
INTORDUCTION
-
기존의 LoRA 결합 방식은 일반적으로 각기 다른 다운스트림 작업에 특화된 LoRA를 별도로 결합하는데 초점을 맞추었고, 이 과정에서 추가적인 학습이 필요한 경우가 많았음
-
모델 병합 방식은 여러 LoRA의 파라미터를 추가 학습 없이 하나의 어댑터로 집약하는 방식을 제공하며, 보다 범용적인 LoRA를 생성할 수 있음. 하지만 이러한 방법은 일반적으로 파라미터를 단순히 요소 단위로 결합하는 방식을 사용 ➡️ LoRA 내부의 의미적 구조를 훼손하거나 무시하게 & 파라미터 간 간섭을 유발하고 병합된 LoRA의 성능 저하로 이어질 수 있음
일반적인 모델 병합 방식이란?
ex) 2개의 LoRA 가 있을 때
이렇게 A,B 각각을 평균을 내서 새로운 LoRA 를 만들 수 있음
의미적 구조 무시
LoRA는 내부적으로 "랭크 단위"의 MSU(작은 의미 단위)로 구성되는데, 그냥 수치적으로 평균만 내면 이런 의미 단위들이 망가짐ex) LoRA A(감정 분석용) - rank 1 : 긍정/부정 감정 구분, rank2 : 강한/약한 감정 구분
LoRA B(개체명 인식용) - rank 1 : 사람 이름 감지, rank 2 : 지명 감지
LoRA 병합 시, rank 1끼리 rank2끼리 평균을 하게되면 각 벡터가 중간에 섞이면서 아무 의미도 갖지 않게 됨
파라미터 간섭
서로 다른 의미의 파라미터들이 섞이면, 하나의 역할도 제대로 못하게 되고 전체 LoRA의 성능 저하로 이어짐ex) "Barack Obama was happy to visit Paris" 이 문장에는 감정 & 사람/지명도 있음. 하지만 병합된 LoRA는 감정과 개체명 파악을 둘 다 하려고 하다 "Barack Obama"를 긍정 감정으로 인식하거나 "happy"를 사람 이름으로 인식하는 기능 충돌이 발생
LoRA를 더 세분화된 독립적 단위로 분해하여 유연하게 재조립 가능한 LoRA-LEGO라는 새로운 병합 방식을 제안함
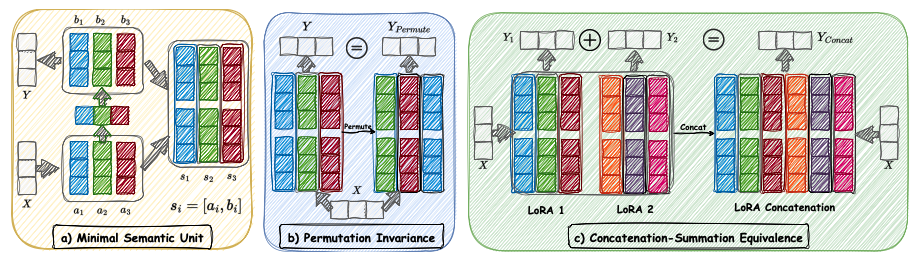
LoRA의 모듈화를 탐구하고, 이를 구성하는 기본 단위로서 MSU를 정의하였으며, 이는 순열 불변성 및 연결-합산 등가성 속성을 가짐.
여러 LoRA를 LEGO처럼 결합할 수 있는 LoRA-LEGO 방법을 제안하였으며, MSU를 그룹화, 클러스터링, 재조립하여 각각의 LoRA를 자연스럽게 통합할 수 있음.
실험 결과, LoRA-LEGO는 다양한 rank의 LoRA를 유연하게 해체 및 재조립할 수 있으며, 기존 모델 병합 방법보다 우수한 성능을 보였음. 또한, 개별 LoRA에 적용하여 파라미터 축소를 통해 성능 손실 없이 LoRA의 경량화를 달성할 수 있음을 보여주었음.
PRELIMINARIES
LoRA
LLMs의 전체 파라미터를 직접 파인튜닝하는 것은 연산 비용이 매우 높아, 리소스가 제한된 환경에서는 현실적으로 불가능함. 새로운 도메인에서 충분한 성능을 얻기 위해 소수의 저랭크 파라미터만을 파인튜닝하면 된다는 아이디어에 기반하여 LoRA를 제안하였고 LoRA는 사전 학습된 파라미터와 병렬로 결합되어 효율적인 추론을 가능하게 함
사전학습된 가중치 가 주어졌을 때, LoRA는 의 형태로 추가함. 여기서 는 두 개의 작은 행렬 와 로 분해됨. 이때 은 LoRA의 랭크로, 이다.
LoRA의 추가적인 모듈화
1️⃣ LoRA의 최소 의미 단위(MSU)
LoRA 모듈 내 행렬 A와 B가 주어졌을 때, 각 인덱스 에 대해 로 정의되는 벡터를 MSU라 함. 는 A의 i번째 행, 는 B의 전치 행렬()의 i번째 행임. 즉, A의 한 행과 B의 한 열이 짝을 이루어 하나의 MSU 구성
MSU는 LoRA의 각 랭크에 해당하며, LoRA의 의미적 정보를 독립적으로 담고 있는 단위임
즉,
2️⃣ 순열 분변성(Permutation Invariance)
LoRA 모듈이 행렬 A와 B로 구성되어 있을 때, A의 행을 임의로 섞고 이에 대응하여 B의 열도 동일하게 섞는다면, 두 행렬의 곱은 변하지 않음.
