지난 글에서 스케일 업(Scale-Up), 스케일 아웃(Scale-Out)에 대해 다뤘고 진행하는 프로젝트에 스케일 아웃 방법을 적용한다고 하였다.
단일 서버를 운용하는 경우에는 세션을 통해 로그인 기능을 구현할 때 세션 불일치 문제를 신경쓸 필요가 없었지만 스케일 아웃을 선택함에 있어 발생할 수 있는 세션 불일치 문제에 대해 다뤄보려고 한다.
세션 불일치가 뭐야?
여러 대의 서버를 운용하면서 분산을 할 때, 각 서버에 세션을 저장하다 보니 클라이언트의 요청이 다른 서버로 요청이 갔을 경우 요청에 맞는 세션 데이터를 찾을 수 없는 상황이다.
그림으로 더 쉽게 알아보자.
- 서버를 총 3대 운영 중이고 로드밸런서로 트래픽을 분산해서 운용 중이다.
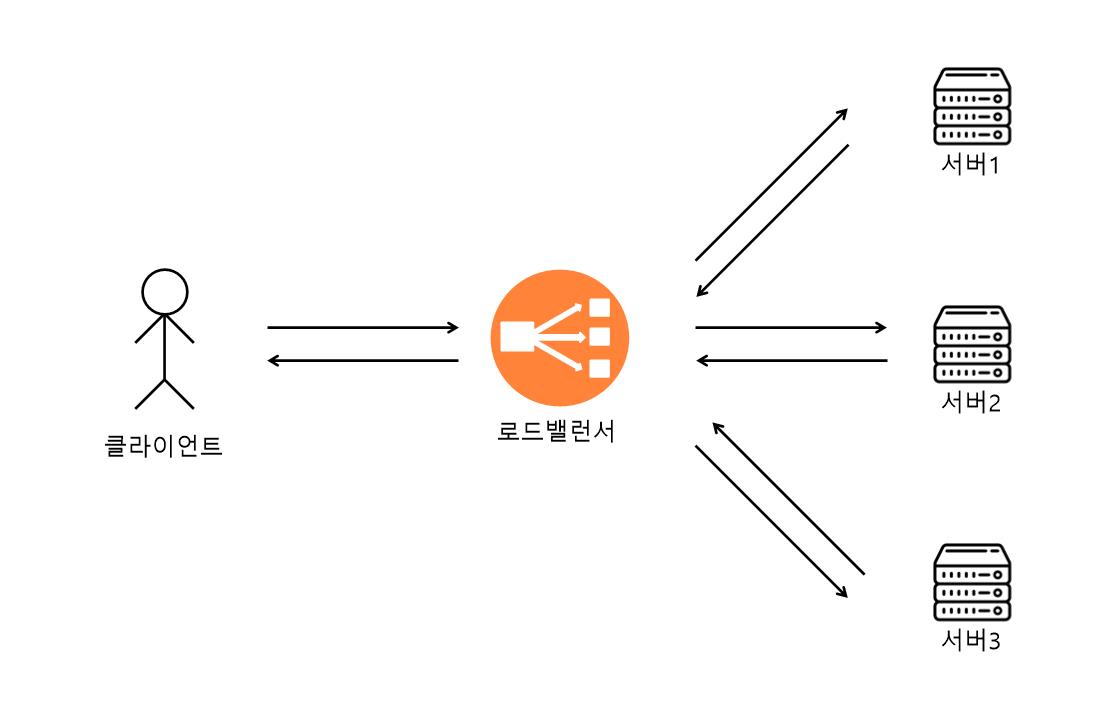
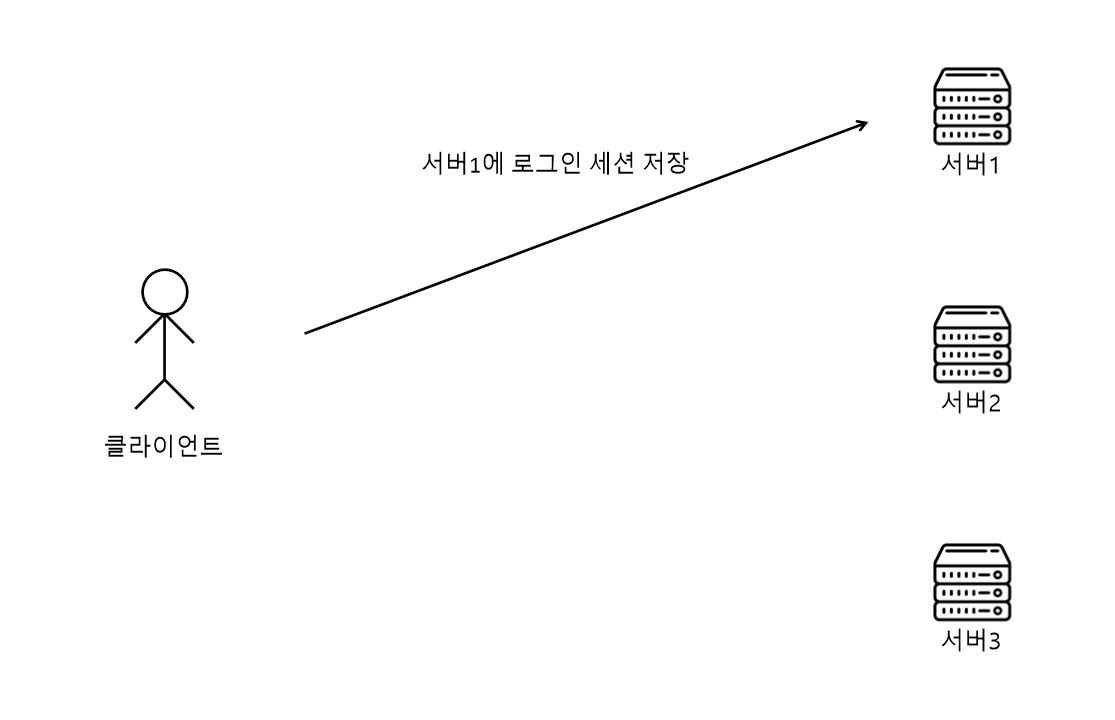
- 사용자가 로그인을 하고 로그인 세션은 서버1에 저장되었고 서버2, 서버3에는 사용자가 로그인한 로그인 세션은 없다.
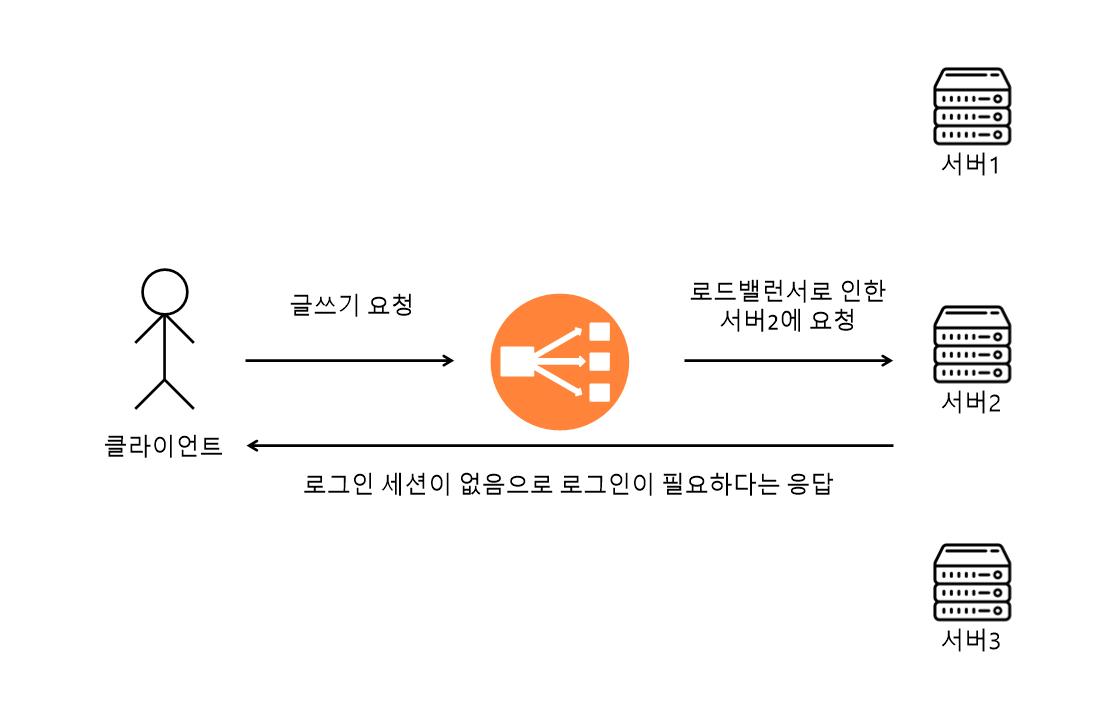
- 2번에서 로그인 한 사용자가 글쓰기를 요청했는데 로드밸런서에 의해 서버2에 요청이 들어갔고, 서버2에선 로그인 세션이 없기 때문에 로그인이 필요하다는 응답을 보냈다.
