(https://opentutorials.org/module/516/5440)
1. 클래스 멤버, 인스턴스 멤버
package org.opentutorials.javatutorials.classninstance;
class Calculator2 {
static double PI = 3.14;
// 클래스 변수인 base가 추가되었다.
static int base = 0;
int left, right;
public void setOprands(int left, int right) {
this.left = left;
this.right = right;
}
public void sum() {
// 더하기에 base의 값을 포함시킨다.
System.out.println(this.left + this.right + base);
}
public void avg() {
// 평균치에 base의 값을 포함시킨다.
System.out.println((this.left + this.right + base) / 2);
}
}
public class CalculatorDemo2 {
public static void main(String[] args) {
Calculator2 c1 = new Calculator2();
c1.setOprands(10, 20);
// 30 출력
c1.sum();
Calculator2 c2 = new Calculator2();
c2.setOprands(20, 40);
// 60 출력
c2.sum();
// 클래스 변수 base의 값을 10으로 지정했다.
Calculator2.base = 10;
// 40 출력
c1.sum();
// 70 출력
c2.sum();
}
}- 변수 PI의 앞에 static이 붙었다. static을 멤버(변수,메소드) 앞에 붙이면 클래스의 멤버가 된다.

package org.opentutorials.javatutorials.classninstance;
class C1{
static int static_variable = 1; //클래스 변수
int instance_variable = 2; //인스턴스 변수
static void static_static(){
System.out.println(static_variable);
//클래스 메소드가 클래스 변수에 접근
}
static void static_instance(){
// 클래스 메소드에서는 인스턴스 변수에 접근 할 수 없다.
//System.out.println(instance_variable);
}
void instance_static(){
// 인스턴스 메소드에서는 클래스 변수에 접근 할 수 있다.
System.out.println(static_variable);
}
void instance_instance(){
System.out.println(instance_variable);
//인스턴스 메소드가 인스턴스 변수 접근
}
}
public class ClassMemberDemo {
public static void main(String[] args) {
C1 c = new C1();
// 인스턴스를 이용해서 정적 메소드에 접근 -> 성공
// 인스턴스 메소드가 정적 변수에 접근 -> 성공
c.static_static();
// 인스턴스를 이용해서 정적 메소드에 접근 -> 성공
// 정적 메소드가 인스턴스 변수에 접근 -> 실패
c.static_instance();
// 인스턴스를 이용해서 인스턴스 메소드에 접근 -> 성공
// 인스턴스 메소드가 클래스 변수에 접근 -> 성공
c.instance_static();
// 인스턴스를 이용해서 인스턴스 메소드에 접근 -> 성공
// 인스턴스 메소드가 인스턴스 변수에 접근 -> 성공
c.instance_instance();
// 클래스를 이용해서 클래스 메소드에 접근 -> 성공
// 클래스 메소드가 클래스 변수에 접근 -> 성공
C1.static_static();
// 클래스를 이용해서 클래스 메소드에 접근 -> 성공
// 클래스 메소드가 인스턴스 변수에 접근 -> 실패
C1.static_instance();
// 클래스를 이용해서 인스턴스 메소드에 접근 -> 실패
//C1.instance_static();
// 클래스를 이용해서 인스턴스 메소드에 접근 -> 실패
//C1.instance_instance();
}
}- 인스턴스 메소드는 클래스 멤버에 접근 할 수 있다.
- 클래스 메소드는 인스턴스 멤버에 접근 할 수 없다.
- 인스턴스 변수는 인스턴스가 만들어지면서 생성되는데, 클래스 메소드는 인스턴스가 생성되기 전에 만들어지기 때문에 클래스 메소드가 인스턴스 멤버에 접근하는 것은 존재하지 않는 인스턴스 변수에 접근하는 것과 같다.
2. this
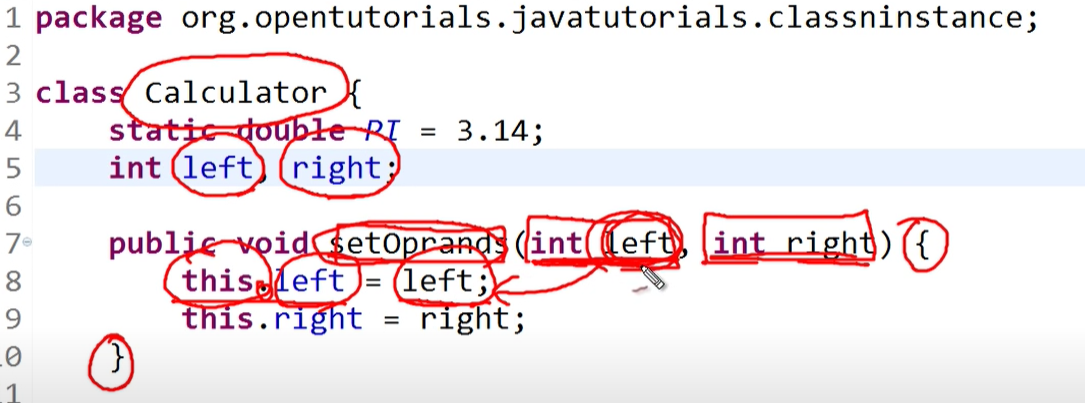
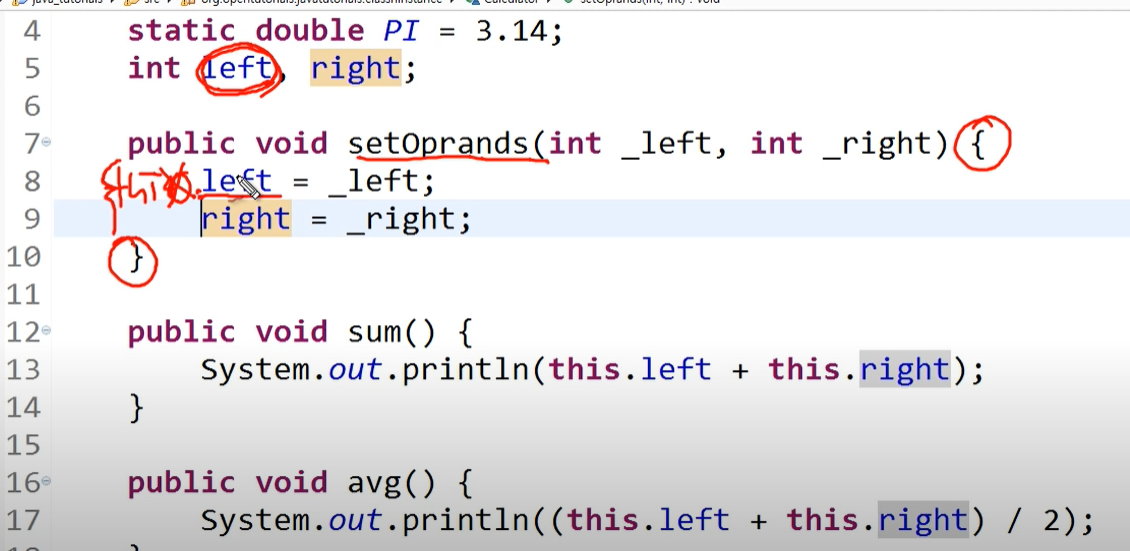
-
둘은 같은 의미를 가진다.
-
지역변수가 아닌 변수 값에 대입하게 되면 스코프 안에 없는 left, right를 밖에 선언된 것인지를 알기 때문이다.
3. 생성자
public Calculator(int left, int right) {
this.left = left;
this.right = right;
}
-
다음과 같이 클래스와 동일한 이름의 함수이다.
-
생성자는 그 이름처럼 객체를 생성할 때 호출된다.
-
생성자 덕분에 Calculator 객체를 사용하기 위해서 사실상 반드시 필요한 작업이라고 할 수 있는 좌항(left)과 우항(right)의 값을 설정하는 과정을 객체 생성 과정에서 강제할 수 있게 되었다. 절차를 하나 줄인 것뿐이지만, 객체를 사용하기 위해서는 객체를 생성해야 한다는 사실은 기본적으로 숙지하고 있는 절차이기 때문에 이 절차에 필수적인 작업을 포함시킨다는 것은 중요한 의미를 갖게 된다.
생성자의 특징
- 값을 반환하지 않는다.
- 생성자는 인스턴스를 생성해주는 역할을 하는 특수한 메소드라고 할 수 있다. 그런데 반환 값이 있다면 엉뚱한 객체가 생성될 것이다. 따라서 반환 값을 필요로하는 작업에서는 생성자를 사용하지 않는다. 반환 값이 없기 때문에 return도 사용하지 않고, 반환 값을 메소드 정의에 포함시키지도 않는다.
- 생성자의 이름은 클래스의 이름과 동일하다.
- 자바에서 클래스의 이름과 동일한 메소드는 생성자로 사용하기로 약속되어 있다.
4. super
-
자바는 메소드가 없는 경우 기본 생성자를 만들어 준다.
-
하지만, 명시적으로 생성자가 만들어질 경우 자바는 기본 생성자를 만들어주지 않는다.
-
하위 클래스가 호출될 때 자동으로 상위 클래스의 기본 생성자를 호출하게 된다. 그런데 상위 클래스에 매개변수가 있는 생성자가 있다면 자바는 자동으로 상위 클래스의 기본 생성자를 만들어주지 않는다. 따라서 존재하지 않는 생성자를 호출하게 되기 때문에 에러가 발생했다. 이 문제를 해결하기 위해서는 아래와 같이 상위 클래스에 기본 생성자를 추가하면 된다.
package org.opentutorials.javatutorials.Inheritance.example3;
class Calculator {
int left, right;
//기본 생성자
public Calculator(){
}
public Calculator(int left, int right){
this.left = left;
this.right = right;
}
public void setOprands(int left, int right) {
this.left = left;
this.right = right;
}
public void sum() {
System.out.println(this.left + this.right);
}
public void avg() {
System.out.println((this.left + this.right) / 2);
}
}
class SubstractionableCalculator extends Calculator {
public SubstractionableCalculator(int left, int right) {
this.left = left;
this.right = right;
}
public void substract() {
System.out.println(this.left - this.right);
}
}
public class CalculatorConstructorDemo5 {
public static void main(String[] args) {
SubstractionableCalculator c1 = new SubstractionableCalculator(10, 20);
c1.sum();
c1.avg();
c1.substract();
}
}
- super는 상위 클래스를 가리키는 키워드다.
class SubstractionableCalculator extends Calculator {
public SubstractionableCalculator(int left, int right) {
//하위 클래스의 생성자에 사용한다.
super(left, right);
}
public void substract() {
System.out.println(this.left - this.right);
}
}
-
super 키워드는 부모 클래스를 의미한다. 여기에 () 붙이면 부모 클래스의 생성자를 의미하게 된다. 이렇게 하면 부모 클래스의 기본 생성자가 없어져도 오류가 발생하지 않는다.
-
하위 클래스의 생성자에서 super를 사용할 때 주의할 점은 super가 가장 먼저 나타나야 한다는 점이다. 즉 부모가 초기화되기 전에 자식이 초기화되는 일을 방지하기 위한 정책이라고 생각하자.
5. overriding(재정의)
package org.opentutorials.javatutorials.overriding.example1;
class Calculator {
int left, right;
public void setOprands(int left, int right) {
this.left = left;
this.right = right;
}
public void sum() {
System.out.println(this.left + this.right);
}
public void avg() {
System.out.println((this.left + this.right) / 2);
}
}
class SubstractionableCalculator extends Calculator {
public void sum() {
System.out.println("실행 결과는 " +(this.left + this.right)+"입니다.");
}
public int avg() {
return (this.left + this.right)/2;
}
public void substract() {
System.out.println(this.left - this.right);
}
}
public class CalculatorDemo {
public static void main(String[] args) {
SubstractionableCalculator c1 = new SubstractionableCalculator();
c1.setOprands(10, 20);
c1.sum();
c1.avg();
c1.substract();
}
}
-
overriding을 하기 위해서는 메소드의 리턴 형식이 같아야 한다. 즉 클래스 Calculator의 메소드 avg는 리턴 타입이 void이다. 그런데 이것을 상속한 클래스 SubstractionableCalculator의 리턴 타입은 int이다. 오버라이딩을 하기 위해서는 아래의 조건을 충족시켜야 한다.
- 메소드의 이름
- 메소드 매개변수의 숫자와 데이터 타입 그리고 순서
- 메소드의 리턴 타입
위와 같이 메소드의 형태를 정의하는 사항들을 통털어서 메소드의 서명(signature) 라고 한다. 즉 위의 에러는 메소드들 간의 서명이 달라서 발생한 문제다. 아래와 같이 상위 클래스의 코드를 변경해서 이 문제를 우회하자.
package org.opentutorials.javatutorials.overriding.example1;
class Calculator {
int left, right;
public void setOprands(int left, int right) {
this.left = left;
this.right = right;
}
public void sum() {
System.out.println(this.left + this.right);
}
public int avg() {
return ((this.left + this.right) / 2);
}
}
class SubstractionableCalculator extends Calculator {
public void sum() {
System.out.println("실행 결과는 " +(this.left + this.right)+"입니다.");
}
public int avg() {
return ((this.left + this.right) / 2);
}
public void substract() {
System.out.println(this.left - this.right);
}
}
public class CalculatorDemo {
public static void main(String[] args) {
SubstractionableCalculator c1 = new SubstractionableCalculator();
c1.setOprands(10, 20);
c1.sum();
c1.avg();
c1.substract();
}
}- 상위 클래스와 하위 클래스의 서명이 같기 때문에 메소드 오버라이딩을 할 수 있었다. 그런데 위의 코드를 보면 중복이 발생했다. 메소드 avg의 부모와 자식 클래스가 같은 로직을 가지고 있다. 중복은 제거 되어야 한다. 생성자와 마찬가지로 super를 사용하면 이 문제를 해결 할 수 있다.
package org.opentutorials.javatutorials.overriding.example1;
class Calculator {
int left, right;
public void setOprands(int left, int right) {
this.left = left;
this.right = right;
}
public void sum() {
System.out.println(this.left + this.right);
}
public int avg() {
return ((this.left + this.right) / 2);
}
}
class SubstractionableCalculator extends Calculator {
public void sum() {
System.out.println("실행 결과는 " +(this.left + this.right)+"입니다.");
}
public int avg() {
//super는 부모클래스를 의미한다.
//뒤에 로직을 추가해도 된다.
return super.avg();
}
public void substract() {
System.out.println(this.left - this.right);
}
}
public class CalculatorDemo {
public static void main(String[] args) {
SubstractionableCalculator c1 = new SubstractionableCalculator();
c1.setOprands(10, 20);
c1.sum();
System.out.println("실행 결과는" + c1.avg());
c1.substract();
}
}- 메소드 sum이 SubstractionableCalculator에 추가 되었다. 실행결과는 c1.sum이 상위 클래스의 메소드가 아니라 하위 클래스의 메소드 sum을 실행하고 있다는 것을 보여준다. 하위 클래스 입장에서 부모 클래스란 말하자면 기본적인 동작 방법을 정의한 것이라고 생각할 수 있다. 하위 클래스에서 상의 클래스와 동일한 메소드를 정의하면 부모 클래스로부터 물려 받은 기본 동작 방법을 변경하는 효과를 갖게 된다. 기본동작은 폭넓게 적용되고, 예외적인 동작은 더 높은 우선순위를 갖게하고 있다. 이것은 공학에서 일반적으로 발견되는 규칙이다. 이것을 메소드 오버라이딩(overriding)이라고 한다.
6. overloading
package org.opentutorials.javatutorials.overloading.example1;
public class OverloadingDemo {
void A (){System.out.println("void A()");}
void A (int arg1){System.out.println("void A (int arg1)");}
void A (String arg1){System.out.println("void A (String arg1)");}
//int A (){System.out.println("void A()");}
public static void main(String[] args) {
OverloadingDemo od = new OverloadingDemo();
od.A();
od.A(1);
od.A("coding everybody");
}
}-
3행과 4행의 메소드 A는 매개변수의 숫자가 다르다. 4행과 5행의 메소드 A는 인자의 숫자는 같지만 매개변수의 데이터 타입이 다르다. 이런 경우는 오버로딩이 가능하다. 메소드를 호출 할 때 전달되는 인자의 데이터 타입에 따라서 어떤 메소드를 호출할지를 자바가 판단 할 수 있기 때문이다.
