CHAPTER 2 - 데이터 수집하기
2-2. 웹스크래핑 사용하기
핵심 키워드
웹 스크래핑 beautiful Soup
웹 스크래핑과 웹 크롤링
프로그램으로 웹사이트의 페이지를 옮겨 가면서 데이터를 추출하는 작업을 웹 스크래핑 또는 웹 크롤링이라고 한다.
ex. 도서 판매 사이트에서 개별 도서의 페이지 수 가져오기
검색 결과 페이지 가져오기
20대가 가장 좋아하는 도서 목록을 코랩으로 불러온다. gdown 패키지로 구글드라이브에 있는 파일을 자동으로 다운로드할 수 있다.
- 데이터의 행과 열 선택하기 - loc 메서드

판다스의 loc[] 메서드는 원하는 행과 열을 선택할 수 있다. 대괄호 안에서 행의 목록과 열의 이름을 받는다. 아래 코드는 슬라이스 연산자를 이용하여 no~isbn13을 전체 행에 대해서 선택해서 새로운 데이터프레임 books 를 만들었다.
- 검색 결과 페이지 HTML 가져오기 - requests.get() 함수
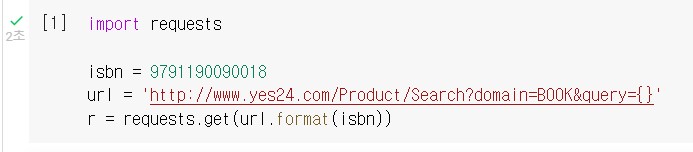
requests.get() 함수로 첫 번째 도서에 대한 검색 결과 페이지 HTML을 가져오도록 하자. 파이썬의 문자열 메서드인 format() 으로 isbs 변수에 저장된 값을 url 변수에 저장한다.
- HTML에서 데이터 추출하기 - Beautiful Soup
