※이 내용은 "파이토치와 유니티 ML-Agents로 배우는 강화학습" (민규식,이현호,김영록,정유정,정규열)책을 토대로 정리하였다.
ML-Agents의 구성 요소
Behavior Parameters
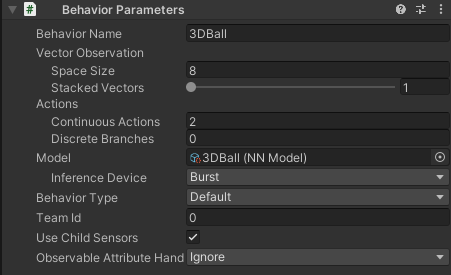
Behavior Name
Behavior Parameters의 이름을 결정함. 여러 개의 Behavior Parameters를 사용하는 경우 이들을 구분하기 위한 것
Vector Observation
본 환경에서 하용할 벡터 관측과 관련된 설정을 함
| Space Size | 현재 환경에서 사용할 벡터 관측의 크기 설정. 8로 설정하면 8개의 숫자로 구성된 벡터를 벡터 관측에 사용한다는 의미 |
| Stacked Vectors | 벡터 관측의 누적 횟수를 결정함. 시간에 따른 누적으로 해당 누적 횟수만큼 시간 스텝에 대해서 벡터 관측을 누적함 |
Actions
에이전트의 행동과 관련된 설정을 함. 에이전트의 연속적 행동과 이산적 행동의 수를 설정할 수 있음.
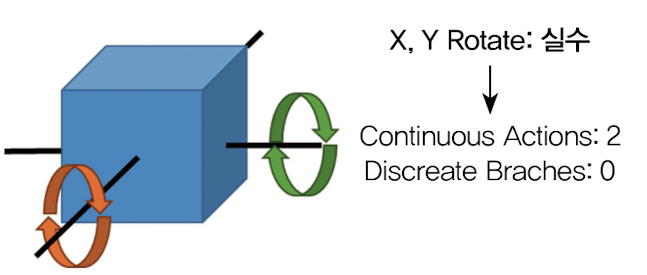
연속적 행동
3D Ball 환경의 경우 에이전트를 두 축으로 회전시키면서 박스를 제어함. 이때 각 축에 대한 회전량을 연속적인 행동 값으로 결정함. 그러므로 두 개의 축에 대한 회전을 제어하기 위해 Continuous Actions를 2로 설정
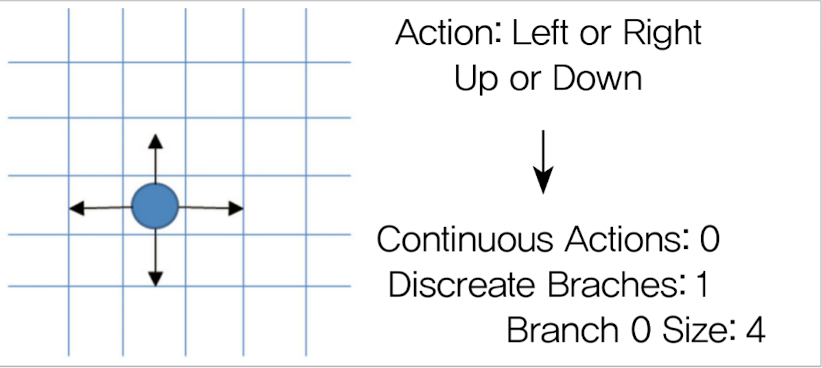
이산적 행동
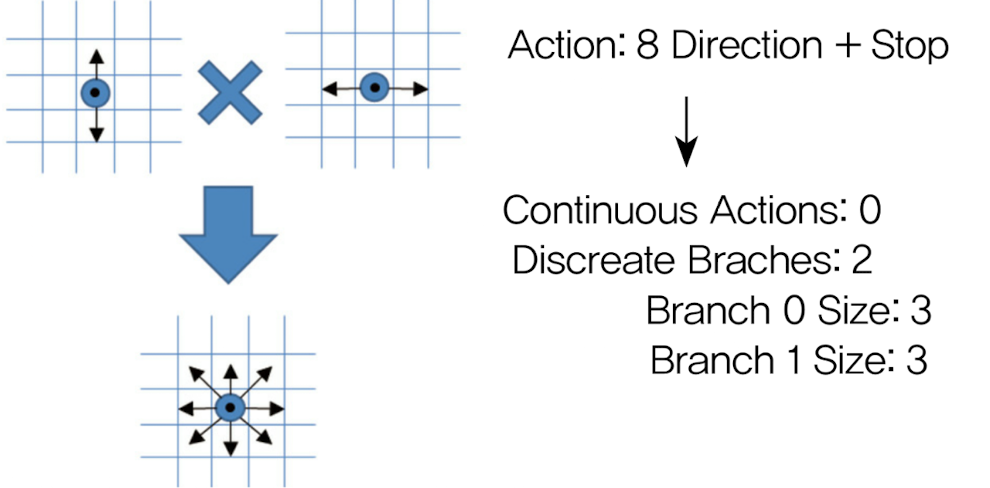
Branches
Branches = 1, Branch 0 Size = 4로 설정한 예시
아래 그림을 보면 에이전트가 격자로 된 공간에서 위,아래,왼쪽,오른쪽으로 이동할 수 있는 상황임. 이 경우 총 이산적인 4개의 행동이 한 세트로 구성돼 있어 Discreate Branches = 1, Branch 0 Size = 4로 정의할 수 있다
Branches = 2,, Branch 0 Size = 3, Branch 1 Size=3
첫번째 Branch의 경우 행동을 정지, 위, 아래 3개로 설정하고, 두 번째 Branch의 경우 행동을 정지, 왼쪽, 오른쪽 3개로 설정했음. 이 경우 첫 번째 Branch와 두 번째 Branch의 행동을 조합하여 새로운 방향으로 최종 행동을 결정할 수 있음.
이런 식의 조합으로 첫 번째 Branch에서 3개의 행동, 두 번째 Branch에서 3개의 행동 조합으로 총 9개의 행동을 정의할 수 있음.
