논문: Practical Annotation Strategies for Question Answering Datasets
Annotation
Annotation은 주석으로 번역되는데, 내가 아는 주석은 여태껏 페이지 하단에 적힌 기술, 혹은 각주 정도였기에... 한번 찾아봤다. 근데 찾아보니 라벨링과 동일하더라
Data Annotation: What it is, Why it matters, and Implementations
Difference Between Labelling and Annotation
똑 같 다
같은 단어도 다른 의미로 사용되는데, 그게 이 두 단어를 예시로 들 수 있으며, 사실상의 차이는 없다
Text Annotation
모델 학습에서의 텍스트 이해를 돕기 위함이다. 좋은 텍스트 주석은 더 나은 유저 경험을 이끈다. 데이터 주석 프로세스 중 주석을 사용해 특정 키워드, 문장 등을 데이터 포인트에 할당한다.
정확한 모델 학습을 위해서는 포괄적인 주석이 필요하며 다음과 같은 타입이 있다.
Semantic Annotation
텍스트에 태그를 지정하는 프로세스.
semantic 주석을 통해 구조화되지 않은 텍스트에서 컨텐츠를 더 쉽게 찾을 수 있으며, 메타데이터의 특정 부분과 의미론적 주석으로 설명된 리소스 간의 관계를 해석하고 읽게 만든다.
Rihanna(person), Australia(country) 등 특정 명사가 의미하는 바를 포괄적인 태그를 붙여준다고 생각하면 될 거 같다.
Sentiment Annotation
텍스트가 내포한 감정(emotion)을 붙여 모델 학습 시에 단어를 통한 인간 감정의 이해를 이끌어 내기 위한 annotation.
한국어 영화리뷰 감정분석 데이터셋을 보면 리뷰문장과 그에 맞는 감정 ( posi/nega )이 붙어있는데, 이를 생각하면 될 것 같다 ! 긍/부정 외에도 중립도 있고 좀 더 깊숙이 들어가면 다채로운 감정이 있지만 그 예시는 패쓰
Annotation in QA dataset
(뇌피셜) 큐에이가 결국 질답이니까... 라벨링을 생각해보면... 데이터셋에서 육하원칙에 맞는 질문과 그에 대한 답을 달아주는 게 아닐까... 한다.
(오피셜)
Active Learning: 능동 학습
적은 수의 Annotated Data로 주석이 없는 데이터에 Annotation 을 수행하는 작업을 일컫는다. Annotator(인간)에게 불확실성이 높은 데이터만을 주석 요청 하여 결과를 받고, 이를 모델에 다시 넣어 재학습을 진행한다.
일련의 과정을 'Active'하다고 명명하여 Active Learning 으로 불린다.
Saturation
번역: "포화"
논문에 첨부되어있는 설명:
전체 데이터셋에서 전체 데이터셋으로 훈련된 모델 성능이 99.5%로 도달했을 때를 포화라고 정의한다.
SQuAD 훈련 세트의 서로 다른 9:1 분할 비율에 대해 훈련하고 평가할 때 우리는 약 0.5%의 표준 편차를 보였다.
하여, 본 논문에서는 전체 모델 성능의 99.5%에 도달하면 포화를 나타내고 나머지 0.5%는 학습 프로세스의 임의 변동에 따른다고 결론지었다.
Abstract
QA 태스크를 위한 Annotating (labelling, 이후 주석) 데이터셋은 고비용이며 집약적 노동과 도메인 지식이 필요하다. 하지만 아직까지는 저비용의 효율적인 주석이 추가된 QA 데이터셋을 위한 전략(기법?)은 부족하다.
본 논문은 경험적 규칙을 개발해 도메인 안팎의 성능은 유지하되 비용을 줄이고자 한다. 하여 practical recommendations의 도출을 위해 대규모 분석을 시행한다.
