Abstract
-
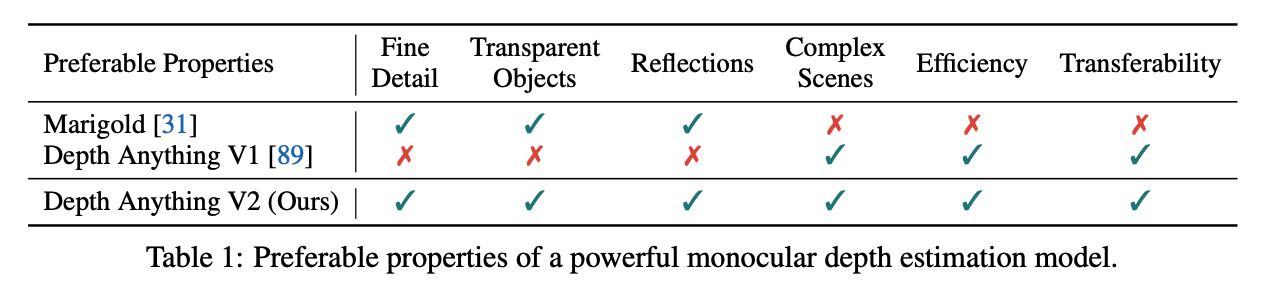
V1과 비교했을 때, 3가지에 초점을 둠
-
labeled real data를 synthetic images로 변경
-
teacher model의 capacity 증가
-
student model 을 pseudo-labeled real images로 teaching
-
-
기존 모델들 보다 훨씬 효율적이며 효과적
Introduction
-
MDE(Monocular Depth Estimation)은 크게 Discriminative, Generative Model로 나뉨
-
위 사진( 위 Generative, 아래 Discriminative)를 참고해 봤을 때, Depth Anything V2에서는 다음과 같은 목표 설정
-
: produce robust predictions for complex scenes, including but not limited to complex layouts, transparent objects (e.g., glass), reflective surfaces (e.g., mirrors, screens)
-
contain fine details (comparable to the details of Marigold) in the predicted depth maps, including but not limited to thin objects (e.g., chair)
-
provide varied model scales and inference efficiency to support extensive applications
-
be generalizable enough to be transferred (i.e., fine-tuned) to downstream tasks
-
-
중요한 것은 다른 특출난 기술이 아니라 데이터였다는 것을 깨달음
Q1: fine details를 위해 꼭 generative(heavy diffusion-based model)을 채택해야 하나?
A1: 그렇지 않다. All labeled real images를 precise synthetic images로 바꿈으로써, 가능하다.Q2: 그렇다면, 이전 모델들은 왜 synthetic images를 사용하지 않았던가?
A2: synthetic images에는 패러다임에서는 해결 못할 문제들이 많았다.Q3: synthetic images의 단점을 피하고, 장점을 극대화하는 방법은 무엇인가?
A3: 오로지 synthetic images로만 훈련된 teacher model을 구축하고, student model을 pseudo-labeled real images로 teach한다.
Revisiting the Labeled Data Design of Depth Anything V1
- Depth Anything V1을 포함한 과거 연구에서, labeled real data의 scale을 키우는 데에만 집중했었다. 이것이 정말 도움이 되는가?
Two disadvantages of real labeled data
- labeled data는 정확하지 않으며, 많은 noise가 포함되어 있다.
- 디테일이 무시된다.

Advantages of synthetic images
-
세세한 디테일을 잘 살릴 수 있음
-
투명, 반사되는 물체에 대해 정확한 GT 그 자체를 얻을 수 있고, 윤리적인 문제 없이 빠르게 확장 가능
Challenges in Using Synthetic Data
-
제아무리 요즘 그래픽 기술들이 뛰어나다 해도, real image와 synthetic image는 확연한 차이가 있다. 전자는 randomness를 포함하는 반면, 후자는 더 정교하고 세밀하다.
-
scene에 제한이 있다. synthetic images는 living room, street 등 pre-defined fixed된 scene에 국한된다.