수학적으로, 단위 행렬 에 대해 인 순열 행렬 가 있을 때,
즉, LoRA 내 MSU들의 순서를 바꿔도 출력에는 영향이 없음
두 행렬은 행 순서만 다르고 결과는 동일한 의미를 가짐. 즉, LoRA 출력에는 영향이 없음
3️⃣ 연결-합산 등가성(Concatenation-Summation Equivalence)
랭크 r을 갖는 두 LoRA 가 있을 때, 처럼 연결하면 연결된 모델의 출력은 개별 모델 출력의 합과 같음
즉, 여러 LoRA의 MSU를 연결하면 이들의 출력을 합산한 것과 동일한 결과를 얻게 되고 이를 통해 LoRA간의 지식 합성을 새로운 연결형 LoRA를 통해 구현할 수 있음
LoRA 1 ➡️
LoRA 2 ➡️
1. 각각 출력 계산 후 더하기
2. MSU들을 붙여서 더 큰 행렬 만든 후 한 번에 계산
➡️ 두 방식의 결과는 같음
문제 정의 및 도전 과제
LLM을 이라 하고, 라는 개의 태스크 특화 LoRA 집합이 있다고 가정하자. 각 LoRA 는 특정 작업 에 맞춰 의 여러 층에 저랭크 행렬을 삽입하여 학습된 것이다.
LoRA의 병합 목적은 LoRA 의 파라미터를 라고 할때 이들로부터 모든 태스크에 고성능을 보이며 일반화 가능한 병합형 LoRA 을 만드는 것임
가장 일반적인 방법은 단순한 파라미터 평균화
그러나 이 방식은 파라미터 간섭 문제를 야기하여 성능 저하를 일으키 수 있으며 이 논문에서는 두 가지 주요 간섭 원인을 실험적으로 확인하였음
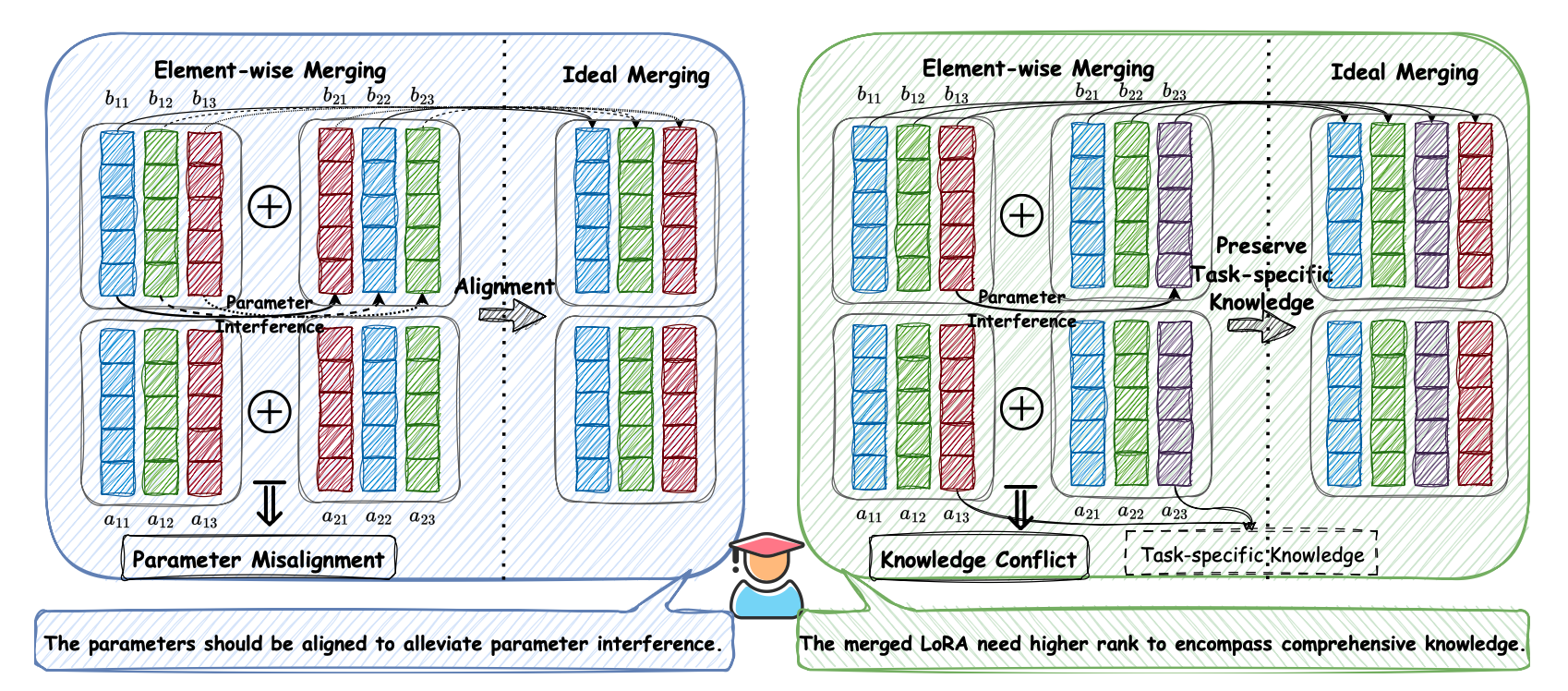
Parameter Misalignment(왼쪽 그림)
두 개의 LoRA가 있고 각 LoRA는 3개의 MSU로 구성됨
하지만 병합할 때 순서가 맞지 않음(빨강-초록-파랑 ↔️ 초록-파랑-빨강)의미가 맞지 않는 블록끼리 섞이게 되고 계산 결과가 의미 불일치를 일으켜 간섭이 발생하게 됨
⭐️ 순서 맞추기 = 파라미터 간섭 줄이기
Knowledge Conflic(오른쪽 그림)
두 LoRA는 서로 다른 작업에 특화됨
두 LoRA를 단순히 요소별 평균처럼 병합하면, 서로 다른 의미의 파라미터(빨강-보라)가 같은 위치에 섞이게 됨
⭐️ 더 높은 rank를 사용해 각 작업의 MSU를 따로 유지
1️⃣ 파라미터 정렬 불일치(Misalignment)
같은 의미의 MSU가 서로 다른 위치에 있을 경우
MSU는 순열 불변성을 가지므로 LoRA 내 MSU의 순서는 상관없음. 그러나 서로 다른 LoRA를 병합할 때 MSU 순서가 일치하지 않으면 간섭이 발생할 수 있음.