Model
ML-Agents에서 제공하는 알고리즘으로 학습하는 방식인 mlagents-learn을 통해 학습된 에이전트의 모델을 적용할 수 있음. mlagents-learn을 통해 학습하는 경우 학습된 모델이 nn 혹은 onnx라는 확장자를 가진 파일로 저장됨. 해당 파일을 Model에 적용하면 학습된 대로 유니티 내에서 에이전트를 제어할 수 있게 됨. 또한 학습된 모델을 적용하고 유니티 환경을 빌드하는 경우 해당 빌드 환경을 실행하면 에이전트가 빌드된 환경 내에서 학습된 대로 행동하게 됨.
Inference device
학습 모델을 적용하여 추론을 수행할 때 사용할 연산 장치를 결정함. Default, CPU, GPU, Burst로 설정할 수 있음
Behavior Type
| Type | 설명 |
|---|---|
| Default | Behavior Parameters의 Model에 학습 모델(.nn, .onnx 파일)이 적용돼 있다면 해당 모델의 학습 결과대로 에이전트가 행동을 수행하는 Inference를 수행함 |
| Heuristic Only | 적용된 모델이 없다면 정해진 규칙대로 행동하거나 사람이 직접 에이전트를 제어하는 옵션 빌드 후 학습을 수행하려면 Behavior Type을 Default로 설정하고 환경에 대한 빌드를 진행 사용자가 직접 정한 규칙에 의해서만 에이전트를 제어 |
| Inference Only | 적용된 모델을 통해서만 에이전트의 행동을 결정 |
Team ID
에이전트가 공유할 정책 index로, 같은 Team ID를 가진 에이전트들은 정책을 공유하여 업데이트를 한다고 이해하면 됨. 여러 에이전트가 정책을 공유하며 업데이트를 하는 경우 동시에 데이터를 수집하여 빠른 학습이 가능하도록 설정할 수 있음. 또한 여러 에이전트가 존재하는 환경에서 Team ID를 몇 개의 에이전트에 대해서는 0으로 몇 개의 에이전트에 대해 1로 설정할 수 있음. 이 경우 같은 Team ID를 가진 에이전트들은 서로 협력하고 다른 Team ID를 가지는 에이전트들과는 서로 경쟁하며 학습을 수행하는 Multi-Agents 강화학습 환경을 만들 수 있음
Agent Script
ML-Agents에서 에이전트에 대한 코딩은 이 Agent 스크립트 내부에서 진행함. 해당 스크립트에서 어떤 정보들을 관측으로 사용할지, 각 액션 값에 대해 어떻게 에이전트를 제어할 지, 어떤 경우 얼만큼의 보상 혹은 패널티를 줄 것인지, 어떤 조건에서 에피소드를 종료할 것인지 등 각종 강화 학습 에이전트와 관련된 코딩을 수행함.
