데이터베이스란?
데이터베이스는 회사가 가지고 있는 데이터가 저장되어 있는 곳이다. 이 안의 데이터를 확인하기 위해서는 데이터베이스 관리 시스템(DBMS) 이라는 프로그램이 필요하다.
MySQL, MariaDB, MongoDB, SQL 서버, OracleDB 등이 있다.
보통 DB와 DBMS를 구분하지 않고 모두 DB라고 부른다.
데이터베이스는 엑셀 파일처럼 레코드(행)과 필드(열)로 구성된 여러 개의 테이블(장)이 있다.
데이터베이스는 엑셀과는 달리 접속 권한을 세밀하게 제어할 수 있기 때문에 부적절한 접근을 막고 데이터를 보호할 수 있다. 예를 들어 동시에 여러 사람이나 프로그램이 데이터베이스를 읽고 쓸 수 있게 하고, 모든 데이터가 안전하게 저장된다.
데이터베이스에서 데이터를 가져오려면 SQL 이라는 언어를 사용해야 한다. SQL을 사용해서 데이터베이스나 테이블을 만들고, 읽고, 추가하고, 삭제할 수 있다.
SQL 문법은 매우 다양하지만 우선 가장 기본적인 SQL 문을 알아보기로 하자.
데이터 읽기: SELECT 문
SELECT: 테이블의 데이터를 읽을 때 사용
SELECT * FROM table_a
table_a로부터 모든 열( * )을 선택하라는 의미이다.
위와 같이 SQL문으로 DBMS에 데이터를 요청하는 것을 쿼리(query)라고 한다.
DBMS가 이 쿼리를 이해하고 데이터베이스에서 데이터를 찾아 반환한다.
파이썬 프로그램을 사용해 쿼리를 전달하면 쿼리 결과로 딕셔너리 또는 리스트 형태의 데이터가 반환된다.
WHERE: 데이터를 추출할 때 어떤 조건을 제시
# table_b 테이블에서 book_name 열에 있는 데이터만 가져와라
SELECT book_name FROM table_b
# table_c 테이블에서 pub_year 열의 값이 2022인 행을 검색한 후, 이 행의 book_name 값을 추출
SELECT book_name FROM table_c WHERE pub_year = 2022 데이터 저장하기: INSERT 문
INSERT: 데이터베이스에서 데이터를 저장(추가)할 때 사용
Ex. 2020년에 출간된 "혼공 머신러닝"을 table_d에 추가해라
INSERT INTO table_d (book_name, pub_year) VALUES ("혼공 머신러닝", 2020)
INSERT INTO 다음에 테이블 이름을 쓴 후 저장하려는 이름을 나열한다. 그리고 VALUES 절에 추가할 값을 나열한다. 열 이름과 값은 모두 소괄호로 감싼다.
주의할 점은 열 이름과 다음에 나열한 값이 서로 짝을 이뤄야 하기 때문에 열 순서대로 값을 나열한다.
예를 들어 위의 book_name에 정수가, pub_year에 문자열 값이 들어가면 오류가 발생한다.
파이썬에서 SQL 사용하기: SQLite
대표적인 오픈소스 DBSM에는 MySQL, MariaDB 등이 있지만 파이썬에 기본적으로 내장되어 있는 임베디드 데이터베이스인 SQLite를 사용해보자.
새 데이터베이스에 남산도서관 데이터를 저장하기 위해서는 테이블이 필요하다. 