LLaMA-2-7b 모델을 사용하여 서로 다른 작업에 대해 LoRA를 훈련하고, MSU 순서를 무작위로 섞어 병합한 실험을 수행하였음
즉, 임의의 순열 행렬 를 사용(순서 섞는 행렬)하여 다음과 같이 파라미터를 구성하였음
이는 동일한 LoRA 두 개를 정렬 불일치 상태에서 병합한 것과 동일하며, 결과적으로 성능이 눈에 띄게 하락함을 확인할 수 있음
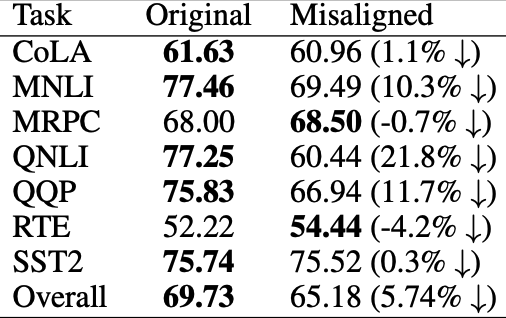
2️⃣ 지식 충돌(Knowledge COnflict)
서로 다른 작업의 정보가 같은 위치에 억지로 들어감
병합된 LoRA가 모든 지식을 담기에는 충분한 파라미터 공간이 부족할 경우, 작업 특화 MSU들이 강제로 병합되며, 이로 인해 파라미터 간섭이 발생하게 됨
작업 특화 MSU를 병합했을 때의 성능 저하를 관찰하는 실험을 통해 지식 충돌이 성능에 미치는 영향을 조사하였음
CoLA 태스크로 학습된 기본 LoRA를 바탕으로, MNLI와 MRPC라는 두 새로운 태스크에 대해 각각 하나의 MSU를 추가하여 두 개의 작업 특화 LoRA를 생성하였음. 이때 새로운 태스크를 학습하는 동안에는 새로 추가된 MSU만 학습 가능하도록 설정하였으며 따라서 MNLI와 MRPC용 LoRA는 각기 다른 MSU 하나만이 차이점이며, 이는 각 작업에 맞는 고유한 의미 정보를 포함하고 있음.
이 실험 구조는 두 작업 특화 LoRA가 단 하나의 MSU로만 구분되도록 설계된 것이며, 이를 병합할 경우 발생하는 파라미터 간섭을 명확히 관찰할 수 있음

위 실험 결과 두 MSU를 단순 평균한 경우 각 태스크의 성능이 현저히 감소한 반면, 두 MSU를 연결하여 각각의 작업 특화 MSU를 유지한 경우 원래의 작업 성능이 잘 보존되었음.
즉, 이상적인 LoRA 병합에서는 작업 특화 MSU를 유지해야 하며, 이를 통해 지식 충돌을 방지하고 파라미터 간섭 문제를 효과적으로 해결할 수 있음을 시사.
METHODOLOGY
LoRA-LEGO FRAMEWORK
LoRA LEGO 프레임워크는 세 가지 주요 단계로 구성됨
이 단계들은 다양한 MSU들을 하나의 응집된 LoRA로 통합하면서 LoRA 병합 시 발생하는 파라미터 간섭을 완화하는 데 기여함
1️⃣ MSU 그룹화(MSU Grouping)
개의 LoRA를 병합하는 초기 단계에서는 각 LoRA를 여러 개의 MSU로 분해하고, 각 LoRA로부터 모든 MSU를 추출하여 하나의 MSU pool로 그룹화함
여기서 LoRA 파라미터 집합 는 각 LoRA의 특정 레이어에 대해 rank 를 갖음. 각 LoRA 모듈 는 총 개의 MSU를 가지며, 이는 다음과 같이 표현됨
, 여기서
- : 의 번째 열
- : 의 번째 행
모든 LoRA에서 수집된 MSU pool 는 다음과 같이 구성됨
2️⃣ MSU 클러스터링(MSU Clustering)
MSU들을 그룹화한 이후에는, 이들을 의미적 유사성에 따라 클러스터로 다시 나눔
MSU pool 를 바탕으로 K-means 알고리즘을 사용하여 MSU를 k개의 클러스터 {}로 분할함. 각 MSU는 자신과 가장 가까운 중심점(centroid)을 가진 클러스터에 할당됨
- : 클러스터 의 중심을 나타냄
3️⃣ LoRA 재구성(Reconstruction)
MSU 클러스터링 이후, 우리는 클러스터별로 MSU들을 정렬하여 k개의 클러스터를 구성함. 각 클러스터의 중심점 는 해당 클러스터 내 MSU들의 평균으로 계산됨. 이 중심점들은 해당 클러스터를 가장 잘 대표하는 일반화된 의미 정보를 담고 있으며, 단순히 다른 LoRA를 직접 병합하는 것보다 정보 손실이 적음
k개의 중심점으로 부터 새로운 LoRA 모듈을 재구성할 수 있음. 각 중심점 는 병합된 모델의 하나의 rank로 사용되며, 병합된 LoRA는 총 rank 를 가지게 됨 ( )
새로운 LoRA 모듈은 다음과 같은 새로운 투영 행렬 A'와 B'로 구성됨
- : 중심점 로부터 추출된 값
이렇게 재구성된 LoRA 모듈 는 병합 전에 유사한 MSU끼리 정렬되었기 때문에 파라미터 간섭 문제를 효과적으로 해결할 수 있음.
이 방식은 다양한 작업의 지식을 포괄하면서도 유연한 rank 설정이 가능하게 해 줌
EXAMPLE
- LoRA A :
- LoRA B :
① MSU 그룹화
- LoRA A
- LoRA B
➡️ MSU 풀() =
② MSU 클러스터링
로 클러스터링 되었다고 가정
그리고 클러스터링 결과가 Cluster 1:, Cluster 2 :③ LoRA 재구성
각 클러스터의 중심점 를 계산
Cluster 1 평균
Cluster 2 평균
최죙 병합된 LoRA 행렬은 아래와 같음
OPTIMAL SCALE OF MERGED LoRA
병합된 LoRA-LEGO의 rank는 최소 1부터 최대 까지 범위를 가질 수 있으므로, LoRA의 출력 스케일은 크게 달라질 수 있으며 이는 성능에 직접적인 영향을 줄 수 있음.
왜 최소 1부터 최대 까지 범위를 가지는가?