Therefore, synthetic-to-real transfer is non-trivial in MDE
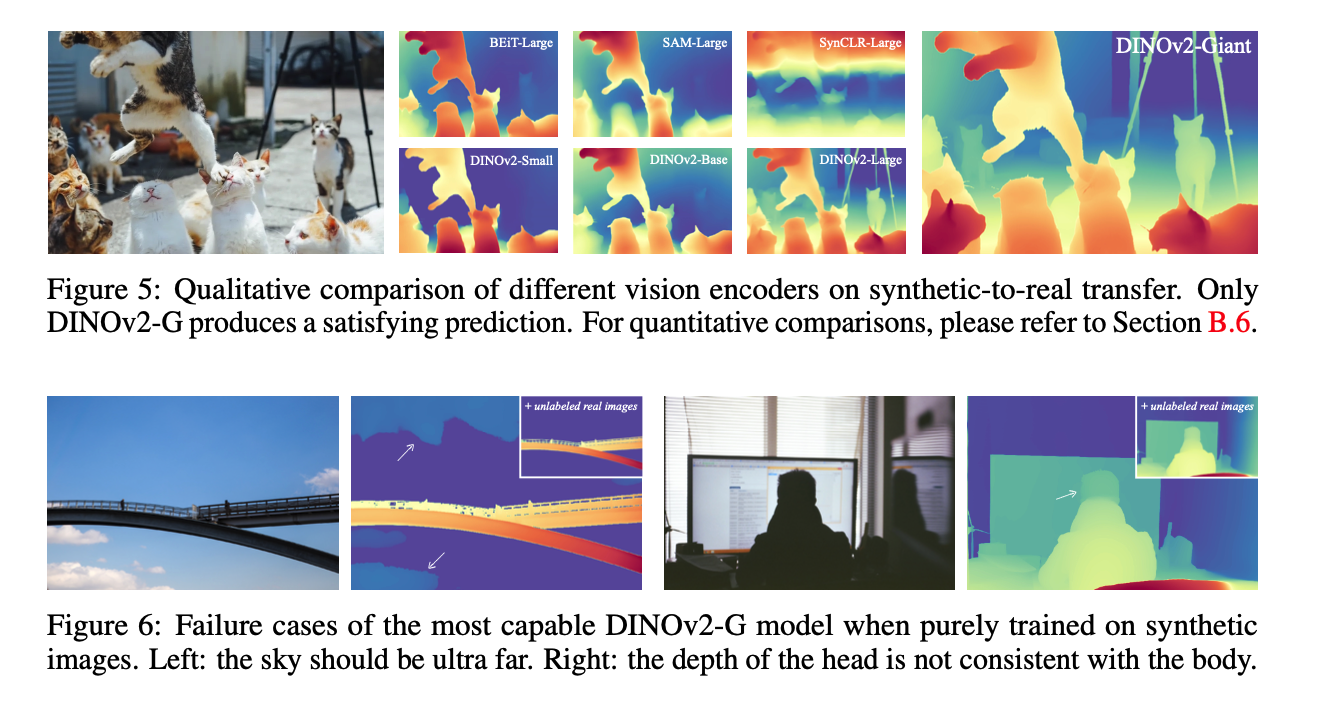
위 사진은 synthetic images 로만 훈련된 모델의 출력 결과이다. 모델이 견고하지 않음이 확인된다.(synthetic images로는 사람의 얼굴 디테일이나, 구름의 디테일 학습이 쉽지 않기 때문)
*Key Role of Large-Scale Unlabeled Real Images
해결책: DINO-G에 기반한 MDE 모델을 오로지 고퀄리티의 synthetic images로 학습, 후에 unlabeled real images와 pseudo depths labels를 할당받는다.
마지막으로, large-scale and precisely pseudo-labeled images로만 훈련을 진행한다.
Importance of Larege-Scaled Unlabeled Real Data
-
Bridge domain gap
-
Enhance scene coverage
-
Transfer knowledge from the most capable model to smaller ones
Depth Anything V2
Overall Framework
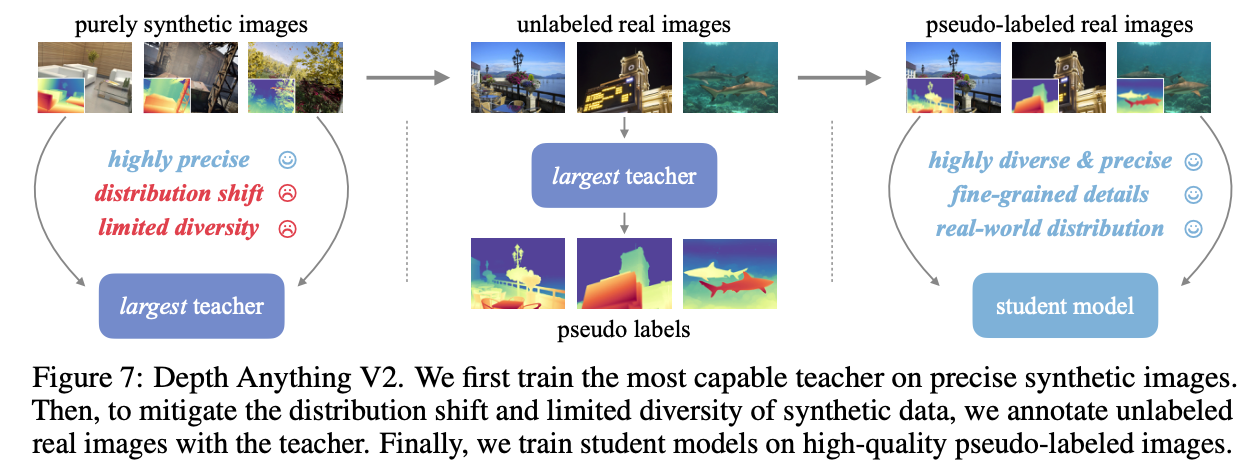
DINOv2-G 기반 모델을 고품질 synthetic images로 훈련
훈련된 모델로 대규모 real imagese들의 pseudo-label 생성
student 모델을 이 데이터들로 학습
학습과정
loss가 높은 상위 10% 영역 무시, affine-invariant inverse depth 생성
최적화를 위해 scale shfit invariant loss 와 gradient matching loss 사용
