max(str, key=len)
문자열의 길이가 가장 큰 것을 반환한다.
단, 최댓값의 길이가 두 개 이상 있을 경우 index가 가장 작은 것을 출력한다.
print(max('zzaa', 'zzab', key=len))
>>> zzaa
print(max('zabc', 'zzaa', 'zzab', key=len))
>>> zabc
print(max('1111', 'zzaa', 'zzab', key=len))
>>> 1111
print(max('aaaa', '1111', 'zzaa', 'zzab', key=len))
>>> aaaa
print(max('zzzz', 'aaaa', '1111', 'zzaa', 'zzab', key=len))
>>> zzzz
heapq
heapq란 자료구조 queue의 일종으로, queue의 내부 구조가 heap으로 이루어져 있다.
보통 우선순위 큐를 구현하기 위해 사용되며, heapq 모듈의 함수들은 Min Heap 기준으로 설계되어 있으므로 주의가 필요하다.
import heapq
#heapq 생성
hq = []
#heapq.heappush( (리스트), (값) ) : 리스트에 Min Heap 기준으로 값 추가
heapq.heappush(hq, 3)
heapq.heappush(hq, 2)
heapq.heappush(hq, 1)
print(hq) # print결과 : deque([1, 3, 2])
print(heapq.heappop(hq)) # print결과 : 1
print(heapq.heappop(hq)) # print결과 : 2
print(heapq.heappop(hq)) # print결과 : 3
#heapq.heapify( (리스트) ) : 기존 리스트를 Min Heap으로 변환
hq = [3, 5, 4, 1, 2]
heapq.heapify(hq)
print(heapq.heappop(hq)) # print결과 : 1
print(heapq.heappop(hq)) # print결과 : 2
print(heapq.heappop(hq)) # print결과 : 3
print(heapq.heappop(hq)) # print결과 : 4
print(heapq.heappop(hq)) # print결과 : 5
Max Heap 구현하는 방법
1) 첫 번째 방식은, 추가 및 출력 시 값에 -를 붙이는 것입니다.
heapq.heappush(hq, -1)
heapq.heappush(hq, -2)
heapq.heappush(hq, -3)
print(-heapq.heappop(hq)) # print결과 : 3
print(-heapq.heappop(hq)) # print결과 : 2
print(-heapq.heappop(hq)) # print결과 : 1
2) 두 번째 방식은, 튜플(tuple)을 이용하는 것입니다.
heapq.heappush(hq, (-1, 1))
heapq.heappush(hq, (-2, 2))
heapq.heappush(hq, (-3, 3))
print(heapq.heappop(hq)[1]) # print결과 : 3
print(heapq.heappop(hq)[1]) # print결과 : 2
print(heapq.heappop(hq)[1]) # print결과 : 1
파이썬 입력 받기(sys.stdin.readline)
한 두줄 입력받는 문제들과 다르게, 반복문으로 여러줄을 입력 받아야 할 때는 input()으로 입력 받는다면 시간초과가 발생할 수 있습니다.
반복문으로 여러줄 입력받는 상황에서는 반드시 sys.stdin.readline()을 사용해야 시간초과가 발생하지 않습니다.
#한 개의 정수를 입력받을 때
import sys
a = int(sys.stdin.readline())
#정해진 개수의 정수를 한줄에 입력받을 때
import sys
a,b,c = map(int,sys.stdin.readline().split())
#임의의 개수의 정수를 한줄에 입력받아 리스트에 저장할 때
import sys
data = list(map(int,sys.stdin.readline().split()))
#임의의 개수의 정수를 n줄 입력받아 2차원 리스트에 저장할 때
import sys
data = []
n = int(sys.stdin.readline())
for i in range(n):
data.append(list(map(int,sys.stdin.readline().split())))
#문자열 n줄을 입력받아 리스트에 저장할 때
import sys
n = int(sys.stdin.readline())
data = [sys.stdin.readline().strip() for i in range(n)]
itertools.permutations()
import itertools
pool = ['A', 'B', 'C']
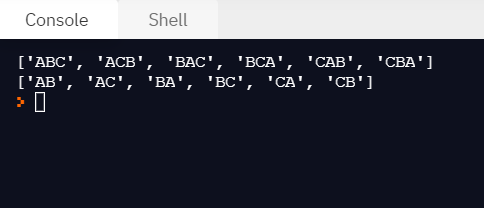
print(list(map(''.join, itertools.permutations(pool)))) # 3개의 원소로 수열 만들기
print(list(map(''.join, itertools.permutations(pool, 2)))) # 2개의 원소로 수열 만들기
itertools.product
from itertools import product
_list = ["012", "abc", "!@#"]
pd = list(product(*_list))
# [('0', 'a', '!'), ('0', 'a', '@'), ('0', 'b', '!'), ('0', 'b', '@'), ('1', 'a', '!'), ('1', 'a', '@'), ('1', 'b', '!'), ('1', 'b', '@')]
```python
from itertools import product
n = 4
print(list(product(['+','-','*','/'], reapeat = (n - 1)))
return None
파이썬에서는 return None은 생략 가능하다.
