Intro
Convolutional LSTM Network(Xingjian, 2015)
연속적인 기간 동안 수집된 데이터는 시계열로 특성화된다. 이러한 경우 흥미로운 접근 방식은
RNN(Recurrent Neural Network)의 LSTM(Long Short Term Mememory)기반을 사용하는 것이다.
이러한 모델은 이전에 숨겨진 상태의 시퀀스를 다음 단계로 전달한다. 따라서 네트워크는 이번에 본 데이터에 대한 정보를 보유하고 이를 사용하여 결정을 내린다.
Convolutional LSTM에서는 전혀 다른 접근을 합니다. 바로 LSTM 내부 오퍼레이션 자체에 컨볼루션을 넣는 것이다. Convolutional LSTM에서 수정된 key equation은 다음과 같다.
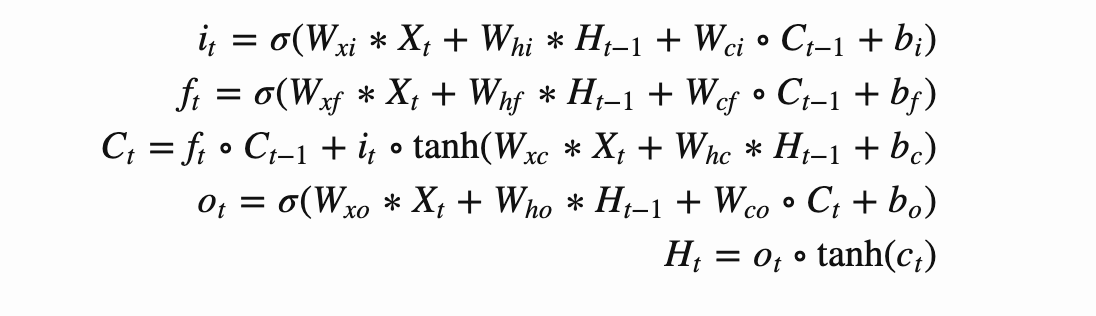
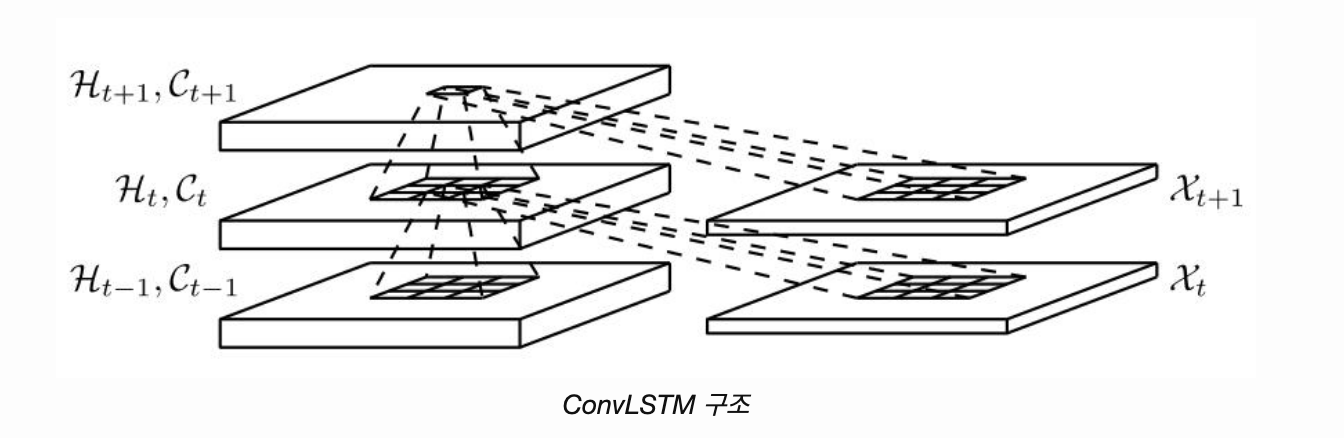
입력, 상태, 출력 모두 3차원 텐서이고, 다음은 입력과 셀의 전 상태를 convolution으로 받는 것을 시각화한 것이다.