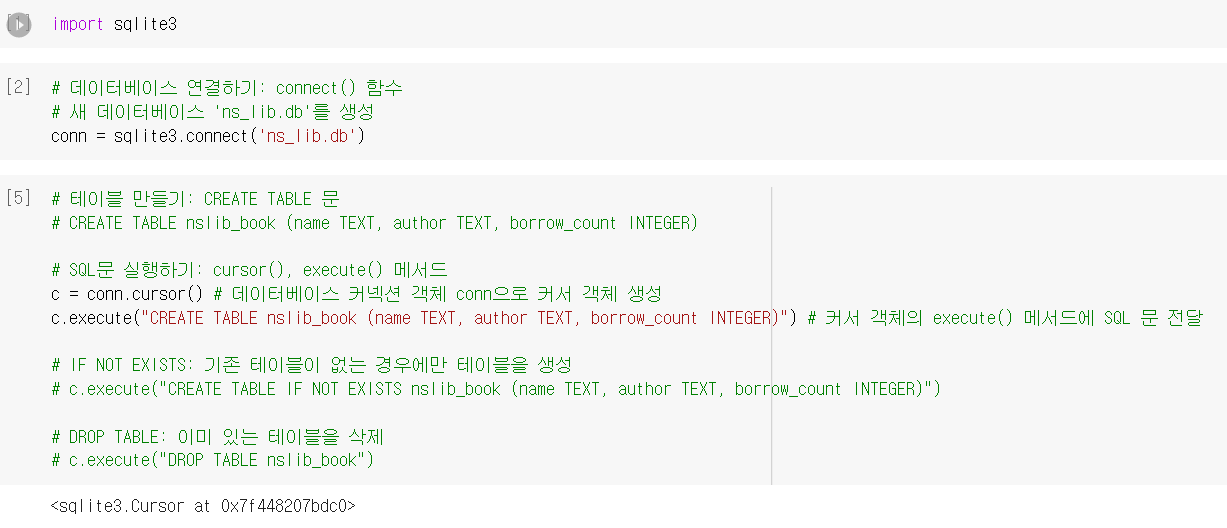
데이터프레임 데이터를 테이블에 추가하기
한 행씩 반복 실행하기 위해서는 for 문과 iterrows() 메서드를 사용한다. 테이블에 데이터프레임의 데이터를 저장하기 위해서는 INSERT INTO nslib_book (name, author, borrow_count) VALUES ('인공지능과 흙', '김동훈 지음', 0) 라고 쓴 후 제목 안에 작은따옴표 등 특수문자가 있는 경우 처리를 수동으로 해줘야 한다.
하지만 아래처럼 execute()를 쓰면 문자열 안의 특수문자를 따로 이스케이프 처리를 해주지 않아도 된다.
c.execute('INSERT INTO nslib_book (name, author, borrow_count) VALUES (?, ?, ?) ', ('인공지능과 흙', '김동훈 지음', 0) )
문자열을 수동으로 다루지 않고 execute() 메서드의 두 번째 매개변수로 튜플을 전달하면 SQL 인젝션을 방지할 수 있다.

약 40만건 정도의 데이터를 데이터베이스에 저장하는데 약 23초가 걸렸다. 만약 데이터가 이보다 많다면 실행시간이 매우 길어질 것이다.
판다스 데이터프레임은 한 행씩 순차적으로 처리하는 데 최적화 되어있지 않아 데이터프레임을 for문으로 돌려 반복하는 일은 아주 비효율적이다.
그대신 to_sql(DB테이블명, DB커넥션객체) 메서드를 사용해서 데이터프레임을 바로 테이블에 추가하면 수행시간을 줄일 수 있다.
if_exists 매개변수는 세 가지 옵션 중에서 하나를 지정해서 테이블이 중복될 때 어떻게 동작하는지 정할 수 있다.
fail: 기본값. 첫 번째 매개변수에 지정된 테이블이 이미 있으면 오류가 발생replace: 테이블을 지우고 새로 만든 다음 데이터를 추가append: 기존의 테이블에 데이터를 추가
index=False로 지정하면 데이터프레임의 인덱스가 저장되지 않는다.

파이썬에서 테이블로 데이터 읽기
데이터베이스의 데이터를 가져오려면 excute() 메서드 안에서 SELECT 문을 실행한다.
데이터베이스에서 가져온 데이터를 확인하기 위해서는 세 가지 메서드를 사용한다.
fetchone(): 가져온 테이블의 첫 번째 행을 추출. 튜플 형태로 반환된다.fetchmany(): 1개 이상의 행을 추출. 튜플 리스트 형태로 반환된다.fetchall(): 모든 행을 추출. 데이터베이스 한 행에 해당하는 튜플 리스트를 반환한다.

또한 데이터베이스를 읽어 바로 데이터프레임을 생성할때는 read_sql_query() 함수를 사용한다.