* 로드밸런서(Load Balancer) : 클라이언트와 서버풀 사이에 위치하며, 한 대의 서버로 부하가 집중되지 않도록 트래픽을 관리해주는 서비스
더욱 편한 방법으로 서버를 운용하려고 했는데 로드밸런서 알고리즘에 의해 사용자가 로그인을 유지하지 못하는 현상이 발생한다.
세션 불일치를 해결하기 위해선?
위에서 봤던 세션 불일치를 해결하기 위해선 3가지의 방법이 있다.
먼저 Sticky Session부터 살펴보자.
1. Sticky Session
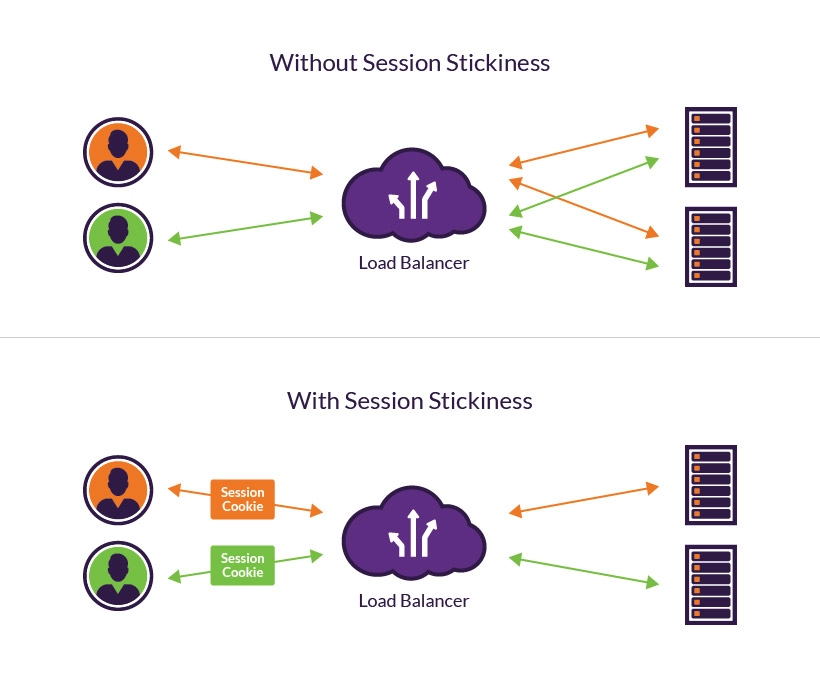
Sticky Session은 클라이언트에서 요청을 보냈을 때 최초로 처리해준 서버로만 세션을 사용하는 방식이다.
처리 과정은 이렇다.
- 클라이언트가 로드밸런서를 통해 서버에 요청을 보낸다. 로드밸런서는 서버들 중 하나를 선택하여 요청을 처리한다.
- 서버가 응답을 보낼 때 자신을 식별할 수 있는 서버ID를 쿠키에 담아 클라이언트에 보낸다.(최초 요청한 서버 정보)
- 이후 클라이언트가 재요청 시 서버ID를 쿠키와 함께 보내고 로드밸런서는 쿠키 정보를 확인하고 쿠키에 서버ID가 생성되어 있으면 그에 맞는 서버로 보내지게 된다.
장점은?
동일한 사용자가 서비스를 이용할 때 해당 서버에 지속적으로 요청, 응답이 이루어지기 때문에 클라이언트와 서버가 서로 연결을 유지할 수 있다.
단점은?
가장 큰 단점은 특정 서버에 트래픽이 집중되는 문제이다.
이렇게 된다면 스케일 아웃의 장점인 서버의 가용성을 최대한 활용하지 못하는 상황이 발생하고 서버 장애가 발생할 수 있다.
2. Session Clustering
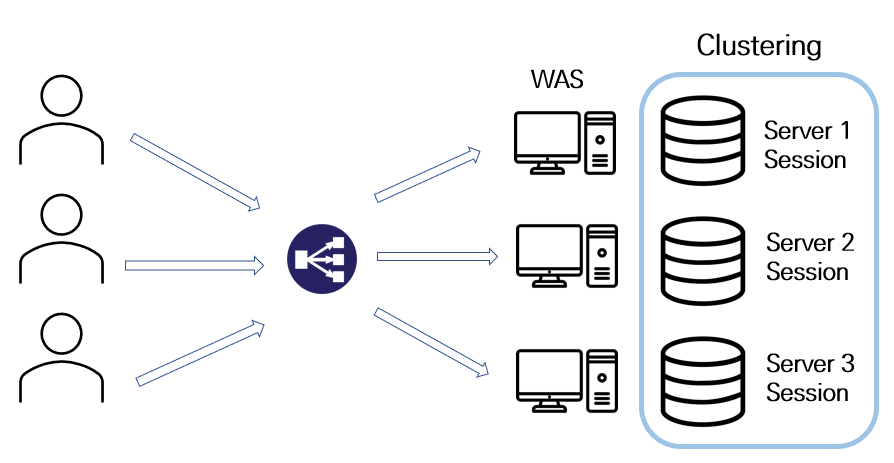
Sticky Clustering은 각각의 서버들의 세션을 묶어 동일한 세션으로 관리하는 방식이다.