-
하지만 메소드의 반환값은 메소드를 호출하는 시점에서 전달되지 않는 정보이기 때문에 오버로딩의 대상이 될 수 없다.
->즉, 리턴값, 메소드의 이름은 같아야하고 매개변수의 데이터 타입은 달라야한다. 추가로 매개변수의 이름은 달라도 상관이 없다.
overriding VS overloading
오버라이딩과 오버로딩은 용어가 참으로 헷갈린다. 당연하다. 중요한 것은 오버라이딩이 무엇이고 오버로딩이 무엇인가를 구분하는 것은 아니다. riding(올라탄다) 을 이용해서 부모 클래스의 메소드의 동작방법을 변경하고, loading을 이용해서 같은 이름, 다른 매개변수의 메소드들을 여러개 만들 수 있다는 사실을 아는 것이 중요하다. 다만 학습이나 협업의 과정에서 개념을 주고 받을 때는 용어가 중요해진다. 필자의 생각에 이 개념들이 헷갈리는 이유는 over라는 공통분모 때문이다. over를 제외하고 알아두면 덜 헷갈리지 않을까 싶다. (참고로 overriding는 재정의라는 사전적인 의미가 있습니다.)
➕더 많은 값을 대상으로 연산을 해야할 때
package org.opentutorials.javatutorials.overloading.example1;
class Calculator{
int[] oprands;
public void setOprands(int[] oprands){
this.oprands = oprands;
}
public void sum(){
int total = 0;
for(int value : this.oprands){
total += value;
}
System.out.println(total);
}
public void avg(){
int total = 0;
for(int value : this.oprands){
total += value;
}
System.out.println(total/this.oprands.length);
}
}
public class CalculatorDemo {
public static void main(String[] args) {
Calculator c1 = new Calculator();
c1.setOprands(new int[]{10,20});
c1.sum();
c1.avg();
c1.setOprands(new int[]{10,20,30});
c1.sum();
c1.avg();
}
}
7. 클래스 패스
- 클래스 하나는 하나의 클래스 파일이 된다.
- ClasspathDemo2.java을 만들고 내용을 아래와 같이 한다.
class Item2{
public void print(){
System.out.println("Hello world");
}
}
class ClasspathDemo2 {
public static void main(String[] args){
Item2 i1 = new Item2();
i1.print();
}
}
- 컴파일을 한다.
javac ClasspathDemo2.java
- 그리고 현재 디렉터리 하위에 lib을 만들고 여기에 Item2.class 파일을 이동한다. 현재 디렉터리에는 Item2.class 파일이 없어야 한다. 그리고 ClasspathDemo2를 실행한다.
java ClasspathDemo2
- 이것은 item.class 파일이 현재 디렉터리에 존재하지 않기 때문에 찾을 수 없다는 메시지다. 아래와 같이 실행해서 이 문제를 해결할 수 있다.
java -classpath ".;lib" ClasspathDemo2
//리눅스,OSX와 같은 유닉스 계열은 콜론 사용
java -classpath ".:lib" ClasspathDemo2
- 옵션 -classpath는 자바를 실행할 때 사용할 클래스들의 위치를 가상머신에게 알려주는 역할을 한다. -classpath의 값으로 사용된 ".;lib"를 살펴보자.
.
현재 디렉터리에서 클래스를 찾는다는 뜻이다.
;
경로와 경로를 구분해주는 구분자
lib
현재 디렉터리에 없다면 현재 디렉터리의 하위 디렉터리 중 lib에서 클래스를 찾는다는 의미다.
- 만약 .을 제외한다면 어떻게 될까? 아래와 같은 오류가 발생할 것이다.
-> 오류: 기본 클래스 Classpath을(를) 찾거나 로드할 수 없습니다.
디렉터리 lib 아래에 있는 Item.class 파일을 찾았는데 정작 현재 디렉터리에 있는 ClasspathDemo.class 파일은 찾을 수 없기 때문이다.
이와 같이 클래스 패스라는 것은 자바를 실행할 때 클래스의 위치를 지정하는 역할을 하는 것이다. 클래스 패스는 자바 애플리케이션이 사용하고 있는 클래스가 여러 경로에 분산되어 있을 때 유용하게 사용할 수 있는 방법이다.
지금까지는 자바를 실행할 때 클래스 패스를 지정하는 방법을 알아봤다. 실행 할 때마다 클래스 패스를 지정하는 것이 귀찮다면 클래스 패스를 시스템의 환경변수로 지정하면 된다.
8. 환경 변수
- 환경변수 는 운영체제에 지정하는 변수로 자바 가상머신과 같은 애플리케이션들은 환경변수의 값을 참고해서 동작하게 된다.
- 자바는 클래스 패스로 환경변수 CLASSPATH를 사용하는데 이 값을 지정하면 실행할 때마다 -classpath 옵션을 사용하지 않아도 되기 때문에 편리하다. 하지만 운영체제를 변경하면 클래스 패스가 사라지기 때문에 이식성면에서 불리할 수 있다.
9. 패키지
良い言葉 :)
우리는 이미 패키지를 사용해왔다. 일부 IDE들은 패키지의 사용을 강제하고 있기 때문에 독자가 패키지가 무엇인지도 숙지하지 않은 상태에서 패키지를 사용한 것이다. 주제에서 어긋나는 이야기이지만 지식이라는 것이 사실은 순차적이지 않고 네트워크적이라는 점을 생각해볼 필요가 있다. 순차적인 것은 순서가 있다는 의미다. 즉 먼저 배워야 할 것이 있고 나중에 배워야 할 것이 있다는 의미다. 우리 수업도 그런 식으로 되어 있다. 수업이 그렇다보니 배우는 입장에서는 지식을 순차적으로만 받아들이게 된다.
하지만 패키지의 예를 통해서도 엿볼 수 있듯이 처음부터 사용되지만, 나중에 설명할 수밖에 없는 것이 있다. 지금 패키지를 설명하고 있지만, 패키지의 어떤 측면은 아직도 설명할 수 없는 것이 있다. 그리고 이러한 부분이 독자 입장에서는 고통스러울 것이다. 필자는 배우는 입장에서 중요한 능력이 두 가지 있다고 생각한다. 하나는 모르는 것을 알고자 하는 호기심이다. 다른 하나는 모르는 것을 견디는 인내심이다. 이 두 가지 상반되는 것 같은 미덕이 조화롭게 공존 할 때 지식은 받아들여지는 것 같다. 처음에는 온갖 개념들이 머릿속에서 춤을 출 것이다. 하지만 차츰 끊어져 있던 개념들이 거미줄처럼 연결되기 시작하면서 개념들의 존재감은 조용히 사라질 것이다. 그러다 어떤 맥락을 만났을 때 거짓말처럼 뛰쳐나와서 춤을 추기 시작한다.
출처는 기억나지 않지만, 인상적으로 간직하고 있는 문구가 있다.
"배우고 익히고 잊어버려라"
//잊어버림은 익숙함인 듯 하다.
-
패키지는 기본적으로 디렉터리와 일치한다. 그렇기 때문에 아래의 패키지들은 물리적으로 같은 디렉터리에 존재할 수 없다.
- org.opentutorials.javatutorials.object
- org.opentutorials.javatutorials.classninstance
-
패키지명은 일반적으로 클래스를 제작한 개인이나 단체가 소속된 웹사이트의 도메인을 이용한다. 패키지의 이름도 중복될 수 있는데 웹사이트의 도메인 전세계에서 유일무일한 식별자이기 때문에 이러한 중복의 문제를 피할 수 있다.
- 서로 다른 패키지에 있는 클래스를 가져오려면 import를 통해서 다른 패키지의 클래스를 현재의 소스코드로 불러와야 한다. 만약 특정 패키지에 있는 모든 클래스를 로드하고 싶다면 아래와 같이 하면 된다.
package org.opentutorials.javatutorials.packages.example2;
import org.opentutorials.javatutorials.packages.example1.*;
public class C {
public static void main(String[] args) {
A a = new A();
}
}
➕손 컴파일
프로젝트 디렉터리의 구성을 살펴보자.
- src : 소스 코드가 들어있다.
- bin : 컴파일된 클래스 파일이 들어있다.
컴파일을 하려면 콘솔을 실행시켜야 한다. 콘솔을 프로젝트 디렉토리로 이동한다. 필자의 경우 아래와 같다.
-
컴파일하기
javac src/org/opentutorials/javatutorials/packages/example3/*.java
-
bin 하위에 클래스파일이 위치하도록 하기
javac src/org/opentutorials/javatutorials/packages/example3/*.java -d bin
- -d bin은 컴파일된 결과를 bin 디렉토리 하위에 위치시킨다는 의미다. 자바 컴파일러는 자동으로 클래스의 패키지에 해당하는 디렉토리를 생성해준다.
10. API
System.out.println(1);이것이 화면에 어떤 내용을 출력하는 것이라는 건 이미 알고 있다. 하지만 도대체 우리가 정의한 적이 없는 이 명령은 무엇일까?를 생각해볼 때가 왔다. 문법적으로 봤을 때 println은 메소드가 틀림없다. 그런데 메소드 앞에 Sytem.out이 있다. System은 클래스이고 out은 그 클래스의 필드(변수)이다. 이 필드가 메소드를 가지고 있는 것은 이 필드 역시 객체라는 것을 알 수 있다. 그리고 System을 인스턴스화한적이 없음에도 불구하고 필드 out에 접근할 수 있는 것은 out이 static이라는 것을 암시한다.
package org.opentutorials.javatutorials.library;
//자동 import
import java.lang.*;
public class LibraryDemo1 {
public static void main(String[] args) {
System.out.println(1);
}
}-
패키지 java.lang은 자바 프로그래밍을 하기 위해서 필수적인 클래스들을 모아둔 패키지다. 따라서 사용자의 편의를 위해서 자동으로 로딩을 하고 있는 것이다.
- 클래스 System은 바로 이 java.lang의 소속이다.
자바 에플리케이션을 만든다는 것은 결과적으로 자바에서 제공하는 패키지들을 부품으로 조립해서 사용자 정의 로직을 만드는 과정이라고 할 수 있다.
API란?
API란 자바 시스템을 제어하기 위해서 자바에서 제공하는 명령어들을 의미한다. Java SE(JDK) 를 설치하면 자바 시스템을 제어하기 위한 API를 제공한다. 자바 개발자들은 자바에서 제공한 API를 이용해서 자바 애플리케이션을 만들게 된다. 패키지 java.lang.*의 클래스들도 자바에서 제공하는 API 중의 하나라고 할 수 있다.
11. 접근 제어자
package org.opentutorials.javatutorials.accessmodifier;
class A {
public String y(){
return "public void y()";
}
private String z(){
return "public void z()";
}
public String x(){
//같은 클래스 내에 있기에 호출 가능
return z();
}
}
public class AccessDemo1 {
public static void main(String[] args) {
A a = new A();
System.out.println(a.y());
// 아래 코드는 오류가 발생한다.
//System.out.println(a.z());
System.out.println(a.x());
}
}-
메소드가 키워드 private으로 시작되고 있다. private은 클래스(A) 밖에서는 접근 할 수 없다는 의미다. 바로 이 private의 자리에 오는 것들을 접근 제어자(access modifier) 라고 한다. 그럼 사용할 수 없는 메소드를 왜 정의하고 있는 것일까? 내부적으로 사용하기 위해서다.
-
접근 제어자가 public이기 때문에 호출 할 수 있다. 그리고 메소드의 내용을 보면 내부적으로 메소드 z를 호출하고 있다. 메소드 z는 정상적으로 호출된다. 왜냐하면 메소드 x와 메소드 z는 같은 클래스의 소속이기 때문이다. 따라서 메소드 x에서 z를 호출 할 수 있는 것이다.
접근 제어자를 사용하는 이유
-
객체의 로직을 보호하기 위해서는 맴버에 따라서 외부의 접근을 허용하거나 차단해야 할 필요가 생긴다. 마치 은행이 누구나 접근 할 수 있는 창구와 관계자외에는 출입이 엄격하게 통제되는 금고를 구분하고 있는 이유와 같다.
-
접근 제어자를 사용하는 또 다른 이유는 사용자에게 객체를 조작 할 수 있는 수단만을 제공함으로서 결과적으로 객체의 사용에 집중 할 수 있도록 돕기 위함이다.
접근 제어자는 public과 private외에도 두가지가 더 있다. protected과 default가 그것이다.
- protected는 상속 관계에 있다면 서로 다른 패키지에 있는 클래스의 접근도 허용한다.
- default는 접근 제어 지시자가 없는 경우를 의미하는데, 접근 제어자가 없는 메소드는 같은 패키지에 있고 상속 관계에 있는 메소드에 대해서만 접근을 허용한다.
아래 그림은 접근 제어자 별로 접근의 허용범위를 그림으로 나타낸 것이다. 안쪽에 있을수록 접근 통제가 삼엄하고, 밖에 있을수록 접근이 허용된다.
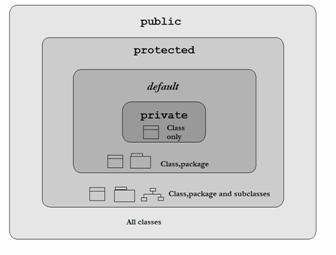
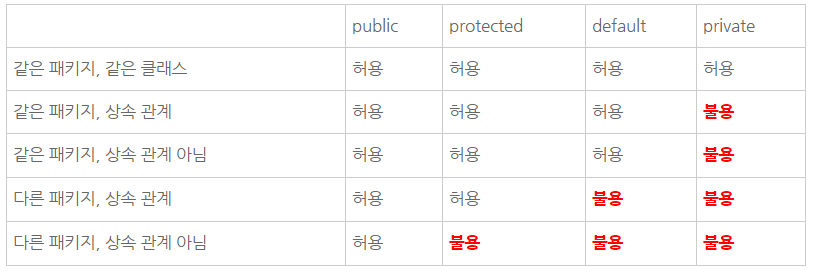
클래스의 접근 제어자
클래스의 접근 제어자는 총 2개로 public과 default이다.
- default는 접근 제어자를 붙이지 않은 경우 default가 된다. 클래스의 접근 제어자는 패키지와 관련된 개념이다.
- 즉 접근 제어자가 public인 클래스는 다른 패키지의 클래스에서도 사용할 수 있고, default인 경우는 같은 패키지에서만 사용 가능하다.
- 한가지 중요한 제약 사항이 있다. public 클래스가 포함된 소소코드는 public 클래스의 클래스 명과 소스코드의 파일명이 같아야 한다. 코드를 보자. 이 코드의 이름은 PublicNameDemo.java이다.
package org.opentutorials.javatutorials.accessmodifier.inner;
//public class PublicName {}
public class PublicNameDemo {}
- 주석처리된 부분은 오류가 발생한다. 퍼블릭 클래스의 이름과 소스코드의 이름이 일치하지 않기 때문이다. 그 말은 하나의 소스 코드에는 하나의 public 클래스가 존재 할 수 있다는 의미다.
접근 제어자는 그것이 무엇인지, 또 어떤 접근 제어자가 있는지 정도만 일단 알아두자. 그리고 당분간은 public과 private만 구분해서 사용만해도 더 안전하고 결고한 에플리케이션을 만들 수 있을 것이다. 다시 한번 강조 하지만 각박하게 외우지 말자. 느긋하게 이해하자. 충분한 이해는 암기의 양을 비약적으로 줄여준다.
12. 추상화(abstract)
추상 메소드
- 추상 메소드란 메소드의 시그니처만이 정의된 비어있는 메소드를 의미한다. 아래의 코드를 보자.
package org.opentutorials.javatutorials.abstractclass.example1;
abstract class A{
public abstract int b();
//본체가 있는 메소드는 abstract 키워드를 가질 수 없다.