파이썬에서는 웹 기반 API를 호출할 때는 requests 패키지를 사용하고, 여기서 뽑아낸 HTML에서 우리에게 필요한 데이터들을 찾을 때는 Beautiful Soup 패키지가 사용된다.
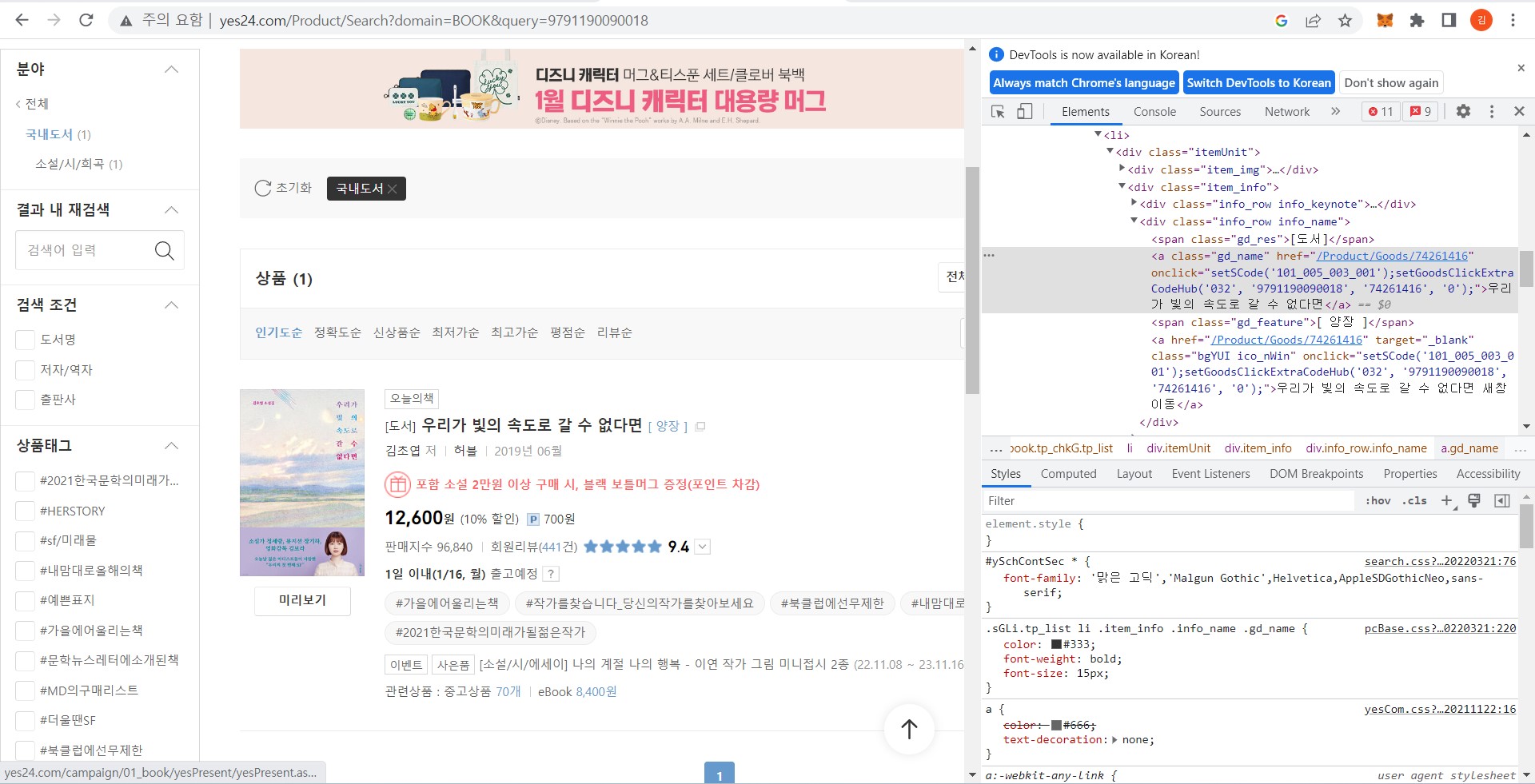
개발자 도구를 열어 우측 커서 아이콘을 클릭 후 알고 싶은 정보인 도서 제목 위에 가져다 대면 해당 페이지 링크의 위치를 쉽게 찾을 수 있다.
Beautiful Soup 클래스를 임포트 후 soup 객체를 생성한다. 첫 번째 매개변수는 파싱할 HTML 문서이고, 두 번째 매개변수는 파싱에 사용할 파서이다.

- 태그 위치 찾기 - find() 메서드

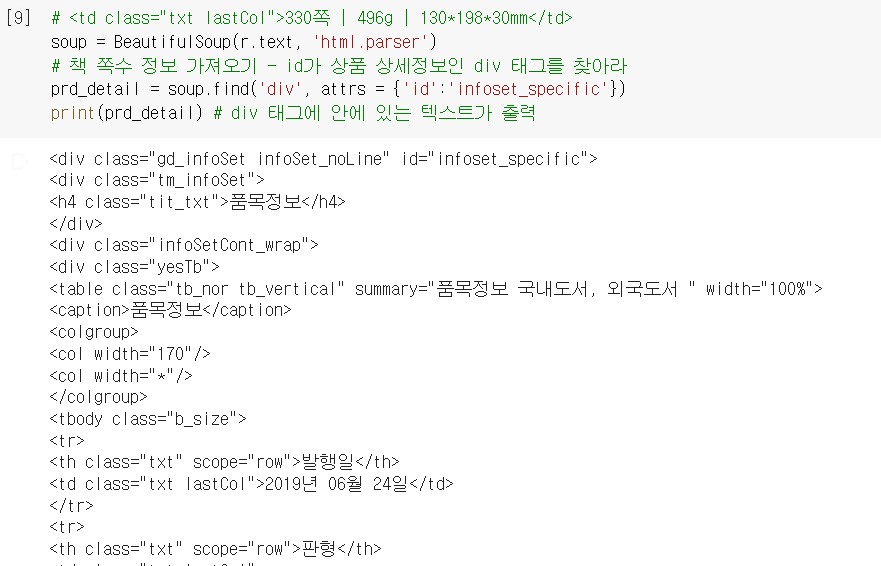
태그 위치는 soup 객체의 soup.find() 메서드를 사용하면 찾을 수 있다. 첫 번째 매개변수에는 찾을 태그 이름을 지정하고, atts 매개변수에는 찾으려는 태그의 속성을 딕셔너리로 지정한다.
- 도서 상세 페이지 HTML 가져오기 - requests.get() 메서드
url에 대한 HTML 정보를 가져오려면 requests.get() 메서드를 사용한다.
- 테이블 태그를 리스트로 가져오기 - find_all() 메서드
find_all() 메서드를 사용하면 특정 HTML 태그를 모두 찾아서 리스트로 반환할 수 있다.