LoRA 1의 rank가 2일때 MSU는 2개가 존재
LoRA 2의 rank가 3일떄 MSU는 3개가 존재
즉, 총 MSU 수는 5개가 됨
이 때 만약 모든 MSU가 매우 유사하게 되면 하나의 클러스터로 묶을 수 있고 반대로, 모두 MSU가 서로 완전히 다르면 각 MSU를 독립된 클러스터로 유지해야 함
1️⃣ Norm Decay After LoRA Merging(병합 후 파라미터 노름 감소)
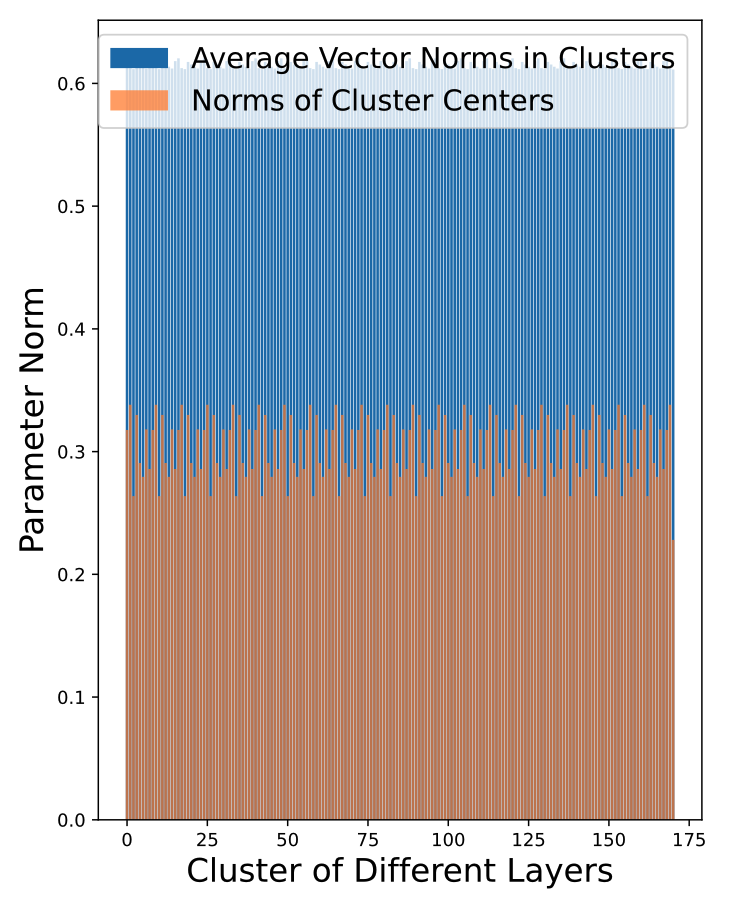
이미지에서 볼 수 있듯이, 각 클러스터 병합 전의 평균 파라미터 노름과 병합 후의 파라미터 노름을 비교한 결과, 병합 후 파라미터 노름이 현저히 감소함을 확인할 수 있음.LoRA 모듈의 출력 크기에 영향을 줄 수 있음
이 현상은 triangle inequality(삼각 부등식)으로 설명할 수 있음
어떤 벡터 들이 있을 때, 여러 벡터의 평균은 개별 벡터 노름 평균보다 작거나 같음을 의미함
위 현상이 나타나면 A,B의 값이 작아지게되고 도 작아지고 출력 값()이 줄어들게되어 모델이 학습한 조정 효과가 약해지므로 성능 저하 가능성이 생기게 된다.
이 노름 감소를 보정하기 위해, 클러스터 중심점 를 재가중화 함
이 구현은 무한 노름을 사용하여 안정성과 강건성을 확보함
무한 노름이란?
벡터에서 가장 큰 절대값 하나만 보는 방식
Example
평균 전 MSU들
평균 벡터(centroid)
L2 Norm :
Infinite Norm :Infinite Norm은 가장 큰 성분을 정확하게 유지 가능
L2 Norm은 전체가 늘어나면서 주요한 성분이 왜곡될 수 있음
2️⃣ Variance Expansion with Increased LoRA Rank(LoRA Rank 증가에 따른 분산 확장)
출력 스케일에 영향을 미치는 또다른 요소는 병합된 LoRA의 rank임.rank r=8$인 LoRA 7개를 병합하면서, 병합된 LoRA의 rank k를 다양하게 바꿔가며 출력의 분산 변화를 실험했음
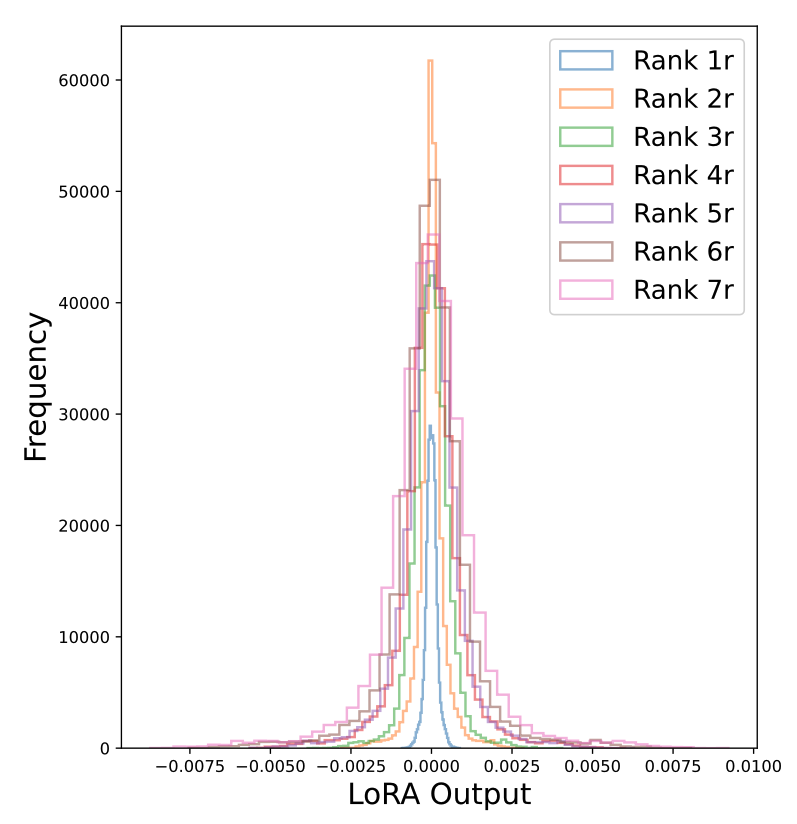
그림에 나타난 바와 같이, 병합된 LoRA의 첫 번째 레이어 출력 분포는 평균 0을 중심으로 한 정규분포 형태를 띄고 있었으며, rank 가 증가함에 따라 출력 분산도 증가하는 경향을 보였음. 이러한 분산 증가를 보정하기 위해서 self-attention 메커니즘의 정규화 방식에 착안하여 다음과 같은 스케일링을 적용함
일때
이들 행렬의 모든 원소가 표준 정규 분포 로부터 독립적이고 동일하게 샘플링되었다고 가정
이 경우 에 스케일링 계수 를 곱하면 다음과 같은 등식이 성립함즉, LoRA의 출력 행렬 과 스케일링된 의 분산이 동일해짐
이 방법은 병합된 LoRA의 출력 분산이 원래 LoRA와 일치하도록 스케일 조정하는 방법임
