damage = 20;
name = NULL;
}
Photon_Cannon::Photon_Cannon(int x, int y, const char *cannon_name) {
hp = shield = 100;
coord_x = x;
coord_y = y;
damage = 20;
name = new char[strlen(cannon_name) + 1];
strcpy(name, cannon_name);
}
Photon_Cannon::~Photon_Cannon() {
// 0 이 아닌 값은 if 문에서 true 로 처리되므로
// 0 인가 아닌가를 비교할 때 그냥 if(name) 하면
// if(name != 0) 과 동일한 의미를 가질 수 있다.
// 참고로 if 문 다음에 문장이 1 개만 온다면
// 중괄호를 생략 가능하다.
if (name) delete[] name;
}
void Photon_Cannon::show_status() {
std::cout << "Photon Cannon :: " << name << std::endl;
std::cout << " Location : ( " << coord_x << " , " << coord_y << " ) "
<< std::endl;
std::cout << " HP : " << hp << std::endl;
}
int main() {
Photon_Cannon pc1(3, 3, "Cannon");
Photon_Cannon pc2 = pc1;
pc1.show_status();
pc2.show_status();
}

-
당연히도,
hp, shield, ...그리고name까지 모두 같은 값을 갖게 됩니다.-
여기서
name이 같은 값 - 즉 두 개의 포인터가 같은 값을 가진 다는 것은 같은 주소 값을 가리킨다는 말이 됩니다. -
즉,
pc1의name이 동적으로 할당받아서 가리키고 있던 메모리 ("Cannon" 이라는 문자열이 저장된 메모리) 를pc2의name도 같이 가리키게 되는 것이지요.
-
-
진짜 문제는 소멸자에서 일어납니다.
main함수가 종료되기 직전에 생성되었던 객체들은 파괴되면서 소멸자를 호출하게 되죠. 만일 먼저pc1이 파괴되었다고 해봅시다.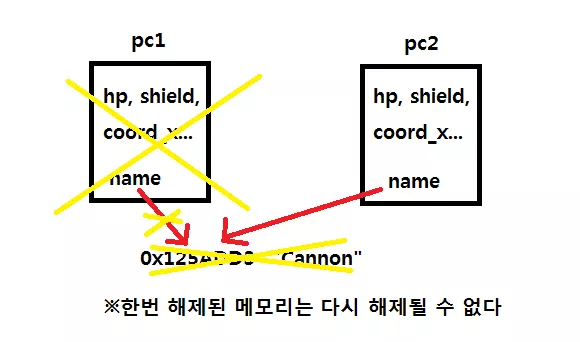
-
그러면 소멸자는
pc1의 내용을 모두 파괴함과 동시에0x125ADD3에 할당한 메모리 까지delete하게 됩니다. -
그런데 문제는
pc2의name이 해제된 메모리인0x125ADD3을 가리키고 있다는 것입니다.
-
-
pc2에서 일단name은NULL이 아니므로 (0x125ADD3이라는 주소값을 가지고 있음)delete [] name이 수행되고,이미 해제된 메모리에 접근해서 다시 해제하려고 하였기 때문에 (사실 접근한 것 자체만으로 오류) 런타임 오류가 발생하게 됩니다.
-
해결 방법
-
복사 생성자에서
name을 그대로 복사하지 말고 따로 다른 메모리에 동적 할당을 해서 그 내용만 복사-
메모리를 새로 할당해서 내용을 복사하는 것을 깊은 복사(deep copy) 라고 부
-
단순히 대입 만 해주는 것을 얕은 복사(shallow copy)
-
-
컴파일러가 생성하는 디폴트 복사 생성자의 경우 얕은 복사 밖에 할 수 없으므로 깊은 복사가 필요한 경우에는 사용자가 직접 복사 생성자를 만들어야 합니다.

