앞 글에서, 셀레니움을 활용하여 법인등록번호를 가져올 수 있는 시스템을 만든 이야기를 소개했다.
거의 최종 목표인 재무제표 데이터를 이번 글에서 받아오려 한다.
테스트 계획
1. 기업 이름 입력
2. dart.fss.or.kr에 자동 검색 후 "법인등록번호" 가져오기
3. 공공데이터로 접근해서 회계연도 2020년의 손익계산서와 재무상태표 데이터를 가져와서 출력해보기.
개발
숫자 함수
나는 우선 데이터 미리 보기를 통해, 우리가 받아올 데이터가 보기에 좋지 않음을 알았다.
따라서 숫자를 영미식으로 보기 좋게 만드는 함수를 우선 만들었다.
1000000 (백만)
-> 1,000,000
#영미식 단위로 끊어주는 함수
def money(mon):
a = mon
result = str(mon)
finalresult = ""
count = 0
while (a > 0):
a = a//1000
if(a != 0):
count+=1
for i in range(count):
info = -3*count
index = info+i*3
result = result[:index] + ',' + result[index:]
return result
#----------------
#test
money(1320000)
#result = 1,320,000
#----------------
# O(n)시간복잡도는... 그냥 저럴거 같이 생겼다.
데이터 처리
공공데이터는 대부분 xml형태이다. 우리는 쓰기 좋게 Dict형태로 가져올 것인데, 이를 위해 xmltodict가 필요하다.
$ pip install xmltodict일단, 데이터를 인터넷에서 읽어와야 한다. 따라서 request를 사용할 것이다.
json도 사용하므로, 아래와 같이 import해준다.
import request as rq
import json, xmltodict- S_I변수와 S_FP변수에 손익계산서 데이터 주소와 재무상태표 데이터 주소를 할당한다.
- rq.get(S_I).content로 xml을 받아온다.
- xmltodict.parse()함수를 사용하여 dict형태로 파싱한다.
- 서버에 저장할 수도 있는 가능성을 고려하여, 이를 string형태로 저장한다.
- 근데 우리는 json 형태를 사용할 것이므로, json.load()를 활용하여 json형태로 바꾼다.
손익계산서 데이터를 처리한 부분을 보면 이해가 될 것이다.
S_I_content = rq.get(S_I).content
S_I_dict = xmltodict.parse(S_I_content)
S_I_jsonString = json.dumps(S_I_dict['response']['body']['items']['item'], ensure_ascii=False)
#string -> json
S_I_jsonObj = json.loads(S_I_jsonString)이렇게 받아온 데이터를 아래와 같이 프린트 했다.
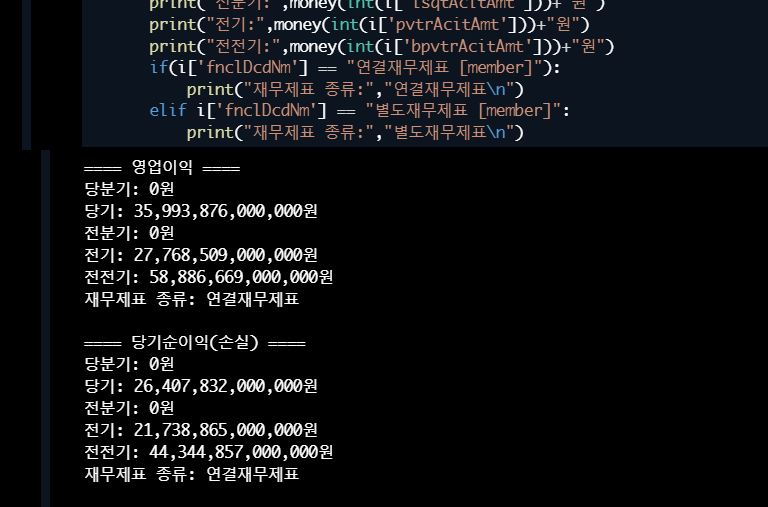
for i in S_I_jsonObj:
print('====',i['acitNm'],'====')
print("당분기:", money(int(i['thqrAcitAmt']))+"원")
print("당기:",money(int(i['crtmAcitAmt']))+"원")
print("전분기:",money(int(i['lsqtAcitAmt']))+"원")
print("전기:",money(int(i['pvtrAcitAmt']))+"원")
print("전전기:",money(int(i['bpvtrAcitAmt']))+"원")
if(i['fnclDcdNm'] == "연결재무제표 [member]"):
print("재무제표 종류:","연결재무제표\n")
elif i['fnclDcdNm'] == "별도재무제표 [member]":
print("재무제표 종류:","별도재무제표\n")결과 중 일부는 다음과 같았다.
향후 계획
이제, 여러 기업들의 정보를 받아서 엑셀로 정리하여 분석 하는 방향으로 나아갈 계획이다.
HUFS 산업경영공학 & 경제학