EXPERIMENTS
Multi-task learning과 Mixed-task settings 두 가지 설정을 선택하였음. 이 두 설정에서 다양한 LoRA 결합 방법들을 비교하여, 제안한 LoRA-LEGO 접근 방식의 성능을 평가하였음
기초 모델로는 Llama2-{7b,13b}를 사용하였고, 각 태스크마다 LoRA를 학습시킬 때는 하이퍼파라미터 를 사용했음
MULTI-TASK LEARNING
개별적으로 학습된 LoRA들을 하나의 통합 모델로 병합하면서도, 각 LoRA가 가진 성능을 유지하는 것을 목표로 함.
Experiment Setting
Llama2-{7b,13b}에서 학습된 7개의 LoRA 모델을 병합하였음. 이 모델들은 Cola, Mnli, MRPR,QNLI, GLUE-QQP, RTE, SST2 등 도메인 내 태스크에 대해 학습되었으며, 병합된 LoRA는 이들 태스크뿐만 아니라 SNLI와 WNLI라는 두 개의 도메인 외 태스크에서도 평가되어, 적응력과 일반화 능력을 측정하였음
Baseline Methods
6개의 사후 학습이 필요 없는 LoRA 결합 방법들과 비교하였음
1 ) weight averaging
2 ) ensemble
3 ) Task Arithmetic
4 ) Ties-Merging
5 ) DARE
6 ) DELLA-Merging
Main Results
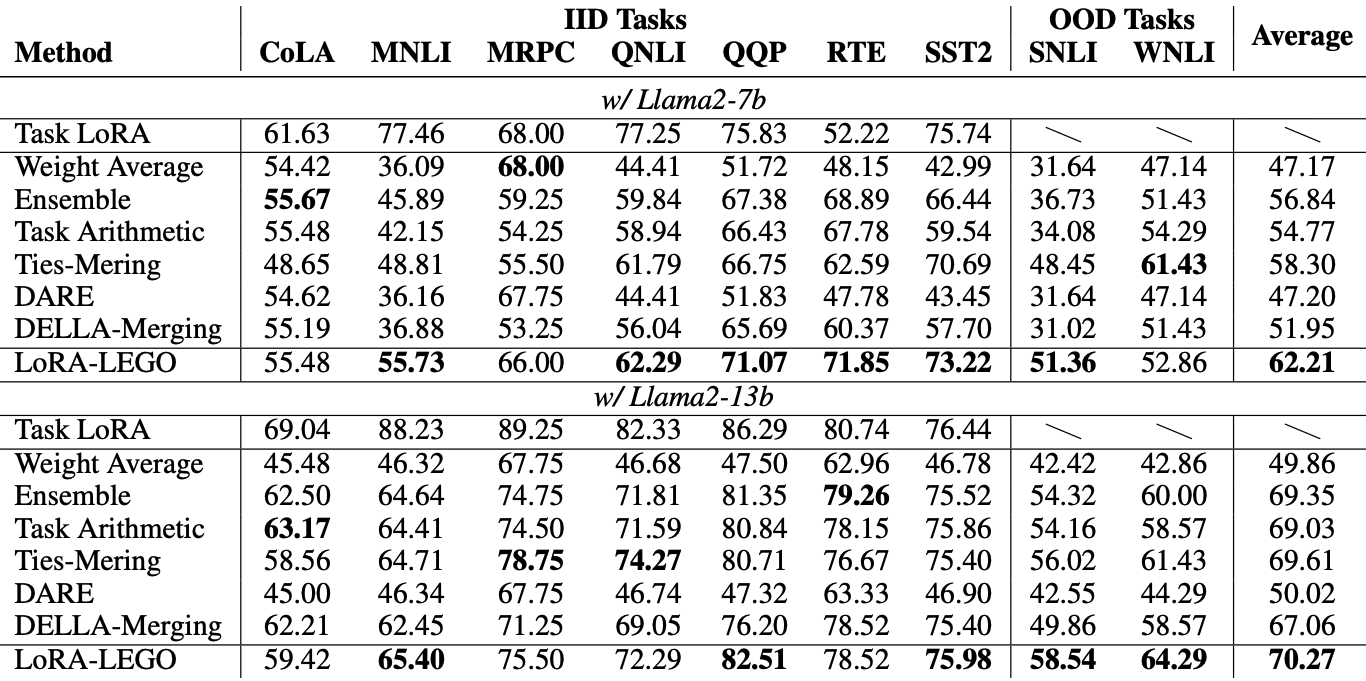
| task | taks 설명 | 형식 |
|---|---|---|
| CoLA | 문장이 문법적으로 수용 가능한지 판별 | 문장 ➡️ 비문법적(0), 문법적(1) |
| MNLI | 두 문장 간의 관계 (추론) 판단 | 전제 + 가설 ➡️ Entailment / Neutral / Contradiction |
| MRPC | 두 문장이 의미적으로 유사한지 판별 | 문장 1 + 문장 2 ➡️ 유사하지 않음(0), 유사함(1) |
| QNLI | 질문에 대한 문장이 정답인지 판단 | Question + Sentence ➡️ Entailment / Not Entailment |
| QQP | 두 질문이 같은 의미인지 판별 | Question1 + Question2 ➡️ 다름(0), 같음(1) |
| RTE | MNLI와 유사하지만 더 간단한 추론 task | 전제 + 가설 ➡️ Entailment / Not Entailment |
| SST2 | 문장의 감정 분류 | 문장 ➡️ 부정(0), 긍정(1) |
| SNLI | MNLI와 유사한 문장 간 추론 문제 | 가설 + 전제 ➡️ Entailment / Neutral / Contradiction |
| WNLI | 공통 지식과 상식 추론 능력 평가 | 문맥 문장 + 참 / 거짓 문장 ➡️ Entailment / Not Entailment |