아무것도 리턴하지 않으면 자바나 C++는 당연히 에러를 내뱉겠지만, 파이썬은 자연스럽게 None을 할당하기 때문이다.
collections.Counter()
컨테이너에 동일한 값의 자료가 몇개인지를 파악하는데 사용하는 객체이다.
import collections
lst = ['aa', 'cc', 'dd', 'aa', 'bb', 'ee']
print(collections.Counter(lst))
'''
결과
Counter({'aa': 2, 'cc': 1, 'dd': 1, 'bb': 1, 'ee': 1})
'''
update()
import collections
# 문자열
a = collections.Counter()
print(a)
a.update("abcdefg")
print(a)
'''
결과
Counter()
Counter({'f': 1, 'e': 1, 'b': 1, 'g': 1, 'c': 1, 'a': 1, 'd': 1})
'''
# 딕셔너리
a.update({'f':3, 'e':2})
print(a)
'''
결과
Counter({'f': 4, 'e': 3, 'b': 1, 'g': 1, 'c': 1, 'a': 1, 'd': 1})
'''
elements()
-
입력된 값의 요소에 해당하는 값을 풀어서 반환한다. 요소는 무작위로 반환하며, 요소 수가 1보다 작을 경우 elements는 이를 출력하지 않는다.
- elements()는 대소문자를 구분하며, sorted()를 이용하여 정렬해줄 수 있다.
import collections
c = collections.Counter("Hello Python")
print(list(c.elements()))
print(sorted(c.elements()))
'''
결과
['n', 'h', 'l', 'l', 't', 'H', 'e', 'o', 'o', ' ', 'y', 'P']
[' ', 'H', 'P', 'e', 'h', 'l', 'l', 'n', 'o', 'o', 't', 'y']
'''
c2 = collections.Counter(a=4, b=2, c=0, d=-2)
print(sorted(c.elements()))
'''
결과
['a', 'a', 'a', 'a', 'b', 'b']
'''
most_common(n)
- 빈도수(frequency)가 높은 순으로 상위 n개를 리스트(list) 안의 투플(tuple) 형태로 반환한다.
c2 = collections.Counter('apple, orange, grape')
print(c2.most_common())
print(c2.most_common(3))
'''
결과
[('a', 3), ('p', 3), ('e', 3), ('g', 2), (',', 2), ('r', 2), (' ', 2), ('n', 1), ('l', 1), ('o', 1)]
[('a', 3), ('p', 3), ('e', 3)]
'''
subtract()
- subtract()는 말 그대로 요소를 빼는것을 의미한다. 다만, 요소가 없는 경우는 음수의 값이 출력된다.
import collections
c3 = collections.Counter('hello python')
c4 = collections.Counter('i love python')
c3.subtract(c4)
print(c3)
'''
결과
Counter({'l': 1, 'h': 1, 'n': 0, 't': 0, 'p': 0, 'e': 0, 'o': 0, 'y': 0, 'i': -1, 'v': -1, ' ': -1})
'''
c = Counter(a=4, b=2, c=0, d=-2)
d = Counter(a=1, b=2, c=3, d=4)
c.subtract(d)
print(c)
'''
결과
Counter({'a': 3, 'b': 0, 'c': -3, 'd': -6})
'''
빈 collection.Counter() 더하기: 핵(Hack)
- 0이하인 아이템을 목록에서 아예 제거해버린다.
