k8s 필요 이유
성숙한 MLOps를 위해서는 3가지 작업이 필요하며 이를 쉽게 수행할 수 있는 인프라는 쿠버네티스와 같은 오케스트레이션 시스템
1. Reproducibility
2. Job Scheduling
3. Auto healing/scaling
- 학습/배포용 서버의 장애 대응 자동화
컨테이너 기반의 자원격리가 바탕이 되어야 함
여럿이서 하나의 gpu 서버를 사용하게 될 때 붐비는 시간을 제외하면 자원 누수가 많음 -> scheduling으로 worker queue에 올리고 끝나면 slack 등으로 noti를 받고 실패 시 재구동을 할 수 있음
gpu 서버 공통 사용 시 training -> serving 모든 단계에서 gpu를 소유하고 있어야 함
그러므로 training 단계에서만 gpu를 사용할 수 있게 만들어주는 것!
Kubeflow
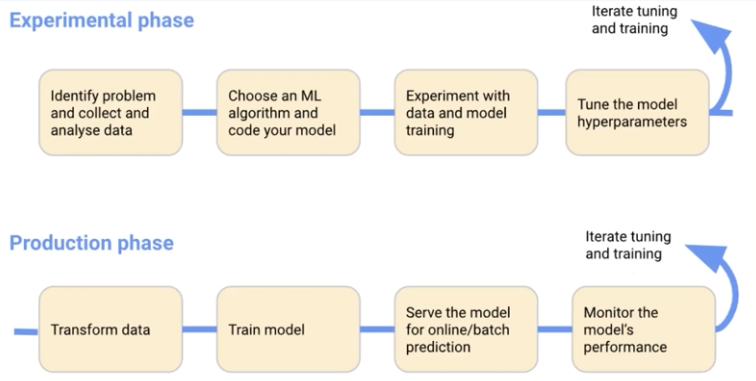
Experimental
- 문제 정의 데이터 수집
- 모델 알고리즘 연구 및 구현
- pytorch, sklearn 사용
- jupyter notebook 동적 사용
- 모델 튜닝
- Katib으로 Optuna 등을 k8s 위에서 구동 가능
Production
- 테스트데이터 전처리
- 모델 학습 및 서빙
- 퍼포먼스 모니터링
Notebook Server
컨테이너 내부 작업한 내용은 보존해주지 않음: stateless
PVC 를 활용해 mount된 경로에 작성할 수 있으므로 주의해야 함
KFServing (Kserve)
seldon core, bentoML과도 연동시킬 수 있음
특정 기능에 있어 더 좋은 툴이 있으면 변경 가능
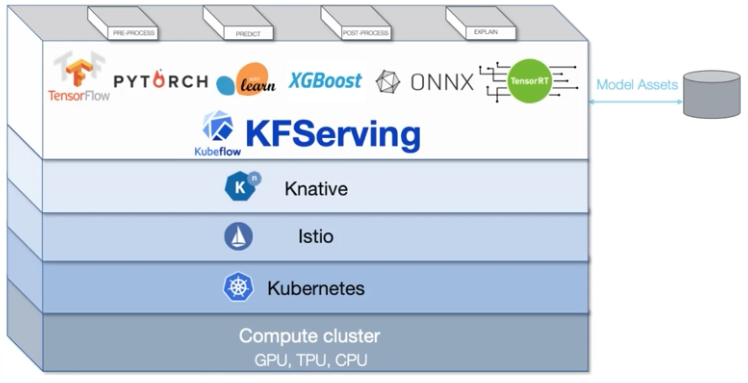
Katib
하이퍼 파라미터 튜닝 등 가능
ML Model lifecycle에서 가장 리소스를 많이 필요로하는 부분을 k8s로 자원 절약이 가능한 모듈
AutoML:= HPO + NAS 을 유저 뒤에서
Training Operators

ML training operator를 합쳐서 TO 구성요소를 만듦
Multi Tenancy
인증: Istio
인가: k8s rbac
를 기반으로 진행
UI / CLI를 거친 유저에게 제한된 자원 내에서 정해진 기능을 사용할 수 있게 구성
Pipelines
- 모델을 서빙까지 보내는데의 모든 작업을 재사용가능한 단위로 나누고, 이를 k8s 위에서 연결시켜주는 역할
Goal
- End2End Orchestration
- Easy Experimentaion
- Easly Re-Use
How to run kubeflow pipeline?