- Convolutional LSTM 기반의 Encoding-Forecasting 모델
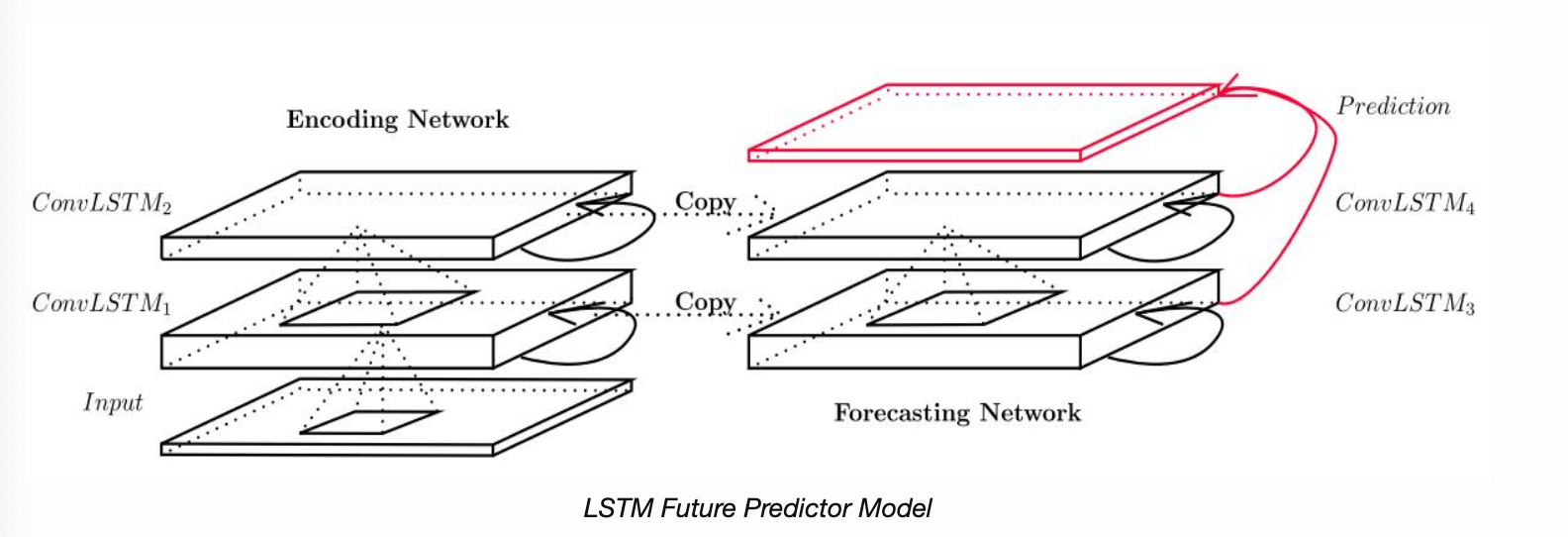
- 단일 LSTM으로 구성되어 있던 부분을 여러 개의 Convolutional LSTM을 stacking한 것을 사용
결과적으로, LSTM 셀 자체에서 공간적인 의미와 시간적인 의미를 동시에 잡아낼 수 있게 됐다는 것이다. - Forecasting 모델에서는 마지막 쌓여진 Convolutional LSTM 셀의 출력을 최종 output으로 삼지 않고,
각각 다른 수준에서의 Convolutional LSTM의 상태를 하나씩 받아 이를 연결한 결과에 1x1 Convolution층에 걸어준다. 이른 출력을 입려과 같은 차원으로 조정해줌과 동시에, 각각 다른 수준의 셀 상태를 동시에 고려해주는 효과가 있기 때문이다.