Max step
해당 스크립트의 파라미터는 Max Step이다. 이는 한 에피소드의 최대 스텝 수를 정하는 값.
Ball, Use Vec Obs
Ball 3D Agent 스크립트에서 코드를 통해 설정된 값, ML-Agents를 위해 사용되는 요소가 아님
Agent Script Code
Initialzie 함수
환경이 처음 실행될 때 한 번만 호출되는 초기화 함수로 각 오브젝트들과 파라미터를 초기화하는 내용이 구성됨
public override void Initialize()
{
m_BallRb = ball.GetComponent<Rigidbody>();
m_ResetParams = Academy.Instance.EnvironmentParameters;
SetResetParameters();
}CollectObservations 함수
에이전트에게 전달할 벡터 관측의 요소를 결정하는 역할을 수행함. 이 함수는 Vector Sensor를 sensor로 정의하고 이 sensor의 AddObservation 함수를 통해 각 데이터를 벡터 관측의 요소로 전달함. 3DBall 환경에서 박스의 x, z축 회전량과 공과 판의 상대 거리의 (x,y,z) 좌표, 공의 속도의 x,y,z 방향 값 까지 총 8개의 값을 벡터 관측에 추가하는 것을 확인할 수 있음. 그러므로 앞에서 Space Size를 8로 설정했음.
✅ Behavior Parameters 내부에 있는 Vector Observation Space Size는 Agent 스크립트의 CollectObservations 함수에서 설정한 벡터 관측의 수와 동일한 값으로 설정해야 함.
public override void CollectObservations(VectorSensor sensor)
{
if (useVecObs)
{
sensor.AddObservation(gameObject.transform.rotation.z);
sensor.AddObservation(gameObject.transform.rotation.x);
sensor.AddObservation(ball.transform.position - gameObject.transform.position);
sensor.AddObservation(m_BallRb.velocity);
}
}OnActionReceived 함수
알고리즘을 통해 결정된 행동에 따라 에이전트 제어, 보상 결정, 에피소드 종료 조건 설정 등을 담당하는 함수. 가장 먼저 에이전트가 결정한 행동을 actionbuffers에서 읽어 오고 그 행동을 환경에 반영함. 3DBall의 경우 행동 값에 따라 연속적인 값을 통해 박스를 2개의 축 방향으로 회전시키는 제어를 수행함. 그렇게 진행된 환경에서 에피소드를 마무리 지을지 또는 보상을 얼마나 줄지 판단하여 에피소드를 진행하게 됨.