-
복사 생성자에서
hp, shield와 같은 변수 들은 얕은 복사를 하지만,name의 경우 따로 메모리를 할당해서 그 내용만 복사하는 깊은 복사를 수행 -
그러면 소멸자에서도 메모리 해제시 각기 다른 메모리를 해제하는 것이기 때문에 전혀 문제가 발생하지 않습니다.
이를 바탕으로 복사 생성자를 만들어보면 아래와 같습니다.
-
// 복사 생성자의 중요성
#include <string.h>
#include <iostream>
class Photon_Cannon {
int hp, shield;
int coord_x, coord_y;
int damage;
char *name;
public:
Photon_Cannon(int x, int y);
Photon_Cannon(int x, int y, const char *cannon_name);
Photon_Cannon(const Photon_Cannon &pc);
~Photon_Cannon();
void show_status();
};
Photon_Cannon::Photon_Cannon(int x, int y) {
hp = shield = 100;
coord_x = x;
coord_y = y;
damage = 20;
name = NULL;
}
Photon_Cannon::Photon_Cannon(const Photon_Cannon &pc) {
std::cout << "복사 생성자 호출! " << std::endl;
hp = pc.hp;
shield = pc.shield;
coord_x = pc.coord_x;
coord_y = pc.coord_y;
damage = pc.damage;
name = new char[strlen(pc.name) + 1];
strcpy(name, pc.name);
}
Photon_Cannon::Photon_Cannon(int x, int y, const char *cannon_name) {
hp = shield = 100;
coord_x = x;
coord_y = y;
damage = 20;
name = new char[strlen(cannon_name) + 1];
strcpy(name, cannon_name);
}
Photon_Cannon::~Photon_Cannon() {
if (name) delete[] name;
}
void Photon_Cannon::show_status() {
std::cout << "Photon Cannon :: " << name << std::endl;
std::cout << " Location : ( " << coord_x << " , " << coord_y << " ) "
<< std::endl;
std::cout << " HP : " << hp << std::endl;
}
int main() {
Photon_Cannon pc1(3, 3, "Cannon");
Photon_Cannon pc2 = pc1;
pc1.show_status();
pc2.show_status();
}
생성자의 초기화 리스트(initializer list)
#include <iostream>
class Marine {
int hp; // 마린 체력
int coord_x, coord_y; // 마린 위치
int damage; // 공격력
bool is_dead;
public:
Marine(); // 기본 생성자
Marine(int x, int y); // x, y 좌표에 마린 생성
int attack(); // 데미지를 리턴한다.
void be_attacked(int damage_earn); // 입는 데미지
void move(int x, int y); // 새로운 위치
void show_status(); // 상태를 보여준다.
};
Marine::Marine() : hp(50), coord_x(0), coord_y(0), damage(5), is_dead(false) {}
Marine::Marine(int x, int y)
: coord_x(x), coord_y(y), hp(50), damage(5), is_dead(false) {}
void Marine::move(int x, int y) {
coord_x = x;
coord_y = y;
}
int Marine::attack() { return damage; }
void Marine::be_attacked(int damage_earn) {
hp -= damage_earn;
if (hp <= 0) is_dead = true;
}
void Marine::show_status() {
std::cout << " *** Marine *** " << std::endl;
std::cout << " Location : ( " << coord_x << " , " << coord_y << " ) "
<< std::endl;
std::cout << " HP : " << hp << std::endl;
}
int main() {
Marine marine1(2, 3);
Marine marine2(3, 5);
marine1.show_status();
marine2.show_status();
}
- 기본 형태
(생성자 이름) : var1(arg1), var2(arg2) {}
-
여기서
var들은 클래스의 멤버 변수들을 지칭하고,
arg는 그 멤버 변수들을 무엇으로 초기화 할 지 지칭하는 역할을 합니다.-
한 가지 흥미로운 점은 var1 과 arg1 의 이름이 같아도 되는데, 실제로 아래의 예제는 정상적으로 작동합니다.