-
더 많은 훈련 샘플이 종종 도메인 내에서의 테스트셋 성능 향상을 도모하지만, unseen dataset에서의 일반화는 도움되지 않음을 실험적으로 설명한다
-
model-guided 주석 전략을 개발한다. 이는 어떤 샘플의 하위 집합에 주석을 달아야 하는지 고려되며 본 전략의 이점은 clinical setting에서의 QA 도메인 맞춤화를 기반으로 한 케이스 스터디에서 기술되었다.
Introduction
모델을 학습하려면 다량의 훈련 데이터가 필요하지만 실제로 데이터 가용성은 제한적이다.
사용 가능한 데이터셋은 주로 영어로 된 open-domain settings에서 비롯된다.
새로운 데이터셋에 주석을 추가하는 작업은 노동집약적 작업이며 전문 지식이 필요하고 고비용이다.
이러한 문제로 실무자에게 할당된 라벨링 가용 예산은 대규모 QA 데이터셋에 주석을 추가하는데 장벽이 되고, 여전히 비용 효율적인 방식의 전략은 부족한 실정이다.
위와 같은 이유로, 본 논문은 비용측면에서의 효율을 실무자에게 안내한다. 이를 위해 주석의 대상이 되는 질문(Q)의 subset을 제안하는 일련의 heuristic 한 방법을 개발하는 것을 목표한다.
이는 trade-off 관계를 야기한다.
주석을 적게 달수록 전체 라벨링 비용은 줄지만, 더 많은 주석은 잠재적으로 학습을 촉진시켜야 한다.(?)
(i). 답변에 주석을 추가하는 건 비용이 많이 들지만, 질문은 유저로부터 오기에 비용이 낮다.
(ii). 주석 전략은 시스템을 배포하기 전과 실제 라벨이 사용 가능하기 전에 선험적으로(priori) 사용되어야 한다.
본 논문에서는 대규모 실험을 진행하며 상기한 작업의 Practical Recommecdations를 도출한다 (Amounting to more than 300 days of computational time). 이러한 것들은 Neural QA (i.e., BERT)의 determinants of performance를 해결하고 이를 기반으로 practical 가이드라인을 설계한다.
Section Desc.
Sec. 4
데이터셋의 사이즈가 도메인 안팎 성능에 어떻게 기여하는지 확인한다.
out-domain: 데이터셋 A로 훈련된 모델로 unseen dataset B, C를 사용해 평가를 진행한다
Sec. 5
model-guided annotation 전략으로 different stratifications (다양한 계층) 을 개발한다.
Sec. 6
context diversity의 영향력을 검토한다. 예를 들어 다양한 컨텍스트 문서에 주석을 추가하는 작업의 중요성을 살핀다.
전체적으로, 이는 annotator를 계층화된 샘플의 하위 집합으로 유도하여 라벨링에 소모되는 작업을 줄이면서 도메인 내외부의 모든 데이터셋에서 원 성능을 largely 크게 유지하려는 휴리스틱 방식을 가져온다.
- 데이터셋 크기가 증가할 때, neural QA는 훈련에 사용된 데이터셋의 개선을 중단하기 전 unseen dataset에 대한 generalising-일반화를 중단했다.
(when increasing the size of a dataset, we find that neural QA stops generalizing to unseen datasets before they stop improv- ing on the dataset used during training.)
이는 out-domain 데이터셋 일반화 능력에 부정적 영향을 끼치지 않으면서 데이터셋 사이즈를 크게 줄일 수 있음을 의미한다. - model-guided annotation 전략을 따르는 데이터셋은 원 훈련 샘플의 65%만을 사용하면서 도메인 안팎의 데이터셋에 대해 동일한 성능을 달성하였다.
Related Work
QA 데이터셋의 이전 연구는 Adversarial 및 이에 따른 Manipulated sample에 따른 response에 중점적이었다.
- Kaushik and Lipton(2018)
- The Relative importance of the context
- 컨텍스트 없이 직접 답변할 수 있는 질문의 수를 조사했다.