다른 예측 프레임에서의 평가 인덱스 그래프
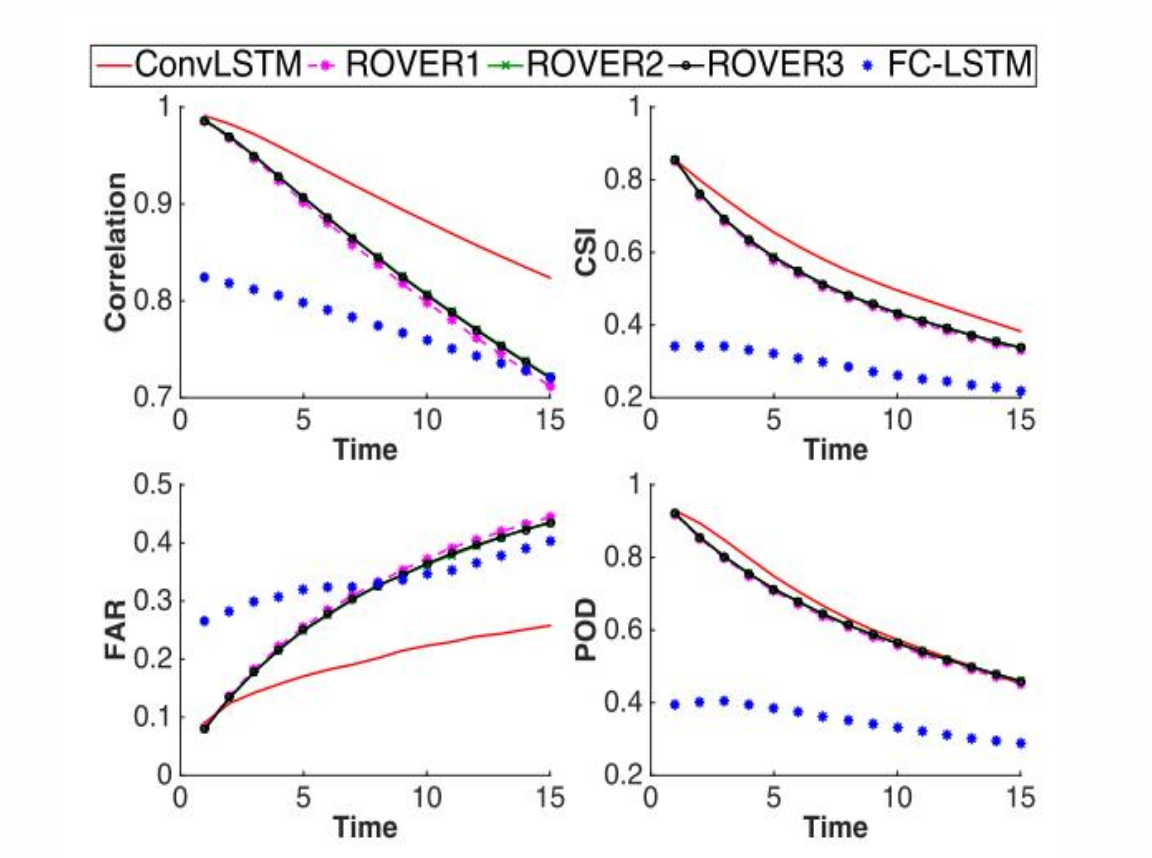
당연히 시간이 멀리 있을수록 예측은 부정확해지는데, 모든 평가에서 ROVER모델과 FC-LSTM모델을 앞서고 있다.
(Correlation: 상관분석, CSI,FAR,POD는 강수 관련 지표라 Pass )
여기서 Correlation은 Digital Image Correlation을 말한다.
'디지털 영상 상관 기법 (digital image correlation, DIC)이란 구조물의 변형 전 영상과 변형 후의 영상을 촬영고 비교하여 구조물의 변형을 계산해주는 방법이다.'
이제 본론으로..
Next-frame video prediction을 위한 Convolutional LSTM을 어떻게 build하고 train시켜야 할까?