//public abstract int c(){System.out.println("Hello")}
//추상 클래스 내에는 추상 메소드가 아닌 메소드가 존재 할 수 있다.
public void d(){
System.out.println("world");
}
}
public class AbstractDemo {
public static void main(String[] args) {
A obj = new A();
}
}- 메소드 b의 선언 부분에는 abstract라는 키워드가 등장하고 있다. 이 키워드는 메소드 b는 메소드의 시그니처만 정의 되어 있고 이 메소드의 구체적인 구현은 하위 클래스에서 오버라이딩 해야 한다는 의미다. - 이렇게 내용이 비어있는 메소드를 추상 메소드라고 부른다.
- 추상 메소드를 하나라도 포함하고 있는 클래스는 추상 클래스가 되고, 자연스럽게 클래스의 이름 앞에 abstract가 붙는다.
추상 클래스의 상속
- 클래스 A를 상속한 하위 클래스를 만들고 추상 메소드를 오버라이드해서 내용있는 메소드를 만들어야 한다.
package org.opentutorials.javatutorials.abstractclass.example2;
abstract class A{
public abstract int b();
public void d(){
System.out.println("world");
}
}
class B extends A{
public int b(){return 1;}
}
public class AbstractDemo {
public static void main(String[] args) {
B obj = new B();
System.out.println(obj.b());
}
}- 추상 클래스는 상속을 강제하기 위한 것이다. 즉 부모 클래스에는 메소드의 시그니처만 정의해놓고 그 메소드의 실제 동작 방법은 이 메소드를 상속 받은 하위 클래스의 책임으로 위임하고 있다.
package org.opentutorials.javatutorials.abstractclass.example3;
abstract class Calculator{
int left, right;
public void setOprands(int left, int right){
this.left = left;
this.right = right;
}
public abstract void sum();
public abstract void avg();
public void run(){
sum();
avg();
}
}
class CalculatorDecoPlus extends Calculator {
public void sum(){
System.out.println("+ sum :"+(this.left+this.right));
}
public void avg(){
System.out.println("+ avg :"+(this.left+this.right)/2);
}
}
class CalculatorDecoMinus extends Calculator {
public void sum(){
System.out.println("- sum :"+(this.left+this.right));
}
public void avg(){
System.out.println("- avg :"+(this.left+this.right)/2);
}
}
public class CalculatorDemo {
public static void main(String[] args) {
CalculatorDecoPlus c1 = new CalculatorDecoPlus();
c1.setOprands(10, 20);
c1.run();
CalculatorDecoMinus c2 = new CalculatorDecoMinus();
c2.setOprands(10, 20);
c2.run();
}
}
- 위의 예제는 합계(sum)를 실행하고 평균(avg)을 실행하는 절차를 메소드 run을 통해서 한 번에 실행되도록 한 코드이다. 그런데 경우에 따라서 합계와 평균을 화면에 출력하는 모습을 달리해야 하는 경우가 있다고 치자. 그런 경우에 상황에 따라서 동작 방법이 달라지는 메소드(sum, avg)는 추상 메소드로 만들어서 하위 클래스에서 구현하도록 하고 모든 클래스의 공통분모(setOprands, run)의 경우에는 상위 클래스에 두어서 코드의 중복, 유지보수의 편의성 등을 꾀할 수 있다.
디자인 패턴
이러한 개발 방법을 template method pattern이라고도 한다. 아래는 추억의 템플릿이다.

위의 그림에 등장하는 템플릿은 자주 사용하는 모양을 모아둔 것이라고 할 수 있다. 템플릿은 모양을 결정하지만 템플릿을 통해서 그려질 도형은 팬의 종류나 색상에 따라서 달라진다. 즉 공통분모인 메소드 run은 메소드 sum과 avg가 어떻게 동작할지 알 수 없지만 sum이 실행되고 avg을 실행시킨다. 반면에 실행결과를 어떤 기호(+,-)로 시작할지는 하위 클래스에서 결정하고 있다.
즉, 위의 예제를 통해서도 알 수 있지만 프로그래밍이라는 것은 반복되는 패턴이 있다. 이런 패턴들을 모아서 정리한 것이 디자인 패턴(design pattern) 이다. 물론 시각 디자이너들의 디자인이 아니라 좋은 소프트웨어를 만들기 위한 설계로서 디자인이라는 표현을 쓰고 있는 것이다.
- 디자인 패턴의 장점은 크게 두가지이다.
- 하나는 좋은 설계를 단기간에 학습할 수 있다는 점이다. 물론 비교적 단기간이라는 뜻이다.
- 다른 하나는 소통에 도움이 된다는 점이다. 설계 방법을 토의하거나 전달할 때 설계 방법에 따라 적절한 이름이 있다면 상호간에 생각을 일치시키는 데 큰 도움이 될 것이다.
13. final
- 추상이 상속을 강제하는 것이라면 final은 상속/변경을 금지하는 규제다.
- 공유되는 것들은 static을 사용 했었는데, 이를 바뀌지 않는 것을 사용하는 방식은 없었기 때문에 final이 그 역할을 해준다.
final 필드
필드와 변수는 같은 의미라는 것 기억할 것이다.
- 실행되는 과정에서 한번 값이 정해진 이후에는 변수 내의 값이 바뀌지 않도록하는 규제다.
package org.opentutorials.javatutorials.finals;
class Calculator {
//final 사용
static final double PI = 3.14;
int left, right;
public void setOprands(int left, int right) {
this.left = left;
this.right = right;
//Calculator.PI = 6;
}
public void sum() {
System.out.println(this.left + this.right);
}
public void avg() {
System.out.println((this.left + this.right) / 2);
}
}
public class CalculatorDemo1 {
public static void main(String[] args) {
Calculator c1 = new Calculator();
System.out.println(c1.PI);
//Calculator.PI = 10;
}
}- final로 지정된 변수에는 한번 값이 할당되면 그 값을 바꿀 수 없다.
final 메소드
package org.opentutorials.javatutorials.finals;
class A{
final void b(){}
}
class B extends A{
void b(){}
}
- final 메소드 b를 상속하려하기 때문에 오류가 발생한다.
final 클래스
package org.opentutorials.javatutorials.finals;
final class C{
final void b(){}
}
class D extends C{}
- final 클래스를 상속하려하고 있다. 따라서 오류가 발생한다.
14. 인터페이스
- 어떤 객체가 있고 그 객체가 특정한 인터페이스를 사용한다면 그 객체는 반드시 인터페이스의 메소드들을 구현해야 한다. 만약 인터페이스에서 강제하고 있는 메소드를 구현하지 않으면 이 에플리케이션은 컴파일 조차 되지 않는다.
package org.opentutorials.javatutorials.interfaces.example1;
interface I{
public void z();
}
//클래스 A는 인터페이스 I를 '구현' 한다.
class A implements I{
public void z(){}
}-
인터페이스와 상속은 다르다. 상속이 상위 클래스의 기능을 하위 클래스가 물려 받는 것이라고 한다면, 인터페이스는 하위 클래스에 특정한 메소드가 반드시 존재하도록 강제한다.
- 클래스를 선언 할 때는 class를 사용하지만 인터페이스는 interface를 사용한다.
- 또 상속은 extends를 사용하지만 인터페이스는 implements를 사용한다. 이를 바탕으로 위의 예제를 해설해보면 아래와 같다.
-
클래스 Calculator를 사용할 개발자가 이 클래스가 가지고 있어야 할 메소드를 인터페이스로 만들어서 제공하는 것이다. 반대의 경우도 가능하다. 만드는 쪽에서 인터페이스를 제공하면 된다.
이렇게 해서 만들어진 코드를 보자. 아래는 약속을 정의하고 있는 인터페이스이다.
package org.opentutorials.javatutorials.interfaces.example2;
public interface Calculatable {
public void setOprands(int first, int second, int third) ;
public int sum();
public int avg();
}
다음은 인터페이스를 구현한 가짜 클래스를 임시로 사용해서 만든 에플리케이션이다.
package org.opentutorials.javatutorials.interfaces.example2;
class CalculatorDummy implements Calculatable{
public void setOprands(int first, int second, int third){
}
public int sum(){
return 60;
}
public int avg(){
return 20;
}
}
public class CalculatorConsumer {
public static void main(String[] args) {
CalculatorDummy c = new CalculatorDummy();
c.setOprands(10, 20, 30);
System.out.println(c.sum()+c.avg());
}
}
다음 코드는 인터페이스에 따라서 구현된 클래스이다.
package org.opentutorials.javatutorials.interfaces.example2;
class Calculator implements Calculatable {
int first, second, third;
public void setOprands(int first, int second, int third) {
this.first = first;
this.second = second;
this.third = third;
}
public int sum() {
return this.first + this.second + this.third;
}
public int avg() {
return (this.first + this.second + this.third) / 3;
}
}
이제 해야 할 일은 가짜 클래스인 CalculatorDummy를 실제 로직으로 교체하면 된다.
package org.opentutorials.javatutorials.interfaces.example2;
public class CalculatorConsumer {
public static void main(String[] args) {
Calculator c = new Calculator();
c.setOprands(10, 20, 30);
System.out.println(c.sum()+c.avg());
}
}
인터페이스의 몇가지 규칙
1. 하나의 클래스가 여러개의 인터페이스를 구현 할 수 있다.
package org.opentutorials.javatutorials.interfaces.example3;
interface I1{
public void x();
}
interface I2{
public void z();
}
class A implements I1, I2{
public void x(){}
public void z(){}
}
- 클래스 A는 메소드 x나 z 중 하나라도 구현하지 않으면 오류가 발생한다.
2. 인터페이스도 상속이 된다.
package org.opentutorials.javatutorials.interfaces.example3;
interface I3{
public void x();
}
interface I4 extends I3{
public void z();
}
class B implements I4{
public void x(){}
public void z(){}
}
3. 인터페이스의 멤버는 반드시 public이다.
- 인터페이스는 그 인터페이스를 구현한 클래스를 어떻게 조작할 것인가를 규정한다. 그렇기 때문에 외부에서 제어 할 수 있는 가장 개방적인 접근 제어자인 public만을 허용한다. public을 생략하면 접근 제어자 default가 되는 것이 아니라 public이 된다. 왜냐하면 인터페이스의 맴버는 무조건 public이기 때문이다.
➕ abstract VS interface
인터페이스와 추상 클래스는 서로 비슷한 듯 다른 기능이다. 인터페이스는 클래스가 아닌 인터페이스라는 고유한 형태를 가지고 있는 반면 추상 클래스는 일반적인 클래스다.
또 인터페이스는 구체적인 로직이나 상태를 가지고 있을 수 없고, 추상 클래스는 구체적인 로직이나 상태를 가지고 있을 수 있다.
15. 다형성
- 다형성이란 하나의 메소드나 클래스가 있을 때 이것들이 다양한 방법으로 동작하는 것을 의미한다.
- 키보드의 키를 사용하는 방법은 '누른다'이다. 하지만 똑같은 동작 방법의 키라고 하더라도 ESC는 취소를 ENTER는 실행의 목적을 가지고 있다.
- 다형성이란 동일한 조작방법으로 동작시키지만 동작방법은 다른 것을 의미한다.
- 클래스 O의 메소드 a는 두개의 본체를 가지고 있다. 동시에 두개의 본체는 하나의 이름인 a를 공유하고 있다. 같은 이름이지만 서로 다른 동작 방법을 가지고 있기 때문에 오버로딩은 다형성의 한 예라고 할 수 있다.
클래스와 다형성
package org.opentutorials.javatutorials.polymorphism;
class A{
public String x(){return "x";}
}
class B extends A{
public String y(){return "y";}
}
public class PolymorphismDemo1 {
public static void main(String[] args) {
A obj = new B();
obj.x();
//이 코드는 실행되지 않는다.
obj.y();
}
}
클래스 B는 메소드 y를 가지고 있다. 그럼에도 불구하고 메소드 y가 마치 존재하지 않는 것처럼 실행되지 않고 있다. 10행의 코드를 아래와 같이 변경해보자.
B obj = new B();
- 즉 클래스 B의 데이터 형을 클래스 A로 하면 클래스 B는 마치 클래스 A인것처럼 동작하게 되는 것이다. 클래스 B를 사용하는 입장에서는 클래스 B를 클래스 A인것처럼 사용하면 된다.
package org.opentutorials.javatutorials.polymorphism;
class A{
public String x(){return "A.x";}
}
class B extends A{
public String x(){return "B.x";}
public String y(){return "y";}
}
public class PolymorphismDemo1 {
public static void main(String[] args) {
A obj = new B();
System.out.println(obj.x());
}
}- 클래스 A의 메소드 x를 클래스 B에서 오버라이딩하고 있다. 실행 결과는 아래와 같다.
결과: B.x
-
클래스 B의 데이터 타입을 클래스 A로 인스턴스화 했을 때 클래스 B의 메소드 y는 마치 존재하지 않는 것처럼 실행되지 않았다.
=> 클래스 B가 클래스 A화 되었다.
-
클래스 B의 데이터 타입을 클래스 A로해서 인스턴스화 했을 때 클래스 B의 메소드 x를 실행하면 클래스 A에서 정의된 메소드가 아니라 클래스 B에서 정의된 메소드가 실행 되었다.
=> 클래스 B의 기본적인 성질은 그대로 간직하고 있다.
- 결론:
클래스 B를 클래스 A의 데이터 타입으로 인스턴스화 했을 때 클래스 A에 존재하는 맴버만이 클래스 B의 맴버가 된다. 동시에 클래스 B에서 오버라이딩한 맴버의 동작방식은 그대로 유지한다.package org.opentutorials.javatutorials.polymorphism; class A{ public String x(){return "A.x";} } class B extends A{ public String x(){return "B.x";} public String y(){return "y";} } class B2 extends A{ public String x(){return "B2.x";} } public class PolymorphismDemo1 { public static void main(String[] args) { A obj = new B(); A obj2 = new B2(); System.out.println(obj.x()); System.out.println(obj2.x()); } }실행결과:
B.x
B2.x
아래의 코드는 서로 다른 클래스 B와 B2가 동일한 데이터 타입 A로 인스턴스화 되었다.
하지만 두 인스턴스의 메소드 x를 호출한 결과는 서로 다르다.
이것이 상속과 오버라이딩 그리고 형변환을 이용한 다형성이다.
package org.opentutorials.javatutorials.polymorphism;
abstract class Calculator{
int left, right;
public void setOprands(int left, int right){
this.left = left;
this.right = right;
}
int _sum() {
return this.left + this.right;
}
public abstract void sum();
public abstract void avg();
public void run(){
sum();
avg();
}
}
class CalculatorDecoPlus extends Calculator {
public void sum(){
System.out.println("+ sum :"+_sum());
}
public void avg(){
System.out.println("+ avg :"+(this.left+this.right)/2);
}
}
class CalculatorDecoMinus extends Calculator {
public void sum(){
System.out.println("- sum :"+_sum());
}
public void avg(){
System.out.println("- avg :"+(this.left+this.right)/2);
}
}
public class CalculatorDemo {
public static void execute(Calculator cal){
System.out.println("실행결과");
cal.run();
}
public static void main(String[] args) {
Calculator c1 = new CalculatorDecoPlus();
c1.setOprands(10, 20);
Calculator c2 = new CalculatorDecoMinus();
c2.setOprands(10, 20);
execute(c1);
execute(c2);
}
}
-
차이점은 Calculator를 상속 받은 클래스들을 인스턴스화 할 때 Calculator를 데이터 타입으로 하고 있다. 이렇게 되면 인스턴스 c1과 c2를 사용하는 입장에서 두개의 클래스 모두 Calculator인 것처럼 사용할 수 있다.
-
클래스 CalculatorDemo의 execute 메소드는 CalculatorDecoPlus와 CalculatorDecoMinus 클래스의 메소드 run을 호출하면서 그것이 '실행결과'라는 사실을 화면에 표시하는 기능을 가지고 있다. 이 때 메소드 execute 내부에서는 매개변수로 전달된 객체의 메소드 run을 호출하고 있다.
-
만약 메소드 execute의 매개변수 데이터 타입이 Calculator가 아니라면 어떻게 해야할까? 위와 같은 로직을 처리 할 수 없을 것이다. 메소드 execute 입장에서는 매개변수로 전달된 값이 Calculator이거나 그 자식이라면 메소드 run을 가지고 있다는 것을 보장 받을 수 있게 되는 것이다.