-
coord_x ( coord_x )에서 바깥쪽의coord_x는 무조건 멤버 변수를 지칭하게 되는데, 이 경우coord_x를 지칭하는 것이고,
괄호 안의coord_x는 원칙상Marine이 인자로 받은coord_x를 우선적으로 지칭하는 것이기 때문입니다.따라서 실제로, 인자로 받은
coord_x가 클래스의 멤버 변수coord_x를 초기화 하게 됩니다.
-
-
Marine::Marine(int coord_x, int coord_y)
: coord_x(coord_x), coord_y(coord_y), hp(50), damage(5), is_dead(false) {}
-
초기화 리스트를 사용한 버전의 경우 생성과 초기화를 동시에 하게 됩니다.
-
반면에 초기화 리스트를 사용하지 않는다면 생성을 먼저 하고 그 다음에 대입 을 수행하게 됩니다.
-
우리 경험상 반드시 '생성과 동시에 초기화 되어야 하는 것들' 이 몇 가지 있었습니다. 대표적으로 레퍼런스와 상수가 있지요.
-
상수와 레퍼런스들은 모두 생성과 동시에 초기화가 되어야 합니다.
-
따라서 만약에 클래스 내부에 레퍼런스 변수나 상수를 넣고 싶다면 이들을 생성자에서 무조건 초기화 리스트를 사용해서 초기화 시켜주어야만 합니다.
-
-
static 멤버 변수
-
마치 전역 변수 같지만 클래스 하나에만 종속되는 변수
-
클래스의 모든 객체들이 '공유' 하는 변수로써 각 객체 별로 따로 존재하는 멤버 변수들과는 달리 모든 객체들이 '하나의'
static멤버 변수를 사용하게 된다.
- 사용 예시
//1)
static int total_marine_num;
//초기화 할 시, 다음과 같이 (초기화 안해줘도 static변수는 0으로 초기화 됨)
int Marine::total_marine_num = 0;
//2) (x): 멤버 변수들을 위와 같이 초기화 시키지 못하는 것처럼
//static 변수 역시 클래스 내부에서 위와 같이 초기화 하는 것은 불가능
class Marine {
static int total_marine_num = 0;
//3) (o): const static 변수일 때만 가능
class Marine {
const static int x = 0;
// static 멤버 변수의 사용
#include <iostream>
class Marine {
static int total_marine_num;
int hp; // 마린 체력
int coord_x, coord_y; // 마린 위치
bool is_dead;
const int default_damage; // 기본 공격력
public:
Marine(); // 기본 생성자
Marine(int x, int y); // x, y 좌표에 마린 생성
Marine(int x, int y, int default_damage);
int attack(); // 데미지를 리턴한다.
void be_attacked(int damage_earn); // 입는 데미지
void move(int x, int y); // 새로운 위치
void show_status(); // 상태를 보여준다.
~Marine() { total_marine_num--; }
};
int Marine::total_marine_num = 0;
Marine::Marine()
: hp(50), coord_x(0), coord_y(0), default_damage(5), is_dead(false) {
total_marine_num++;
}
Marine::Marine(int x, int y)
: coord_x(x), coord_y(y), hp(50), default_damage(5), is_dead(false) {
total_marine_num++;
}
Marine::Marine(int x, int y, int default_damage)
: coord_x(x),
coord_y(y),
hp(50),
default_damage(default_damage),
is_dead(false) {
total_marine_num++;
}
void Marine::move(int x, int y) {
coord_x = x;
coord_y = y;
}
int Marine::attack() { return default_damage; }
void Marine::be_attacked(int damage_earn) {
hp -= damage_earn;
if (hp <= 0) is_dead = true;
}
void Marine::show_status() {
std::cout << " *** Marine *** " << std::endl;
std::cout << " Location : ( " << coord_x << " , " << coord_y << " ) "
<< std::endl;
std::cout << " HP : " << hp << std::endl;
std::cout << " 현재 총 마린 수 : " << total_marine_num << std::endl;
}
void create_marine() {
Marine marine3(10, 10, 4);
marine3.show_status();
}
int main() {
Marine marine1(2, 3, 5);
marine1.show_status();
Marine marine2(3, 5, 10);
marine2.show_status();
create_marine();
std::cout << std::endl << "마린 1 이 마린 2 를 공격! " << std::endl;
marine2.be_attacked(marine1.attack());
marine1.show_status();
marine2.show_status();
}
static 함수
-
어떤 특정 객체에 종속되는 것이 아니라 클래스 전체에 딱 1 개 존재하는 함수
- 즉,
static이 아닌 멤버 함수들의 경우 객체를 만들어야지만 각 멤버 함수들을 호출할 수 있지만static함수의 경우, 객체가 없어도 그냥 클래스 자체에서 호출할 수 있게 된다.