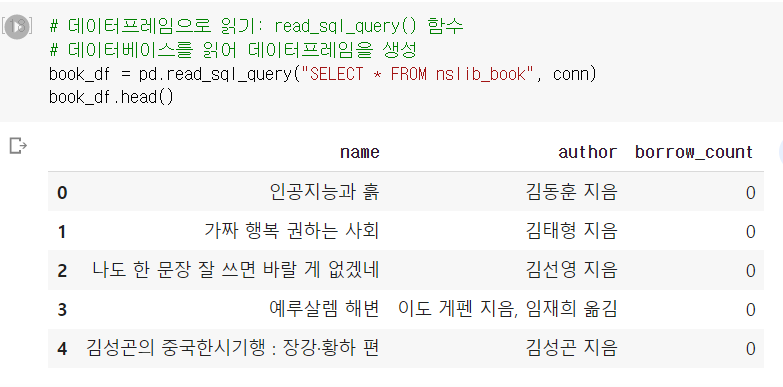
데이터베이스에서 제공하는 함수로 통계량 구하기
DBMS는 SQL 문과 함께 사용할 수 있는 통계, 수학 함수를 제공한다.
그래서 fetchall() 메서드로 전체 데이터를 모두 읽어서 파이썬 함수로 직접 계산하는 것보다, DBMS가 제공하는 함수를 사용하면 사용하기 편리하고 실행속도도 빠르다.
테이블 데이터 정렬하기
테이블 데이터를 순서대로 정렬하려면 테이블 이름 뒤에 ORDER BY 절을 사용한다.
Ex 1. 가장 많이 대출된 도서를 오름차순으로 출력하라.
SELECT * FROM nslib_book ORDER BY borrow_count
Ex 2. 가장 많이 대출된 도서를 내림차순으로 출력하라.
SELECT * FROM nslib_book ORDER BY borrow_count DESC
Ex 3. 가장 많이 대출된 10개 도서를 내림차순으로 출력하라.
SELECT * FROM nslib_book ORDER BY borrow_count DESC LIMIT 10

프로그램이 종료되면 데이터베이스 연결이 자동으로 종료된다.
데이터베이스 사용을 끝낼 때는 커서와 커넥션 객체를 명시적으로 닫아준다.
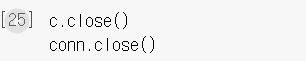
데이터베이스 정규화
데이터베이스 정규화는 데이터가 가능한 중복되지 않도록 여러 테이블에 나누는 과정을 의미한다.
데이터베이스가 정규화되어있지 않다면 여러 데이터를 바꿔야 할 일이 생길때 데이터 불일치가 발생하거나 오류가 발생할 위험이 크다.
예를 들어 book 테이블에 도서정보와 출판사명을 모두 다루지 않고 출판사명만 따로 publisher 테이블로 관리하면 어느 날 출판사명이 바뀌었을 때 해당 테이블의 데이터만 바꾸면 된다.
여러 테이블로 나눠 중복되는 데이터를 줄일수록 좋은 정규화라고 할 수 있다.
이런 정규화를 지원하는 데이터베이스를 관계형 데이터베이스(RDBMS)라고 한다. MySQL, MarinaDB, SQLite가 여기에 해당한다.
반면 정규화와 SQL문을 다루지 않는 데이터베이스인 NoSQL에 해당하는 비관계형 데이터베이스도 있다. 보통 이미지, 문서, 오디오, 빅데이터 등 정규화되기 어려운 데이터를 다루고 저장할 때 사용한다. 그래서 최근 인기가 많은 데이터베이스이기도 하다.
NOSQL 데이터베이스는 표준 SQL 문을 사용하지 않기때문에 데이터베이스마다 데이터를 저장하고 관리하는 방법이 모두 다르다. 하지만 데이터가 정규화 되어있지 않아 전체 데이터를 쉽게 얻을 수 있기 때문에 데이터분석을 하기가 편리하다. Redis, MongoDB 등이 여기에 해당된다.
아쉽게도 코랩에서 바로 사용할 수 있는 NoSQL 데이터베이스는 아직까지 없다.