Dictionary
popitem()
-
pop()은 반드시 키를 지정해야 하고, 해당 키의 아이템을 추출하는 역할을 한다. -
따로 키를 지정하지 않고 가장 마지막 아이템을 추출하기 위해서는
popitem()을 사용한다.
ord(), chr()
ord()
- 특정한 한 문자를 아스키 코드 값으로 변환해 주는 함수
print(ord('A'))
print(ord('a')
#65
#97
chr()
- 아스키 코드 값을 문자로 변환해 주는 함수 (10, 16진수 사용 가능)
print(chr(65))
print(chr(96))
print(chr(0x32))
#A
#`
#2
collections.OrderedDict()
(https://excelsior-cjh.tistory.com/98)
OrderedDict 는 기본 딕셔너리(dictionary)와 거의 비슷하지만, 입력된 아이템들(items)의 순서를 기억하는 Dictionary 클래스이다.
OrderedDict 는 아이템들(items)의 입력(또는 삽입) 순서를 기억하기 때문에 sorted()함수를 사용하여 정렬된 딕셔너리(sorted dictionary)를 만들때 사용할 수 있다. 아래 [예제1]은 sorted dictionary 를 만드는 예제이다.
# 예제1 - sorted()를 이용한 정렬된 OrderedDict 만들기
from collections import OrderedDict
# 기본 딕셔너리
d = {'banana': 3, 'apple': 4, 'pear': 1, 'orange':2}
# 키(key)를 기준으로 정렬한 OrderedDict
ordered_d1 = OrderedDict(sorted(d.items(), key=lambda t:t[0]))
print(ordered_d1)
'''
결과
OrderedDict([('apple', 4), ('banana', 3), ('orange', 2), ('pear', 1)])
'''
# 값(value)를 기준으로 정렬한 OrderedDict
ordered_d2 = OrderedDict(sorted(d.items(), key=lambda t:t[1]))
print(ordered_d2)
'''
결과
OrderedDict([('pear', 1), ('orange', 2), ('banana', 3), ('apple', 4)])
'''
# 키(key)의 길이(len)를 기준으로 정렬한 OrderedDict
ordered_d3 = OrderedDict(sorted(d.items(), key=lambda t:len(t[0])))
print(ordered_d3)
'''
결과
OrderedDict([('pear', 1), ('apple', 4), ('orange', 2), ('banana', 3)])
'''
# ordered_d1에 새로운 아이템 추가
ordered_d1.update({'grape': 5})
print(ordered_d1)
'''
결과
OrderedDict([('apple', 4), ('banana', 3), ('orange', 2), ('pear', 1), ('grape', 5)])
'''
출처: https://excelsior-cjh.tistory.com/98 [EXCELSIOR]
(https://appia.tistory.com/216)
import collections
ordered_Dict1 = collections.OrderedDict()
ordered_Dict1['x'] = 100
ordered_Dict1['y'] = 200
ordered_Dict1['z'] = 300
ordered_Dict2 = collections.OrderedDict()
ordered_Dict2['x'] = 100
ordered_Dict2['z'] = 300
ordered_Dict2['y'] = 200
print("Object1")
print(ordered_Dict1)
print("Object2")
print(ordered_Dict2)
if ordered_Dict1 == ordered_Dict2 :
print(" Dictionary가 동일")
else :
print(" Dictionary가 다름")
Object1
OrderedDict([('x', 100), ('y', 200), ('z', 300)])
Object2
OrderedDict([('x', 100), ('z', 300), ('y', 200)])
Dictionary가 다름
-
순서와 상관없이, key/value 쌍이 동일하면 동일하다고 인식하는 것이 일반적인 Dictionary입니다.
-
OrderedDict의 경우 순서까지도 저장되어 있기 때문에 관련해서 순서 또한 비교 대상으로 포함이 됩니다.
아스테리스크 (*)
Unpacking
알고리즘을 짜다보면 결과부분을 출력할 때, for-loop를 이용하여 list를 순회하며 출력하는 경우가 있습니다.
# list unpacking
test = [1, 2, 3, 4]
print(*test) # 1 2 3 4
# tuple unpacking
test = (5, 6, 7, 8)
print(*test) # 5 6 7 8
-
다음은 각 변수 중 하나에 가변적으로 할당하고 싶은 경우입니다.
-
다음과 같이 사용할 수도 있습니다.
test = [1, 2, 3, 4, 5]
*a, b = test
print(a, b) # [1, 2, 3, 4], 5
a, *b, c = test
print(a, b, c) # 1, [2, 3, 4], 5