-
이 맥락에서의 다형성이란 하나의 클래스(Calculator)가 다양한 동작 방법(ClaculatorDecoPlus, ClaculatorDecoMinus)을 가지고 있는데 이것을 다형성이라고 할 수 있겠다.
인터페이스와 다형성
- 특정한 인터페이스를 구현하고 있는 클래스가 있을 때 이 클래스의 데이터 타입으로 인터페이스를 지정 할 수 있다.
package org.opentutorials.javatutorials.polymorphism;
interface I{}
class C implements I{}
public class PolymorphismDemo2 {
public static void main(String[] args) {
I obj = new C();
}
}
- 위의 코드를 통해서 알 수 있는 것은 클래스 C의 데이터 타입으로 인터페이스 I가 될 수 있다는 점이다. 이것은 다중 상속이 지원되는 인터페이스의 특징과 결합해서 상속과는 다른 양상의 효과를 만들어낸다. 아래 코드를 보자.
package org.opentutorials.javatutorials.polymorphism;
interface I2{
public String A();
}
interface I3{
public String B();
}
class D implements I2, I3{
public String A(){
return "A";
}
public String B(){
return "B";
}
}
public class PolymorphismDemo3 {
public static void main(String[] args) {
//D는 클래스
//I2는 D가 구현한 인터페이스 중 하나 ( A를 강제)
//I3는 D가 구현한 인터페이스 중 하나 ( B를 강제)
D obj = new D();
I2 objI2 = new D();
I3 objI3 = new D();
obj.A();
obj.B();
objI2.A();
//objI2.B();
//objI3.A();
objI3.B();
}
}
-
주석처리된 메소드 호출은 오류가 발생하는 것들이다. objI2.b()에서 오류가 발생하는 이유는 objI2의 데이터 타입이 인터페이스 I이기 때문이다.
-
인터페이스 I는 메소드 A만을 정의하고 있고 I를 데이터 타입으로 하는 인스턴스는 마치 메소드 A만을 가지고 있는 것처럼 동작하기 때문이다.
-
이것은 인터페이스의 매우 중요한 특징 중의 하나를 보여준다. 인스턴스 objI2의 데이터 타입을 I2로 한다는 것은 인스턴스를 외부에서 제어할 수 있는 조작 장치를 인스턴스 I2의 맴버로 제한한다는 의미가 된다. 인스턴스 I2와 I3로 인해서 하나의 클래스가 다양한 형태를 띄게 되는 것이다.
16. 예외(Exception)
- 예외(Exception) 란 프로그램을 만든 프로그래머가 상정한 정상적인 처리에서 벗어나는 경우에 이를 처리하기 위한 방법이다.
package org.opentutorials.javatutorials.exception;
class Calculator{
int left, right;
public void setOprands(int left, int right){
this.left = left;
this.right = right;
}
public void divide(){
try {
System.out.print("계산결과는 ");
System.out.print(this.left/this.right);
System.out.print(" 입니다.");
} catch(Exception e){
System.out.println("오류가 발생했습니다 : "+e.getMessage());
}
}
}
public class CalculatorDemo {
public static void main(String[] args) {
Calculator c1 = new Calculator();
c1.setOprands(10, 0);
c1.divide();
Calculator c2 = new Calculator();
c2.setOprands(10, 5);
c2.divide();
}
}try...catch
try
- try 안에는 예외 상황이 발생할 것으로 예상되는 로직을 위치시킨다.
catch
- catch 안에는 예외가 발생했을 때 뒷수습을 하기 위한 로직이 위치한다.
} catch(Exception e){
System.out.println("오류가 발생했습니다 : "+e.getMessage());
}
-
e는 변수다. 이 변수 앞의 Exception은 변수의 데이터 타입이 Exception이라는 의미다.
-
Exception은 자바에서 기본적으로 제공하는 클래스로 java.lang에 소속되어 있다. 예외가 발생하면 자바는 마치 메소드를 호출하듯이 catch를 호출하면서 그 인자로 Exception 클래스의 인스턴스를 전달하는 것이다.
-
e.getMessage() 는 자바가 전달한 인스턴스의 메소드 중 getMessage를 호출하는 코드인데, getMessage는 오류의 원인을 사람이 이해하기 쉬운 형태로 리턴하도록 약속되어 있다.
-e.toString() 은 e.getMessage()보다 더 자세한 예외 정보를 제공한다.
-e.printStackTrace() 는 리턴값이 없다. 이 메소드를 호출하면 메소드가 내부적으로 예외 결과를 화면에 출력한다. printStackTrace는 가장 자세한 예외 정보를 제공한다.
다중캐치
package org.opentutorials.javatutorials.exception;
class A{
private int[] arr = new int[3];
A(){
arr[0]=0;
arr[1]=10;
arr[2]=20;
}
public void z(int first, int second){
try {
System.out.println(arr[first] / arr[second]);
} catch(ArrayIndexOutOfBoundsException e){
System.out.println("ArrayIndexOutOfBoundsException");
} catch(ArithmeticException e){
System.out.println("ArithmeticException");
} catch(Exception e){
System.out.println("Exception");
}
}
}
public class ExceptionDemo1 {
public static void main(String[] args) {
A a = new A();
a.z(10, 0);
a.z(1, 0);
a.z(2, 1);
}
}
-
예제는 다중 catch를 보여준다. 조건문의 else if처럼 여러 개의 catch를 하나의 try 구문에서 사용할 수 있다. 이를 통해서 보다 간편하게 다양한 상황에 대응할 수 있다. 위의 코드는 try 구문에서 예외가 발생했을 때 그 예외의 종류가 ArrayIndexOutOfBoundsException이라면 14행이 실행되고, ArithemeticException이라면 16행이 실행되고 그 외의 것이라면 18행이 실행된다는 의미다.
-
Exception이 ArrayIndexOutOfBoundsException, ArithemeticException 보다 포괄적인 예외를 의미하기 때문에 Exception 이후에 등장하는 catch 문은 실행될 수 없는 구문이기 때문이다.
finally
- finally는 try 구문에서 예외가 발생하는 것과 상관없이 언제나 실행되는 로직이다.
- 어떤 작업의 경우는 예외와는 상관없이 반드시 끝내줘야 하는 작업이 있을 수 있다. 그런 경우 finally를 사용한다.
package org.opentutorials.javatutorials.exception;
class A{
private int[] arr = new int[3];
A(){
arr[0]=0;
arr[1]=10;
arr[2]=20;
}
public void z(int first, int second){
try {
System.out.println(arr[first] / arr[second]);
} catch(ArrayIndexOutOfBoundsException e){
System.out.println("ArrayIndexOutOfBoundsException");
} catch(ArithmeticException e){
System.out.println("ArithmeticException");
} catch(Exception e){
System.out.println("Exception");
} finally {
System.out.println("finally");
}
}
}
public class ExceptionDemo1 {
public static void main(String[] args) {
A a = new A();
a.z(10, 0);
a.z(1, 0);
a.z(2, 1);
}
}예를 들어 데이터베이스를 사용한다면 데이터베이스 서버에 접속해야 한다. 이때 데이터베이스 서버와 여러분이 작성한 에플리케이션은 서로 접속상태를 유지하게 되는데 데이터베이스를 제어하는 과정에서 예외가 발생해서 더 이상 후속 작업을 수행하는 것이 불가능한 경우가 있을 수 있다. 예외가 발생했다고 데이터베이스 접속을 끊지 않으면 데이터베이스와 연결 상태를 유지하게 되고 급기야 데이터베이스는 더 이상 접속을 수용할 수 없는 상태에 빠질 수 있다. 접속을 끊는 작업은 예외 발생여부와 상관없기 때문에 finally에서 처리하기에 좋은 작업이라고 할 수 있다. 말하자면 finally는 작업의 뒷정리를 담당한다고 볼 수 있다.
예외 던지기
- API를 사용할 때 설계자의 의도에 따라서 예외를 반드시 처리해야 하는 경우가 있다.
package org.opentutorials.javatutorials.exception;
import java.io.*;
public class CheckedExceptionDemo {
public static void main(String[] args) {
BufferedReader bReader = new BufferedReader(new FileReader("out.txt"));
String input = bReader.readLine();
System.out.println(input);
}
}-
Throws는 한국어로는 '던지다'로 번역된다. 위의 내용은 생성자 FileReader의 인자 fileName의 값에 해당하는 파일이 디렉토리이거나 어떤 이유로 사용할 수 없다면 FileNotFoundException을 발생시킨다는 의미다.
-
이것은 FileReader의 생성자가 동작할 때 파일을 열 수 없는 경우가 생길 수 있고, 이런 경우 생성자 FileReader에서는 이 문제를 처리할 수 없기 때문에 이에 대한 처리를 생성자의 사용자에게 위임하겠다는 의미다. 그것을던진다(throw) 고 표현하고 있다. 따라서 API의 사용자 쪽에서는 예외에 대한 처리를 반드시 해야 한다는 의미다. 따라서 아래와 같이 해야 FileReader 클래스를 사용할 수 있다.
package org.opentutorials.javatutorials.exception;
import java.io.*;
public class CheckedExceptionDemo {
public static void main(String[] args) {
try {
BufferedReader bReader = new BufferedReader(new FileReader("out.txt"));
} catch (FileNotFoundException e) {
e.printStackTrace();
}
String input = bReader.readLine();
System.out.println(input);
}
}
-
BufferedReader 클래스의 readLine 메소드는 IOException을 발생시킬 수 있다. 아래와 같이 코드를 수정하자.
-
그런데 위의 코드는 컴파일되지 않는다. 여기에는 함정이 있는데 변수 bReader를 보자. 이 변수는 try의 중괄호 안에서 선언되어 있다. 그리고 이 변수는 11행에서 사용되는데 bReader가 선언된 6행과 사용될 11행은 서로 다른 중괄호이다. 따라서 11행에서는 6행에서 선언된 bReader에 접근할 수 없다. 이해가 안 되면 유효범위 수업을 참고하자. 코드를 수정하자.
package org.opentutorials.javatutorials.exception;
import java.io.*;
public class CheckedExceptionDemo {
public static void main(String[] args) {
BufferedReader bReader = null;
String input = null;
try {
bReader = new BufferedReader(new FileReader("out.txt"));
} catch (FileNotFoundException e) {
e.printStackTrace();
}
try{
input = bReader.readLine();
} catch (IOException e){
e.printStackTrace();
}
System.out.println(input);
}
}
throw, throws
package org.opentutorials.javatutorials.exception;
import java.io.*;
class B{
void run(){
BufferedReader bReader = null;
String input = null;
try {
bReader = new BufferedReader(new FileReader("out.txt"));
} catch (FileNotFoundException e) {
e.printStackTrace();
}
try{
input = bReader.readLine();
} catch (IOException e){
e.printStackTrace();
}
System.out.println(input);
}
}
class C{
//C는 B의 사용자
void run(){
B b = new B();
b.run();
}
}
public class ThrowExceptionDemo {
public static void main(String[] args) {
//C에 대한 사용자는 ThrowExceptionDemo
C c = new C();
c.run();
}
}
-
위의 코드는 B.run이 FileReader의 생성자와 BufferedReader.readLine가 던진 예외를 try...catch로 처리한다. 즉 B.run이 예외에 대한 책임을 지고 있다.
-
그런데 B.run이 예외 처리를 직접 하지 않고 다음 사용자 C.run에게 넘길 수 있다. (사용자에게 책임을 넘길 수 있다.)
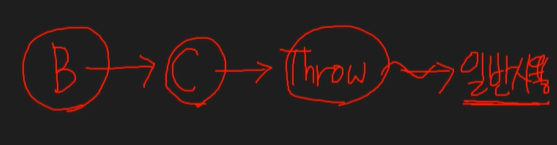
package org.opentutorials.javatutorials.exception;
import java.io.*;
class B{
void run() throws IOException, FileNotFoundException{
BufferedReader bReader = null;
String input = null;
bReader = new BufferedReader(new FileReader("out.txt"));
input = bReader.readLine();
System.out.println(input);
}
}
class C{
void run(){
B b = new B();
b.run();
}
}
public class ThrowExceptionDemo {
public static void main(String[] args) {
C c = new C();
c.run();
}
}
- B 내부의 try...catch 구문은 제거되었고 run 옆에 throws IOException, FileNotFoundException이 추가되었다. 이것은 B.run 내부에서 IOException, FileNotFoundException에 해당하는 예외가 발생하면 이에 대한 처리를 B.run의 사용자에게 위임하는 것이다.
- 위의 코드에서 B.run의 사용자는 C.run이다. 따라서 C.run은 아래와 같이 수정돼야 한다.
package org.opentutorials.javatutorials.exception;
import java.io.*;
class B{
//throws 여기!
void run() throws IOException, FileNotFoundException{
BufferedReader bReader = null;
String input = null;
bReader = new BufferedReader(new FileReader("out.txt"));
input = bReader.readLine();
System.out.println(input);
}
}
class C{
void run(){
B b = new B();
try {
b.run();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
public class ThrowExceptionDemo {
public static void main(String[] args) {
C c = new C();
c.run();
}
}
**예외는 중첩해서 사용할 수도 있다.
- 이 책임을 다시 main에게 넘겨보자.
package org.opentutorials.javatutorials.exception;
import java.io.*;
class B{
void run() throws IOException, FileNotFoundException{
BufferedReader bReader = null;
String input = null;
bReader = new BufferedReader(new FileReader("out.txt"));
input = bReader.readLine();
System.out.println(input);
}
}
class C{
void run() throws IOException, FileNotFoundException{
B b = new B();
b.run();
}
}
public class ThrowExceptionDemo {
public static void main(String[] args) {
C c = new C();
try {
c.run();
} catch (FileNotFoundException e) {
System.out.println("out.txt 파일은 설정 파일 입니다. 이 파일이 프로잭트 루트 디렉토리에 존재해야 합니다.");
} catch (IOException e) {
e.printStackTrace();
}
}
}
-
out.txt 파일을 찾을 수 없는 상황은 B.run 입장에서는 어떻게 할 수 있는 일이 아니다.
-
엔드유저인 애플리케이션의 사용자가 out.txt 파일을 루트 디렉토리에 위치시켜야 하는 문제이기 때문에 애플리케이션의 진입점인 메소드 main으로 책임을 넘기고 있다.
-
예외 처리는 귀찮은 일이다. 그래서 예외를 다음 사용자에게 전가(throw)하거나 try...catch로 감싸고 아무것도 하지 않고 싶은 유혹에 빠지기 쉽다. 하지만 예외는 API를 사용하면서 발생할 수 있는 잠재적 위협에 대한 API 개발자의 강력한 암시다. 이 암시를 무시해서는 안 된다. 물론 더욱 고민스러운 것은 예외 처리 방법에 정답이 없다는 것이겠지만 말이다.
예외 만들기
위의 코드에서 예외가 발생한 이유는 10을 0으로 나누려고 하기 때문이다. 즉 setOprands를 통해서 입력된 두번째 인자의 값이 0이기 때문에 발생한 문제다. 우리가 할 수 있는 조치는 두가지다.
- setOprands의 두번째 인자로 0이 들어오면 예외를 발생시킨다.
- 메소드 divide를 실행할 때 right의 값이 0이라면 예외를 발생시킨다.
package org.opentutorials.javatutorials.exception;
class Calculator{
int left, right;
public void setOprands(int left, int right){
if(right == 0){
throw new IllegalArgumentException("두번째 인자의 값은 0이 될 수 없습니다.");
}
this.left = left;
this.right = right;
}
public void divide(){
try {
System.out.print("계산결과는 ");
System.out.print(this.left/this.right);
System.out.print(" 입니다.");
} catch(Exception e){
System.out.println("\n\ne.getMessage()\n"+e.getMessage());
System.out.println("\n\ne.toString()\n"+e.toString());
System.out.println("\n\ne.printStackTrace()");
e.printStackTrace();
}
}
}
public class CalculatorDemo {
public static void main(String[] args) {
Calculator c1 = new Calculator();
c1.setOprands(10, 0);
c1.divide();
}
}
-
두번째 인자의 값이 0이 되었을 때 setOprands의 사용자에게 예외 클래스인 IllegalArgumentException을 던지고 있다. 사용자인 main은 예외와 함께 '두번째 인자의 값은 0이 될 수 없습니다.'라는 메시지를 받게 되고 이 정보를 바탕으로 전달 값을 변경하게 된다.