Convolutional LSTM 아키텍쳐는 LSTM layer 안의 convolutional recurrent cell time에 의해 series processing(시계열 처리)과 computer vision을 가져온다.
아래의 예제에서 'next-frame prediction'을 위한 Convolutional LSTM model을 살펴봅시다.
http://www.cs.toronto.edu/~nitish/unsupervised_video
Setup
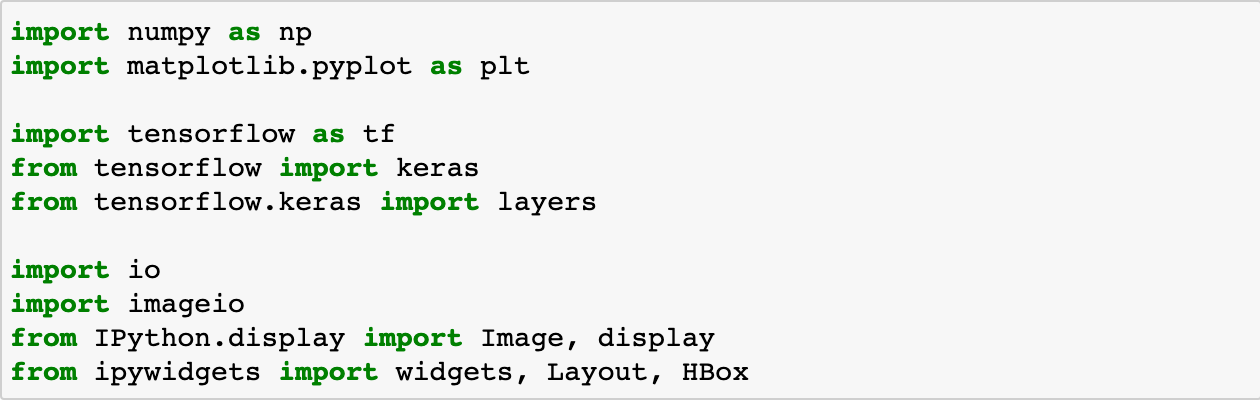
Dataset Construction(데이터 구성)
Moving MNIST data set을 이 예제에서 사용하고, 이를 다운받아
Training과 validation 셋으로 나누고 전처리를 했다.
- Convolutional LSTM의 기능과 효과를 보여주기 위해 해당 논문에서는 Moving MNIST data set을 이용한다.
Next-frame 예측하는 위해 fn이라 불리는 previous frame을 사용하여 f(n+1)인 new frame을 예측한다.
모델이 이러한 예측을 하도록 하기 위해 frame x_n인 입력과 출력이 이동되도록 데이터를 처리해야 한다. 입력 데이터는 새로운 프레임을 예측하는데 사용된다.

Data Visualization
이 데이터는 frame의 시퀀스로 구성되어 있고, upcoming frame을 예측하기 위해 사용되어진다.
Model Construction
Convolutional LSTM model 빌드를 위해 ConvLSTM2D layer사용하고, 이것으로 shape의 input과 같은 shape의 예측 무비를 리턴

Model Training
With our model and data constructed, we can now train the model.
모델과 구조화된 데이터를 가지고 모델을 학습시킨다.
Frame Prediction Visualiz
모델을 구성하고 훈련하여 새로운 영상 기반으로 몇가지 예제 frame 예측을 만들 수 있다.
