-
데이터의 컬럼 별 단위 또는 범위를 통일시켜준다고 생각하면 편하다.
-
컬럼별로 뭐 시간, km, kg 등 다양한 단위를 가지는데 이러면 직접적인 비교가 불가능하다.
-
예를 들어, 넌 180cm인데 난 80kg이니깐 내가 더 몸이 좋아! 라고 한다면 상대방이 나를 이상한 사람 취급할 것이다.
- 또는 토익 300점(990점 만점)인데 넌 학교 영어점수가 100점(100점만점)이니 내가 더 영어를 잘하네. 라고 한다면 똑같이 나를 이상한 취급을 할 것이다.
-
-
이처럼 다른 데이터로 비교한다는 것이 말이 안되므로 이를 극복하기 위해 정규화 또는 표준화를 해준다고 생각하면 편하다.
정규화
-
정규화는 값의 범위를 0~1사이로 옮겨준다.
- 모든 데이터의 단위가 모두 0~1사이로 옮겨지게 해주는 것이다.
-
데이터의 컬럼들이 평등하게 0~1사이로 놓여지기 때문에 기계가 학습하기에 어느 컬럼에 중점을 두고 학습하기보단 평등하게 컬럼들을 보고 학습시킨다.
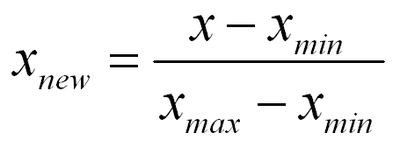
표준화
-
표준화는 먼저 데이터가 정규분포를 따른다는 가정하에 실시된다.(정규분포는 종모양 분포임)
-
정규분포를 따른다는 가정하에 데이터를 평균은 0, 표준편차는 1이 되도록 만들어준다.
-
그렇기에 평균은 0이니깐 0의 근처로 많이 잡힐 것이다. 0의 좌우로 표준편차 1이 되게 분포가 될 것이다.

For the sake of someone who studies computer science