-
아래와 같이 divide 내에서 예외를 처리할 수도 있다.
package org.opentutorials.javatutorials.exception;
class Calculator{
int left, right;
public void setOprands(int left, int right){
this.left = left;
this.right = right;
}
public void divide(){
if(this.right == 0){
throw new ArithmeticException("0으로 나누는 것은 허용되지 않습니다.");
}
try {
System.out.print("계산결과는 ");
System.out.print(this.left/this.right);
System.out.print(" 입니다.");
} catch(Exception e){
System.out.println("\n\ne.getMessage()\n"+e.getMessage());
System.out.println("\n\ne.toString()\n"+e.toString());
System.out.println("\n\ne.printStackTrace()");
e.printStackTrace();
}
}
}
public class CalculatorDemo {
public static void main(String[] args) {
Calculator c1 = new Calculator();
c1.setOprands(10, 0);
c1.divide();
}
}
-
throw는 예외를 발생시키는 명령이다.
- throw 뒤에는 예외 정보를 가지고 있는 예외 클래스가 위치한다. 자바 가상 머신은 이 클래스를 기준으로 어떤 catch 구문을 실행할 것인지를 결정한다. 또 실행되는 catch 구문에서는 예외 클래스를 통해서 예외 상황의 원인에 대한 다양한 정보를 얻을 수 있다. 이 정보를 바탕으로 문제를 해결하게 된다.
-
필자가 사용한 예외인 IllegalArgumentException, ArithmeticException은 자바에서 기본적으로 제공하는 예외다. 이러한 예외들은 자바 가상머신이 사용하기도 하고 또 응용 프로그램 개발자가 사용할 수도 있다. 기본적으로 제공되는 어떤 예외들이 있는지를 파악하고 적당한 예외를 사용하는 것은 중요한 문제다.
-
클래스 Exception을 API 문서에서 찾아보고 그 하위 클래스로 어떤 것들이 있는지 살펴보는 것도 도움이 된다. 다음은 기억할만한 주요 Exception들의 리스트다. (effective Java p338 참고)
http://www.yes24.com/Product/Goods/65551284
➕ 예외의 여러가지 상황들
예외의 선조 - Throwable
(https://docs.oracle.com/javase/7/docs/api/java/lang/ArithmeticException.html)
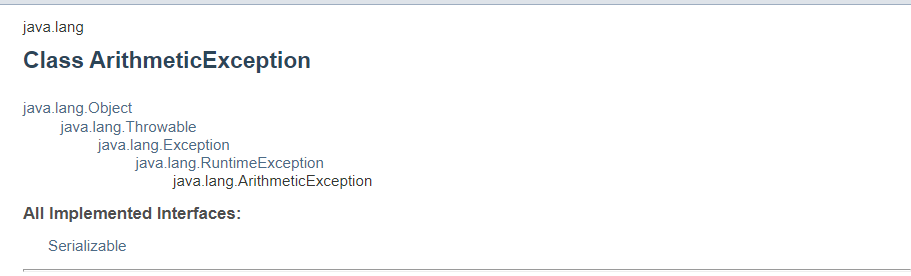
- 이것을 통해서 ArithmeticException의 부모 클래스 중에 java.lang.Exception 클래스가 있다는 사실을 알 수 있다. ArithmeticException 클래스는 Exception 클래스의 하위 클래스였던 것이다. 그렇기 때문에 Exception 클래스가 더 많은 예외 상황을 포괄하는 것이고 ArithmeticException 클래스는 더 구체적인 상황을 특정하는 것이다.
- 우리가 지금까지 사용했던 getMessage, printStackTrace, toString이 Throwable 클래스에서 정의 되어 있었던 것이다! 또 이 클래스의 이름이 Throwable이다. '던질 수 있는'이라는 뜻이다.
- 즉 예외로 '던질 수 있는' 클래스는 반드시 Throwable 클래스를 상속 받아야 한다.
예외의 종류
-
우선 중요한 예외 클래스들은 아래와 같다.
-
Throwable
- 클래스 Throwable은 범 예외 클래스들의 공통된 조상이다. 모든 예외 클래스들이 가지고 있는 공통된 메소드를 정의하고 있다. 중요한 역할을 하는 클래스임에는 틀림없지만 이 클래스를 직접 사용하지는 않기 때문에 우리에게는 중요하지 않다.
-
Error
- 에러는 여러분의 애플리케이션의 문제가 아니라 그 애플리케이션이 동작하는 가상머신에 문제가 생겼을 때 발생하는 예외다. 애플리케이션을 구동시키기에는 메모리가 부족한 경우가 이에 속한다. 이런 경우는 애플리케이션 개발자가 할 수 있는 것이 없다. 따라서 예외처리를 하지 말고 그냥 에러로 인해서 애플리케이션이 중단되도록 내버려둔다. 대신 자신의 애플리케이션이 메모리를 과도하게 사용하고 있다면 로직을 변경하거나 자바 가상머신에서 사용하는 메모리의 제한을 변경하는 등의 대응을 한다.
- 지구에 문제가 생겨도 우리가 아무것도 못하는 것처럼
-
Exception
- 결국 우리의 관심사는 Exception 클래스와 RuntimeException 클래스로 좁혀진다.
- Exception api
-
Runtime Exception
- RuntimeException을 제외한 Exception 클래스의 하위 클래스들과 RuntimeException 클래스의 차이를 자바에서는 checked와 unckecked라고 부른다. 관계를 정리하면 아래와 같다.
-checked 예외: RuntimeException을 제외한 Exception의 하위 클래스, 반드시 try...catch나 throws를 사용해서 예외처리를 해야한다.
-unchekced 예외: RuntimeException의 하위 클래스

-
강조 표시한 부분을 주의 깊게 살펴보자. ArithmeticException의 부모 중에 RuntimeException이 있다. 반면에 IOException은 Exception의 자식이지만 RuntimeException의 자식은 아니다. 이런 이유로 IOException은 checked이고 ArithmeticException은 unchekced이다. (Error도 unchecked이다)
<상속관계>
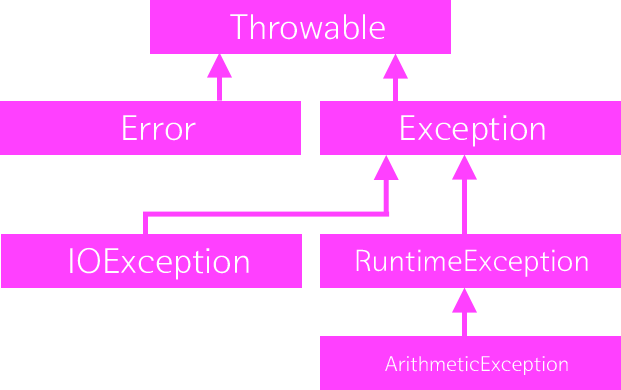
나만의 예외 만들기
-
표준 예외 클래스로도 많은 예외 상황을 표현할 수 있다. 하지만 그렇지 않은 경우도 있을 것이다. 이런 때는 직접 예외를 만들면 된다.
-
예외를 만들기 전에 해야 할 것은 자신의 예외를 checked로 할 것인가? unchecked로 할 것인가를 정해야 한다. 그 기준은 모호한 문제다. 하지만 기준이 없는 것도 아니다.
-
API 쪽에서 예외를 던졌을 때 API 사용자 쪽에서 예외 상황을 복구 할 수 있다면 checked 예외를 사용한다.
checked 예외는 사용자에게 문제를 해결할 기회를 주는 것이면서 예외처리를 강제하는 것이다.
(checked 예외를 너무 자주 사용하면 API 사용자를 몹시 힘들게 할 수 있기 때문에 적정선을 찾는 것이 중요하다.) -
사용자가 API의 사용방법을 어겨서 발생하는 문제거나 예외 상황이 이미 발생한 시점에서 그냥 프로그램을 종료하는 것이 덜 위험 할 때 unchecked를 사용한다.
-
기존의 ArithmeticException을 직접 만든 Exception으로 교체해보자.
package org.opentutorials.javatutorials.exception;
//RuntimeException 상속 받아서 생성
class DivideException extends RuntimeException {
DivideException(){
super();
}
DivideException(String message){
super(message);
}
}
class Calculator{
int left, right;
public void setOprands(int left, int right){
this.left = left;
this.right = right;
}
public void divide(){
if(this.right == 0){
throw new DivideException("0으로 나누는 것은 허용되지 않습니다.");
}
System.out.print(this.left/this.right);
}
}
public class CalculatorDemo {
public static void main(String[] args) {
Calculator c1 = new Calculator();
c1.setOprands(10, 0);
c1.divide();
}
}
- 만약 DivideException을 Exception으로 바꾸면 어떻게 될까? 아래 코드의 RuntimeException을 Exception으로 변경하면 된다.
package org.opentutorials.javatutorials.exception;
class DivideException extends Exception {
DivideException(){
super();
}
DivideException(String message){
super(message);
}
}
class Calculator{
int left, right;
public void setOprands(int left, int right){
this.left = left;
this.right = right;
}
public void divide(){
if(this.right == 0){
try {
throw new DivideException("0으로 나누는 것은 허용되지 않습니다.");
} catch (DivideException e) {
e.printStackTrace();
}
}
System.out.print(this.left/this.right);
}
}
public class CalculatorDemo {
public static void main(String[] args) {
Calculator c1 = new Calculator();
c1.setOprands(10, 0);
c1.divide();
}
}
- 혹은 사용자에게 예외를 던진다. 사용자는 반드시 예외에 대한 처리를 해야 한다.
package org.opentutorials.javatutorials.exception;
class DivideException extends Exception {
DivideException(){
super();
}
DivideException(String message){
super(message);
}
}
class Calculator{
int left, right;
public void setOprands(int left, int right){
this.left = left;
this.right = right;
}
public void divide() throws DivideException{
if(this.right == 0){
throw new DivideException("0으로 나누는 것은 허용되지 않습니다.");
}
System.out.print(this.left/this.right);
}
}
public class CalculatorDemo {
public static void main(String[] args) {
Calculator c1 = new Calculator();
c1.setOprands(10, 0);
try {
c1.divide();
} catch (DivideException e) {
e.printStackTrace();
}
}
}
17. Object 클래스
package org.opentutorials.javatutorials.progenitor;
class O {}
위의 코드는 아래와 코드가 같다.
package org.opentutorials.javatutorials.progenitor;
class O extends Object {}
-
자바에서 상속이란 필수적이다. 여러분이 상속하건 하지 않았건 기본적인 상속을 하게 된다.
-
자바에서 모든 클래스는 사실 Object를 암시적으로 상속받고 있는 것이다. 그런 점에서 Object는 모든 클래스의 조상이라고 할 수 있다. 그 이유는 모든 클래스가 공통으로 포함하고 있어야 하는 기능을 제공하기 위해서다.
(http://docs.oracle.com/javase/7/docs/api/java/lang/Object.html)
toString
- toString은 객체를 문자로 표현하는 메소드이다.
package org.opentutorials.javatutorials.progenitor;
class Calculator{
int left, right;
public void setOprands(int left, int right){
this.left = left;
this.right = right;
}
public void sum(){
System.out.println(this.left+this.right);
}
public void avg(){
System.out.println((this.left+this.right)/2);
}
}
public class CalculatorDemo {
public static void main(String[] args) {
Calculator c1 = new Calculator();
c1.setOprands(10, 20);
System.out.println(c1);
}
}
- 25라인에 아래 코드는 클래스 Calculator의 인스턴스 c1을 화면에 출력하고 있다.
System.out.println(c1);
org.opentutorials.javatutorials.progenitor.Calculator@11be650f
- 이것은 인스턴스 c1이 클래스 Calculator의 인스턴스라는 의미다. @ 뒤의 내용은 인스턴스에 대한 고유한 식별 값이라고 생각하자.
package org.opentutorials.javatutorials.progenitor;
class Calculator{
int left, right;
public void setOprands(int left, int right){
this.left = left;
this.right = right;
}
public void sum(){
System.out.println(this.left+this.right);
}
public void avg(){
System.out.println((this.left+this.right)/2);
}
public String toString(){
return "left : " + this.left + ", right : "+ this.right;
}
}
public class CalculatorDemo {
public static void main(String[] args) {
Calculator c1 = new Calculator();
c1.setOprands(10, 20);
System.out.println(c1);
System.out.println(c1.toString());
}
}
-
클래스 설계자의 필요에 따라서 toString의 결과를 더욱 유용하게 만들 수 있다. 예를들어 계산기 인스턴스의 left, right 값을 알 수 있다면 개발을 좀 더 편하게 할 수 있을 것이다.
-
클래스 Calculator에 toString을 재정의(overiding)했다.
그리고 인스턴스를 System.out.println의 인자로 전달하니까 toString을 명시적으로 호출하지 않았음에도 동일한 효과가 나고 있다.
toString 메소드는 자바에서 특별히 취급하는 메소드다. toString을 직접 호출하지 않아도 어떤 객체를 System.out.print로 호출하면 자동으로 toString이 호출되도록 약속되어 있다.
이를 통해서 인스턴스 c1의 상태를 쉽게 파악할 수 있게 되었다.
equals
- equals는 객체와 객체가 같은 것인지를 비교하는 API이다. 객체 간에 같고 다름은 필요에 따라서 달라질 수 있기 때문이다.
package org.opentutorials.javatutorials.progenitor;
class Student{
String name;
Student(String name){
this.name = name;
}
public boolean equals(Object obj) {
Student _obj = (Student)obj;
return name == _obj.name;
}
}
class ObjectDemo {
public static void main(String[] args) {
Student s1 = new Student("egoing");
Student s2 = new Student("egoing");
System.out.println(s1 == s2);
//자식 데이터타입을 가진 값을 부모 데이터타입을 가진 변수에 할당하려고 함
System.out.println(s1.equals(s2));
}
}
System.out.println(s1 == s2);
결과는 false다.
그 이유는 s1과 s2가 서로 다른 객체이기 때문이다. 어찌 보면 당연한 결과다. 하지만 두 개의 객체가 논리적으로는 egoing이라는 값을 가지고 있기 때문에 객체를 만든 필자는 저 두 개의 객체가 같은 객체로 간주 되었으면 좋겠다. 이럴 때 클래스 Object의 메소드 equals를 overiding하면 된다.
public boolean equals(Object obj) {
//명시적 형변환
Student _obj = (Student)obj;
return name == _obj.name;
}위의 코드 (Student)obj 는 메소드 equals로 전달된 obj의 데이터 타입이 Object이기 때문에 이를 Student 타입으로 형 변환하는 코드다. 아래 코드를 통해서 현재 객체의 변수 name과 equals의 인자로 전달된 객체의 변수 name을 비교한 결과를 Boolean 값으로 리턴하고 있다. 이 값에 따라서 두 개의 객체는 같거나 다른 것이 된다.
return name == _obj.name;
그런데 eqauls를 제대로 사용하기 위해서는 hashCode라는 클래스도 함께 구현해야 한다. 하지만 이에 대한 이야기는 우리 수업의 범위를 넘어서고 그 효용(사용 빈도)도 높지 않기 때문에 더 이상 설명을 하지 않겠다. 하지만 이 메소드의 취지를 이해하는 것은 또한 중요하기 때문에 언급을 하지 않을 수는 없었다.
<메소드 equals에 대해서 필자가 권고하는 입장은 아래와 같다.>
-
객체 간에 동일성을 비교하고 싶을 때는 ==를 사용하지 말고 equals를 이용하자.
-
equals를 직접 구현해야 한다면 hashCode도 함께 구현해야 함을 알고 이에 대한 분명한 학습을 한 후에 구현하자.
-
equals를 직접 구현해야 한다면 eclipse와 같은 개발도구들은 equals와 hashCode를 자동으로 생성해주는 기능을 가지고 있다. 이 기능을 이용하는 것을 고려해보자.
-
그 이유가 분명하지 않다면 비교 연산자 == 은 원시 데이터형을 비교할 때만 사용하자.