-
태그 안의 텍스트 가져오기 - get_text() 메서드
tr 태그를 리스트로 추출하고 나면 for문으로
prd_tr_list를 순회하면서 th 태그 안의 텍스트가 쪽수, 무게, 크기에 해당하는지 검사하고, 원하는 행을 찾으면 태그 안의 텍스트를page_td변수에 저장한다.태그 안에 있는 텍스트를 가져오려면 Tag 객체의
get_text()메서드를 사용한다.

전체 도서의 쪽수 구하기
도서 사이트에서 각 도서의 페이지 수를 텍스트로 가져오는 함수를 아래와 같다.
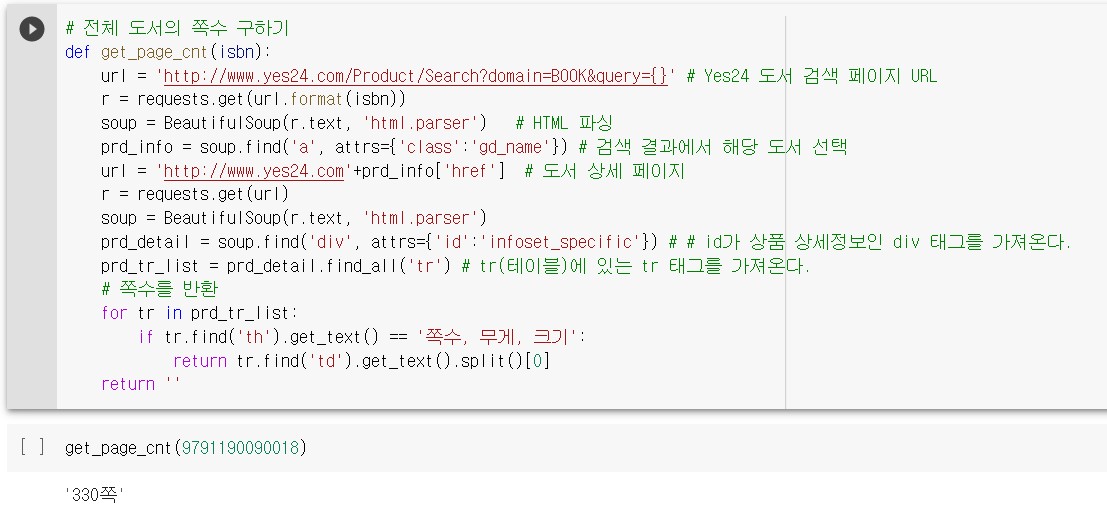
여기서 상위 10권까지의 쪽수를 가져오려면 각 행의 반복 작업을 수행하는 apply() 메서드를 사용한다. 첫 번째 매개변수는 실행할 함수이다.
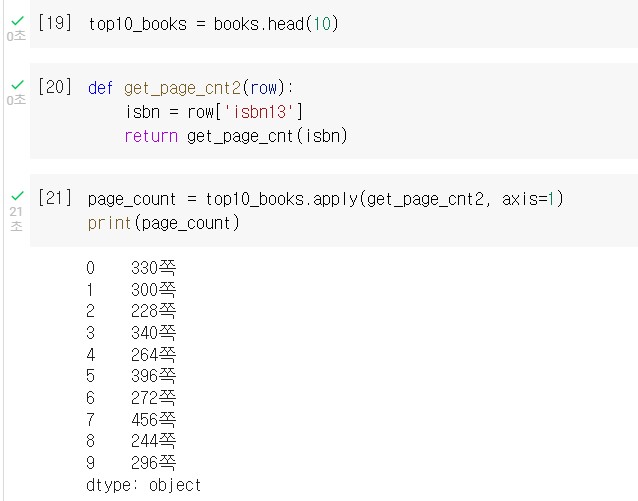
apply() 메서드의 axis=1 은 각 행에 대해 해당 함수를 적용하겠다는 의미이고, axis=0(defualt) 이면 각 열에 대해 적용하겠다는 의미이다.
이렇게 추출한 page_count 시리즈 객체를 top10_books 데이터프레임의 열로 합친다.
시리즈 객체의 name 속성 으로 열 이름을 지정하고, merge() 함수로 데이터프레임과 시리즈를 합친다.