Finally
Truth Prediction
Expand Thinking
Convolutional LSTM을 이용하고 있는 몇몇 연구들
- Forecasting weather(기상 예측 모델)
- Indoor behavior recognition(실내 행동 인식)
- ** 컴퓨터 비전 및 패턴 인식 문제
Ref)
- 딥러닝 기반 기상 예측 모델 연구 https://mikigom.github.io/jekyll/update/2017/06/13/deep-learning-forecast-research-1.html
Appendix
RNN
https://velog.io/@cosmicdev/RNN
LSTM
Long-Short-Term Memory
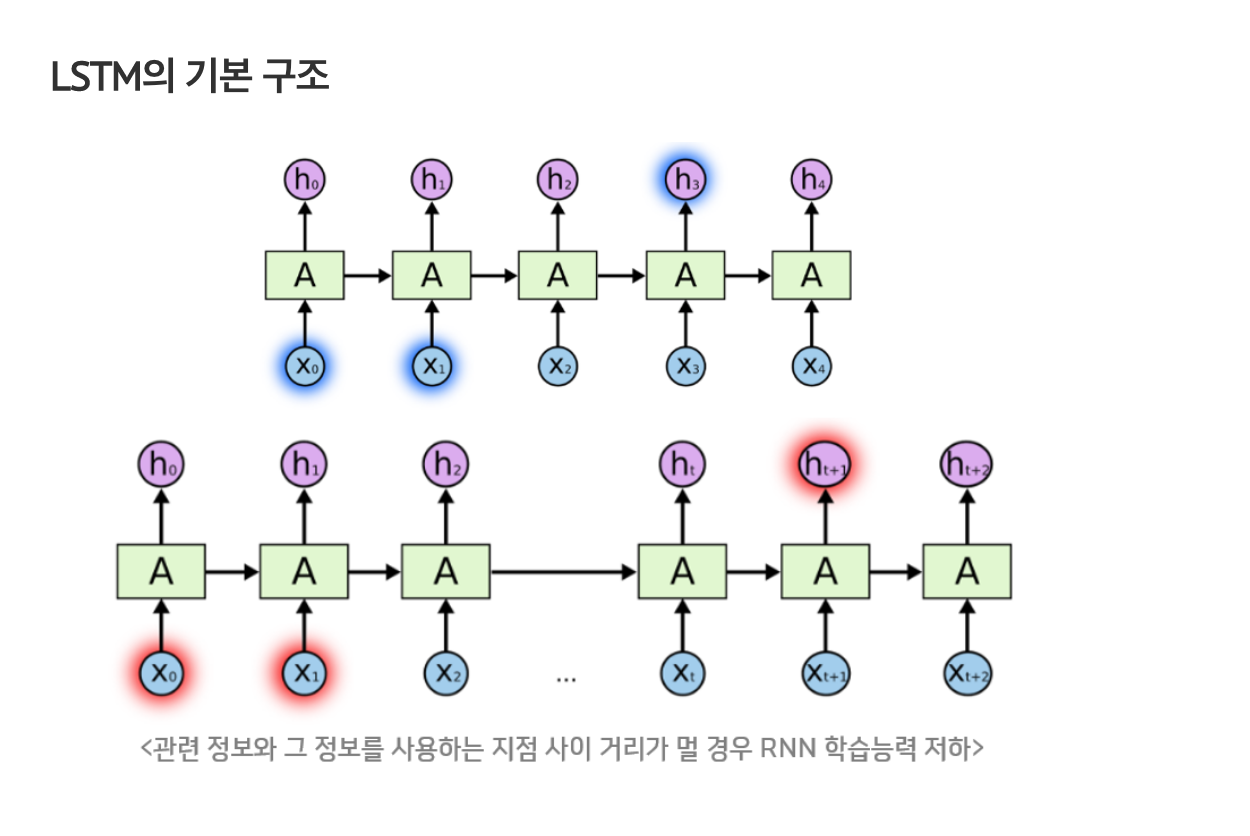
RNN은 관련 정보와 그 정보를 사용하는 지점 사이 거리가 멀 경우 backpropergation시 gradient가 점차 줄어 학습능력이 크게 저하된다. 이를 vanishing gradient problem이라 한다.
이를 극복하기 위해 나온 것이 'LSTM'으로 RNN의 hidden state에 cell-state를 추가한 구조이다.