예를 들어, 최초 로그인 세션이 서버1에 저장되었다면 서버2와 서버3에도 동일한 세션을 복제하는 것이다.
WAS마다 Session Clustering 방식이 다른데 현재 나는 Tomcat을 사용하고 있기 때문에 Tomcat에서 Session Clustering을 어떻게 다루는 지 알아보자.
Tomcat Session Clustering
1. All-to-All Session Replication
All-to-All 방식은 말그대로 모든 세션들이 동일한 데이터를 가질 수 있도록 복사하는 것이다.
DeltaManager를 사용하는데 작은 클러스터에는 적합하지만, 노드가 4개 이상인 큰 클러스터에는 적합하지 않다고 한다.
또한, 세션이 모든 노드로 복제되므로 배포되지 않은 노드에도 세션이 복제될 수 있다.2. Primary-Secondary session replication
All-to-All보다 더 큰 클러스터에서 사용되며 배포된 노드에만 복사를 진행하고 Primary 노드의 세션 데이터는 Secondary 노드에만 복제하여 저장하는 방식이다.
All-to-All 방식처럼 모든 서버에 복제하고 저장하는 것이 아니여서 메모리를 절약할 수 있다. 때문에 저장해야 할 세션 정보의 양이 상대적으로 줄어든다.
만약 Primary, Secondary가 아닌 그 외 노드인 Proxy에 요청이 들어온다면, 세션 아이디와 Primary나 Secondary 주소값으로 Primary-Secondary에 다시 요청하여 받아오게 되고 최종적으로 클라이언트는 모든 세션으로부터 동일한 값을 불러올 수 있다.
장점은?
트래픽이나 작업 부하를 분산시킬 수 있음으로 서비스의 성능을 향상할 수 있다.
또한, Sticky Session에서 나왔던 문제 중 모든 서버에 세션이 저장되는 문제가 발생하지 않는다.
단점은?
우선 클러스터링 작업을 위한 많은 메모리가 필요하다는 것이고 기존에 존재하던 WAS에 새로운 서버의 IP/Port를 입력해서 클러스터링을 해줘야하는 불편함이 있다.
두번째로 복제하지 전까지 시간이 소요될 때, 세션 불일치 위험이 존재할 것이고 빈번하게 복제가 일어나게 된다면 결국엔 성능 저하 문제까지 발생할 수 있을 것이다.
3. Inmemory DB
Inmemory DB은 기존 세션 정보를 데이터베이스가 디스크에 관리를 하는 것과 반대로 메모리에 데이터를 업로드하여 사용하는 방식이다.
보통 데이터가 디스크에서 읽기/쓰기 처리가 되는 데 이것은 시간이 걸리는 문제가 발생한다.
하지만 인메모리 DB는 메모리에 데이터를 읽기/쓰기를 하기 때문에 처리 속도도 월등히 빠르다.
또한, Inmemory DB의 종류는 여러가지가 있는데 보통 Redis를 많이 사용한다.
현재 Inmemory DB같은 경우에는 빠른 데이터 처리 속도와 실시간 분석등 솔류션을 제공해주기 때문에 실시간 금융 거래 분석, 고속 트랜잭션 처리, 대규모 온라인 게임의 실시간 상태관리 등 다양한 분야에서 활용되고 있다.
장점은?
위 설명을 들을 땐 데이터베이스 관리하는 방법이라고 생각할 수 있다. 물론 데이터베이스를 관리하는 방법 중 하나이긴 하지만Inmemory DB를 사용한다면 모든 세션이 Inmemory DB를 바라보게 함으로 불필요한 복제가 일어나지 않는다.
그 외 장점은 빠른 데이터 처리 속도를 자랑한다. 메모리 내에서 데이터를 처리하기 때문에, 디스크 I/O에 비해 훨씬 빠르다.
그리고 Inmemory DB는 처리량이 높기때문에 쿼리와 조인 연산에도 뛰어난 성능을 보여준다.