- Sugawaraet al. (2018)
- hard와 easy로 나누어 분류된 벤치마크 내 질문의 비율을 계산했다
- 유사성과 엔티티 유형 휴리스틱을 기반으로 진행 ( Similarity and entity type heuristics )
- (Talmor and Berant, 2019; Fisch et al., 2019)
- QA 데이터셋의 일반화 능력을 연구했다.
- i.e. 하나의 데이터셋으로 훈련된 모델이 unseen datasets에 일반화 되는 방식
이전 작업에서는 도메인 내외의 성능이 데이터셋 사이즈에 어떻게 영향을 받는가에 대한 질문이 무시되었다. 이러한 이유로 성능을 유지하면서 라벨링 노력을 줄이기 위해서는 어떤 데이터 샘플의 subset이 annotated되어야 하는지 불분명했다.
본 논문에서는 Active Learning 에 기반을 두면서, assuming an unlabeled pool of resources for which we can request labels in every iteration.
본 논문에서의 방식은 라벨이 지정되지 않은 샘플 풀에서 하위집합을 추론한다.
Experimental Setting
Total Computation Time: 300 days with 7 GPUs
Dataset:
(i) SQuAD(Rajpurkar et al., 2016)
(ii) NewsQA(Trischler et al., 2017)
(iii) HotPotQA(Yang et al., 2018)
(iv) TriviaQA(Joshi et al., 2017)
Model:
BERT(Devlin et al., 2019)
Experimental Design
훈련 샘플 개수에 따른 성능에의 영향력을 조사하기 위한 데이터셋 와,
훈련 시 사용하지 않았던 (unseen dataset) 데이터셋에 대한 일반화에 어떻게 미치는지 조사한다.
실험 단계
1. 처음에 데이터셋 의 트레이닝 데이터셋 중 인 무작위 샘플에 대해 BERT 모델을 훈련합니다.
2. Train 후, 데이터셋 의 hold-out 부분에 대한 성능을 평가합니다.
3. 일반화 능력을 평가하기 위해 훈련에 사용하지 않은 데이터셋의 테스트셋에 대한 성능도 평가합니다. i. e.,
4. 훈련 샘플의 수를 b만큼 늘린다.
- 다음 의 모든 학습 데이터가 사용될 때까지 2 ~ 4를 반복한다.
에서 훈련 모집단으로부터 questions 성능을 측정하는 반면 에서는 unseen 데이터셋에 대한 성능을 측정하며 일반화하는 작업을 되풀이한다.
다음 3개의 섹션에서 설명하는 실험은 실험 4단계에서 샘플을 선택하는 방법의 차이가 있다.
e.g. randomly vs by context diversity
세 번의 개별적인 실행에 걸쳐 모든 결과를 평균지었다.
How does the Size of a Dataset Impact Performance and Generalization?
훈련 중 사용된 샘플 수는 성능에 어떻게 미치는 영향을 조사한다. 이를 위해 training-set size 함수로 performance를 반환하도록 실험을 설정했다. 이는 데이터셋 간의 비교 시 항상 적용된다.