원시 데이터 형(Primitive Data Type)이란 자바에서 기본적으로 제공하는 데이터 타입으로 byte, short, int, long, float, double, boolean, char가 있다. 이러한 데이터 타입들은 new 연산자를 이용해서 생성하지 않아도 사용될 수 있다는 특징이 있다.
finalize
- finalize는 객체가 소멸될 때 호출되기로 약속된 메소드이다. 여기서는 이 메소드의 취지만 이해하면 된다. 많은 자바의 전문가들이 이 메소드의 사용을 만류하고 있다.
➕ 가비지 컬렉션(garbage collection)
인스턴스를 만드는 것은 내부적으로는 컴퓨터의 메모리를 사용하는 것이다. 여기서 말하는 메모리는 RAM을 의미한다. 램은 가장 빠른 저장 장치이기 때문에 컴퓨터 프로그램들은 이 램에 저장된 후에 동작하게 된다.
하지만 램은 가격이 비싸고 용량이 적기 때문에 램은 컴퓨터에서 가장 소중한 저장 장치라고 할 수 있다.
그러므로 램의 적게 사용하는 프로그램이 좋은 프로그램이다. 그런 이유로 많은 프로그래밍 언어들이 램을 효율적으로 사용하기 위해서 더 이상 사용하지 않는 데이터를 램에서 제거할 수 있는 방법들을 제공한다.
하지만 자바에서는 이러한 방법이 제한적으로 제공되고 있는데 그것은 자동으로 해주기 때문이다. 이 작업을 자동화한 것을 가비지 컬렉션이라고 한다. 이를테면 어떤 인스턴스를 만들었고, 그것을 변수에 담았다. 그런데 그 변수를 사용하는 곳이 더 이상 없다면 이 변수와 변수에 담겨있는 인스턴스는 더 이상 메모리에 머물고 있을 필요가 없는 것이다. 자바는 이를 감지하고 자동으로 쓰지 않은 데이터를 삭제한다. 따라서 개발자가 사용하지 않는 데이터를 직접 삭제하는 작업을 하지 않아도 되는 것이다. 이것은 어려운 메모리 관리로부터 개발자들의 부담을 경감시킨 도약이라고 할 수 있다.
clone
- clone은 복제라는 뜻이다. 어떤 객체가 있을 때 그 객체와 똑같은 객체를 복제해주는 기능이 clone 메소드의 역할이다.
package org.opentutorials.javatutorials.progenitor;
//Clonealbe은 비어있는 클래스인데 이를 재정의 해서 사용해야한다.
class Student implements Cloneable{
String name;
Student(String name){
this.name = name;
}
//Exception은 필수 정의해야한다.
protected Object clone() throws CloneNotSupportedException{
return super.clone();
}
}
class ObjectDemo {
public static void main(String[] args) {
Student s1 = new Student("egoing");
try {
Student s2 = (Student)s1.clone();
System.out.println(s1.name);
System.out.println(s2.name);
} catch (CloneNotSupportedException e) {
e.printStackTrace();
}
}
}
Object 클래스를 놓고 생각해보자. 이 클래스가 모든 클래스의 부모라는 사실은 이해의 영역이 아니라 약속의 영역이다(그냥 알아야하는 것). 즉 자바를 만든 측과 자바를 사용하는 측의 약속이다. 그리고 이 클래스가 clone이나 toString과 같은 메소드를 가지고 있다는 것 또한 이해의 영역이 아니라 숙지해야 하는 영역이다. 한편 모든 클래스가 toString을 사용할 수 있고 또한 이 메소드를 새롭게 재정의 할 수 있다는 점은 이해의 영역이다. 어떤 지식을 배울 때는 이해해야 하는 것과 그냥 알아야 하는 것을 잘 분별하는 것이 중요하다.
18.상수 - enum
- Java 5.0부터 제공되기 시작했다.
- 변수도 상수가 될 수 있다. 변수를 지정하고 그 변수를 final로 처리하면 한번 설정된 변수의 값은 더 이상 바뀌지 않는다. 또한 바뀌지 않는 값이라면 인스턴스 변수가 아니라 클래스 변수(static)로 지정하는 것이 더 좋을 것이다.
package org.opentutorials.javatutorials.constant2;
public class ConstantDemo {
private final static int APPLE = 1;
private final static int PEACH = 2;
private final static int BANANA = 3;
public static void main(String[] args) {
int type = APPLE;
switch(type){
case APPLE:
System.out.println(57+" kcal");
break;
case PEACH:
System.out.println(34+" kcal");
break;
case BANANA:
System.out.println(93+" kcal");
break;
}
}
}
- 이미 다양한 영역에서 사용되고 있는 상태에서 APPLE을 추가하려면 낭패가 될 것이다. 이러한 문제를 회피하기 위해서 접두사를 붙여보자.
package org.opentutorials.javatutorials.constant2;
public class ConstantDemo {
// fruit
private final static int FRUIT_APPLE = 1;
private final static int FRUIT_PEACH = 2;
private final static int FRUIT_BANANA = 3;
// company
private final static int COMPANY_GOOGLE = 1;
private final static int COMPANY_APPLE = 2;
private final static int COMPANY_ORACLE = 3;
public static void main(String[] args) {
int type = FRUIT_APPLE;
switch(type){
case FRUIT_APPLE:
System.out.println(57+" kcal");
break;
case FRUIT_PEACH:
System.out.println(34+" kcal");
break;
case FRUIT_BANANA:
System.out.println(93+" kcal");
break;
}
}
}
이름이 중복될 확률을 낮출 수 있다. 이러한 기법을 네임스페이스라고 한다. 그런데 상수가 너무 지저분하다. 좀 깔끔하게 바꿀 수 없을까? 이럴 때 인터페이스를 사용할 수 있다.
package org.opentutorials.javatutorials.constant2;
interface FRUIT{
int APPLE=1, PEACH=2, BANANA=3;
}
interface COMPANY{
int GOOGLE=1, APPLE=2, ORACLE=3;
}
public class ConstantDemo {
public static void main(String[] args) {
int type = FRUIT.APPLE;
switch(type){
case FRUIT.APPLE:
System.out.println(57+" kcal");
break;
case FRUIT.PEACH:
System.out.println(34+" kcal");
break;
case FRUIT.BANANA:
System.out.println(93+" kcal");
break;
}
}
}
- 훨씬 깔끔하다. 접미사(FRUIT, COMPANY)로 이름을 구분했던 부분이 인터페이스로 구분되기 때문에 언어의 특성을 보다 잘 살린 구조가 되었다. 인터페이스를 이렇게 사용할 수 있는 것은 인터페이스에서 선언된 변수는 무조건 public static final의 속성을 갖기 때문이다.
그런데 type의 값으로 누군가 COMPANY_GOOGLE을 사용했다면 어떻게 될까? 13행을 아래와 같이 변경해보자.
int type = COMPANY.GOOGLE;
결과는 57 Kcal이다! 구글이 57 Kcal인 것이다!
- 우리 코드는 과일과 기업이라는 두 개의 상수 그룹이 존재한다. 위의 코드는 서로 다른 상수그룹의 비교를 시도했고 양쪽 모두 값이 정수 1이기 때문에 오류를 사전에 찾아주지 못하고 있다. 컴파일러가 이런 실수를 사전에 찾아줄 수 있게 하려면 어떻게 해야 할까?
package org.opentutorials.javatutorials.constant2;
class Fruit{
//자기 자신을 데이터 타입으로 정의
//각각 다른 인스턴스 정의
public static final Fruit APPLE = new Fruit();
public static final Fruit PEACH = new Fruit();
public static final Fruit BANANA = new Fruit();
}
class Company{
public static final Company GOOGLE = new Company();
public static final Company APPLE = new Company();
public static final Company ORACLE = new COMPANY(Company);
}
public class ConstantDemo {
public static void main(String[] args) {
if(Fruit.APPLE == Company.APPLE){
System.out.println("과일 애플과 회사 애플이 같다.");
}
}
}
Fruit와 Company 클래스를 만들고 클래스 변수로 해당 클래스의 인스턴스를 사용하고 있다. 각각의 변수가 final이기 때문에 불변이고, Static이므로 인스턴스로 만들지 않아도 된다. 결과는 17행에서 에러가 발생한다. 이것이 우리가 바라던 것이다. 서로 다른 카테고리의 상수에 대해서는 비교조차 금지하게 된 것이다. 언제나 오류는 컴파일 시에 나타나도록 하는 것이 바람직하다. 실행 중에 발생하는 오류는 찾아내기가 더욱 어렵다.
그런데 위의 코드는 두 가지 문제점이 있는데 하나는 switch 문에서 사용할 수 없고 또 하나는 선언이 너무 복잡하다는 것이다. 주인공이 등장할 시간이 되었다.
enum
-
enum은 열거형(enumerated type) 이라고 부른다.
-
열거형은 서로 연관된 상수들의 집합이라고 할 수 있다. 위의 예제에서는 Fruit와 Company가 말하자면 열거인 셈이다.
-
이러한 패턴을 자바 1.5부터 문법적으로 지원하기 시작했는데 그것이 열거형이다.
package org.opentutorials.javatutorials.constant2;
enum Fruit{
APPLE, PEACH, BANANA;
}
enum Company{
GOOGLE, APPLE, ORACLE;
}
public class ConstantDemo {
public static void main(String[] args) {
/* 에러 발생
// enum이 서로 다른 상수 그룹에 대한 비교를 컴파일 시점에서 차단할 수 있다는 것을 의미한다.
//상수 그룹 별로 클래스를 만든 것의 효과를 enum도 갖는다는 것을 알 수 있다.
if(Fruit.APPLE == Company.APPLE){
System.out.println("과일 애플과 회사 애플이 같다.");
}
*/
Fruit type = Fruit.APPLE;
//Fruit가 데이터 타입인 것을 알기 때문에 type에 에러가 발생하지 않는다.
switch(type){
case APPLE:
System.out.println(57+" kcal");
break;
case PEACH:
System.out.println(34+" kcal");
break;
case BANANA:
System.out.println(93+" kcal");
break;
}
}
}
- enum은 class, interface와 동급의 형식을 가지는 단위다.
하지만 enum은 사실상 class이다. 편의를 위해서 enum만을 위한 문법적 형식을 가지고 있기 때문에 구분하기 위해서 enum이라는 키워드를 사용하는 것이다. 위의 코드는 아래 코드와 사실상 같다.
class Fruit{**텍스트**
public static final Fruit APPLE = new Fruit();
public static final Fruit PEACH = new Fruit();
public static final Fruit BANANA = new Fruit();
private Fruit(){}
}
- 생성자의 접근 제어자가 private이다. 그것이 클래스 Fruit를 인스턴스로 만들 수 없다는 것을 의미한다. 다른 용도로 사용하는 것을 금지하고 있는 것이다.
-
enum을 사용하는 이유를 정리하면 아래와 같다.
-
코드가 단순해진다.
-
인스턴스 생성과 상속을 방지한다.
-
키워드 enum을 사용하기 때문에 구현의 의도가 열거임을 분명하게 나타낼 수 있다.
-
enum과 생성자
enum은 사실 클래스다. 그렇기 때문에 생성자를 가질 수 있다. 아래와 같이 코드를 수정해보자.
package org.opentutorials.javatutorials.constant2;
enum Fruit{
APPLE, PEACH, BANANA;
Fruit(){
System.out.println("Call Constructor "+this);
}
}
enum Company{
GOOGLE, APPLE, ORACLE;
}
public class ConstantDemo {
public static void main(String[] args) {
/*
if(Fruit.APPLE == Company.APPLE){
System.out.println("과일 애플과 회사 애플이 같다.");
}
*/
Fruit type = Fruit.APPLE;
switch(type){
case APPLE:
System.out.println(57+" kcal");
break;
case PEACH:
System.out.println(34+" kcal");
break;
case BANANA:
System.out.println(93+" kcal");
break;
}
}
}
//결과
Call Constructor APPLE
Call Constructor PEACH
Call Constructor BANANA
57 kcal- Call Constructor가 출력된 것은 생성자 Fruit가 호출되었음을 의미한다. 이것이 3번 호출되었다는 것은 필드의 숫자만큼 호출되었다는 뜻이다. 즉 enum은 생성자를 가질 수 있다.
//에러발생
enum Fruit{
APPLE, PEACH, BANANA;
public Fruit(){
System.out.println("Call Constructor "+this);
}
}
- 이것은 enum의 생성자가 접근 제어자 private만을 허용하기 때문이다. 덕분에 Fruit를 직접 생성할 수 없다.
그렇다면 이 생성자의 매개변수를 통해서 필드(APPLE..)의 인스턴스 변수 값을 부여 할 수 있다는 말일까? 있다. 그런데 방식이 좀 생경하다.
package org.opentutorials.javatutorials.constant2;
enum Fruit{
//아래 줄은 Fruit의 상수를 선언하면서 동시에 생성자를 호출하고 있다.
APPLE("red"), PEACH("pink"), BANANA("yellow");
public String color;
Fruit(String color){
System.out.println("Call Constructor "+this);
//성자의 매개변수로 전달된 값은 this.color를 통해서 인스턴스 변수의 값으로 할당된다.
this.color = color;
}
}
enum Company{
GOOGLE, APPLE, ORACLE;
}
public class ConstantDemo {
public static void main(String[] args) {
/*
if(Fruit.APPLE == Company.APPLE){
System.out.println("과일 애플과 회사 애플이 같다.");
}
*/
Fruit type = Fruit.APPLE;
switch(type){
case APPLE:
//아래처럼 호출하면 APPLE에 할당된 Fruit 인스턴스의 color 필드를 반환하게 된다.
System.out.println(57+" kcal, "+Fruit.APPLE.color);
break;
case PEACH:
System.out.println(34+" kcal"+Fruit.PEACH.color);
break;
case BANANA:
System.out.println(93+" kcal"+Fruit.BANANA.color);
break;
}
}
}
//결과
Call Constructor APPLE
Call Constructor PEACH
Call Constructor BANANA
57 kcal, red
- 열거형은 메소드를 가질수도 있다. 아래 코드는 이전 예제와 동일한 결과를 출력한다.
package org.opentutorials.javatutorials.constant2;
enum Fruit{
APPLE("red"), PEACH("pink"), BANANA("yellow");
private String color;
Fruit(String color){
System.out.println("Call Constructor "+this);
this.color = color;
}
String getColor(){
return this.color;
}
}
enum Company{
GOOGLE, APPLE, ORACLE;
}
public class ConstantDemo {
public static void main(String[] args) {
Fruit type = Fruit.APPLE;
switch(type){
case APPLE:
System.out.println(57+" kcal, "+Fruit.APPLE.getColor());
break;
case PEACH:
System.out.println(34+" kcal"+Fruit.PEACH.getColor());
break;
case BANANA:
System.out.println(93+" kcal"+Fruit.BANANA.getColor());
break;
}
}
}
- enum은 멤버 전체를 열거 할 수 있는 기능도 제공한다.
package org.opentutorials.javatutorials.constant2;
enum Fruit{
APPLE("red"), PEACH("pink"), BANANA("yellow");
private String color;
Fruit(String color){
System.out.println("Call Constructor "+this);
this.color = color;
}
String getColor(){
return this.color;
}
}
enum Company{
GOOGLE, APPLE, ORACLE;
}
public class ConstantDemo {
public static void main(String[] args) {
//for in 구문
// values 메소드를 호출하면 Fruit이 가지고 있는 데이터들을 하나씩 꺼내어 f에 담는다
for(Fruit f : Fruit.values()){
System.out.println(f+", "+f.getColor());
}
}
}
-
열거형(enum)의 특성
- 열거형은 연관된 값들을 저장한다.
- 그 값들이 변경되지 않도록 보장한다.
- 열거형 자체가 클래스이기 때문에 열거형 내부에 생성자, 필드, 메소드를 가질 수 있어서 단순히 상수가 아니라 더 많은 역할을 할 수 있다.