마지막으로 높은 확장성으로 성능에 악영향을 미치지 않으면서 읽기/쓰기 크기를 모두 조정할 수 있다.
단점은?
기본적으로 메모리에 저장되므로 데이터 유실 위험이 있다.
또한, 메모리 용량에 따라 성능차이가 발생하기 때문에 메모리 용량이 부족하면 시스템의 성능이 저하될 수 있다.
세션 불일치를 해결하기 위해선?
세션 불일치를 해결하기 위해 위에서 살펴본Sticky Session, Session Clustering, Inmemory DB 세개 중 어느 것을 사용해야할까??
첫번째로 Sticky Session은 세션 불일치를 해결할 수 있지만 가장 큰 단점인 트래픽이 특정 서버에 몰릴 수 있다는 점이다.
두번째로 Session Clustering은 Sticky Session의 단점인 특정 서버에 트래픽이 몰릴 수 있는 문제를 해결해줄 수 있다.
그러면 Session Clustering을 선택해야 되나??
하지만 클러스터링 셋팅의 어려움이 있고 서비스가 확장될 경우 추가 메모리 비용이 발생하고 데이터 변경이 발생할때 마다 세션을 복제하는 작업이 일어나기 때문에 네트워크 요청 트래픽이 증가하게 된다.
결국 Sticky Session과 Session Clustering은 특정 서버 트래픽 급증, 네트워크 요청 트래픽 증가 등 문제로 세션 불일치 문제를 원할하게 해결해주기에는 부족한 것 같다.
마지막으로 Inmemory DB는 메모리에 데이터가 저장되기 때문에 전원이 꺼지면 데이터 유실 위험이 있다.
하지만 나는 세션을 이용한 로그인 기능 구현에서 세션 불일치 문제를 다루고 있고 세션은 중요한 정보가 담기는 것이 아니기 때문에 세션 데이터만 저장한다면 데이터 유실이 발생해도 크게 문제가 되지 않는다고 생각한다.
또한, 세션 데이터가 하나의 DB를 바라보기 때문에 Session Clustering의 데이터 복사로 인한 성능 저하 문제도 해결할 수 있다.
Inmemory DB가 세션 불일치 문제와 Sticky Session, Session Clustering의 문제를 해결할 수 있기 때문에 최적의 선택이라고 생각한다.
Inmemory DB를 선택했는데 그 다음은??
우선 Inmemory DB종류는 많은 종류가 존재하는데 Redis와 Memcached가 무료 오픈소스 데이터베이스로 운용되고 Key-Value 형태로 저장되기 때문에 세션 데이터를 다루는 데 적합하다고 생각한다.
하지만 두 종류에 차이점이 존재한다.
1. Thread 차이
Redis는 싱글스레드를 지원하고Memcached는 멀티스레드를 지원한다.2. Replication 지원
Memcached같은 경우에는 Replication을 지원하지 않고 노드 분산을 통한 완화 방식을 지원한다.
Redis는 master-slave 관계의 Replication을 지원한다. 때문에 이런 복제 방식은 스스로 장애 극복이 가능하다.
또한, master-slave 관계로 master가 다운됐을 경우 자동으로 slave로 지정되기 때문에 서비스의 중단없이 이용할 수 있다.3. 데이터 타입 지원
Memcached는 String만 지원하는 반면,Redis는 String, Set, Sorted Set, Hash, List 등 다양한 데이터 타입을 지원한다.4. 메모리 사용량
Memcached는 다시 시작하지 않는 이상 사용하지 않는 공간을 회수할 수 있는 방법은 없다.
Redis의 경우에는 더 이상 사용하지 않는 메모리는 다시 제공한다.
위 차이점을 비교해봤을 때 Redis를 선택하는 것이 좋을 것 같다는 생각이 들었다. 특히나 Replication을 지원하는 Redis의 경우 세션 불일치 및 서비스가 중단되는 단점을 크게 보완해줄 수 있을 것 같다.
이 외 개발환경에서도 현재 Spring Boot로 개발 중이기 때문에 Redis를 사용한다면 편하게 API를 제공받을 수 있다는 점도 있다.
Redis로 가자 !!!
긴 글 읽어주신 분들께 감사하고 잘못된 내용이 있다면 지적해주시면 감사하겠습니다.
다음 이야기는 Redis가 싱글스레드를 지원하기 때문에 일어날 수 있는 병목현상 및 동시성 문제를 어떻게 다룰 것인지가 될 것 같다. 시간이 된다면 블로그에 추가로 글을 남길 예정이다.