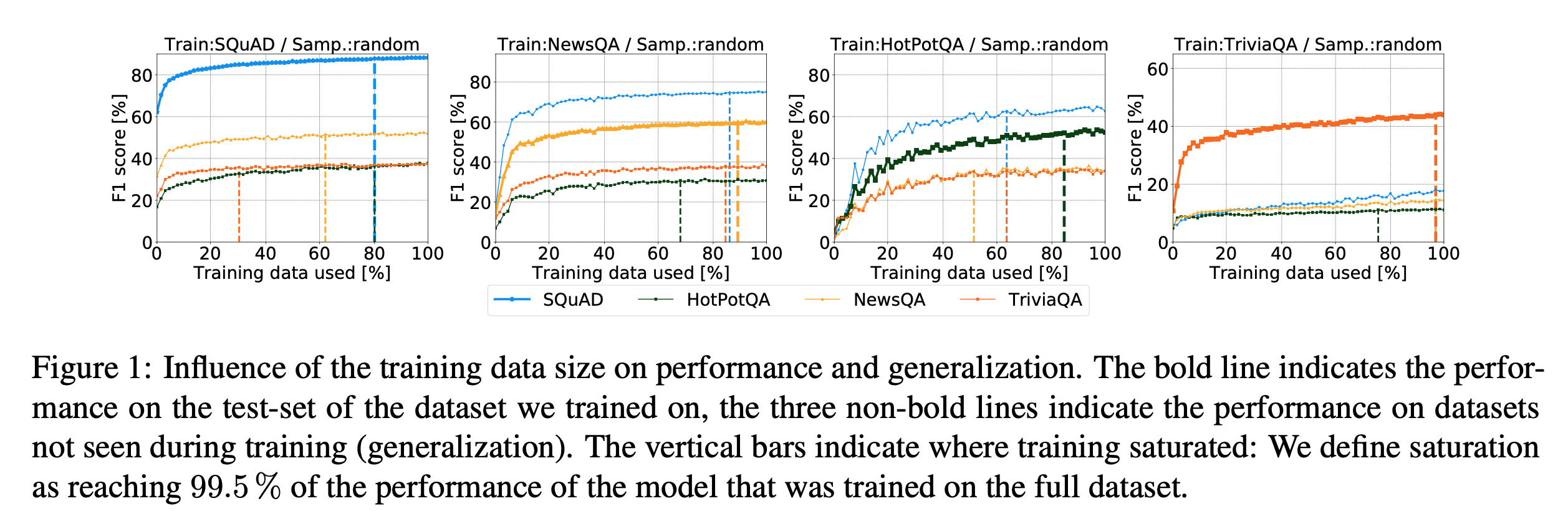
fig1 그래프 내의 수직선은 훈련이 포화되는 위치를 나타낸다(training saturated).
포화는 전체 데이터셋에서 훈련된 모델 성능이 99.5%에 도달했을 때로 정의된다.
즉, 모델이 학습을 멈출 때 힌트를 준다.
결과:
(1) 에서의 성능
SQuAD, NewsQA 및 HotPotQA의 경우, 훈련 샘플의 약 85-90%가 모델 학습 시 자체 테스트셋에서 포화에 도달하기위한 충분한 데이터였다. 이보다 많은 샘플을 추가한다고 해서 성능에 큰 변화를 일으키지는 않았다.
(2) 로의 일반화
이전과 비교하여 일반적으로 이전에 훈련에서 볼 수 없었던 데이터 세트(즉, 일반화 능력)에 대한 성능이 포화됩니다. 종종 모델은 훈련 데이터의 30%만 사용한 후에, 보이지 않는 데이터셋에 대한 일반화를 중지합니다.
(3) TriviaQA의 경우
훈련 세트의 포화와 보이지 않는 세트에 대한 일반화 모두 매우 늦게 도달합니다.
TriviaQA는 실험 데이터 중 유일하게 Distant Supervision을 통해 주석이 추가되었으며, 나머지 3개의 데이터셋은 수동으로 주석이 추가되었다.
이런 차이점으로 인해 발생할 가능성이 높다.
또한, TriviaQA는 다른 데이터셋에도 잘 일반화되지 않았다.
(cf. TriviaQA에서 훈련되었을 때 세 개의 다른 데이터 세트의 최종 성능).
Recommendations
neural QA 모델은 훈련 중 사용된 데이터셋이 포화되기 전에 unseen dataset에 대한 일반화를 중지한다. 이러한 이유로 더 큰 데이터셋은 거의 도움이 되지 않는다.
일반화와 포화 사이의 격차는 현재의 개방형 도메인 QA 데이터셋이 성능에 영향을 미치지 않으면서 데이터셋의 사이즈를 크게 줄일 수 있다는 강력한 증거를 제공합니다.
