python 'set'
set
-> 집합 자료형이다.
-> 중복을 허용하지 않는다.
-> 순서가 없다(Unordered).
실무에서 혹은 과제나 스터디용으로 파일을 다룰 때, 파일 내에 중복데이터가 생겨 곤란한 경우가 있습니다.
위와 같은 상황일 때, python의 set을 잘 활용하면 중복 제거를 구현할 수 있습니다!!
python set을 이용한 file data 중복 제거 구현😎
방법1(low data일 경우)
import csv
f = open('overlap.csv', 'w', encoding = 'utf-8')
wr = csv.writer(f)
wr.writerow([1, 'apple', True])
wr.writerow([1, 'apple', True])
wr.writerow([1, 'apple', False])
wr.writerow([2, 'banana', True])
wr.writerow([3, 'peach', True])
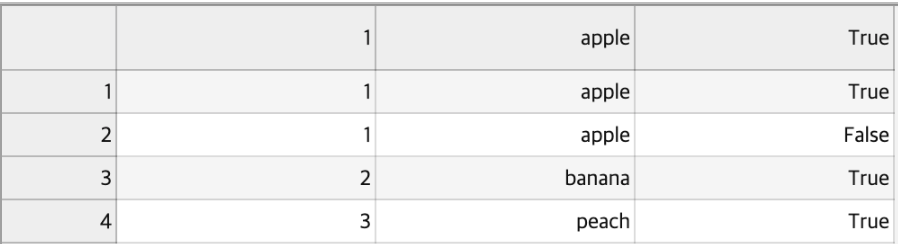
f.close()위와 같이 test용으로 csv file을 만들어봤습니다.
overlap.csv file은 첫 번째 줄과 두 번째 줄이 중복이 되는데요.
file 내용은 아래 사진과 같습니다.
lines = set()
outfile = open("out.csv","w")
for line in open("filepath/overlap.csv","r"):
if line not in lines:
outfile.write(line)
lines_seen.add(line)
outfile.close()위를 해결하기 위해 python 내장함수인 set을 이용하면 중복제거가 됩니다.
또한 set의 단점인 순서가없어진다는걸 보완해서 순서또한 지키면서 out.csv가 생기게 됩니다. out.csv의 내용은 아래 사진과 같습니다.
참고로, r mode는 read mode의 약자이며 파일을 읽기만 할 때 사용이되며
w은 write mode의 약자로 파일에 내용을 쓸 때 사용됩니다.
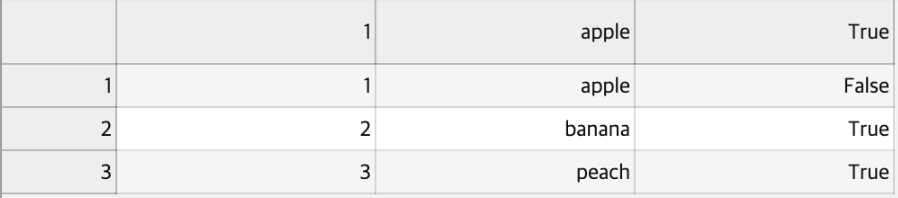
중복이 잘 제거되었으며 기존의 파일 순서 또한 지킨걸 확인했습니다.
방법2(big data일 경우)
위와 같은 방식도 좋지만 저희가 대용량 file data를 다룰 경우 file line을 한번에 한 줄씩 읽으면 경우에 따라 읽기만하는데에 몇십분, 몇시간, 혹은 그 이상이 걸릴 수도 있습니다.
이에 해결방법중으로 하나인 readlines를 소개해볼까합니다!
readlines는 제가 개인적으로 big data file을 읽을 때, 사용하는 방식입니다.
file = open('filepath,file_name','w')
file2 = open('filepaht, file_name', 'r')
lines = file2.readlines(100000) # 10만 줄을 한 번에 읽음
# user가 설정할 수 있음
lines = list(set(lines))
lines.sort()
for line in lines:
file.write(line)
file.close()
file2.close()위와 같은 방식을하면 아래와 같이 가능해집니다.
set -> 중복 제거
sort -> 정렬
readlines(num) -> 해당 숫자만큼 한 번에 read
마무리
이렇게 python에서 file data 중복 제거를 하는 방법을 알아보았습니다.
다음 python 포스팅으로는 python에서 자동으로 file directory를 생성하는 방법을 다루겠습니다.😊😊
긴 글 읽어주셔서 감사합니다!!
참고 문헌 && 자료📝
https://wikidocs.net/1015
https://docs.python.org/ko/3.7/c-api/set.html