| 방법 | 성능 저하 이유 |
|---|---|
| Weight Averaging | LoRA 병합 중 발생하는 파라미터 간섭으로 인해 성능이 크게 저하 |
| Ensemble | 파라미터 중복으로 인해 최적 이하의 성능과 느린 추론 속도를 보임 |
| Task Arithmetic 및 Ties-Merging | 요소 단위 결합을 수행하므로 LoRA내 파라미터 간섭 문제를 제대로 해결하지 못해 병합 성능이 낮음 |
| DARE & DELLA-MERGING | 요소 단위 파라미터 병합을 사용하여, 파라미터 의미 공간의 정렬을 고려하지 않고 병합하므로, 파라미터 간섭으로 인한 병합 실패 초래 |
Performance on LoRA Pruning
하나의 LoRA가 랭크 을 가질 때, LoRA-LEGO는 을 선택하여 rank를 로 줄임으로써 모델을 가지치기할 수 있음.
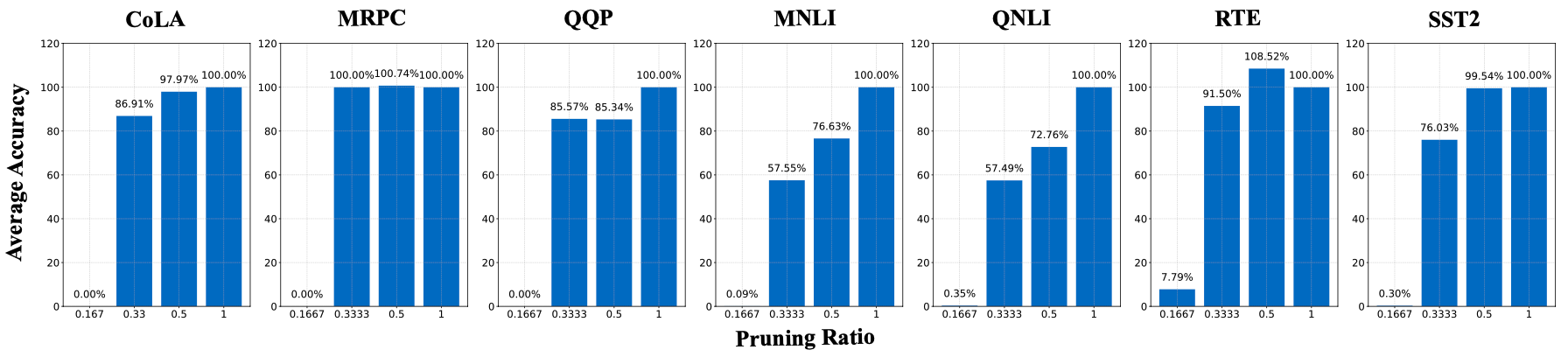
다양한 비율의 파라미터를 유지하면서 단일 LoRA 모델의 성능을 평가하였음. LoRA-LEGO는 매우 효율적인 파라미터 압축을 가능하게 하며, 전체 파라미터의 33%만 유지해도 원래 성능의 79%, 50%를 유지하면 92%의 성능을 보존할 수 있음.
Ablation of Scaling Strategies(스케일링 전략에 대한 소거 실험)
병합된 LoRA의 클러스터 수를 조정하면서 두 가지 스케일링 전략의 효과를 평가하였음
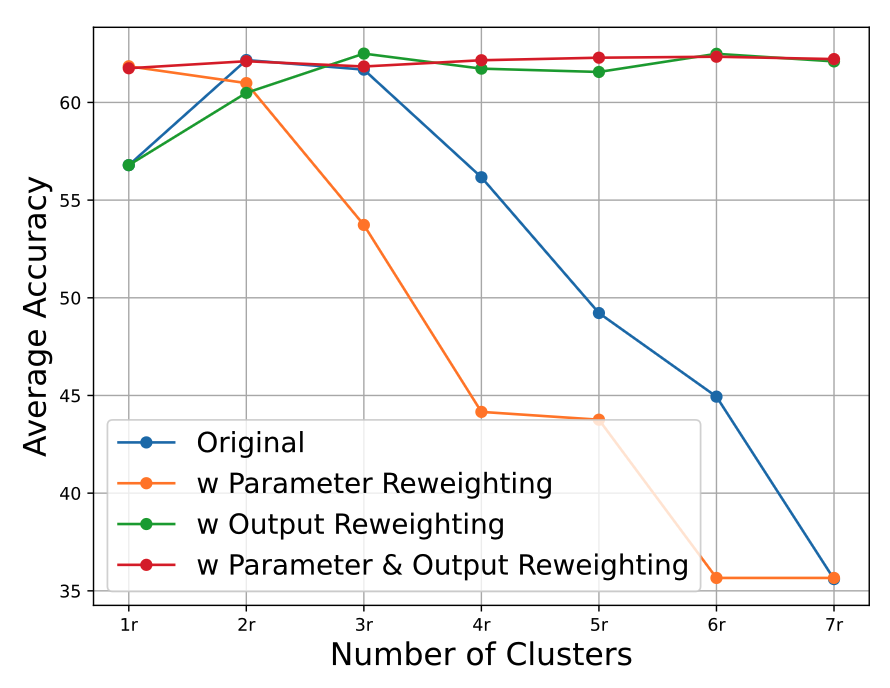
- 기존 LoRA
rank가 증가할 수록 출력 분산이 확장되어 기존 LoRA 계산은 성능 저하를 겪게 됨. 반대로, rank가 너무 작을 경우 파라미터 노름 감소로 인해 최적 성능에 도달하지 못하는 문제 발생 - Parameter Reweighting
rank가 낮을 때는 성능을 크게 향상시키지만 rank가 증가하면 노름 감소가 오히려 출력 분산을 완화해주던 역할이 사라지므로, 분산 확장 현상이 심화되어 성능이 저하됨 - Output Reweighting
rank가 클수록 성능이 안정적으로 향상되지만, 여전히 노름 감소로 인한 효과로 인해 완전한 최적은 아님 - 두 전략 함께 사용
모든 rank 수준에서 가장 안정적이고 뛰어난 성능을 보여주었음
LoRA-LEGO의 유일한 하이퍼파라미터는 클러스터 수 이며, 이중 스케일링 전략을 적용한 이후에는 성능이 매우 안정적이어서 하이퍼파라미터 선택에 민감하지 않음이 입증되었음. 이에 따라, 기본 설정으로는 을 사용함
Merging Different Number of Tasks
태스크 수가 방법에 미치는 영향을 더 잘 평가하기 위해, 각 태스크의 성능을 해당 단일 태스크 LoRA 성능으로 나눈 정규화 점수를 사용하였고, 이들의 평균을 계산하였음.