본 연구에서 주석의 품질이 높은 데이터셋이 더 빠르게 포화되며 더 잘 일반화됨을 발견했다. (manual vs distantly supervised annotation)
따라서 실무자는 먼저 테스트 샘플에 주석을 달고 해당 테스트셋의 포화가 관찰되면 데이터 주석을 중지함으로써 일반화 가능성의 하락에 직면하지 않고 라벨링 노력을 절약할 수 있다.
How Does a Stratified Annotation Help Learning?
이전에는 주석에 대한 질문 선택이 무작위였으나, 현재는 Active Learning에서 계층화된 접근 방식을 실험한다. 따라서 계층화된 Annotators가 주석이 얼마나 도움이 되는지에 대한 추정치를 보여줌으로써 더 빨리 포화 상태에 도달할 수 있는지 테스트하게 된다.
본 논문에서는 두 가지 모델 기반 주석 전략을 설계한다.
Question Difficulty
첫 번째 전략
- 적절한 의미(Semantics)를 배우지 않고 간단한 질문에 대답할 수 있다는 아이디어 기반
- e.g. 컨텍스트 문서에 언급된 엔티티가 하나만 있을 때, "누가" 무엇을 했는지에 대한 질문
모델은 전체 질문의 의미를 학습할 필요는 없다. 본 논문에서는 모든 샘플에 대한 답을 두 번 예측하며 이런 질문에 대한 답변을 예측한다.
한 번은 완전한 질문 q를 사용하고 한 번은 q의 처음 세 단어만 사용합니다.
둘 다 예상 답변이 같으면 질문이 쉬움으로, 그렇지 않으면 어려움으로 라벨을 붙인다. 그런 뒤 처음에는 어려운 것으로 레이블이 지정된 질문을 샘플링하고, 이후에는 쉬움으로 레이블이 지정된 질문만 샘플링한다.
Model Uncertainty
모델 불확실성은 Shannon의 엔트로피에 의해 포착된다. 구체적으로 context document 내에서 질문에 대한 답변 범위를 예측하고, 답변에 대한 시작 및 종료 예측의 엔트로피를 평균화합니다. 모든 반복에서 모델 불확실성이 가장 높은 샘플을 선택한다.