- 즉,
-
호출 방법
-
static함수는 앞에서 이야기 한 것과 같이, 어떤 객체에 종속되는 것이 아니라 클래스에 종속되는 것으로, 따라서 이를 호출하는 방법도(객체).(멤버 함수)가 아니라,(클래스)::(static 함수)형식으로 호출하게 됩니다.-
어떠한 객체도 이 함수를 소유하고 있지 않기 때문이죠.
-
그러하기에,
static함수 내에서는 클래스의static변수 만을 이용할 수 밖에 없습니다.
-
-
Marine::show_total_marine();
- 예시
// static 함수
#include <iostream>
class Marine {
static int total_marine_num;
const static int i = 0;
int hp; // 마린 체력
int coord_x, coord_y; // 마린 위치
bool is_dead;
const int default_damage; // 기본 공격력
public:
Marine(); // 기본 생성자
Marine(int x, int y); // x, y 좌표에 마린 생성
Marine(int x, int y, int default_damage);
int attack(); // 데미지를 리턴한다.
void be_attacked(int damage_earn); // 입는 데미지
void move(int x, int y); // 새로운 위치
void show_status(); // 상태를 보여준다.
static void show_total_marine();
~Marine() { total_marine_num--; }
};
int Marine::total_marine_num = 0;
void Marine::show_total_marine() {
std::cout << "전체 마린 수 : " << total_marine_num << std::endl;
}
Marine::Marine()
: hp(50), coord_x(0), coord_y(0), default_damage(5), is_dead(false) {
total_marine_num++;
}
Marine::Marine(int x, int y)
: coord_x(x), coord_y(y), hp(50), default_damage(5), is_dead(false) {
total_marine_num++;
}
Marine::Marine(int x, int y, int default_damage)
: coord_x(x),
coord_y(y),
hp(50),
default_damage(default_damage),
is_dead(false) {
total_marine_num++;
}
void Marine::move(int x, int y) {
coord_x = x;
coord_y = y;
}
int Marine::attack() { return default_damage; }
void Marine::be_attacked(int damage_earn) {
hp -= damage_earn;
if (hp <= 0) is_dead = true;
}
void Marine::show_status() {
std::cout << " *** Marine *** " << std::endl;
std::cout << " Location : ( " << coord_x << " , " << coord_y << " ) "
<< std::endl;
std::cout << " HP : " << hp << std::endl;
std::cout << " 현재 총 마린 수 : " << total_marine_num << std::endl;
}
void create_marine() {
Marine marine3(10, 10, 4);
Marine::show_total_marine();
}
int main() {
Marine marine1(2, 3, 5);
Marine::show_total_marine();
Marine marine2(3, 5, 10);
Marine::show_total_marine();
create_marine();
std::cout << std::endl << "마린 1 이 마린 2 를 공격! " << std::endl;
marine2.be_attacked(marine1.attack());
marine1.show_status();
marine2.show_status();
}
this
// 자기 자신을 가리키는 포인터 this
#include <iostream>
class Marine {
static int total_marine_num;
const static int i = 0;
int hp; // 마린 체력
int coord_x, coord_y; // 마린 위치
bool is_dead;
const int default_damage; // 기본 공격력
public:
Marine(); // 기본 생성자
Marine(int x, int y); // x, y 좌표에 마린 생성
Marine(int x, int y, int default_damage);
int attack(); // 데미지를 리턴한다.