19. 참조
복제
package org.opentutorials.javatutorials.reference;
public class ReferenceDemo1 {
public static void runValue(){
int a = 1;
int b = a;
b = 2;
System.out.println("runValue, "+a);
}
public static void main(String[] args) {
runValue();
}
}
//결과
runValue, 1
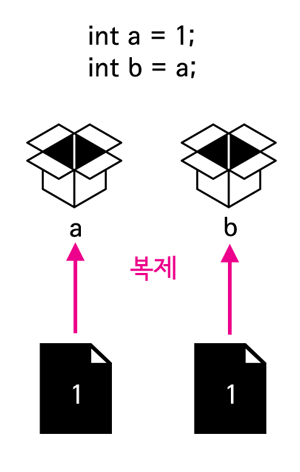
참조
package org.opentutorials.javatutorials.reference;
class A{
public int id;
A(int id){
this.id = id;
}
}
public class ReferenceDemo1 {
public static void runValue(){
int a = 1;
int b = a;
b = 2;
System.out.println("runValue, "+a);
}
public static void runReference(){
A a = new A(1);
A b = a;
//b에 담긴 인스턴스의 id값을 2로 변경했는데 a.id의 값도 2가 되었다.
/이는 b와 a에 담긴 인스턴스가 서로 같다는 것을 의미한다.
b.id = 2;
System.out.println("runReference, "+a.id);
}
public static void main(String[] args) {
runValue();
runReference();
}
}
//결과
runValue, 1
runReference, 2
참조 VS 복제
앞서 필자는 전자화된 세계에서 가장 중요한 특징으로 복제를 들었다. 그런데 복제만으로 전자화된 시스템을 설명하는 것은 조금 부족하다. 비유하자면 복제는 파일을 복사하는 것이고 참조는 심볼릭 링크(symbolic link) 혹은 바로가기(윈도우)를 만드는 것과 비슷하다. 원본 파일에 대해서 심볼릭 링크를 만들면 원본이 수정되면 심볼릭 링크에도 그 내용이 실시간으로 반영되는 것과 같은 효과다. 심볼릭 링크를 통해서 만든 파일은 원본 파일에 대한 주소 값이 담겨 있다. 누군가 심볼릭 링크에 접근하면 컴퓨터는 심볼릭 링크에 저장된 원본의 주소를 참조해서 원본의 위치를 알아내고 원본에 대한 작업을 하게 된다.
다시 말해서 원본을 복제한 것이 아니라 원본 파일을 참조(reference)하고 있는 것이다.
덕분에 저장 장치의 용량을 절약할 수 있고, 원본 파일을 사용하고 있는 모든 복제본이 동일한 내용을 유지할 수 있게 된다. 참조는 전자화된 세계의 극치라고 할 수 있다.
프로그래밍에서 광범위하게 사용하는 라이브러리라는 개념도 일종의 참조라고 할 수 있다. 공용 라이브러리를 사용하게 되면 하나의 라이브러리를 여러 애플리케이션에서 공유해서 사용하게 된다. 라이브러리의 내용이 변경되면 이를 참조하고 있는 애플리케이션에도 내용이 반영되게 된다. 또 우리가 변수를 사용하는 이유도 말하자면 참조를 위해서라고 할 수 있을 것이다. 본질을 파악하면 이해력도 높아지고 암기할 것도 줄어든다.
- 아래 두 개의 구문의 차이점을 생각해보자
int a = 1;
A a = new A(1);
전자는 데이터형이 int이고 후자는 A이다.
int는 기본 데이터형(원시 데이터형, Primitive Data Types) 이다. 자바에서는 기본 데이터형을 제외한 모든 데이터 타입은 참조 데이터형(참조 자료형) 이라고 부른다. 기본 데이터형은 위와 같이 복제 되지만 참조 데이터형은 참조된다.
new를 사용해서 객체를 만드는 모든 데이터 타입이 참조 데이터형이라고 생각해도 된다. (단 String은 제외다) 이를 그림으로 나타내면 아래와 같다.
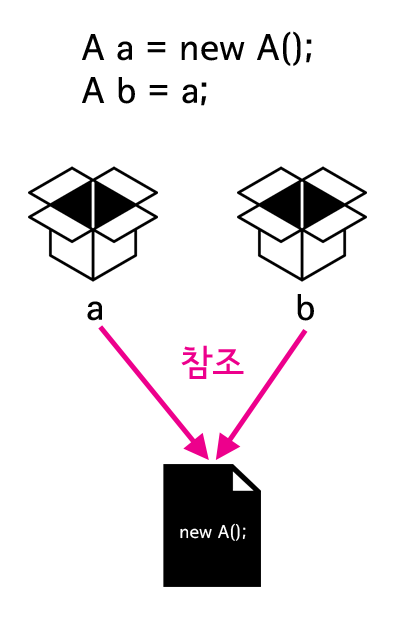
- 정리하면 변수에 담겨있는 데이터가 기본형이면 그 안에는 실제 데이터가 들어있고, 기본형이 아니면 변수 안에는 데이터에 대한 참조 방법이 들어있다고 할 수 있다.
참조 데이터 형과 매개 변수
package org.opentutorials.javatutorials.reference;
public class ReferenceParameterDemo {
static void _value(int b){
b = 2;
}
public static void runValue(){
int a = 1;
_value(a);
System.out.println("runValue, "+a);
}
static void _reference1(A b){
b = new A(2);
}
public static void runReference1(){
A a = new A(1);
_reference1(a);
System.out.println("runReference1, "+a.id);
}
static void _reference2(A b){
b.id = 2;
}
public static void runReference2(){
A a = new A(1);
_reference2(a);
System.out.println("runReference2, "+a.id);
}
public static void main(String[] args) {
runValue(); // runValue, 1
runReference1(); // runReference1, 1
runReference2(); // runReference2, 2
}
}
//결과
runValue, 1
runReference1, 1
runReference2, 2
- 아래 코드는 _value의 매개변수로 기본 데이터형(int)를 전달했다.
runValue();
메소드 _value의 인자로 a를 전달했다. 인자 a는 매개변수 b가 되어서 _value 안으로 전달되고 있다. _value 안에서 b의 값을 변경했다. _value가 실행된 후에 runValue에서 a값을 출력해본 결과 값이 변경되지 않았다. 호출된 메소드의 작업이 호출한 메소드에 영향을 미치지 않고 있다.
- 아래 코드는 _reference1의 매개변수로 참조 데이터 타입을 전달하고 있다.
runReference1();
메소드 _reference1 안에서 매개변수 b의 값을 다른 객체로 변경하고 있다. 이것은 지역변수인 b의 데이터를 교체한 것일 뿐이기 때문에 runReference1의 결과에는 영향을 미치지 않는다.
- 다음의 코드는 호출된 메소드의 작업이 호출한 메소드의 변수에 영향을 미친다.
runReference2();
매개변수 b의 값을 다른 객체로 교체한 것이 아니라 매개변수 b의 인스턴스 변수 id 값을 2로 변경하고 있다. 이러한 맥락에서 _reference2의 변수 b는 runReference2의 변수 a와 참조 관계로 연결되어 있는 것이기 때문에 a와 b는 모두 같은 객체를 참조하고 있는 변수다.
매개변수를 다른 객체로 변경하는 것과 참조 데이터 타입의 매개변수에 담겨 있는 객체에 접근하는 것은 완전히 다른 의미를 가지기 때문에 두가지 경우의 차이점을 확실하게 이해하도록 하자.
20. 제네릭
-
제네릭(Generic) 은 클래스 내부에서 사용할 데이터 타입을 외부에서 지정하는 기법을 의미한다.
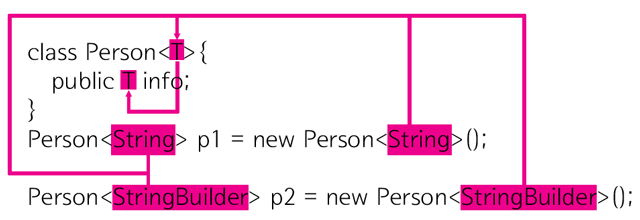
package org.opentutorials.javatutorials.generic;
class Person<T>{
public T info;
}
public class GenericDemo {
public static void main(String[] args) {
Person<String> p1 = new Person<String>();
Person<StringBuilder> p2 = new Person<StringBuilder>();
}
}-
데이터 타입
- p1.info : String
- p2.info : StringBuilder
그것은 각각의 인스턴스를 생성할 때 사용한 <> 사이에 어떤 데이터 타입을 사용했느냐에 달려있다.
- 클래스 선언부
public T info;
클래스 Person의 필드 info의 데이터 타입은 T로 되어 있다. 그런데 T라는 데이터 타입은 존재하지 않는다. 이 값은 아래 코드의 T에서 정해진다.
class Person<T>{
위 코드의 T는 아래 코드의 <> 안에 지정된 데이터 타입에 의해서 결정된다.
Person<String> p1 = new Person<String>();
위의 코드를 나눠보자. 아래 코드는 변수 p1의 데이터 타입을 정의하고 있다.
Person<String> p1
아래 코드는 인스턴스를 생성하고 있다.
new Person<String>();
즉 클래스를 정의 할 때는 info의 데이터 타입을 확정하지 않고 인스턴스를 생성할 때 데이터 타입을 지정하는 기능이 제네릭이다.
제네릭을 사용하는 이유
타입 안전성
//기존의 중복 제거한 코드
package org.opentutorials.javatutorials.generic;
class StudentInfo{
public int grade;
StudentInfo(int grade){ this.grade = grade; }
}
class EmployeeInfo{
public int rank;
EmployeeInfo(int rank){ this.rank = rank; }
}
class Person{
public Object info;
Person(Object info){ this.info = info; }
}
public class GenericDemo {
public static void main(String[] args) {
//객체가 아닌 String이 오고 있다.
Person p1 = new Person("부장");
EmployeeInfo ei = (EmployeeInfo)p1.info;
System.out.println(ei.rank);
}
}클래스 Person의 생성자는 매개변수 info의 데이터 타입이 Object이다. 따라서 모든 객체가 될 수 있다. 그렇기 때문에 위와 EmployeeInfo의 객체가 아니라 String이 와도 컴파일 에러가 발생하지 않는다. 대신 런타임 에러가 발생한다. 컴파일 언어의 기본은 모든 에러는 컴파일이 발생할 수 있도록 유도해야 한다는 것이다. 런타임은 실제로 애플리케이션이 동작하고 있는 상황이기 때문에 런타임에 발생하는 에러는 항상 심각한 문제를 초래할 수 있기 때문이다.
위와 같은 에러를 타입에 대해서 안전하지 않다고 한다. 즉 모든 타입이 올 수 있기 때문에 타입을 엄격하게 제한 할 수 없게 되는 것이다.
제네릭화
package org.opentutorials.javatutorials.generic;
class StudentInfo{
public int grade;
StudentInfo(int grade){ this.grade = grade; }
}
class EmployeeInfo{
public int rank;
EmployeeInfo(int rank){ this.rank = rank; }
}
class Person<T>{
public T info;
Person(T info){ this.info = info; }
}
public class GenericDemo {
public static void main(String[] args) {
Person<EmployeeInfo> p1 = new Person<EmployeeInfo>(new EmployeeInfo(1));
EmployeeInfo ei1 = p1.info;
System.out.println(ei1.rank); // 성공
Person<String> p2 = new Person<String>("부장");
String ei2 = p2.info;
System.out.println(ei2.rank); // 컴파일 실패
}
}
-
p1은 잘 동작할 것이다. 중요한 것은 p2다.
p2는 컴파일 오류가 발생하는데 p2.info가 String이고 String은 rank 필드가 없는데 이것을 호출하고 있기 때문이다.
여기서 중요한 것은 아래와 같이 정리할 수 있다.- 컴파일 단계에서 오류가 검출된다.
- 중복의 제거와 타입 안전성을 동시에 추구할 수 있게 되었다.
복수의 제네릭
package org.opentutorials.javatutorials.generic;
class EmployeeInfo{
public int rank;
EmployeeInfo(int rank){ this.rank = rank; }
}
class Person<T, S>{
public T info;
public S id;
Person(T info, S id){
this.info = info;
this.id = id;
}
}
public class GenericDemo {
public static void main(String[] args) {
Person<EmployeeInfo, int> p1 = new Person<EmployeeInfo, int>(new EmployeeInfo(1), 1);
}
}
위의 코드는 예외를 발생시키지만 문제는 다음 예제에서 처리하고 형식만 보자.
- 즉, 복수의 제네릭을 사용할 때는 <T, S> 와 같은 형식을 사용한다. 여기서 T와 S 대신 어떠한 문자를 사용해도 된다. 하지만 묵시적인 약속(convention)이 있기는 하다. 그럼 예제의 오류를 해결하자.
기본 데이터 타입과 제네릭
제네릭은 참조 데이터 타입에 대해서만 사용할 수 있다. 기본 데이터 타입에서는 사용할 수 없다. 따라서 아래와 같이 코드를 변경한다.
package org.opentutorials.javatutorials.generic;
class EmployeeInfo{
public int rank;
EmployeeInfo(int rank){ this.rank = rank; }
}
class Person<T, S>{
public T info;
public S id;
Person(T info, S id){
this.info = info;
this.id = id;
}
}
public class GenericDemo {
public static void main(String[] args) {
EmployeeInfo e = new EmployeeInfo(1);
Integer i = new Integer(10);
Person<EmployeeInfo, Integer> p1 = new Person<EmployeeInfo, Integer>(e, i);
System.out.println(p1.id.intValue());
}
}
new Integer는 기본 데이터 타입인 int를 참조 데이터 타입으로 변환해주는 역할을 한다.
이러한 클래스를 래퍼(wrapper) 클래스라고 한다. 덕분에 기본 데이터 타입을 사용할 수 없는 제네릭에서 int를 사용할 수 있다.
제네릭의 생략
EmployeeInfo e = new EmployeeInfo(1);
Integer i = new Integer(10);
Person<EmployeeInfo, Integer> p1 = new Person<EmployeeInfo, Integer>(e, i);
Person p2 = new Person(e, i);메소드에 적용
- 제네릭은 메소드에 적용할 수도 있다.
package org.opentutorials.javatutorials.generic;
class EmployeeInfo{
public int rank;
EmployeeInfo(int rank){ this.rank = rank; }
}
class Person<T, S>{
public T info;
public S id;
Person(T info, S id){
this.info = info;
this.id = id;
}
public <U> void printInfo(U info){
System.out.println(info);
}
}
public class GenericDemo {
public static void main(String[] args) {
EmployeeInfo e = new EmployeeInfo(1);
Integer i = new Integer(10);
Person<EmployeeInfo, Integer> p1 = new Person<EmployeeInfo, Integer>(e, i);
p1.<EmployeeInfo>printInfo(e);
p1.printInfo(e);
}
}
제네릭의 제한
1. extends
- 제네릭으로 올 수 있는 데이터 타입을 특정 클래스의 자식으로 제한할 수 있다.
package org.opentutorials.javatutorials.generic;
abstract class Info{
public abstract int getLevel();
}
class EmployeeInfo extends Info{
public int rank;
EmployeeInfo(int rank){ this.rank = rank; }
public int getLevel(){
return this.rank;
}
}
class Person<T extends Info>{
public T info;
Person(T info){ this.info = info; }
}
public class GenericDemo {
public static void main(String[] args) {
Person p1 = new Person(new EmployeeInfo(1));
Person<String> p2 = new Person<String>("부장");
}
}
class Person<T extends Info>{
- 즉 Person의 T는 Info 클래스나 그 자식 외에는 올 수 없다.
extends는 상속(extends)뿐만 아니라 구현(implements)의 관계에서도 사용할 수 있다.
package org.opentutorials.javatutorials.generic;
interface Info{
int getLevel();
}
class EmployeeInfo implements Info{
public int rank;
EmployeeInfo(int rank){ this.rank = rank; }
public int getLevel(){
return this.rank;
}
}
class Person<T extends Info>{
public T info;
Person(T info){ this.info = info; }
}
public class GenericDemo {
public static void main(String[] args) {
Person p1 = new Person(new EmployeeInfo(1));
Person<String> p2 = new Person<String>("부장");
}
}
21. Collections framework
ArrayList
package org.opentutorials.javatutorials.collection;
import java.util.ArrayList;
public class ArrayListDemo {
public static void main(String[] args) {
String[] arrayObj = new String[2];
arrayObj[0] = "one";
arrayObj[1] = "two";
// arrayObj[2] = "three"; 오류가 발생한다.
for(int i=0; i<arrayObj.length; i++){
System.out.println(arrayObj[i]);
}
ArrayList al = new ArrayList();
//추가
al.add("one");
al.add("two");
al.add("three");
//length는 size로 접근
for(int i=0; i<al.size(); i++){
//값을 가져올 때는 .get(인덱스번호)
System.out.println(al.get(i));
}
}
}
-
따라서 ArrayList 내에서 add를 통해서 입력된 값은 Object의 데이터 타입을 가지고 있고, get을 이용해서 이를 꺼내도 Object의 데이터 타입을 가지고 있게 된다. 그래서 위의 코드는 아래와 같이 바꿔야 한다.