Result
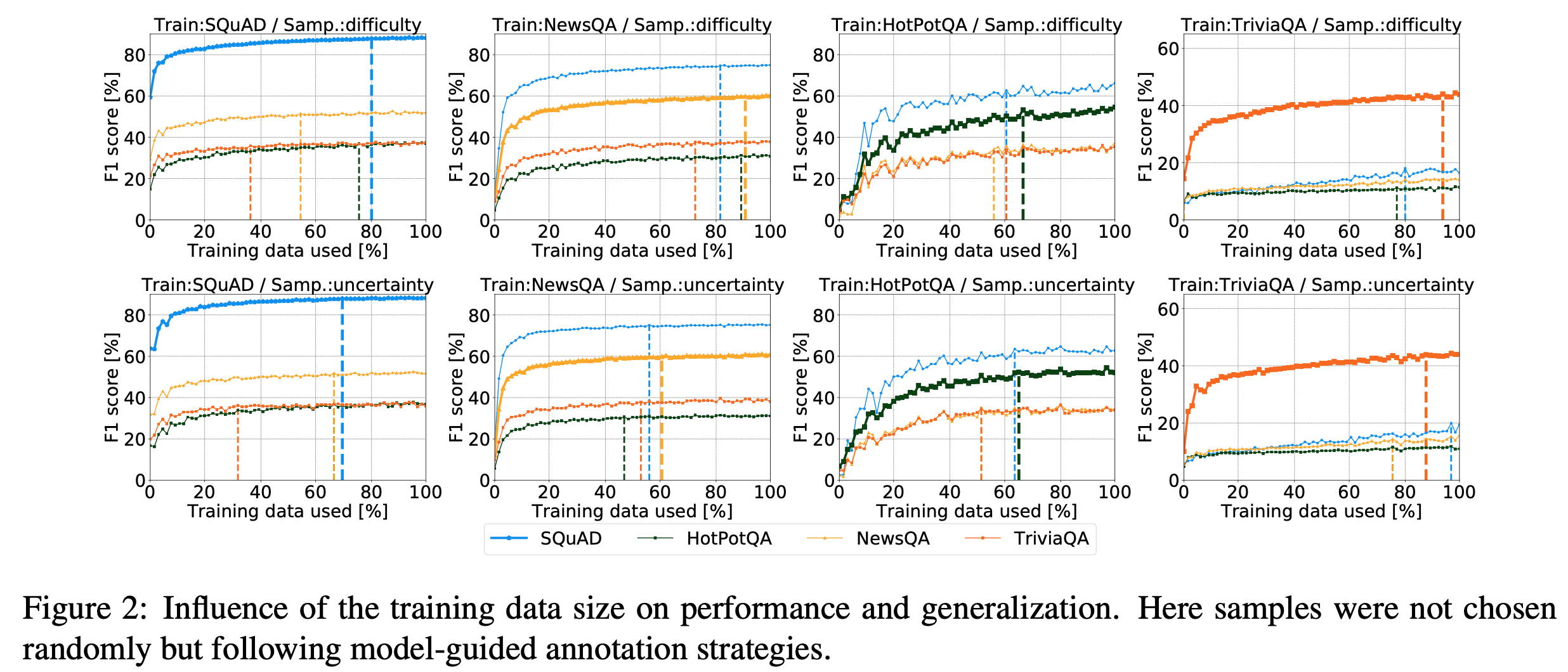
(1) 질문 난이도 샘플링: Fig 2.
Fig 1의 무작위 샘플링 방식과 비교할 때 훈련 데이터 세트의 포화도가 향상되었다.
평균적으로 포화는 4.9% 더 적은 샘플을 사용하고 9.5% 더 적은 수의 일반화를 사용하여 도달한다.
(2) 모델 불확실성 샘플링: 포화와 일반화 모두에 긍정적인 영향
구체적으로 무작위 샘플링보다 훈련 데이터셋에서 포화시키기 위해 약 16.9% 더 적은 데이터가 필요하고, 다른 데이터셋에서는 포화하기 위해 약 10.2% 더 적은 데이터(일반화)가 필요하다.
TriviaQA의 경우, 실측 주석이 상당히 fairly noisy하다고 알려져 있기 때문에 결과가 더 좋지 않다.
Recommendations
위의 Annotation 전략은 훈련 데이터셋와 다른 데이터셋의 포화도에 도달하는 지점 사이의 간격을 줄인다. 실제로 이러한 전략은 계산하기 쉽고 모델에 따라 유연하게 적용될 수 있다.
또한 주석 품질 추정치를 제공하기 위해 주석 작성자에게 즉시 표시될 수 있습니다. (?)
따라서 실무자는 이 전략은 훨씬 적은 수의 샘플로 원본 데이터셋과 unseen dataset 모두 동일한 성능 수준에 도달하는 데 도움이 되기 때문에, 모델 기반 주석 전략(특히 불확실성 샘플링)을 사용해야한다.
What is the Benefit of Annotating Diverse Contexts First?
Robuseness check으로 다양한 컨텍스트 문서에 주석을 다는 이점이 있는지를 평가한다.
이 분석은 SQuAD 및 NewsQA를 사용하여 단일 컨텍스트 문서에 대한 여러 질문-답변 주석이 포함되어 있는지를 확인한다.
이를 통해 (i)무작위 샘플링과 (ii)컨텍스트 문서 샘플링의 두 가지 샘플링 전략을 비교한다. 라운드 로빈 방식이 모든 컨텍스트 문서를 먼저 샘플링하는 데 사용되는지 여부입니다. (???)