public override void OnActionReceived(ActionBuffers actionBuffers)
{
var actionZ = 2f * Mathf.Clamp(actionBuffers.ContinuousActions[0], -1f, 1f);
var actionX = 2f * Mathf.Clamp(actionBuffers.ContinuousActions[1], -1f, 1f);
if ((gameObject.transform.rotation.z < 0.25f && actionZ > 0f) ||
(gameObject.transform.rotation.z > -0.25f && actionZ < 0f))
{
gameObject.transform.Rotate(new Vector3(0, 0, 1), actionZ);
}
if ((gameObject.transform.rotation.x < 0.25f && actionX > 0f) ||
(gameObject.transform.rotation.x > -0.25f && actionX < 0f))
{
gameObject.transform.Rotate(new Vector3(1, 0, 0), actionX);
}
if ((ball.transform.position.y - gameObject.transform.position.y) < -2f ||
Mathf.Abs(ball.transform.position.x - gameObject.transform.position.x) > 3f ||
Mathf.Abs(ball.transform.position.z - gameObject.transform.position.z) > 3f)
{
SetReward(-1f);
EndEpisode();
}
else
{
SetReward(0.1f);
}
}Heuristic 함수
Heuristic Only 모드에서 에이전트를 제어하는 방법을 결정함.
public override void Heuristic(in ActionBuffers actionsOut)
{
var continuousActionsOut = actionsOut.ContinuousActions;
continuousActionsOut[0] = -Input.GetAxis("Horizontal");
continuousActionsOut[1] = Input.GetAxis("Vertical");
}continousActionsOut의 첫 번째 인덱스에는 "Horizontal"입력을 받는데 이는 키보드에서 A,D키 또는 방향키의 왼쪽, 오른쪽을 의미함.
continousActionsOut의 두 번째 인덱스에는 "Vertical" 입력을 받음. 이는 키보드에서 W,S키 혹은 방향키의 위, 아래를 의미함.
Decision Requester, Model Overrider
Decision Period
Decision Request의 Decision Period는 에이전트가 새로운 행동을 결정하는 스텝의 간격임. 이를 5로 설정하면 5스텝마다 한 번씩 행동을 결정함. 그러므로 Decision period의 값이 작아질수록 에이전트는 자주 새로운 행동을 결정하게 됨.
Take Actions Between Decisions
행동 결정 사이의 간격 동안 이전에 결정된 행동을 반복할지, 아니면 아무 행동도 취하지 않을지 선택하는 설정.
예를 들어 Take Actions Between Decision을 체크하는 경우 에이전트가 왼쪽으로 이동하도록 행동을 결정하면 다음 새로운 행동을 결정하기 전까지 계속 왼쪽으로 이동하는 행동을 취함.
만약 해당 설정에 대한 체크를 해제하면 왼쪽으로 이동하는 행동을 한 번만 수행하고 새로운 행동을 결정할 때까지 정지하게 됨.
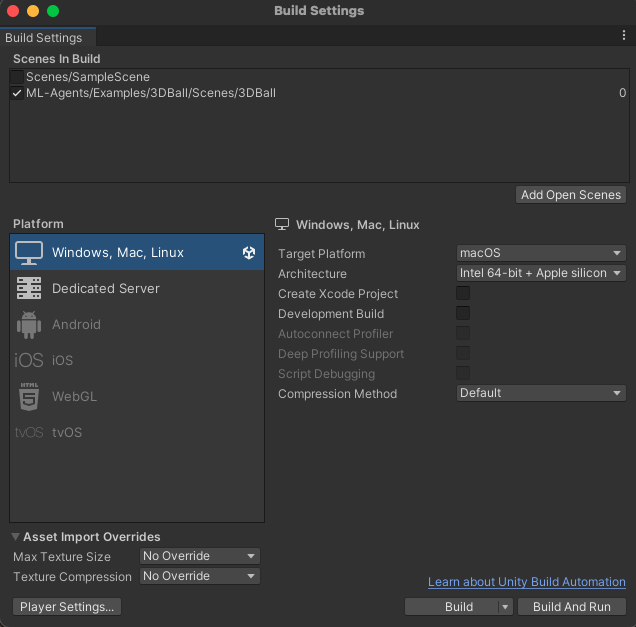
환경 빌드하기
-
Ctrl + Shift + B (windows) or Cmd + Shift + B (Mac)을 사용하여 Build Settings 창을 연다
-
Add Open Scenes 버튼을 통해 Scenes In Build에 현재 씬을 추가한다.