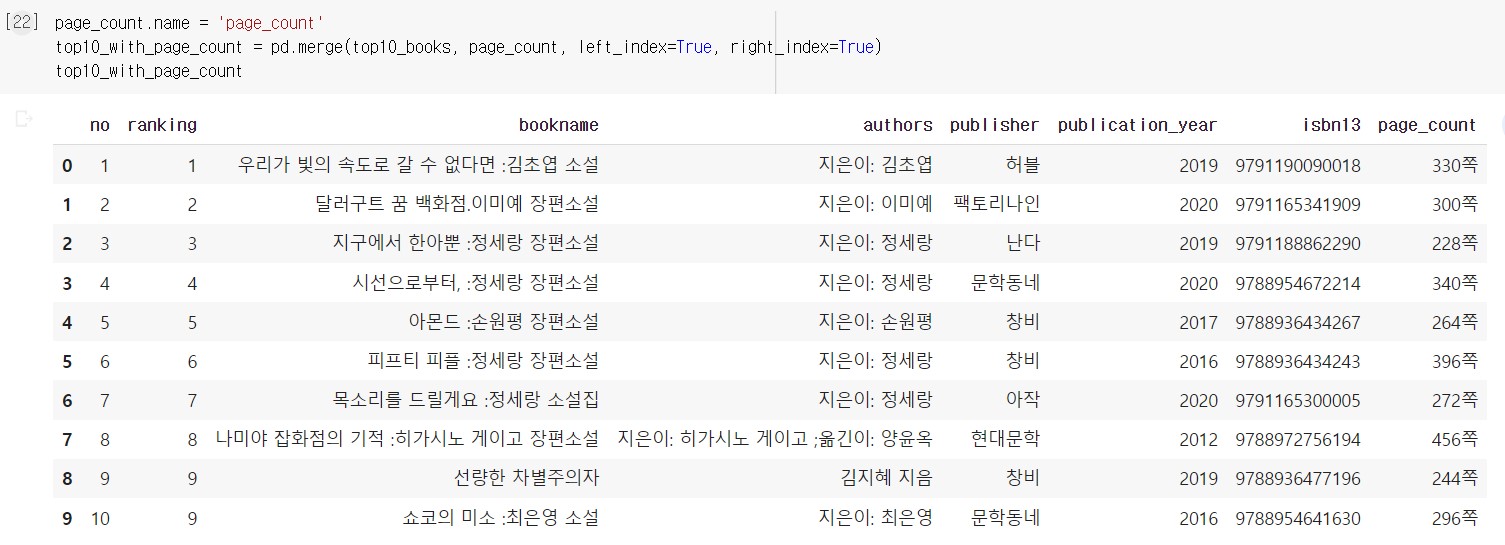
merge() 함수의 첫 번째와 두 번째 매개변수는 합칠 데이터프레임 또는 시리즈 객체이다. 위처럼 두 객체의 인덱스를 기준으로 합칠 경우에는 left_index 와 right_index 매개변수를 True로 지정한다.
웹 스크래핑 시 주의할 점
- 어떤 웹 페이지를 스크래핑 하기 전에, 해당 웹사이트에서 스크래핑을 허락했는지 명시한 robots.txt 파일을 확인한다.
- HTML 태그를 특정할 수 있는지 확인한다. 태그 이름이나 속성 등 필요한 HTML 태그를 특정할 수 없다면 Selenium 과 같은 고급 라이브러리를 사용해야 한다.
또한 데이터베이스와는 달리 웹 페이지는 언제 바뀔지 모르기 떄문에 만약 웹 페이지가 변경되었다면 원하는 데이터를 찾는 과정을 다시 되풀이해야 한다. 즉, 유지보수가 어렵다.
더 알아보기
스크래피 패키지
최근에는 파이썬에서 웹 스크래핑을 사용할 때 Scrapy 패키지를 사용한다. 스크래피는 requests와 Beautiful Soup 를 합쳐 놓은 기능이 담겨있다. 이 패키지에 대해 자세히 알고 싶으면 스크래피 공식 홈페이지를 참고하자.
파싱과 파서
파서는 입력 데이터를 받아 데이터 구조를 만드는 소프트웨어 라이브러리를 의미하고, 이러한 과정을 수행하는 것을 파싱이라고 한다.
예를 들어 파이썬에서 파서는 json 패키지, xml 패키지가 있고, html.parser 는 파이썬에 기본 내장된 HTML 파서이다.