Results
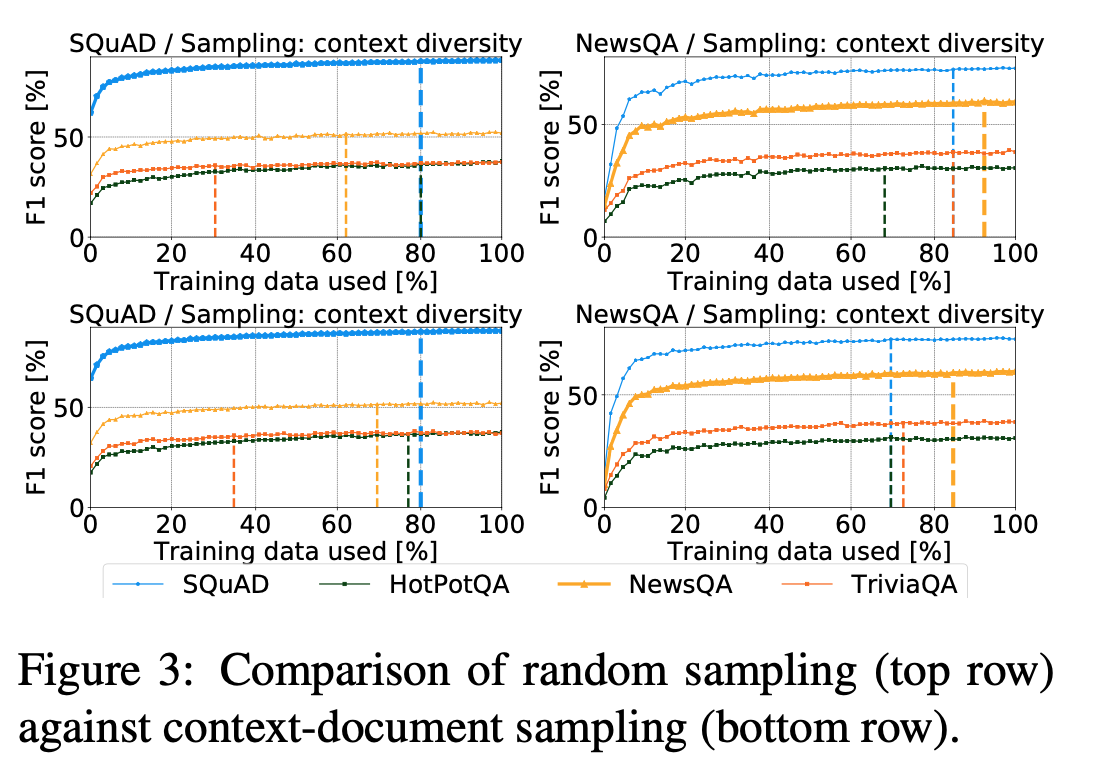
NewsQA의 경우 더 다양한 컨텍스트로 질문을 샘플링하면 포화와 일반화 모두에 이점이 있었고, SQUAD의 경우 개선 사항을 거의 관찰할 수 없습니다.
하지만 성능 향상은 모델 기반 주석 전략만큼 중요하지 않습니다.
두 결과 모두 데이터셋 특성으로 설명된다.
- NewsQA: 다양한 주제와 작성자 스타일을 다루는 주석이 달린 신문 기사로 구성
- SQuAD: 컨텍스트 문서는 주로 소규모 Wikipedia 기사 세트에서 추출한 단락으로 제공
Recommendations
다양한 문서가 있는 말뭉치의 경우 주석은 다양한 컨텍스트 문서셋로 나누어져야 합니다.
이는 단일 문서에 대해 여러 질문-답변 쌍에 주석을 추가하는 고전적인 접근 방식보다 우세할 수 있다. 이는 Case Study에서 더욱 입증되었다.
Case Study: Clinical QA
위 권장사항의 가치는 도메인별 설정을 기반으로 설명된다. 이를 위해 Clinical (이하 임상) QA, 특히 emrQA 데이터셋(Pampari et al., 2018)을 사용합니다.
본 데이터셋은 전자 의료 기록의 임상 노트와 함께 대규모 QA 데이터셋(약 100만 QA 쌍)를 제공한다.
