SQL processing은 SQL 파싱, 최적화, 행소스 생성, SQL 문장 생성으로 구성된다.
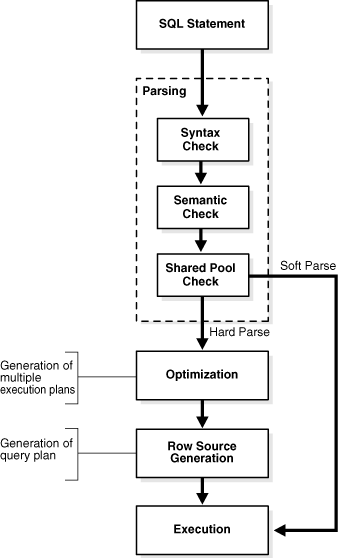
SQL 문장에 따라 몇 단계는 생략될 수 있음.
SQL Parsing
파싱 단계에선 SQL을 조각으로 나누고, 다른 루틴에서 처리할 수 있는 데이터 구조로 연관시킴.
애플리케이션이 SQL 문장을 DB에 주면, parse call이 발생한다. 그럼 DB는 SQL 문장 실행을 준비하게 된다.
Parse Call이 이뤄지면 커서를 만들거나 열게 된다. Session specific private SQL area를 다루는 용도로 사용된다.
Session specific private SQL area는 파싱된 SQL 문장과 다른 실행용 정보들을 포함하고 있음.
Parse call 동안에 데이터베이스는 문장 실행 전 에러가 있는지는 체크함. 어떤 에러는 파싱에 의해 검출되지 않음. 예를 들면, 데드락이나 데이터 변환(Conversion)에 의한 오류가 있음.
Syntax check
DB는 문장 구문의 유효성을 검증함. SQL 구문을 망가뜨리는 규칙 위반을 검사를 실패하게 함.
SQL> SELECT * FORM employees;
SELECT * FORM employees
*
ERROR at line 1:
ORA-00923: FROM keyword not found where expected위는 FROM을 FORM으로 쓰는 경우임.
Semantic Check
의미 체크 단계. 여기선 문장이 의미 있는지를 체크함. 예를들면 문장 안의 컬럼이나 개체가 존재하는지를 체크.
SQL> SELECT * FROM nonexistent_table;
SELECT * FROM nonexistent_table
*
ERROR at line 1:
ORA-00942: table or view does not existShared Pool Check
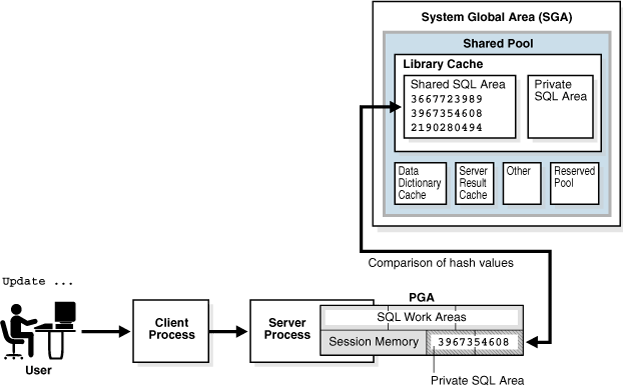
DB는 유저가 제출한 SQL 텍스트를 SQL ID로 해쉬화 함. SQL ID는 텍스트와 파싱옵션(OPTIMIZER_MODE 등)에 따라 달른 값을 가지게 됨. 일반적으로 하나의 텍스트 + 파싱옵션 당 하나의 Shared SQL Area가 생성되고, SQL ID는 이 Shared SQL Area로 매핑됨.
DB는 SQL ID를 사용해서 룩업 테이블 상의 Shared SQL Area 메모리 주소를 발견하게 됨. 동일한 SQL이라도 다른 실행계획을 가질 수 있으므로 하나의 SQL ID에는 여러개의 plan hash value가 매핑될 수 있음.
파싱 작업은 다음 두 가지 케이스로 진행됨.