- UI
- CLI
- REST API
- Http request
- Python SDK
여러 모델과 연동시켜 사용하기 편리함
Deep Dive into pipeline
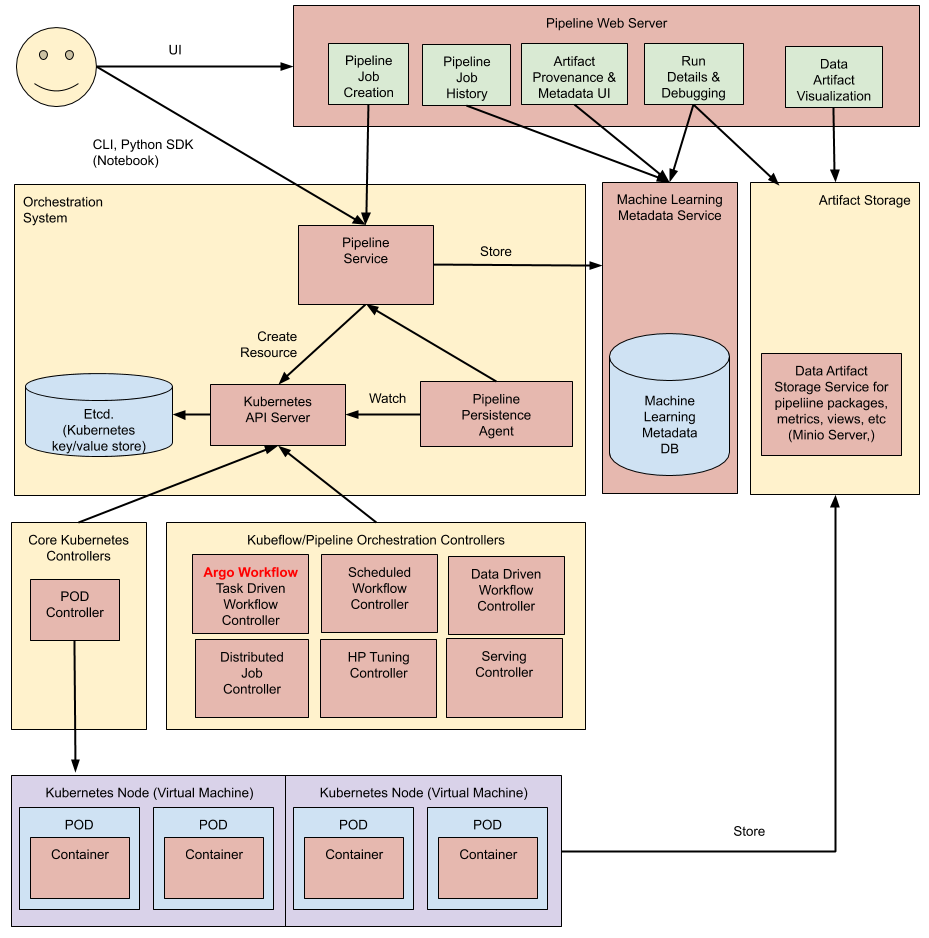
파이프라인 리소스를 중심으로 모든 동작이 수행됨
- user pipeline 생성 yaml 파일 생성
- yaml파일로 바로 pipeline service 를 실행할 수 있음
- etcd에 저장하며 해당 이벤트를 트리거 삼아 argo workflow를 create
- workflow를 구성하는 각 스텝은 최소단위인 pod로 실행됨
- 각 pod (KFP component)s는 minio에 저장됨
