
![]()
이 시리즈는 공개자료인 Operating Systems: Three Easy Pieces (OSTEP)을 공부하면서 정리한 글들입니다. 궁금한 점이 있거나 오류가 있다면 댓글로 알려주세요!
The Abstraction: The Process
OS의 3요소중 가상화(Virtualization)를 통해 가상의 CPU 코어들을 만드는데, 이때 핵심이 되는 기술이 바로 프로세스(Process)입니다. 프로세스는 돌아가고 있는 프로그램입니다. 결국 프로그램이 가지고 있는 요소들은 프로세스에도 들어가 있는데, 프로그램이 돌아가는 명령어(Instructions)와 데이터, PC(Program Counter), Stack pointer등이 들어가 있습니다.
프로세스를 통제하는 OS는 가상으로 CPU를 늘리기 때문에 이를 관리하는 방식이 있어야 합니다. 대표적인 관리방식은 Time Sharing입니다. 이 방식을 사용하면 하나의 CPU 코어를 여러 프로세스가 쓰되, 한 프로세스가 쓰다가 중단해 다른 프로세스에게 넘겨주는 방식으로 작동됩니다. 이때 넘겨주는 행위를 Context Switch라고 합니다. 만약 수 많은 프로세스가 있다면 어떤 순서로 CPU를 넘겨줘야 할까요? 이런 순서를 정해주는 정책을 Scheduling policy라고 하고 정책에 따라 우선순위를 정합니다.
Process API
글 후반에서 실제 UNIX가 사용하는 프로세스 API를 다루지만, 어떤 형식의 API가 있어야 하는지 다뤄봅시다.
- Create : 프로세스를 생성하는 메서드가 있어야 합니다.
- Destroy : 프로세스 내부에서도 프로세스를 종료하는 방식이 있지만, 프로세스 내부에서 오류가 발생하거나 외부에서 종료가 필요할때 사용하는 메서드가 있어야 합니다.
- Wait : 프로세스가 돌아갈 때 잠시 일시정지하는 메서드가 있어야 합니다.
- Miscellaneous Control : 위 메서드 이외에도 다양한 컨트롤을 할 수 있는 메서드가 있어야 합니다.
- Status : 프로세스의 상태를 확인하는 메서드가 있어야 합니다.
Process States
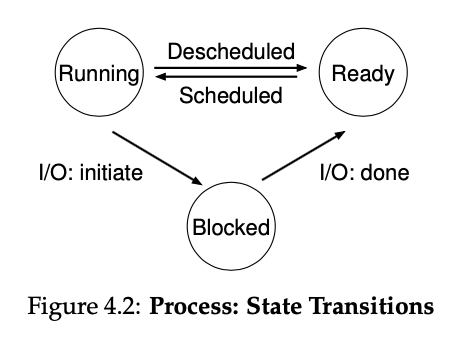
프로세스가 만들어지면, 프로세스의 상태는 항상 3가지 중 하나의 상태를 가지고 있습니다.
- Running : 프로세스가 CPU를 가지고 돌아가고 있는 상태입니다.
- Ready : 프로세스가 만들어졌지만, 스케쥴링 정책에 의해 대기중인 상태입니다.
- Blocked : 실행(Running)과정 중 특정 요소를 사용해야 되 CPU의 사용을 일시중지한 상태이다. 대표적으로 I/O 작업을 진행해야 되 이에 대한 결과가 오기 전까지는 Blocked되어있는 상태입니다.
이에 대한 상태를 변경하는 것은 OS의 스케쥴러(Scheduler)가 하는 일입니다. 만약 프로세스 A가 I/O 작업을 해야되 Blocked 되어 대기하고 있는 프로세스 B가 Running 하다가 프로세스 A의 I/O 작업이 끝나 Ready 상태로 변경되었을 때 프로세스 B를 Descheduled하고 프로세스 A를 바로 Scheduled할지 아님 프로세스 B의 작업이 끝나고 A를 Scheduled할지는 모두 스케쥴러와 스케쥴링 정책에 따라 달라집니다.
Data Structures
OS에서 프로세스의 정보를 저장하기 위해 Process List를 만들어 관리합니다. 이때 리스트의 노드 하나하나를 각각 PCB(Process Cotrol Block)라고 하는데 쉽게 생각하면 C에서의 structure 하나를 의미하는 거라고 이해하면 될 것 같습니다. PCB안에는 프로세스의 상태, ID(PID), 부모 프로세스, 열어놓은 파일들, 현재 실행중인 디랙토리 위치, 레지스터에 저장된 데이터들 등을 저장합니다.
Interlude: Process API
UNIX에서 제공하는 Process API 중 주요 시스템콜 3개는 fork, wait, exec 입니다. 이에 대해 하나씩 알아보겠습니다.
