f-lab 멘토링 진행 중 멘토님께서 프로젝트에 적용 해야하는 고려 사항에 대해 말씀해 주셨다.
고려 사항은 캐시에 대해 알아보고 현재 프로젝트에서 어떤 방식을 사용하면 좋을지 고려해 보라고 하셨다.
캐시? 캐싱? 둘 다 많이 들어봤는데 정확한 차이와 무엇인지 개념을 아예 몰랐다.
이번엔 캐시와 캐싱을 살펴보고 어떤 방식을 사용해서 프로젝트에 적용할지 알아보자.
캐시? 캐싱? 두 개 차이가 뭔데?
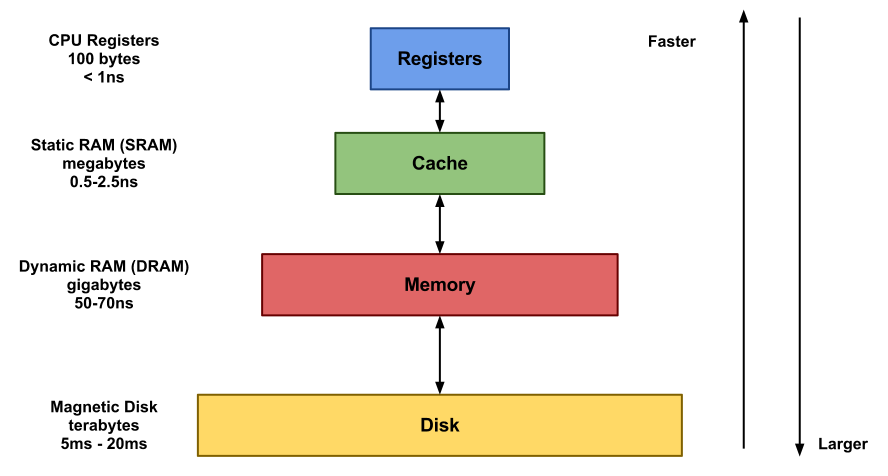
캐시
캐시는 원본 데이터 저장소보다 빠르게 데이터를 가져올 수 있는 임시 데이터 저장소.
레지스터 다음으로 CPU 코어 가까이 위치한 것이 캐시 메모리.직접 읽거나 쓸 수 없고, 하드웨어 메모리 관리 시스템에서 내부적으로 제어한다.
그 때문에 프로그래머가 직접 코드상으로 접근할 방법이 없다.
캐싱
캐시에 접근해서 데이터를 빠르게 가져오는 방식 및 기술.
그래서 왜 중요해?
캐시 메모리를 직접 읽고 쓰지 못하기 때문에 간접적으로 데이터 접근 시간을 단축시키고 메모리 접근 패턴을 최적화하여 프로세스 대기 시간을 줄이기 위해서다.
캐시의 구조와 작동은 어떻게 되는 거야?
우선 캐시는 L1, L2, L3 캐시로 계층화되어 있다.
레벨마다 접근 속도와 저장 용량에 차이가 있다.
L1 캐시는 가장 빠르지만 용량이 작으며 L2 캐시는 L1 캐시보다 크지만 약간 느리며 L3 캐시는 속도가 느리지만 용량이 가장 크다.
캐시의 작동 원리는 직접매핑(Direct-Mapped), 연관매핑(Associative), 세트-연관매핑(Set-Associative)의 매핑 방식과 가장 핵심인 데이터 지역성 중 시간적 지역성, 공간적 지역성을 활용하여 작동 효율을 높인다.
직접매핑(Direct-Mapped)
직접매핑은 캐시 메모리와 메모리가 1:1로 매핑하는 구조로 메모리와 동일한 배열 구조를 가진다.
또한, 단순하고 탐색이 매우 쉬운 반면에 캐시 히트율이 낮다.연관매핑(Associative)
연관매핑은 직접매핑과 다르게 1:N으로 매핑하는 구조로 메모리 주소를 함께 저장하여 메모리 데이터가 캐시 메모리 어느 곳이나 적재가 가능하다.
캐시 히트율이 높은 반면에 구현회로가 복잡하여 처리 속도가 느리다.세트-연관매핑(Set-Associative)
세트-연관매핑은 직접매핑과 연관매핑을 합친 매핑으로 캐시 메모리의 한 index에 2개 이상의 서로 다른 데이터 블록을 저장하여 하나의 Set를 형성한다.
캐시 히트율이 높고 구현회로 및 구조가 복잡하다.시간적 지역성
최근 접근한 데이터는 가까운 시간에 다시 접근될 가능성이 높기 때문에 자주 사용된 데이터를 유지한다.
공간적 지역성
메모리의 인접한 주소에 위치한 데이터들이 함께 접근될 가능성이 높기 때문에 캐시는 데이터 블록으로 데이터를 가져온다.
성능 향상을 위해선?
캐시 메모리의 성능 향상을 위해 캐시 히트율을 높이고 캐시 미스를 줄여야 한다.
또한 캐시 친화적인 코드를 작성해야 하는데 데이터 구조를 캐시 라인에 맞춰 설계하고, 루프 퓨전이나 블로킹 같은 기법을 사용하여 메모리 접근 패턴을 최적화할 수 있다.
캐시 히트율이란?
캐시 히트율은 캐시가 미리 원본 데이터에서 가져와 원하는 데이터를 바로 캐시로부터 가져오는 것을캐시 히트율이라고 한다.
적중률은 적중 횟수 / 총접근 횟수로 계산을 하고 적중률이 0.95~0.99일 때 적중률이 가장 우수하다고 말할 수 있다.