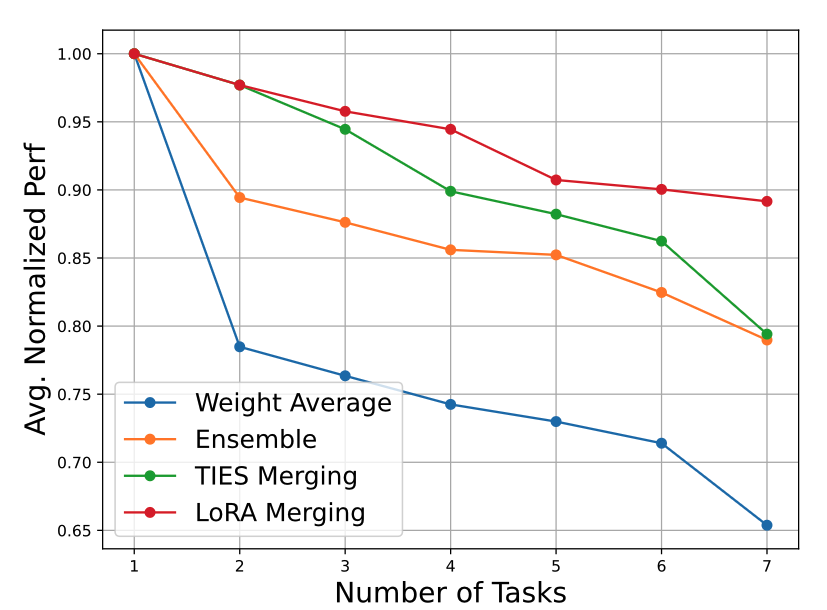
위 그림을 보면 병합되는 태스크 수가 증가할수록 병합된 LoRA의 성능은 일반적으로 감소하는 경향을 보였음
LoRA-LEGO는 파라미터 간섭을 유연하게 해결할 수 있으므로, 태스크 수가 많아질수록 성능이 감소하더라도 그 감소폭이 가장 작았으며, 기준 방법들을 능가하였음
MIXED-TASK EVALUATION
Evaluation Setting
48개 Flan-v2 태스크 기반 LoRA들을 학습시켜 LoRA pool을 만들고, 이를 10개 태스크 크러스터로 그룹화함
각 태스크에서 50개 샘플을 무작위로 추출해 총 2400개로 구성된 통합 테스트셋 생성
LoRARetriever를 사용해, 각 입력 샘플과 LoRA few-shot 샘플 간 문장 임베딩 유사도 계산한 뒤 top-3 관련 LoRA를 선택
Baseline Methods
모든 방법은 일관된 평가 파이프라인을 사용함. 평가 세트의 각 인스턴스에 대해, 먼저 top-3 LoRA를 검색하고, 이후 해당 LoRA들을 조합하여 예측을 수행함. 비교 대상이 되는 LoRA 결합 방법은 다음과 같음
1. Weight Average
2. Ensemble
3. Selection
4. Ties-Merging
Main Results
기존에는 개별 입력에 맞는 LoRA를 검색하여 활용하는 방식이 개인화된 서비스 환경에서 더 효율적이고 효과적임을 보여주었음.
