Intro
추론 기반 기법과 wordvec.
단어를 벡터로 표현하는 방법에서 대표적으로 '통계 기반 기법'과 '추론 기반 기법'이 있다.
기존의 one-hot vector 방식의 단어 표현은 단어 간 유사도를 전혀 표현할 수 없다는 단점을 해결하기 위해 나온 단어들의 특정 차원 벡터로 만들어 주는 word embedding의 방법이다.
통계 기반 기법의 문제점
단어의 frequency를 베이스로 표현했는데, 단어의 동시발생 행렬에 SVD를 적용하여 밀집벡어(단어의 분산표현)을 얻었다. but 이 방식은 대규모 말뭉치를 다룰 때 이슈가 발생한다.
이는 현실적으로 수많은 어휘가 존재하는데 SVD를 적용하는 것은 어렵다.
(*SVD를 행렬에 적용하는 비용은 O(n^3)이다. 한 마디로 처리하기에 무리가 많다는 이야기다.)
통계 기반 기법은 학습 데이터를 한번에 처리한다.(배치 학습)
반대로 추론 기반 기법은 학습 데이터의 일부를 사용하여 순차적으로 처리한다.(미니배치 학습)
추론 기반 기법
추론 기반 기법은 맥락에서 주변 단어를 보고 빠진 부분의 단어를 추측한다. 그 과정에서 모델이 사용되는데
이 모델에서 신경망을 사용한다.
신경망에서 단어 처리
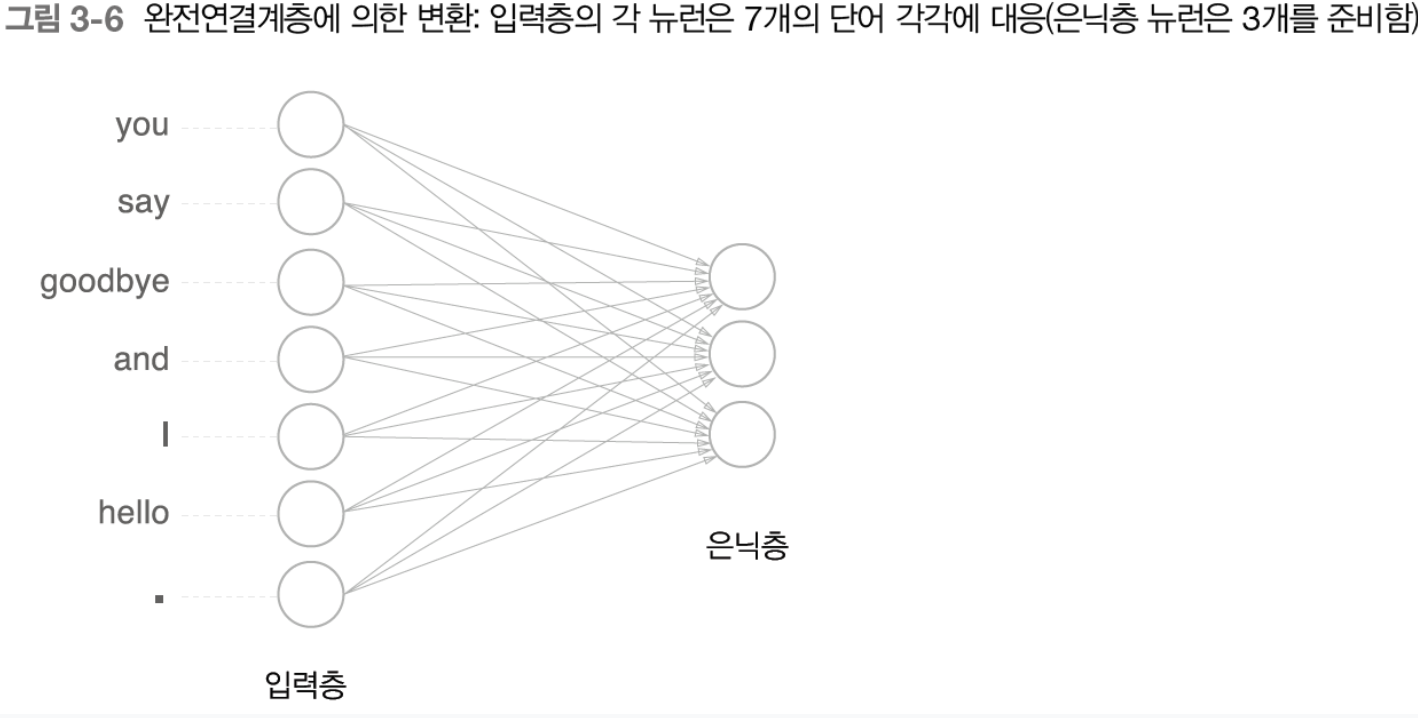
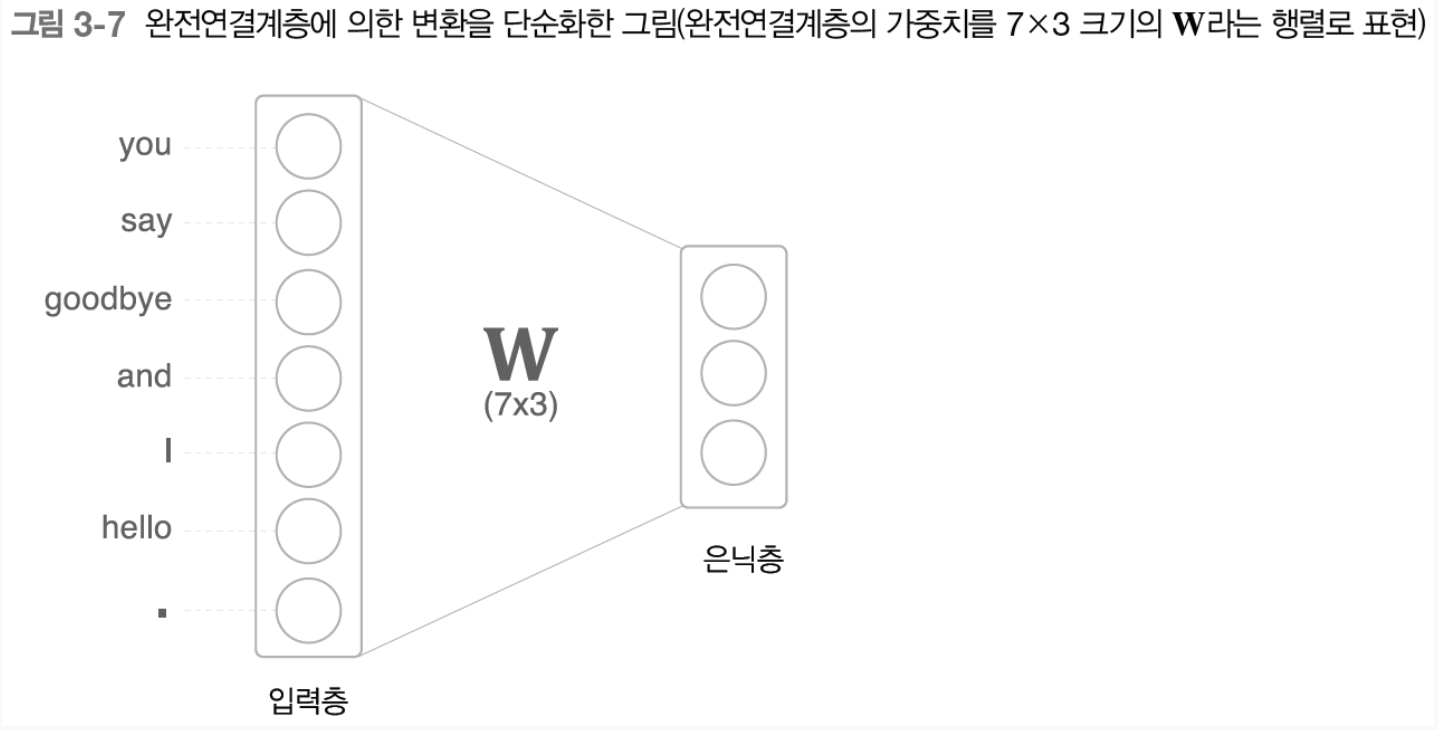
신경망은 단어를 있는 그대로 처리할 수 없어 고정 길이의 벡터로 변환 하기위해 one-hot을 쓴다.


Innovation is mine