즉, 캐시 히트율이 높을수록 캐시를 효율적으로 사용하고 있는 것이고 이는 응답 시간 단축과 부하 감소로 이어진다.
그렇다면 캐시 미스는?
캐시 미스는 반대로 캐시 메모리에서 데이터를 가져오지 못하고 원본 데이터에 접근해서 가져오는 상황을 말한다.
루프 퓨전이란?
다수의 루프를 단일 병렬 루프로 결합하여 개별로 접근하는 루프를 최소화하여 최적화하는 것이다.
블로킹이란?
블로킹은 루프 반복 구간을 작은 블록 단위로 나누어 캐시에 맞도록 처리하는 방식이다.
캐시 히트율에 영향이 미치는 요소는?
캐시 히트율에 영향을 미치는 요소들은 다양하다.
대표적으로 만료시간, 캐시 제거 정책(알고리즘), 캐시의 크기가 있다.
만료시간
캐시에 저장된 데이터는 데이터가 만료되는 시간도 있고 실시간 시간도 적중률에 영향을 줄 수 있다.
캐시 데이터가 너무 빨리 만료되면 원본 데이터를 더 자주 가져오기 때문에 적중률을 낮추고 반대로 느리게 만료되면 적중률은 높아지지만, 데이터의 신선도가 떨어지게 된다.
캐시 제거 정책(알고리즘)
캐시 삭제는 캐시의 크기가 한정되어 있을 때, 새로운 데이터를 저장하기 위해 기존 데이터를 제거한다.
제거 정책에는LRU,LFU등이 있다.
LRU 알고리즘과 장단점
LRU(Least Recently Used)는 가장 최근에 사용된 데이터를 먼저 남기고, 가장 오랫동안 사용되지 않은 데이터를 제거하는 방식이다.
LRU알고리즘의 가장 큰 장점은 자주 사용되는 데이터를 캐시에 유지하여 성능을 최적화할 수 있다.
또한, Hash Map과 Doubly Linked List를 결합하여 데이터를 빠르게 찾고, 접근 시간을 효율적으로 관리할 수 있어 구현이 비교적 간단하다.하지만 단점으로는 데이터의 접근 시간을 기록하고 갱신하는 데 추가적인 메모리와 연산이 필요하고
주기적으로 사용되는 특정 데이터의 주기가 길면 해당 데이터가 캐시에서 제거될 수 있다.
LFU 알고리즘과 장단점
LFU(Least Frequently Used)는 캐시 내 데이터의 사용 빈도가 적게 사용된 데이터를 제거하는 방식이다.
LFU알고리즘의 장점은 빈번하게 사용되는 데이터를 보다 오래 유지할 수 있다.단점은
LRU알고리즘과 마찬가지로 낭비되는 메모리 공간이 많다. 왜냐하면 페이지 접근 횟수를 표시하는 데 추가 공간이 필요하므로 그만큼 메모리가 낭비된다.
캐시는 어디에 저장해?
캐시 데이터를 저장하는 방법은 로컬 캐시와 글로벌 캐시가 있다.
로컬 캐시와 글로벌 캐시의 개념과 둘의 장단점을 알아보자.
로컬 캐시(Local Cache)
로컬 캐시는 웹 애플리케이션의 서버에 캐시를 저장하는 방법이다.
애플리케이션이나, EhCache 라이브러리를 사용해서 저장한다.
장점은 네트워크 통신이 발생하지 않아 빠른 성능을 제공하고 별도의 캐시를 위한 서버를 증설하지 않아도 되기 때문에 비용적인 측면도 적게 발생한다.
단점은 분산 환경에서는 서로 다른 캐시가 저장되어 불일치하는 문제가 발생할 수 있다.
이 문제를 해결하려면 분산 환경의 각 서버에 동일한 캐시를 저장해야 하는데, 이는 심각한 자원 낭비가 발생한다.
글로벌 캐시(Global Cache)
글로벌 캐시는 캐시 서버를 따로 분리하여 캐시를 저장한다. 주로 Redis, Memcached 등을 활용하여 저장한다.
장단점은 로컬 캐시와 반대이다.
우선 장점은 분산 환경에서 하나의 캐시 저장소를 바라보기 때문에 캐시를 공유하므로 중복 저장을 줄일 수 있다.
그 때문에 각 서버가 동일한 캐시를 얻을 수 있다는 말이다.
추가로 중복 저장을 줄여 메모리를 효율적으로 사용할 수 있다.
단점은 로컬 캐싱에 비해 속도가 느리고 별도의 캐시 저장소를 두어야 하므로 비용적인 측면이 발생할 수 있다.
현재 내 상황에 맞는 캐싱 방식은?
현재 내 상황에 맞는 캐싱 방식은 무엇일까? 로컬 캐시? 글로벌 캐시?
우선 진행하는 프로젝트의 서버 확장 방식은 Scale-Out 확장 방식을 채택했다.
또한, 세션 불일치 문제를 해결하기 위해 Redis를 사용하고 있다.
"어? 로컬 캐시는 빠르지만 분산 환경에서는 해당 서버에만 캐시가 저장되거나 변경되거나 할텐데 그러면 각 서버마다 캐시를 동기화 시켜줘야되는 거 아니야?"
맞다.
Scale-Out 서버 확장 방식을 채택했고 세션 불일치 문제 해결을 위해 Redis를 사용하고 있다. 때문에 글로벌 캐시가 현재 프로젝트 환경에 가장 적합하다고 생각한다.
결론은 글로벌 캐시 선택 !
긴글을 읽어주셔서 감사합니다. 사실과 맞지 않은 내용이 있다면 지적해주시면 감사하겠습니다.