-
Hard parse
만약 다시 사용할 SQL이 없다면, 새로운 실행 버전을 빌드해야함. 이 과정에서 데이터베이스는 데이터 딕셔너리를 체크하기 위해서 라이브러리 캐시와 데이터 딕셔너리 캐시를 매우 많이 접근하게 됨. 이 단계에서 DB는 '래치'라고 불리는 직렬 통신 장치를 통해서 요구된 개체에 접근함. Latch에 대한 '경쟁'은 SQL 실행시간을 증가시키고, 동시성을 감소시킴. 래치는 여러 프로세스가 동일한 개체에 접근할 때, 데이터를 보호하기 위한 lock 장치의 일종이다. 이를 통해 해당 객체가 처리되는 동안에 다른 사용자가 이 객체를 변경하지 못하게 막는 역할을 함. 정리 : Hard parse 단계에서 제출된 SQL 문을 완전히 다시 빌드하는데, 이때 이 SQL문에서 사용하는 처리 대상을 latch 라는 장치로 접근하고, 동시에 다른 사용자들이 접근하지 못하게 막음. -
Soft parse
hard parse가 아닌 모든 파싱을 의미함. shared pool에서 재사용할 수 있는 SQL을 발견한 경우, 오라클은 이 코드를 재사용 함. 이런 재사용을 library cache hit 라고 함. soft parse는 그 작업량에 따라 효율성이 달라지는데, 예를들어 세션 공유 SQL 영역을 잘 설정하면 필요한 latch의 수를 줄일 수 있음. 따라서 동시성 제어가 감소하여 더 효율적인 수행이 가능함.
-
SGA와 PGA는 다른 영역이다. PGA는 세션별 메모리 공간이다. private SQL Area가 이 안에 포함된다. PGA에는 사용자 세션이 SQL을 실행할 때 필요한 모든 임시 데이터가 저장된다. Private SQL Area는 수행중인 SQL의 Cursor 상태가 저장된다. 즉 세션에서 어떤 SQL이 실행중이며 어떻게 어디까지 읽었는지를 기록한다.
-
SGA는 오라클 인스턴스 전체가 공유하는 공간이다. 이중 Shared SQL Area는 SQL 텍스트, SQL 실행 계획들, 메타 데이터가 저장됨.
Program Global Area는 오라클 데이터베이스 서버 내부에서 각 서버 프로세스마다 할당되는 전용 메모리 영역임. Spring boot 서버가 실행된다고 PGA를 갖지 않음. 오직 Oracle 데이터베이스 서버 프로세스 내에 생성됨. Oracle DB 서버의 응용 프로그램(서버 프로세스, 백그라운드 프로세스)이 수행되는 머신의 메모리.
SQL Optimization
최적화 단계에선 오라클 DB는 적어도 한 번은 Hard parsing을 모든 유일한 DML에 대해서 수행해야 함. DDL은 최적화 되지 않음에 주의. DDL이 DML을 포함하는 경우 (create table tbl_my as select user_id, user_pw from users; ) 에는 예외적으로 적용됨.
SQL Row Source Generation
행 소스 생성 과정. 이 과정에선 Optimization 과정에서 생성된 최적의 실행 계획을 받아 iterative execution plan을 생성한다고 함. iterative execution plan은 이진 프로그램으로 결과 집합을 생성하는 기능을 수행함. SQL Engine에 의해 실행됨. iterative execution plan은 여러 단계로 이뤄져있음. 이 단계들이 행 집합을 반환함. 이 결과가 다음 단계에 제공됨. 또는 마지막 단계에서 이 결과를 SQL 문장을 실행한 응용 프로그램에 리턴해줌.
Row Source 란, 각 행들을 반복적으로 처리하는 제어 구조에 따라서 실행된 실행계획의 결과물임. 이 Row Source는 테이블, 뷰 또는 조인이나 그룹 연산의 결과가 될 수 있음.
Row source generator는 row source tree를 만들어 냄. 이 트리 구조가 row source의 모음이 됨. 이 트리는 다음 정보를 담고 있음.
- 문장에 의해 참조된 테이블의 순서
- 문장에 기술된 테이블에 접근하는 방법
- join 연산으로 붙여진 테이블을 조인하는 방법
- filter, 정렬, 집합 등의 데이터 연산
AUTOTRACE (SQL 실행시 자동으로 실행계획, 실행 통계를 확인하게 해주는 기능) 등에 의해 출력되는 실행 계획은 Row source generator 결과 출력이다.