-
get의 리턴값을 문자열로 형변환하고 있다. 원래의 데이터 타입이 된 것이다.
for(int i=0; i<al.size(); i++){
String val = (String)al.get(i);
System.out.println(val);
}
이제는 제네릭을 사용한다.
ArrayList<String> al = new ArrayList<String>();
al.add("one");
al.add("two");
al.add("three");
for(int i=0; i<al.size(); i++){
String val = al.get(i);
System.out.println(val);
}- 제네릭을 사용하면 ArrayList 내에서 사용할 데이터 타입을 인스턴스를 생성할 때 지정할 수 있기 때문에 데이터를 꺼낼 때(String val = al.get(i);) 형변환을 하지 않아도 된다.
컬렉션즈 프레임워크란?
-
컬렉션즈 프레임워크라는 것은 다른 말로는 컨테이너라고도 부른다.
-
즉 값을 담는 그릇이라는 의미이다.
-
그런데 그 값의 성격에 따라서 컨테이너의 성격이 조금씩 달라진다.
-
자바에서는 다양한 상황에서 사용할 수 있는 다양한 컨테이너를 제공하는데 이것을 컬렉션즈 프레임워크라고 부른다. ArrayList는 그중의 하나다.
<컬렉션즈 프레임워크의 구성>
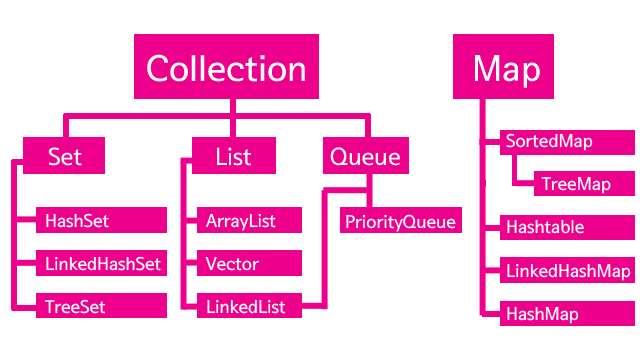
-
ArrayList를 찾아보자. Collection-List에 속해있다. ArrayList는 LIst라는 성격으로 분류되고 있는 것이다.
-
List는 인터페이스이다. 그리고 List 하위의 클래스들은 모두 List 인터페이스를 구현하기 때문에 모두 같은 API를 가지고 있다.
-
클래스의 취지에 따라서 구현방법과 동작방법은 다르지만 공통의 조작방법을 가지고 있는 것이다.
List와 Set
- List와 Set의 차이점은 List는 중복을 허용하고, Set은 허용하지 않는다.
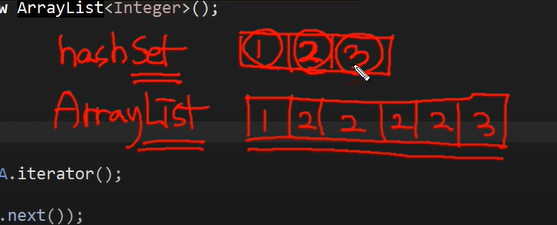
package org.opentutorials.javatutorials.collection;
import java.util.ArrayList;
import java.util.HashSet;
import java.util.Iterator;
public class ListSetDemo {
public static void main(String[] args) {
ArrayList<String> al = new ArrayList<String>();
al.add("one");
al.add("two");
al.add("two");
al.add("three");
al.add("three");
al.add("five");
System.out.println("array");
Iterator ai = al.iterator();
while(ai.hasNext()){
System.out.println(ai.next());
}
HashSet<String> hs = new HashSet<String>();
hs.add("one");
hs.add("two");
hs.add("two");
hs.add("three");
hs.add("three");
hs.add("five");
Iterator hi = hs.iterator();
System.out.println("\nhashset");
while(hi.hasNext()){
System.out.println(hi.next());
}
}
}
//결과
array
one
two
two
three
three
five
hashset
two
five
one
three- 우선 값을 가져오는 방법이 조금 달라졌다. (ArrayList에서도 이 방법을 사용할 수 있다)
- Set은 순서(인덱스)를 가지지 않기 때문
//여기 iterator
Iterator ai = al.iterator();
while(ai.hasNext()){
System.out.println(ai.next());
}iterator
메소드 iterator는 인터페이스 Collection에 정의되어 있다. 따라서 Collection을 구현하고 있는 모든 컬렉션즈 프레임워크는 이 메소드를 구현하고 있음을 보증한다. 메소드 iterator의 호출 결과는 인터페이스 iterator를 구현한 객체를 리턴한다.
-
인터페이스 iterator는 아래 3개의 메소드를 구현하도록 강제하고 있는데 각각의 역할은 아래와 같다.
-
hasNext
반복할 데이터가 더 있으면 true, 더 이상 반복할 데이터가 없다면 false를 리턴한다. -
next
hasNext가 true라는 것은 next가 리턴할 데이터가 존재한다는 의미다.
-
-
이러한 기능을 조합하면 for 문을 이용하는 것과 동일하게 데이터를 순차적으로 처리할 수 있다.
import java.util.ArrayList;
import java.util.HashSet;
import java.util.Iterator;
public class SetDemo{
public static void main(String[] args){
// HashSet<Integer> A = new HashSet<integer>();
//Collection도 사용가능
ArrayList<Integer> A = new ArrayList<Integer>();
A.add(1);
A.add(2);
A.Add(3);
Iterator hi = A.iterator();
while(hi.hasNext()){
System.out.println(hi.next());
}
}
}
Set
-
Set은 한국어로 집합이라는 뜻이다. 여기서의 집합이란 수학의 집합과 같은 의미다. 수학에서의 집합도 순서가 없고 중복되지 않는 특성이 있다는 것이 기억날 것이다.
-
수학에서 집합은 교집합(intersect), 차집합(difference), 합집합(union)과 같은 연산을 할 수 있었다. Set도 마찬가지다.
아래와 같이 3개의 집합 hs1, hs2, hs3이 있다고 하자. h1은 숫자 1,2,3으로 이루어진 집합이고, h2는 3,4,5 h3는 1,2로 구성되어 있다. set의 API를 이용해서 집합 연산을 해보자.
package org.opentutorials.javatutorials.collection;
import java.util.ArrayList;
import java.util.HashSet;
import java.util.Iterator;
public class SetDemo {
public static void main(String[] args) {
HashSet<Integer> A = new HashSet<Integer>();
A.add(1);
A.add(2);
A.add(3);
HashSet<Integer> B = new HashSet<Integer>();
B.add(3);
B.add(4);
B.add(5);
HashSet<Integer> C = new HashSet<Integer>();
C.add(1);
C.add(2);
System.out.println(A.containsAll(B)); // false
System.out.println(A.containsAll(C)); // true
//A.addAll(B);
//A.retainAll(B);
//A.removeAll(B);
Iterator hi = A.iterator();
while(hi.hasNext()){
System.out.println(hi.next());
}
}
}
부분집합(subset)
System.out.println(A.containsAll(B)); // false
System.out.println(A.containsAll(C)); // true
합집합(union)
A.addAll(B);
교집합(intersect)
A.retainAll(B);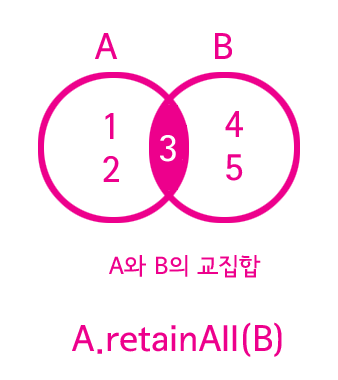
차집합(difference)
A.removeAll(B);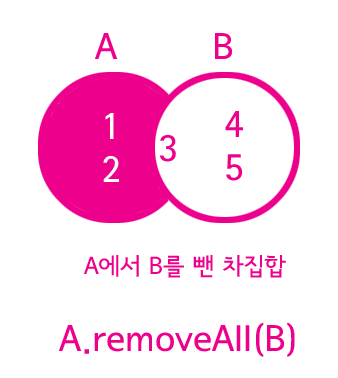
Map
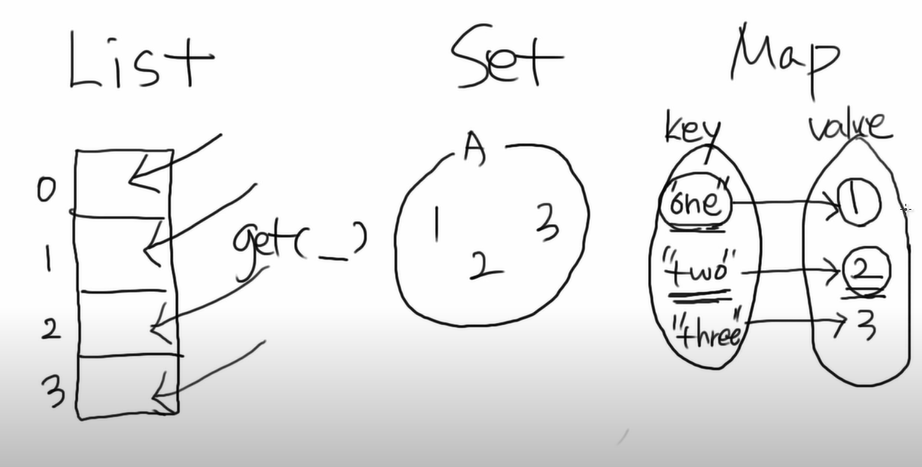
- Map 컬렉션은 key와 value의 쌍으로 값을 저장하는 컬렉션이다.
package org.opentutorials.javatutorials.collection;
import java.util.*;
public class MapDemo {
public static void main(String[] args) {
//제네릭이 2개이다 -> key/value
HashMap<String, Integer> a = new HashMap<String, Integer>();
a.put("one", 1);
a.put("two", 2);
a.put("three", 3);
a.put("four", 4);
System.out.println(a.get("one"));
System.out.println(a.get("two"));
System.out.println(a.get("three"));
iteratorUsingForEach(a);
iteratorUsingIterator(a);
}
//첫번째 방식
static void iteratorUsingForEach(HashMap map){
Set<Map.Entry<String, Integer>> entries = map.entrySet();
for (Map.Entry<String, Integer> entry : entries) {
System.out.println(entry.getKey() + " : " + entry.getValue());
}
}
// 두번째 방식
static void iteratorUsingIterator(HashMap map){
Set<Map.Entry<String, Integer>> entries = map.entrySet();
Iterator<Map.Entry<String, Integer>> i = entries.iterator();
while(i.hasNext()){
Map.Entry<String, Integer> entry = i.next();
System.out.println(entry.getKey()+" : "+entry.getValue());
}
}
}
- Map에서 데이터를 추가할 때 사용하는 API는 put이다.
- put의 첫번째 인자는 값의 key이고
- 두번째 인자는 key에대한 값이다. key를 이용해서 값을 가져올 수 있다.
- key 값은 중복되어서는 안 된다.
System.out.println(a.get("one"));
이것이 Map의 가장 기본적인 사용법이다. 그럼 Map에 저장된 데이터를 열거할 때는 어떻게 해야할까?
- Map은 iterator가 지원되지 않는다.
```java
Set<Map.Entry<String, Integer>> entries = map.entrySet();
for (Map.Entry<String, Integer> entry : entries) {
System.out.println(entry.getKey() + " : " + entry.getValue());
}메소드 entrySet 은 Map의 데이터를 담고 있는 Set을 반환한다. 반환한 Set의 값이 사용할 데이터 타입은 Map.Entry이다. Map.Entry는 인터페이스인데 아래와 같은 API를 가지고 있다.
-
getKey
-
getValue
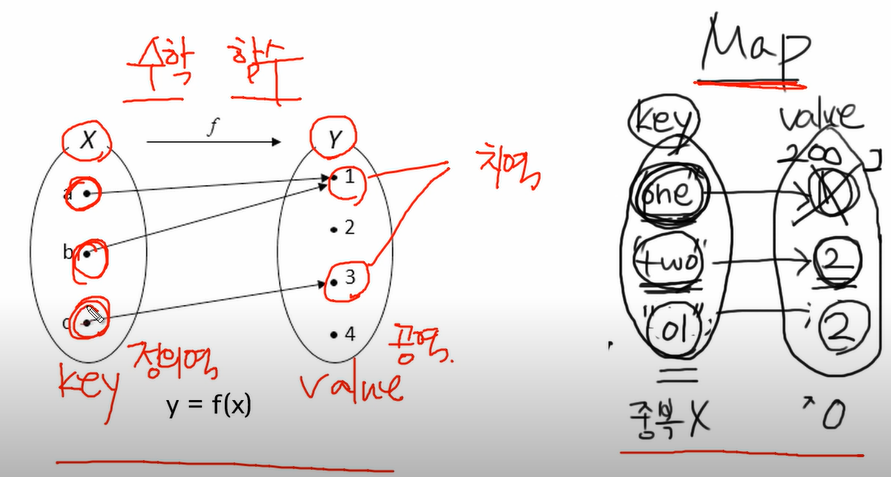
데이터 타입의 교체
컬렉션을 사용할 때는 데이터 타입은 가급적 해당 컬렉션을 대표하는 인터페이스를 사용하는 것이 좋다.
HashMap<String, Integer> a = new HashMap<String, Integer>();
이 코드를 다음과 같이 수정한다.
Map<String, Integer> a = new HashMap<String, Integer>();
정렬
컬렉션을 사용하는 이유 중의 하나는 정렬과 같은 데이터와 관련된 작업을 하기 위해서다.
정렬하는 법을 알아보자. 패키지 java.util 내에는 Collections라는 클래스가 있다. 이 클래스를 사용하는 법을 알아보자.
package org.opentutorials.javatutorials.collection;
import java.util.*;
class Computer implements Comparable{
int serial;
String owner;
Computer(int serial, String owner){
this.serial = serial;
this.owner = owner;
}
public int compareTo(Object o) {
return this.serial - ((Computer)o).serial;
}
public String toString(){
return serial+" "+owner;
}
}
public class CollectionsDemo {
public static void main(String[] args) {
List<Computer> computers = new ArrayList<Computer>();
computers.add(new Computer(500, "egoing"));
computers.add(new Computer(200, "leezche"));
computers.add(new Computer(3233, "graphittie"));
Iterator i = computers.iterator();
System.out.println("before");
while(i.hasNext()){
System.out.println(i.next());
}
Collections.sort(computers);
System.out.println("\nafter");
i = computers.iterator();
while(i.hasNext()){
System.out.println(i.next());
}
}
}
//결과
before
500 egoing
200 leezche
3233 graphittie
after
200 leezche
500 egoing
3233 graphittie
클래스 Collectors는 다양한 클래스 메소드를 가지고 있다. 메소드 sort는 그 중의 하나로 List의 정렬을 수행한다.
다음은 sort의 시그니처다.
public static <T extends Comparable<? super T>> void sort(List<T> list)sort의 인자인 list는 데이터 타입이 List이다. 즉 메소드 sort는 List 형식의 컬렉션을 지원한다는 것을 알 수 있다. 인자 list의 제네릭 는 coparable을 extends 하고 있어야 한다. Comparable은 인터페이스인데 이를 구현하고 있는 클래스는 아래 메소드를 가지고 있어야 한다.
아래의 메소드는 이러한 제약 조건을 준수하기 위해서 구현한 메소드다.
public int compareTo(Object o) {
return this.serial - ((Computer)o).serial;
}- 메소드 sort를 실행하면 내부적으로 compareTo를 실행하고 그 결과에 따라서 객체의 선후 관계를 판별하게 된다.
➕
(https://prashantgaurav1.files.wordpress.com/2013/12/java-util-collection.gif)
{kind=link}