-
플랫폼은 [Windows, Mac, Linux]로 설정하고 Target Plaform은 자신 운영체제에 맞게 선택하자
-
Player Settings를 클릭하여 환경과 관련된 다양한 설정을 할 수 있음
Product Name은 이 이름에 따라 생성되는 파일 이름이 결정됨. 아래쪽 Resolution에서는 실행될 창의 크기를 결정함.
- 설정이 마무리되면 Build를 클릭하고 빌드 파일을 생성한 경로를 설정해 최종적으로 빌드를 마무리함.
mlagents-learn을 이용해 ML-Agents 사용하기
ML-Agents를 사용하여 제작한 환경을 학습하는 방법은 두 가지가 있다.
첫 번째는 ML-Agents에서 제공하는 mlagents-learn 기능을 이용해 학습을 수행하는 것이다 이 경우 강화학습 알고리즘을 직접 구현하지 않아도 되고 간단한 명ㄹ여어만으로 학습을 수행할 수 있다. 하지만 학습과 관련된 파라미터만 변경할 수 있고, 알고리즘에 대한 변경은 제한적이다
두 번째는 ML-Agents의 Python-API를 사용하여 직접 구성한 파이썬 코드를 통해 에이전트를 학습하는 것. 이 경우는 알고리즘에 대한 변경이 자유롭다는 장점이 있지만, 알고리즘을 직접 다 구현해야 한다는 점에서 난이도가 높음.
ML-Agents에서 제공하는 강화학습 알고리즘
ML-Agents는 다음과 같은 알고리즘들을 제공함
| 강화학습 | 모방학습 |
|---|---|
| PPO | BC |
| SAC | GAIL |
| ICM,RND | |
| MA-POCA |
ML-Agents에서 제공하는 학습 방식
| 방법 | 설명 |
|---|---|
| Curriculum Learning | 어려운 문제가 있을 때 처음부터 어려운 문제를 학습하는 것은 어려우므로 난이도를 쉽게 만들고 순차적으로 난이도를 높여가면서 학습을 수행하는 방식 |
| Parameter Randomization | 환경 내의 다양한 파라미터들을 변경해가며 학습을 수행하는 것. |
| Competitive Multi Agent | 퐁 환경을 예시로 생각하자 공을 받아 치는 게임으로 왼쪽과 오른쪽 바 모두 강화학습 에이전트로 설정하고 학습을 진행한다. 두 에이전트가 서로를 이기도록 학습하며 점점 게임을잘 플레이하도록 학습하게 된다 |
| Cooperative Multi Agent | 하나의 에이전트가 희생을 하더라도 결국 모든 에이전트들의 공동 목표인 용 죽이고 탈출하도록 학습을하는 게임 |
어떻게 학습을 시킬까?
먼저 파이썬 3.10.12 가상환경을 만들자
conda crate -n ml-agetns python=3.10.12이후 가상환경을 활성화하자
conda activate ml-agents이후 아래 명령어를 차례대로 입력하자
git clone https://github.com/Unity-Technologies/ml-agents
cd ml-agents
pip install -e ./ml-agents-envs
pip install -e ./ml-agents
우리가 다운받은 ml-agents 폴더로 이동한뒤 아래 형식으로 코드를 실행하자
mlagents-learn config/ppo/3DBall.yaml --env=[3DBall Build파일 경로] --run-id=mlagent_test1
이때 위 처럼 이전 코드가 실패해서 다시 시도할때 mlagent_test1이라는 폴더가 존재하면 실행이 안되므로(동일한 run-id를 가지면) 폴더를 삭제 후 진행 바란다.