Marine& be_attacked(int damage_earn); // 입는 데미지
void move(int x, int y); // 새로운 위치
void show_status(); // 상태를 보여준다.
static void show_total_marine();
~Marine() { total_marine_num--; }
};
int Marine::total_marine_num = 0;
void Marine::show_total_marine() {
std::cout << "전체 마린 수 : " << total_marine_num << std::endl;
}
Marine::Marine()
: hp(50), coord_x(0), coord_y(0), default_damage(5), is_dead(false) {
total_marine_num++;
}
Marine::Marine(int x, int y)
: coord_x(x),
coord_y(y),
hp(50),
default_damage(5),
is_dead(false) {
total_marine_num++;
}
Marine::Marine(int x, int y, int default_damage)
: coord_x(x),
coord_y(y),
hp(50),
default_damage(default_damage),
is_dead(false) {
total_marine_num++;
}
void Marine::move(int x, int y) {
coord_x = x;
coord_y = y;
}
int Marine::attack() { return default_damage; }
Marine& Marine::be_attacked(int damage_earn) {
hp -= damage_earn;
if (hp <= 0) is_dead = true;
return *this;
}
void Marine::show_status() {
std::cout << " *** Marine *** " << std::endl;
std::cout << " Location : ( " << coord_x << " , " << coord_y << " ) "
<< std::endl;
std::cout << " HP : " << hp << std::endl;
std::cout << " 현재 총 마린 수 : " << total_marine_num << std::endl;
}
int main() {
Marine marine1(2, 3, 5);
marine1.show_status();
Marine marine2(3, 5, 10);
marine2.show_status();
std::cout << std::endl << "마린 1 이 마린 2 를 두 번 공격! " << std::endl;
marine2.be_attacked(marine1.attack()).be_attacked(marine1.attack());
marine1.show_status();
marine2.show_status();
}
-
C++ 언어 차원에서 정의되어 있는 키워드
-
이는 객체 자신을 가리키는 포인터의 역할을 합니다.
-
이 멤버 함수를 호출하는 객체 자신을 가리킨다는 것
-
//1)
Marine& Marine::be_attacked(int damage_earn) {
hp -= damage_earn;
if (hp <= 0) is_dead = true;
return *this;
}
//2)
Marine& Marine::be_attacked(int damage_earn) {
this->hp -= damage_earn;
if (this->hp <= 0) this->is_dead = true;
return *this;
}
//1)과 2)는 동일한 의미이다.
- 실제로 모든 멤버 함수 내에서는
this키워드가 정의되어 있으며 클래스 안에서 정의된 함수 중에서this키워드가 없는 함수는 (당연하게도)static함수 뿐입니다.