📖 아래 설명들은 정말 간단하게 설명한 글입니다. 실제로 사용하게 된다면 꼭
man명령어를 사용해 매뉴얼을 읽어보길 바랍니다. RTFM!
fork
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main(int argc, char **argv) {
printf("hello world (pid:%d)\n", (int) getpid());
int rc = fork(); // [A]
if (rc < 0) {
// fork failed
fprintf(stderr, "fork failed\n");
exit(1);
}
else if (rc == 0) // child (new process)
printf("hello, I am child (pid:%d)\n", (int) getpid());
else // parent goes down this path (main)
printf("hello, I am parent of %d (pid:%d)\n", rc, (int) getpid());
return 0;
}fork 함수는 프로세스를 생성하는 함수입니다. 이때 코드는 약간 특이한 방식으로 실행되게 됩니다. 위 코드에서는 [A] 파트에서 fork 함수를 실행하는데, 이때 프로세스가 생깁니다. 이렇게 생긴 프로세스는 원 프로세스의 자식(child) 프로세스라고 하고, 원 프로세스는 부모(parent) 프로세스라고 부릅니다. 이때 자식 프로세스는 프로그램의 맨 처음부터 실행하는 것이 아니라, [A]파트부터 실행하게 됩니다.
프로세스가 생성되면, 자식 프로세스는 부모 프로세스와 서로 다른 프로그램으로 분리됩니다. 그러기 때문에 자식 프로세스와 부모 프로세스는 서로 다른 메모리, 레지스터, PC(Program Counter), 스택, PID를 사용합니다. 이때 자식의 메모리의 경우에는 부모의 메모리를 복사해 이전 부모 프로세스의 실행 결과를 가지게 됩니다. 또한 부모는 자식의 PID를 fork 함수의 리턴값으로 알 수 있습니다. 반대로 자식 프로세스는 fork 함수의 리턴값으로 0을 반환받는데 이를 통해 본인의 프로세스가 자식 프로세스라는 것을 알 수 있습니다.
wait
fork 예시 코드에서 자식 프로세스와 부모 프로세스 중 누가 먼저 끝나게 될까요? 정답은 알 수 없음 입니다. 둘 중 누가 먼저인지 정해진 원칙이 없기 때문에 상황에 따라 달라집니다. 이때 부모의 경우에는 wait 함수가 프로세스의 순서를 정할 수 있습니다.
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/wait.h>
int main(int argc, char **argv) {
printf("hello world (pid:%d)\n", (int) getpid());
int rc = fork(); // [A]
if (rc < 0) {
// fork failed
fprintf(stderr, "fork failed\n");
exit(1);
}
else if (rc == 0) // child (new process)
printf("hello, I am child (pid:%d)\n", (int) getpid());
else { // parent goes down this path (main)
int wc = wait(NULL);
printf("hello, I am parent of %d (wc:%d) (pid:%d)\n", rc, wc, (int) getpid());
}
return 0;
}wait 함수는 생성한 자식 프로세스가 종료될 때 까지 기다리는 함수이다. 그 말은, 자식 프로세스가 종료해야 wait 함수의 작동이 종료됩니다. 이때 리턴값으로 자식 프로세스의 PID를 가져옵니다.
exec
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <sys/wait.h>
int main(int argc, char *argv[]){
printf("hello world (pid:%d)\n", (int) getpid());
int rc = fork();
if (rc < 0) { // fork failed; exit
fprintf(stderr, "fork failed\n");
exit(1);
} else if (rc == 0) { // child (new process)
printf("hello, I am child (pid:%d)\n", (int) getpid());
char *myargs[3];
myargs[0] = strdup("wc"); // program: "wc" (word count)
myargs[1] = strdup("p3.c"); // argument: file to count
myargs[2] = NULL; // marks end of array
execvp(myargs[0], myargs); // runs word count
printf("this shouldn’t print out");
} else { // parent goes down this path (main)
int wc = wait(NULL);
printf("hello, I am parent of %d (wc:%d) (pid:%d)\n",
rc, wc, (int) getpid());
}
return 0;
}exec 함수는 fork와는 다르게 외부 프로그램을 실행할 때 사용하는 함수입니다. 이때 매개변수로 실행하는 프로그램에 대해 명시해야 합니다. 이때 exec를 실행한 프로세스는 종료됩니다. 그렇기 때문에 위 예시에서 자식 프로세스는 execvp 함수를 실행하고 다음줄은 출력되지 않고 종료됩니다.
Why fork and exec?
지금까지 살펴보았을 때 fork와 exec는 유사하다고 볼 수 있습니다. 두 함수 모두 새로운 프로세스를 사용하기 때문에, 이를 통합해도 괜찮다는 생각이 들 수도 있습니다. 다만 이 두 함수가 분리된 이유는 UNIX Shell의 작동 방식 때문입니다. Shell에서는 코드 실행을 fork -> 코드 실행 -> exec의 순으로 진행됩니다.
이에 대한 예시로써 Piping이 있습니다. 쉘에서 wc p3.c > newfile.txt를 실행하면 wc 명령어의 결과를 newfile.txt에 저장하게 됩니다. 이때 wc를 실행하기 전 stdout을 newfile.txt로 변경하는 과정이 필요합니다. 이를 exec 전에 실행해야 되기 때문에 fork 와 exec 사이에 그 작업을 집어넣습니다.
참고자료