본 논문에서는 DocReader를 기반으로 구현한다. (자세한 설명은 appendix)
본 논문은 다음과 같은 4가지 주석 전략을 통해 위의 권장 사항을 설정했다.
( 다양한 컨텍스트 문서에 주석을 달고 고품질의 질문 선택하는 방법 )
(1) Conventional Sampling: 148개 문서에 대해 컨텍스트 당 50개 질문에 주석을 단다.
(2) Context Document Sampling: 컨텍스트 당 25개의 질문에 주석을 달지만 296개의 개별 문서를 사용한다.
(3) Model Uncertainty: 엔트로피를 사용해 가장 높은 모델 불확실성을 갖는 컨텍스트 당 25개의 질문에 주석을 단다.
모든 전략은 약 7,500개의 주석이 달린 샘플을 생성한다(원래 훈련 데이터의 약 1.2%).
비교를 위해 약 620,000 QA 쌍의 전체 교육 데이터에 주석을 달 때의 성능을 나타내는 (4) FULL DATASET을 나열합니다.
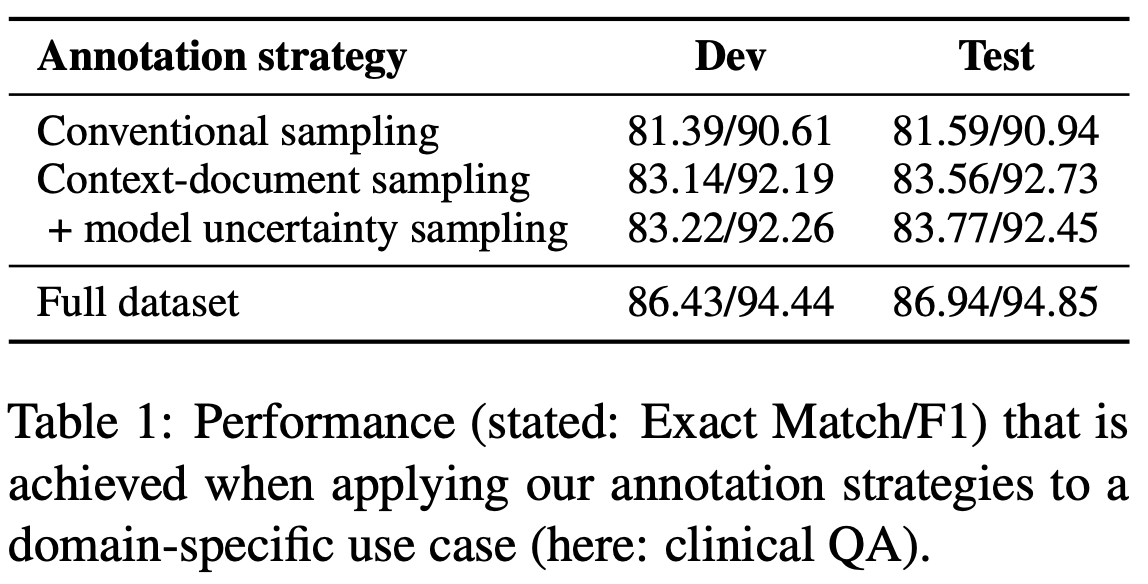
Context Document Sampling 전략은 Conventional Sampling보다 성능이 우수하므로, 보다 다양한 컨텍스트 문서 셋에 주석을 달면 얻을 수 있는 이점이 있다. ( Table 1에서 Dev, Test 둘 다 모두 우수함 )
Model Uncertainty를 기반으로 한 Context Document Sampling 전략을 사용하면 성능이 더 향상된다.
본 논문의 Annotation 전략은 놀라운 성능을 달성하는 compact dataset을 산출한다.
실제로 전체 데이터셋에 주석을 달 때, 데이터의 1.2%는 최대 97.7%의 성능 수준에 도달하기 충분하다.