아래 그림을 보면,
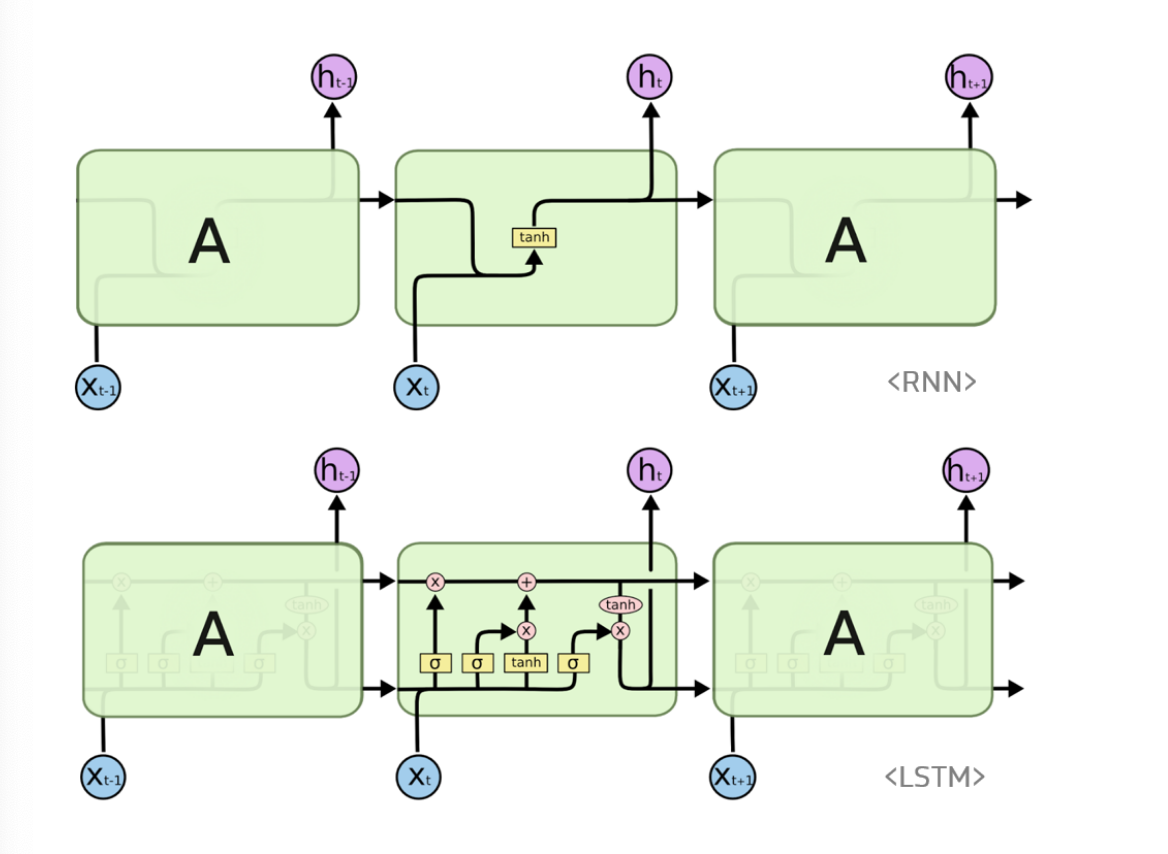
cell state는 일종의 컨베이어 벨트 역할을 하는데, state가 꽤 오래 경과하더라도 gradient가 비교적 전파가 잘 된다는 장점이 있다.
- 정리하자면 전통적인 RNN의 단점을 보완한 것이 LSTM이다. LSTM의 핵심은 cell state
Cell state는 컨베이어 벨트와 같아서, 작은 linear interaction만을 적용시키면서 전체 체인을 계속 구동시킨다. 정보가 전혀 바뀌지 않고 그대로 흐르게만 하는 것은 매우 쉽게 할 수 있다.
LSTM은 은닉층의 메모리 셀에 입력 게이트, 망각 게이트, 출력 게이트를 추가하여 불필요한 기억을 지우고, 기억해야할 것들을 정한다.