이 후 학습이 마무리 되면 onnx파일 생성됨을 확인할 수 있다
이렇게 학습된 onnx 파일을 유니티 프로젝트로 가져오면 Behavior Parameters 내부의 Model에 적용할 수 있음.
mlagents-learn config/ppo/3DBall.yaml --run-id=mlagnet_test1_3dball위와 같이 빌드하지 않고 사용 시 명령 프롬프트에 에디터에서 플레이 버튼을 눌러 학습을 시작하라는 문구가 나옴
Python-API를 통한 에이전트 랜덤 제어
from mlagents_envs.environment import UnityEnvironment
if __name__ == '__main__':
env = UnityEnvironment(file_name = './Env/3DBall/3DBall')
env.reset()
behavior_name = list(env.behavior_specs.keys())[0]
print(f'name of behavior : {behavior_name}')
spec = env.behavior_specs[behavior_name]| 변수 | 설명 |
|---|---|
| mlagents_envs.environment | 유니티 환경 라이브러리를 불러옴 해당 라이브러리의 함수를 통해 ML-Agents 환경 실행, 환경에 대한 상태와 보상 등 다양한 정보 취득, 행동을 환경으로 보내는 명령 등을 수행 가능 |
| UnityEnvironment | 입력으로 설정한 file_name에 빌드된 환경 파일의 경로를 입력하면 환경이 실행되며 해당 환경과 파이썬 코드를 통해 통신 가능 |
| behavior_specs | 이 변수에는 에이전트들의 행동이나 관측 정보들이 저장돼 있음 |
for ep in range(10):
env.reset()
decision_steps, terminal_steps = env.get_steps(behavior_name)
tracked_agent= -1
done = False
ep_rewards = 0| for문 | 에피소드를 10번 진행하는 것을 확인 |
| env.reset() | ML-Agents 관련 요소 중 Agent 스크립트의 OnEpisodeBegin함수 내부의 코드대로 환경을 초기화함 |
| get_steps | 각 스텝에서 에이전트의 상태, 행동, 보상 등의 정보를 반환 환경의 에피소드가 끝나지 않은 상태로 스텝이 진행 중이면 정보는 decision_step에 저장 에피소드가 끝난 마지막 스텝인 경우 terminal_step에 정보들이 저장되고, decision step에는 다음 에피소드의 첫 스텝 정보가 저장됨 |
while not done:
if tracked_agent == -1 and len(decision_steps) >= 1:
tracked_agent= decision_steps.agent_id[0]
action = spec.action_spec.random_action(len(decision_steps))
env.set_actions(behavior_name,action)
env.step()먼저 에피소드의 첫 스텝을 시작할 때, agent_id를 지정하며 tracked_agent를 정의함.
| agent_spec.random_action | 무작위 행동을 도출함. 이 때 decision step의 길이, 즉 에이전트의 총 숫자인 12개의 행동을 도출하여 12개의 에이전트에 대한 행동을 모두 도출하고 이를 action이라는 변수에 저장함. |
| set_action | behavior에 대한 에이전트의 행동 세팅. 모두 동일한 behavior parameter를 가지는 경우 하나의 behavior_name에 대해서 모든 행동을 결정하면 됨 다른 behavior parameters를 가지는 에이전트들이 있는 경우 각 behavior name에 따라 행동을 따로 정의해야 함. |
| step() | 행동 지정이 완료되면 에이전트가 행동을 취하도록 함 |
decision_steps, terminal_steps = env.get_steps(behavior_name)
if tracked_agent in decision_steps:
ep_rewards += decision_steps[tracked_agent].reward
if tracked_agent in terminal_steps:
ep_rewards += terminal_steps[tracked_agent].reward
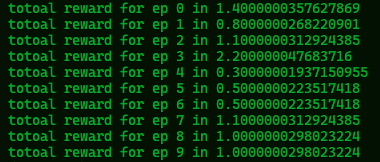
print(f'total reward for ep {ep} is {ep_rewards}')
env.close()행동이 마무리되면 행동의 결과에 따른 정보들을 decision_steps와 terminal_steps로 behavior_name에 따라 읽어옴. 그리고 추적 중인 에이전트가 에피소드를 계속 진행하고 있는 상태인지, 또는 에피소드가 마무리된 상태인지 구분하여 보상을 저장함. 만약 에피소드가 종료되는 단계였다면 에피소드의 종료를 나타내는 Done 변수를 True로 설정하여 while 문을 나오게 되고 해당 에피소드의 보상 정보를 출력하며 에피소드를 마무리함.