SELECT e.last_name, j.job_title, d.department_name
FROM hr.employees e, hr.departments d, hr.jobs j
WHERE e.department_id = d.department_id
AND e.job_id = j.job_id
AND e.last_name LIKE 'A%';
Execution Plan
----------------------------------------------------------
Plan hash value: 975837011
---------------------------------------------------------------------------
| Id| Operation | Name |Rows|Bytes|Cost(%CPU)|Time|
---------------------------------------------------------------------------
| 0| SELECT STATEMENT | | 3 |189 |7(15)|00:00:01 |
|*1| HASH JOIN | | 3 |189 |7(15)|00:00:01 |
|*2| HASH JOIN | | 3 |141 |5(20)|00:00:01 |
| 3| TABLE ACCESS BY INDEX ROWID| EMPLOYEES | 3 | 60 |2 (0)|00:00:01 |
|*4| INDEX RANGE SCAN | EMP_NAME_IX | 3 | |1 (0)|00:00:01 |
| 5| TABLE ACCESS FULL | JOBS |19 |513 |2 (0)|00:00:01 |
| 6| TABLE ACCESS FULL | DEPARTMENTS |27 |432 |2 (0)|00:00:01 |
---------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("E"."DEPARTMENT_ID"="D"."DEPARTMENT_ID")
2 - access("E"."JOB_ID"="J"."JOB_ID")
4 - access("E"."LAST_NAME" LIKE 'A%')
filter("E"."LAST_NAME" LIKE 'A%')Operation에 각 이름마다 공백으로 띄어져 있는데 이런 방식으로 단계를 표현한다. 1의 자손이 2, 6 2의 자손이 3, 5 3의 자손이 4
각 노드가 row source로 동작한다. row source가 실행계획의 각 단계이며, DB에서 행을 조회하거나 다른 row source에서 행들을 입력 받는다.
우선 물리적으로 DB에서 데이터를 조회하는 row source를 식별한다. 이 row source는 접근 경로나 INDEX RANGE SCAN 같은 접근 기술 등이 된다. 각 실행 계획은 순차적으로 수행된다. 실행동안 DB는 메모리에 데이터가 없다면 디스크에서 읽어온다. 또 무결성을 유지하기 위해 lock과 latch를 사용한다. SQL 실행동안 발생한 변화를 로그로 기록한다. 처리의 마지막 단계는 커서를 닫는 것이다.
오라클 DB가 DML을 처리하는 방법
대부분의 DML 문장은 쿼리 요소이다. 쿼리에서 커서 실행 결과를 result set이라 불리는 행 집합으로 출력한다.
Row set 패치 방법
result set의 행들은 각각 또는 그룹 단위로 패치될 수 있다. 쿼리가 요청된다면 패치 단계에서 DB는 행들을 선택한다. 각각의 연속적인 패치는 마지막 행이 패치될 때까지 다른 행들을 패치해나간다.
일반적으로 DB는 마지막 행이 패치될 때까지 패치될 행들의 정확한 개수를 알 수 없다. 오라클 DB는 패치 콜에 대한 응답으로 데이터를 검색한다. 그래서 더 많은 행을 읽을 수록 더 많이 이 과정을 수행하게 된다. 일부 쿼리에 대해서는 전체 result set을 구성하는 대신에, DB가 첫번째 행을 가능한한 빨리 리턴한다.
즉, Row set은 순차적으로 패치된다. 때때로는 전체 행을 패치하는 대신 첫번째 행을 즉시 패치해준다.
읽기 일관성
Oracle DB는 데이터를 읽어올 때, 대상이 되는 데이터 블록들에 대해서 실행 시점의 데이터가 리턴되도록 보장해준다.
데이터를 읽는 과정에서 다른 세션에 의해 수정된 행을 발견하면, undo 명령을 통해 변경 전의 데이터를 읽어오게 된다. (오라클의 기본 격리 수준은 Read Committed 이다) (MySQL은 Repeatable read임. 동시성 제어에 MVCC(Multi Version Concurrency Control)를 사용하여 SQL 실행 시 당시의 상태를 스냅샷으로 저장하여 다른 트랜잭션이나 세션의 연산이 영향을 미치지 않도록 함.)