레퍼런스를 리턴하는 함수
// 레퍼런스를 리턴하는 함수
#include <iostream>
class A {
int x;
public:
A(int c) : x(c) {}
int& access_x() { return x; } //레퍼런스 리턴
int get_x() { return x; } // '값'을 리턴
void show_x() { std::cout << x << std::endl; }
};
int main() {
A a(5);
a.show_x();
int& c = a.access_x();
c = 4;
a.show_x();
int d = a.access_x();
d = 3;
a.show_x();
// 아래는 오류
// int& e = a.get_x();
// e = 2;
// a.show_x();
int f = a.get_x();
f = 1;
a.show_x();
}
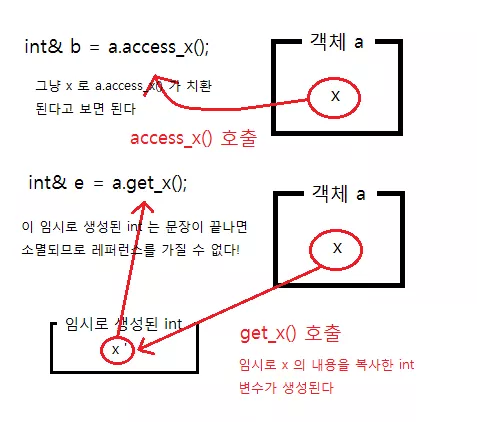
-
클래스
A는 아래와 같이int와int의 레퍼런스를 리턴하는 두 개의 함수를 가지고 있습니다. -
여기서 레퍼런스
c는x의 레퍼런스, 즉x의 별명을 받았습니다.-
따라서,
c는x의 별명 -
레퍼런스를 리턴하는 함수는 그 함수 부분을 원래의 변수로 치환했다고 생각해도 상관이 없습니다.
-
즉
int &c = x; // 여기서 x 는 a 의 x와 동일한 의미
-
-
만일
d가int&였다면x의 별명을 받아서d역시 또 다른x의 별명이 되었겠지만,d가 그냥int변수 이므로, 값의 복사가 일어나d에는x의 값이 들어가게 된다.d는x의 별명이 아닌 또 다른 독립적인 변수 이기에,d = 3;을 해도x의 값은 바뀌지 않은 채, 그냥4가 출력되게 된다.
-
주석 처리된 코드
-
레퍼런스가 아닌 타입을 리턴하는 경우는 '값' 의 복사가 이루어지기 때문에 임시 객체가 생성되는데, 임시객체의 레퍼런스를 가질 수 없기 때문입니다.
-
int를 리턴하는a.get_x에 대해서는 레퍼런스를 만들 수 없습니다.
(정확한 설명을 하자면int&는 좌측값에 대한 레퍼런스 이고,a.get_x()는 우측값 이기 때문에 레퍼런스를 만들 수 없습니다.좌측값은 어떠한 메모리 위치를 가리키는데, & 연산자를 통해 그 위치를 참조할 수 있다. 우측값은 좌측값이 아닌 값들이다
참고
-
const 함수
-
C++ 에서는 변수들의 값을 바꾸지 않고 읽기 만 하는, 마치 상수 같은 멤버 함수를 상수 함수 로써 선언할 수 있습니다.
-
상수 함수 내에서는 객체들의 '읽기' 만이 수행되며, 상수 함수 내에서 호출 할 수 있는 함수로는 다른 상수 함수 밖에 없습니다.
//상수 함수
(기존의 함수의 정의) const;
int attack() const; // 데미지를 리턴한다.
//상수 멤버 함수
int Marine::attack() const { return default_damage; }
사실 많은 경우 클래스를 설계할 때, 멤버 변수들은 모두
private에 넣고,
이 변수들의 값에 접근하는 방법으로get_x함수 처럼 함수를public에 넣어
이 함수를 이용해 값을 리턴받는 형식을 많이 사용합니다.
이렇게 하면 멤버 변수들을private에 넣음으로써 함부로 변수에 접근하는 것을 막고, 또 그 값은 자유롭게 구할 수 있게 됩니다.
explicit 키워드
-
C++ 에서는
explicit키워드를 통해 원하지 않는 암시적 변환을 할 수 없도록 컴파일러에게 명시할 수 있습니다. -
explicit은implicit의 반대말로, 명시적 이라는 뜻을 가지고 있습니다.
explicit MyString(int capacity);
mutable 키워드
-
const함수 내부에서는 멤버 변수들의 값을 바꾸는 것이 불가능 합니다.- 하지만, 만약에 멤버 변수를
mutable로 선언하였다면const함수에서도 이들 값을 바꿀 수 있습니다.