이 논문은 입력마다 top-k LoRA를 검색한 후 LoRA 병합을 통해 어떻게 효과적으로 통합할 수 있는지에 초점을 맞추고 있음. LoRA 조합 방법들의 성능을 IID 시나리오와 OOD 시나리오 모두에서 평가하였음
IID 성능
모든 LoRA가 검색기에 접근 가능한 환경
OOD 성능
각 테스트 샘플이 속한 해당 테스크에 연결된 LoRA를 검색할 수 없도록 마스킹하여, 해당 샘플이 이상적인 LoRA를 사용할 수 없게 만든 환경. 이러한 방식은 LoRA 조합 방법의 태스크 간 일반화 능력을 평가할 수 있게 함
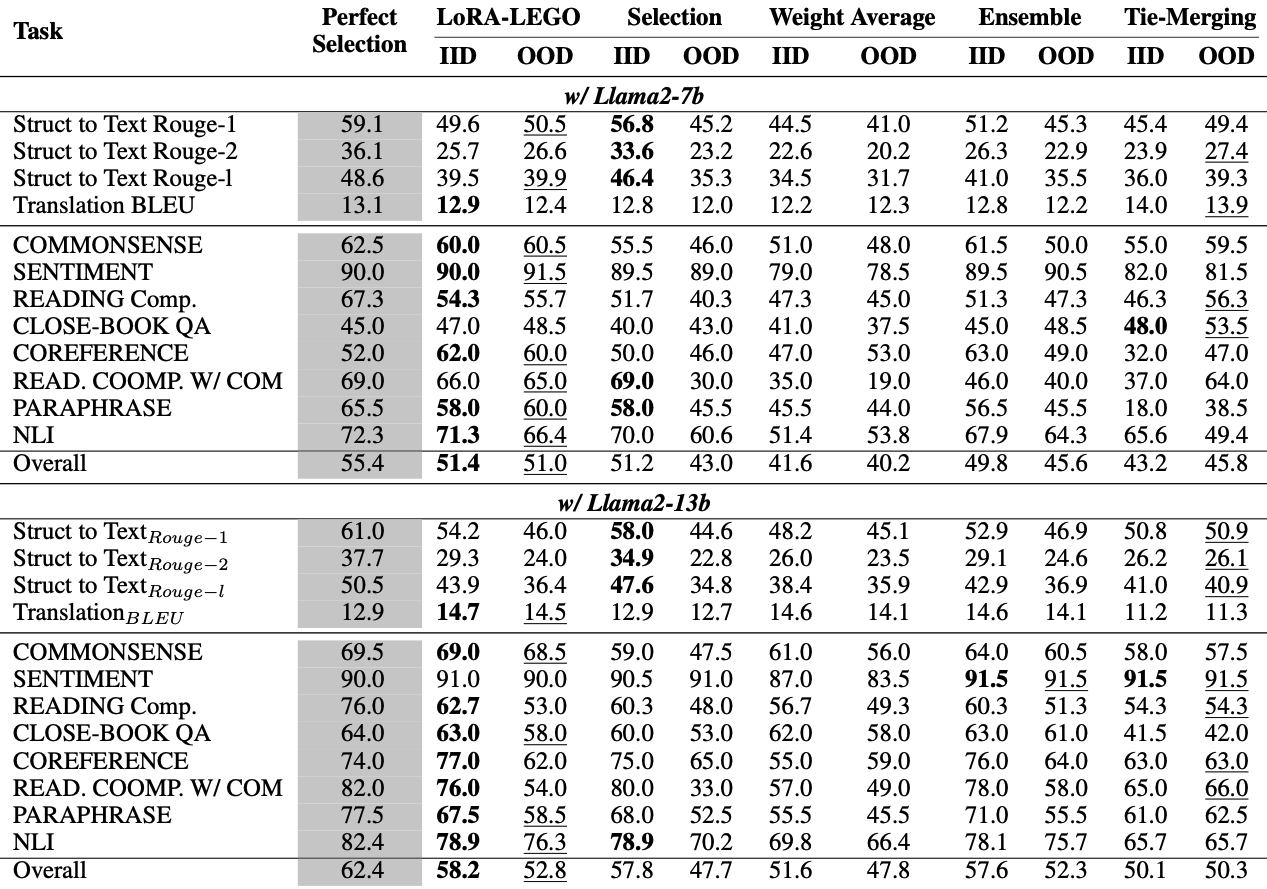
위 표에 따르면 LoRA-LEGO는 IID와 OOD 시나리오 모두에서 다른 조합 방법들보다 뛰어난 성능을 보이며, 파라미터 간섭을 완전히 제거함. 반면, 기존의 LoRA 조합 방법들은 파라미터 간섭을 완전히 해결하지 못해 성능 저하를 겪었음
- IID 시나리오
Selection 방법이 가장 뛰어난 성능을 보였는데, 이는 Retriever가 유사한 태스크들 중에서 가장 적합한 LoRA를 선택할 수 있기 때문. 여기에 기반하여, LoRA-LEGO는 서로 다른 태스크 간 전이 능력을 더욱 효과적으로 활용함으로써 더 나은 성능을 달성함 - OOD 시나리오
Ties-Merging과 Ensemble 방법이 다양한 관련 태스크로부터의 지식을 활용하여 양호한 성능을 보였음. 그러나 LoRA-LEGO는 파라미터 간섭을 효과적으로 해소함으로써, 이보다 더 넓고 다양한 LoRA의 기능을 종합적으로 활용할 수 있었고, 결과적으로 OOD 환경에서도 가장 뛰어난 성능을 보여주었음
RELATED WORK
모델 병합 연구 흐름
1. 손실이 낮은 경로 기반 병합
파라미터 공간에서 low-loss path를 찾아 선형 보간
본 논문도 이와 유사하게 MSU 클러스터링을 통해 파라미터 연결성 향상 추구
2. 지식 전이 기반 모델 병합
서로 다른 작업에서 학습된 모델들을 병합해 종합적인 능력 확보
3. LoRA aggregation 연구 증가
대형 언어 모델(LLM)의 등장 이후, 여러 도메인의 LoRA를 병합하여 활용하는 방식 주목
기존 연구의 한계
많은 기존 방법들이 파라미터 간섭 문제를 간과하였으며 대규모 추가 학습을 요구해 범용성 부족 & 성능 저하를 유발함
CONCLUSION
본 논문에서는 다수의 태스크 특화 LoRA를 하나의 통합 모델로 병합하는 문제를 다루었음. 병합 과정에서 발생하는 주요 장애 요소로 misalignment 및 knowledge conflict에 따른 parameter inference을 식별하였음.
이를 해결하기 위해, LoRA의 핵심 특성을 다음과 같이 규명함
1. 각 rank는 MSU로 작동함
2. MSU는 순열 불변성을 가짐
3. 여러 MSU를 연결하여 포괄적인 LoRA를 구성할 수 있음
이러한 통찰에 기반하여 LoRA-LEGO를 제안하였고, 이는 대상 LoRA들로부터 MSU를 추출하고 클러스터링한 후, 클러스터 중심점을 활용해 병합된 LoRA를 생성하는 방식임
향후 연구 방향으로는 다음과 같은 가능성을 제시함
- 유클리드 거리 외에 Optimal Transport와 같은 대체 거리 측정 방식을 활용하여 파라미터 유사도를 더 효과적으로 포착하였음
- LoRA의 추가적인 모듈화를 통해 연합 학습 등 다양한 응용 분야에서의 활용 가능성 탐색