- 하지만, 만약에 멤버 변수를
#include <iostream>
class A {
mutable int data_;
public:
A(int data) : data_(data) {}
void DoSomething(int x) const {
data_ = x; // 가능!
}
void PrintData() const { std::cout << "data: " << data_ << std::endl; }
};
int main() {
A a(10);
a.DoSomething(3);
a.PrintData();
}
-
mutable 키워드가 필요한 이유
-
먼저 멤버 함수를 왜
const로 선언하는지 부터 생각해봅시다.
클래스의 멤버 함수들은 이 객체는 이러이러한 일을 할 수 있습니다 라는 의미를 나타내고 있습니다.그리고 멤버 함수를
const로 선언하는 의미는 '이 함수는 객체의 내부 상태에 영향을 주지 않습니다' 를 표현하는 방법 입니다.대표적인 예로 읽기 작업을 수행하는 함수들을 들 수 있습니다.
-
대부분의 경우 의미상 상수 작업을 하는 경우, 실제로도 상수 작업을 하게 됩니다.
하지만, 실제로 꼭 그렇지만은 않습니다.
-
- 다음과 같은 서버 프로그램을 만든다고 해봅시다.
class Server {
// .... (생략) ....
// 이 함수는 데이터베이스에서 user_id 에 해당하는 유저 정보를 읽어서 반환한다.
User GetUserInfo(const int user_id) const {
// 1. 데이터베이스에 user_id 를 검색
Data user_data = Database.find(user_id);
// 2. 리턴된 정보로 User 객체 생성
return User(user_data);
}
};
-
GetUserInfo: 입력 받은user_id로 데이터베이스에서 해댱 유저를 조회해서 그 유저의 정보를 리턴하는 함수- 당연히도 데이터베이스를 업데이트 하지도 않고, 무언가 수정하는 작업도 당연히 없기 때문에
const함수로 선언되어 있습니다.
- 당연히도 데이터베이스를 업데이트 하지도 않고, 무언가 수정하는 작업도 당연히 없기 때문에
-
대개 데이터베이스에 요청한 후 받아오는 작업은 꽤나 오래 걸립니다. 그래서 보통 서버들의 경우 메모리에 캐쉬(cache)를 만들어서 자주 요청되는 데이터를 데이터베이스까지 가서 찾지 않아도 메모리에서 빠르게 조회할 수 있도록 합니다.
-
캐쉬는 데이터베이스만큼 크지 않기 때문에 일부 유저들 정보 밖에 포함하지 않습니다. 따라서 캐쉬에 해당 유저가 없다면 (cache miss),
데이터베이스에 직접 요청하고, 대신 데이터베이스에서 유저 정보를 받으면 캐쉬에 저장해놓아서 다음에 요청할 때는 빠르게 받을 수 있게 됩니다.
-
class Server {
// .... (생략) ....
Cache cache; // 캐쉬!
// 이 함수는 데이터베이스에서 user_id 에 해당하는 유저 정보를 읽어서 반환한다.
User GetUserInfo(const int user_id) const {
// 1. 캐쉬에서 user_id 를 검색
Data user_data = cache.find(user_id);
// 2. 하지만 캐쉬에 데이터가 없다면 데이터베이스에 요청
if (!user_data) {
user_data = Database.find(user_id);
// 그 후 캐쉬에 user_data 등록
cache.update(user_id, user_data); // <-- 불가능
//mutable Cache cache; // 캐쉬!
}
// 3. 리턴된 정보로 User 객체 생성
return User(user_data);
}
};
-
문제는
GetUserInfo가const함수라는 점-
캐쉬를 업데이트 하는 작업을 수행할 수 없습니다.
- 캐쉬를 업데이트 한다는 것은 케쉬 내부의 정보를 바꿔야 된다는 뜻이기 때문
-
-
그렇기에
mutable키워드가 필요해진다.
